
이전에 YOLOv9에 대해 논문 요약을 한 적이 있었다.
이번 포스팅에서는 YOLOv9의 시발점인 YOLO의 초기 모델에 대한 논문을 읽고 요약을 해볼 것이다.
Introduction
YOLO의 아이디어는 당연하게도 사람에게서 왔다. 인간이 어떤 물체를 감각기관을 통해 인식하고 뇌를 거쳐서 이것이 어떤 물체인지 판별하는데 까지 걸리는 시간은 0.1초도 안걸릴 정도로 상당히 빠른 순간에 프로세스가 진행된다. 그러나 YOLO가 등장하기 이전 Object Detection 기법들은 정확성은 높았으나, 인식하는데 까지 시간이 걸린다는 단점이 존재했었다. 그렇기 때문에 자율주행 자동차 같이 실시간으로 객체를 인식해서 시스템에 반영해야 하는 것들에는 적용을 하기에 분명한 한계점이 존재하였다.

R-CNN 같은 기법들은 region proposal 같은 방법을 통해 image에 potential bounding box를 만들고 드 다음에 이 box에 대해 classifier를 동작시키는 방식을 사용해왔다. 이 Classifier를 통해 분류가 끝나면 후처리 (post-processing)가 진행되는데 크게 3가지가 진행된다.
- refine the bounding boxes
- eliminate duplicate detections
- rescore the boxes based on other objects in the scene
이러한 과정들이 복잡하고 느릴 뿐더러 각각의 component를 개별적으로 training 시켜야 하기 때문에 최적화가 힘들다는 단점이 존재하였기 때문에 다른 방법을 고안하게 되었다.
그래서 연구원들은 object detection을 single regression problem으로 생각하기 시작했고 실시간 객체 검출이라는 개념이 등장하게 되었다.
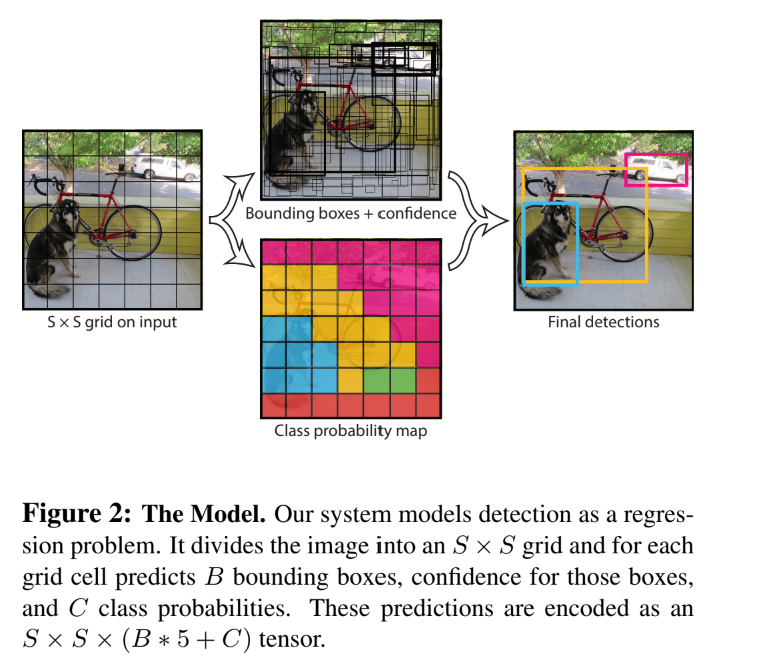
YOLO의 동작 과정은 단순하다. Figure1에서 볼 수 있듯이 하나의 Convolution network가 여러개의 bounding box를 동시에 예측해서 분류하는 것이다. YOLO는 전체 이미지를 학습해서 곧바로 최적화를 하기 때문에 복잡한 pipeline도 필요없고 그로 인해 기존의 model들 보다 훨씬 속도가 빠르게 된다.
Unified Detection
위에서 말했듯이 YOLO는 object detection의 각각의 구성 요소들을 하나의 neural network로 합쳐놓은 모델이라고 생각하면 된다. 이 network는 합쳐져 있기 때문에 하나의 이미지에서 각각의 bounding box를 예측하기 위해 feature들을 사용한다.
우선 YOLO는 input image를 SxS grid로 나눈 뒤 객체의 중앙이 grid cell로 들어오게 된다면 그 객체를 인식했다고 판단을 한다. 각각의 grid cell은 bounding box B를 예측하고 box들에게 confidence score를 부여한다.
여기서 confidence 값이란 모델에서 box가 얼마나 객체를 포함하고 얼마나 정확히 예측을 했는지에 대한 수치이다.
These confidence scores reflect how confident the model is that the box contains an object and how accurate it thinks the box is that it predicts
이를 수식으로 나타내면 가 된다. 만약 어떠한 객체도 grid cell에 존재하지 않는다면 confidence score는 0이되고, 객체가 존재한다면 예측과 실제 간의 IOU (Intersection over union) 값이 된다.
각각의 bounding box는 이렇게 5개의 예측값을 갖는다. (x,y)는 box의 중앙을 나타내고, w,h는 전체 이미지와 관련된 예측, confidence score는 위에서 말한 IOU를 의미한다.
각각의 grid cell은 또한 조건부 확률을 예측하는데, 이 역시 confidence score와 마찬가지로 grid cell이 객체를 포함하는 정도에 대한 값이다.
이 값들을 모아서 test를 할 때 위의 두 값을 곱한다.
이 값은 결과적으로 class에 특정되는 confidence 값을 return 하게 된다.
1. Network Design
YOLO의 network architecture는 이미지 분류에서는 GoogLeNet의 영향을 받았다고 한다.
24개의 convolution layer 뒤에 2개의 fully connected layer가 따라오는데, GoogLeNet에서 사용한 inception model 대신에 단순히 3x3 convolutional layer과 1x1 reduction layer를 사용했다.

이를 통해 마지막에 나오는 output은 7x7x30 크기의 tensor가 나오게 된다.
2. Training
연구원들은 ImageNet의 1000개의 class competition dataset으로 convolution layer를 pretrain 시켰다. 이 pretraining 과정에서 위의 그림에 있는 20개의 convolutional layer를 average pooling layer와 fully connected layer 뒤에 사용했다. 이를 통해 ImageNet validation set에서 88%의 정확도를 보였다.
그 뒤, 성능을 향상시키기 위해 4개의 convolutional layer들을 추가하고 2개의 fully connected layer들을 무작위로 초기화된 weight와 함께 추가하였다. Detection은 fine-grained visual information을 요구하기 때문에 네트워크의 resolution을 224x224에서 448x448로 늘렸다고 한다.
이 네트워크의 마지막 layer는 위에서 수식으로 설명했듯이 class probability와 bounding box coordinate를 동시에 예측하기 때문에 bounding box의 w, h 값을 0과 1 사이의 값으로 정규화 시키고 x, y 값도 특정한 grid cell의 offset이 되도록 0과 1 사이로 정규화 시켰다.
여기서 특이한 점은 activation function으로 보통 ReLU함수를 쓰는데, 여기서는 leaky ReLU를 사용했다는 것이다.
Leaky Relu의 장점은 기존의 ReLU함수 와 달리 미분을 했을 때 0이 되는 부분이 존재하지 않기 때문에 vanishing gradient 문제가 발생하지 않는다는 점이다. 네트워크의 깊이가 깊어지게 되면 보통 vanishing 또는 exploding gradient의 문제가 발생한다. 그렇게 되는 이유가 점점 0에 가까워지는 값이 되게 되어 어느 순간 사라지게 되는 문제가 생기기 때문인데 Leaky ReLU 함수를 사용하게 되면 적어도 0이 되지는 않기 때문에 vanishing gradient 문제를 예방할 수 있는 것이다.
또한 이 모델에서는 평균적인 정확도를 최대화하고자 하는 목표와는 부적합함에도 불구하고 SSE (Sum Squared Error)를 사용하였는데 이는 SSE가 최적화에 용이하기 때문이다. SSE의 경우 localization error에게 동일한 weight 값을 부여하는데, 이는 이상적이지 않다. 또한 모든 이미지에서 많은 grid cell이 객체를 포함하고 있지 않을 수도 있다. 이렇게 되면 confidence score의 합이 0에 가까워지게 되고 gradient를 overpowering하게 되어 exploding gradient가 발생할 가능성이 높아지게 된다.
이 문제점을 해결하기 위해 bounding box의 loss를 증가시키고 객체를 포함하지 않는 box의 confidence 예측 값에서 loss를 감소시켰다. 여기서 parameter 가 추가되었다.
를 줘서 coordinate에 대한 계수를 더 높게 주고 객체를 포함하지 않는 box에 대한 계수를 1보다 작게 부여하였다.
SSE는 또한 박스의 크기에 영향을 받지 않는다. 그 말인 즉슨 박스의 크기가 크든 작든 똑같은 weight를 부여한다는 의미이다. 이 모델에서 error metric은 큰 box에서의 작은 오차가 작은 box에서의 오차보다 작게 반영되어야 하기 때문에 이 모델에서는 w, h를 직접적으로 예측하는 것 대신 square root를 통해 예측을 하였다.
Loss function
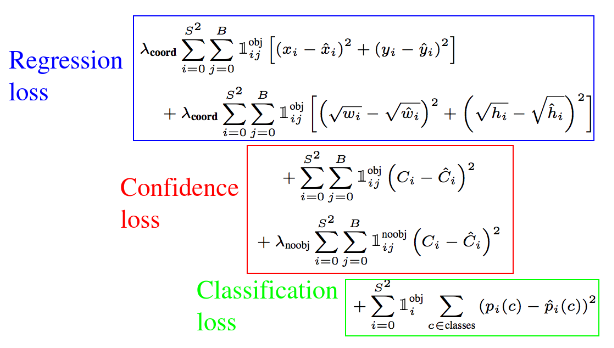
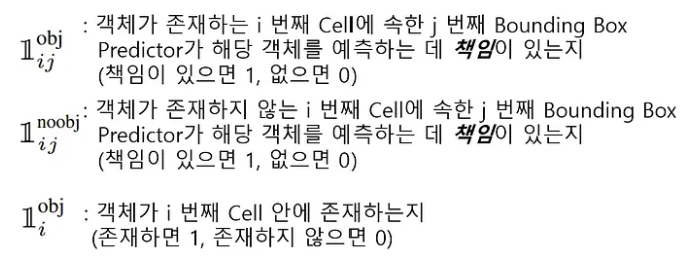
Loss 함수를 살펴보면, 예측값과 실제값의 차이를 구하기 위해 SSE를 사용하고 있는 것을 확인할 수 있다.
-
먼저
Regression loss에 대해 살펴보면 가 앞에 곱해져 있는 것을 확인할 수 있다. 아까 위에서 5로 설정해주었기 때문에 5가 앞에 곱해졌다고 생각하면 된다. 이 식을 통해 구하고자 하는 내용은 모든 grid cell에서 예측한 B개의 bounding box의 좌표 와 GT box 좌표 사이의 차이를 구하는 것이다. -
두 번째로
Confidence loss에 대해 살펴보면 여기서는 를 곱해 객체가 없는 영역에 대한 가중치를 줘서 클래스 불균형을 해소하고 있다. 이를 통해 구하고자 하는 내용은 모든 grid cell에서 예측한 B개의 클래스에 속할 확률값과 GT 값의 오차를 구하기 위함이다. -
마지막으로
Classification loss에 대해 살펴보면 클래스 별 확률을 구한 것으로 각 클래스별 오차의 제곱으로 구한다.
Training Info
- Epoch : 135
- Batch Size : 64
- Momentum : 0.9
- Decay : 0.0005
- Learning rate
- 0.01 - 75 epochs
- 0.001 - 35 epochs
- 0.0001 : 30 epochs
- Dropout : Avoid Overfitting
- Extensive data augmentation
3. Limitations of YOLO
-
공간적 제약
: bounding box prediction에 있어서 큰 공간적 제약이 존재하는데, 이는 grid cell이 오로지 2개의 box만 예측할 수 있고 하나의 class만 가질 수 있기 때문이다. 이 공간적 제약은 model이 예측할 수 있는 주위에 존재하는 객체의 수를 제한하게 된다. -
이 모델의 경우 data로부터 bounding box를 예측하는 방식을 배우기 때문에 새롭고 특이한 종횡비 또는 구성의 객체로 일반화하는 것이 어렵다
-
Architecture가 input image로부터 여러개의 downsampling layer들을 갖고 있기 떄문에 bounding box를 예측하는 과정에 있어 상대적으로 거친 feature들을 사용한다.
-
Detection 성능을 근사하는 과정에서 loss function을 training 시킬 때 bounding box의 크기에 상관없이 error를 모두 동일하게 처리를 한다.
(큰 box의 작은 error 보다 작은 box의 작은 error가 IOU에 더 큰 영향을 미치기 때문)
Experiments
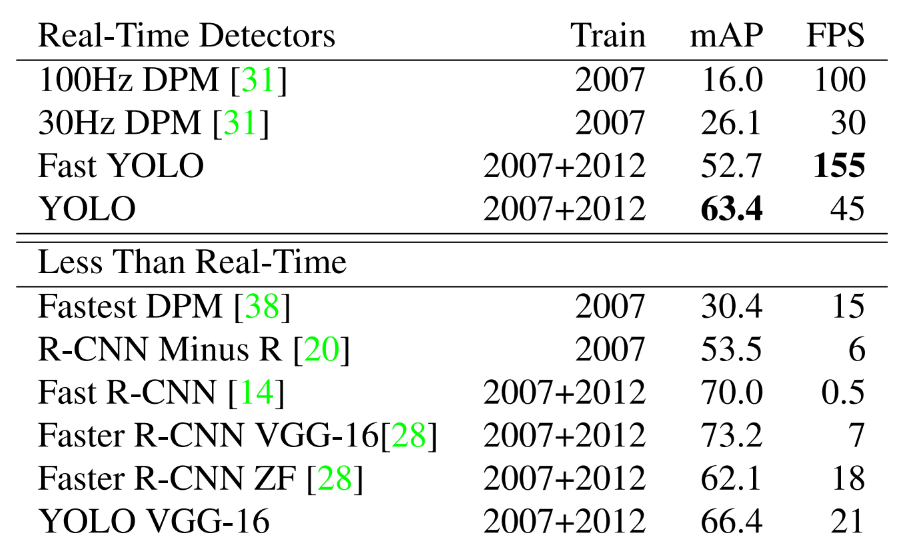
위의 표를 보면 YOLO가 mAP값이 높게 측정되고, Fast R-CNN보다는 낮지만 FPS값이 높게 측정되는 것을 알 수 있다.
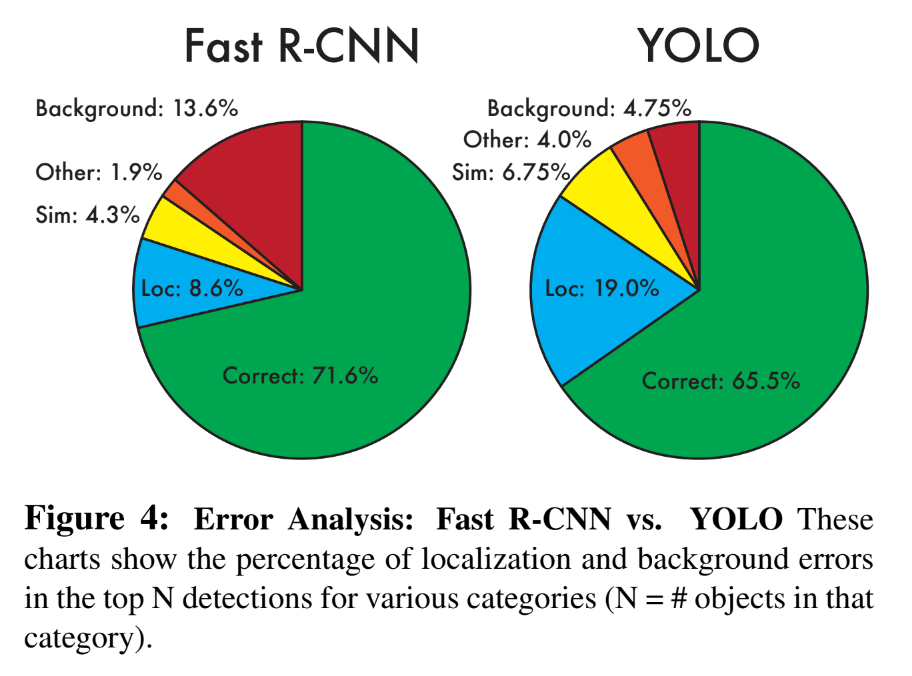
그리고 YOLO를 Fast R-CNN과 비교하였을 때, 비록 정답을 옳게 예측할 점수는 낮지만 (71.6% > 65.5%) False Positive인 배경에 대한 잘못된 예측은 훨씬 적게하는 것을 알 수 있다. (13.6% > 4.75%)
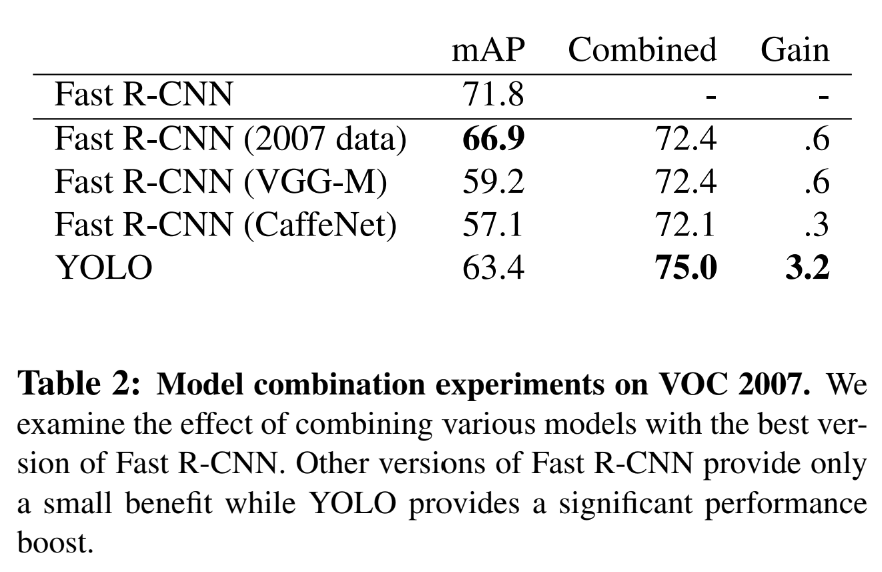
그렇기 때문에 background mistake를 줄이기 위해 Fast R-CNN과 YOLO를 결합해보기도 하였다.
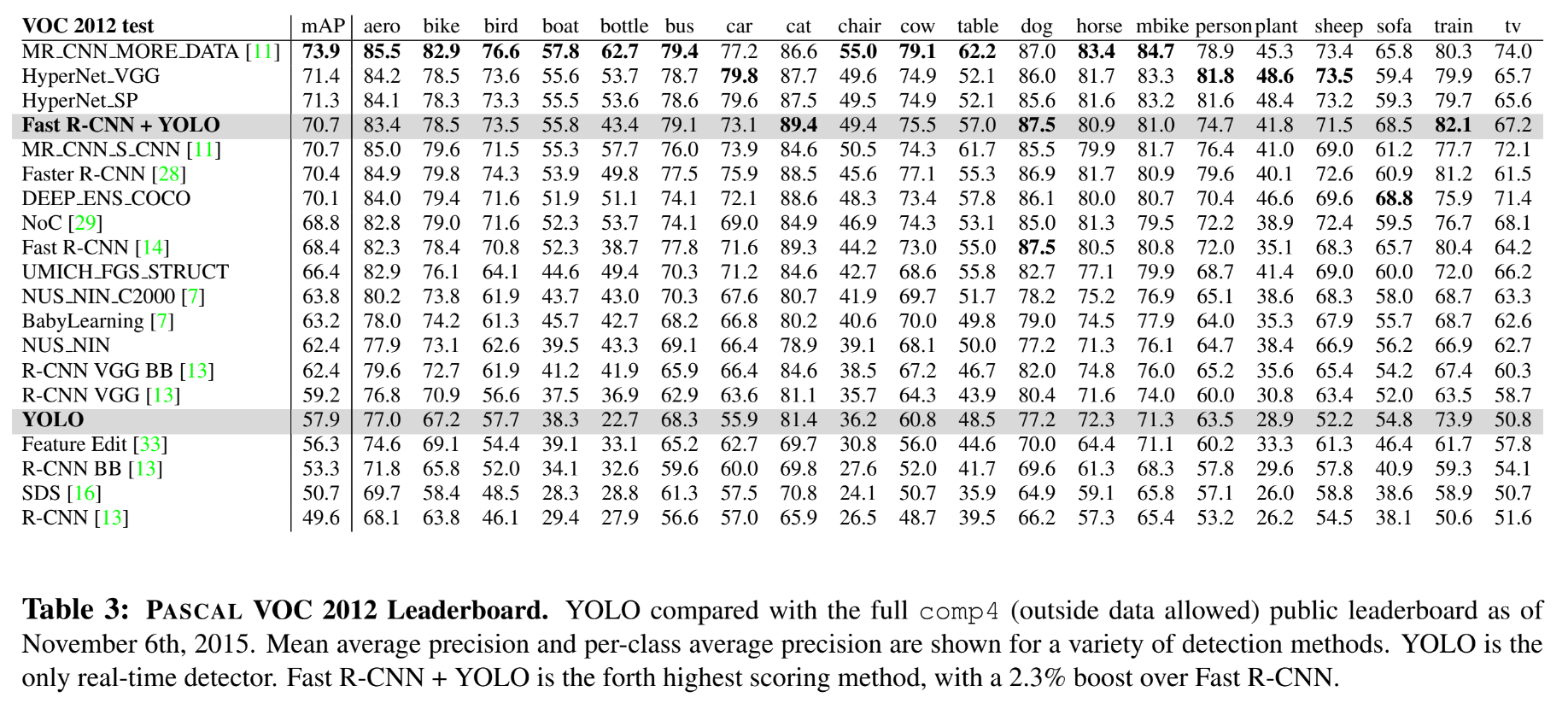
그랬을 때 mAP 값은 높게 나왔지만, 이 경우 각각의 모델을 별개로 학습 시킨 뒤 결과를 합친 것이기 때문에 실시간 객체 인식이라는 YOLO의 장점을 활용할 수가 없다.
이상 Object Detection 기술의 새로운 paradigm을 연 실시간 객체 인식 알고리즘 YOLO에 대해 살펴보았습니다. 긴 글 읽어주셔서 감사합니다ㅎㅎ
참고용으로 아래의 영상을 보면 YOLO에 대해 이해하기 좋을 것 같아서 첨부합니다.
(글보다는 동영상이 이해하기 좋잖아요?)
Reference
[Darknet - YOLO] https://pjreddie.com/darknet/yolo/
[YOLO 논문 출처] https://arxiv.org/abs/1506.02640
