
YOLO라고 하면 한번 사는 인생 후회없이 살다가 가자 라는 의미를 지닌 You Only Live Once를 떠올릴 것이다.
그러나 Object Detection 분야에서의 YOLO는 You Only Look Once 즉, 한번 보자마자 객체가 무엇인지를 탐지해낼 수 있는 알고리즘을 의미한다.
YOLO에는 여러가지 버전들이 있는데, 이번에는 그 중에서도 가장 최근에 나오느 YOLOv9에 대해 알아보고자 한다.
참고
Introduction
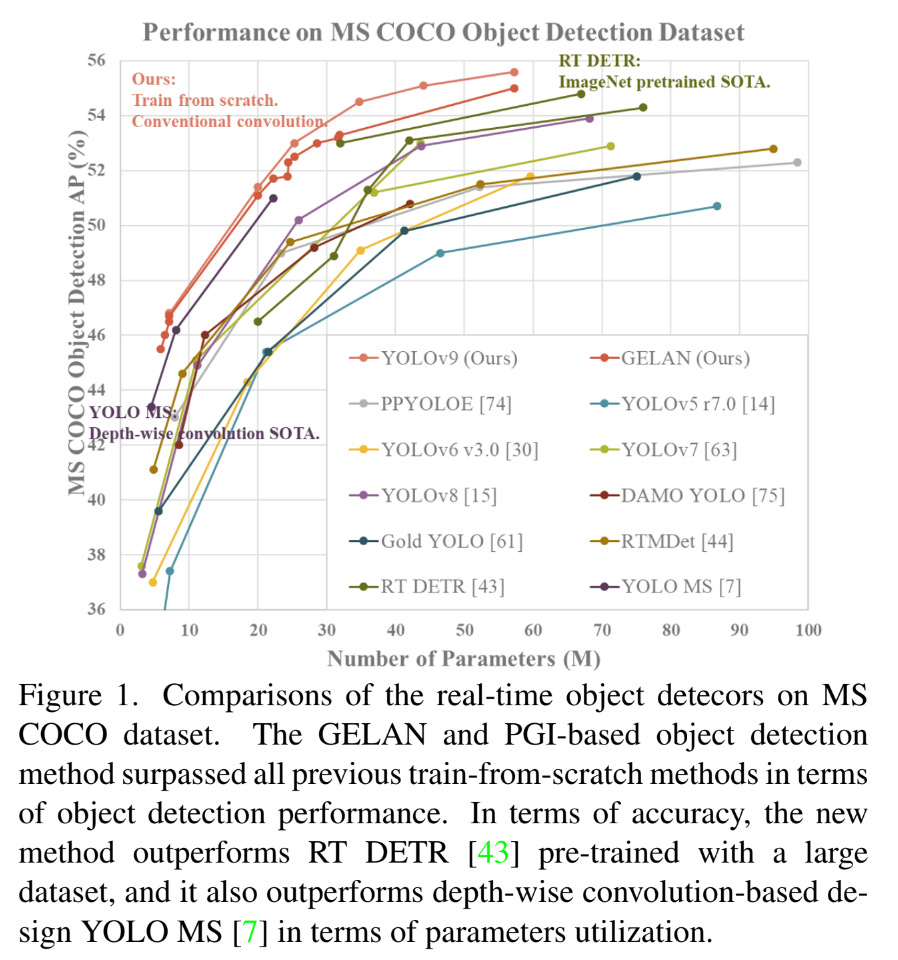
Deep Learning 기반의 모델들은 Computer Vision과 NLP 등의 분야에서 높은 성능을 보이고 있다. 최근 연구원들은 CNN이나 Transformer처럼 더욱 강력한 시스템구조와 학습 기법들을 어떻게 개발할지에 focusing 중이다. 더하여 몇몇 연구원들은 loss function과 같은 object function을 개발하려고 하는데 이는 input과 target의 완벽한 mapping을 찾아야 한다.
여기서, 과거의 연구들이 간과한 점이 있는데 이는 input data가 feedforward network 과정에서 무시할 수 없는 양의 정보 손실이 있다는 점이다. 이는 곧 편향된 gradient를 유도할 수 있다. (Overfitting)
이를 우리는 Information Bottleneck이라고 한다.

따라서 이 문제를 줄이기 위해 최근에 들어서는 다음과 같은 방법을 사용한다.
1. Reversed architecture들의 사용
- repeated input data를 주로 사용
- 명시적인 방법으로 input data의 정보를 유지함
2. Masked modeling의 사용
- reconstruction loss를 주로 사용
- 추출된 feature들을 최대화 하기 위해 암묵적인 방법을 채택함
- input 정보를 갖고 있음
3. Deep Supervision Concept
- 중요한 정보가 더 깊은 층으로 전달될 수 있도록 보장하기 위해 feature에서 target으로 넘어가는 mapping을 미리 세울수 없게 하면서 중요한 정보를 잃지 않도록 shallow feature들을 사용함
그러나, 위의 3가지 process들도 문제점이 존재했는데 training과 inference process에서 각기 다른 결점들이 존재한다는 것이다. 또한 이전에 ResNet에서 다뤘던 문제였던 network의 깊이가 깊어지면서 어느 순간 vanishing/exploding gradient로 인해 성능이 나빠지는 것 처럼 이 역시 너무 깊은 모델을 만들 수 없어서 high-order semantic information을 모델링하기에 제한점이 존재했다.
이 모든 것들을 해결하고자 PGI (Programmable Gradient Information)이 등장하게 되었다. PGI의 목적은 결국 deep feature들이 target task를 수행하면서 주요한 특성들을 유지하기 위해 auxillary reversible branch로 reliable한 gradient를 만드는 것이다. 이렇게 하면 기존의 deep model에서 발생하는 semantic loss를 줄일 수 있기 때문에 더 좋은 성능을 얻어낼 수 있다. 또한 auxillary branch에 만들어지기 때문에 추가적인 cost도 필요가 없게 된다.
PGI의 경우, target tast에 적합한 loss 함수를 자유롭게 선택할 수 있기 때문에 mask modeling으로 부터 생기는 문제도 극복할 수 있다.
Related work
Real-time Object Detectors
현재 Real-time object detector의 mainstream은 누가 뭐래도 YOLO이다. 이 논문에서는 여러 Computer vision task와 다양한 시나리오에서 효과적이다라는 것이 입증된 YOLOv7을 사용하였고, 여기에 architecture와 training process를 개선시키기 위해 GELAN (Generalized ELAN)을 사용했다.
Reversible Architectures
Reversible architecture의 실행 단위는 reversible conversion의 특성을 무조건 유지해야한다. 그렇기 때문에 각각의 layer가 원래의 정보를 갖고 있어야 한다는 것을 보장해야 한다.
이 논문에서는 DynamicDet 구조를 reversible branch 구조의 기저라고 제안한다. 이 제안된 새로운 inference process 동안 추가적인 connection을 요구하지 않기 때문에 speed의 장점, parameter의 양, 정확성을 완전히 보유할 수 있게 된다.
The proposed new architecture does not require additional connections during the inference process, so it can fully retain the advantages of speed, parameter amount, and accuracy.
DynamicDet
CBNet (Composite Backbone Network) + YOLOv7
Auxiliary Supervision
Deep supervision은 중간 층에 추가적인 예측 layer를 삽입함으로써 훈련을 실행하는 가장 흔한 auxillary supervision 방법이다. 특히 transformer model에 의해 제안된 Multi-layer decoder의 적용이 가장 흔하다.
또 다른 auxiliary supervision 방법은 intermediate layer에 의해 제공된 feature map들을 아내하고 이것들이 target task들에게서 제공받은 특성들을 갖게 하기 위해 관련된 메타 정보를 이용하는 것이다.
이 과정들은 모두 object detector의 정확성을 높이기 위해 segmentation loss나 depth loss를 포함한다.
그러나, auxillary supervision의 경우 large model에만 적용할 수 있기 때문에 lightweight model에 적용하게 될 경우 성능을 악화시키는 under parameterization phenomenon이 발생할 수 있다. 그래서 PGI를 적용하여 lightweight model도 적용할 수 있도록 하고자 하는 것이다.
Problem Statement
보통 Deep neural network에서 수렴에 문제가 생기는 것의 원인은 Vanishing / Exploding gradient라고들 한다. 그러나 최근의 model들은 다양한 정규화기법이나 ReLU나 tanh 같은 activation 함수들을 적용함으로써 이러한 문제를 해결했다. 그럼에도 여전히 수렴 속도가 너무 느리거나 결과가 좋지 않은 문제점들이 존재한다.
이 논문에서는 이러한 문제들의 원천을 탐색하기 시작했고 information bottleneck problem의 분석을 통해 매우 깊은 network에서 온 초기 gradient는 목표를 달성하기 위해서는 많은 양의 정보를 잃을 수 밖에 없다고 추측했다.
Through in-depth analysis of information bottleneck, we deduced that the root cause of this problem is that the initial gradient originally coming from a very deep network has lost a lot of information needed to achieve the goal soon after it is transmitted.
Information Bottleneck Principle
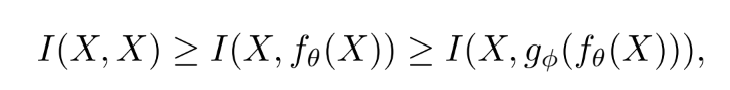
Network의 깊이가 깊어질 수록 원본 data는 잃어버리기 쉬울 것이라고 생각한다. 그러나, Deep neural network의 parameter들은 network의 output 뿐만 아니라 주어진 target에 근거하고 loss 함수를 계산함으로써 새로운 gradient를 만든 뒤 network를 update한다. DNN의 output이 예측된 target에 대해 완전한 정보를 갖고 있을 확률은 적다고 생각하기 때문에 network를 training하는 과정에 불완전한 정보를 사용하게 하여 unreliable gradient와 poor convergence를 야기한다.
This will make it possible to use incomplete information during network training, resulting in unreliable gradients and poor convergence.
이 문제를 해결하는 한가지 방법으로는 model의 크기를 직접적으로 늘리는 것이다. 모델을 구성할 때 더 많은 양의 parameter를 사용하게 되면 더 완전한 data의 전송이 가능해지기 때문이다.
그러나 이 방법 역시 근본적으로 unreliable gradient 문제를 해결할 수 없다.
Reversible Functions
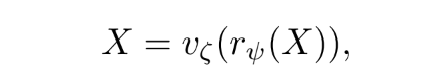
위의 그림에서의 함수처럼 함수 이 역변환 함수 를 갖고 있을 때 이것을 reversible function이라고 부른다고 한다.
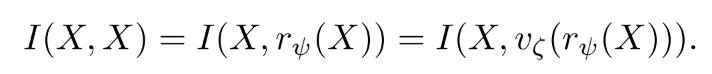
만약 network의 변환 함수가 reversible 함수로 구성되어 있다면 더 많은 reliable gradient가 model을 update하기 위해 얻어진다고 한다. 따라서 오늘날의 deep learning 기법은 reversible property에 순응하기 위해 다음과 같은 구조를 사용한다.
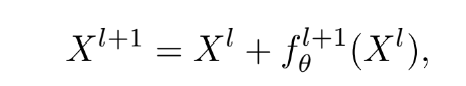
이 모델의 경우 수천개의 layer들이 있는 DNN의 수렴을 도와주지만, 어려운 문제에 대해서는 이 모델이 우리가 간단한 mapping 함수 찾는 것을 어렵게 한다. 이렇게 되면 굳이 DNN을 사용할 필요가 없게 된다. 이러한 점 때문에 layer의 개수가 작을 경우 ResNet의 성능이 PreAct ResNet보다 높다고 한다.
더하여, 상당한 진전을 이루기 위해 transformer model에서 masked modeling을 사용했었다.
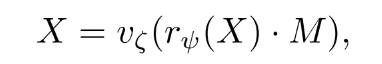
여기서 M은 Dynamic Binary Mask이다. Transformer 뿐만 아니라 Diffusion model이나 VAE에서도 위의 task들이 사용되는데, 만약 이러한 모델들을 lightweight model에 적용한 경우, lightweight model이 많은 양의 raw data에 대해 under parameterized 될 수 있기 때문이다.
그래서 이러한 점 때문에 information bottleneck 구조의 개념을 적용하려고 시도했다고 한다.
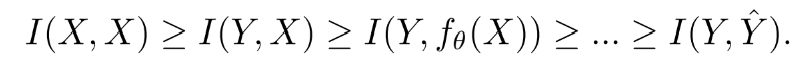
lightweight model이 parameterized state에 있게 되면 feedforward stage에서 중요한 정보를 잃어버리기 쉽게 된다. 그래서 lightweight model에 대한 목표를 "how to accurately filter from "로 정했다. 왜냐하면 가 에서 매우 작은 부분을 차지하고 있기 때문에 feedforward 단계에서 손실되는 정보의 양이 크지 않더라도 를 포괄하는 훈련 효과는 크게 영향을 받을 것이다.
위의 분석을 기반으로 연구원들은 model을 update하기 위한 reliable gradient를 만들어 내는 것 뿐만 아니라 shallow, lightweight한 neural network에도 적합한 DNN을 제안하는 것을 원했다고 한다.
Methodology
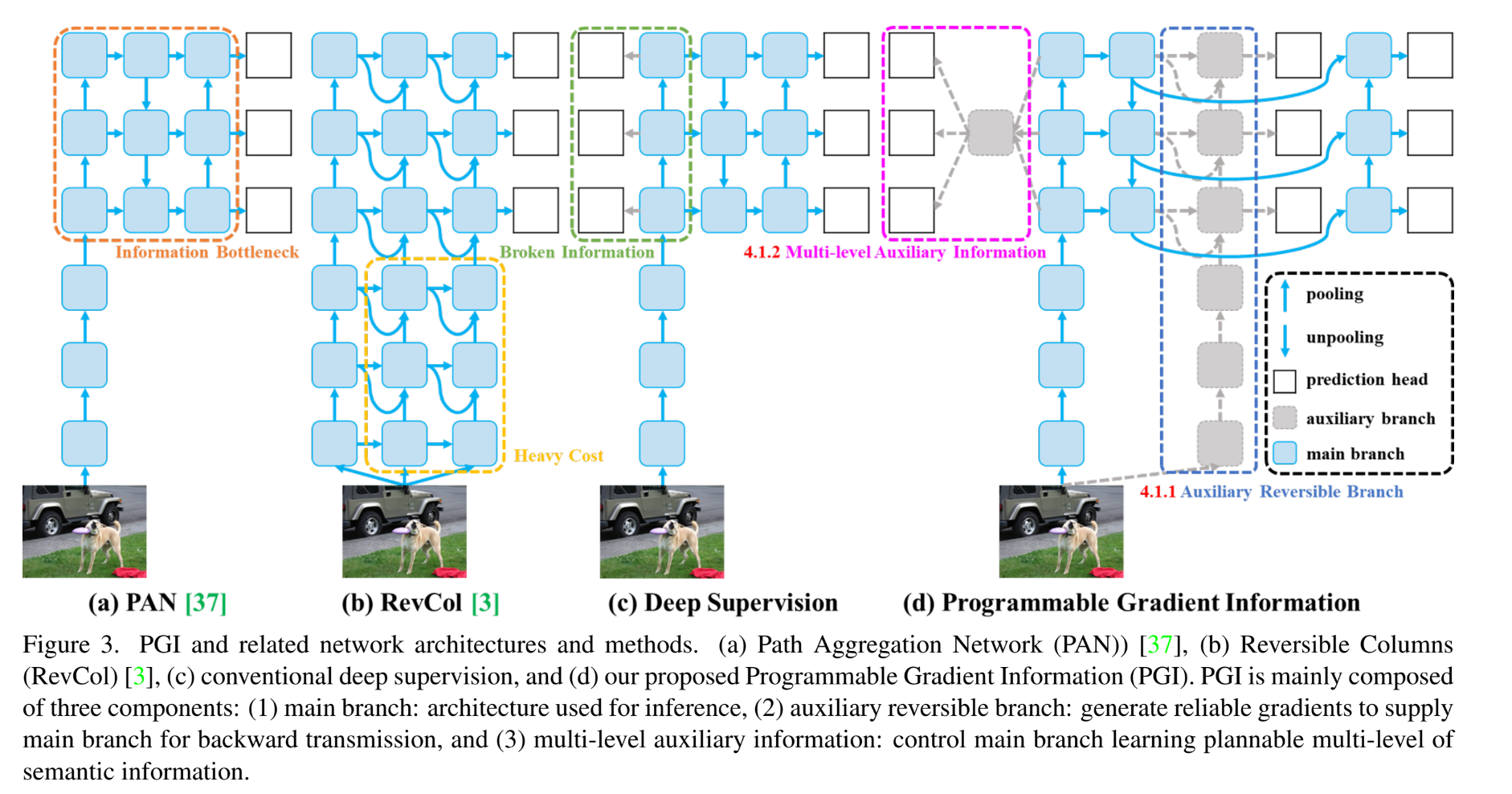
Programmable Gradient Information
- Main branch
- Auxillary reversible branch
- Multi-level auxillary information
PGI는 이 세가지를 포함한다.
네트워크가 깊어지는 것은 loss function이 reliable gradient를 만들 수 없는 loss 함수를 만드는 information bottleneck 현상을 야기한다.
Network deepening will cause information bottleneck, which will make the loss function unable to generate reliable gradients.
1. Auxillary Reversible Branch
PGI에서 auxiliary reversible branch를 제안한 이유는 reliable gradient를 만들고 network parameter를 update 하기 위함이였다. Data에서 target으로 정보를 제공함으로써, loss 함수는 guidance를 제공하고 불완전한 feedforward로부터 잘못된 상관관계를 찾을 가능성을 피라게 한다. 이를 위해 reversible architecture를 제안했다.
그러나 이 역시 엄청난 inference cost가 든다. 이 논문의 목표가 reliable gradient를 얻기 위해 reversible architecture를 사용하는 것이기 때문에 "reversible"라는 단어는 inference stage에서 필수적인 조건이 아니다.
이 논문에서 제안한 방법은 main branch가 완전한 원래의 정보를 갖는 것을 강요하지는 않지만 auxiliary supervision mechanism을 통해 유용한 gradient를 만듦으로써 update한다. 이 모델의 가장 큰 장점은 더 얕은 네트워크에도 적용할 수 있다는 것이다.
Our proposed method does not force the main branch to retain complete original information but updates it by generating useful gradient through the auxiliary supervision mechanism. The advantage of this design is that the proposed method can also be applied to shallower networks
2. Multi-level Auxiliary Information
Deep supervision branch를 연결한 이후에 shallow feature를 학습하는 것은 더 작은 객체 인식에 필요하다. 그러나 이 과정에서 target object를 예측할 때 필요한 많은 정보를 잃을 수 있다. 그렇기 때문에 subsequent main branch가 많은 target 예측하기 위한 완전한 정보를 학습하기 위해 각각의 feature pyramid가 정보를 받아야할 필요가 있다고 생각한다.
Multi-level auxiliary information의 개념은 feature pytamid 계층 사이사이에 integration network를 삽입한 뒤 다른 prediction head를 결합하는데 쓰인다. 이러한 경우 main branch의 feature pyramid 계층의 특성이 몇몇 특정한 정보에 지배받지 않게 된다. 결과적으로 이 방식은 deep supervision에서 정보 손실을 완화시킬 수 있다.
Experiment
YOLOv9 = YOLOv7 & Dynamic YOLOv7 + a
네트워크 구조에서 ELAN을 CSPNet block을 사용한 GELAN으로 변경하고 downsampling module을 단순화하고 anchor-free prediction head를 최적화 했다.
Comparison with SOTA
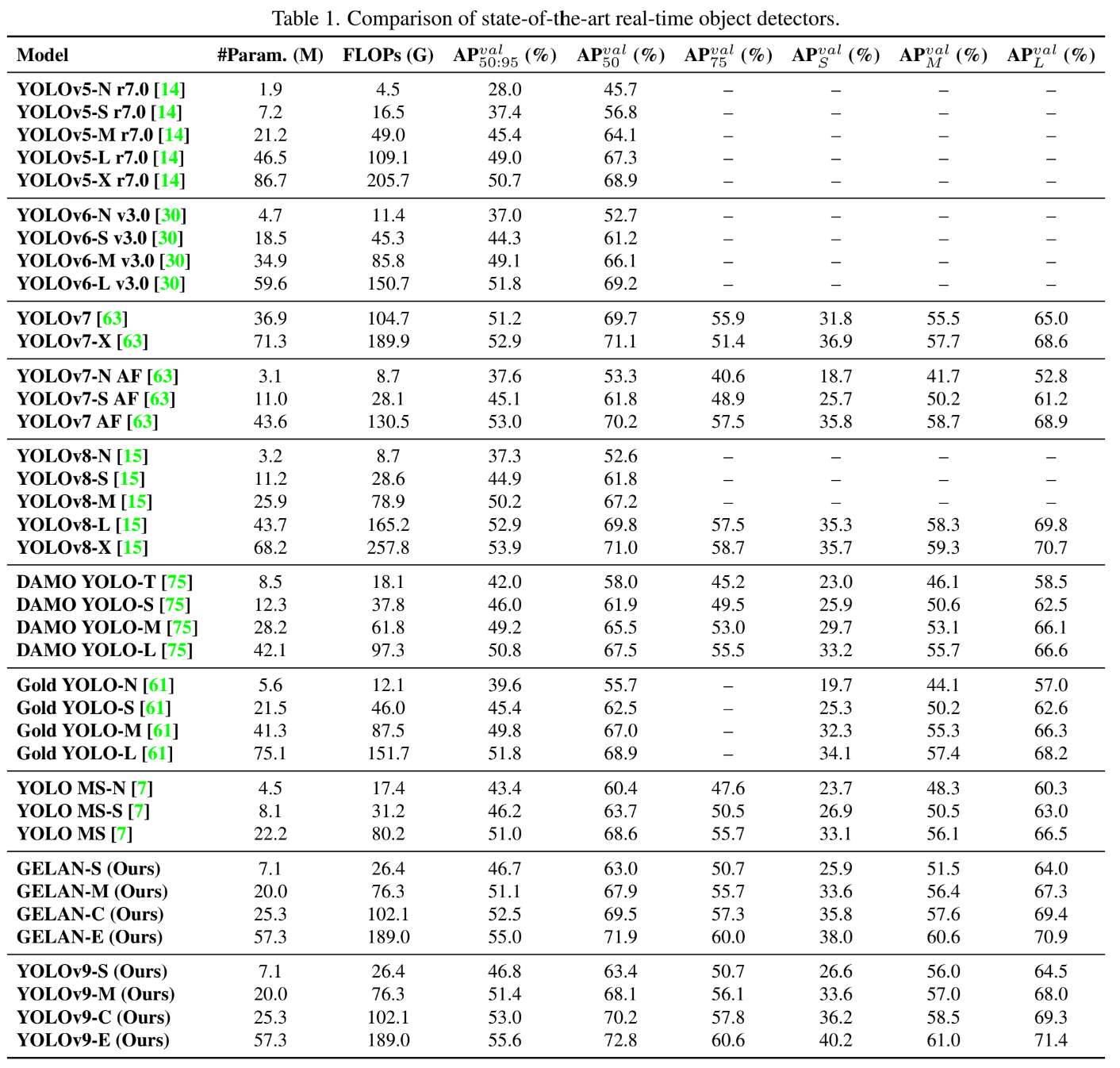
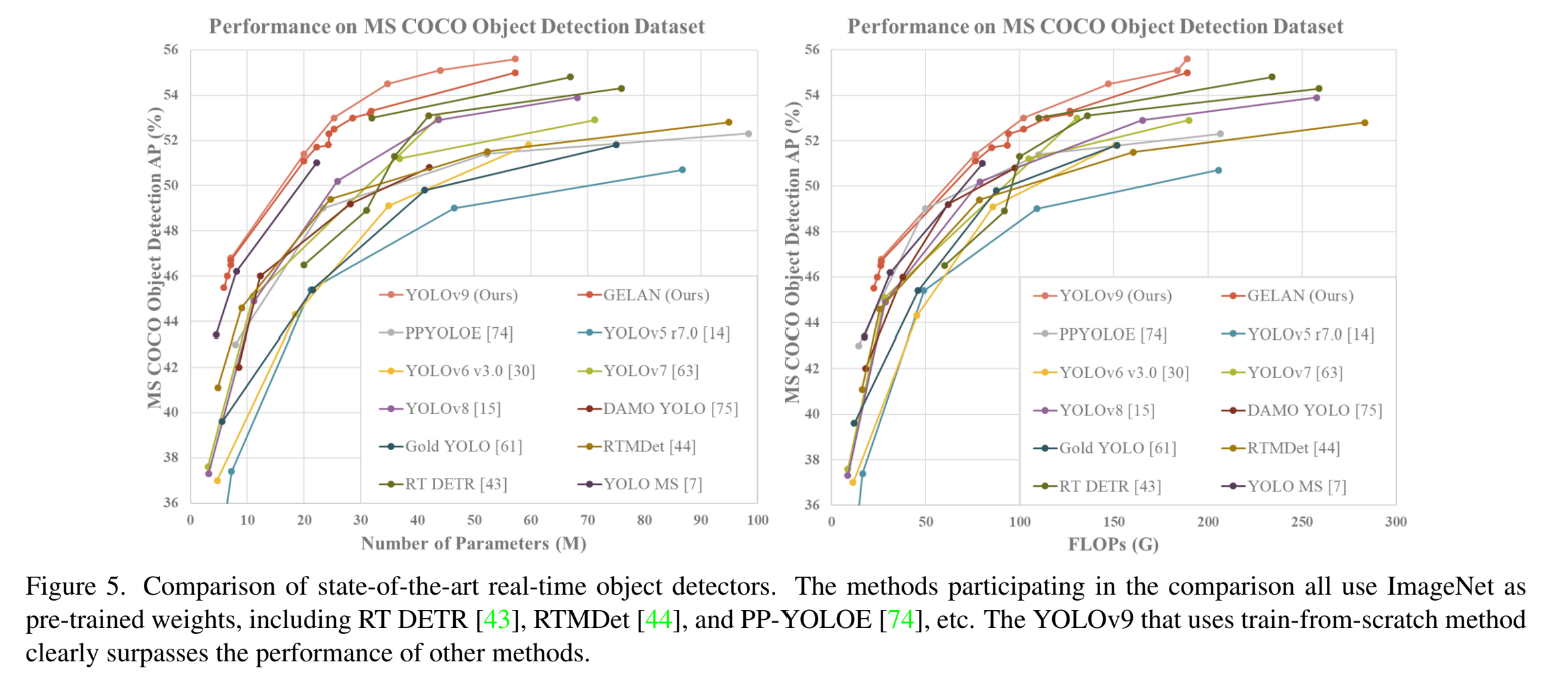
위의 표를 보면 아래쪽이 GELAN과 YOLOv9에 관한 내용인데 계산량이 줄고 성능이 좋아졌다는 이야기를 하고 있다.
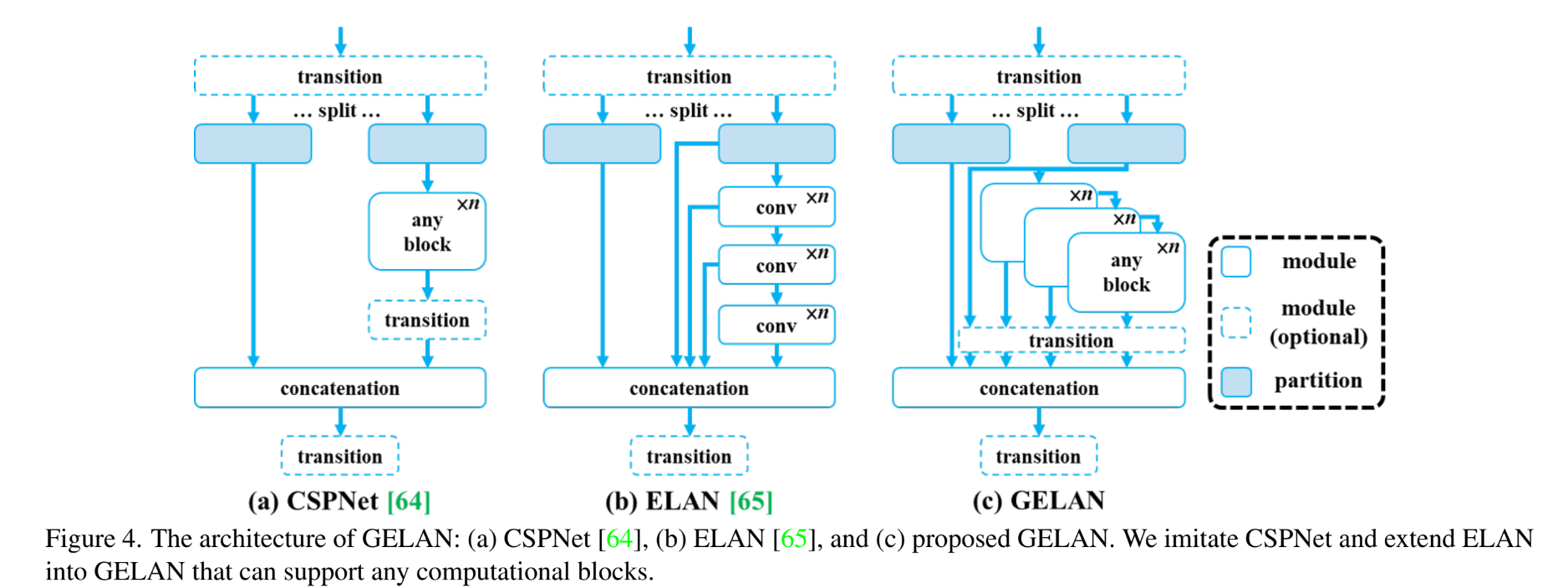
GELAN
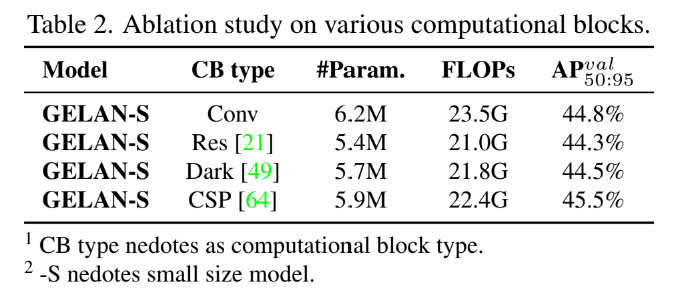
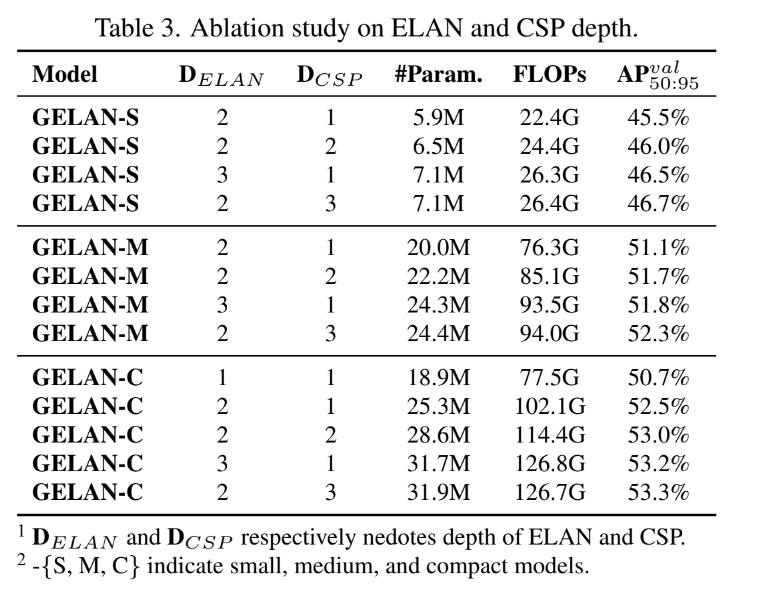
그 다음으로는 GELAN에 대한 내용인데 이를 통해 GELAN이 depth에 민감하지 않고 사용자가 임의로 구성요소를 결합할 수 있다는 것을 보여준다.
PGI

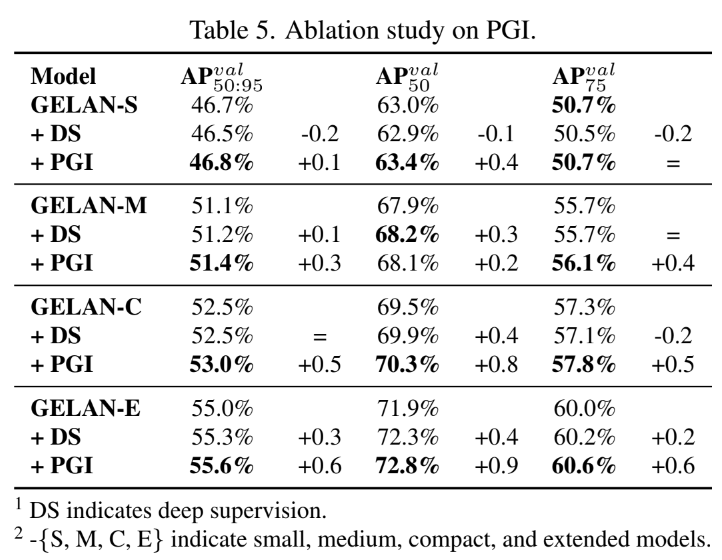

한 문장으로 요약하면 PGI를 사용하였더니 다 얕은 모델에 대해서도 정확도가 높았고 information bottleneck이나 broken information 같은 문제들을 효과적으로 다뤄서 다양한 크기의 모델에 대한 정확도를 향상시켰다는 것이다.
The proposed PGI can effectively handle problems such as information bottleneck and information broken, and can comprehensively improve the accuracy of models of different sizes.
Visualization

위의 표에 있는 test 과정들을 시각화하면 위의 그림과 같다고한다.
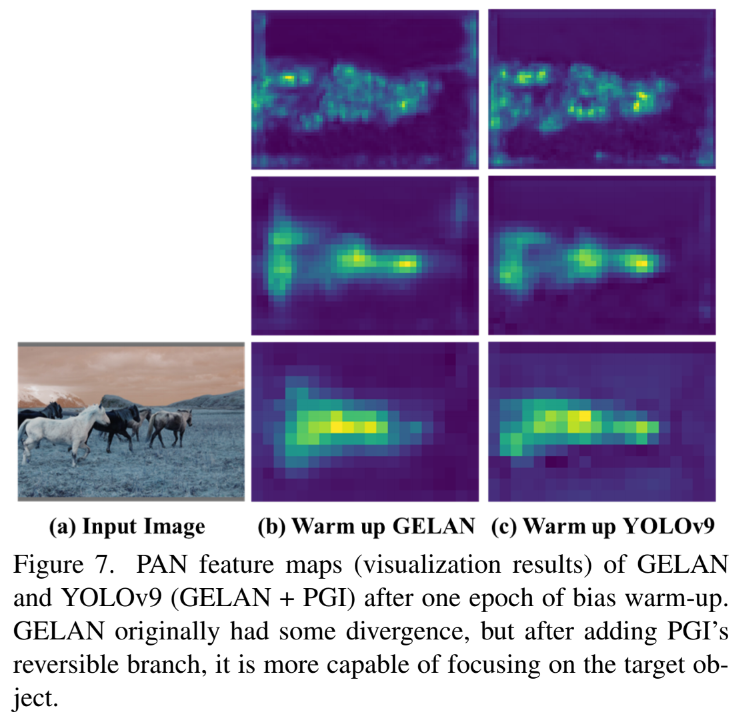
Figure7의 경우 PGI가 training 과정 동안 더 reliable한 gradient를 제공하는지 확인하기 위한 과정이다. 위의 그림을 보면 GELAN과 GELAN + PGI의 YOLOv9을 비교하는데 PGI를 포함하였더니 훨씬 정확하고 간결한 객체 인식 영역이 구현되는 것을 확인할 수 있다.
Conclusion
이 논문을 통해 연구원들은 PGI를 통해 information bottleneck 문제와 deep supervision mechanism이 lightweight model에는 적합하지 않다는 문제점을 해결하고자 했다. 연구원들은 매우 효율적이고 lightweight한 neural network인 GELAN을 설계했고 이는 object detection에서 강하고 안정적인 성능을 보인다. GELAN과 PGI를 결합함으로써 parameter의 개수를 49% 줄일 수 있었고 연산의 양을 YOLOv8에 비해 43% 줄일 수 있었지만, MS COCO dataset에 대해 여전히 0.8%의 AP improvement가 있다.
