1. 비교 작업에 사용되는 테이블
- 테이블 : points(MySQL)
- rows : 13214469 rows
- columns : 6 columns
- pointId : uuid
- userId : int unsigned
- amount : int
- pointDate : varchar(8) YYYYMMDD
- createdAt : datetime
- type : varchar(40)
2. 수행할 작업
- 최근 1년간 사용 유저가 가장 많았던 날의 유저 수(일간)
- 최근 1년간 포인트 적립이 가장 많았던 날의 포인트 적립 수(일간)
- 최근 1년간 사용 유저가 가장 많았던 달의 유저 수(월간)
- 최근 1년간 포인트 적립이 가장 많았던 달의 유저 수(월간)
- 누적 사용시간
3. 쿼리 실행
3-1. MySQL
-- 최근 1년의 데이터만 추출
SET @one_year_ago = DATE_SUB(NOW(), INTERVAL 1 YEAR);
-- 일일 사용유저 많은 순
SELECT pointDate, COUNT(DISTINCT userId) AS userCount
FROM points
WHERE pointDate >= @one_year_ago
GROUP BY pointDate
ORDER BY userCount DESC;
-- 일별 포인트 적립 많은 순
SELECT pointDate, COUNT(*) AS pointCount
FROM points
WHERE pointDate >= @one_year_ago AND amount > 0
GROUP BY pointDate
ORDER BY pointCount DESC;
-- 월별 사용유저 많은 순
SELECT DATE_FORMAT(pointDate, '%Y-%m') AS pointMonth, COUNT(DISTINCT userId) AS userCount
FROM points
WHERE pointDate >= @one_year_ago
GROUP BY pointMonth
ORDER BY userCount DESC;
-- 월별 포인트 적립 많은 순
SELECT DATE_FORMAT(pointDate, '%Y-%m') AS pointMonth, COUNT(*) AS pointCount
FROM points
WHERE pointDate >= @one_year_ago AND amount > 0
GROUP BY pointMonth
ORDER BY pointCount DESC;
-- 총 사용시간 계산
SELECT SUM(amount > 0) * 30 AS totalUsageTime
FROM points;-
실행 결과
-
최근 1년간 사용 유저가 가장 많았던 날의 유저 수(일간)
- 연산 불가(8분 넘어가서 강제 종료)
-
최근 1년간 포인트 적립이 가장 많았던 날의 포인트 적립 수(일간)
- 연산 불가(8분 넘어가서 강제 종료)
-
최근 1년간 사용 유저가 가장 많았던 달의 유저 수(월간)
-
최근 1년간 포인트 적립이 가장 많았던 달의 유저 수(월간)
-
누적 사용시간
-




평가
- 짧고 빠른 트랜잭션을 위해 설계되고, 쓰기에 최적화 된 OLTP의 한계점으로 인해 일간 쿼리는 연산이 불가능했다.
- AWS RDS 인스턴스가 프리 티어 인스턴스인 점도 연산이 불가능한 점에 영향이 있는 것으로 판단된다.
3-2. DuckDB
DuckDB에서는 MySQL과 쿼리문이 살짝 다르다.
-- 일일 사용유저 많은 순, 최근 1년 데이터
SELECT pointDate, COUNT(DISTINCT userId) AS userCount
FROM points
WHERE createdAt >= CURRENT_DATE - INTERVAL '1' YEAR
GROUP BY pointDate
ORDER BY userCount DESC;
-- 일별 포인트 적립 많은 순, 최근 1년 데이터
SELECT pointDate, COUNT(*) AS pointCount
FROM points
WHERE createdAt >= CURRENT_DATE - INTERVAL '1' YEAR AND amount > 0
GROUP BY pointDate
ORDER BY pointCount DESC;
-- 월별 사용유저 많은 순, 최근 1년 데이터
SELECT strftime('%Y-%m', CAST(SUBSTR(pointDate, 1, 4) || '-' || SUBSTR(pointDate, 5, 2) || '-' || SUBSTR(pointDate, 7, 2) AS DATE)) AS pointMonth,
COUNT(DISTINCT userId) AS userCount
FROM points
WHERE createdAt >= CURRENT_DATE - INTERVAL '1' YEAR
GROUP BY pointMonth
ORDER BY userCount DESC;
-- 월별 포인트 적립 많은 순, 최근 1년 데이터
SELECT strftime('%Y-%m', CAST(SUBSTR(pointDate, 1, 4) || '-' || SUBSTR(pointDate, 5, 2) || '-' || SUBSTR(pointDate, 7, 2) AS DATE)) AS pointMonth, COUNT(*) AS pointCount
FROM points
WHERE createdAt >= CURRENT_DATE - INTERVAL '1' YEAR AND amount > 0
GROUP BY pointMonth
ORDER BY pointCount DESC;
-- 총 사용시간 계산
SELECT SUM(CASE WHEN amount > 0 THEN 1 ELSE 0 END) * 30 AS totalUsageTime
FROM points;- 실행 결과
- 최근 1년간 사용 유저가 가장 많았던 날의 유저 수(일간)
- 최근 1년간 포인트 적립이 가장 많았던 날의 포인트 적립 수(일간)
- 최근 1년간 사용 유저가 가장 많았던 달의 유저 수(월간)
- 최근 1년간 포인트 적립이 가장 많았던 달의 유저 수(월간)
- 누적 사용시간
- 최근 1년간 사용 유저가 가장 많았던 날의 유저 수(일간)





평가
- 분석을 위해 설계된 OLAP답게 쿼리문 실행은 가능했지만, 실시간 데이터를 처리하는 부분에 있어 속도에서 만족스럽지는 않았다.
3-3. Pandas
pandas는 내 이전 글
https://velog.io/@i-am-not-kangjik/%EB%A1%9C%EC%BB%AC-%EC%8A%A4%EC%BC%80%EC%A4%84%EB%9F%AC%EB%A5%BC-%ED%99%9C%EC%9A%A9%ED%95%B4-%EC%B5%9C%EC%8B%A0-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%9C%A0%EC%A7%80%ED%95%98%EA%B8%B0-MacOS-crontab
을 통해 매일 새벽 3시에 전날의 데이터를 .parquet파일로 저장한 상태이다.
5개 쿼리를 한번에 실행한 결과는 다음과 같다.
# 최근 1년의 날짜 구하기
one_year_ago = datetime.now() - timedelta(days=365)
# Convert pandas datetime 형식으로 변환
points_df['pointDate'] = pd.to_datetime(points_df['pointDate'])
# 최근 1년의 데이터만 추출
points_df_last_year = points_df[points_df['pointDate'] >= one_year_ago]
# 일일 사용유저 많은 순
# pointDate별로 userId의 unique한 수를 계산
user_count_per_date = points_df_last_year.groupby('pointDate')['userId'].nunique().reset_index(name='userCount')
# 일별 사용자 수 많은 순으로 정렬
user_count_per_date_sorted = user_count_per_date.sort_values(by='userCount', ascending=False)
# 일별 포인트 적립 많은 순
# amount > 0 인 데이터만 추출
points_with_positive_amount = points_df_last_year[points_df_last_year['amount'] > 0]
# pointDate별로 데이터 수를 계산
point_count_per_date = points_with_positive_amount.groupby('pointDate').size().reset_index(name='pointCount')
# 일별 포인트 적립 많은 순으로 정렬
point_count_per_date_sorted = point_count_per_date.sort_values(by='pointCount', ascending=False)
# points_df_last_year를 복사
points_df_last_year = points_df_last_year.copy()
# pointDate를 기준으로 월별로 변환
points_df_last_year['pointMonth'] = points_df_last_year['pointDate'].dt.to_period('M')
# 월별 사용유저 많은 순
# 월별로 userId의 unique한 수를 계산
user_count_per_month = points_df_last_year.groupby('pointMonth')['userId'].nunique().reset_index(name='userCount')
# 월별 사용자 수 많은 순으로 정렬
user_count_per_month_sorted = user_count_per_month.sort_values(by='userCount', ascending=False)
# 월별 포인트 적립 많은 순
# 월별로 amount > 0 인 데이터만 추출
points_with_positive_amount = points_df_last_year[points_df_last_year['amount'] > 0]
# 월별로 포인트 적립 데이터 수를 계산
point_count_per_month = points_with_positive_amount.groupby('pointMonth').size().reset_index(name='pointCount')
# 월별 포인트 적립 많은 순으로 정렬
point_count_per_month_sorted = point_count_per_month.sort_values(by='pointCount', ascending=False)
# 최근 1년간 사용자 수가 가장 많았던 날짜와 사용자 수
top_user_count_row = user_count_per_date_sorted.iloc[0]
# 최근 1년간 사용자 수가 가장 많았던 달과 포인트 적립 수(월별)
top_user_count_row_per_month = user_count_per_month_sorted.iloc[0]
# 최근 1년간 포인트 적립이 가장 많았던 날짜와 포인트 적립 수
top_point_count_row = point_count_per_date_sorted.iloc[0]
# 최근 1년간 포인트 적립이 가장 많았던 달과 포인트 적립 수(월별)
top_point_count_row_per_month = point_count_per_month_sorted.iloc[0]
# 총 사용시간 계산
total_usage_time = len(points_df[points_df['amount'] > 0]) * 30
# 시간, 분, 초로 변환
hours, remainder = divmod(total_usage_time, 3600)
minutes, seconds = divmod(remainder, 60)
# 결과 출력
print("--------------일간--------------")
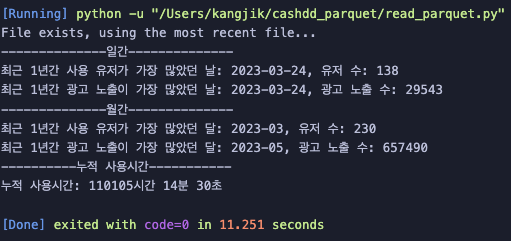
print(f"최근 1년간 사용 유저가 가장 많았던 날: {top_user_count_row['pointDate'].strftime('%Y-%m-%d')}, 유저 수: {top_user_count_row['userCount']}")
print(f"최근 1년간 광고 노출이 가장 많았던 날: {top_point_count_row['pointDate'].strftime('%Y-%m-%d')}, 광고 노출 수: {top_point_count_row['pointCount']}")
print("--------------월간--------------")
print(f"최근 1년간 사용 유저가 가장 많았던 달: {top_user_count_row_per_month['pointMonth'].strftime('%Y-%m')}, 유저 수: {top_user_count_row_per_month['userCount']}")
print(f"최근 1년간 광고 노출이 가장 많았던 달: {top_point_count_row_per_month['pointMonth'].strftime('%Y-%m')}, 광고 노출 수: {top_point_count_row_per_month['pointCount']}")
print("----------누적 사용시간-----------")
print(f"누적 사용시간: {hours}시간 {minutes}분 {seconds}초")실행 결과는?

무려 11.251초가 나왔다.
ipynb로 확인해 파일을 읽어오는 시간이 3초정도 나오는데,
단순 연산에 필요한 시간은 8.251초가 걸렸다.
평가
- 미리 데이터를 가지고 있어야 하고, 실시간 데이터 처리가 아닌 단점이 있지만,
RDS에 접속해 해당 데이터를 받아오는 데 2분 30초 정도 시간이 소요되니 모든걸 종합해도 속도가 제일 빠르다. - 또한 이전 글에서 처럼 로컬에서 스케줄링을 하거나, 인프라 환경에서 스케줄링을 한다면 매일 데이터를 저장하는 것은 어렵지 않아 사실상 위 두개보다 압도적으로 성능이 좋다.
결과
- 이 작업을 통해서 마케팅 팀이 자료를 요청할 때,
초기 MySQL에서 일괄 조회가 불가능해 분할해 조회하고 병합해 결과를 만드느라 오래 걸렸던 작업을
DuckDB 도입으로 10분 이내에 완료할 수 있게 만들었다. - 여기서 만족하지 않고 Crontab으로 스케줄링을 하고 Pandas를 통해 결과를 얻는 방식으로 변경해
11.251초가 소모되도록 바꿨다. - 불가능 했던 작업을 가능한 작업으로 바꾸고, 가능하기만 했던 작업의 소요시간을 97.7% 단축시키는 성과를 만들 수 있었다.
