모든 내용은 앤드루 응 교수님의 강의를 듣고 필자가 정리를 위해서 작성하는 것입니다. 오류가 있을 경우 댓글로 알려주세요.
- Supervised Learning
- Unsupervised Learning
- Recommenders Systems
- Reinforcement Learning
머신러닝은 크게 두 가지 유형으로 나뉘어집니다. Supervised Learning 과 Unsupervised Learning으로 나뉘어집니다.
앤드루 응 교수님의 기계학습 특화 과정의 Course 1, 2에서 Supervised Learning과 Unsupervised Learning에 대하여 배우게 되고, Course 3에서 Recommnders Systems와 Reinforcement Learning에 대하여 배우게 됩니다.
1. Supervised Learning
supervised learning은 input X와 output y과 mapping이 되어있는 학습을 의미합니다.
| Input(X) | Output(Y) | Application |
|---|---|---|
| Spam(0/1) | spam filter | |
| audio | text transcripts | speech recognition |
| English | Spanish | machine translation |
| ad, user info | Click(0/1) | online advertising |
| image, radar info | position of other cars | self-driving car |
| image of phone | defect(0/1) | visual inspection |
위의 표와 같이 input과 output이 mapping된 data가 주어진다는 것이 supervised learning의 특징입니다. 이러한 Supervised learning에는 대표적으로 regression과 classification이 있습니다.
A. Regression
Regression은 가능한 수 많은 output으로 부터 숫자를 예측합니다.
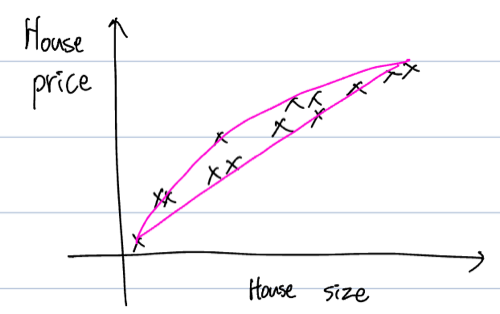
위의 그래프는 집의 면적과 집의 가격을 x모양으로 plot해놓은 그래프입니다. 이 데이터에서는 집의 면적이 input(X), 가격이 output(Y)가 됩니다. 분홍색 곡선 혹은 직선과 같은 선들이 집의 면적에 따른 집의 가격을 예측할 수 있게 해줍니다.
Supervised Learning part2
B. Classification
Classification은 Regression과 다르게 가능한 output의 종류가 적을 때 사용합니다.
본 강의에서는 예시로 Breast Cancer Detection을 보여줍니다.
(Regression에서는 가능한 output이 위의 예시인 집의 가격처럼 여러 숫자가 가능하지만, Classification에서는 아래의 예시와 같이 악성 종양 혹은 양성 종양처럼 output의 종류는 두가지로 그 종류가 적습니다.)
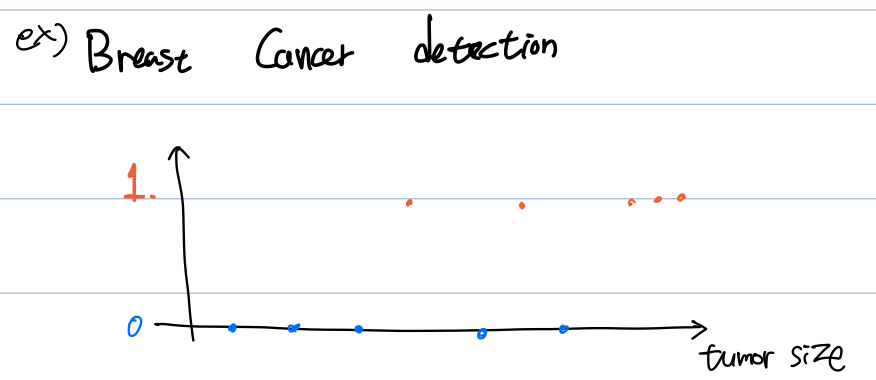
이러한 경우 위의 그림 같은 x-y축 그래프보다는,
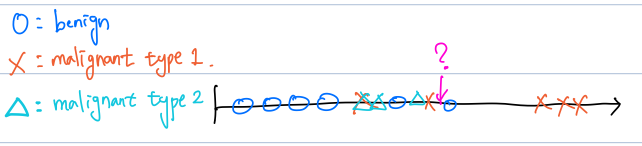
이러한 수직선에 표기하는 것이 더 알아보기 쉽습니다. 이렇게 표기할 경우 여러가지 class 즉 category로 분류된 output을 알 수 있습니다.
이렇듯 Classification 알고리즘은 category를 예측할 수 있게 도와줍니다.
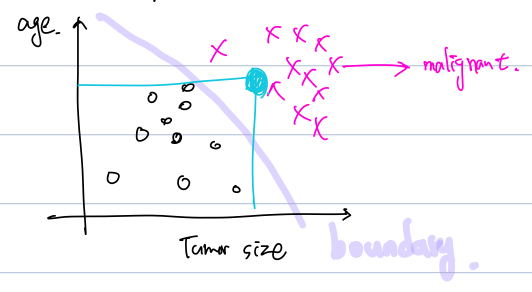
위으 그림 처럼 x-y축에 표시하여 boundary를 지정해주며 category를 구분할 수도 있습니다.
C. Recap - Regression VS Classification
| Regression | Classification |
|---|---|
| 값을 예측 | category를 예측 |
| 가능한 output이 무한함 | 가능한 output이 적음 |
2. Unsupervised Learning
Unsupervised Learning이란 특정 input에 대하여 정답 output이 주어지는 Supervised Learning과 달리 Unsupervised Learning은 input에 대한 output이 미리 주어지지 않고 인공지능이 input에 대한 상관관계를 알아내는 알고리즘입니다.
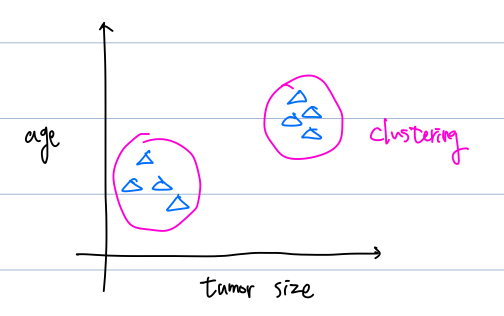
위의 그림과 같이 전체 input에 대하여 clustering을 통해 상관관계를 파악합니다.
Unsupervised Learning의 예로는
- Clustering
- Anomaly detection
- Dimensionality reduction
이 있습니다.
A. Clustering
Clustering은 전체 input들 중에서 유사한 data들을 하나의 group으로 지어주는 알고리즘입니다.
B. Anomaly Detection
이상 data를 찾는 알고리즘입니다.
C. Dimensionality Reduction
큰 data를 아주 작게 압축하는 알고리즘입니다.
