0. 앙상블 기법 (배깅, 부스팅, 보팅, 스태킹)
앙상블 (Ensemble) : 다양한 학습 알고리즘을 결합하여 학습 시키는 것,
예측 성능을 높이고 각각의 알고리즘을 단일로 사용할 시 발생할 수 있는 단점 보완 가능.
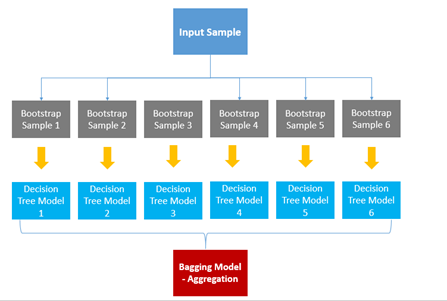
1. 배깅 (Bagging- Bootstrap aggreagting:)
- 먼저, 부트스트랩(bootstrap)이란? 통계학 용어 중 하나로, random sampling 적용 방법.
(복원 랜덤 샘플링¸중복으로 sampling 될 수도 있음)
즉, 배깅(Bagging)은 부트스트랩(bootstrap)을 집계(Aggregating)하여 학습 데이터가 충분하지 않더라도 충분한 학습효과를 주어 높은 bias의 underfitting 문제나, 높은 variance로 인한 overfitting 문제를 해결.
Categorical Data는 투표 방식(Votinig)으로 결과를 집계하며, Continuous Data는 평균으로 집계
( 6개의 결정 트리 모델이 있다고 가정. 4개 -> A로 예측, 2개 -> B로 예측.
투표에 의해 4개의 모델이 선택한 A를 최종 결과로 예측)
1-2. 랜덤 포레스트(Random Forest)
: 다수의 결정 트리를 구축하여 각 트리의 예측을 평균내거나 다수결로 결정하는 방식
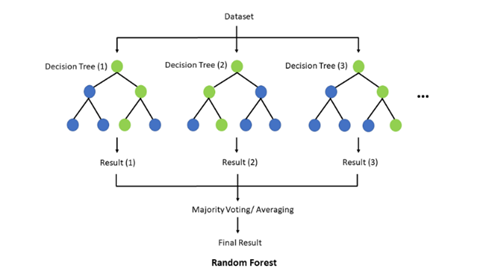
각 트리는 랜덤으로 추출된 특징으로 훈련된다. 이로 인해 각 트리는 낮은 상관관계를 가지게 된다. (feature bagging)
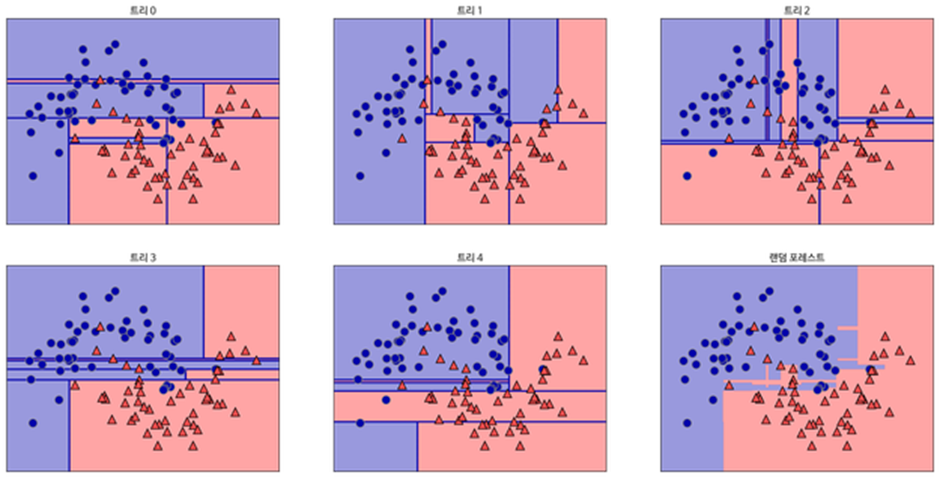
오른쪽 아래가 랜덤 포레스트의 Decision Boundary이고, 나머지는 결정 트리 각각의 Decision Boundary이다.
결정 트리의 경계는 다소 모호하고 오버피팅되어 있음
1-2-1. 랜덤 포레스트의 특징
5개의 결정 트리 경계를 평균 내어 만든 랜덤 포레스트의 경계는 보다 깔끔함
Classification(분류) 및 Regression(회귀) 문제에 모두 사용 가능
- 회귀: 개별 결정트리의 결과값의 평균으로 예측됨.
- 분류: 최빈 범주 변수로 예측됨. Missing value(결측치)를 다루기 쉬움
대용량 데이터 처리에 효과적. 모델의 노이즈를 심화시키는 Overfitting(오버피팅) 문제를 회피하여, 모델 정확도를 향상시킴
Classification 모델에서 상대적으로 중요한 변수를 선정 및 Ranking 가능
대규모 데이터에 대해 정확한 예측을 제공하지만 그만큼 데이터 처리 속도가 느리며, 그만큼 많은 리소스를 필요로 한다
특정 feature만을 선별한 개별 트리들을 구하고, 여러 결정 트리들이 내린 예측 값들 중 가장 많이 나온 값을 최종 예측값으로 선택 (다수결의 원칙).
즉, 하나의 거대한 (깊이가 깊은) 결정 트리를 만드는 것이 아니라 여러 개의 작은 결정 트리를 만드는 것.
문제를 풀 때도 한 명의 똑똑한 사람보다 100 명의 평범한 사람이 더 잘 푸는 원리)
- 하이퍼파라미터
n_estimators: 랜덤 포레스트 안의 결정 트리 갯수
n_estimators는 클수록 좋다. 결정 트리가 많을수록 메모리와 훈련 시간이 증가하는 대신, 더 깔끔한 Decision Boundary가 나올 수 있다.
max_features: 무작위로 선택할 Feature의 개수
max_features가 전체 Feature 개수와 같을 때,
- boostrap = False (비복원추출) : 전체 Feature를 사용해 트리를 제작.
- bootstrap=True(복원추출, default 값)
max_features 값이 크면 랜덤 포레스트의 트리들이 매우 비슷해지고, 가장 두드러진 특성에 맞게 예측을 할 것이다. max_features 값이 작으면 랜덤 포레스트의 트리들이 서로 매우 달라지며, 오버피팅이 줄어든다.
2.부스팅(Boosting)
: 가중치를 활용하여 약 분류기를 강 분류기로 만드는 방법
(Bagging과 크게 다르지 않으며 거의 동일한 매커니즘)
.
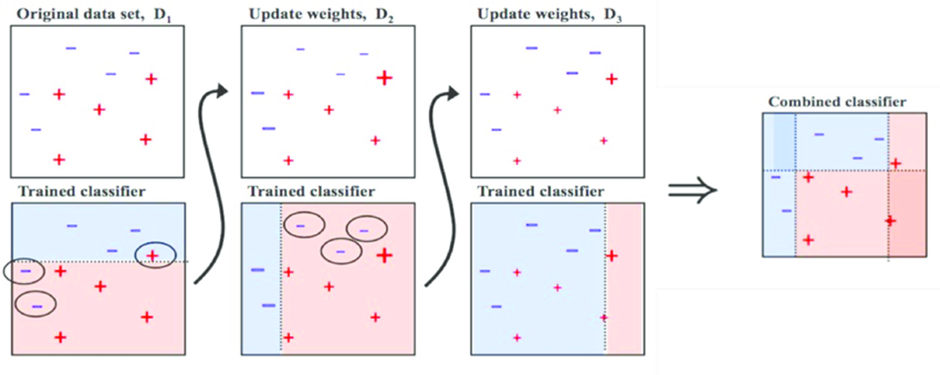
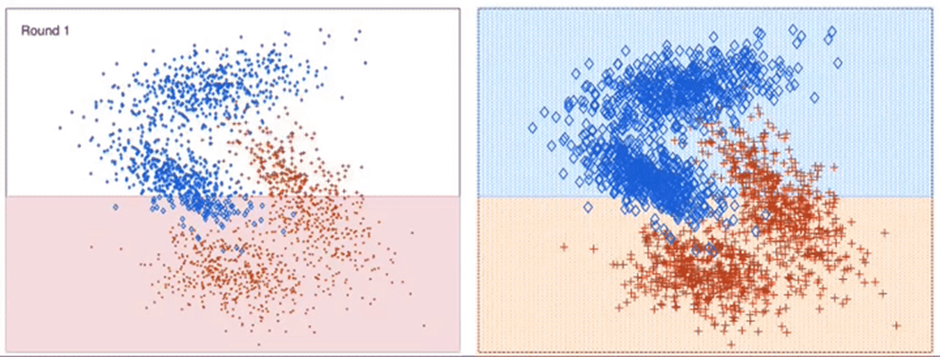
잘못 분류한 데이터에 가중치를 두어, 이를 다음 모델에 반영해서 학습할 수 있도록 함.
D1, D2, D3의 Classifier를 합친 최종 Classifier 모델에서는 +와 -를 정확하게 구분하는 것을 확인 가능
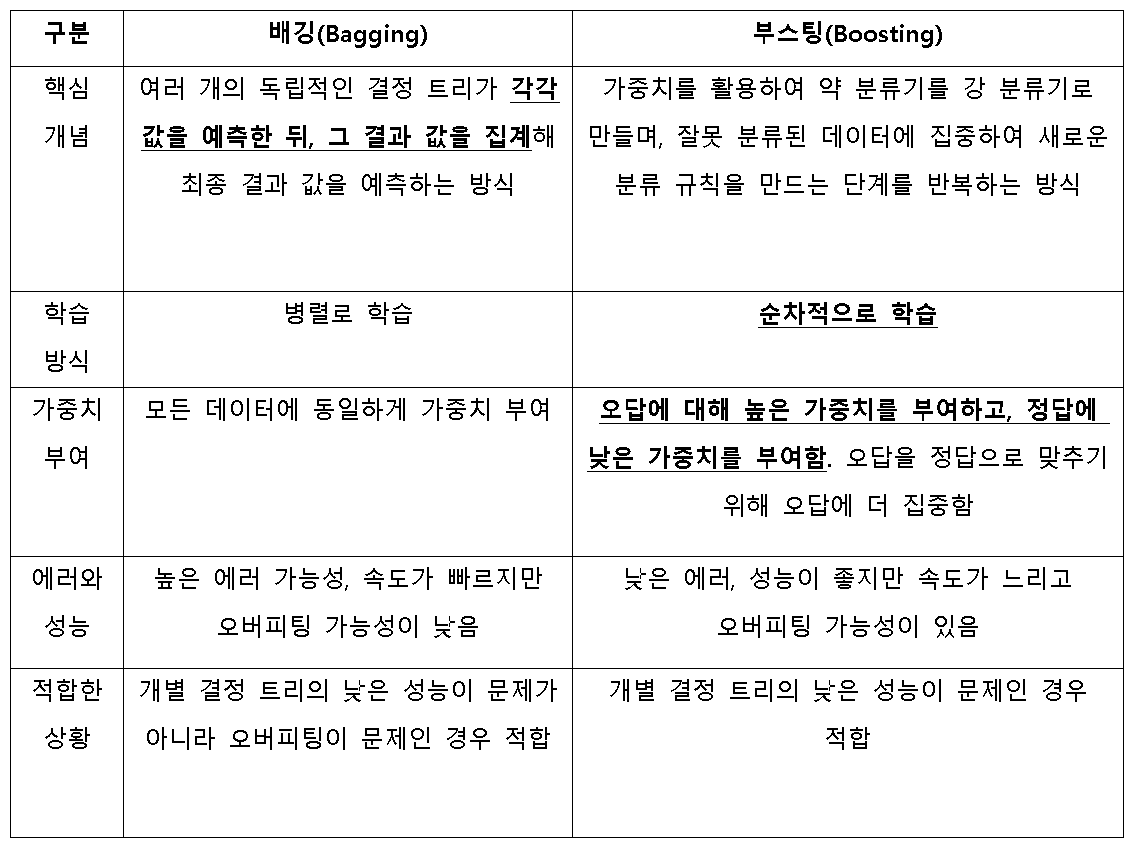
2-2. 배깅과 부스팅의 차이
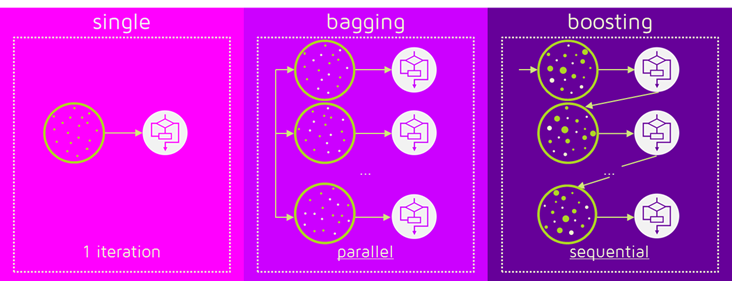
2-3. AdaBoost(Adaptive Boosting) > “오차”에 집중
: 약한 분류기(weak classifier)들이 상호보완 하도록 순차적(sequential)으로 학습하고, 이들을 조합하여 최종적으로 강한 분류기(strong classifier)의 성능을 향상시키는 것
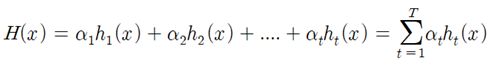
H(x) : 최종 강한 분류기, h : 약한 분류기, α : 약한 분류기의 가중치, t : 반복 횟수
먼저 학습된 분류기가 잘못 분류한 결과 정보를 다음 분류기의 학습 시 사용하여
이전 분류기의 단점을 보완하도록 한다. > 순서가 중요
즉, 이전 분류기가 오분류한 샘플의 가중치를 adaptive하게 바꾸어가며
잘못 분류되는 데이터에 더 집중하여 잘 학습하고 분류할 수 있도록 만든다.
최종 분류기(strong classifier)는 개별 약분류기(weak classifier)들에 각각 가중치를 적용, 조합하여 얻을 수 있다.
🔎참고 AdaBoost(Adaptive Boosting) 기본 원리
- 기타정리
스텀프(Stump, 그루터기)
틀리면 1보다 큰 값을 곱함 = 틀릴수록 가중치가 커짐. => 다음 분포에서는 맞출 확률이 높아짐.
지니 인덱스(Gini Index) : 결정 트리(Decision Tree)와 같은 분류 알고리즘에서 불순도(impurity) 또는 순도(purity)를 측정하는 데 사용되는 지표
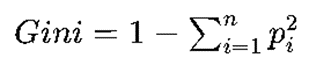
Pi :특정 분할에서 클래스 i에 속하는 데이터 포인트의 비율, n : 클래스의 총 수
(지니 인덱스의 값은 0에서 0.5 사이에서 변동(이진 분류의 경우). 값이 0에 가까우면 불순도가 낮다는 것을 의미하며, 데이터 집합이 순수한 상태(즉, 한 클래스의 데이터만 포함)라는 것을 의미)
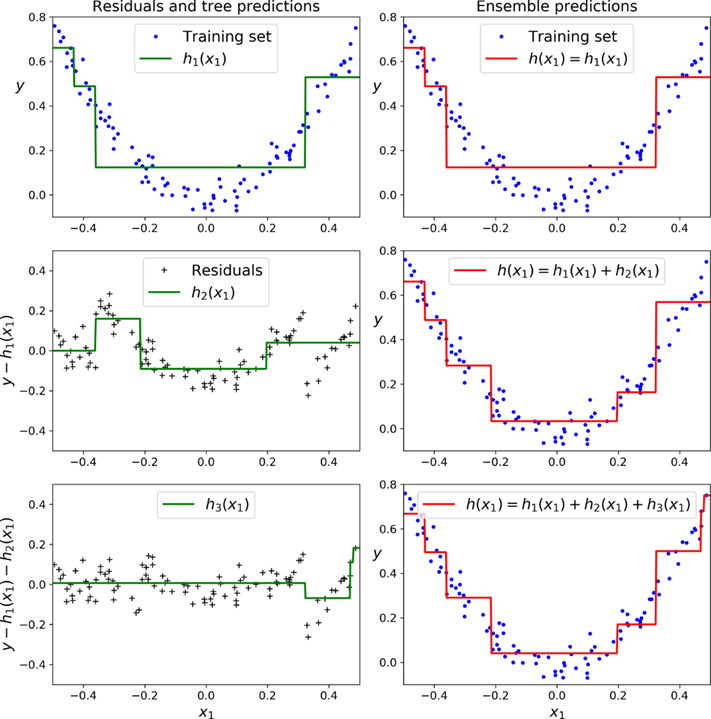
2-4. GradientBoost(GBM) > “잔차”에 집중
에이다부스트처럼 반복마다 샘플의 가중치를 수정하는 대신 이전 예측기가 만든 잔차(residual)에 새로운 예측기를 학습.
- 경사 하강법(Gradient Descent)을 이용하여 손실함수의 기울기를 최소화하는 방향으로 가중치를 업데이트한다.
🔎 경사 하강법이란?
오차함수를 조금씩 줄여가며 반복적으로 가중치를 개선해 가며 최적의 가중치를 찾아가는 방법을 말한다.
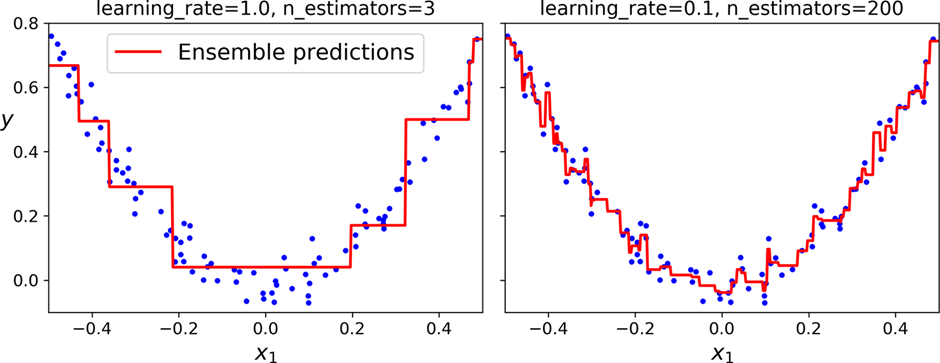
<과대적합의 예시>
2-4. XGBoost((eXtreme Gradient Boosting))
: GBMd에 기반하고 있지만, GBM의 단점인 느린 수행시간 및 과적합 규제(Regularization) 부재 등의 문제를 해결해서 각광받고 있다.
• 뛰어난 예측 성능 - 분류와 회귀영역에서 뛰어난 예측 성능 발휘
• GBM 대비 빠른 수행시간
• 과적합 규제(Regularization) - 표준 GBM 경우 과적합 규제기능이 없으나 XGBoost는 자체에 과적압 규제 기능으로 좀다 강한 내구성 지님
• Tree pruning(나무 가지치기)
• 자체 내장된 교차 검증
• 결손값 자체 처리
• Early Stopping 기능이 있음
3. 보팅 (Voting)
: 서로 다른 알고리즘을 가진 분류기를 결합하는 방법
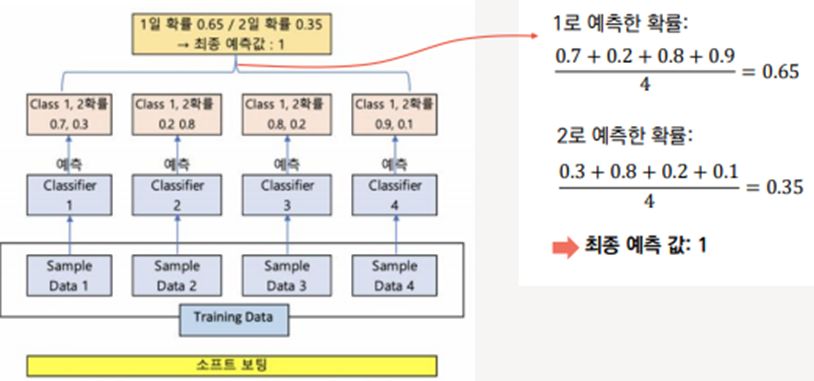
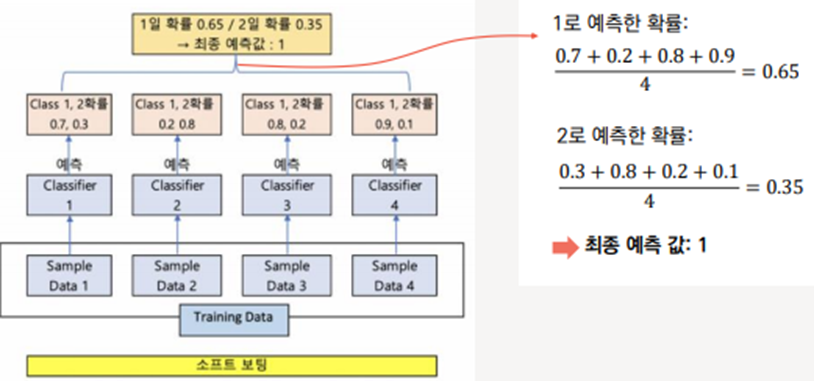
a. 소프트 보팅 (Soft Voting)
각 분류기의 확률의 평균 -> 확률이 가장 높은 레이블 값을 최종 보팅 결과값으로 선정
b. 하드 보팅(Hard Voting)
다수결 원칙, 예측한 결과값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결과값으로 선정
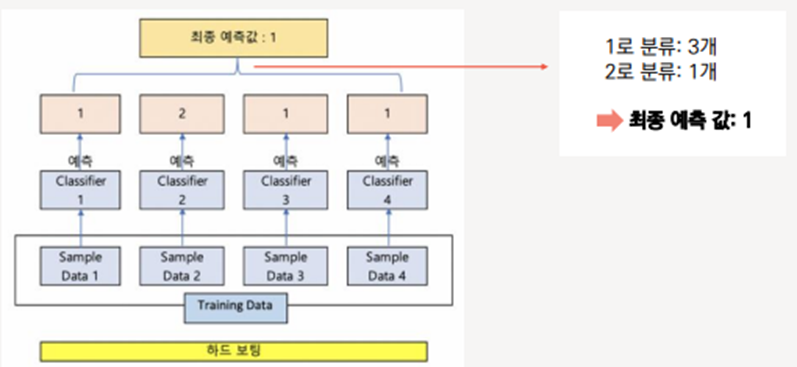
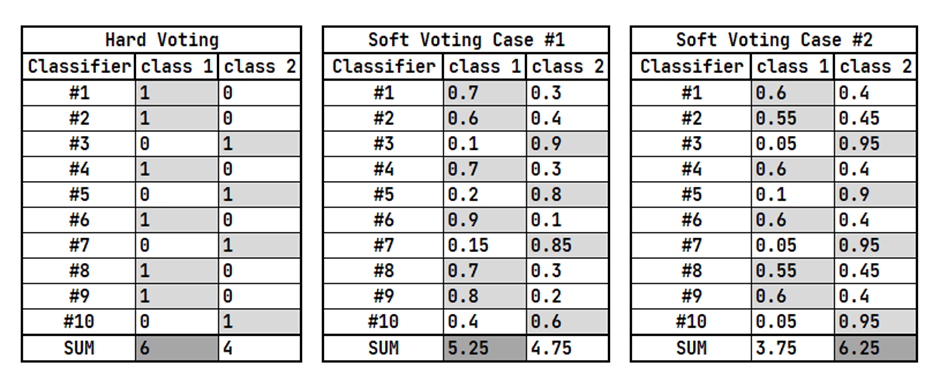
위와 같이 예측값이 확률로 산출될 경우 Hard Voting과 Soft Voting의 최종 예측 Class가 다르게 나올 수 있다. (일반적으로 하드 보팅보다는 소프트 보팅이 예측 성능이 좋아서 더 많이 사용된다.)
- Voting Classifier
4. 스태킹(Stacking)
여러 다른 모델의 예측 결과값을 새로운 데이터로 사용하여, 또 다른 모델(메타 모델)을 학습시켜 최종 예측 결과를 도출하는 방법
(개별 모델이 예측한 데이터를 다시 meta data set으로 사용해서 학습)

단일 알고리즘 모델로 각각의 예측값을 뽑아내어, 최종 학습 데이터 셋을 제작
Base Learner들이 동일한 데이터 원본 데이터를 가지고 그대로 학습을 진행했기 때문에 overfitting 문제가 발생
Base Learner의 validation set와 test set을 모아 meta train set와 meta test 셋으로 활용하여 학습한 뒤, 최종 모델을 생성
크로스 벨리데이션(Cross Validation) 기반으로 서로 상이한 모델들을 조합
최종모델은 개별 모델의 교차검증으로부터 예측된 값들로 구성되어있고, 학습데이터의 레이블은 기존 데이터의 y_train 값이다.
개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 것 > 배깅(Bagging), 부스팅(Boosting)과 차별.
(스태킹은 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다는 점에서 차이)
Base Learner들이 동일한 데이터 원본 데이터를 가지고 그대로 학습을 진행했기 때문에 overfitting 문제가 발생
(Bagging과 Boosting에서는 bootstrap(데이터를 random sampling) 과정을 통해 overfitting을 효과적으로 방지한 것과는 대조적)
📍 그렇다면 스태킹에서 랜덤 샘플링을 할 수는 없을까?
4-2. 크로스 벨리데이션(Cross Validation,CV)
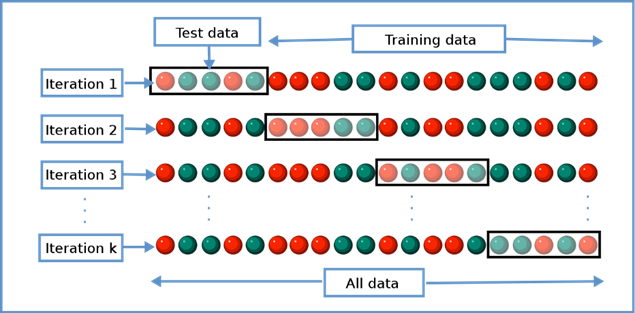
크로스 벨리데이션(CV)이란, data set을 k번 쪼개서 반복적으로 쪼갠 data를 train과 test에 이용하여(k-fold cross validation) 교차 검증을 하는 것입니다. (보통 10-fold cross validation이 안정적이라고 합니다
CV 기반의 Stacking 과정
- dataset을 k-1 번 접어주면(fold) k 개의 fold로 분할
- 나누어진 dataset을 통해 모델을 학습할때에, 각 iteration마다 test set을 위와 보이는 것과 같이 중복 없이 다르게하여 모델의 training과 testing을 반복
- 각 test fold에서 나온 검증 결과를 평균내어 모델의 성능을 평가
(4-fold CV의 경우 총 9개의 validation set를 meta train set로, 3개의 test set를 meta test set로 사용하죠!)
이렇듯 CV 기반으로 Stacking을 적용함으로써 overfitting은 피하며 meta 모델은 '특정 형태의 샘플에서 어떤 종류의 단일 모델이 어떤 결과를 가지는지' 학습할 수 있게 된다
결과적으로 더욱 완성도 있는 모델을 완성 가능하다!
• 장점 : k-fold 방법으로 dataset을 분할하여 사용한다면 데이터 양이 적을때 모델이 각기 다른 train과 test data를 학습하고 평가받게 되어 overfitting을 방지할 수 있을 뿐만 아니라 다양한 데이터에 대한 학습을 진행 가능.
• 단점 : iteration 횟수가 많아지기 때문에 학습에 걸리는 시간이 늘어난다
위 포스팅은 아래 링크 자료들을 참고해서 제작하였습니다. 온라인 속 선생님들 모두 감사드립니다🙇♂️
[참고자료]
https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-11-%EC%95%99%EC%83%81%EB%B8%94-%ED%95%99%EC%8A%B5-Ensemble-Learning-%EB%B0%B0%EA%B9%85Bagging%EA%B3%BC-%EB%B6%80%EC%8A%A4%ED%8C%85Boosting
https://data-analysis-science.tistory.com/61
https://swingswing.tistory.com/281
https://helpingstar.github.io/ml/ensemble/
https://velog.io/@dltnstlssnr1/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-5%EB%8B%A8%EA%B3%84%EC%95%99%EC%83%81%EB%B8%94-%EB%B3%B4%ED%8C%85%EB%B0%B0%EA%B9%85%EB%B6%80%EC%8A%A4%ED%8C%85%EC%8A%A4%ED%83%9C%ED%82%B9
https://cerulean85.tistory.com/494
https://hwi-doc.tistory.com/entry/%EC%8A%A4%ED%83%9C%ED%82%B9Stacking-%EC%99%84%EB%B2%BD-%EC%A0%95%EB%A6%AC
https://hwi-doc.tistory.com/entry/%EC%8A%A4%ED%83%9C%ED%82%B9Stacking-%EC%99%84%EB%B2%BD-%EC%A0%95%EB%A6%AC
https://velog.io/@sykim0/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-Random-Forest
https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-5-%EB%9E%9C%EB%8D%A4-%ED%8F%AC%EB%A0%88%EC%8A%A4%ED%8A%B8Random-Forest%EC%99%80-%EC%95%99%EC%83%81%EB%B8%94Ensemble
https://quantdare.com/what-is-the-difference-between-bagging-and-boosting/
