Self-Supervised Pre-trainig Model
- Unlabel된 Data를 통해 먼저 Model을 학습시키고(Pre-train), 이렇게 학습시킨 Model에 Classifier를 추가시켜 내가 원하는 출려값을 도출하도록 만든 Model
- Unlabel된 Data로 Pretrained Model을 만들고, 이후 Labeled Data로써 내가 원하는 Model의 형태로 변형하는 것
- Unlabel Text Data는 매우 많지만, Labeled Data는 매우 빈약함
- 따라서, Unlabeld Data를 통해 Pretrain을 시키고, Fine-tuning을 통해 내가 원하는 모델로 최종적인 Model을 형성하는 것
- Unlabel Data로만 학습시키는 것보다 훨씬 효율적
GPT-1
- Transformer의 Decoder 구조를 활용한 Model
- Text의 Long-term dependencies에 강인한 결과를 보여줌
- 기존 Model에 비해 구조화된 Memory를 쓸 수 있음
- Speical Token을 제안하여 많은 Task를 동시에 처리할 수 있는 Model을 제안
- 학습 단계
- Corpus에서 대용량 언어모델을 학습
- 분류 데이터를 활용하여 모델을 미세조정함
- GPT-1 구조 및 Task별 활용법
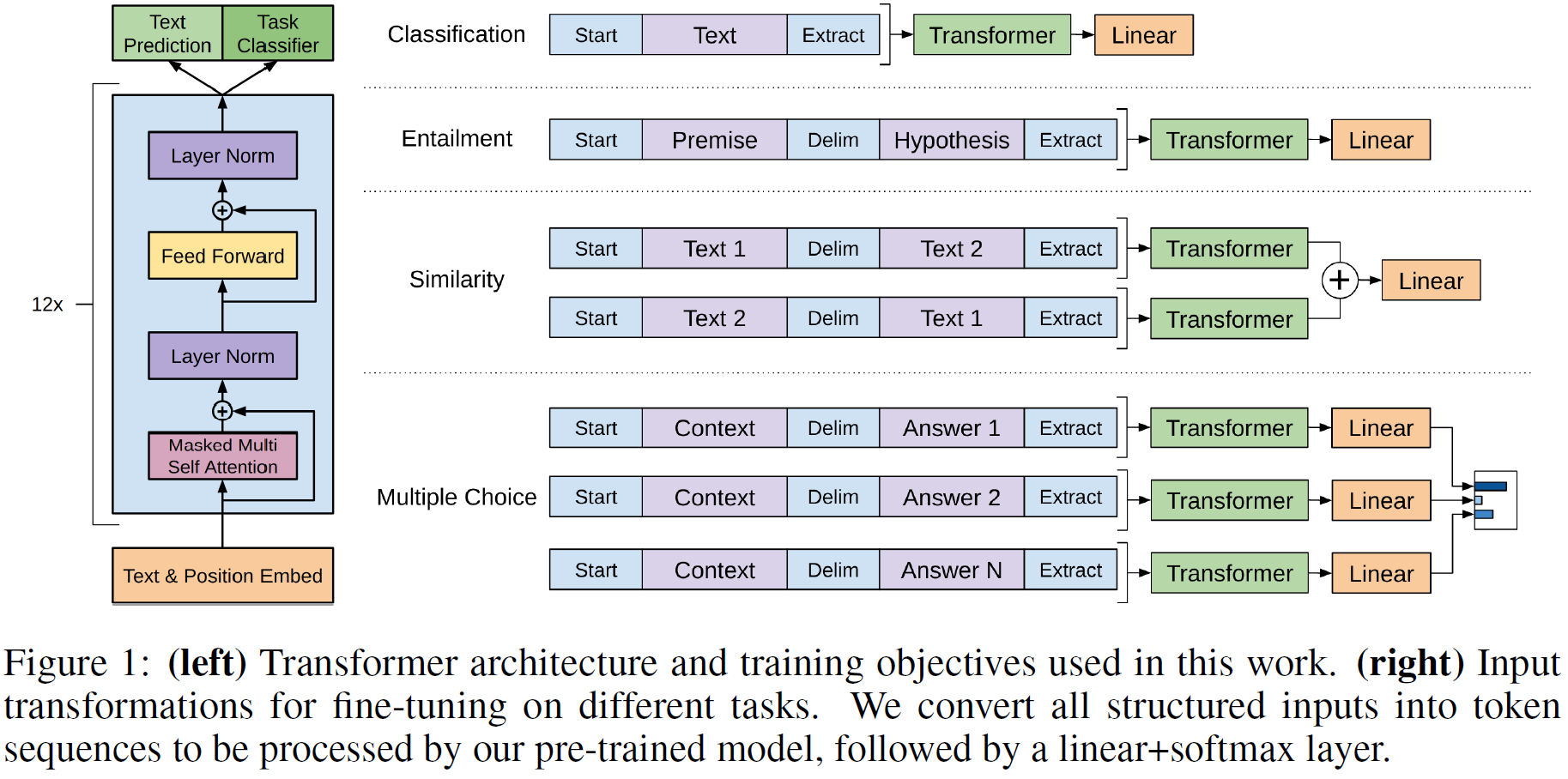
- 사진 출처
https://greeksharifa.github.io/nlp(natural%20language%20processing)%20/%20rnns/2019/08/21/OpenAI-GPT-1-Improving-Language-Understanding-by-Generative-Pre-Training/- Similarity : 2개 Text 사이에는 순서가 딱히 없으므로 다른 순서로 이어붙여 총 2개 입력을 만듦
BERT
GPT-2
- GPT-1보다 더 범용적인 LM을 만들기 위한 Model
- LM(Language Model) : 다음 단어를 예측하는 Model
- Transformer Layer를 깊게 쌓음
- 활용한 Dataset
- Reddit : 3개 이상의 추천을 받은 경우 데이터를 모두 활용. 외부 링크의 경우 해당 링크로 들어가 데이터를 얻어옴
- 위키피디아
- Preprocess :BPE(Byte Pair Encoding)
- Layer Normlization 위치 변경
- 각 Sub Block의 Input으로 옮겨짐
- 마지막 Self-Attention Block 이후에 추가
- 각 Sub Block의 Input으로 옮겨짐
- Layer 위로 갈수록 활용되는 Parameter가 더 작은 값으로 설정되도록 함
- 위로 갈수록 0에 가까움
- 위 쪽에 있는 Layer가 하는 일이 줄어듦
- Downstream tasks in a zero-shot setting
- Few-shot Leraning : 모델의 Window에 넣을 수 있는 만큼 많은 예제를 넣음
- one-shot Learning : 하나의 예제만을 허용
- zero-shot learning : 예제는 활용하지 않고, Task에 대한 설명이나 지시사항만을 모델에게 전달
- 문제에 대한 예시들을 몇 개 주고 문제를 풀라고 시키는 것이 Few-shot Learning이다. 예를 들어, 번역 문제의 경우 집에 간다->I go home, 배고파 -> I am hungry라는 예시를 주고, "케이크 먹고 싶어"라는 단어를 번역하도록 시키는 것이다.
- Zero-shot Learning을 통해 Fine-tuning의 과정이 생략됨
GPT-3
- Model Size를 매우 크게 했음
- Few-Shot Learners 활용
- Model Size가 클수록 Few shot의 성능이 좋아짐
- Model Size를 키울수록 Few shot의 성능 향상 차이가 더 커짐
ALBERT
- 기존 BERT Model의 문제점 : Model이 너무 큼
- Memory 제한
- 학습 속도가 느림
- 이런 BERT Model의 문제점을 해결하기 위해 나온 Model
- Factorized Embedding Parametrization
- 큰 단어 Embedding Matrix를 두 행렬로 분해하고, Hidden Layer 크기와 Embedding 크기를 각각 설정하도록 분리
- BERT : Hidden Layer Size H와 WordPiece Embedding Size(Input Data Size) E는 동일
- H = E일 때 발생하는 문제점
- 실용적 관점 : E = H일 경우, Embedding Marix는 이기 때문에 파라미터가 매우 많아지고, 학습 속도가 느려짐
- 모델링 관점 : E는 Context-Independent한 Representation이지만 H는 Context-Dependent한 Representation. 따라서 E와 H를 다르게 설정하는 것이 더 효과적
- 방법 : 큰 Embedding Matrix를 작은 2개의 Matrix로 나눔
- 작은 Dimension인 E로 Mapping한 후, E Dimension Vector를 다시 H Dimension으로 보냄
- 파라미터 수 :
- Cross-Layer Parameter Sharing
- Parameter가 네트워크 깊이가 증가함에 따라 계속해서 커지는 것을 방지하기 위한 기법
- Transformer Layer간 같은 Parameter를 공유하여 사용하는 것
- Shared-FFN : Feed-forward 관련 Parameter들만 공유
- Shared-attention : Attention 관련 Parameter들만 공유
- All-shared : Shared-FFN + Shared-attention
- Parameter 수를 주링기 때문에 성능 상승 효과를 가지고 옴
- Negative Sampling 활용 : 중심 단어를 학습할 때, 모든 단어의 Weight들을 Update시키지 않게 하는 것
- 현재 단어(문장)에 영향을 거의 끼치지 않거나, 판단의 근거로 삼을 수 없는 Sample들을 줄이기 위해 활용
- Sentence Order Prediction
- BERT에서 활용하던 NSP 대신 새로 적용하는 학습
- 2개 문장을 원래 있었던 순서쌍, 순서를 바꾼 쌍으로 구성해 Order를 다르게 하여 Order를 판단하는 과정
- Positive Example : 실제 연속인 두 문장
Negiatve Example : 두 문장의 순서를 앞뒤로 바꾼 것
ELECTRA
- GAN 구조와 비슷하게 만든 NLP Model
- Generator, Discriminator 모두 Transformer의 Encoder 구조
- Generator(Small MLM; BERT모델) : 단어를 복원해주는 Model
- [MASK]로 숨겨진 단어를 예측하는 역할을 수행
- Discriminator(ELECTRA) : 각 Token에 대하여 토큰이 Original인지 Replaced인지 학습함
- 치환된 입력에 대하여(즉, Generator가 [MASK] 부분을 예측한 것에 대하여) 각 토큰이 원래 입력(원본 Data)와 동일한지를 예측함
Light-weight Models
- 목적 : 큰 Size Model의 성능을 유지하면서도 계산 속도를 빠르게 하고 크기를 작게하는 것(경량화)
- 고성능의 GPU와 Cloud를 활용하지 않더라도 계산을 수행할 수 있도록 하기 위하여 고안됨
- DistilBERT
- Student Model과 Teacher Model이 존재
- Teacher의 softmax 연산을 Ground Truth로 활용하여 경량화된 Model인 Student를 학습시키는 Model
- TinyBERT
- DistilBERT는 결과물에 대해서만 비슷하도록 학습을 진행하지만, TinyBERT는 Attention Vector, Hidden State Vector 등 중간 결과물까지 비슷하게 학습시키는 Model
Fusing Knowledge Graph into LM
- 외부 Data를 활용하여 직접적으로 답이 나와 있지 않은 QA Task를 처리하기 위하여 등장한 Model
- ERNIE
- BERT는 단어를 일정 확률로 Masking하지만, ERNIE는 단어 뿐만 아닌 Entity, Phrase 전체를 하나의 Unit으로 취급하여 Masking
- KagNET

개념부터 확실히!