
Gradient Descent Methods
Stochastic gradient descent
Update with the gradient computed from a single sample.
Mini-batch gradient descent
Update with the gradient computed from a subset of data.
Batch gradient descent
Update with the gradient compued from the whole data.
Batch-size Matters
It has been observed in practice that when using a larger batch there is a degradation in quality of the model, as measured by its ability to generalize.
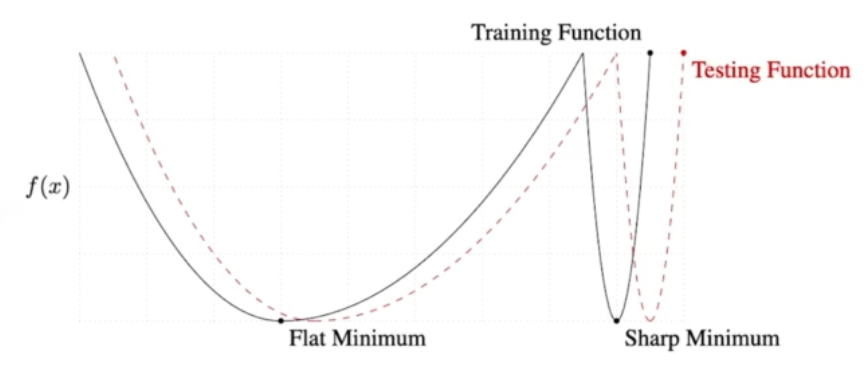
Flat Minimum (작은 batch size)의 경우 Generalization gap이 비교적 작습니다. 반면, Sharp Minimum (큰 batch size)의 경우 그 gap이 큰 것을 알 수 있습니다.
Gradient Descent Methods (Optimization strategies)
1. (Stochastic) Gradient descent
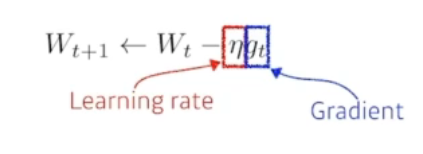
Learning rate와 Gradient 값을 통해 지속적으로 갱신하는 형태입니다. 단점은 이 Learning rate의 초기 값을 설정하는 것이 너무 모호합니다. 절대적인 값을 설정했을 때 이 값이 해당 모델에 최적화된 초기 값인지 알 수 없습니다.
2. Momentum
Momentum (관성): 특정 방향으로 흐르던 gradient 가 있었을 때, 만약 다음 gradient가 정반대의 방향이더라도, 어느 정도 기존 방향을 유지시켜 주는 것.
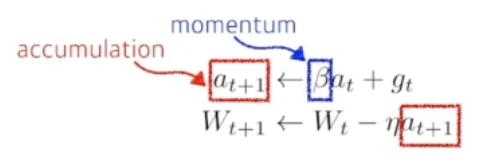
- Mini-batch를 사용하는 경우 A batch와 B batch의 gradient가 다를 수 있습니다. 이럴 때 대세를 따르자(관성을 유지시키자) 라는 아이디어에서 출발한 optimization 방법론입니다.
- : Momentum
3. Nesterov Accelarate Gradient (NAG)
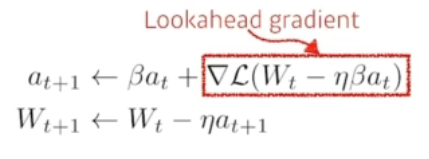
Momentum과 비슷한 논리를 활용하는 이론입니다. 우선 한 번 이동 후 계산한 gradient를 accumulate 하는 방식입니다. Momentum과 NAG 가 가장 대표적인 모멘텀 최적화 방법론들이라고 할 수 있습니다.
4. Adagrad
Adagrad adapts the learning rate, performing larger updates for infrequent and smaller updates for frequent parameters.
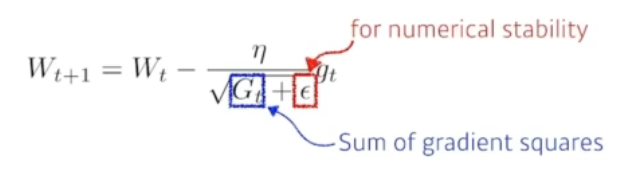
- Sum of gradient squares
모든 parameter들의 gradient 값을 제곱하여 더한 값입니다. 많이 변한 parameter들에 대한 값은 클 것이고, 반대로 적게 변한 parameter의 경우 값이 작을 것입니다. 이를 분모에 집어넣음으로서 parameter를 갱신할 때 많이 변한 parameter의 변화량을 작게, 적게 변한 parameter의 변화량은 크게 설정해줄 수 있습니다.
문제는 G는 제곱의 합이라는 것입니다. 학습이 길어지면, G 값은 무한히 커지겠죠? 따라서 가 갱신되지 않는 문제점이 발생하게 됩니다.
5. Adadelta
Adadelta extends Adagrad to reduct its monotonically decreasing the learning rate by restricting the accumulation window.
6. RMSprop
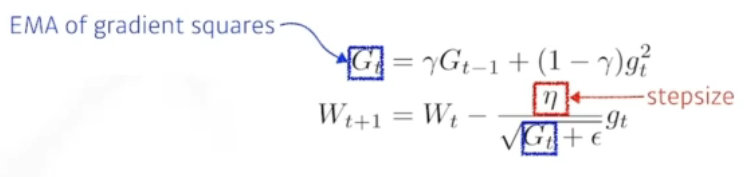
RMSprop is unpublished, adaptive learning rate method proposed by Geoff Hinton in his lecture.
7. Adam
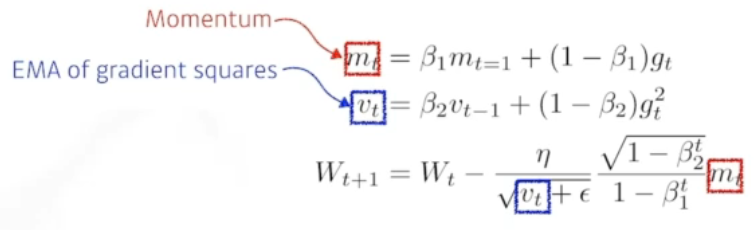
가장 많이, 무난하게 사용하는 방법론입니다. 많은 논문에서 활용하지만 정작 왜 사용하는지, 왜 정확도가 잘 나오는지 명확하게 언급해주는 논문들은 많지 않습니다. 대부분의 연구들에서 활용한다고 보면 될 것 같습니다.
Adaptive Momentum Estimation (Adam) leverages both past gradients and squared gradients.
