Prologue
모델학습에서 가장 중요한 hyperparameter 하나를 고르라면 learning rate를 고를 거다. 과제마다, 모델구조마다, optimizer마다, 학습데이터마다 요구하는 learning rate가 달라서 연구자들에게도 optimal learning rate를 찾는 게 쉬운 일은 아니다. Andrej Karpathy는 이런 농담도 했다.
3e-4 is the best learning rate for Adam, hands down.
— Andrej Karpathy (@karpathy) November 24, 2016
오.. 진짜?
(i just wanted to make sure that people understand that this is a joke...)
— Andrej Karpathy (@karpathy) November 24, 2016
What did the authors try to accomplish?

신경망은 loss를 최대한으로 줄여야 하는데 너무 높거나 너무 낮으면 학습이 느리거나 안된다. 그래프에서 잘 보여주듯이 좋은 learning rate를 찾을 때가지 실험을 반복해야 한다. learning rate를 찾았으면 일정 규칙으로 decay하거나 epoch가 올라갈수록 자체적으로 learning rate를 낮추는 optimizer를 쓴다. learning rate를 낮추다보면 optimizer가 거의 움직이지 않는 구간이 나오는데 대표적으로 2가지가 있다.
- local minima
- saddle point

이 때는 억지로 learning rate를 높여줘야 optimizer가 이런 구간에서 탈출해서 global minimum을 계속해서 찾아갈 수 있다. optimizer가 언제 local minima와 saddle point를 만날지 모르니까 주기적으로 learning rate를 크게 했다가 작게 했다가 반복해보기로 했다.
What were key elements of the approach?
Cyclical Learning Rate
Implementatin
순환하는 그래프를 그리는 방법은 많은데 그 중 가장 간단한 trianglar window와 다른 그래프 사이에는 별 차이가 없었다. 그래서 연구에서 이런 그래프를 볼 수 있다.

Step size
이미지처럼 learning rate가 최저지점과 최고지점을 순환하게 할 건데 한 쪽에서 또 다른 한 쪽으로 도달하는 길이를 step size라고 한다. 연구에서는 step size로 2000을 제안했고 일반적으로는 mini_batch의 2-10배 크기가 좋다고 주장하고 있다.
Cycle
learning rate가 최저지점을 출발해서 다시 최저지점으로 돌아오는 주기를 cycle이라고 하고 길이는 당연하게도 2step size다.
Update rule
이제 1 cycle을 주기로 learning rate가 진동하게 할 건데 친절하게도 연구에서 update rule까지 알려주고 있다.
update rule도 3가지가 있다.
- triangular
learning rate range를 학습이 끝날 때까지 진동 - triangular2
cycle이 끝날 때 learning rate를 반으로 decay - exp_range
cycle이 끝날 때 learning rate를 만큼 decay. 그러므로 는 이다.

그러면 자연스럽게 드는 의문이 들거다. 그러면 learning rate range는 어떻게 정하는 거야?
LR range test
Implementatin
연구에서 이 점도 상세하게 설명하고 있다. 일단 마음대로 learning rate range를 정하고 나서 전체 iteration 만큼 range를 쪼갠 다음 각 iteration이 끝날 때마다 learning rate를 올려간다.
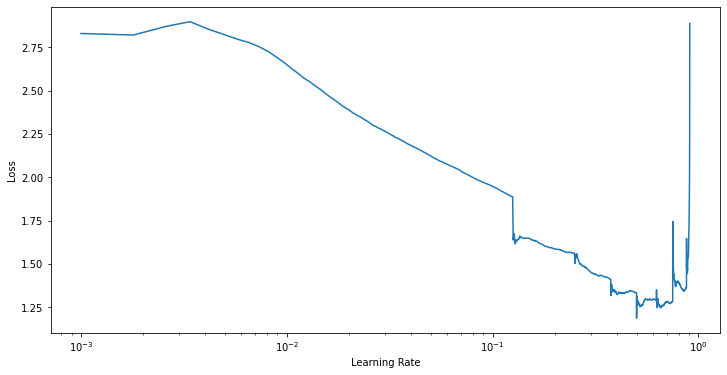
그러면 이런 그래프를 볼 수 있는데 loss가 낮아지기 시작하는 learning rate부터 loss가 치솟기 전까지를 새로운 learning rate range로 정하면 된다. 연구에서는 maxLR의 또는 을 minLR로 정한다고 제안했다.
Expreiment
나머지 부분은 여러 dataset, 모델, optimizer를 동원해서 실험한 내용이다. 결론은 뭐 어디서나 잘 된다. 알아보니까 kaggle에서도 많이 쓰인다고 한다.
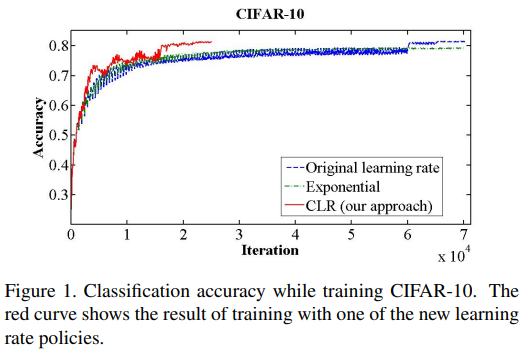
짧은 시간에 모델이 학습하게 하는 현상을 후속연구에서 super convergece라고 정의했다.
Epilogue
이 방법은 fast.ai에서 개발해서 밀고 있는 방법이다. 이게 왜 잘되는지는 후속연구[2]에서 잘 설명하고 있다. 아마 이만큼 잘 될지는 예상 못했던 모양이다.
