- update: 모델구현
Prologue
그동안의 연구에 따르면 layer를 쌓으면 쌓을수록 gradient를 전하기 힘들어진다. 이 현상으로 인해 아이러니하게도 깊은 모델이 얕은 모델보다 성능이 떨어졌고 ResNet에서는 identity mapping를 제안하면서 100개 layer를 넘는 모델을 만들 수 있는 토대를 마련했다. 여기에서 밝혀진 점은 gradient flow를 원활하게 하면 layer를 더 쌓으면서 성능향상도 기대할 수 있다는 점이다.
What did authors try to accomplish?
이 연구에서는 mapping이 가져오는 효과를 극대화하기 위해 모든 layer와 mapping해보기로 했다.
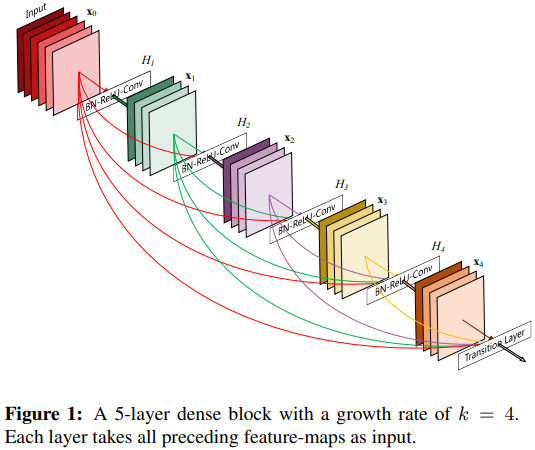
예시에서도 보이듯 개의 layer로 구성하고 있는 DenseBlock의 connection을 계산한다고 할 때 로 같은 수의 block으로 구성하고 있는 ResNet은 개의 connection이 있다는 점과는 대조적이다.
What were key elements to approaches?
DenseBlock
DenseBlock은 ResBlock을 적절히 활용해서 만들었다.
ResBlock
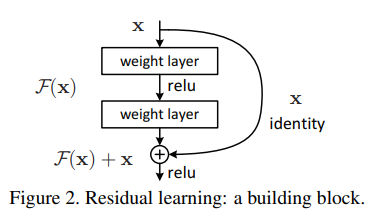
ResBlock은 Conv, BN, ReLU를 하나의 building block으로 구성해서 입력값 를 buliding block과 모양을 맞춰서 더한다.
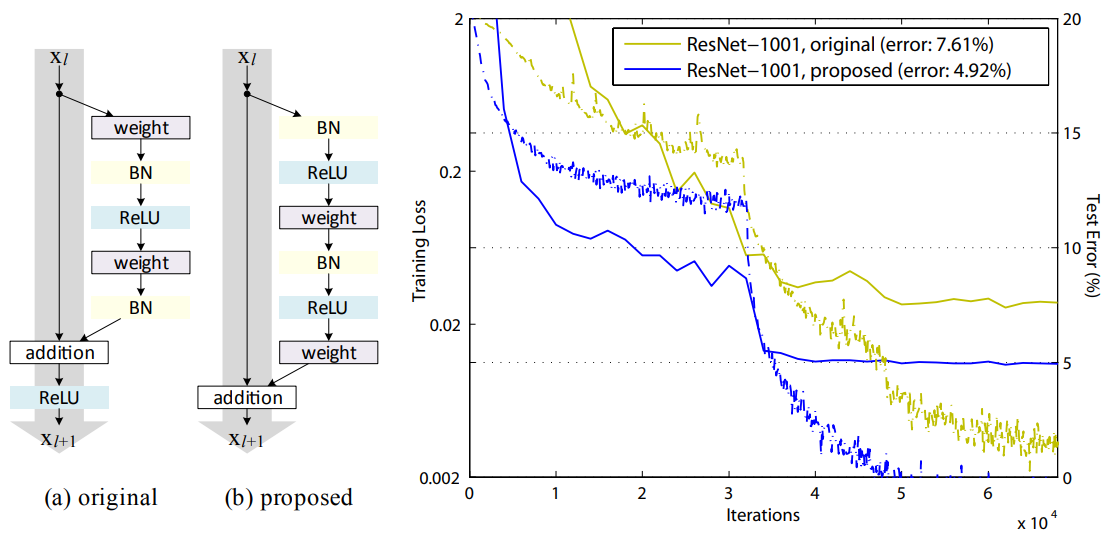
ResNet의 후속연구[3]에서 기존에 제안했던 Conv - BN - ReLU보다 BN - ReLU - Conv가 성능면에서 더 이득을 볼 수 있다고 증명하면서 DenseBlock도 BN - ReLU - Conv이렇게 가져가고 있다.
Concatenate
앞에서 언급했듯이 DenseNet은 이전 layer의 출력값들을 모두 입력값으로 받기위해 concatenate를 통해서 이전 layer에서 만드는 feature map을 최대한 보존하려고 한다.
ResNet은 input layer와 classification layer를 제외한 전체 layer가 ResBlock으로 구성하고 있어서 이전 layer의 출력값을 다음 layer로 전달한다. 이 구조를 DenseNet에 그대로 가져오면 concatenate한 feature map을 받아야 하는 탓에 연산량은 급격하게 늘어날 거다. 연산량을 줄이기 위한 방법을 몇 가지 제시하고 있다.
Growth rate
연구에서는 각 Conv layer가 가지는 kernel의 갯수를 growth rate라고 부르고 로 정의했다. model의 크기에 따라 는 12, 24, 32, 40으로 다양하게 정할 수 있다. ResBlock에 들어있는 kernel의 갯수는 64, 128, 256, 512개로 정하고 있다는 점을 생각하면 DenseBlock을 구성하는 conv layer는 kernel의 갯수가 상대적으로 적은 편인데 을 input layer의 depth라고 할 때 번째 DenseBlock이 받아야 하는 depth를 계산해보면 로 급격하게 늘어나기 때문이다.
Bottleneck layer
ResNet에서는 spatial dimension과 depth를 줄이려고 Conv layer 앞에 Conv layer를 붙여서 사용하면서 bottleneck layer라고 소개했다. 이 연구에서도 ImageNet을 학습하는 것처럼 큰 모델을 만들어야 할 때는 bottleneck layer를 사용하고 bottleneck layer를 포함하는 DenseBlock을 DenseBlock-B라고 불렀다. 이 때 bottleneck layer에서는 만큼의 kernel을 사용했다.
Transition layer
CNN은 feature map을 줄여서 연산량을 줄인다. ResBlock을 이어붙인 ResNet에서는 pooling layer없이 stride에 변화를 줘서 줄이지만 DenseNet에서는 두 DenseBlock사이에 translation layer를 넣었다. transition layer는 Conv layer와 pooling layer로 구성해서 feature map을 줄인다.
Compression
이 때 conpression rate 를 통해서 feature map의 depth를 만큼 줄이고 있다. 는 이므로 일 때 DenseBlock-C라고 부른다. 연구에서는 로 정하고 모든 실험을 진행했고 동시에 bottleneck layer도 함께 쓰고 있으면 DenseBlock-BC로 부르고 있다.
Architecture
전체 구조는 이렇게 생겼다.
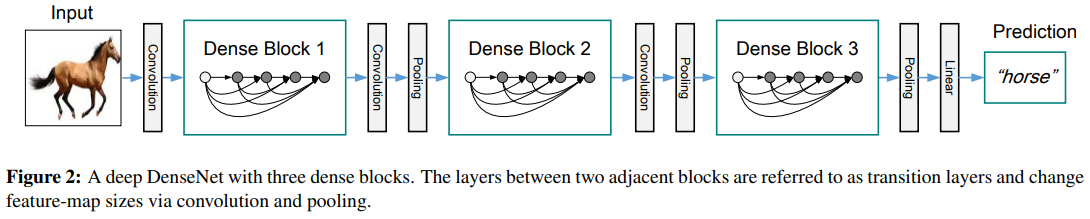
다만 마지막 DenseBlock 이후에 GAP(Global Average Pooling)와 softmax를 activation function으로 하는 dense layer를 붙여서 쓴다.
ResNet vs DenseNet
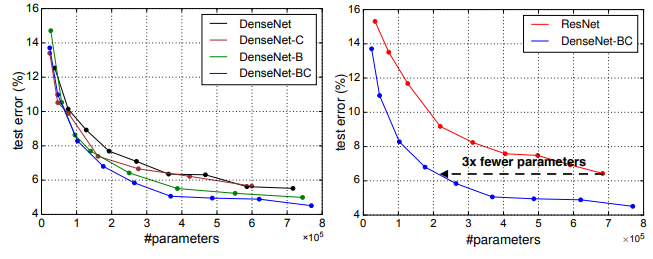
ImageNet을 학습하는 과제에서 ResNet과 비슷한 성능을 가진 DenseNet-BC model을 만드는데는 필요한 연산량은 ResNet의 이라고 밝히면서 자신들의 방법으로 layer를 효율적으로 쌓을 수 있다고 주장했다.
Feature reuse
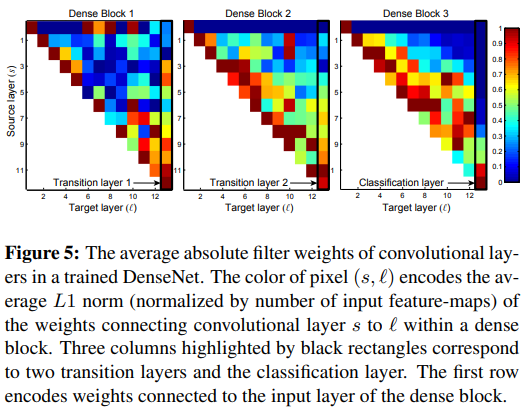
DenseBlock을 구성하고 있는 각 layer의 weight들의 의존도를 나타내는 heatmap이다. 빨간색에 가까울수록 높고 파란색에 가까울수록 낮다. 먼저 3개의 DenseBlock은 각각 를 12로 하고 있고 이 model은 augmented CIFAR 10으로 학습했다. 그리고 나서 각 layer가 다른 layer간의 의존도를 계산했다.
검은색으로 강조된 transition layer들을 중점적으로 보면 된다. 각각의 traisition layer들은 자신이 속해있는 DenseBlock의 모든 layer의 신호를 이용해서 학습에 쓰고 있지만 두번째, 세번재 DenseBlock으로 갈수록 early stage layer와의 의존성은 점점 떨어진다. 이런 경향성은 classification layer에 가서 더욱 심해진다. 여기에서는 자신과 가까운 layer의 신호만으로 학습에 이용하는데 이 점은 classification layer와 가까운 layer에 고수준 feature가 만들어지기 때문이라고 추정할 수 있다.
Epilogue
-
내가 구현한 건 parameter가 30만개인데 연구에서는 100만개라고 한다. 아마 growth rate가 좀 이상한 것 같은데 다른 코드를 좀 봐야겠다.
-
엔지니어링에 관심이 있으면 후속연구를 읽어보면 좋다. 대충 읽어봤는데 요지는 DenseNet은 feature map을 concatenate해서 BN연산을 하는데 이 과정에서 새로운 memory cell을 사용해야 해서 여전히 연산량이 크다고 지적하면서 이 문제를 pointer를 이용해서 연산량을 에서 으로 크게 줄였다는 점이다.
