
📝 ProJect - Auto_Forger
아래는 일반적으로, AI 서비스를 위한 모델을 개발에 필요한 과정들이다.
- 데이터 수집
- 데이터 전처리
- 모델 구축 및 학습
- 모델 평가
이 프로젝트에서는 데이터 수집 및 전처리 과정에 집중해보자.
⚠️ Problem Scoping
데이터 수집 단계에서는 각종 데이터셋들을 필요에 의해 가공하거나 변형을 통해 사용하거나, 직접 데이터를 수집하는 단계에 해당한다.
데이터 전처리 직접 데이터를 수집하거나 사전 구축된 데이터셋을 사용하여 데이터를 필요 목적에 의해 가공하여 학습 모델의 데이터로 사용될 준비를 하는 과정.
데이터 수집과 데이터 전처리 이 두 과정들에서 소요되는 시간들이 너무나 크다는 것이 해당 프로젝트에서 주목해야 할 요점이다. 또한, 필자가 생각하는 데이터 수집 및 전처리 단계에서의 한계는 주변에서 바로 구할 수 있는 데이터 즉, 이미지, 텍스트, 음성 등의 데이터를 학습 모델에 바로 활용할 수 없다는 것이다.
왜? 학습을 위해서는 데이터의 Shape, 데이터의 길이를 통일 시키는 등의 과정들이 필요하는 것이다.
이러한 과정들이 다소 비효율적으로 보이는 경우가 많다. 이를 어떻게 개선할 수 있을까?
🚀 Project Goals
Auto_Forger를 통해, Data Pipleline을 개선하여, AI를 이용한 융합 서비스들의 개발 속도를 개선하며, 데이터를 가공하고 전처리하는 과정에서 드는 불필요한 인력과 비용을 최소화하여 기업과 단체의 금전적 손실을 최소화 하는 것. 그리고, 데이터에 아직 익숙하지 않은 초보자들과 입문자들의 흥미를 유발하여 Data Handling Skill에 대해서 한 걸음 더 나아갈 수 있게 모두를 잇는 것이 본 프로젝트의 목적이자, 앞으로의 비전이라고 할 수 있다.
💡 Solutions
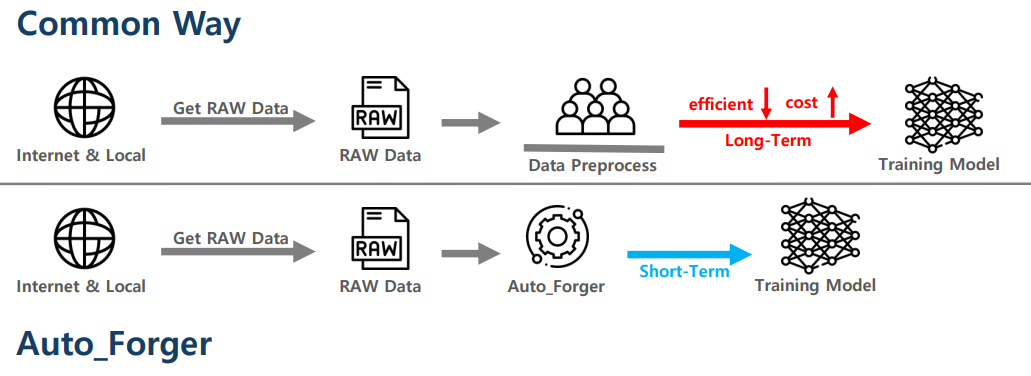
위 Diagram은 기존
Functions
- Padding
- Max Length Padding
- Min Length Padding
- Average Length Padding
- Image & Video
- Person Keypoint Extraction(OpenPose, MediaPipe)
- Image Auto Labeling(Array, Json, xml)
- NLP
- RAW Data to ChatBot Dataset
