결석했다! 공부하자!
22.10.02 시작!
0105 - python 기술통계
여기서는 다양한 서드파티 라이브러리를 통해 쉽게 data의 기술통계를 살펴볼 수 있는 방법을 배운 것 같다.
1. pandas profiling
2. sweetviz
3. autoviz
위 세 가지 프로그램을 이용했다.
위와 같은 프로그램들을 사용하게 되면, 우리가 번거롭게 그래프를 그려보고, describe를 이용하고 등의 활동을 할 필요 없이 알아서 다양한 기술통계 값과 시각화한 자료를 보여준다는 장점이 있다.
하지만 대용량의 데이터에 대해서는 사용하는데 시간이 너무 오래걸린다는 단점이 있다.
먼저 pandas profilling 부터 살펴보자.
Pandas profiling
!pip install pandas-profiling==3.1.0을 통해 설치한다.
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Pandas Profiling Report MPG")
profile.to_file("pandas_profile_report.html")을 통해 pandas profiling report를 만들어낼 수 있다.
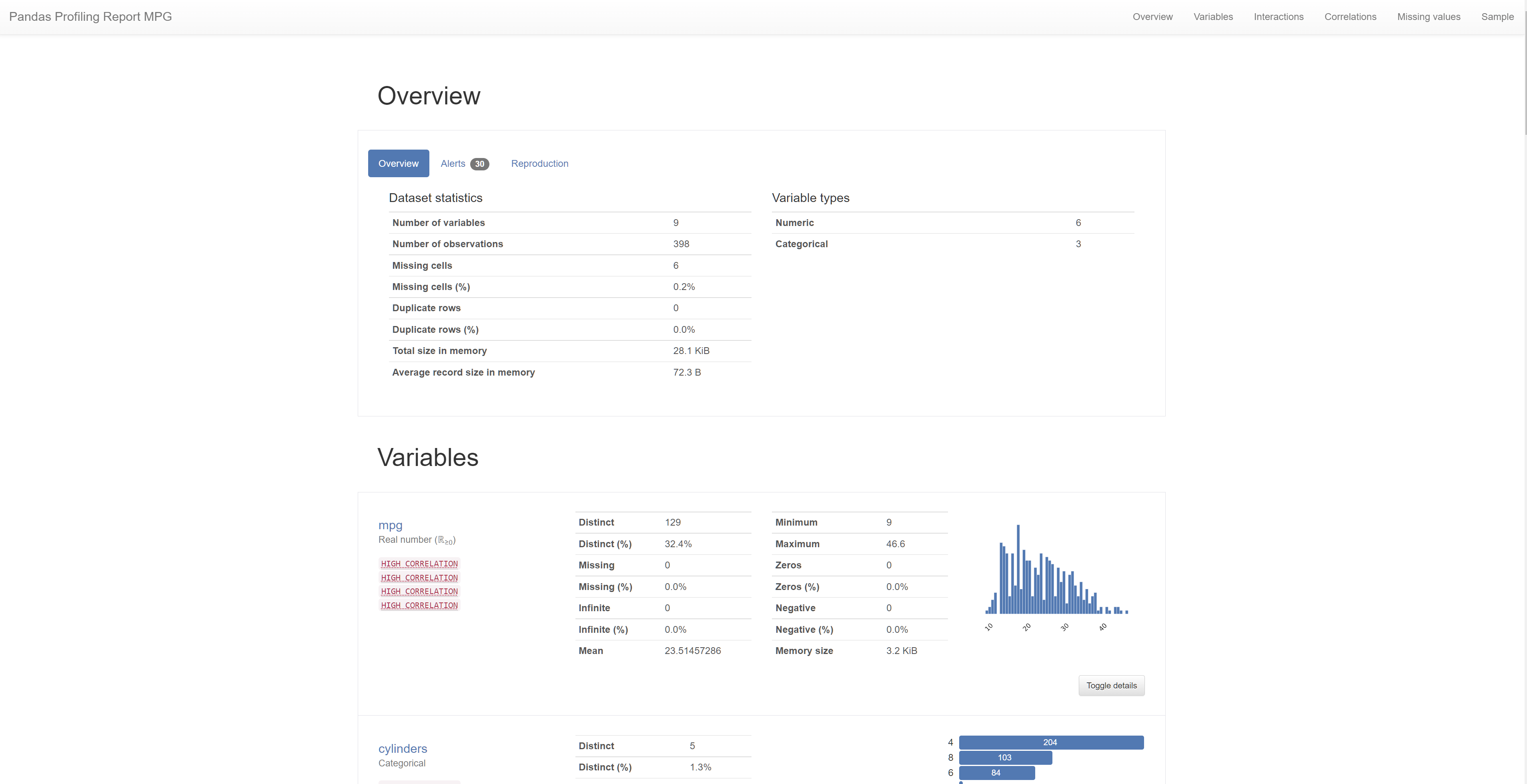
다음과 같은 profiling report를 생성한다.
해당 report를 통해, 기본적인 기술통계값을 확인할 수도 있고, 각 column별 기술 통계 값도 확인할 수 있으며, column들 간의 상관 관계에 대해서도 파악할 수 있다. 심지어는 결측값의 유무도 파악해준다.
pandas profiling 예시
pandas-profiling/pandas-profiling: Create HTML profiling reports from pandas DataFrame objects
sweetviz
!pip install sweetviz
import sweetviz as sv
my_report = sv.analyze(df)
# 타겟변수 없이 그릴 수도 있고 타겟변수를 지정할 수도 있습니다.
# 타겟변수는 범주형이 아닌 수치, bool 값만 가능합니다.
# 데이터에 따라 수치형으로 되어있지만 동작하지 않을 수도 있습니다.
# my_report = sv.analyze(df, target_feat ='mpg')
my_report.show_html()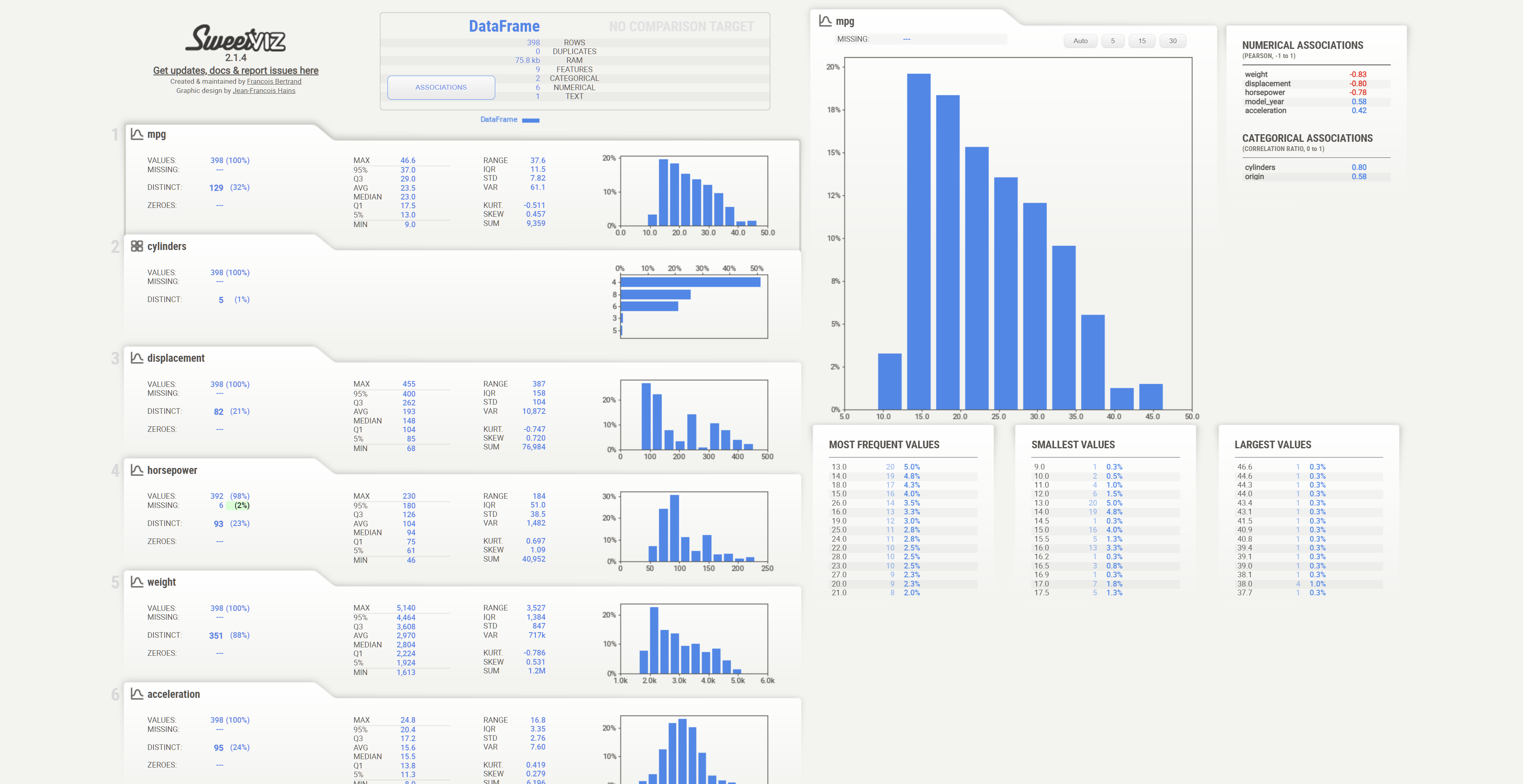
다음과 같은 report를 만들어준다. 해당 리포트를 통해서도 역시 데이터에 대해 전반적으로 살펴볼 수 있다.
Autoviz
!pip install autoviz
from autoviz.AutoViz_Class import AutoViz_Class
AV = AutoViz_Class()
filename = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/mpg.csv"
sep = ","
dft = AV.AutoViz(
filename,
sep=",",
depVar="",
dfte=None,
header=0,
verbose=0,
lowess=False,
chart_format="html",
# chart_format="bokeh",
max_rows_analyzed=150000,
max_cols_analyzed=30,
# save_plot_dir=None
)
앞의 두 가지보다는 사용법이 조금 더 복잡해보인다. Autoviz는 파이썬의 시각화 라이브러리 중 하나인 bokeh를 이용해 다양한 시각화를 해주는 라이브러리이다.
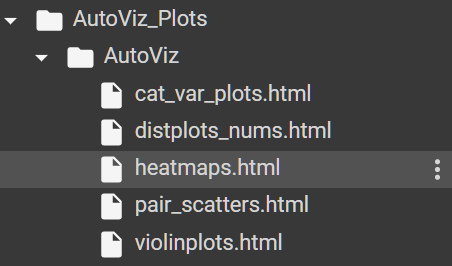
위와 같이 cat_var_plots, distplots, heatmaps, pair_scatters, violinplot 등 의 그래프로 시각화해준다.
각 그래프에서 x축, y축에 들어갈 변수들을 지정해줄 수도 있으며, 그래프를 확대 및 축소하여 살펴볼 수도 있다.
위의 도구들을 사용하면, 우리가 반복적인 작업을 통해서 스스로 살펴봐야 하는 여러가지 통계 자료들을 자동으로 제작해주어, EDA에 큰 도움이 될 것이다!
0106 - 수치형 변수 EDA
본격적인 EDA에 대해서 배웠다. EDA에서 중요한 것 중 하나가 바로 결측치 처리였다. pandas를 사용해 결측치를 어떻게 처리하는지 보도록 하자.
결측치 확인
df.isnull()을 통해 각 데이터들을 NULL이면 TRUE, 아니면 FALSE로 표시할 수 있다.
따라서 결측치의 개수를 구하기 위해서는 다음과 같이 사용한다.
df.isnull().sum()해당 코드를 통해 각 column별로 결측치가 몇 개 씩 있는지 파악할 수 있다.
만약 결측치의 비율을 구하고 싶다면 아래와 같이 사용한다.
df.isnull().mean()*100음.. 생각을 해보면, True == 1이므로, 평균을 구한다는 것은 전체 중 결측치의 비율을 구한다는 것으로 해석할 수 있다. 백분위로 표현하기 위해 100을 곱해주었다. 해당 코드로 컬럼 별 결측치의 비율을 알 수 있겠다.
다르게는 다음과 같이 표현할 수 있다.
df.isnull().sum()/len(df)하지만 아래와 같은 코드는 안된다.
df.isnull().sum()/count(df)이는, count()함수가 결측치를 제외한 개수를 세기 때문이다!
시각화를 통해 결측치를 알아보기 위해서는 다음과 같은 코드를 사용한다.(heatmap 사용)
plt.figure(figsize=(12, 8))
sns.heatmap(df.isnull(), cmap="Greys_r")
이때, heatmap의 색상은 cmap(colormap)을 바꾸어줌으로써 변경할 수 있는데, print(plt.colormaps())를 통해 cmap의 종류를 확인할 수 있다.
음.. 결측치를 처리하는 방법은 배우지 않았나보다.
근데 뭔가 어디선가 배운 기억이 있어 끄적여보면,
.dropna()를 통해 결측치를 삭제할 수 있는데, how = Any, All 이었나 그런 parameter를 통해 결측치가 하나라도 있는 열을 삭제할건지, 모든 값이 결측치인 열을 삭제할 건지를 결정할 수 있었던 것 같고, 행을 삭제할 지 열을 삭제할지도 결정할 수 있었을 것이다.
혹은 ,fillna()를 통해 결측치를 다른 값으로 대체해 줄 수도 있었을 것이다. fillna()안에 들어가는 인자로 해당 열의 중앙값 또는 평균을 주어 결측치를 다른 값으로 대체하는 경우가 있다.
기술통계 보기
전부터 하던 것 과 동일하게 기술통계 값을 보기 위해서느 아래 코드를 사용한다.
df.describe() # 수치형 변수의 기술통계값
df.describe(include = "object") # 범주형 변수의 기술통계값수치형 변수를 범주형 변수로 변경하여 기술통계값을 보고자 한다면 다음과 같이 사용한다.
df[['cylinders','model_year']].astype(str).describe()astyoe(str)을 이용해 수치형 변수를 범주형 변수로 바꾸어주었다.
수치형 변수와 범주형 변수의 차이는 '측정할 수 있는 값'이면 수치형 변수이다 라고 알고 있었는데, 데이터 분석 시에는 unique값의 개수에 따라 수치형 변수로 사용할지 범주형 변수로 사용할지 결정한다고 한다.
그럼 본격적으로, 수치형 변수의 EDA에 대해 살펴보자.
수치형 변수 EDA
df.nunique().nunique()를 사용하면, 각 컬럼 별로 unique한 값의 개수를 알려준다.
.unique()가 고유값들을 모두 알려주는 것과 차이가 있다.
수치형 변수에 대해 histogram을 그려 전체 변수의 분포를 파악하곤 한다.
df.hist(figsize=(12, 10), bins=50)
plt.show()여기서 막간 tip으로, jupyter 등에서 matplotlib 그래프를 그릴때 주석이 나오지 않게 하려면 plt.show()를 사용하거나, df.hist(~);처럼 코드의 마지막에 ;를 찍으면 된다고 한다.
새롭게 알게 된 기술통계 값이 있다면, 바로 skewness와 kurtosis이다.
skewness는 비대칭도, 혹은 왜도라고 부르는 값으로, 데이터가 중앙에서 벗어나 한 쪽에 많이 치우쳐있는지 여부를 나타낸다.
왜도가 음수이면 중앙값이 오른쪽 부분에 위치해 있다. 즉, 데이터가 오른쪽에 더 많이 분포하며 왼쪽으로 긴 꼬리를 가진다. 양수라면 왼쪽 부분에 위치해있다. 왜도가 0이면 평균과 중앙값이 같다.
df.skew()
df.skew().sort_values()위와 같이 왜도를 알아볼 수 있다.
kurtosis는 첨도라고 부르는 값으로, 첨도값(K)가 3(혹은 0) 일 경우 산포도가 정규분포에 가깝다. K<3(또는 0)이면 정규분포보다 좁고 높게 솟은 형태라고 생각할 수 있다.
df.kurt().sort_values(ascending=False)위의 코드를 통해 전체 컬럼에 대한 첨도를 구할 수 있다.
df["mpg"].agg(["skew", "kurt", "mean", "median"])해당 코드를 통해 agg를 사용해 여러 기술통계 값을 한번에 구할 수도 있다. agg(aggregate)를 이용하면, dataframe에 다양한 함수를 한번에 적용할 수 있다.
실행 결과는 다음과 같다.
skew 0.457066
kurt -0.510781
mean 23.514573
median 23.000000
Name: mpg, dtype: float64displot
displot에 대해 이야기 하기 전에, 다시 seaborn 공식 문서에 있는 그래프의 종류 사진에 대해 살펴보자.
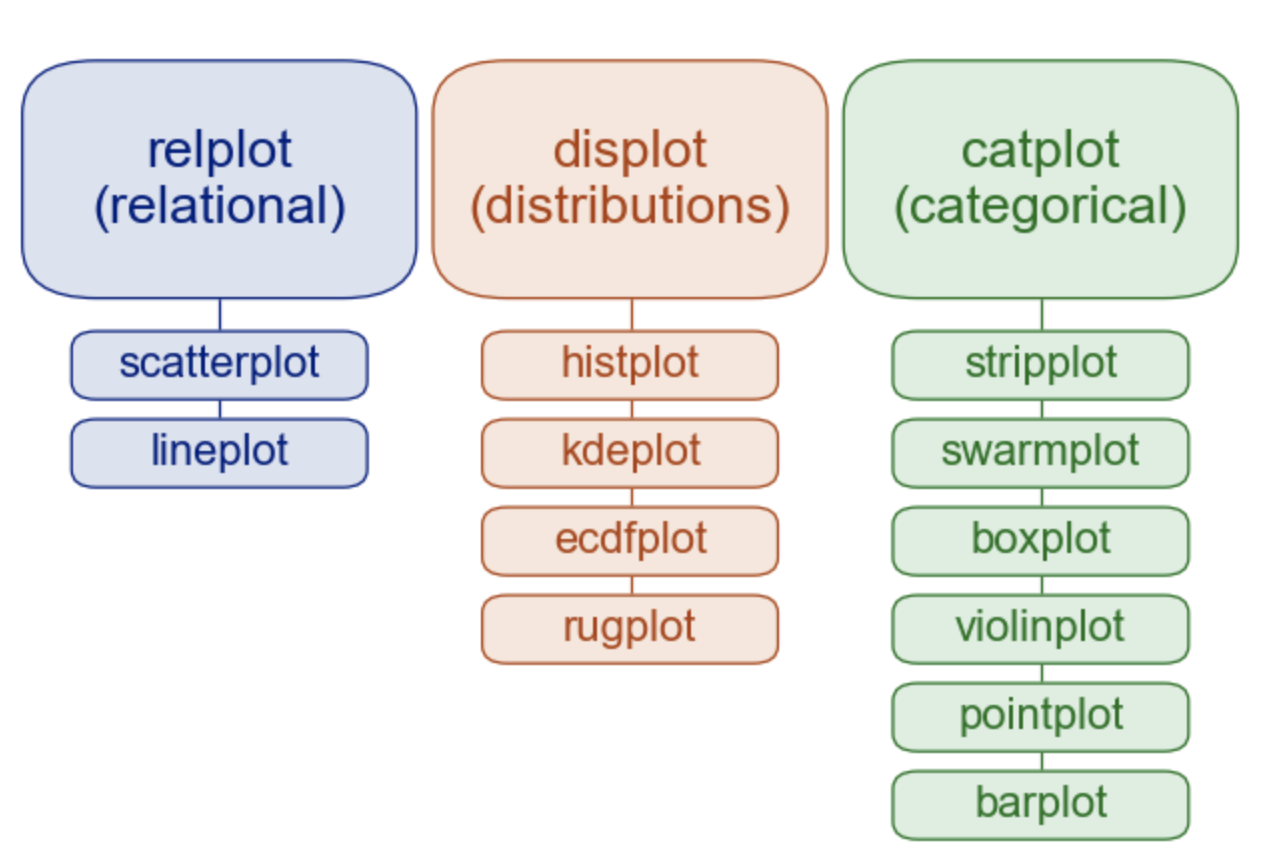
여러 변수 간의 관계를 나타내기 위해서는 relplot을 사용하고,
변수들의 분포를 나타내기 위해서는 displot을 사용하며,
범주형 변수의 그래프를 그리기 위해서는 catplot을 사용한다.
해당 그래프들(relplot, displot, catplot)은 그 안에서 다양한 그래프들을 그릴 수 있는데, 여기서 특이한 점은 Facetgrid가 합쳐진 형태여서 subplot들을 나누어 그릴 수 있다는 점이다.
따라서 원하는 그래프 하나만 그릴 때에는 각각의 함수를 이용해도 되지만, subplot으로 여러 카테고리나 변수를 나누어 그리고 싶다면 Facetgrid가 합쳐진 relplot, displot, catplot, lmplot등을 사용한다.
그럼 다시 displot 에 대해 알아보자. 데이터의 분포를 나타낼 수 있는 plot인 displot은 내부에 histplot, kdeplot, ecdfplot, rugplot을 그릴 수 있다.
기본적으로 히스토그램이 나타나며, kde 등은 추가로 그릴 수 있다고 생각하면 된다.
그리는 방법은 아래와 같다.
# displot을 통해 히스토그램과 kdeplot 그리기
sns.displot(data=df, kde=True);하지만 해당 코드로 그래프를 그려보면, 모든 column에 대해 그래프를 그리느라 자세한 값을 알아볼 수 없다는 문제가 있다. 따라서 x축에 들어갈 변수를 설정하여 그래프를 그릴 수 있다.
sns.displot(data=df, x="mpg", kde=True)여기서 또 중요한 점, hue와 col을 설정해준다면, 그 값을 기준으로 subplot을 나누어 그려준다.
col에 들어간 값을 기준으로 나누어 subplot을 그리고, hue를 기준으로 색을 다양하게 표현한다고 생각할 수 있겠다.
sns.displot(data=df, x="mpg", kde=True, hue="origin", col="origin", bins=50)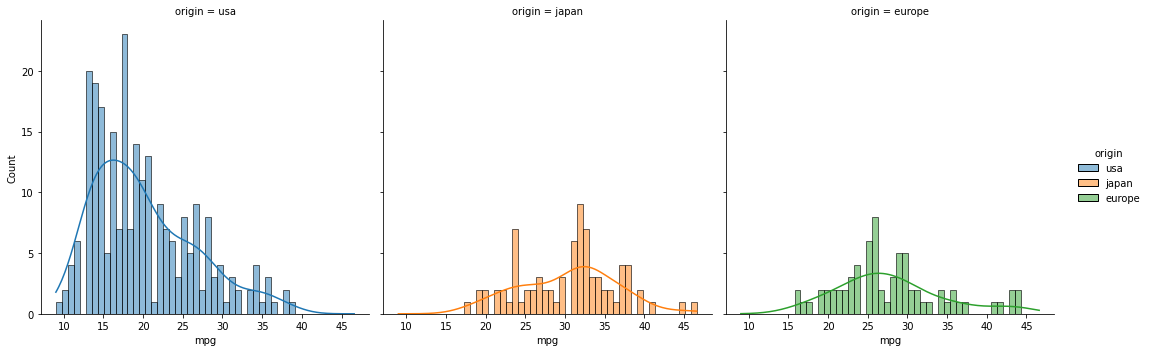
rugplot은, x축 위에 데이터가 분포해 있는 곳 마다 선을 그어 데이터의 분포를 표시해주는 그래프이다.
# kdeplot, rugplot으로 밀도함수 표현하기
sns.kdeplot(data=df, x="mpg")
sns.rugplot(data=df, x="mpg")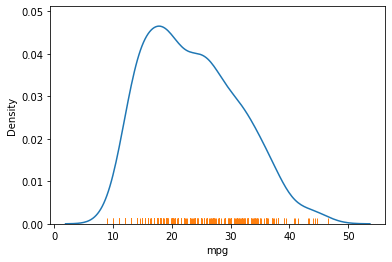
위 코드는 하나의 fig(ax?)내에 두 개의 그래프를 그려주므로 그래프가 겹쳐져서 표시된다.
catplot
다음은 catplot 중 하나인 boxplot이다.
sns.boxplot(data=df, x="mpg")boxplot은 전에 한번 정리한 바 있듯이 4분위 값을 이용한 그래프이며, 이상치까지 표시할 수 있다. 그러나 데이터의 분포를 표시할 수 없다.
따라서 violinplot을 이용한다.
sns.violinplot(data=df, x="mpg")violinplot은 boxplot과 kdeplot을 합쳐 놓은 형태라고 볼 수 있었다.
# boxplot 으로 전체 변수 시각화하기
sns.violinplot(data=df)전체 변수들에 대해 violinplot을 그리면, 변수들의 scale이 모두 다르기 때문에 제대로 값을 관찰할 수 없다.
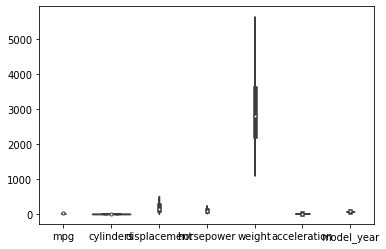
따라서 scaling을 해준다.
scaling
데이터들의 scale(값의 범위)를 조정해, 데이터들 간의 비교를 수월하게 하거나, 학습 시 특정 column에 가중치가 주어지는 일을 막기 위한 행위.
Standardization과 Normalization으로 나누어 생각할 수 있다.Standardization
평균과 표준 편차를 이용해 scaling 하는 것.
데이터가 정규분포를 따르게 한다고 생각할 수 있으며, standardScaler, RobustScaler가 있다.Normalization
최댓값과 최솟값을 사용해 데이터를 [-1,1] 사이의 값으로 scaling 한다고 볼 수 있다. MinMaxScaler, normalizer(행 방향)이 있다.
우리는 아래와 같은 코드를 사용해 scaling 해주었다.
df_std = (df_num - df_num.mean()) / df_num.std()
df_std.describe().round(2)standard scaling을 사용했다고 볼 수 있겠다.
minmax의 경우 (df- df.min()/(df.max()-df.min())으로 사용할 수 있겠다.
스케일링한 데이터를 사용해 violinplot을 그리면 다음과 같다.
sns.violinplot(data=df_std)
앞에서와 달리 데이터들의 scale이 모두 유사해져 한눈에 잘 볼 수 있다.
relplot
다음은 relplot 중 하나인 scatterplot에 대해 알아보자.
두 변수 간의 관계를 나타내는데, 점을 찍어서 나타내준다.
sns.scatterplot(data=df, x="mpg", y="horsepower")regplot은, scatterplot에 회귀선까지 더해서 표시한다.
sns.regplot(data=df, x="mpg", y="horsepower")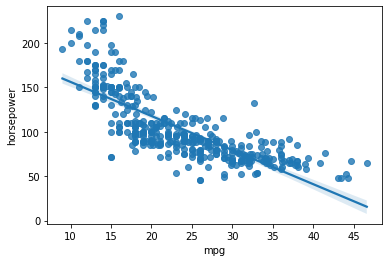
회귀선의 잔차(residual)을 시각화하기 위해서는 residplot을 사용한다.
sns.residplot(data=df, x="mpg", y="horsepower")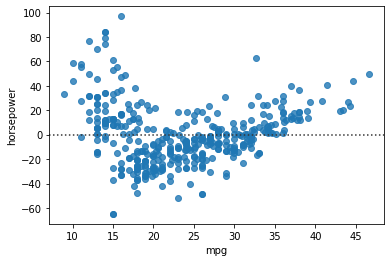
그래프를 보면 회귀선이 x축이 되는 방향으로 regplot이 회전하였다고 생각할 수 있다.
regplot을 여러 subplot으로 나누어 그리기 위해서는 lmplot을 사용한다.
sns.lmplot(data=df, x="mpg", y="horsepower", hue="origin", col="origin")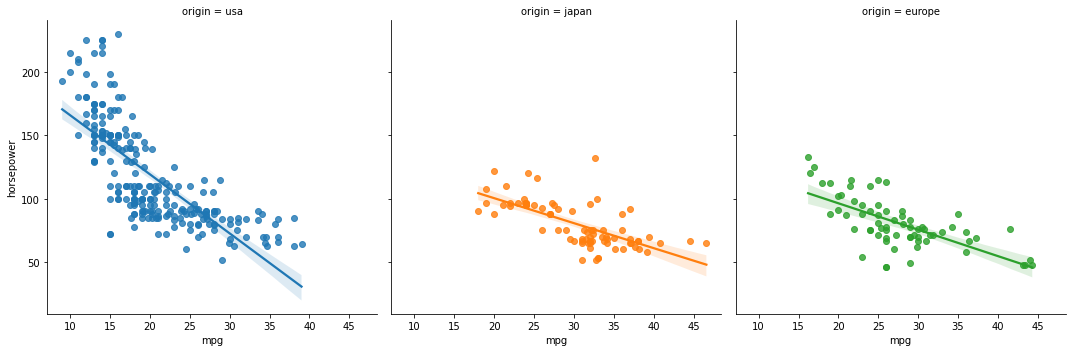
어 이건 또 처음보는거. jointplot
jointplot은 그래프 안쪽과 바깥쪽을 이용해 안쪽에는 두 변수 사이의 관계를, 바깥 쪽에는 각각의 그래프의 분포를 표시해주는 그래프인 것 같다.
sns.jointplot(data=df, x="mpg", y="horsepower", kind="hex")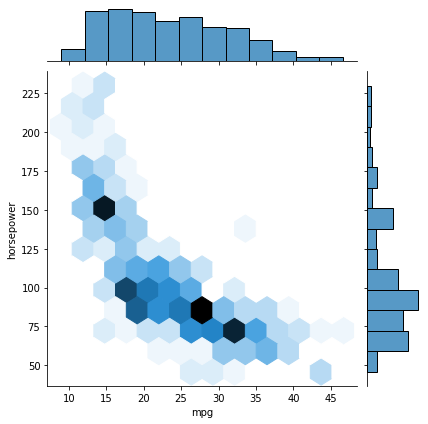
그래프의 종류를 바꿀 수도 있다.
sns.jointplot(data=df,x="mpg",y="horsepower",kind = "kde")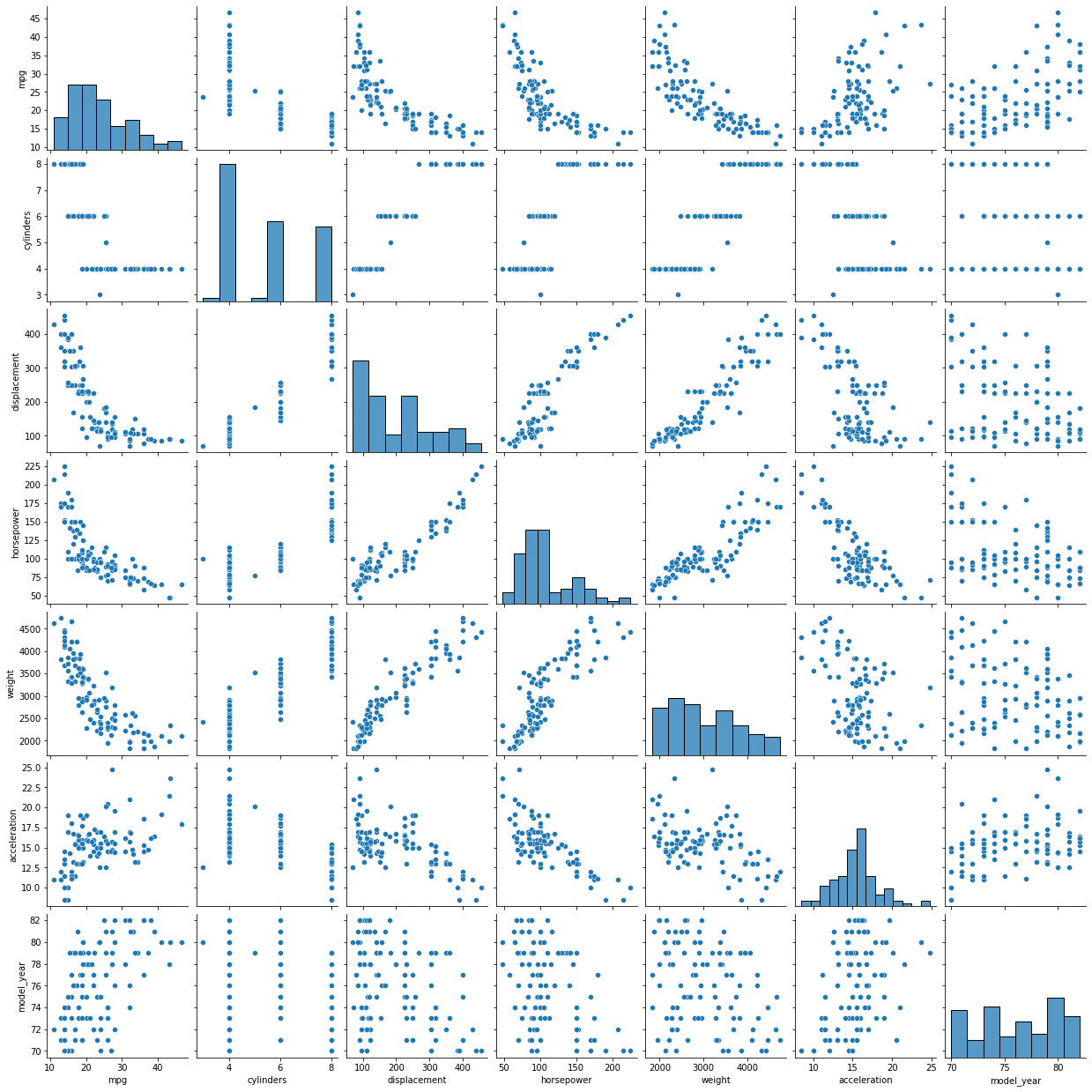
그리고 또, pairplot은 음... 뭐지..?
datafrmae의 모든 column의 조합에 대해 그래프를 그려준다. 자기 자신과의 교차 지점에는 본인의 히스토그램을, 다른 열과의 교차 지점에는 scatterplot을 그려준다.
sns.pairplot(data=df.sample(100),hue = 'origin')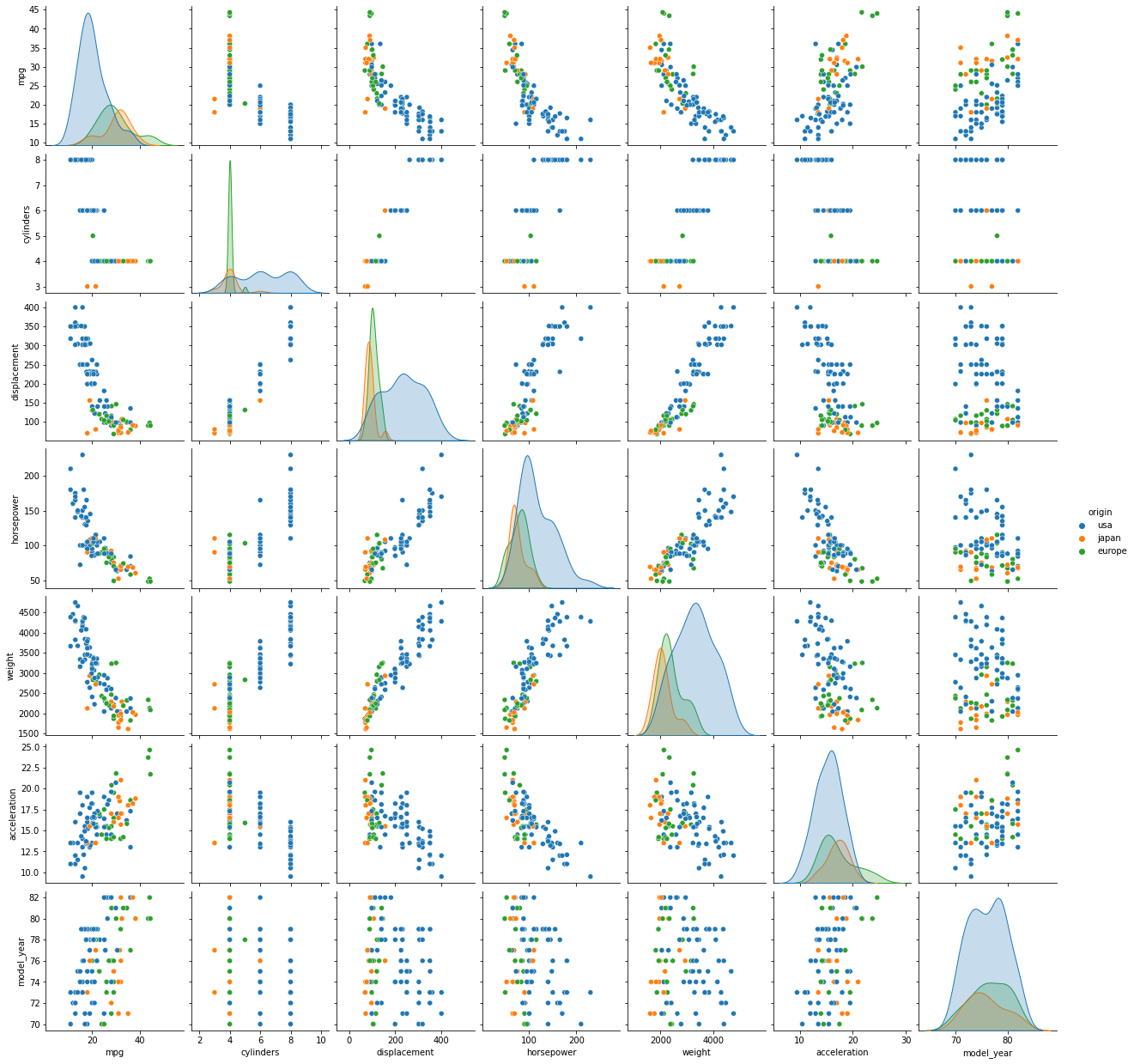
lineplot은 말 그대로 선형 그래프를 그려준다.
sns.lineplot(data=df, x="model_year", y="mpg")
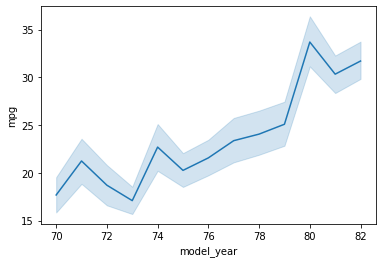
역시 hue값을 나누어서 그려주려면 relpolt을 사용한다.
sns.relplot(data=df, x="model_year", y="mpg", hue="origin", col="origin", kind="line", ci=None)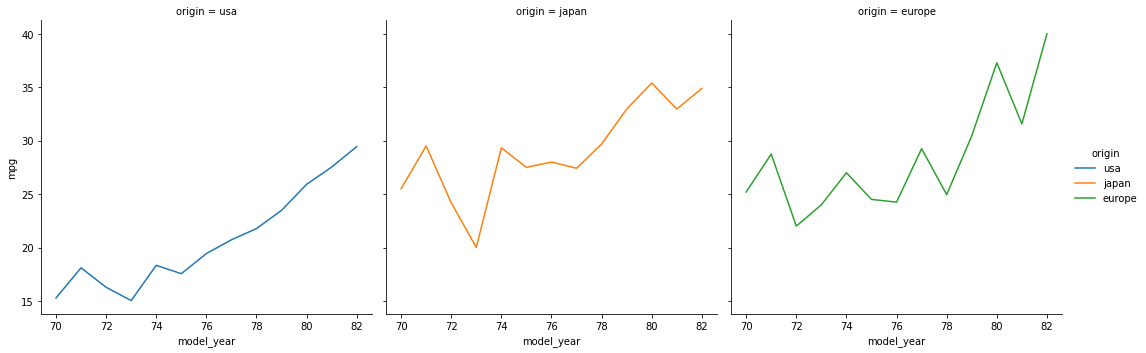
상관계수
두 변수 간 선형적 혹은 비선형적으로 가지고 있는 관계를 파악한다. 다양한 상관계수가 존재하는데, 우리는 주로 피어슨 상관계수를 사용했다.
x와 y과 완전히 동일하면 1, 반대방향으로 완전히 동일하면 -1이고, 아무런 관계가 없다면 0이라고 생각할 수 있다.
corr = df.corr().corr()를 사용하여 상관계수를 구할 수 있으며, 기본적으로는 pearson 상관 계수가 구해진다.
이제 heatmap을 사용해 상관계수를 시각화해보자.
여기서, 상관계수는 대각선으로 대칭이므로, 한 쪽만 표시해주기 위해 다음과 같은 코드를 이용한다.
# np.triu : matrix를 상삼각행렬로 만드는 numpy math
# [1 2 3] np.triu [1 2 3]
# [4 5 6] -------> [0 5 6]
# [2 3 4] [0 0 4]
# np.ones_like(x) : x와 크기만 같은 1로 이루어진 array를 생성
# 수식적으로 어려워 보일수도 있지만 간단함
# 자기상관계수는 대각행렬을 기준으로 대칭되어 같은 값이 출력되므로,
# 이대로 전체를 heatmap을 plot하면 오히려 가독성이 떨어질 수 있음
# 이에, 가독성을 높이기 위해 대각행렬 기준으로 한쪽의 데이터들만 masking 기법을 통해 plot하여
# 가독성을 높이는 효과를 가질수 있음
# np.ones_like로 heatmap의 마스크값 구하기
mask = np.triu(np.ones_like(corr))
mask
>>>
array([[1., 1., 1., 1., 1., 1., 1.],
[0., 1., 1., 1., 1., 1., 1.],
[0., 0., 1., 1., 1., 1., 1.],
[0., 0., 0., 1., 1., 1., 1.],
[0., 0., 0., 0., 1., 1., 1.],
[0., 0., 0., 0., 0., 1., 1.],
[0., 0., 0., 0., 0., 0., 1.]])이렇게 아래만 표시하기 위한 mask를 만들었고, heatmap은 다음과 같이 사용한다.
sns.heatmap(corr, cmap="coolwarm", annot=True, mask=mask)annot = True는 heatmap의 각 상자 안에 값을 표시한다는 것을 의미하고, mask를 이용해 표시할 부분을 정해 줬으며, center = 0(cmap의 중앙), vmax=.3(cmap의 최댓값), square=True(사각형 하나하나 밖에 선을 그린다),linewidth=.5 등의 parameter가 있다.
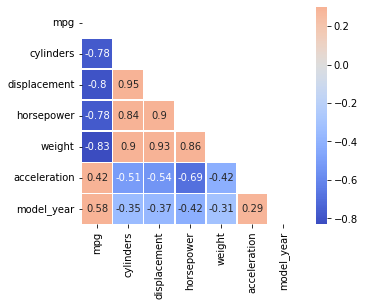
상관계수는 인과관계를 의미하지 않는다!
이렇게 첫번째 결석한 날의 수업을 한 번 따라잡아 보았다.
강의자료 보고, discord 보고, 다른 분들이 데일리 키워드 요약하신거 보니 어느정도는 따라잡을 수 있었다.
다만, 공부 방법에 고민이 아직 되네! 뭔가 정리를 하는 느낌이 아니라, 배운걸 다시 한번 다 써내려가보는 느낌이다. 눈에 딱 들어오고, 나중에 궁금할때 찾아볼 수 있도록 정리를 하고 싶었는데!
그리고그리고그리고, seaborn에 대해서!
이제 relplot, displot, catplot 등 어떤 함수들이 관계를 표시하기 위해, 혹은 분포를 표시하기 위해 사용하는지는 좀 알겠는데..
아직 수치형 변수를 표현하기 위해선 이걸 사용해라, 범주형 변수를 표현하기 위해서는 이걸 사용해라 이건 모르겠다.
다음날이 범주형 변수의 EDA니까, 그거 공부하면 좀 알수도 있으려나..?
어쨌든 파이팅!
