NMF (Non-negative Matrix Factorization)
- 음수를 포함하지 않은 행렬 X를 음수를 포함하지 않은 W,H의 곱으로 분해하는 알고리즘.
- PCA가 데이터의 분산이 가장 크고 수직인 성분을 찾았다면, NMF 는 음수가 아닌 성분과 계수를 찾음 : 즉 주성분과 계수가 모두 0보다 크거나 같음.
- PCA는 성분간 우열이 있는 반면, NMF는 성분의 우열 없이 특징을 뽑아낸다!
- 음수가 아닌 가중치 합으로 데이터를 분해하는 기능은 오디오 트랙이나 음악처럼 독립된 소스를 추가하여 만들어진 데이터에 특히 유용.
- 최근에는 추천 시스템으로 자주 쓰인다!
| 특징 | 사용자 기반 협업 필터링 | NMF / ALS (행렬 분해) |
|---|---|---|
| 추천 근거 | 사용자 간의 유사도 | 사용자와 아이템 간의 잠재 요인 |
| 필요 데이터 | 사용자-아이템 상호작용 데이터 | 사용자-아이템 평점 데이터 |
| 추천 방식 | 비슷한 사용자들이 좋아한 아이템 추천 | 행렬 분해로 예상 평점을 계산한 뒤 추천 |
| 장점 | 직관적이고 이해하기 쉬움 | 희소한 데이터에서도 효율적 추천 가능 |
| 단점 | 데이터 희소성이 크면 성능 저하 | 모델 학습이 상대적으로 복잡 |
주요 노테이션
- 행렬 X: 데이터셋, m개의 행, n개의 변수 (열) m x n 행렬이라고 간주 (여기서 차원은 n)
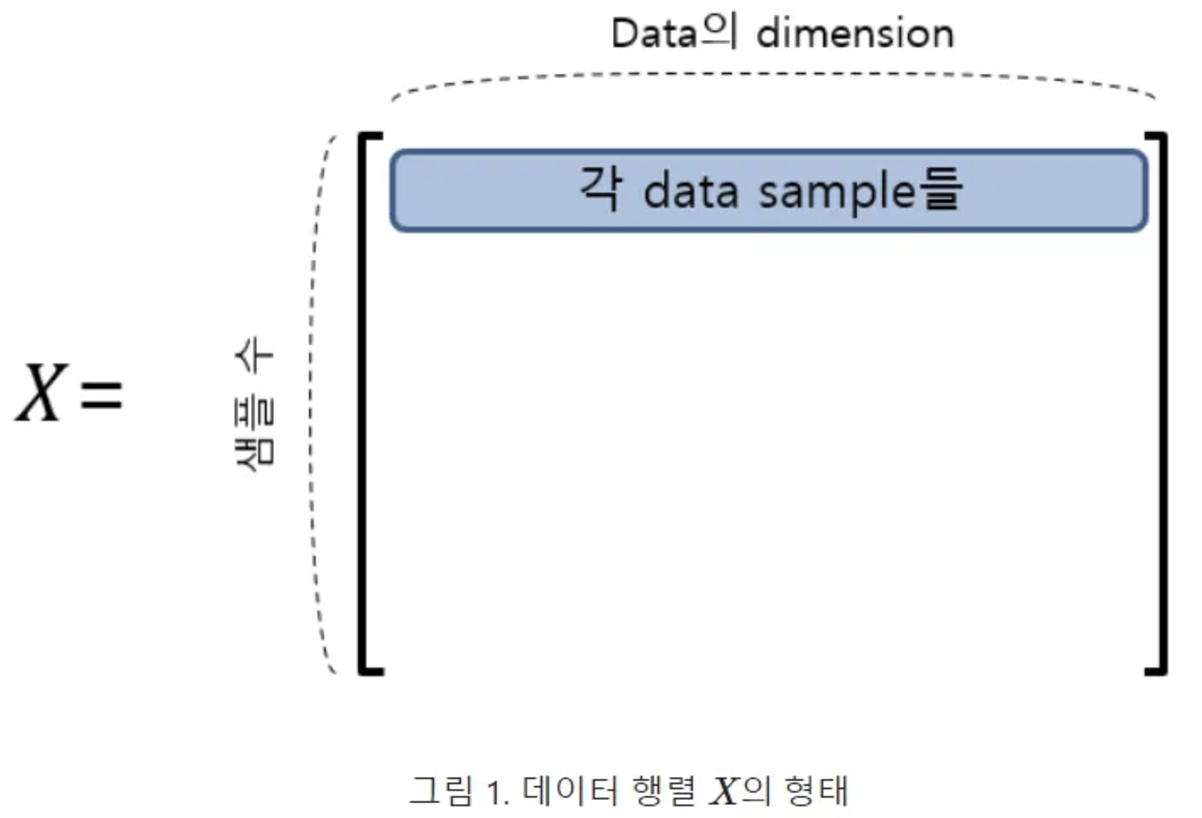
- 우리는 현재 차원을 p차원으로 줄이려고 함.
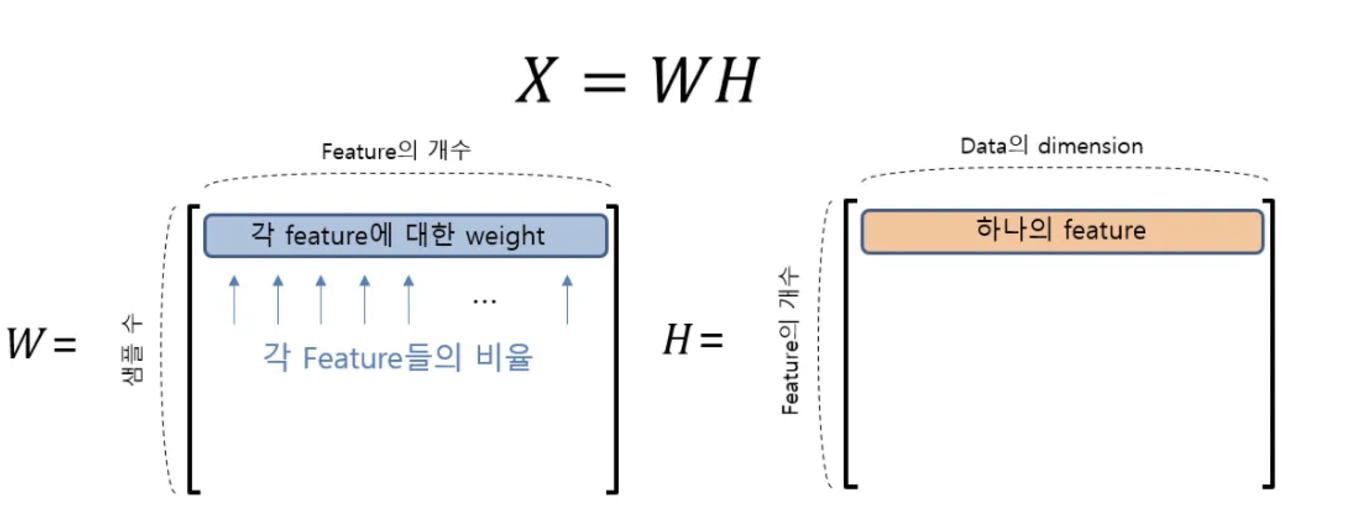
예시
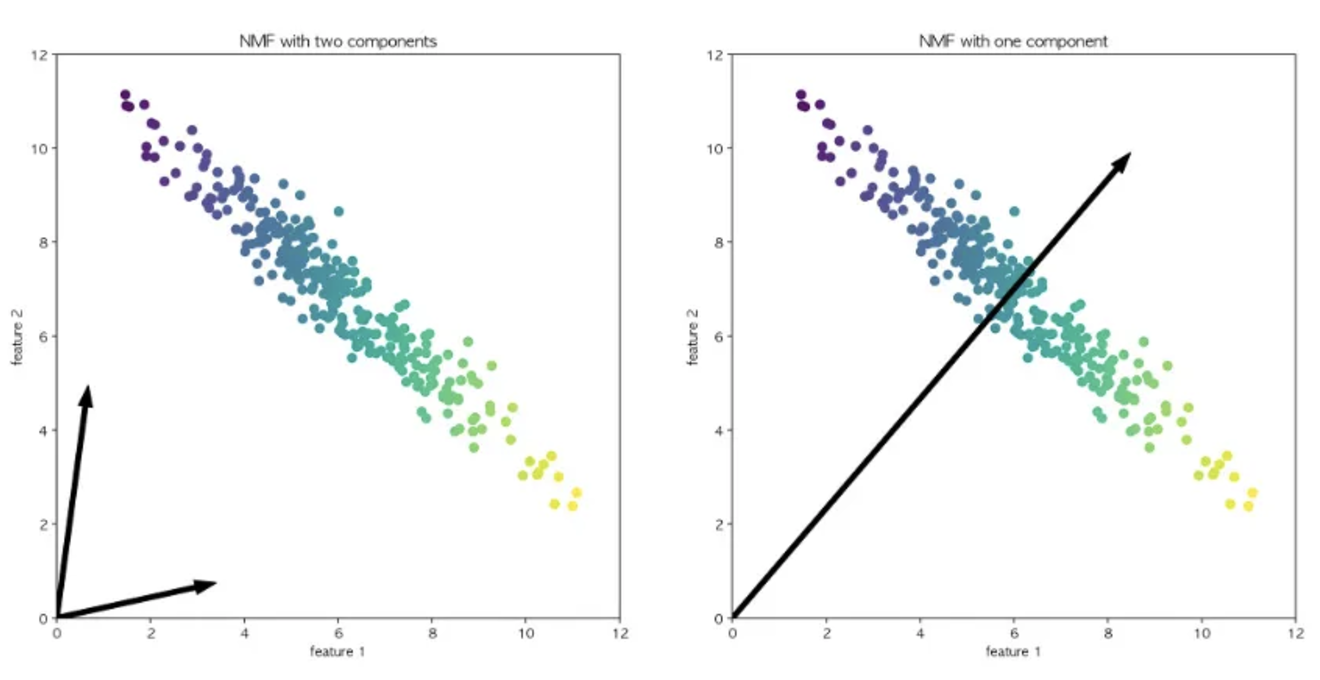
왼쪽: 두개의 성분으로 표현함 ⇒ 데이터셋의 모든 포인트를 양수로 이루어진 두개의 벡터로 표현할 수 있다.
오른쪽: 1개의 성분만 이용⇒ 데이터를 가장 잘 표현하는 평균으로 향하는 벡터를 만듦
활용

원본데이터셋

nmf 적용을 통해 얻은 25개의 feature set

pca와 비교했을 때 확연히 나은 결과!
코드
from sklearn.decomposition import NMF
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
%matplotlib inline
iris = load_iris()
iris_ftrs = iris.data
nmf = NMF(n_components=2)
nmf.fit(iris_ftrs)
iris_nmf = nmf.transform(iris_ftrs)
plt.scatter(x=iris_nmf[:,0], y= iris_nmf[:,1], c= iris.target)
plt.xlabel('NMF Component 1')
plt.ylabel('NMF Component 2')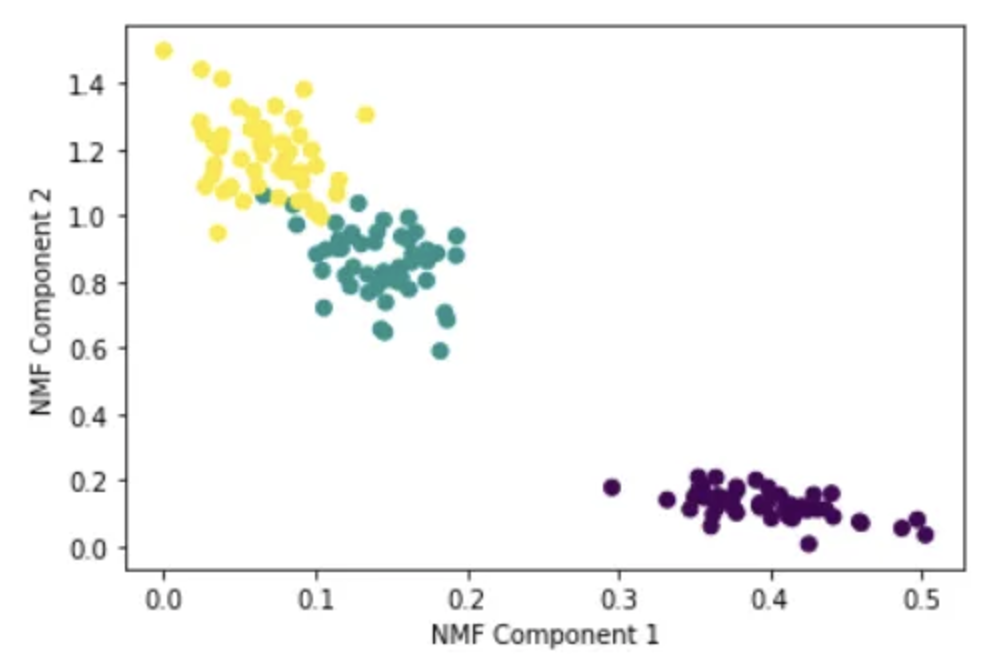
참고링크
https://angeloyeo.github.io/2020/10/15/NMF.html
https://woolulu.tistory.com/41
https://kolikim.tistory.com/28
https://velog.io/@mios_leo/파이썬-머신러닝-완벽-가이드-7.-Dimension-Reduction2-SVD-NMF

you're on your own kid, you always have been.