AudioLDM2: Learning Holistic Audio Generation with Self-Supervised Pretraining 논문 리뷰
Paper Review
Introduction
2023년 8월 CVSSP(Center for Vision, Speech and Signal Processing)와 Bytedance가 Audio Generation, 혹은 멀티모달(Multi-Modal) 영역의 SOTA AudioLDM2를 발표했다. 동해 1월에 등장한 AudioLDM을 이은 모델로 Latent Diffusion을 이용해 텍스트나 이미지 등 Multi Modal condition을 입력으로 받아 Audio를 생성한다. OpenAI에서 만든 DALL-E의 경우 Text-to-Image라는 TTI 모델로 텍스트를 입력받지만 AudioLDM2는 여러 도메인의 데이터를 입력으로 받아서 음성을 생성하기에 확장성 차원에서 높은 가치를 가진다.
Audio Generation은 기존의 TTS(Text-to-Speech)나 Music Generation을 포괄하는 개념으로 2010년대 후반이 되어서야 발전한 기술이다. 이 분야의 성장이 더디었던 이유는 크게 두 가지가 있는데 먼저 멀티모달 입력 데이터를 표현할 방법을 찾기 힘들었기 때문이다. “가고 있어요” 라는 문장을 음성화하는 TTS에서 “ㄱ”이라는 텍스트 토큰은 그대로 발음으로 맵핑될 수 있으나 “Soft whispers of a bedtime story being told”라는 문장 속 맥락을 음성화하는 경우에서의 “S”라는 단어는 쉽게 발음으로 맵핑될 수 없다. 맥락 정보를 잘 파악한 후 추상적인 방식의 모델링을 할 필요가 있었던 것이다. AudioLDM2는 LOA(Language-of-Audio)라는 개념을 도입해 입력 데이터를 효과적으로 표현하고자 했다. LOA는 의성어와 같은 개념인데, 이를 이용하면 “A dog barking” 의 상황을 모델링할 때 “왈왈왈 컹컹” 이라는 의성어로 입력 데이터를 토큰화할 수 있다.
Audio Generation은 일반화 가능성(Generalizability)의 차원에서도 한계점을 보였다. 기존의 TTS나 Music Generation, 혹은 Sound effect generation은 각각 Speech, Music, Sound effect라는 각기 다른 오디오 신호를 잘 생성하기 위해 모델의 구조를 해당 오디오 신호 생성에만 적합하게 설정하는 경향이 있다. 모델들이 귀납적 편향(Inductive bias)을 지나치게 많이 가지고 있었던 것이다. Audio Generation은 포괄적인 음성 생성, 즉 Speech나 Music 등 각기 다른 오디오 신호를 모두 효과적으로 생성할 수 있어야 하기에 Specialization이 아닌 Generalization에 초점을 두어야 한다. 이에 AudioLDM2는 서로 다른 음성 신호를 생성할 때에도 단일 생성 방식을 고수해 모델의 강건성(Robustness)을 높일 수 있었다.
Example
AudioLDM2를 이용해 모델링한 Audio Generation 예시는 여기에서 확인할 수 있다.
Model
Summary
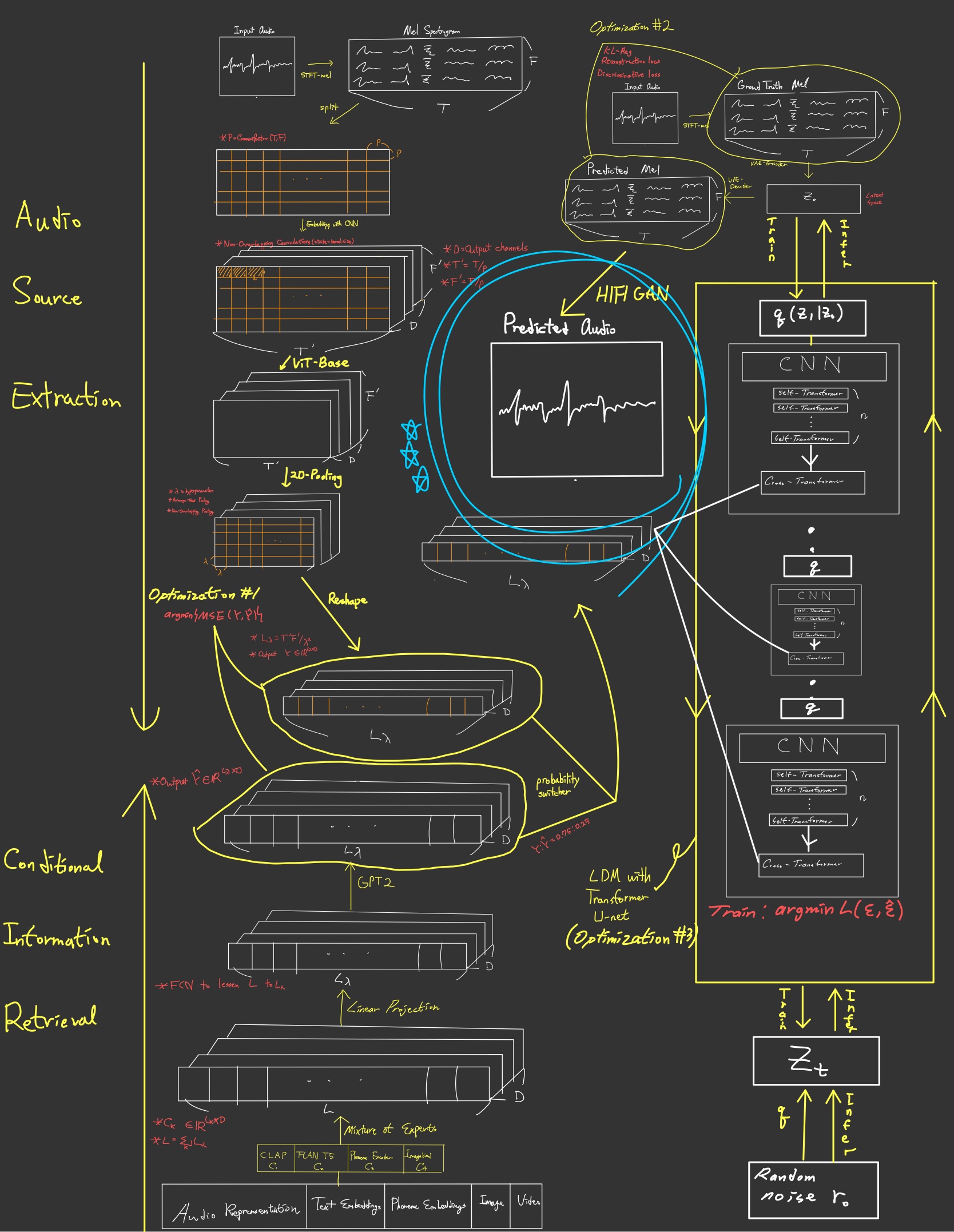
AudioLDM2는 입력 데이터를 LOA로 바꾸는 단계와 LOA로부터 음성을 생성하는 단계로 구성된다. 먼저 입력 데이터는 텍스트 데이터, 자막, 이미지, 영상 등 각종 멀티모달 데이터로 조건(Condition)을 나타내는 로 표현한다. 이 조건 데이터는 모드(Mode)를 나타내는 이라는 함수를 거쳐 LOA인 가 된다.
는 LOA를 생성하는 표현 학습(Representation Learning)의 일종으로 원본 LOA인 와의 차이를 줄여나가는 방식으로 학습한다. 이를 위해 원본 음성과 조건 데이터로 이루어진 쌍 데이터(paired data)를 준비한 뒤 AudioMAE(Audio Masked AutoEncoder)라는 사전 학습된 음성 인코더를 거쳐 만든 원본 LOA (는 AudioMAE를 나타냄) 를 만든다. 은 Mixture-of-Experts 기법과 GPT2를 조합하는 과정이고 이 과정을 거쳐 예측 LOA 역시 만든다. 이렇게 만들어진 두 LOA의 를 줄여나가는 방식으로 을 최적화해 LOA의 표현을 학습한다.
LOA로부터 음성을 생성할 때에는 아래와 같은 수식을 따른다. LOA였던 를 생성(Generation) 함수 에 넣어 원본 음성을 나타내는 를 만들 수 있다.
는 두 가지의 독립적인 단계로 이루어져 있는데 먼저 VAE(Variational AutoEncoder)를 이용해 오디오를 저차원 잠재 공간(Low-dimensional Latent space) 에 맵핑하는 과정과, 이렇게 만들어진 에 LDM(Latent Diffusion Model)와 HIFI-GAN(High Fidelity Generative Adversarial Network)를 이용해 원본 음성으로 합성해 내는 과정으로 이루어져 있다.
Semantic Representation learning with AudioMAE
What is MAE?
AudioMAE는 Audio와 MAE(Masked AutoEncoder)의 합성어로 CV 영역의 주요 기술인 MAE를 오디오 영역에 적용하기 위해 수정한 형태의 인코더이다. 이는 트랜스포머 구조를 기반으로 하여 오디오 데이터의 시간적, 주파수적 특성을 잘 파악할 수 있는 고성능 사전학습(Pretrained) 모델이다. <Masked Autoencoders Are Scalable Vision Learners> 라고 하는 논문에서 처음 제안되었던 MAE는 여타 AutoEncoder들과 다르게 데이터를 마스킹하여 인코딩 시 입력되는 데이터의 사이즈를 크게 줄여 효율적인 학습을 가능하게 해 효과적인 Encoding을 성공적으로 수행하였다.
이 글에서는 Masked learning과 Autoencoding의 개념을 설명하지 않는다.
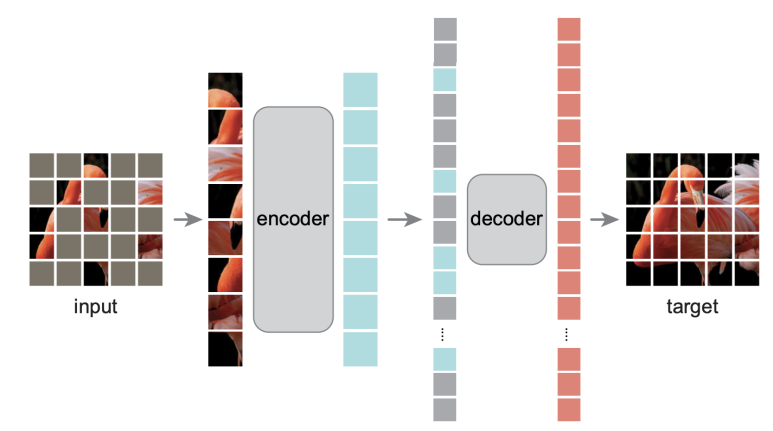
MAE의 모델 구조는 위와 같다. 먼저 입력 이미지를 특정 비율(masking ratio)로 마스킹한다. (논문에서는 마스킹 비율로 75~80%를 사용한다. ) 마스킹된 이미지를 제외하고 남아있는 원본 픽셀들만을 Encoder에 넣는데 이때의 Encoder 구조는 Vision-Transformer(ViT)인데 입력 픽셀들이 Masking되지 않고 남아 있는 부분들만 있다는 점에서 차별점이 있다. ViT는 2021년 공개된 <An Image is worth 16X16 words: Transformers for image recognitions at scale> 논문에서 제시한 Transformer encoder 구조로 MLP with resnet, Positional Embedding 등의 부분에서 일반적인 Transformer와 비슷하다. (참고로 Linear Projection은 FCN이다)
MAE는 Encoding 시 masking 된 부분은 삭제하고 나머지 부분(masking ratio가 75%라면 25%)만 입력 데이터로 활용한다. Transformer 기반의 대규모 모델을 적은 데이터양으로 학습시킬 수 있다는 점에서 연산속도 차원에서 굉장히 큰 이점이 있다.
이렇게 Latent Space에 맵핑된 입력 데이터는 마스킹되었던 75%의 mask tokens와 결합(concat)된 후 positional embedding이 더해져 Decoding 셀에 입력된다. Positional Embedding을 더하는 과정을 통해 어느 위치에 마스킹이 되었는지를 파악할 수 있게 된다. Decoding 역시 여러 개의 Transformer 블럭으로 이루어져 있다. Decoding의 목적은 Latent Space에 맵핑된 정보들과 마스크 토큰을 바탕으로 원본 이미지를 재건(Reconstruction)하는 것이다.
MAE의 모델 구조에 Encoder과 Decoder가 있지만 학습 후 궁극적으로는 Encoder만을 활용할 것이기 때문에 Decoder가 좋은 성능을 낼(원본 이미지를 완벽히 재현할) 이유가 그리 크지는 않다. Encoder보다 훨씬 dimension도 작고 층의 개수도 적은 Transformer 블럭을 활용해서 굉장히 경량화된 모델 구조를 이용하는 것이 MAE의 디코더이다. 논문에 따르면 Decoder는 Encoder에 비해 약 10%도 안되는 크기라고 한다.

What is AudioMAE?
AudioMAE는 AudioLDM2내의 과정의 에 해당한다. CV 영역의 MAE를 오디오 영역에 적용하기 위해서는 Mel Spectrogram 형태의 2차원 오디오 데이터가 일반적인 2차원 이미지 데이터와 어떠한 점에서 차이가 있는지 살펴보아야 한다.
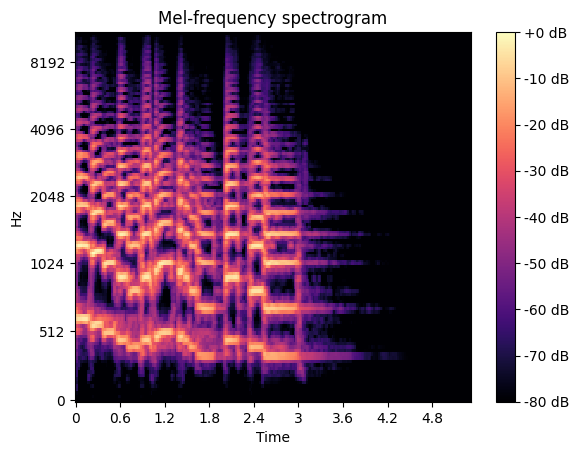

두 2차원 데이터를 비교해 보면 2차원 오디오 데이터의 도드라진 특성을 찾아볼 수 있다. 오디오 데이터는 x축으로 표현된 시간축과 y축으로 표현된 주파수축 방향으로 굉장히 높은 상관관계를 가진다. 시간축으로의 상관관계는 특히 텍스트에서 두드러지는데 발화와 휴지가 교차한다는 것과, STFT 적용 시 매 window를 옮길 때마다 25%씩 중복 연산되는 데이터 부분이 있다는 것 때문이다. 주파수축 방향으로의 상관관계는 자연음이 기본음과 고조음으로 이루어진 배음(Harmonics) 구조를 가지기에 존재한다. 배음 구조는 위 Mel Spectrogram에서 찾아볼 수 있는데 같은 패턴의 음색이 배수 형태로 반복되는 것을 확인할 수 있다.
Masking
마스킹하는 방식은 기존의 MAE와 같다. 음성을 10초 단위로 랜덤 샘플링한 뒤 이를 128개의 Mel bands를 가지는 Mel Spectrogram으로 만들어 준다. 이렇게 만든 Mel Spectrogram은 격자(grid)를 기준으로 구역이 나뉘게 되고 각 구역의 위치 정보를 부여하기 위해 Positional Embedding을 sinusoidal 하게 수행한다(여기는 BERT와 같다). 각 위치별로 나뉜 구역들 속 이미지를 patch라고 부르는데 모든 patch를 1차원 평면 상에 나란히 나열한다. 즉 2차원 이미지를 좌우로 나란히 나열해 구역 번호에 따라 1차원으로 정렬(flatten)하는 과정이라 보면 된다. 이렇게 flatten된 데이터는 linear projection, 즉 FCN을 거쳐 embedding된 후 위에서 만든 positional embedding과 더해진다. 이렇게 만들어진 embedding 중 특정 patch들만 masking해 삭제하게 되는데 이때의 masking 기법은 Unstructured masking과 Structured masking으로 분류할 수 있다.
Unstructured masking은 Time, Frequency 축 관계없이 무작위하게 patch를 골라 masking하는 것이고 아래 그림 속 (c), (d), (e)에 해당하는 Structured Masking은 시간축만 masking하거나 주파수 대역만 masking하는 방식으로 masking하는 것이다.
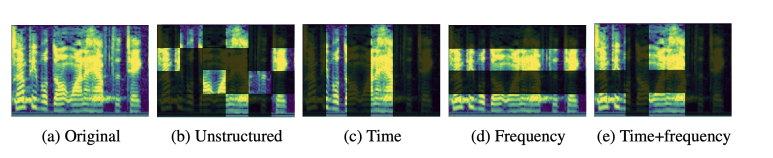
BERT나 GPT는 15%의 masking ratio를, CV 영역의 MAE는 75%의 masking ratio를 설정했다. 하지만 오디오 데이터는 시간축, 주파수축 어느 쪽으로도 패치들이 굉장히 큰 양의 상관관계를 가지기에 80%라는 다소 파격적으로 높은 masking ratio로 마스킹할 때 가장 높은 성능을 보였다. 또한 Structured Masking보다 Unstructured Masking이 성능이 훨씬 높았는데 이는 masking된 패치를 재건(reconstruction) 하는 self-supervised task 내에서 시간축과 주파수축을 모두 참고할 때 패치 재건이 훨씬 쉽기 때문이다.
AudioMAE에서 사용하는 마스킹은 두 가지 장점이 있는데 (1) 마스킹된 패치를 제외하고 남아 있는 패치들만을 인코딩하기에 input sequence의 길이를 줄여 학습 효율을 증가시킬 수 있고 (2) 적은 양의 입력 패치를 바탕으로 원본 mel spectrogram을 재건해야 하기 때문에 global, contextualized representation을 학습할 수 있다.
Attention
AudioMAE의 디코더 attention을 모델링하는 방식은 CV의 MAE와는 많이 다르다. CV의 MAE의 transformers는 Scaled dot-product attention이라고 하는 global context self-attention의 일종을 사용한다. 이 attention 기법을 선택한 것은 이미지를 다루는 주요 inductive bias 중 하나인 translation invariance, position invariance 성질 때문이다. 이미지에서 강아지의 위치를 조금 이동한다 해도 이미지의 고유 특성(강아지)는 사라지지 않는다.
하지만 오디오는 translation-variant, position-variant하다. Speech 데이터라고 해 보자. 이 세상 어떤 자연음이든 기본음과 고조파의 Harmonics로 이루어져 있다. 고음역대의(high-frequency) mel spectrogram을 예측할 때는 기본음의 구조를 그대로 정수배하는 방식이 합리적이다. 이렇게 오디오와 같이 시간, 주파수 정보의 위치(locality)가 중요한 데이터는 translation이나 position shift에 취약하다. 이 문제를 해결하기 위해 AudioMAE에서는 local context self-attention 중 하나인 shifted window self-attention을 이용한다(Swin-Transformer에서 처음 제안되었다). 이는 25ms라는 window 내에서만 attention을 연산하고자 하는 방식이다. 이외에도 global context를 고려하기 위해 동일 형태로 구성된 decoder transformers(논문에서는 16개의 층을 쓴다)들 중 전반부에는 shifted window self-attention을 적용하나 후반부에는 일반적인 global self-attention을 넣었다. 두 형태의 attention을 모두 적용하는 방식을 Hybrid Attention이라고 한다.
Semantic Representation Learning
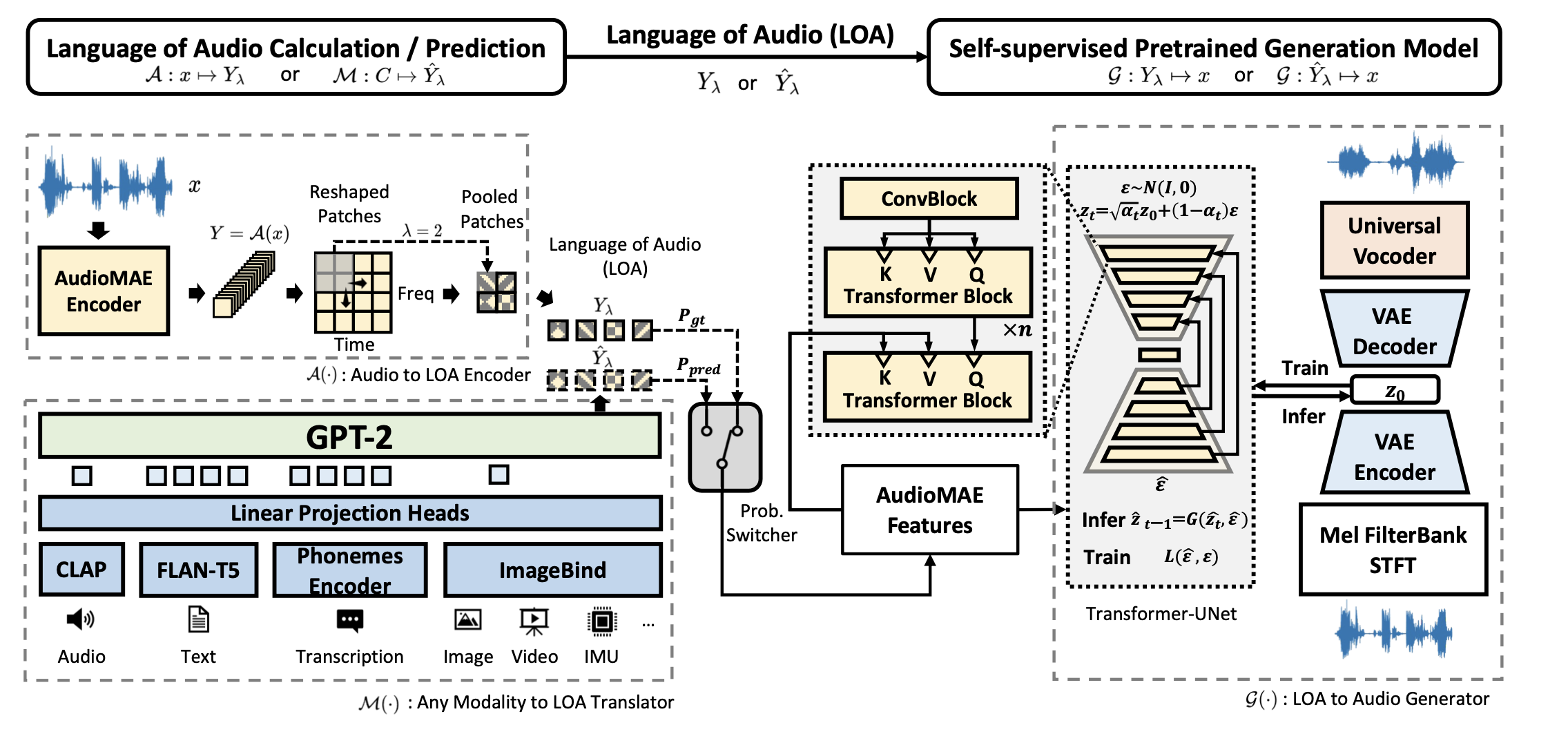
마스킹→예측의 과정을 반복하며 Self-Supervised Learning 방식으로 Encoder와 Decoder를 동시에 학습한 뒤 Encoder 부분만 남은 AudioMAE는 데이터의 의미를 효과적으로 표현할 수 있게 된다. 이렇게 학습된 AudioMAE를 가지고 를 모델링하는 과정은 다음과 같이 설명할 수 있다.
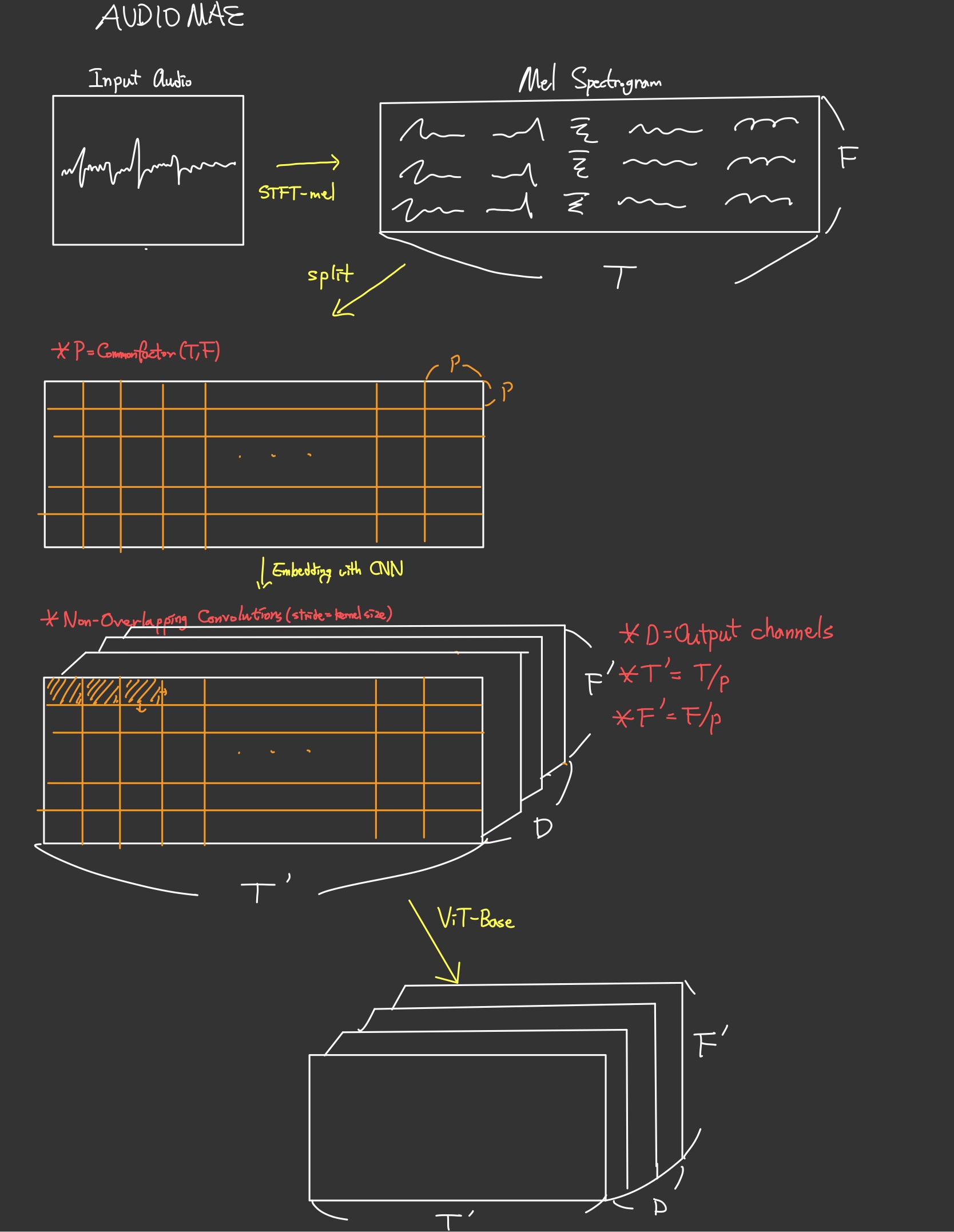
(1) 먼저 입력 음성 데이터를 Mel Spectrogram으로 만든다. 이렇게 만들어진 음성 데이터 은 시간축의 개수인 와 주파수축의 개수인 으로 이루어진 2차원 데이터이다.
(2) 넓이가 인 정사각형 형태의 patch로 Mel Spectrogram을 구역화해 준다. 이때 P는 와 의 최대공약수이다.
(3) 이렇게 구역화된 Patches에 Positional Embedding을 CNN으로 수행해 준다. 이때 stride와 kernel size를 같게 하여 CNN 연산이 한 데이터에 중복 연산되지 않도록 한다. 이때 는 CNN의 output channel의 개수이다.
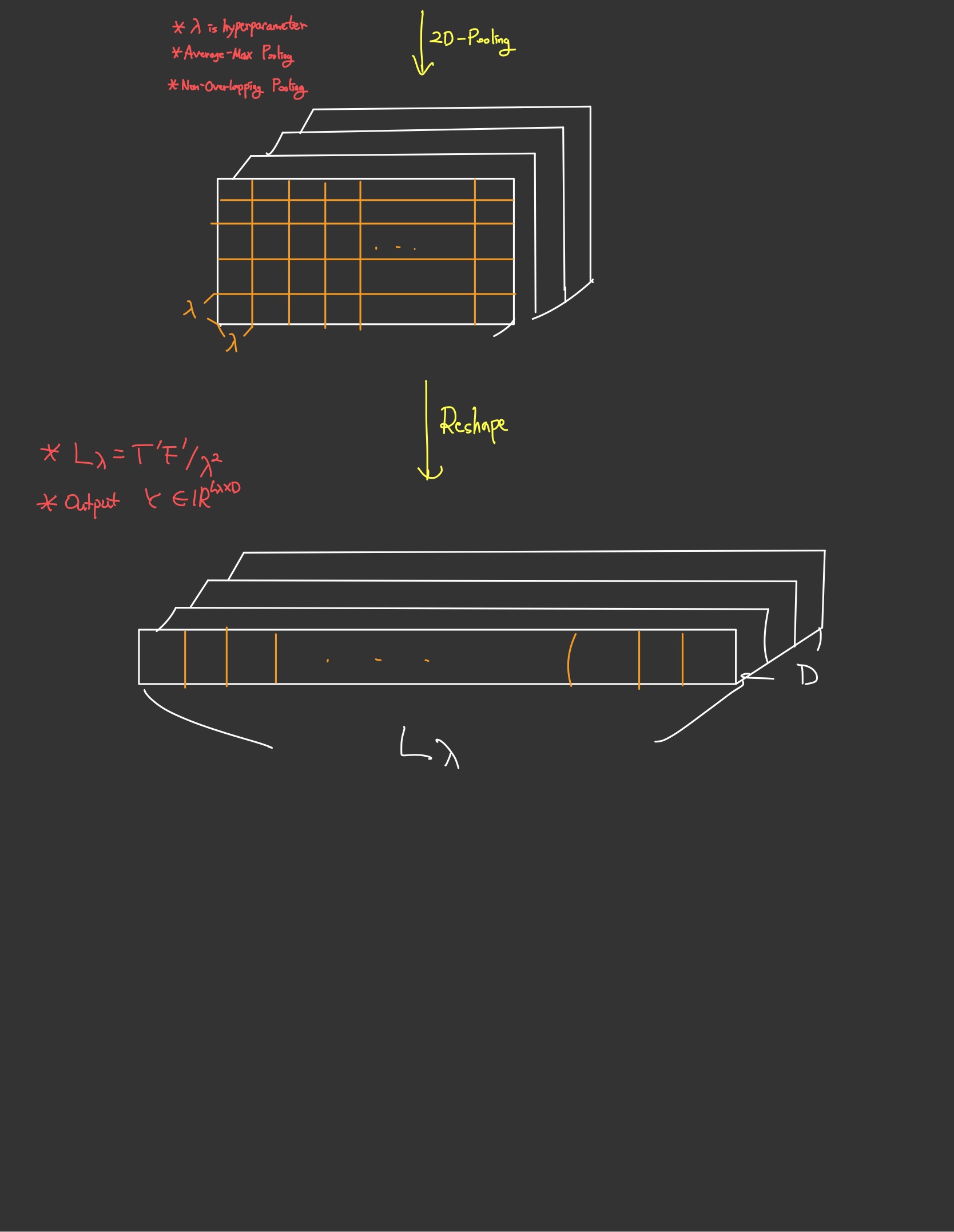
(4) 여기에 사전학습된 AudioMAE의 ViT를 거쳐 Semantic Representation을 만들고 데이터 크기를 만큼 줄이기 위해 2D-Pooling을 수행한다.
(5) 마지막으로 이 데이터를 Reshape해 1차원 시계열 데이터로 바꾸어 준다.
이 과정을 도식화하면 아래와 같다.
이렇게 만들어진 Semantic Representation이자 LOA인 는 이후부터는 와 구분하지 않는다. 는 정답 레이블(ground truth) 오디오를 표현한 것이므로 본질적으로 생성 모델인 AudioLDM2 특성상 배포 과정에서 사용하는 것이 아니라 학습 과정에서 사용한다. 배포 시에는 텍스트 입력, 이미지 데이터 등 만을 이용하기에 본 논문 리뷰의 다음 장에서 설명하는 과정을 통해 나온 예측 LOA 의 현실성을 높이기 위해 비교 학습에 사용될 뿐이다.
Conditional Audio Semantic Language Modeling
Mixture of Experts
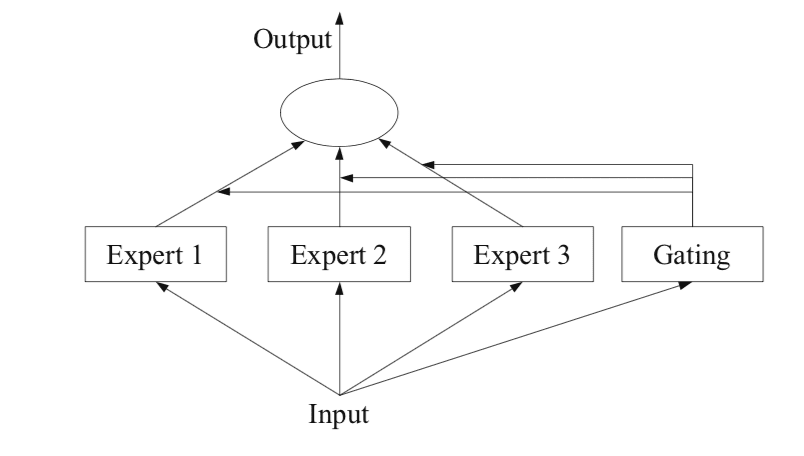
이 장에서는 예측 LOA를 만들기 위한 과정을 소개한다. 텍스트나 이미지 데이터를 바탕으로 LOA를 만들 때에는 서로 다른 영역의 Representation을 잘 수행할 수 있는 사전학습된 Multi-Modal 모델들을 차용한다. 과정을 모델링할 때에는 Mixture of Experts라는 기법을 사용하는데 이 기법은 다양한 Multi-Modal 모델들을 통해 인코딩된 의 결과값을 합쳐서 활용하는 앙상블의 일종이다. 여러 명의 전문가(사전학습된 Multi-Modal 모델)들이 합쳐 최선의 결과를 만들기 위해 노력하는 것과 같다. 이렇게 합쳐진 결과값은 최종 전문가 격인 GPT-2에 입력되어 최종 예측 LOA를 만든다. GPT2는 이 과정의 최종 결재를 내리는 총책임인 셈이다. 이 모델링에 사용된 다양한 전문가들을 소개한다.
LAP: contrastive language and audio pretraining
2023년에 제안된 Language-Audio 모델 CLAP은 오디오와 텍스트 간 결합 임베딩 공간을 학습하여 음성 신호와 언어의 발음적 유사성이 클 때 임베딩 공간에서의 거리 역시 가까워지게 학습시킨 사전학습 모델이다. AudioLDM에도 활용된 바 있으며 각종 TTS 모델의 인코더로서 활용된다.
FLAN-T5
CLAP이 발음적 유사성에 기반한 임베딩 공간에 대한 표현을 효과적으로 수행하지만, 시간적 유사성에 기반한 인코딩 능력은 부족하였기 때문에, 대규모 언어 모델 T5를 발전시킨 FLAN-T5를 기용하였다.
Phoneme Encoder
음성 분리의 가장 작은 단위인 음소(Phoneme) 단위로 인코딩을 수행하는 Phoneme Encoder는 TTS 영역의 SOTA 모델 중 하나인 NaturalSpeech에 기용된 Encoder이다.
ImageBind
이미지, 텍스트, 오디오, 영상 등 굉장히 많은 도메인의 데이터의 결합 임베딩 공간을 학습하는 모델로 그 범용성이 매우 뛰어나다.
사전학습 전문가 모델들의 가중치는 변치 않는다. 이런 4개의 모델 를 바탕으로 를 모델링하면 네 개의 인코딩 결과값이 생긴다.
이 결과값을 전부 가로로 합치면(Concatenate) GPT2를 거치기 전 최종 결과값 를 다음과 같이 얻을 수 있다.
Concatenation
이렇게 만들어진 는 FCN을 거쳐 길이를 조정한 뒤 사전학습된 GPT2를 거쳐 예측 LOA를 만든다. 이 GPT2의 가중치는 다른 전문가 모델들과 다르게 학습 가능하다.
이 과정을 도식화하면 아래와 같다.
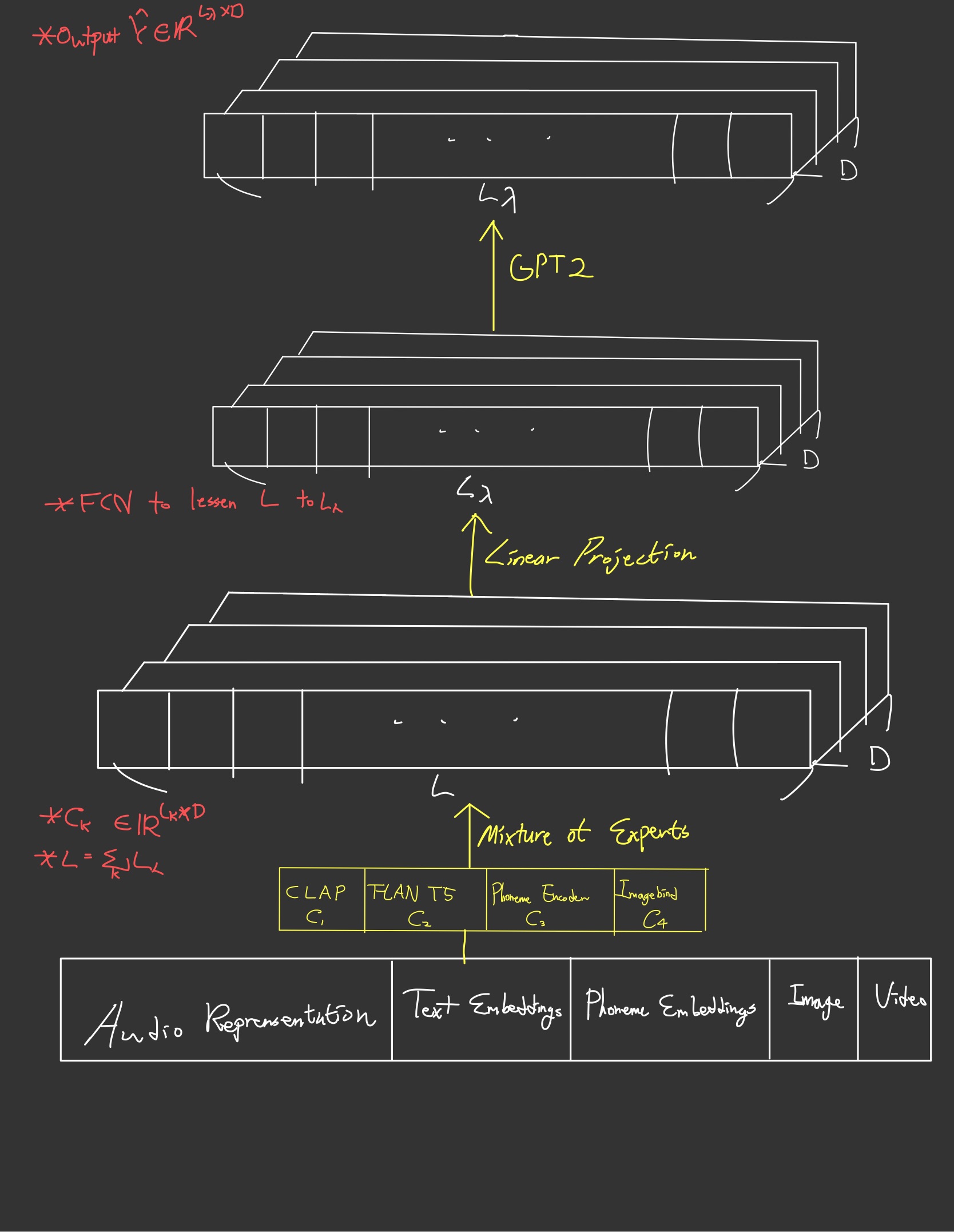
이제 예측 LOA 를 실제 LOA 와 비슷하게 만들어주면 LOA의 표현 학습(Representation Learning)을 수행할 수 있게 된다. 이를 위해 목적 함수와 손실 함수를 각각 아래와 같은 순서로 제작할 수 있다.
Semantic Reconstruction with Latent Diffusion Model
이제는 생성된 예측 LOA 를 바탕으로 오디오 신호를 생성할 차례이다. 생성 과정을 요약하면, VAE를 학습시켜 Diffusion을 수행할 잠재 공간 를 만들고, 이 에서 LDM(Latent Diffusion Model)과 Transformer U-net을 결합하여 음성 신호를 모델링한다.
이 과정은 LOA 로부터 음성 신호 를 만드는 생성(Generation) 과정이므로 아래와 같은 함수로 표현할 수 있다.
Acoustic Representation Learning with VAE
잠재 공간 는 고차원 정보인 오디오 신호를 적절하게 차원 축소한 공간이다. 이 잠재 공간을 도입함으로서 연산량을 줄일 수 있었기에 자기회귀적(Autoregressive)으로 수행되어 그 병렬 가능성이 낮은 Diffusion 모델의 단점을 극복할 수 있었다. 저차원 잠재 공간 는 VAE(Variational AutoEncoder)를 통해 만든다.
VAE는 인코더와 디코더로 구성되어 있는데 인코더는 입력 데이터를 저차원 잠재 공간 로 맵핑하고 디코더는 이 정보를 다시 원본 데이터로 재구성한다. Self-Supervised Learning이 가능한 이 VAE를 바탕으로 저차원 특징 벡터인 Acoustic Representation을 만들기 위해서는 원본 음성인 를 VAE로 학습시켜 생성한 와의 를 낮추기 위해 학습한다. 이 과정을 통해 생성된 사전학습(Pretrained) 모델을 AudioLDM2에서 활용한다.
LOA to Audio Generation with Latent Diffusion Model
VAE를 거쳐 원본 음성을 변형한 데이터를 이라고 하자. 이제 Diffusion 적용해 를 모델링하면 된다. 학습 과정에서는 이렇게 노이즈를 더해나가는 순방향 과정(Forward Process)와 노이즈를 빼는 역방향 과정(Reverse Process)가 같은 구조로 이루어진다. 한 스텝의 과정은 다음과 같은 두 단계로 이루어진다.
- 노이즈를 더한다(Forward Process) / 뺀다(Reverse Process)
- Transformer U-net을 거친다.
이 두 단계를 순차적으로 수행하면 하나의 스텝이 완성되고 순방향 과정을 예로 들면 총 스텝을 거쳐 데이터를 등방향 정규 분포(Isotropic Gaussian Distribution)로 만든다.
Transformer U-net은 AudioLDM에 활용된 U-net을 발전시킨 구조로, U-net 구조와 동일하게 축소(Downsampling) 기능을 하는 Encoders와 확대(Upsampling) 기능을 하는 Decoders로 이루어진다. Skip Connection 역시 존재한다.
매 Encoder & Decoder 마다 축소나 확대 기능을 수행하기 위해 CNN을 활용하는데 성능을 향상시키기 위해 매 CNN 블럭 연산이 끝날 때마다 개의 transformer 블럭을 삽입하였다. 매 Encoding & Decoding 스텝마다 개의 self-attention과 1개의 cross-attention으로 이루어진다. cross-attention은 key와 value로 LOA에서 생성된 를 입력으로 받는데, 이는 Classifier Guidance가 없는 AudioLDM2의 Diffusion 모델링 방식 특성상 사용자가 입력한 프롬프트(텍스트, 이미지 등)에 알맞는 Diffusion 방향을 설정하는 매우 중요한 연산이다.
하나의 Encoding & Decoding 스텝은 아래와 같은 구조로 도식화할 수 있다.

학습 과정에서는 이렇게 두 단계로 이루어진 순방향 과정(Forward Process) Diffusion step을 차례 거쳐 등방향 정규 분포(Isotropic Gaussian Distribution) 를 만들고, 다시 역방향 과정(Reverse Process)을 차례 거쳐 원본 잠재 벡터 을 근사하게 해 유사도를 계산하는 방향으로 학습한다.
추론 과정에서는 역방향 과정(Reverse Process)만 수행하면 되기에 잠재 공간 내 정규 분포 벡터 를 만들고, 매 스텝마다 일정량의 노이즈를 제거해주면서 잠재 벡터 을 근사한다. 생성된 잠재 벡터는 사전학습된 VAE를 거쳐 원본 Mel로 바뀌고, 이 원본 Mel이 사전학습된 보코더 HiFi-GAN에 입력되어 음성을 생성하게 된다.
Conclusion
AudioLDM2는 단일 모델로 LOA(Language-of-Audio)라는 개념을 도입해 TTS(Text-to-Speech), TTM(Text-to-Music) 등 여러 오디오 생성 임무를 수행할 수 있다는 점에서 굉장히 강건한(Domain-Robust) 모델이다. 또한 모델 학습 시 자기주도학습(Self-Supervised Learning)을 적극 활용할 수 있다는 점에서 그 활용성 또한 주목받을 수 있다.
Summary
AudioLDM2를 요약해 보았다. 학습 과정과 추론 과정으로 나누어 설명하였다.
Training
LOA prediction
‘프롬프트-오디오’의 짝지은 데이터를 준비한다. 프롬프트를 Mixture of Experts 기법과 GPT2를 이용해 예측 LOA 로 만든다. 오디오를 AudioMAE를 활용하여 원본 LOA 를 만든다. 이 둘의 오차를 줄이기 위해 AudioMAE와 GPT2를 학습시킨다. 이 학습 과정을 (1)로 지칭한다.
위 과정을 통해 생성된 와 를 각각 0.75, 0.25의 비율로 가중합해 오디오 생성을 위한 조건 정보(Conditional Information)을 만든다.
Audio Generation
‘프롬프트-오디오’의 짝지은 데이터에서 오디오를 Mel Spectrogram 형태로 변환하고 이를 사전학습된 VAE를 이용해 저차원 특징 벡터로 맵핑한다. 위에서 생성한 LOA 조건 정보를 Query로 받는 Transformer U-net을 포함하는 Diffusion을 학습한다.
Inference
LOA prediction
프롬프트를 준비한다. 프롬프트를 Mixture of Experts 기법과 GPT2를 이용해 예측 LOA 를 만든다.
Audio Generation
등방향 가우시안 분포(Isotropic Gaussian Distribution)을 따르는 랜덤 노이즈로부터 를 query로 받는 Transformer U-net 을 포함하는 Diffusion을 거쳐 Mel Spectrogram을 만든다. 이렇게 만들어진 Mel Spectrorgam은 사전학습된 HIFI-GAN 을 거쳐 음성을 생성해 낸다.
아래는 모델의 구성을 개괄한 그림이다.