Paper Review: Are all negatives created equal in contrastive instance discrimination?
Paper Review
Paper
Are all negatives created equal in contrastive instance discrimination? (arxiv preprint, 2020)
Link
https://arxiv.org/abs/2010.06682
Introduction
Contrastive learning (CL) aims to design a method of mapping images of different labels onto a latent space. The key aspect of CL lies in maximizing the distance of the latent vectors of images of different labels, while minimizing the distance of the latent vectors of images of the same labels.
The sampling of negative samples is a very important research topic in CL due to many reasons such as False Negatives, where deeming other image as a negative does not always mean the different labels, which have shown a very promising performance degradation in many scenarios.
This paper focuses on the difficulty of the negative samples when put on a latent space. Say, an ignorant kid can easily tell between a tree and a tiger. He or she would not much from telling betwen those two objects. However, it takes a significant amount of effort to tell between a Leopard and a Jaguar. You will learn much from telling between those two images.
As illustrated in the above metaphor, it is important that hard negatives are selected for training a instance discrimination task to build a model with high performance.
Findings
The paper has shown three properties of negatives, which is illustrated in the figure below.
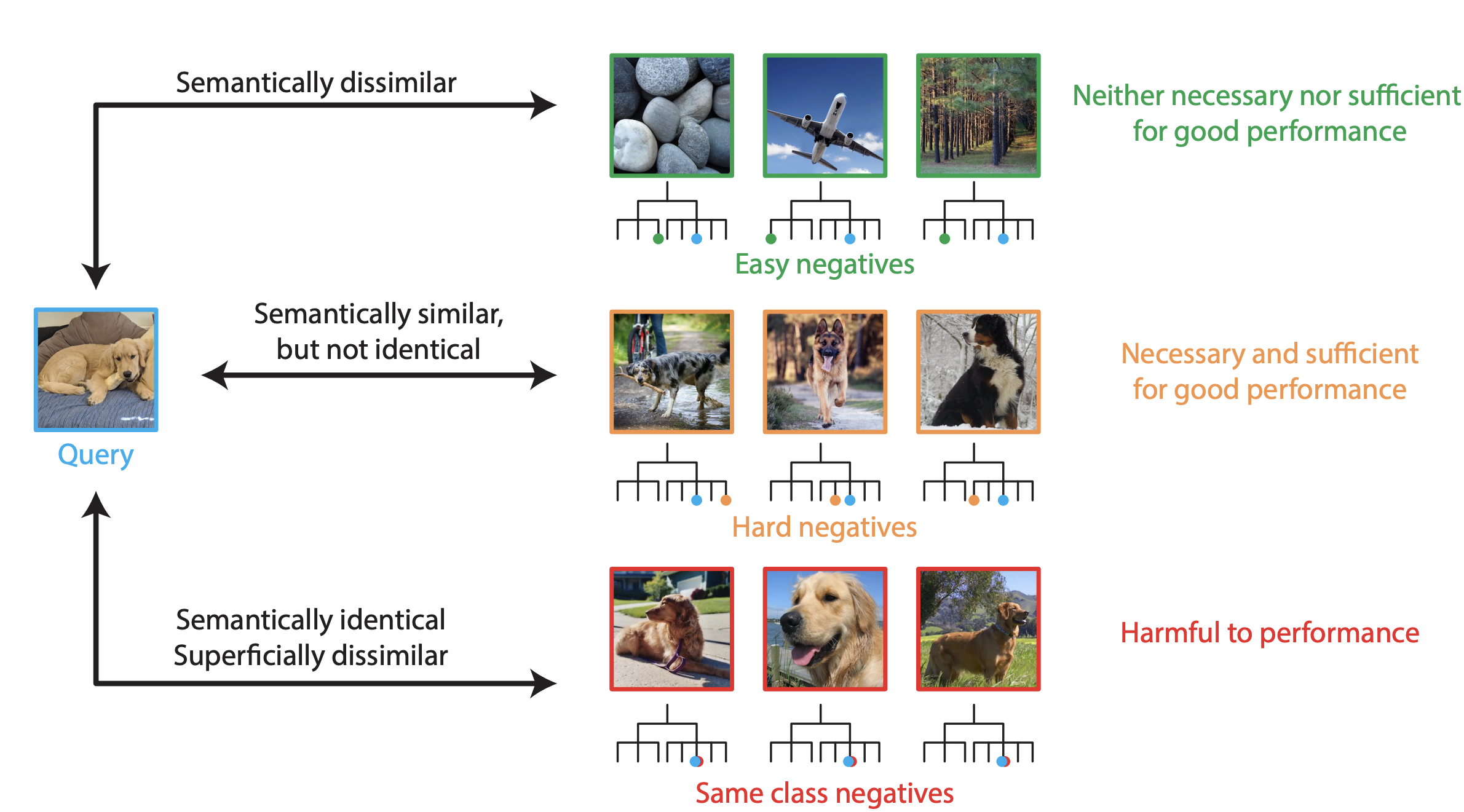
1. The easiest 95% of negatives are unnecessary and insufficient, while the top 5% hardest negative are necessary and sufficient.
You can use only the top 5% hardest negative for CL. It not only helps the model to perform better but lower the computational costs by neglecting the easy samples for negatives.
2. The hardest 0.1% of negatives are necessary and sometimes detrimental.
Well, this finding is very consistent with the intuition behind False Negative Cancellation (FNC). As you can see from the experimental results below, removing 0.1% hardest has the same impact of removing same class.
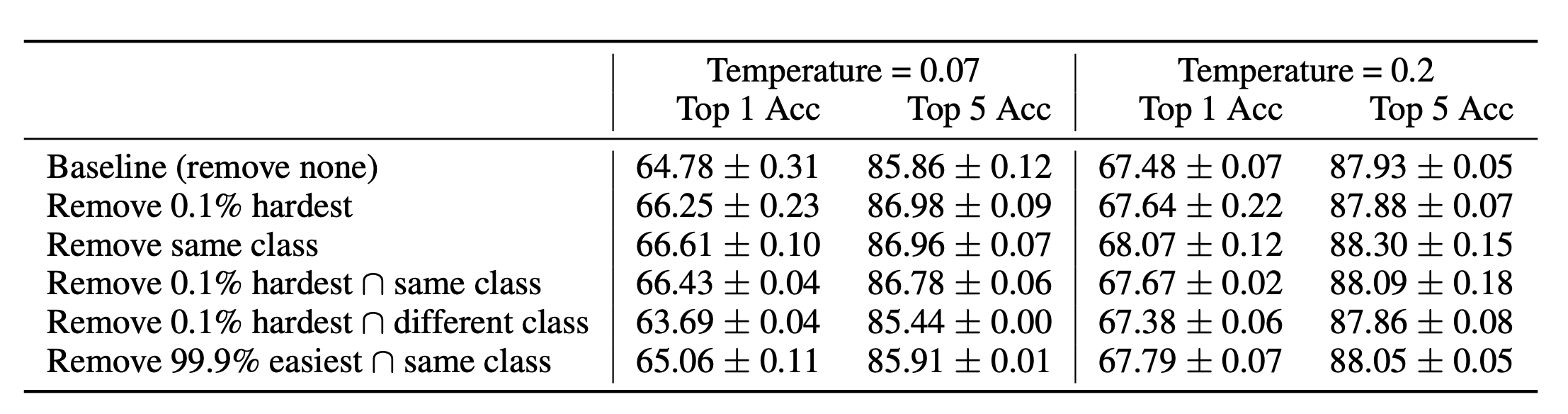
However, it is not always the case that 0.1% hardest is on the same page to the performance with FNC. It is notable that "Remove 0.1% hardest in different class" actually had detrimental effect on performance.
Whether the negative sample is in the same class or not, the hardest 0.1% actually worsens the training.
3. Some of the easiest negatives are both anti-correlated and semantically similar to the query.
As the difficulties of the negatives are computed through the cosine similarity of the latent embeddings between an anchor and a negative sample, the range is from -1 (the negative orthogonal) to 1 (identical). Some of the easiest negatives (cosine similarity around -1) actually had labels that are semantically similart to the query. Here, semantic similarity is computed through the wordnet similarty of the labels to mean the hierachy in the word tree.
A poodle and a golden retriever are both a dog, retaining the high semantic similarity. They might score the cosine similarity around -1.
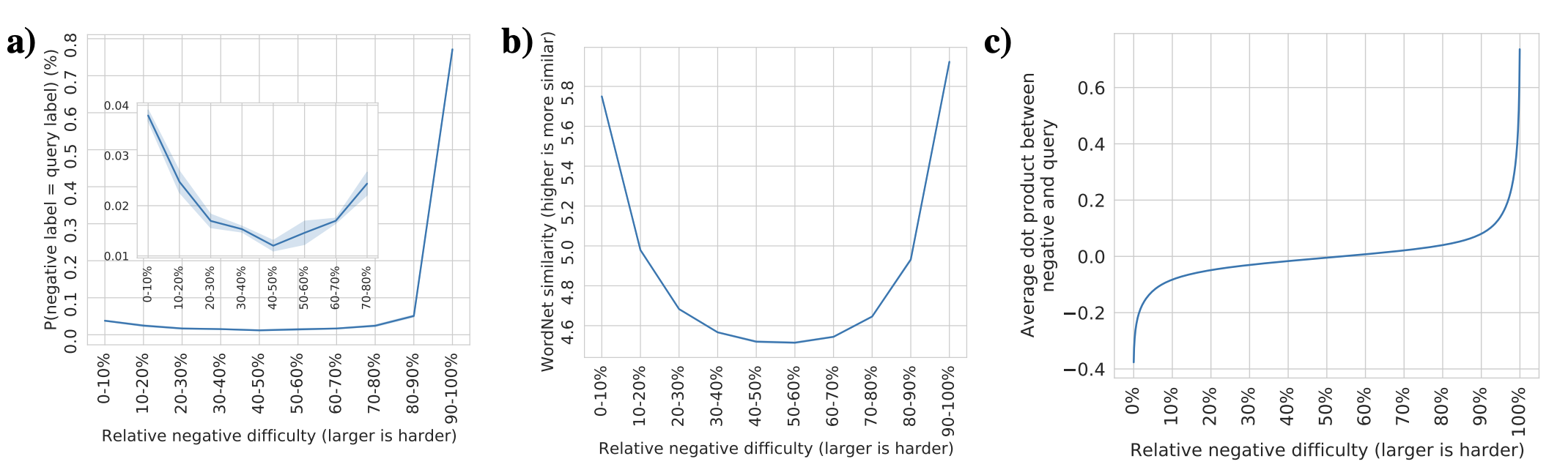
As you can see from the Figure b), semantic similarity (y-axis) is high in both easy (cosine similarity around -1) and difficult (cosine similarty close to 1).
The more interesting fact is that from figure c), you can see that the distribution of the cosine similarity is not uniformly distributed in span of -1 and 1. Most values are around -0.2~0.2, and only the subset of the similarity is above or below that range.
Outro
The questions I think need to be solved is that, the contrastive-learned latent space embeddings are used for the measure of the similarity here, which is also the objective of the Contrastive Instance Discriminative learning. The chicken-and-egg problem still persists in the context. If further researches focus on providing an ad-hoc and simple methods of measuring the hard samples from the easy ones, the paper could make its full use of applications in various fields.
Well, there are more experiments that the author provided, which are very interesting. A lot of findings are omitted for the sake of simplicity of explanation. You can find more information through reading the original paper.
