HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis 논문 리뷰
Paper Review

논문 리뷰를 마음속으로만, 노트 필기로만 하고 velog 등에 올리는 것이 귀찮아서 좀 안했었다. 하지만 이제부터라도 꾸준히 논문 리뷰를 하고, 이전에 읽었던 것들 혹은 새로이 읽게되는 것들에 대해 리뷰성 글들을 꾸준히 작성해 보아야겠다.
오늘 리뷰하는 논문은 Kakao에서 나온 HiFiGAN으로 2021년 NeurIPS에 accept 되어 지금까지 Vocoder 부문 SOTA를 지속적으로 달성하고 있는 모델이다. TTS 분야의 SOTA Fastspeech 2, Speech Super Resolution 분야의 SOTA NVSR 모두 HiFiGAN 을 이용한다. 참으로 대단한 논문이다.
Summary
GAN을 생성 베이스라인으로 삼아 만들어진 Fully convolutional network이다.
Model
Generator
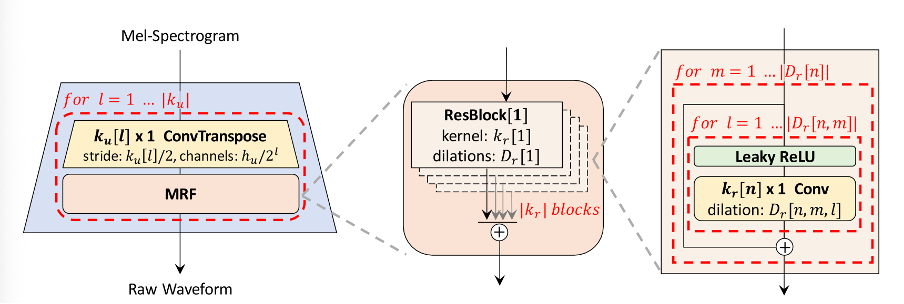
Generator는 복잡하게 생겼으나 이해하면 상당히 간단하다. Transposed Convolution과 MRF가 순차적으로 연결되어 있는 것이 upsampling ratio에 따라 반복된다.
Transposed Convolution은 Input인 Mel Spectrogram을 Output인 Wav로 만들어주기 위해 time sequence의 길이를 upsampling 해주는 역할을 한다. 이 과정에서 input hidden dimension을 1/2 배 해주는 것이 마치 U-net의 Upsampling 부분과도 유사하다. 이는 마치 Vision Transformer에서 초기 convolutional embedding을 만들어주듯, pattern recognition 관점에서 의미가 있다기 보다는 upsampling 의 역할만 충실히 해줄 뿐이다.
MRF (Multiple Receptive Field Fusion) 은 여러 Receptive field로 input sequence의 패턴을 파악하고 이들을 계속 더해 다양한 pattern을 학습할 수 있게 한다. MRF에는 kernel size가 각각 3, 7, 11 이면서 dilation rates가 각각 1, 3, 5 인 Convolution Block들이 존재한다. 즉 총 9개의 Block이 있는 것이다. 이를테면 kernel size = 11, dilation rates = 5인 block이면 receptive field가 매우 커 long-term dependency를 shallow하게 파악하는 모듈일 것이며, kernel size = 3, dilation rates = 1인 block이면 short-term dependency를 dense하게 파악하는 block일 것이다. 이 구조가 Generator의 핵심으로, Transposed Convolution만 이용한 generation이 연산 과정 특징상 generated sample의 continuity를 보장하지 못하고 metallic 하거나 noise가 끼는 등 artifacts가 많이 발생한다는 점에서, 이 불완전한 upsampling 과정을 보완해준다는 점에서 굉장히 의미가 깊다.
한편, MRF에서 dilation rates와 kernel size를 바꾸어 가며 audio data의 패턴을 파악하는 것은 2015년 초기 neural vocoder의 하나인 wavenet에서 그 초시를 제안한 바 있다,. Receptive field를 키우기 위해 kernel size를 늘리는 데에는 파라미터 개수와 efficiency 차원에서 한계가 있기 때문에 Dilation 을 적절히 활용하면 receptive field를 효율적으로 늘릴 수 있다.
Discriminator
HiFi GAN의 또다른 breakthroughs는 Discriminator에 있다. Discriminator 는 MPD (MultiPeriod Discriminator)와 MSD (Multi Scale Discriminator)두 개로 이루어져 있는데, 필자가 생각하기에, generator의 MRF보다도 더욱 대단한 부분은 MPD에 있는 것 같다. 따라서 MPD 먼저 설명하겠다.
MPD
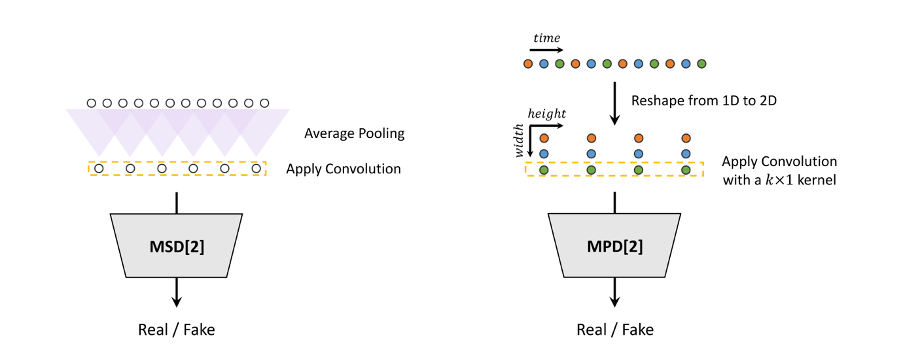
Multi-Period Discriminator는 generated samples인 1D audio waveform을 2D로 reshape한다. 이후 Reshaped 된 2D image에 2D Convolution 을 반복적으로 적용해 Real/Fake를 구분하는 것이 특징이다. (Vision Transformer에서 2D 였던 Input image가 1D로 바뀌는 것과 비슷한데 그 변환 방향이 반대라는 것이 특징이다.)
다양한 패턴을 파악하기 위해 reshape할 때 행의 개수를 소수 (prime numbers) 로 맵핑한다. 이는 2D Convolution 연산 특징상 행의 개수가 배수인 것들이 있으면 computation이 overlap 될 것이고, 이는 Overfitting 관점과 efficiency 관점에서 모두 바람직하지 않기 때문이다.
MSD
Multi-scale Discriminator는 MelGAN (Kumar, 2019, NeurIPS) 의 것을 그대로 차용했기에 말을 많이 덧붙이지 않겠다. 다만 Low-frequency pattern, (Low + Mid ) frequency pattern, Full frequency pattern을 파악할 수 있는 각기 다른 scale에서의 discriminator를 병렬적으로 운용하여 마치 Mel이 그랬듯 인간의 인지 기준에 부합한 discriminator 작업을 수행했다는 점이 눈여겨 볼 만하다.
Loss
Loss는 MelGAN에서 사용한 것과 똑같다. Generator의 Loss term에 predicted wav와 ground truth wav 간 distance를 파악하는 metrics가 없다는 점이 굉장히 특이한데, 이는 wav 차원에서의 L1 loss를 줄이는 것이 실제 생성 음성 품질의 차원에서는 큰 성능 향상을 이끌어내지 못하기 때문이다.
Ablations

참 놀랍다. MPD와 Mel Spectrogram Loss가 실제 MOS 평가 (Subjective evaluation score) 에 큰 영향을 주었다는 점에서 이들의 존재가 매우 중요했던 것을 확인할 수 있다.
Key aspects
-
Dilated Convolution을 사용해 Receptive field를 크게 만들어Multi speech의 long-term dependency를 학습할 수 있게 했다.
-
Fully Convolutional network를 이용해 variable length audio input을 직접적으로 처리할 수 있고 parallizable해 매우 efficient하다.
-
Multi-period Discriminator를 사용해 audio에 내재하는 다양한 패턴을 학습할 수 있다.
