Paper review: Listen through the Sound: Generative Speech Restoration Leveraging Acoustic Context Representation
Paper Review
목록 보기
14/17
Introduction
- Current models do not explicitly model degradation information (e.g., type, intensity)
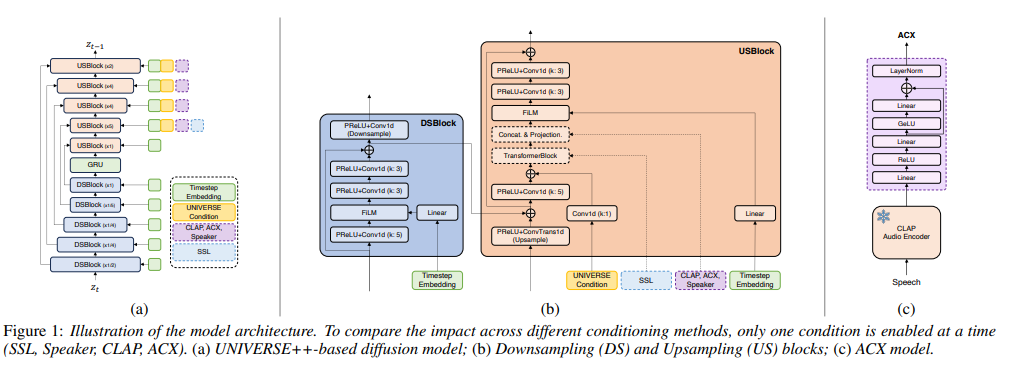
Proposed Methods
- Injection of conditions like SSL or Speaker embedding
- ACX, a novel conditions that fine-tunes CLAP in contrastive fashion
Anchor: audio sample A + degradation X
Positive sample: audio sample B + degradation X
Weak negative: audio sample C (whatever) + degradation Y
Hard negative: audio sample A + degradation X (same type but more severe)
1. Learn the type of degradation
1-1. Minimize the distance between Anchor and Positive Sample
1-2. Maximize the distance between Anchor and Weak negative
2. Learn the intensity of degradation
2-1. Minimize the distance between Anchor and Hard negative to a extent of Positive Sample
2-2. Maximize the distance between Anchor and Weak negative.
Experimental Findings
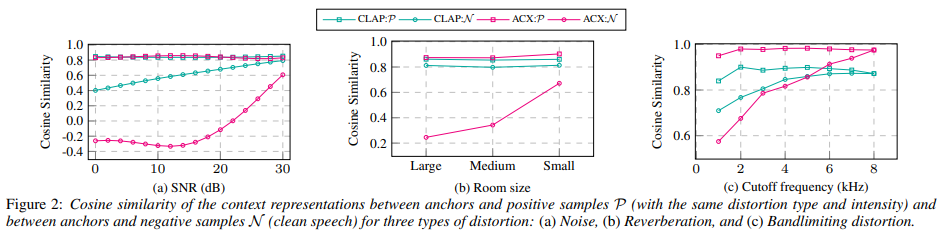
- For negative samples in CLAP, not much difference is exhibited when different degradation intensity is provided.
- For negative samples in ACX, strong correlations between the degradation intensity and the embedding.
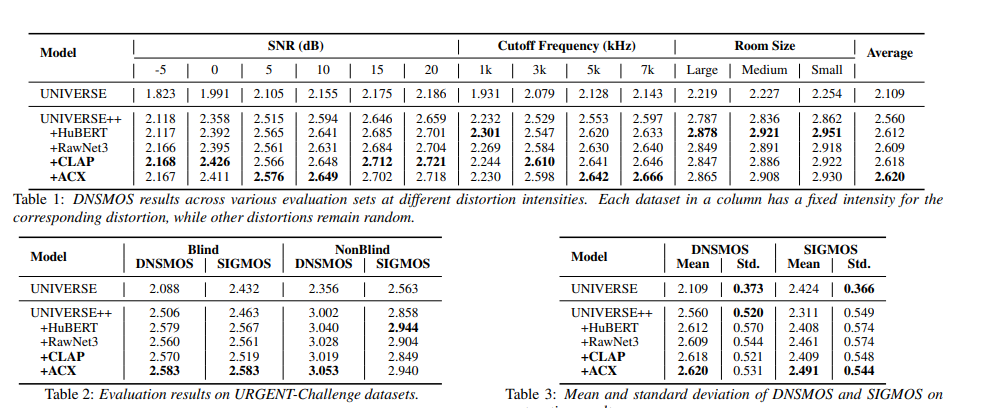
- Conditioning helps for every conditioning methods
- ACX is the most effective way of conditioning
Thoughts & Questions
- Is contrastive learning really a go-to method in learning degradation?
- CLAP/ACX embedding isn't time-varying, but information such as additive noise can be time-varying. Wouldn't the embedding be better if injected without losing time information?
- Experiments when multiple degradations happen simultaneously?

Ad libitum