두 주 사이에 읽은 Mamba 관련 논문들 한번 리뷰해 보겠다. 얼마전에 NeurIPS 2024에 Mamba 관련 논문만 거의 10편 넘게 실려서 읽을 게 더 늘어난 상황이다.
Rethinking Mamba in Speech Processing by
Self-Supervised Models (Xiangyu Zhang et al., 2024)
Insight: Reconstruction task에서 Mamba는 Independent하게 쓰여도 잘 작동하지만, Classification task에서 Mamba는 Transformer 등 Decoder와 함께 쓰였을 때 잘 작동할 수 있다.
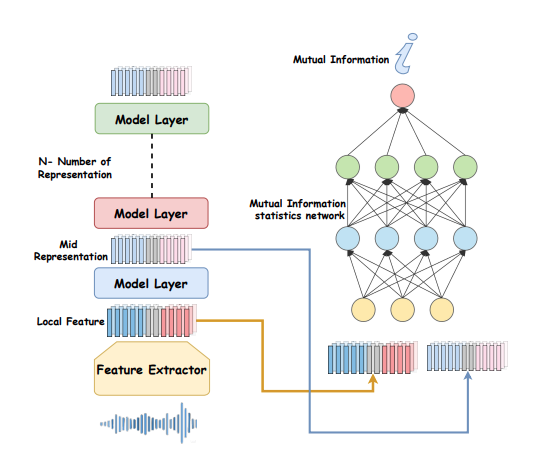
Mamba in Speech: Towards an Alternative to Self-Attention (Xiangyu Zhang et al., 2024)
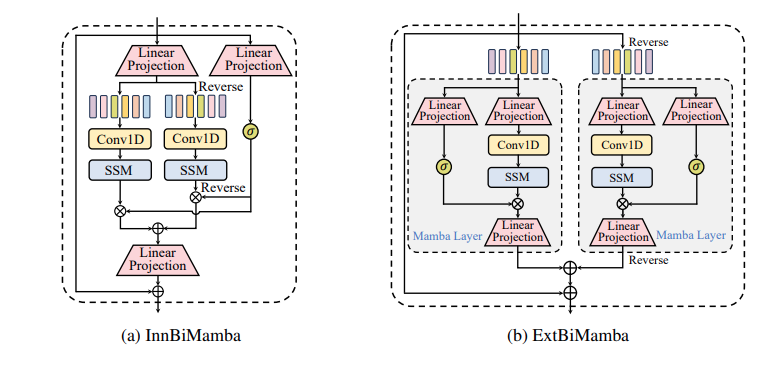
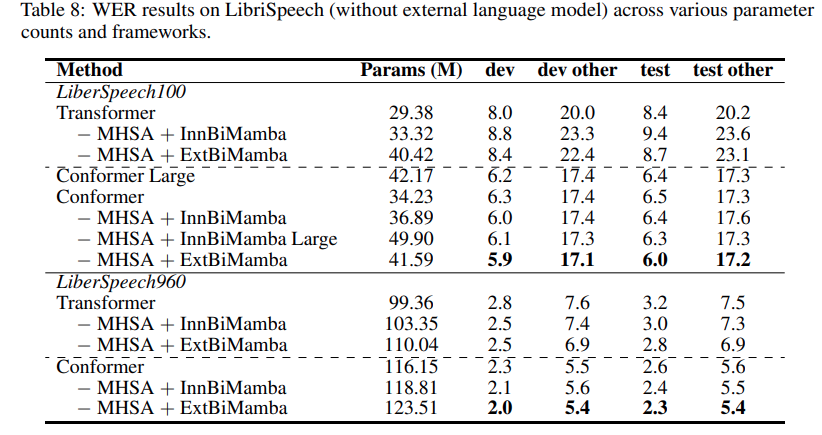
Insights: 기존의 Vision Mamba에 쓰였던 Bidirectional Mamba와, 두 Mamba를 독립적으로 구성하고 이 결과를 더해서 사용한 Mamba를 각각 만들고 다양한 Task에 대해 실험했다. 실험 결과 후자의 Bidirectionality를 쓰는 것이, 그리고 Transformer 의 MHSA 부분에 Mamba를 넣는 방식이 일반적으로 좋은 성능을 냈다.
The Hidden Attention of Mamba Models
(Ali et al., 2024)
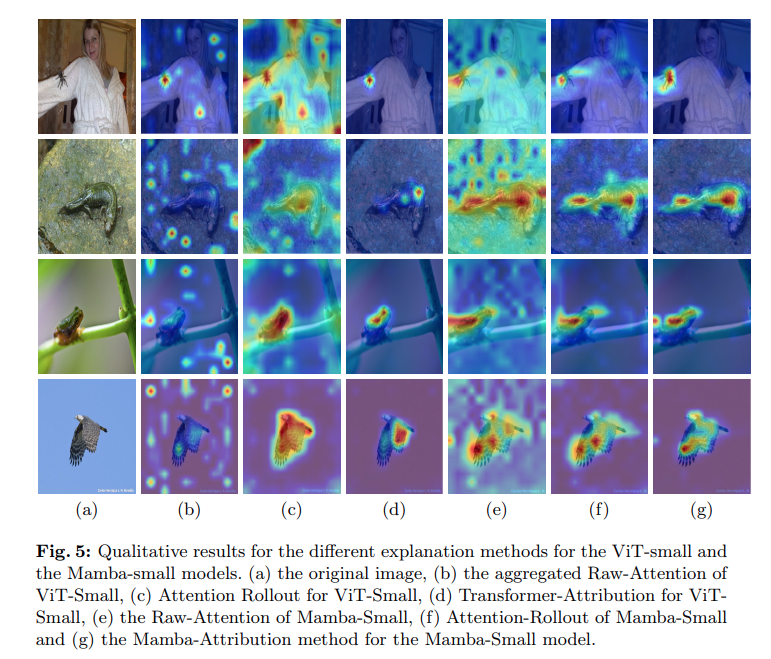
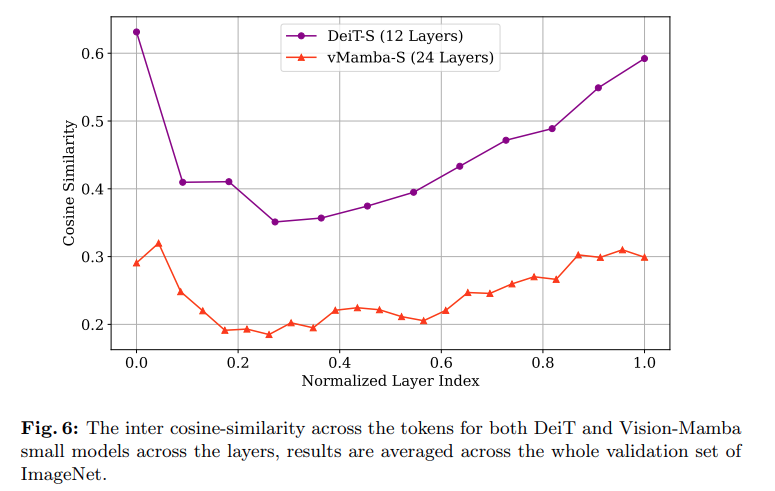
Insight: Mamba를 data-driven non-diagonal feature mixer로 바라보고, hidden attention map을 implicit 하게 그릴 수 있었다. 그리고 그 과정에서 Transformer보다 Mamba가 oversmoothing 문제를 덜 겪는다는 것을 알게 되었다. 이는 곧 Mamba가 Locality를 잘 반영한다는 것이 되고, SSL tasks 중에서 reconstruction 등을 수행하는데 Mamba가 큰 역할을 할 것으로 생각할 수 있다.

수식 설명이 필요해요 ㅠㅠ