👉 SQL을 어떻게 튜닝할 것인지
목차
- MySQL Optimizer
- Join
- Index
- Etc
- Query Plan
- Practice
이 과정의 목표
- 쿼리를 보고 인덱스를 생성할 수 있다.
- Nested Loop Join을 이해한다.
- 복합 인덱스를 이해한다.
- Semi Join으로 변경할 수 있는 쿼리패턴을 익힌다.
1. MySQL 옵티마이저
여러 툴들이 있지만 결국 인덱스, 쿼리는 사람이 짜야하므로 옵티마이저가 잘 동작하게끔 튜닝하는 것이 필요하다.
MySQL 아키텍처
먼저 MySQL 서버의 아키텍처에 대해 알아보자.
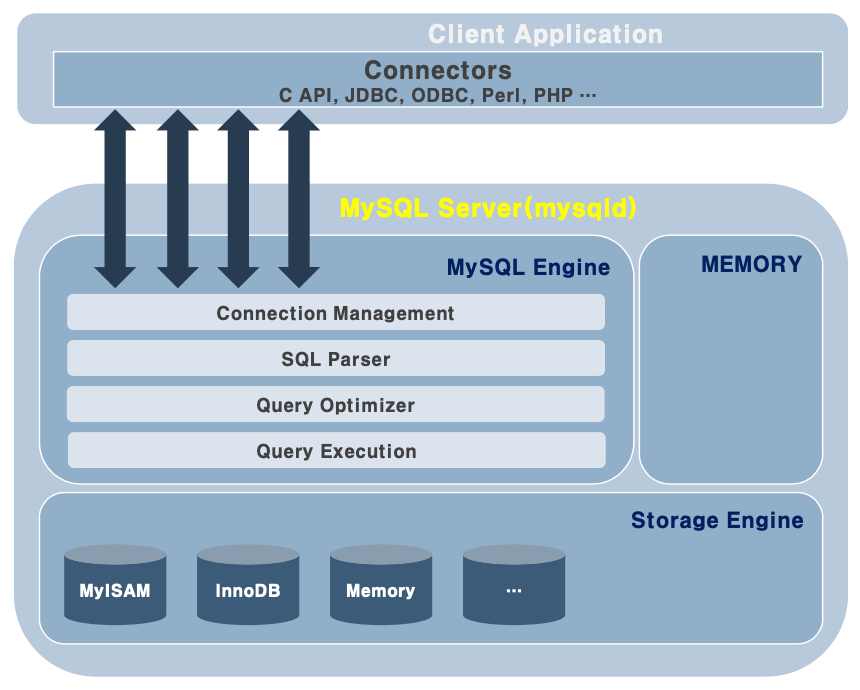
크게 메모리와 파일, 프로그램으로 구성된다. 필요한 파일의 내용을 메모리에 끌어올려서 사용한다.
MySQL을 설치하고 프로세스 목록을 살펴보면, mysqld 프로세스 하나만 존재하는 것을 볼 수 있는데, 이는 하나의 프로세스 안에서 여러 프로그램이 스레드로 동작하는 구조이기 때문이다.
스레드로 동작하는 프로그램들이 커넥션 생성 및 관리, SQL 파싱, 쿼리 옵티마이징, 쿼리 실행에 대한 업무를 수행한다.
MySQL 엔진
MySQL 엔진의 구조에 대해 알아보자.
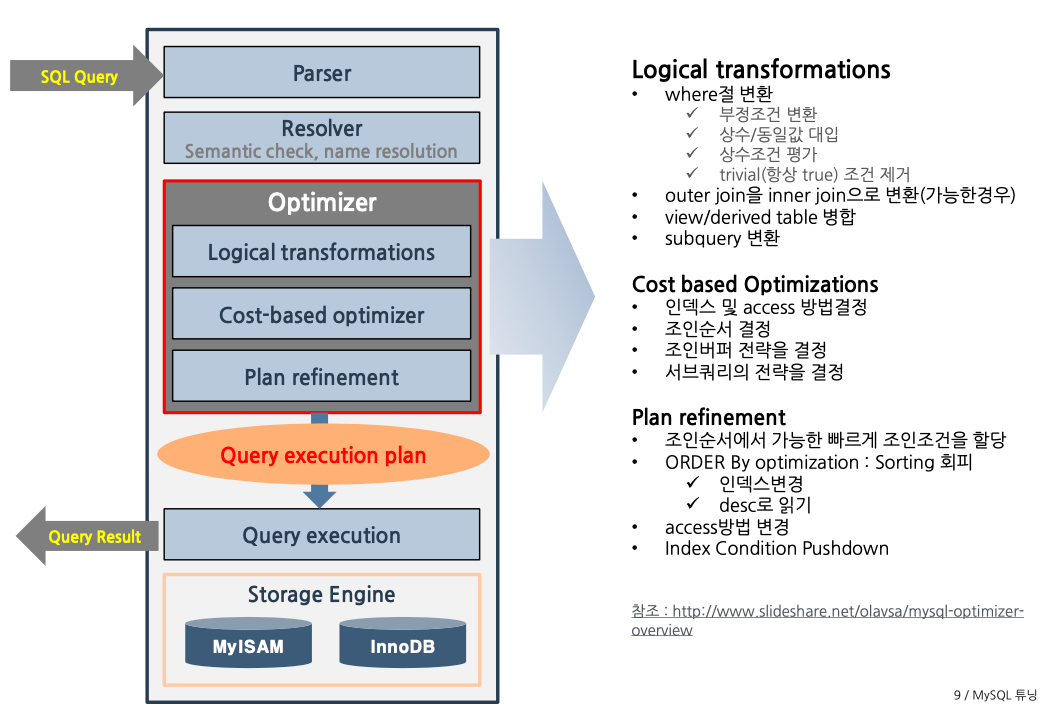
- Parser : 가장 먼저 쿼리를 받고 파싱
- Resolver : semantic check, name resolution, 권한 체크 등
- Optimizer
- Logical transformations
- Cost based Optimizations
- Plan refinement
Logical Transformations 예시

WHERE절 변환 수행 (드모르간 법칙으로 NOT을 안으로 합쳐서 부등호 바꾸기, 항상 참인 조건 제거)

LEFT JOIN이 필요없는 데 사용된 경우 JOIN으로 변경
1 warning 표시 👉 show warning;으로 실제로 실행된 쿼리 확인 가능
Optimizer 비교

-
옵티마이저 타입과 비용
- MySQL의 경우 과거에는 Rule Based Optimizer가 있었지만, 현재는 Cost Based Optimizer만 사용됩니다. 이는 CPU COST보다는 DISK I/O를 줄이는 방향입니다.
- Oracle의 경우 기본적으로 Cost Based Optimizer를 사용하며 일부 특수한 상황에서 Rule Based Optimizer를 사용합니다. 이는 CPU COST와 DISK I/O 모두 줄이는 방향입니다.
-
Block Size
- 리눅스는 4K 단위로 Block을 사용합니다.
- 이에 DB의 Block Size도 OS에 맞춰 변경 가능하지만, 요구사항에 따라 동일한 것이 좋을 수도 있고 늘리는 것이 좋을 수도 있습니다.
- 사내에서는 큰 차이가 없다고 여기기 때문에 16K 고정으로 사용합니다.
-
데이터 정렬
- MySQL은 Clustered Index 저장구조를 이용합니다.
- Oracle은 들어오는대로 Insert됩니다.
-
통계정보
- MySQL은 8개의 페이지에 대해서만 통계를 샘플링합니다.
- 따라서 테이블이 점점 커져도 128KB의 통계데이터를 가지게 되므로 데이터가 커질수록 통계 정보가 부정확할 위험이 커집니다. 하지만 사실상 큰 차이는 없습니다.
-
NULL 처리
- MySQL은 NULL을 값으로 인식하여 함께 인덱싱을 수행합니다.
-
조인 방식
- MySQL 8.0.18 미만 까지는 Nested Loop만 지원합니다.
- MySQL 8.0.28 이상부터는 Nested Loop / Hash 조인 모두 지원합니다.
-
인덱스 활용
- MySQL는 인덱스를 적극 활용하므로 다른 DB에 비해 플랜이 자주 바뀌지 않습니다.
통계정보
통계정보란 Cost Base Optimizer가 실행계획을 세울 당시에 참조하는 스키마 관련 정보입니다.
테이블의 예상 건수, 테이블/인덱스 공간의 크기(블록의 개수), 칼럼의 distinct value의 개수 및 칼럼 데이터 분포도 등을 의미합니다.
MySQL은 테이블 및 인덱스의 크기, 테이블의 예상 건수, 인덱싱 된 칼럼의 distinct value 수를 계산하여 주기적으로 자동 갱신합니다.
관련 용어
Cardinality (카디날리티)
: 인덱싱된 칼럼의 distinct value의 개수입니다.
Selectivity (선택도)
: 전체 데이터 건수 대비 distinct value의 비율 (#Cardinality / #TotalRows) 입니다.
Selectivity가 1인 경우(Unique)가 최상입니다.
Data Distribution (데이터 분포도)
: 특정 칼럼에 대해 전체 건수 대비 특정 값이 차지하는 비율입니다.
통계 정보 샘플링
MySQL은 테이블 Open 시 무작위 8 페이지(128KB) 샘플링을 통해 통계 정보를 생성하므로 부정확할 수 있습니다.
이때 인덱싱 칼럼의 통계 정보만 생성하며, 인덱싱 되지 않은 칼럼의 통계 정보는 관리하지 않습니다.
테이블 변경이 많거나 사용자가 analyze table 명령을 수행 하는 경우 통계정보가 갱신됩니다.
Primary Key, Unique Index의 Cardinality는 거의 정확합니다.
만약 Cardinality가 작은 경우, 실제보다 크게 계산되는 경우도 있습니다.
통계정보 확인구문
- 테이블 통계 정보
mysql> show table status like 'cust'\G
************** 1. row ***********
Name: cust
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 61
Avg_row_length: 268
Data_length: 16384
Max_data_length: 0
Index_length: 98304
Data_free: 0
Auto_increment: 62
Create_time: 2016-09-21 17:54:54
Update_time: NULL
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)- 인덱스 통계 정보
mysql> show index from cust\G
************ 1. row ***********
Table: cust Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: cust_id
Collation: A
Cardinality: 61
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
************ 2. row ***********
Table: cust
Non_unique: 1
Key_name: idx2_age
Seq_in_index: 1
Column_name: age
Collation: A
Cardinality: 30
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:연습문제
-
MySQL 옵티마이저가 참고하는 통계 데이터 중에 카디날러티(Cardinality)의 의미는?
👉 칼럼에 존재하는 유일 값의 개수 -
cust 테이블의 데이터/인덱스 사이즈 확인해 보세요.
👉 SHOW TABLE STATUS LIKE ‘tablename’; -
sale 테이블의 인덱스 정보를 통해 cust_id 칼럼의 카디날러티(Cardinality)를 확인해 보세요.
👉 SHOW INDEX FROM tablename; -
아래와 같이 cust 테이블을 복제합니다.
create table cust_temp like cust;
insert into cust_temp select * from cust;
show index from cust_temp;
analyze table cust_temp;
show index from cust_temp;아래와 같은 대량 업데이트를 수행하고, 업데이트 수행 전후의 통계 정보를 비교해 보세요.
update cust_temp set age=0;
analyze table cust_temp;
show index from cust_temp;- InnoDB 엔진의 데이터 샘플링이 8 page(128KB)로 고정되어 있다고 가정할 때, 아래와 같은 요소가 통계 정보에 어떤 영향을 줄지 생각해 보세요.
- Row 사이즈
👉 page 개수가 증가하므로 통계 정보가 부정확해짐 - 테이블 사이즈
👉 통계 정보가 부정확해짐 - 인덱스 개수
👉 인덱스 사이즈가 증가하므로 통계 정보와 관계 없음
- Row 사이즈
