Abstract
- 기존의 시퀀스 변환 모델들은 대부분 복잡한 RNN 또는 CNN을 기반으로 하며, 가장 성능이 좋은 모델들은 인코더와 디코더를 어텐션 매커니즘을 통해 연결한다.
- 이 논문에서는 Transformer라는 새로운 네트워크 아키텍쳐를 제안한다.
- Transformer는 전적으로 어텐션 메커니즘에 의존하며, 순환 구조(recurrence)와 합성곱(convolution)을 전혀 사용하지 않는다.
- 또한, 두 가지 기계 번역 작업에 대해 실험한 결과, 기존 모델보다 우수한 품질을 보였으며, 병렬화가 더 잘 되고, 학습에 상당히 적은 시간이 필요하다는 장점이 존재한다.
- WMT 2014 영어-독일어 번역 작업에서 28.4 BLEU 달성함.
- WMT 2014 영어-프랑스어 번역 작업에서도 41.8 BLEU 달성함.
- 다른 작업에도 일반화될 수 있음을 보이기 위해 영어 구문 분석에도 적용했고, 이때도 좋은 성능을 보임을 확인함.
1. Introduction
- 순환 신경망(Recurrent Neural Networks, RNN), 특히 LSTM 및 GRU는 시퀀스 모델링 및 언어 모델링, 기계 번역과 같은 변환 문제에서 최첨단 기법으로 확고히 자리 잡고 있으며, 순환 언어 모델과 인코더-디코더 구조를 발전시키기 위한 다양한 연구가 지속되어 왔다.
- 순환 모델은 일반적으로 입력 및 출력 시퀀스의 심볼 위치에 따라 연산을 수행한다. (쉽게 말해, 시간 순서에 따라 순차적으로 연산을 수행한다는 의미이다) 이전의 hidden state 와 현재 시점 t의 입력 으로, 새로운 hidden state 를 생성한다.
-
- 이러한 순차적 특성으로 인해 개별 학습 샘플 내에서 병렬 처리가 어려워지며(반드시 이전 상태를 이용해 현재 상태를 업데이트 해야 하므로), 시퀀스 길이가 길어질수록 메모리 제한으로 인해 샘플 간 배치 처리가 어려워진다.
- 최근 연구에서는 인수 분해(factorization) 기법 및 조건부 연산(conditional computation)을 활용하여 연산 효율성을 크게 개선하고, 후자의 경우 모델 성능도 향상시켰으나, 순차적 연산이라는 근본적인 한계는 여전히 존재한다.
- Attention 매커니즘은 다양한 작업에서 강력한 시퀀스 모델링 및 변환 모델의 핵심 요소가 되었으며, 입력 또는 출력 시퀀스에서 거리와 무관하게 의존성을 모델링할 수 있도록 한다. 하지만 소수의 예외를 제외하면, 대부분의 어텐션 메커니즘은 여전히 순환 신경망과 함께 사용된다.
- 이 연구에서는 순환 구조를 완전히 배제하고, 입력과 출력 간 Global Dependencies을 학습하기 위해 오직 어텐션 메커니즘만을 활용하는 Transformer라는 새로운 모델 구조를 제안한다.
- Transformer는 병렬 처리를 대폭 향상시키며, 8개의 P100 GPU에서 단 12시간의 학습만으로 기계 번역 성능에서 새로운 최첨단 결과를 달성할 수 있다.
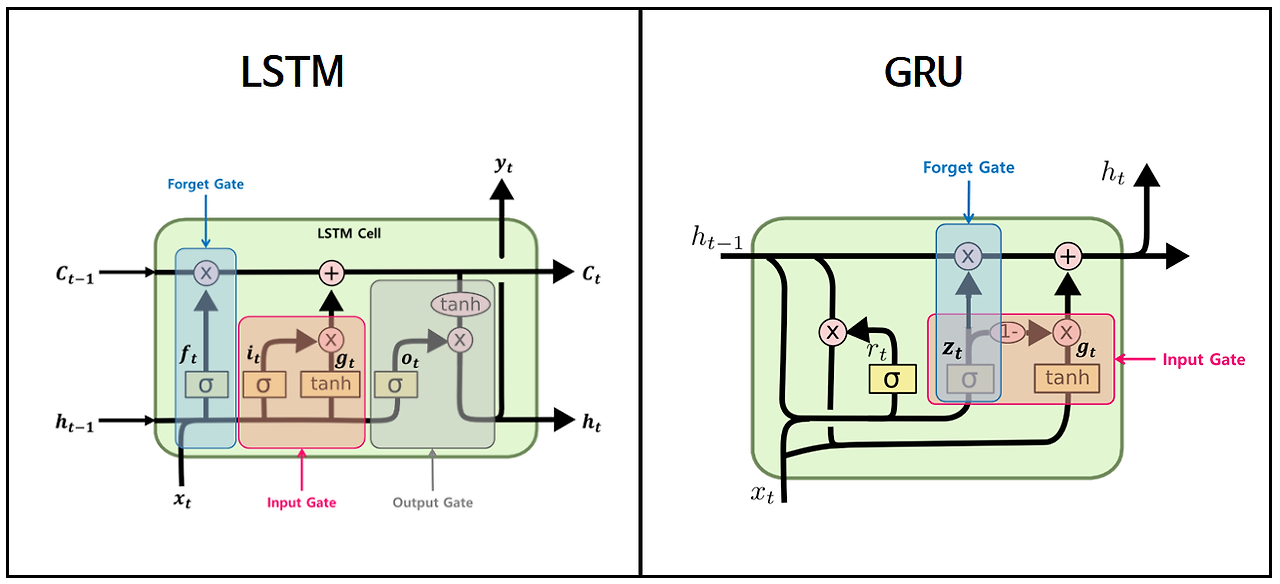
** 이전에 사용하던 RNN의 구조 (LSTM, GRU) : 이전까지의 결과와 현재 입력을 참고하여 새로운 결과를 생성한다.
- 초기 어텐션 메커니즘은 기본적으로 RNN(LSTM, GRU) 모델과 함께 사용되는 보조 기법이었음.
- 시퀀스가 길어질수록, 초반에 입력된 정보가 나중에 손실될 가능성이 높아 LSTM이나 GRU가 등장해 일부 개선되었지만, 여전히 긴 문장을 다룰 때는 정보 손실이 발생하는 문제가 있었음.
- 어텐션을 추가하면 이전의 모든 입력 정보를 한 번에 참고할 수 있어, RNN만 사용할 때보다 장기 의존성을 더 잘 학습할 수 있음. (RNN이 시퀀스를 순차적으로 처리하는 동안, 어텐션은 모든 time step의 정보에 대해 한 번에 가중치를 부여하며 활용하기 때문)
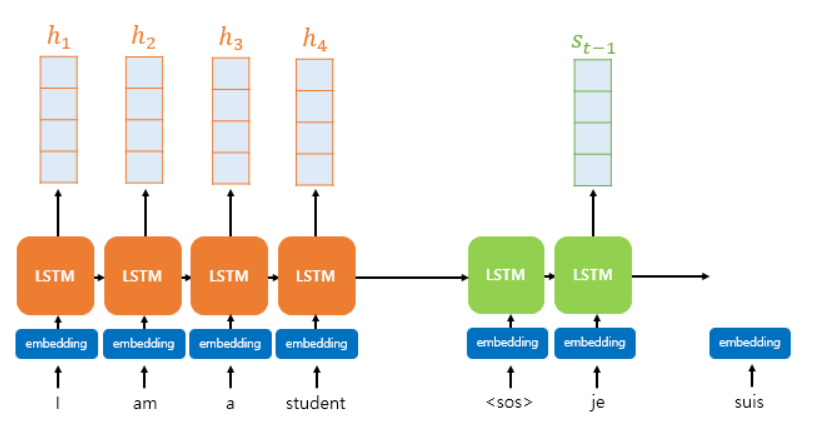
** RNN 모델 + 어텐션 매커니즘의 대표적인 예시 : 바다나우 어텐션(Bahdanau Attention)
- Seq2Seq 구조에 어텐션 매커니즘이 추가된 형태
- 핵심 아이디어는 인코더의 모든 hidden state들의 weighted sum을 구한 후, 이를 디코더의 입력(hidden state)과 결합하여 최종 출력을 생성하는 것임.
- 기존 Seq2Seq는 마지막 hidden state 하나만 사용했지만, Bahdanau Attention은 모든 hidden state를 참고하여 중요한 정보를 유지함.
- 각 타임스텝마다 어텐션 가중치를 동적으로 계산하여, 디코더가 더 중요한 부분을 집중적으로 활용할 수 있도록 개선됨.
2. Background
- 순차적 연산을 줄이려는 목표는 Extended Neural GPU인 ByteNet, ConvS2S와 같은 모델의 기반이 됨.
- 이들은 모두 합성곱 신경망을 기본 구성 요소로 사용하여, 입력 및 출력의 모든 위치에 대해 hidden representation을 병렬적으로 계산함.
- 이러한 모델에서, 두 개의 임의의 입력 또는 출력 위치 간 신호를 연결하는 데 필요한 연산 수는 위치 간 거리에 따라 증가함.
- ConvS2S의 경우 선형적으로, ByteNet의 경우 로그 형태로 증가함.
- 이로 인해, 먼 거리 간의 의존성을 학습하는 것이 더 어려워짐.
- Transformer에서는 이러한 연산을 상수 개수로 줄일 수 있음.
- 그러나, 어텐션 가중치가 적용된 여러 위치를 평균화하는 과정에서 해상도가 감소하는 문제가 발생 -> Multi-Head Attention 기법을 사용하여 보완
- Self-Attention (= Intra-Attention) : 단일 시퀀스 내 서로 다른 위치 간의 관계를 학습하여 해당 시퀀스의 표현을 계산하는 기법
- Reading Comprehension, Abstractive Summarization, Textual Entailment, learning task-independent sentence representations과 같은 다양한 작업에서 성공적으로 활용됨.
- End-to-End Memory Networks는 순차적으로 정렬된 RNN 기반 모델이 아닌, Recurrent Attention Mechanism을 기반으로 하며(RNN처럼 time step을 따라가며 업데이트하는 방식이 아니라, Attention을 여러 번 반복해서 메모리를 갱신하는 구조), Simple-Language Question Answering 및 Language Modeling 작업에서 우수한 성능을 거두는 것으로 나타남.
- Transformer는 시퀀스 정렬 RNN이나 합성곱을 사용하지 않고, 오직 Self-Attention만을 활용하여 입력과 출력의 표현을 계산하는 최초의 변환 모델이다.
** Recurrent Attention Mechanism : RNN 기반의 모델에서 어텐션 매커니즘을 적용하는 방식
** End-to-End Memory Network : 외부 메모리를 활용하여 입력 정보를 저장하고 검색하는 신경망 모델로, Transformer 이전에 메모리를 유지하면서 학습할 수 있는 모델을 만들기 위해 등장했다.
** 정리하자면, 기존의 신경망 기반 번역 모델들은 주로 RNN과 CNN을 사용했다. RNN은 연속적인 상태를 기반으로 문장을 변환하지만, 병렬 처리에 한계가 있었고, CNN 기반 모델들은 병렬성을 높였으나, 문장 내 장거리 의존성을 모델링하는 데 어려움이 있다. 이러한 문제를 해결하기 위해 Attention Mechanism이 도입되었으며, Transformer는 이를 기반으로 RNN이나 CNN 없이 Self-Attention만을 활용하는 최초의 모델이다.
** 어텐션 가중치가 적용된 여러 위치를 평균화하면 정확한 의미를 담지 못하게 될 수 있으므로, 더미 토큰을 사용해 어디에도 편향되지 않은 데이터를 뽑아내기도 한다. 다만, 이 경우는 Sequence-level Prediction에 주로 사용되고, Token-level Prediction이 필요한 경우엔 더미 토큰을 사용하지 않는다. (개별 단어의 정보를 그대로 유지해야 하기 때문)
3. Model Architecture
- 대부분의 경쟁력 있는 신경망 기반 시퀀스 변환 모델은 인코더-디코더 구조를 따른다.
- 인코더는 입력 시퀀스 -> 로 변환하며, 디코더는 z를 기반으로 출력 시퀀스 을 auto-regressive하게 생성한다. (즉, 이전에 생성된 심볼을 추가 입력으로 사용해 순차적 출력을 만들어냄)
- Transformer 모델 역시 이러한 인코더-디코더 아키텍처를 따르지만, 인코더와 디코더 모두에 스택된 Self-Attention과 Point-wise FC Layer를 사용한다.
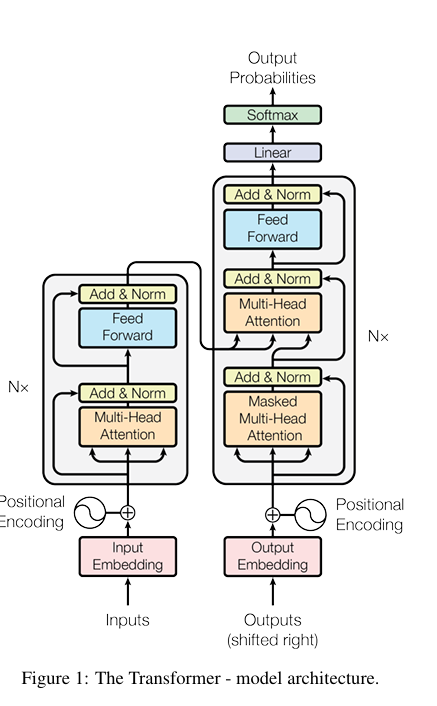
** Point-wise FC Layer : 각 단어(토큰)에 독립적으로 적용되는 완전 연결 신경망
3.1 Encoder and Decoder Stacks
- Encoder: 6개의 동일한 레이어로 구성. 각 레이어는 Multi-Head Self-Attention과 Feed-Forward Network (FFN)으로 구성됨. 두 하위층주위에 Residual Connection을 사용한 다음, 정규화를 따름.
- 즉, 각 하위층의 출력은 LayerNorm(x + Sublayer(x))
- Residual Connection을 원활하게 적용하기 위해, 모델 내 모든 서브 레이어와 임베딩 층은 출력 차원을 로 통일
- Decoder: Encoder와 비슷하지만, 추가적인 세 번째 레이어 Encoder-Decoder Attention을 포함하여 인코더의 출력을 참고하도록 함.
- 인코더와 마찬가지로, 각 서브 레이어에는 Residual Connection이 적용된 후 Layer Normalization을 수행
- 디코더 스택 내 Self-Attention 서브 레이어에는 Masking 기법이 적용되어, 각 위치가 이후의 위치를 참고하지 못하도록 설계
- Output Embeddings은 한 위치씩 밀려 있어, 위치 i에 대한 예측이 i보다 작은 위치의 알려진 출력에만 의존하도록 보장 (shifted right를 의미)
3.2 Attention
- Attention Function은 입력 쿼리(Query), 키(Key), 값(Value)을 출력에 매핑하는 것임.
- Query, Key, Value 및 출력은 모두 벡터이며, 출력은 Value들의 weighted sum으로 계산됨.
- 각 값에 할당된 가중치는 쿼리와 해당 키 간의 유사성을 측정하는 적합도 함수(Compatibility Function)에 의해 계산됨.
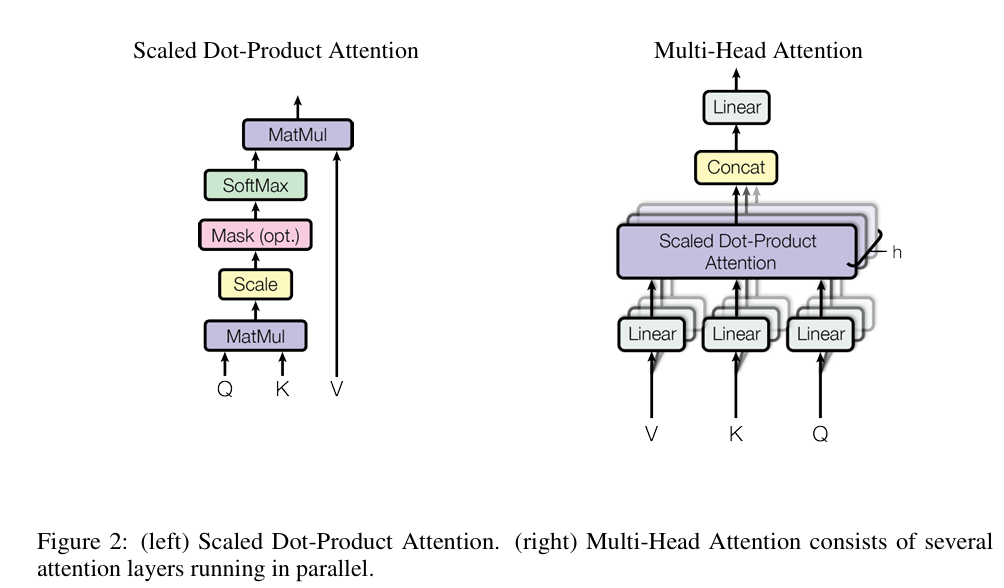
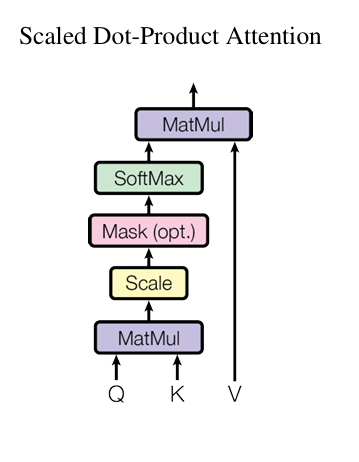
3.2.1 Scaled Dot-Product Attention
- 입력 : Query와 Key의 차원 , Value의 차원
- Query와 모든 키 간의 내적(dot product)을 계산한 후, 이를 로 나누고, Softmax를 적용해 값에 대한 가중치를 얻음.
- 실제 구현에서는 여러 개의 쿼리에 대해 동시에 어텐션을 수행하기 위해,
쿼리 𝑄, 키 K, 값 V를 행렬 형태로 묶어서 연산하며, 출력 행렬은 다음과 같음.
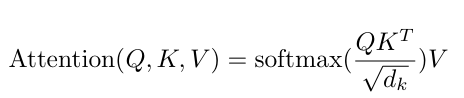
- 가장 일반적으로 사용되는 Attention Function
- Additive Attention : 단일 은닉 계층이 있는 FFN을 사용하여 Compatibility Function을 계산함.
- Dot-Product (Multiplicative) Attention : 현재 방식과 비슷하나, 스케일링이 없는 상태
- 이론적으로 두 방식의 복잡도는 유사하지만, Dot-Product Attention은 고도로 최적화된 행렬 곱셈 연산 활용이 가능해 훨씬 빠르고, 메모리 효율적임.
- 값이 작을 때, Additive Attention과 Dot-Product Attention의 성능 차이는 크지 않으나, 값이 클 경우 스케일링 없이 Dot-Product Attention을 사용하면 Softmax 함수의 출력이 매우 작은 기울기를 갖는 영역으로 밀려 성능이 저하됨.
- 이를 해결하기 위해 쿼리-키 내적 결과를 로 스케일링하여 Softmax의 기울기 문제를 완화함.
3.2.2 Multi-Head Attention
- 단일 Attention Function을 적용할 때, 쿼리(Query), 키(Key), 값(Value)을 차원의 동일한 공간에서 연산하는 대신, Linear Projection하여 h개의 다른 서브 공간으로 분할하는 것이 더 효과적임을 발견함.
- 즉, 쿼리, 키, 값을 각각 차원으로 변환하는 linear projection을 h번 수행
- 각각의 변환된 쿼리, 키, 값에 대해 Attention 연산을 병렬적으로 수행하며, 결과로 얻어진 차원의 출력 값들을 연결한 후, 다시 한 번 선형 변환을 적용해 출력을 생성함.
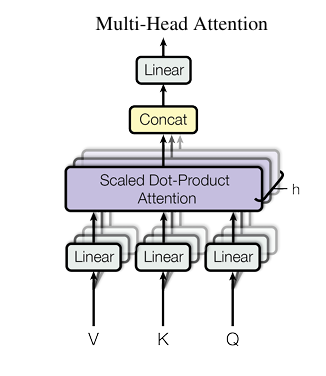
- Multi-Head Attention은 다양한 표현 서브 공간에서 서로 다른 위치의 정보를 동시에 학습할 수 있도록 함. (다양한 패턴을 학습하기 위해 여러 개의 독립적인 Attention을 동시에 사용함)
- 만약 단일 Attention만 사용하면, 여러 정보가 평균화되어 정보 손실 발생 (문장 내 여러 관계들이 하나의 벡터로 표현되면서 뒤섞이기 때문)

-
각각 쿼리, 키, 값에 대해 학습 가능한 선형 변환 행렬
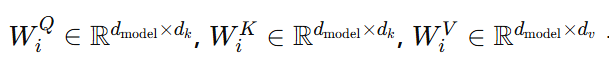
-
최종 출력을 위한 선형 변환 행렬
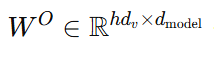
-
실제 실험에서는, h=8개의 병렬 어텐션 레이어를 사용하며, 각 헤드의 차원은 다음과 같다. 각 헤드의 차원을 줄였기 때문에, 전체 계산 비용은 Single-Head Attention과 비슷하게 유지됨.
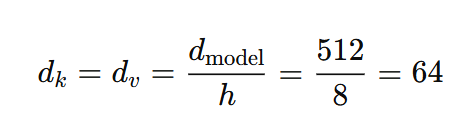
3.2.3 Applications of Attention in the Transformer
Transformer는 Multi-Head Attention을 세 가지 방식으로 활용한다.
- Encoder-Decoder Attention
- Query : 이전 디코더 레이어의 출력에서 가져옴.
- Key, Value : 인코더의 출력에서 가져옴.
- 디코더의 모든 위치가 입력 시퀀스의 모든 위치에 주목할 수 있음.
- Seq2Seq 모델에서 사용되는 인코더-디코더 어텐션 메커니즘과 유사함.
- Self-Attention in Encoder
- Self-Attention Layer 포함.
- Query, Key, Value : 모두 동일한 곳에서 나옴. (이전 인코더 레이어의 출력이 사용됨)
- 인코더의 각 위치가 이전 레이어의 모든 위치에 주목할 수 있음.
- Self-Attention in Decoder
- Self-Attention Layer 포함. (마찬가지로 모든 위치 주목 가능)
- 디코더에서의 정보 흐름이 미래 방향으로 전파되지 않도록(leftward information flow 방지) Masking을 적용
- Scaled Dot-Product Attention 내부에서 Softmax 입력 중 불가능한 연결에 해당하는 값을 -∞로 설정하여 마스킹을 구현
** leftward information flow : 미래 시점의 단어를 볼 수 없도록 만드는 것
- 만약 미래 시점 단어를 볼 수 있다면 모델이 제대로 된 예측 결과를 내지 않고, 정답을 미리 알고 그대로 복사하는 문제가 발생한다. 이를 방지하기 위해 마스킹을 적용하는 것이다.
3.3 Position-wise Feed-Forward Networks
- Attention Sub-Layers 외에도, 인코더와 디코더의 각 레이어는 완전 연결 피드포워드 신경망(Fully Connected Feed-Forward Network, FFN)을 포함함.
- 이 신경망은 각 위치에 독립적으로 적용되며, 동일한 연산이 수행됨.
- FFN은 두 개의 선형 변환과 그 사이에 ReLU 활성화 함수로 구성됨.
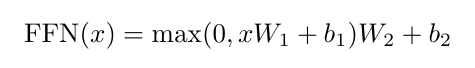
- 선형 변환은 모든 위치에서 동일하게 적용되지만, 레이어마다 서로 다른 파라미터를 사용함.
- 다른 방식으로 설명하면, 커널 크기 1의 두 개의 합성곱 연산과 동일한 구조
- 입력 및 출력 차원 , inner-layer 차원 (즉, 입력 512차원 → 내부 2048차원 → 512차원으로 변환)
3.4 Embeddings and Softmax
- 다른 시퀀스 모델들과 마찬가지로, 학습된 임베딩을 사용하여 입출력 토큰의 차원을 의 벡터로 변환하며, 디코더의 출력을 예측된 다음 토큰 확률로 변환하기 위해 일반적인 선형 변환과 Softmax 함수를 적용함.
- Embedding Layers와 Pre-Softmax 선형 변환 간 동일한 가중치 행렬을 공유함. (입출력 임베딩과 Pre-Softmax 선형 변환이 가중치 공유)
- Embedding Layers에서 해당 가중치를 로 곱함. (스케일링)
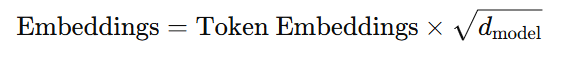
- 최대 경로 길이/레이어별 연산 복잡도/최소 순차 연산 횟수 비교

3.5 Positional Encoding
- RNN이나 CNN 구조를 포함하지 않으므로, 시퀀스 내 토큰들의 순서를 반영하기 위해 상대적 혹은 절대적 위치 정보를 추가해야 하며, 이를 위해 인코더와 디코더의 Embedding에 Positional Encoding를 추가함.
- Positional Encoding의 차원은 임베딩 차원()과 동일하기에 위치 정보와 입력 임베딩을 단순히 합(sum)할 수 있음.
- Positional Encoding에는 다양한 방식이 존재하는데(learned and fixed), 이 연구에서는 서로 다른 주파수의 사인 코사인 함수를 사용해 생성함. (이를 통해 단어의 상대적인 위치 정보를 학습)
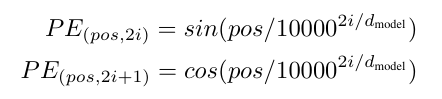
- pos : 시퀀스 내에서의 위치 / i : 차원 (위치 인코딩의 각 차원은 개별적인 사인, 코사인 함수에 해당함))
- 위치 인코딩에 사용되는 파장은 2π 에서 10000 × 2𝜋까지 기하급수적으로 증가하는 형태 (이러한 함수 형태를 선택하면 모델이 상대적 위치에 따라 Attention을 학습하는 것이 더 쉬워질 것이라 판단함)
- 고정된 offset k에 대해 가 의 선형 함수로 표현될 수 있음.
- learned positional embedding에 대해 실험한 결과, 두 버전은 거의 동일한 결과를 나타냈으며, 사인 및 코사인 기반의 위치 인코딩을 선택함. (이 방식이 훈련 과정에서 보지 못한 더 긴 시퀀스에 대해 일반화하는 능력을 가질 가능성이 높기 때문)
** learned positional embedding vs fixed positional embedding
- fixed positional embedding : 특정한 수식을 이용하여 단어의 위치 정보를 미리 계산한 후 사용하는 방식 (주로 위의 공식을 사용)
- learned positional embedding : 위치 정보를 뉴럴 네트워크가 직접 학습하도록 만드는 방식으로, 각 단어의 위치에 대한 벡터를 랜덤 초기화한 후, 학습을 통해 최적의 값으로 업데이트함.
4. Why Self-Attention?
- 이 섹션에서는 Self-Attention 층과, 일반적으로 가변 길이의 기호 표현 시퀀스 를 동일한 길이의 다른 시퀀스 로 변환하는 데 사용되는 recurrent 및 convolutional 층의 다양한 측면을 비교한다.
- Self-Attention을 사용하는 동기를 설명하기 위해 세 가지 기준을 고려
- 층당 전체 계산 복잡도
- 병렬화할 수 있는 계산량 (최소한의 순차적 연산 횟수)
- 장거리 의존성 학습 경로 길이
- 의존성을 학습하는 능력에 영향을 미치는 주요 요인 중 하나는, 입력 및 출력 시퀀스의 임의의 위치 간 신호가 순방향 및 역방향으로 이동해야 하는 경로의 길이이며, 이 길이가 짧을수록 장거리 의존성 학습이 쉬워짐.
- 서로 다른 층 유형으로 구성된 네트워크에서 임의의 입력 및 출력 위치 간 최대 경로 길이를 비교함.
- Self-Attention 층은 일정한 수의 순차적 연산을 통해 모든 위치를 연결할 수 있는 반면, Recurrent 층은 O(n)개의 순차적 연산이 필요함.
- 계산 복잡도 측면에서도 Self-Attention은 시퀀스 길이 n이 표현 차원 d보다 작을 때 Recurrent 층보다 빠름. (대부분 문장 표현에서 빠름)
- 긴 시퀀스 처리 시엔 계산 성능 향상을 위해 Self-Attention을 특정 출력 위치를 중심으로 입력 시퀀스에서 크기가 r인 국소 영역 내에서만 작동하도록 제한 가능 -> 최대 경로 길이가 O(n/r)로 증가
- 커널 너비 k < n을 가지는 단일 합성곱 층은 모든 입력 및 출력 위치 쌍을 직접 연결하지 않으며, 이를 가능하게 하려면 연속적인 커널 사용 시 O(n/k)개의 합성곱 층을 쌓아야 하며, 확장 합성곱 사용 시 개가 필요함. -> 최장 경로 길이 증가
- 합성곱 층은 일반적으로 순환 층보다 계산 비용이 더 많이 들며, 그 차이는 𝑘배 정도임. (다만, separable convolution을 사용하면 복잡도를 크게 줄일 수 있으며 이 경우 계산 비용은 . k=n일 때 separable convolution의 복잡도는 Self-Attention 층과 point-wise feed-forward 층을 조합한 것과 동일)

- 추가적인 장점으로, Self-Attention은 모델 해석 가능성을 높일 수 있음. (모델에서 학습된 어텐션 분포를 분석)
- Individual Attention Head들이 각기 다른 작업을 수행하도록 학습될 뿐만 아니라, 많은 헤드들이 문장의 구문적/의미적 구조와 관련된 패턴을 보임.
Self-Attention이란, 단어 간의 관계성 연산 결과를 활용하여 연관성 높은 단어끼리 연결해주기 위해 활용하는 매커니즘으로 기존의 Attention과 비슷하지만, 입력과 출력을 연결하는 것이 아니라, 입력 문장 내에서 자체적으로 단어 간 관계를 학습한다는 점에서 차이가 있다. (즉, 앞의 출력을 뒤의 입력으로 사용하지 않고, 각 단어가 다른 단어들과 얼마나 연관이 있는지 관계를 한 번에 계산하여 학습한다.)
Self-Attention을 수행하기 위해선 일단, 세 개의 가중치 행렬 를 생성한다. 각 단어의 임베딩에 세 행렬을 곱해 Query, Key, Value를 만든다.
그리고 나서 Query 벡터와 Key 벡터의 내적(dot product)을 계산하여 score를 구한다. 이 score를 Key 벡터의 차원 수()의 제곱근으로 나누어 스케일링한다. 이후, Softmax를 적용하여 가중치를 정규화한 후, 이 가중치를 Value 벡터와 곱한다.
마지막으로, 이 과정에서 얻은 weighted value vector들을 모두 합하는데, 이것이 self-attention layer의 출력을 생성한다.

5. Training
5.1 Training Data and Batching
- WMT 2014 영어-독일어 데이터셋 (450만 개 문장쌍)
- 문장은 Byte-Pair Encoding을 사용해 인코딩되었으며, 약 37,000개의 source target vocabulary를 가짐.
- 영어-프랑스어 데이터셋 (3,600만 개 문장)
- 문장은 32,000개의 word-piece vocabulary로 분할됨.
- 문장 쌍은 대략적인 시퀀스 길이에 따라 그룹화해 배치되었으며, 각 훈련 배치는 약 25000개의 소스 토큰과 25000개의 타겟 토큰을 포함하는 문장 쌍 세트로 구성됨.
5.2 Hardware and Schedule
- 8개의 NVIDIA P100 GPU가 장착된 단일 머신에서 모델 훈련
- 기본 모델 : 논문에서 설명한 하이퍼파라미터 사용 & 각 training step은 약 0.4초가 소요되었으며, 총 100,000step(약 12시간) 동안 훈련됨.
- 대형 모델 : 각 training step에 1.0초가 걸렸으며, 총 300,000step(약 3.5일) 동안 훈련됨.
5.3 Optimizer
- Adam 옵티마이저 사용.
- 하이퍼파라미터 :
- learning rate는 다음 공식에 따라 조정됨. (처음 warmup_steps 동안 선형적으로 학습률을 증가시키고, 이후에는 step 수의 역제곱근에 비례하여 감소)
- warmup_steps=4000으로 설정함.
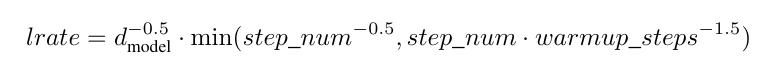
5.4 Regularization
- 학습 중 세 가지 유형의 정규화 사용
- Dropout
- 각 서브 레이어의 출력에 Dropout 적용 후, 이를 서브 레이어의 입력에 더함. (정규화 이전에 수행)
- Decoder 및 Encoder 스택에서 임베딩과 위치 인코딩의 합에도 Dropout 적용
- Base model에선,
- Label Smoothing : 훈련 과정에 Label Smoothing 기법을 사용했으며, 스무딩 값으로 0.1을 설정함. (모델이 덜 확신하도록 학습되므로 perplexity 성능은 저하되나, 정확도와 BLEU score를 향상시키는 효과)
** Label Smoothing이 처음 보는 기법이라 찾아봤는데, 이는 모델이 너무 확신하는 것을 방지하고, 일반화를 향상시키기 위해 정답 라벨을 약간 부드럽게 하는 기법으로, 정답 클래스의 확률을 100%로 설정하는 것이 아니라, 일정 비율로 다른 클래스에도 분포하도록 조정한다고 한다.
예를 들어, 기존 원-핫 라벨을 사용하면 y = [0, 1, 0]와 같이 확실한 답을 가지지만, Label Smoothing을 적용할 시 y_smooth = [0.05, 0.90, 0.05]와 같이 확률을 분산시킨다. 이를 통해 과적합을 방지할 수 있다.
6. Results
6.1 Machine Translation
- WMT 2014 영어-독일어 번역 작업
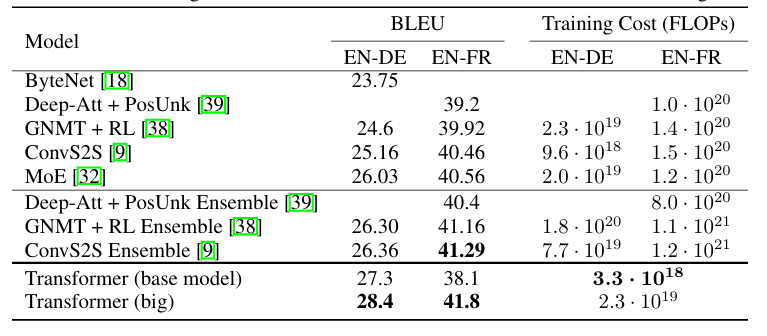
- Big transformer 모델은 이전에 보고된 모든 최고 성능 모델(앙상블 포함)보다 2.0 BLEU 이상 높은 점수를 기록하며, 새로운 최첨단 BLEU 점수인 28.4를 달성함.
- 모델 구조

- 8개의 P100 GPU에서 3.5일이 소요되었으며, Base model 또한 이전에 발표된 모든 단일 모델 앙상블보다 성능이 뛰어나며, 경쟁 모델들보다 훨씬 적은 훈련 비용으로 성능을 달성함.
- WMT 2014 영어-프랑스어 번역 작업
- Big Model은 BLEU 점수 41.0을 기록하며, 이전까지 발표된 모든 단일 모델보다 높은 성능을 달성하였으며, 이전 최고 성능 모델 대비 훈련 비용이 1/4 이하임.
- Big Model은 기본적으로 (이전 모델의 설정은 0.3)
- 기본 모델의 경우, 10분 간격으로 저장된 마지막 5개 체크포인트를 평균 내어 단일 모델을 생성하고, 대형 모델의 경우 마지막 20개의 체크포인트를 평균냄.
- Beam search를 사용했으며, Beam size는 4, 길이 패널티 α = 0.6으로 설정 (하이퍼파라미터는 개발 세트에서의 실험을 통해 선택됨)
- 추론 과정에서 최대 출력 길이는 입력 길이 + 50이며, 가능한 경우 조기 종료를 수행함.
- 실험 결과 요약 및 기존 아키텍처와의 번역 품질, 훈련 비용 비교
- 모델 훈련에 사용된 부동소수점 연산량은 훈련 시간, 사용된 GPU 개수, 각 GPU의 지속적인 단정밀도 부동소수점 연산 성능 추정치를 곱하여 추정함.
6.2 Model Variations
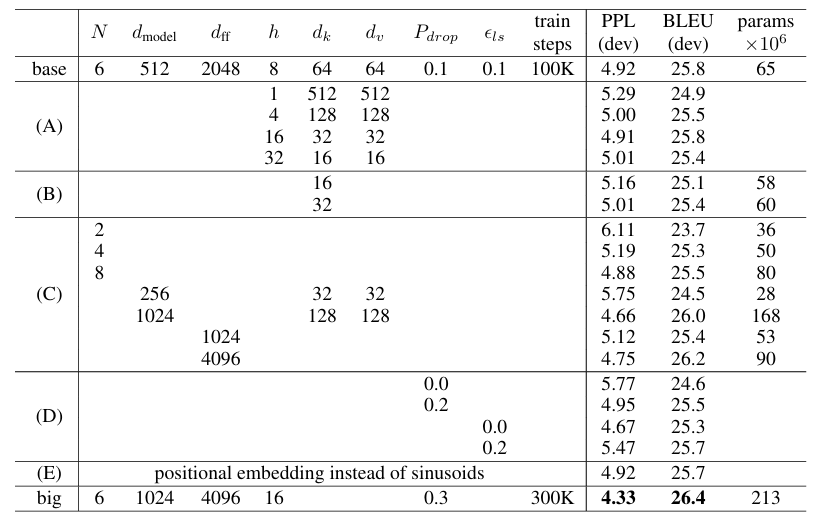
Transformer 구성 요소의 중요성 평가를 위해 Base model을 여러 방식으로 변경하며 실험을 진행했으며, 이후 개발 세트(netstest2013)의 영어-독일어 번역 성능 변화를 측정함. 이때 Beam search는 이전 섹션에서 설명한 방식으로 사용했으나 체크포인트 평균화는 적용하지 않음.
- (A) : 어텐션 헤드 수와 어텐션 Key, Value의 차원을 변경하되, 전체 연산량은 일정하게 유지함(3.2.2). 단일-헤드 어텐션의 경우 최적 설정 대비 BLEU 점수가 0.9 감소했으며, 헤드 개수가 너무 많으면 성능이 저하됨.
- (B) : 어텐션 키 크기() 감소 시 모델 성능이 저하되며, 호환성 결정이 쉽지 않음. (단순한 내적 방식보다 더 정교한 compatibility function이 유용할 수 있음을 시사함)
- (C), (D) : 더 큰 모델이 더 나은 성능을 보이며, Dropout이 과적합 방지에 매우 효과적임.
- (E) : sinusoidal positional encoding을 learned positional embeddings로 교체했고, 기본 모델과 거의 동일한 성능을 기록함.
6.3 English Constituency Parsing
Transformer가 다른 작업에도 일반화되는지 평가하기 위해 영어 구성 구문 분석 실험을 수행했으며 이 작업은 특정한 도전 과제를 포함함.
1. 출력이 강한 구조적 제약을 받음.
2. 출력 길이가 입력보다 훨씬 김.
3. RNN 기반 sequence-to-sequence 모델들은 소규모 데이터 환경에서 최첨단 성능을 달성하지 못함.
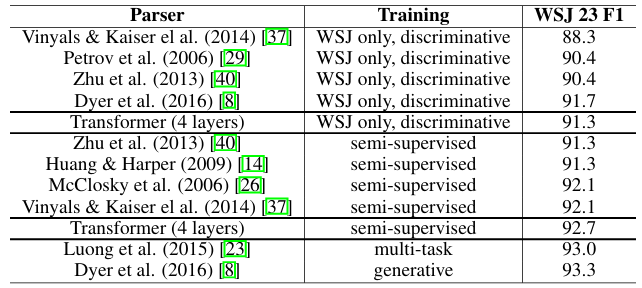
- 4-layer transformer 모델()을 WSJ 데이터셋(약 40K의 training sentence)에서 훈련하였으며, 반지도 학습도 수행함.
- 신뢰도가 높은 Berkeley Parser 코퍼스를 사용했으며, 이는 약 1,700만 개 문장으로 구성됨.
- WSJ 단독 학습 (only setting)) : 16K 토큰의 어휘 사용
- 반지도 학습 (semi-supervised setting) : 32K 토큰의 어휘 사용
- 추론 시, maximum output length = input length + 300
- Beam size = 21, α = 0.3
- 이때, WSJ 단독 학습 및 반지도 학습 환경 모두 동일한 설정임.
- task-specific tuning의 부재에도 Transformer 모델은 놀라운 성능을 보였으며, Recurrent Neural Network Grammar(RNNG)를 제외하고 이전에 보고된 모든 모델들보다 더 나은 결과를 달성함.
- RNN 기반 sequence-to-sequence 모델과는 달리, 40K 문장의 WSJ 학습 세트에 대해서만 학습하더라도 Berkeley Parser보다 높은 성능을 기록함.
7. Conclusion
- Transformer는 오직 Attention만을 기반으로 시퀀스 변환을 수행하는 최초의 모델로, 기존 인코더-디코더 구조에서 가장 일반적으로 사용되던 Recurrent layer를 Multi-Headed Self-Attention으로 대체하였다.
- WMT 2014 영어-독일어 및 영어-프랑스어 번역 작업에서도 최신 성능을 달성했으며, 특히 영어-독일어 번역 작업에서는 이전까지 보고된 모든 앙상블 모델을 능가하는 최고 성능을 기록했다.
- Transformer를 텍스트 이외의 입력 및 출력 모달리티(예: 이미지, 오디오, 비디오 등)를 포함하는 문제로 확장하고, 더욱 효율적으로 대규모 입력 및 출력을 처리할 수 있도록 국소적이고 제한된 어텐션 메커니즘을 연구할 예정임.
- 아울러, 순차적 생성 방식을 줄이는 것 역시 연구 목표 중 하나임.
정리
RNN 또는 CNN을 기반으로 하는 방식은 시퀀스를 처리하는 데 병렬성이 부족하며, 긴 문장에서 계산 비용이 증가하는 문제가 있다. Transformer 모델은 이 문제를 해결하기 위해 등장한 모델이다. 이 모델은 RNN과 CNN을 완전히 배제하고, 전적으로 Attention Mechanism만을 사용한다.
기존 RNN 계열 모델(LSTM, GRU)은 장기 의존성(long-term dependency) 문제를 가지며, 긴 문장에서 과거 정보를 잊어버리는 경향이 있었다. 또한, RNN 계열 모델은 이전 시점의 출력을 현재 시점의 입력으로 사용하기 때문에(Sequential Dependency) 각 time step을 순차적으로 처리해야 해서 병렬성이 떨어졌다.
CNN 계열 모델은 고정된 커널 크기와 입력 크기를 사용하므로, 학습한 입력 크기와 다른 길이의 시퀀스를 처리하는 데 어려움이 존재했다.
그래서 이를 해결하기 위해 나온 것이 Attention Mechanism이다. 이는 긴 문장에서 중요한 정보를 유지하면서 필요한 정보를 선택적으로 집중해서 사용하기 위해 등장했으며, 디코더에서 출력 단어를 예측하는 매 시점(time step)마다 인코더에서의 전체 입력 문장을 다시 한 번 참고하는 방식을 사용한다. 이러한 어텐션 매커니즘이 CNN이나 RNN 없이 잘 동작하는 이유는 순차적 종속성을 제거(모든 요소를 한 번에 참고하기 때문에 순서에 얽매일 필요가 없음)하고, 병렬성을 극대화하는 구조적 특성을 지니고 있기 때문이다.
하지만, 이러한 Attention Mechanism은 어텐션 가중치가 적용된 여러 위치를 평균화하는 과정에서 세부적인 정보가 손실될 수 있다는 단점이 있었는데, Transformer에서는 이러한 단점을 Multi-Head Attention을 통해 해결한다. 이는 다양한 패턴을 학습하기 위해 여러 개의 독립적인 Attention을 동시에 사용하는 방식으로 Single-Head Attention과 비슷한 계산 비용으로 더 좋은 결과를 낼 수 있다.
Transformer에서는 번역 작업, 영어 구성 구문 분석 등 다양한 문제에 대해 일반화 성능을 지니고 있으며, 텍스트 이외에 이미지, 오디오, 비디오 등을 포함한 문제에서도 더 좋은 결과를 낼 것으로 예상되어 이에 관해 연구할 예정이다. (실제로, 더 찾아보면 알게 되겠지만, Transformer 이후에 Vision 분야에서 ViT와 같은 transformer를 활용한 모델들이 등장한다.)
