논문 리뷰
1.ResNet
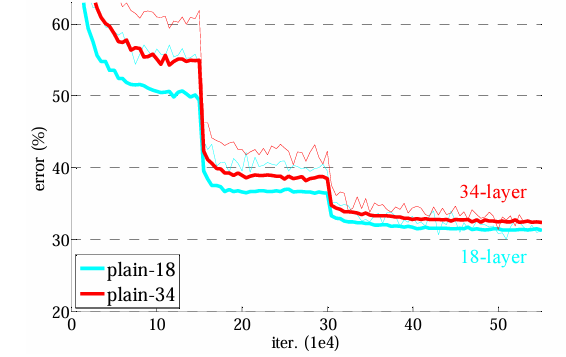
오늘은 ResNet 논문을 리뷰해 보고자 한다. 일단, 처음 받아서 읽은 논문인 만큼, 처음부터 다 이해할 수 있을 거란 생각은 안 했고... 이해할 수 있는 만큼 하고자 노력했다. 아직 완벽히 이해한 건 아니지만, 그래도 정리해보는
2.Attention Is All You Need

Abstract 기존의 시퀀스 변환 모델들은 대부분 복잡한 RNN 또는 CNN을 기반으로 하며, 가장 성능이 좋은 모델들은 인코더와 디코더를 어텐션 매커니즘을 통해 연결한다. 이 논문에서는 Transformer라는 새로운 네트워크 아키텍쳐를 제안한다. Transformer는 전적으로 어텐션 메커니즘에 의존하며, 순환 구조(recurrence)와 합성곱(c...
3.Vision Transformer 논문 리뷰

이때 당시에 자연어처리에서의 Transformer 아키텍처는 사실상 표준이 됐지만, 컴퓨터 비전 분야에서의 적용은 제한적이었다. 그래서 NLP에서 Transformer가 성공적으로 확장된 것에서 착안하여, CNN과 비슷한 구조를 Self-Attention과 결합하는
4.DenseNet
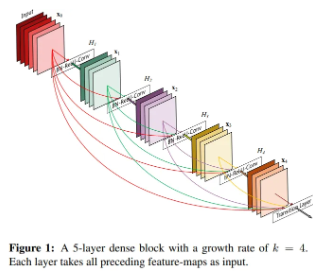
DenseNet은 각 층을 피드포워드 방식으로 다른 모든 층과 직접 연결함.일반적인 합성곱 신경망은 L개의 층이 존재할 때, N개의 연결(즉, 각 층이 그 다음 층과만 연결됨)만을 지니는 반면, DenseNet은 L(L+1)/2 개의 직접 연결을 지님. (즉, 각 층
5.GoogLeNet
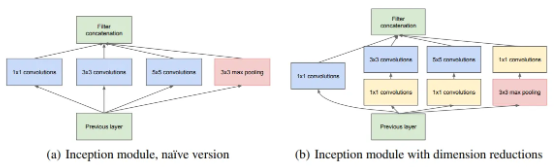
네트워크 내부의 컴퓨팅 자원 활용을 크게 개선한 모델성능 최적화를 위해 Hebbian principle와 multi-scale processing(여러 크기 필터 동시 적용)을 적용함.이 당시까지의 최신 트렌드는, 레이어 수를 늘리고, 레이어 크기를 키우는 방향으로 발
6.Xception
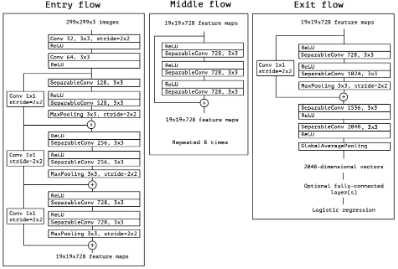
Inception 모듈 : 일반적인 합성곱 연산-Depthwise Separable Convolution의 중간 단계Depthwise Separable Convolution : 매우 많은 수의 tower를 가진 Inception 모듈tower : Inception에서
7.MobileNet
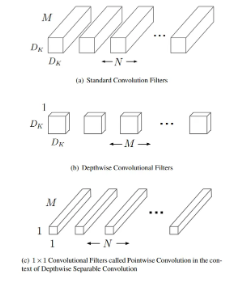
기존에 작고 효율적인 신경망 구축 방법 → 사전 학습된 네트워크 압축 or distillation (큰 네트워크가 작은 네트워크를 가르치는 방식) → 후자의 방법은 MobileNet 접근과 상호보완적임.MobileNet → 모델 개발자가 직접 작은 네트워크 선택할 수
8.Efficientnet
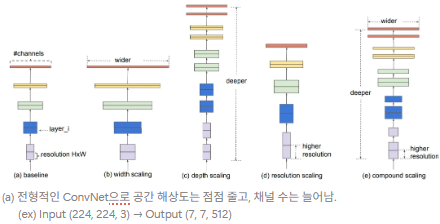
기존 연구 : depth, width, resolution 중 하나를 확장해 정확도를 높이는 것이 일반적이고, 두 개 또는 세 개 차원을 임의로 확장할 수도 있으나, 수많은 수작업 조정 과정의 필요 & 최적이 아닌 성능이나 효율성을 낼 가능성이 존재함.핵심 질문 : “
9.Group Normalization
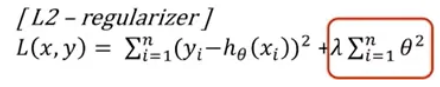
배치 정규화(Batch Norm, BN) : (미니)배치 내에서 계산된 평균과 분산으로 특성 정규화배치 통계의 확률적 불확실성은 일반화를 향상시키는 정규화로 작용하기도 함.배치 차원에서 정규화하는 독특한 동작으로 인해 충분히 큰 크기의 배치가 필요(ex. 작업자당 32
10.AlexNet
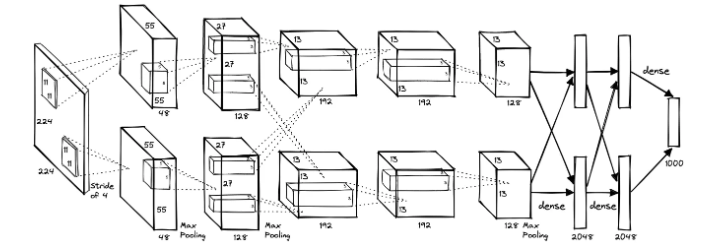
설정 수치에서 나오는 ILSVRC는 ImageNet Large Scale Visual Recognition Challenge 의 약자로, 매년 열린 이미지 인식 대회이다.2010년 데이터셋의 특징 :테스트 데이터의 정답 레이블이 공개되어 있어, 연구자들이 모델을 학습