Introduction
등장 배경
이때 당시에 자연어처리에서의 Transformer 아키텍처는 사실상 표준이 됐지만, 컴퓨터 비전 분야에서의 적용은 제한적이었다.
그래서 NLP에서 Transformer가 성공적으로 확장된 것에서 착안하여, CNN과 비슷한 구조를 Self-Attention과 결합하는 연구가 많이 수행됐고, 일부 연구에서는 컨볼루션을 완전히 대체하기도 했으나, 이러한 구조는 이론적으론 효율적임에도 불구하고 최신 하드웨어 가속기에서 효과적으로 확장되지 못한다는 단점이 있었다.
이러한 이유에서 대규모 이미지 인식에선 ResNet과 같은 기존 아키텍처를 활용해 왔다.
ViT
이러한 상황에서, ViT는 CNN에 의존하는 모델의 구조에서, CNN에 대한 의존 없이 이미지를 patch로 분할하고 각 패치의 선형 임베딩을 모델에 입력되는 시퀀스로 변환한 뒤 Transformer를 적용해 우수한 성능을 이끌어냈다.
이러한 Vision Transformer의 성능을 살펴보면, ImageNet과 같은 중간 규모 데이터셋에서 정규화 없이 훈련한 경우 모델 정확도는 유사한 크기의 ResNet보다 조금 낮은 수준으로 나타났고, 모델을 더 큰 데이터셋에서 훈련하면 좋은 성능을 보였는데 이러한 차이를 보이는 이유는 Inductive bias 때문이다.
Inductive bias는 Training에서 보지 못한 데이터에 대해서도 적절한 귀납적 추론이 가능하도록 하기 위해 모델이 가지고 있는 가정들의 집합을 의미한다.
예를 들어, "Convolutional 계층은 작은 크기의 커널로 이미지를 지역적으로 보며, 동일한 커널로 이미지 전체를 본다는 점에서 locality와 transitional invariance를 지닌다.", "Recurrent 계층은 입력한 데이터들이 시간적 특성을 가지고 있다고 가정하므로 sequentiality와 temporal invariance를 지닌다."와 같이, 귀납적 추론이 가능하게 하는 가정들의 집합을 Inductive bias라고 한다. 이러한 Inductive bias는 모델의 일반화 성능을 높여주는 효과가 있는데, Vision Transformer에서는 패치 추출 과정이나, 파인 튜닝 과정에서의 해상도 조정 과정에서만 Inductive bias가 수동으로 적용되기 때문에 모든 관계들을 직접 학습시켜 주어야 한다. 그래서 작은 데이터셋에서는 성능이 조금 낮고, 데이터셋이 커질 수록 성능이 좋은 현상이 나타나는 것이다.
Method
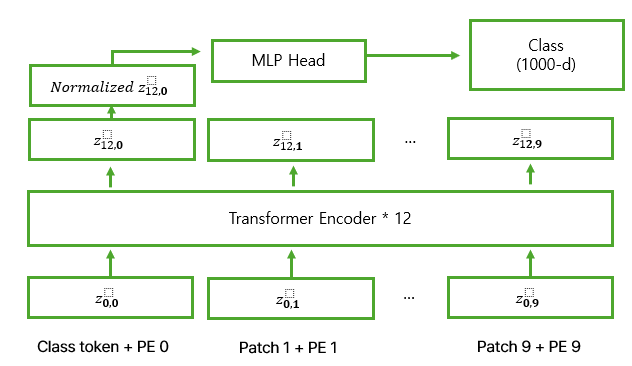
ViT의 구조는 아래의 사진과 같으며, 사진에서도 볼 수 있듯이 모델 설계에서 원래의 Transformer를 가능한 한 그대로 따르고 있는 것을 확인할 수 있고, 이러한 특성 때문에 NLP Transformer 아키텍처의 확장성과 효율적인 구현의 장점을 거의 그대로 활용할 수 있다.
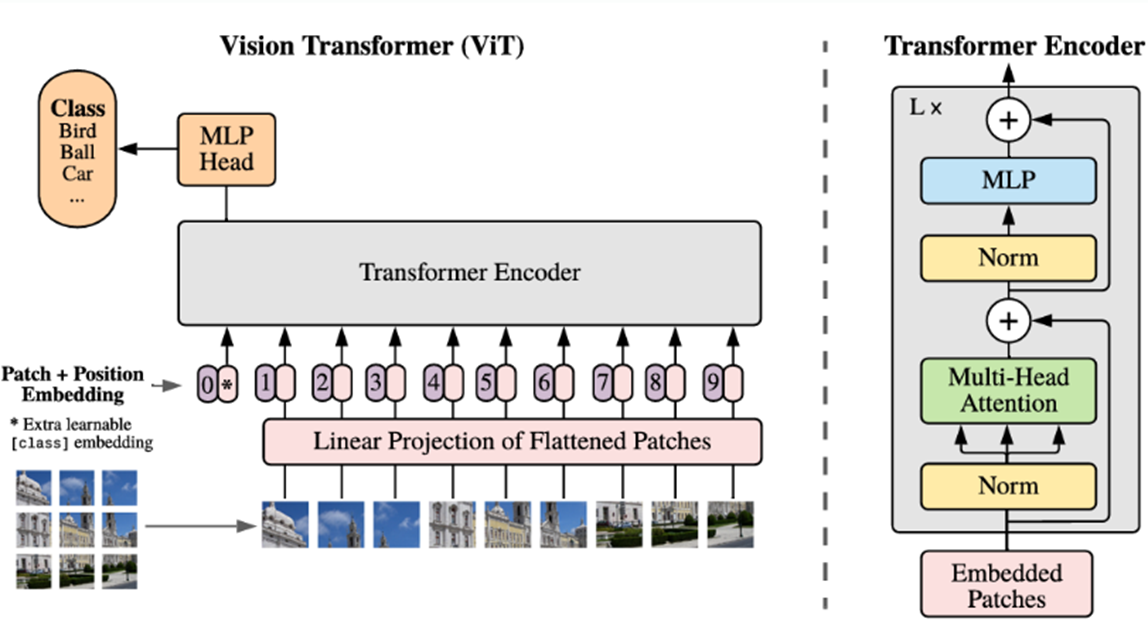
모델의 작동 과정을 천천히 살펴보자. 일단, 이미지를 패치로 나누고, 패치 임베딩을 진행한다. 패치 임베딩은 (H x W x C)로 구성된 이미지를, ((패치 개수, 각 패치의 Flatten된 벡터 크기), 즉 (N, D))로 변환하는 과정을 의미한다.
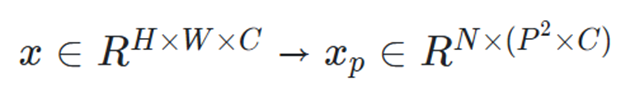
이때 은 한 패치의 크기를, N은 패치의 개수를 의미하며, 패치 개수는 다음과 같이 계산될 수 있다.
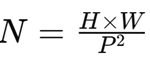
패치 임베딩을 진행하고 나면, Position Embedding을 지정해 줘야 한다. 이때, Position Embedding을 Patch Embedding의 결과에 더해주기 전에, 맨 앞에 [CLS] 토큰을 붙여주고 N+1개 만큼의 PE를 더해주어야 한다.
이러한 [CLS] 토큰은 BERT 모델에서 문장 앞에 [CLS] 토큰을 추가해 문장 전체를 대표하는 벡터로 사용하던 것에서 유래하였는데, 이렇게 추가하면 초기 [CLS] 토큰은 별다른 정보를 담지 않은, learnable한 토큰이기 때문에 점차 학습을 해나가면서 이미지 전체를 대표하는 Global한 정보를 담게 된다. (그리고 후에 Classification을 할 때, 이러한 [CLS] 토큰이 담은 정보를 활용하게 된다. [CLS] 토큰의 최종 출력 벡터 = 이미지 전체의 대표 벡터 = y이기 때문이다.)
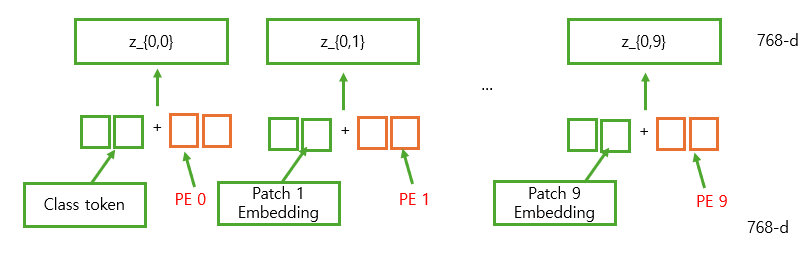
이렇게 이미지를 패치 단위로 나누고, Position Embedding을 하고 나면, 이 값을 Transformer Encoder의 입력값으로 넣게 된다. Encoder 블록 내부에선 MSA, MLP 앞에서 LayerNorm이 적용되며, 결과로 나온 값에 대해 Multi-Head Self Attention을 수행하여 Attention Map을 계산한 후, Value와 결합하여 변환된 벡터를 출력한다.
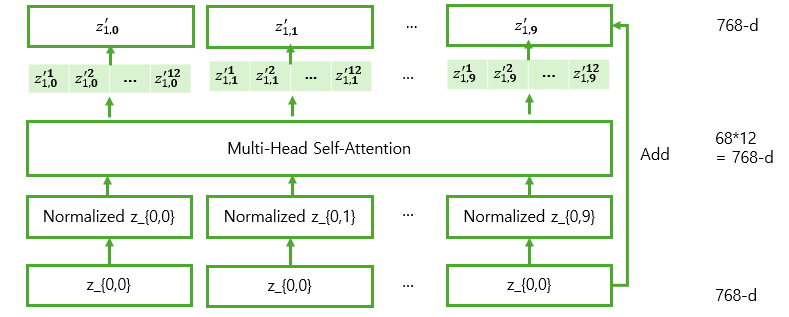
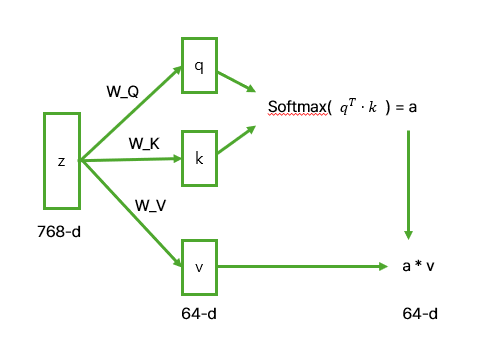
MSA 내부에선, 기존의 Multi-Head Self-Attention과 동일하게 여러 개의 Self-Attention 연산이 병렬적으로 수행되며, 각 헤드에서 독립적으로 계산된 후 최종적으로 결합된다.
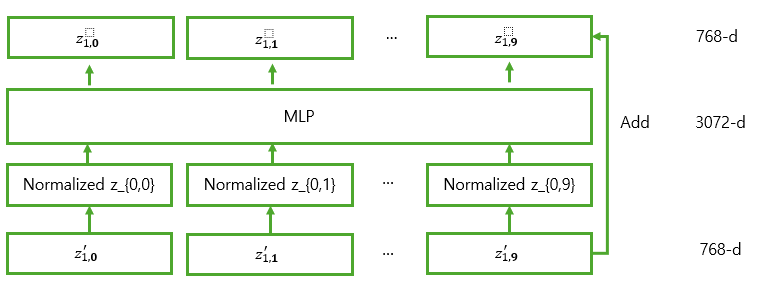
이렇게 MSA를 거친 결과가 MLP에 들어가기 전, 또 다시 LayerNorm을 적용하고 MLP를 거쳐 개별 벡터에 비선형성을 추가해 준다.
이렇게 Encoder를 거쳐 나온 결과 중 Class Token의 최종 출력 결과에 대해 Normalized를 적용해 주고, MLP Head를 거쳐 최종 Classification을 수행한다. (이때, [CLS] 토큰의 결과를 사용하는 것은 앞에서도 말했듯이, 이미지 전체의 전역적인 정보를 담고 있기 때문이다)
이게 ViT 모델의 전체적인 개요이다. 한 가지 더 특징이 있다면, Pre-training 과정에서의 MLP head는 한 개의 은닉층과 비선형성이 포함된 2-layer MLP로 시행되며, Fine-Tuning 단계에서는 비선형성이 포함되지 않은 Single linear layer로 시행된다. 이렇게 MLP의 동작 방식을 다르게 하는 이유는, Pre-training 과정에선 일반적인 표현 학습이 중요하고 Fine-Tuning 단계에선 이미 학습한 Feature를 활용해 과적합을 방지하는 것이 중요하기 때문이다.
Inductive bias
앞에서도 말했듯, Vision Transformer는 CNN보다 이미지별 Inductive bias가 훨씬 적다.
CNN은 locality, neighborhood structure, translation equivariance가 모델 전체의 각 레이어에 내재되어 있으며, ViT는 MLP 레이어만 지역적으로 translation equivariance를 지니고, Self-Attention 레이어는 전역적이며, neighborhood structure는 매우 제한적으로 사용되는데, 이 경우는 앞에서도 말했듯이 패치 분할, Fine-Tuning 과정에서 서로 다른 해상도의 이미지 처리 시 위치 임베딩 조정 과정에만 활용된다.
또, 초기 위치 임베딩에는 위치 정보가 포함되지 않는다는 특징도 있는데, 이것의 의미는 Positional Embedding에서 위치를 학습하는 방식이 Standard learnable 1D Embedding 방법이기 때문에, 초기에는 별다른 정보가 없는 learnable한 PE를 더해주고, Training 과정에서 모든 공간적 관계를 학습해 나간다. 이러한 이유에서 ViT는 데이터가 적으면 일반화 성능이 떨어진다는 특징이 있다.
Hybrid Architecture
Hybrid Architecture는 원본 이미지를 직접 패치로 나누지 않고, CNN을 통해 추출한 Feature Map을 Transformer의 입력으로 사용하는 아키텍처를 의미한다. 원래의 패치 임베딩과 유사한 방식으로 Feature Map을 Flatten하여 Transformer의 입력으로 사용하는데, 만일 패치 크기가 1*1의 크기를 지닌다면 더이상 패치로 자를 수 없고, 개별 픽셀 수준의 Feature를 유지해야 하기 때문에, 이런 경우엔 단순히 공간적 차원을 Flatten하여 Transformer 토큰으로 변환한다.
Fine-Tuning and Higher Resolution
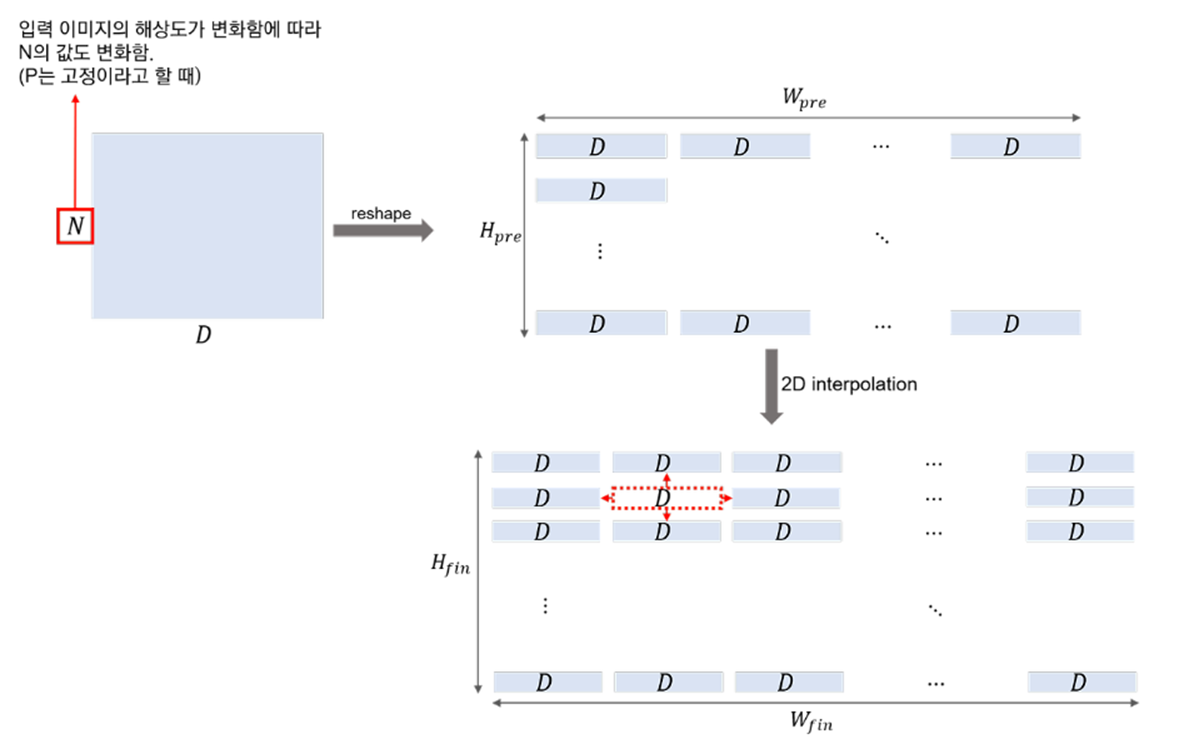
일반적으로 ViT는 대규모 데이터셋에서 사전 학습한 후, 더 작은 다운스트림 작업에 Fine-tuning하는데, Fine-tuning 시, 사전 학습보다 높은 해상도를 사용하는 것이 유리할 수 있다.
이를 위해 해상도(W*H)를 증가시키게 되면, 패치 크기()는 유지되지만, 패치 개수가 증가하여 Transformer가 더 긴 시퀀스를 처리하게 된다. 사실, ViT는 메모리 제한 내에서 임의의 시퀀스 길이를 처리할 수 있기에 동작하는 것엔 문제가 없지만, Position Embedding이 기존 패치 개수 N에 맞춰 학습됐기에 해상도 증가로 패치 수가 늘어나면서 사전 학습된 Position Embedding이 유효하지 않은 문제가 발생할 수 있다.
이를 해결하기 위해 원본 이미지에서의 위치에 맞게 Position Embedding도 2D 보간을 적용해 값을 채워준다.
Experiments
Transfer Learning 성능 비교
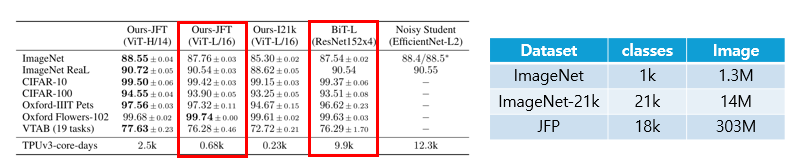
ViT는 기존 SOTA 모델과 성능이 비슷하거나, 그것보다 더 좋은 성능을 보이며, 하루 동안 훈련시키는 데 필요한 TPUv3-core-days의 수도 다른 모델들에 비해 적은 것을 확인 할 수 있다.
크기 증가에 따른 성능 변화
- ImageNet : 적절한 정규화를 적용했음에도 ViT-Large 모델이 ViT-Base 모델보다 성능이 낮음.
- ImageNet-21k : ViT-L과 ViT-B 성능이 유사함.
- JFT-300M : 큰 모델일 수록 더 우수한 성능 (대규모 데이터셋에서만 ViT-Large 모델 장점이 극대화됨)

무작위 샘플링된 서브셋에서의 성능 비교
- 추가적인 정규화 기법을 적용하지 않고, 모든 설정에서 동일한 하이퍼파라미터 사용함.
- 조기 종료를 적용하고 최고 검증 정확도를 보고함.
- ViT가 ResNet보다 과적합이 심함

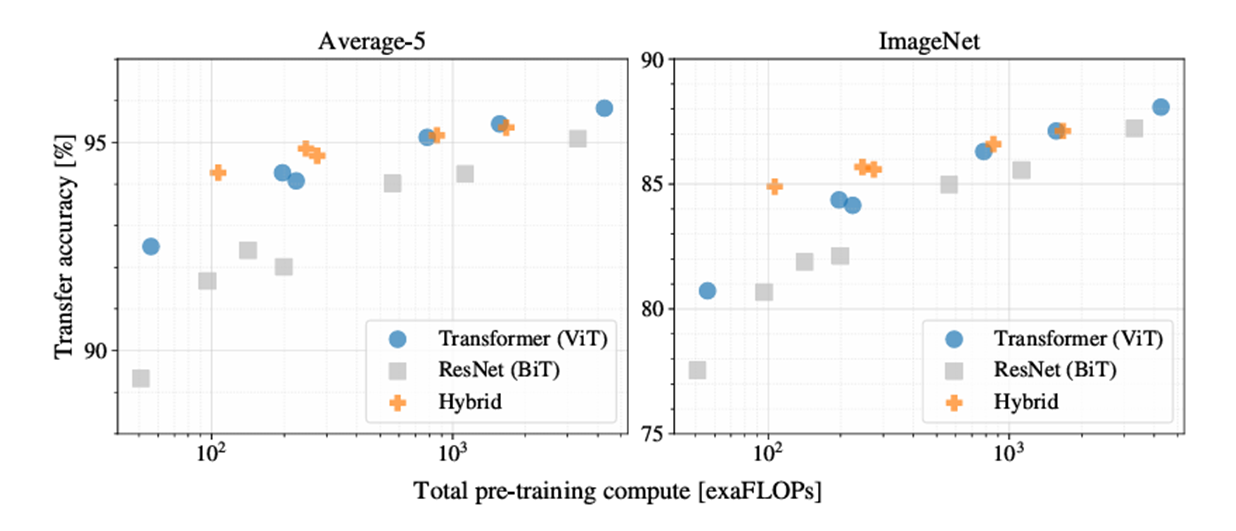
각 모델의 성능과 pre-training cost 간의 관계 비교
- ViT가 성능과 cost의 trade-off에서 ResNet (BiT)보다 우세함.
- Cost가 증가할수록 Hybrid와 ViT의 성능과 trade-off 차이가 감소함.
- 즉, 더 많은 연산 자원을 투입하면 Hybrid 모델도 ViT에 근접한 성능을 낼 수 있음.
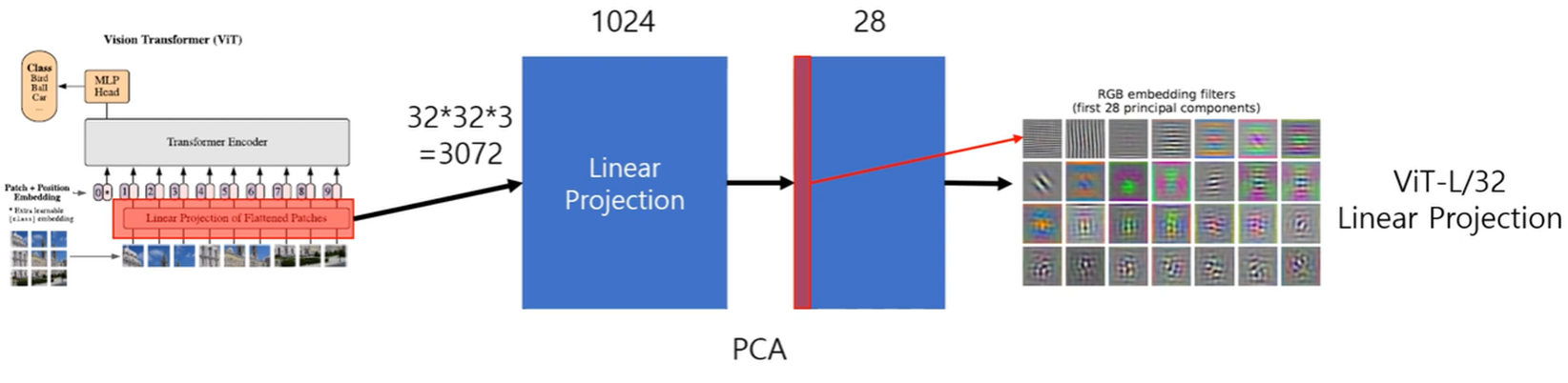
ViT가 이미지를 어떻게 처리하는지 이해를 위한 실험
ViT-L/32의 Linear Projection 시각화
- 학습이 끝난 Convolution filter를 시각화한 것과 유사함.
- 학습이 잘 된 ViT는 CNN과 유사한 역할을 수행함.
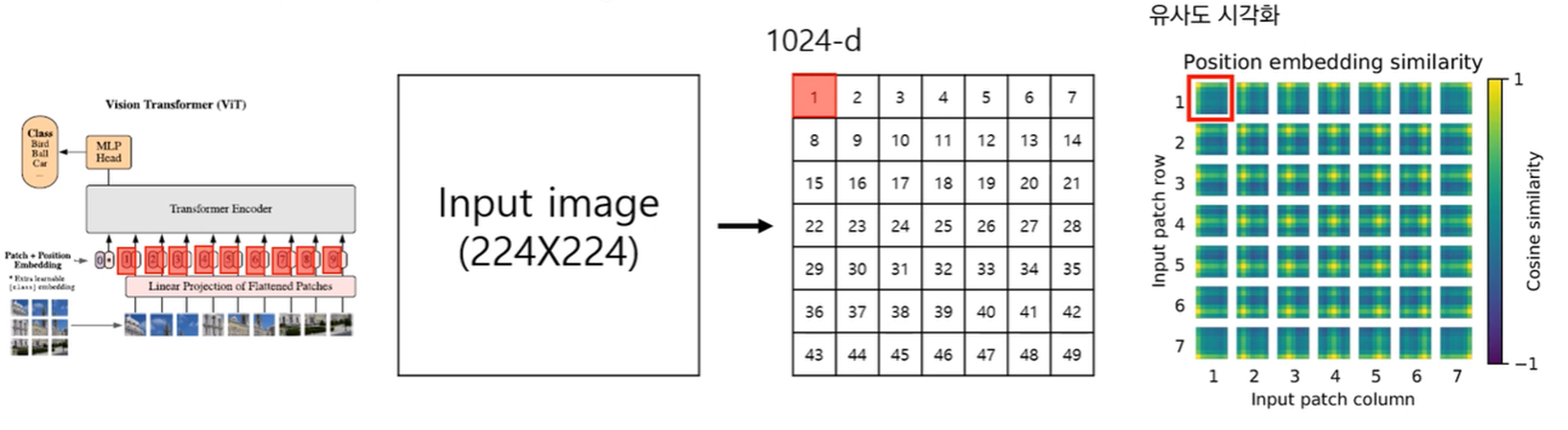
ViT-L/32의 Position Embedding 시각화
- 거리적으로 가까운 위치에 있는 Position Embedding의 유사도는 높다.
- 어떤 Position Embedding을 기준으로 삼더라도 경향성은 동일하다.
ViT-L/16 모델의 각 Transformer 레이어에서 Attention Head가 얼마나 먼 거리의 토큰과 상호작용하는지 시각화
- ViT의 레이어별 평균 Attention distance를 확인한 결과, 초반 레이어에서도 Attention을 통해 이미지 전체의 정보를 통합하여 사용함을 알 수 있음.
- 초기 레이어에서의 평균 Attention distance가 작은 값에만 몰려있지 않고, 넓은 범위까지 분포하고 있기 때문
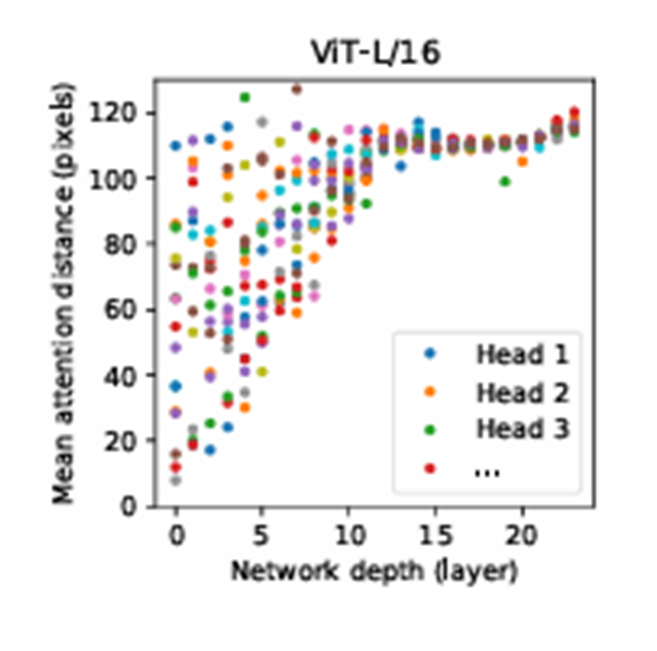
Internal Representation 분석
- Self-Attention 매커니즘을 통해 ViT는 lowest layers에서도 이미지 전역적인 정보를 통합할 수 있으며, 하위 계층에서도 일관적으로 작은 Attention distance가 유지되므로 초기 컨볼루션 계층과 유사한 역할을 수행할 가능성이 높음.
- 네트워크 깊이가 증가할수록 Attention distance도 증가하므로 더 넓은 영역 고려함.
- ViT는 Self-Attention을 통해 이미지 내 중요한 영역(특히 Classification에 중요한 의미론적 영역)에 집중하는 경향이 존재함.

Conclusion
- ViT는 Transformer를 이미지 인식에 직접 적용함.
- 기존의 컴퓨터 비전에서 Self-Attention을 사용하는 연구들과 달리, ViT는 초기 패치 추출 과정을 제외하곤 아키텍처에 이미지 특유의 inductive bias를 도입하지 않는 대신, 이미지를 패치의 시퀀스로 해석하고 NLP에서 사용되는 표준 Transformer 인코더로 이를 처리함.
- 이러한 전략은 대규모 데이터셋에서 사전 학습과 결합될 경우 잘 작동하며, ViT는 여러 이미지 분류 데이터셋에서 최첨단 성능을 달성하거나 이를 뛰어넘으면서도, 상대적으로 사전 학습 비용이 저렴함.
참고 - 추가적인 정리
ViT
Vision Transformer는 CNN에 의존하는 기존 모델 구조에서, CNN에 대한 의존 없이 이미지를 패치 단위로 분할하고, 각 패치의 선형 임베딩을 모델에 입력되는 시퀀스로 변환 후 Transformer를 적용해 우수한 성능을 이끌어낸 모델임.
Patch Embedding
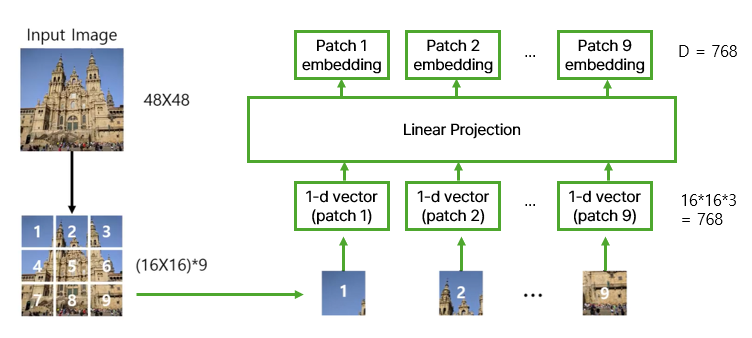
- Transformer는 일반적으로 1D 토큰 임베딩 시퀀스를 입력으로 받는데, 이미지는 본래 2D 형태(HWC)이므로 이미지를 Flatten된 패치의 시퀀스로 변환해야 함.
- 여기선 16163 = 768. 즉, 한 패치엔 총 768개의 픽셀 값(=입력 채널)이 존재함.

torch._assert(condition, message): 조건에 해당하는지 검사하고, 틀리면 문구 출력
def _process_input(self, x: torch.Tensor) -> torch.Tensor:
# 입력 이미지 크기가 설정한 이미지 크기와 맞는지 확인
n, c, h, w = x.shape
p = self.patch_size
torch._assert(h == self.image_size, f"Wrong image height! Expected {self.image_size} but got {h}!")
torch._assert(w == self.image_size, f"Wrong image width! Expected {self.image_size} but got {w}!")
# 패치 크기대로 분리
n_h = h // p # 세로로 n_h개 패치
n_w = w // p # 가로로 n_w개 패치
# (n, c, h, w) -> (n, hidden_dim, n_h, n_w)
x = self.conv_proj(x) # conv2d 함수를 활용해 이미지를 패치 임베딩
# (n, hidden_dim, n_h, n_w) -> (n, hidden_dim, (n_h * n_w))
# 패치 벡터들의 시퀀스로 reshape (flatten)
# (ex) (n, hidden_dim, 14, 14) -> (n, hidden_dim, 196)
x = x.reshape(n, self.hidden_dim, n_h * n_w)
# 축 변환 함수 (permute)
# Self-Attention은 (batch_size, seq_len, embed_dim) 형태를 기대하기에
# 차원 순서를 변환해 주어야 함.
# (n, hidden_dim, seq_len)인데 → 순서를 바꿔서 (n, seq_len, hidden_dim)
# (n, hidden_dim, (n_h * n_w)) -> (n, (n_h * n_w), hidden_dim)
# The self attention layer expects inputs in the format (N, S, E)
# where S is the source sequence length, N is the batch size, E is the
# embedding dimension
x = x.permute(0, 2, 1)
return x(conv_proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))self.conv_proj = nn.Conv2d(
in_channels=3, out_channels=hidden_dim, kernel_size=patch_size, stride=patch_size
)- 패치 임베딩 후 flatten, cls 토큰 추가와 같은 부분은 forward pass에 나타남.
self.class_token = nn.Parameter(torch.zeros(1, 1, hidden_dim)) # (배치, 토큰, 임베딩 차원) // vision transformer
def forward(self, x: torch.Tensor):
# Reshape and permute the input tensor
# 이 부분에서 패치 임베딩
# 결과는 (n, (n_h * n_w), hidden_dim) 형태의 패치 임베딩된 이미지
x = self._process_input(x)
n = x.shape[0] # n = 배치 크기 (한 번에 몇 개의 이미지를 처리할 것인지)
# Expand the class token to the full batch
# 인자가 -1이면 해당 차원은 그대로 두므로
# (1, 1, hidden_dim) → (n, 1, hidden_dim)
# 즉, 각 이미지마다 필요한 독립적인 class token을 배치 크기만큼 추가
# 만약 배치 크기가 3이라면, 이런 형태의 cls token이 만들어짐!
# [
# [[0, 0, 0, ..., 0]], # ← 첫 번째 이미지의 class token (768 차원짜리 벡터 1개)
# [[0, 0, 0, ..., 0]], # ← 두 번째 이미지의 class token
# [[0, 0, 0, ..., 0]] # ← 세 번째 이미지의 class token
# ]
batch_class_token = self.class_token.expand(n, -1, -1)
# concat (원래의 시퀀스 앞에 붙임)
# torch.cat에서 dim=0 : 행 방향, dim=1 : 열 방향 이어 붙이기
# (n, num_patches, hidden_dim) -> (n, num_patches + 1, hidden_dim)
x = torch.cat([batch_class_token, x], dim=1)
# 인코더에 넣기
x = self.encoder(x)
# Classifier "token" as used by standard language architectures
x = x[:, 0] # 클래스 토큰만 뽑기
# MLP나 Linear layer에 넣어서 원하는 클래스 수만큼 출력 (최종 분류)
x = self.heads(x)
return x # EncoderBlock
def forward(self, input: torch.Tensor):
# 입력 텐서가 (배치, 시퀀스 길이, 임베딩 차원) 형태인지 확인
torch._assert(input.dim() == 3, f"Expected (batch_size, seq_length, hidden_dim) got {input.shape}")
# Layer Norm
x = self.ln_1(input)
# Multi-head Self-Attention
# self.self_attention = nn.MultiheadAttention(hidden_dim, num_heads, dropout=attention_dropout, batch_first=True)
x, _ = self.self_attention(x, x, x, need_weights=False)
# Dropout
x = self.dropout(x)
# Residual Connection
x = x + input
# Layer Norm
y = self.ln_2(x)
# MLP
y = self.mlp(y)
return x + y # Residual ConnectionEncoder
- 전형적인 Vision Transformer Encoder Block
- 패치 임베딩 → 인코더 (드롭아웃, LayerNorm → MultiheadAttention → LayerNorm → MLP)
VisionTransformer(
(conv_proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
(encoder): Encoder(
(dropout): Dropout(p=0.0, inplace=False)
(layers): Sequential(
(encoder_layer_0): EncoderBlock(
# elementwise_affine=True -> 정규화 이후, scale, shift 허용할지 설정
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
# 각 헤드에서 나온 결과 concat -> linear projection
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
# 인코더 블록 반복- Vision Transformer에서 MLP는 다음과 같은 구조를 지님.
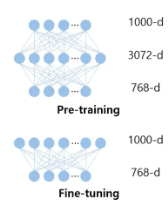
MLP Head
(ln): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
)
(heads): Sequential(
# 원하는 클래수 수로 변환 -> 결과
# 그리고 forward를 보면, mlp head에 넣기 전에 클래스 토큰만 뽑는 것을 확인 가능.
# 전체 global한 정보를 담고 있는 토큰이기 때문.
# 이런 구조 때문에 ViT는 Classification에 적합함.
(head): Linear(in_features=768, out_features=1000, bias=True)
)
)참고 )
GELU (Gaussian Error Linear Unit)
- 비선형 활성화 함수(activation function) 중 하나로, 입력을 그대로 통과시키지 않고, 비선형으로 가공해 다음 레이어로 보냄.
- : 표준 정규분포의 누적 분포 함수 (CDF)로, 크면 통과, 작으면 억제하기에 ReLU 비슷한 효과 + 부드러운 곡선의 형태를 보임.
- https://hongl.tistory.com/236
