MobileNet
- 기존의 작고 효율적인 신경망 구축 방법 : 사전 학습된 네트워크 압축 or distillation (큰 네트워크가 작은 네트워크를 가르치는 방식)
- 후자의 방법은 MobileNet 접근과 상호보완적임.
- MobileNet : 모델 개발자가 직접 작은 네트워크 선택할 수 있도록 해주는 아키텍처 구조로, latency 최적화에 중점을 두지만, 모델 크기도 작게 유지됨.
- depthwise separable convolution을 기반으로 한 간결한 아키텍처를 사용해 경량 DNN 구성
- latency, accuracy 간 효율적 균형을 위해 두 가지 전역 하이퍼파라미터 도입 (width multiplier, resolution multiplier)
- 모바일 및 임베디드 비전 애플리케이션 설계 요구 사항에 맞춰 쉽게 조정 가능한 모델
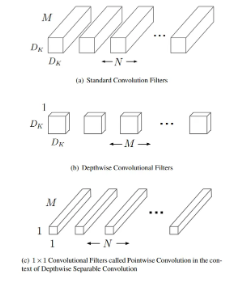
Depthwise Separable Convolution
- 일반적인 합성곱을 depthwise convolution과 1*1 pointwise convolution으로 나눈 것
- MobileNet에선 depthwise convolution은 각 입력 채널마다 하나의 필터만 적용하고, 그 뒤에 pointwise convolution이 1*1 합성곱을 통해 depthwise convolution의 출력을 결합함.
(1): InvertedResidual(
(conv): Sequential(
(0): Conv2dNormActivation(
# group=32이므로 입력 채널 1개마다 별도 필터를 써 채널별로 독립적으로 convolution (Depthwise convolution)
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# ReLU6 -> 출력을 6으로 클리핑
(2): ReLU6(inplace=True)
)
# pointwise convolution
(1): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)- Standard convolutions cost : (이때, 는 커널 크기, 는 피쳐맵 크기, M은 입력 채널 수, N은 출력 채널 수)
- MobileNet cost : (Depthwise + Pointwise)
- 다음과 같은 연산량 절감 효과가 있으며, Standard Convolution보다 8~9배 더 적으면서도 정확도 손실은 작음. ** 참고로, 추가적인 공간 차원의 인수 분해 방법은 depthwise convolution 자체가 계산량이 적기에 큰 절감 효과를 주지 못함.
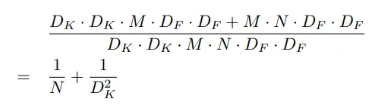
Network Structure and Training
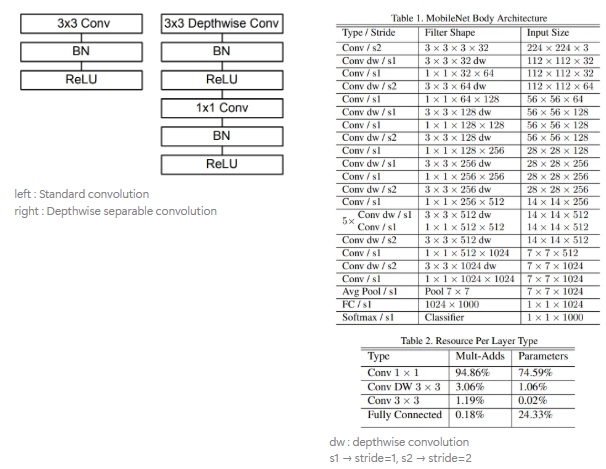
- depthwise separable convolution을 기반으로 하지만, 첫 번재 레이어는 예외적으로 일반 합성곱을 사용하며, 모든 레이어는 BatchNorm, ReLU를 따르고 마지막 FC Layer만 비선형 함수 없이 Softmax 분류기로 연결됨.
- Downsampling은 depthwise convolution에서 stride를 통해 수행되며, 마지막에선 Average Pooling을 통해 공간 해상도를 1로 줄인 뒤 FC Layer로 연결함.
- 구조화되지 않은 희소 행렬 연산은 일정 수준 이상의 희소성 확보 전까진 밀집 행렬보다 연산이 느린 경우가 많은데, MobileNet은 대부분 연산을 dense 1*1 conv에 집중시키므로 im2col 없이 GEMM으로구현 가능함.
Width Multiplier: Thinner Models
- 특정 용도에 따라 필요한 더 작고 빠른 모델을 만들기 위해 width multiplier라 불리는 파라미터 α 도입
- 너비 계수 α : 네트워크의 모든 레이어에서 채널 수를 균일하게 줄임.
- 너비 계수가 적용된 depthwise separable convolution의 계산 비용
- α의 범위는 (0, 1]이며, 일반적으로 1, 0.75, 0.5, 0.25 등이 사용됨.
- α=1일 땐 기본 MobileNet, α<1일 땐 축소된 MobileNet 구조임.
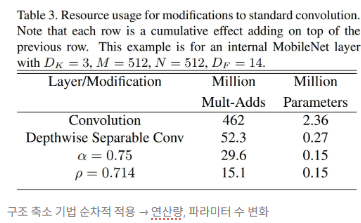
- 너비 계수 사용 시 계산량과 파라미터 수가 대략 에 비례해 줄어듦.
- 소형 모델 정의에 좋으나, 축소된 구조는 처음부터 새로 학습이 필요함.
(ex) 어떤 레이어에 너비 계수 α를 적용하면, 입력 채널 수 M은 αM, 출력 채널 수 N은 αN으로 감소
Resolution Multiplier: Reduced Representation
- 해상도 계수 ρ는 입력 이미지에 적용되며, 모든 레이어의 내부 표현 크기도 동일한 비율로 줄어듦.
- 실제로는 입력 해상도를 설정함으로써 ρ 값을 간접적으로 결정하며, 너비 계수와 해상도 계수를 적용한 depthwise separable convolution의 연산 비용은 다음과 같음.
- 이때, ρ 값의 범위는 (0, 1]이고, 일반적으로 입력 해상도를 224, 192, 160, 128 중 하나로 설정해 ρ 값을 간접적으로 정하며, ρ = 1일 땐 기본 MobileNet, ρ < 1인 경우 계산량이 더 줄어든 MobileNet
-
해상도 계수 적용 시 연산량이 비율로 감소함.
-
참고 )
- 너비 계수는 모델의 전체 채널 수를, 해상도 계수는 모델 입력 이미지 크기를 조절해 조절함.
- distillation : 작은 모델이 정답 레이블이 아니라 큰 모델의 출력을 모방하도록 학습되는 방식으로, 라벨이 없는 대규모 데이터셋에서도 학습이 가능함.
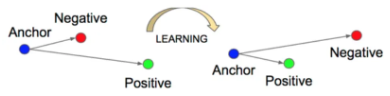
- Triplet Loss : 한 학습 샘플 = (Anchor, Positive, Negative)일 때, anchor를 기준으로 positive는 가까이, negative는 멀리 배치하는 방법
- FaceNet 논문 : https://arxiv.org/pdf/1503.03832

얼렁뚱땅 바보 학부생...