Efficientnet
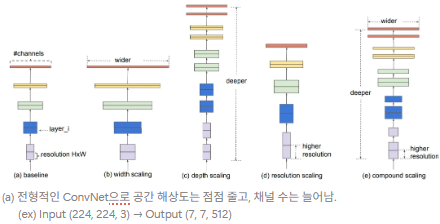
- 기존 연구 : depth, width, resolution 중 하나를 확장해 정확도를 높이는 것이 일반적이고, 두 개 또는 세 개 차원을 임의로 확장할 수도 있으나, 수많은 수작업 조정 과정의 필요 & 최적이 아닌 성능이나 효율성을 낼 가능성이 존재함.
- 핵심 질문 : “is there a principled method to scale up ConvNets that can achieve better accuracy and efficiency?”
- 깊이, 너비, 해상도의 모든 차원을 고정된 계수로 균일하게 확장함으로써 차원 사이 균형을 맞추는 간단하지만 효과적인 compound coefficient를 사용해 균일하게 확장하는 스케일링 방법 제안함.
- 모델 확장 효과가 기본이 되는 네트워크 구조에 크게 의존하므로 Neural Architecture Search(NAS)를 통해 새로운 기본 네트워크를 설계함. → 이 네트워크를 확장한 것이 EfficientNet
- (ex) 계산 자원을 배로 늘리고 싶다면, 깊이는 , 너비는 , 해상도는 만큼 증가시키면 되며, 이때, 는 원래 작은 모델에서 grid search를 통해 정해진 상수임.
Problem Formulation
-
ConvNet의 레이어 →
- 이때 입력 텐서 의 shape은
- 하나의 ConvNet 은 여러 레이어가 순차적으로 합성된 구조로 표현될 수 있음.
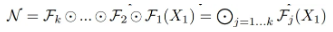
- 실제론, ConvNet 레이어들이 여러 개 stage로 나뉘고, 각 stage 내 레이어들은 동일한 구조를 가지는 경우가 많으므로 다음과 같이 표현될 수 있음.
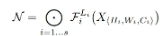
-
기존 ConvNet 설계는 주로 각 레이어 구조 를 어떻게 설계할지를 중심으로 하지만, 모델 스케일링은 를 고정하고, 레이어 개수(), 채널 수(너비, ), 해상도()를 확장함.
-
또한, 조합을 조정할 수 있는 design space를 줄이기 위해, 모든 레이어를 동일한 비율로 스케일하도록 제한함.
-
목표 : 주어진 resource constraints에 대해 모델 정확도를 최대화하는 것으로, 다음과 같은 최적화 문제로 공식화될 수 있음.

Scaling Dimensions
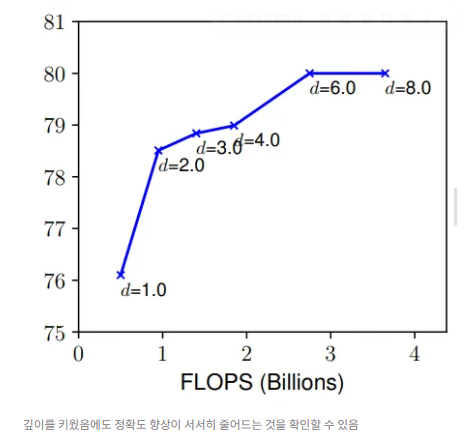
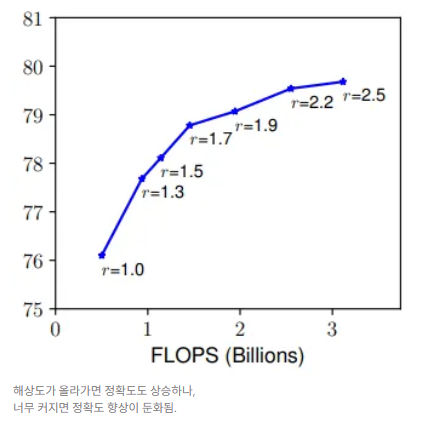
Observation 1 : 네트워크의 너비, 깊이, 해상도 중 어느 차원이든 확장하면 정확도가 향상되나, 모델이 커질수록 그 이득은 줄어든다.
- Depth (d) : 가장 일반적인 방법으로, 복잡한 특징 학습 가능 / 일반화 성능 좋음
- 깊은 네트워크는 Gradient Vanishing으로 인해 학습이 어렵기에 이를 해결하기 위해 skip connection이나 batch normalization과 같은 기법들이 도입되었으나, 그럼에도 불구하고 너무 깊은 모델은 성능 향상이 거의 없거나 오히려 나빠짐. (ex) ResNet, Inception 등
- Width (w) : 너비가 넓으면 더 세밀한 특징 포착이 가능하고, 학습도 더 쉬워지는데, 작은 모델에서는 괜찮으나, 너무 넓고 얕은 네트워크는 높은 수준 특징을 포착하지 못함. (ex) MobileNet, ShuffleNet 등
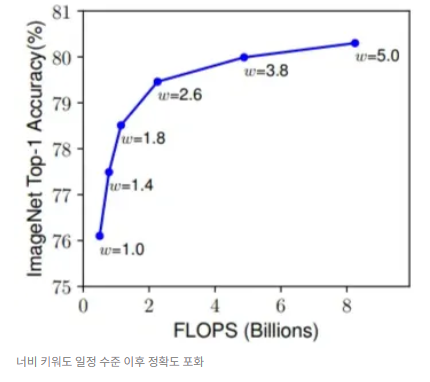
- Resolution (r) : 해상도가 높으면 좀 더 세밀한 패턴 포착이 가능하고, 초기엔 보통 224*224 해상도를 사용했으나, 최근엔 더 높은 정확도를 위해 299x299, 331x331, 480x480, 600x600 등이 사용됨.
- r = 1.0은 224x224, r = 2.5는 560x560 해상도
Compound Scaling
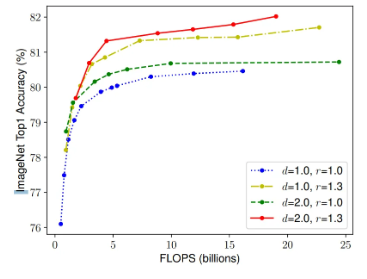
Observation 2 : 더 나은 정확도와 효율성을 달성하려면, ConvNet 스케일링 시 너비, 깊이, 해상도 세 차원을 균형 있게 조정해야 한다. (스케일링 차원들이 서로 독립적이지 않으므로)
- 다양한 깊이, 해상도에서 너비만 확장했을 때의 성능 비교
- d = 1.0, r = 1.0 → 너비만 키우면 정확도가 금방 포화됨
- d = 2.0, r = 2.0 → 같은 FLOPS 조건에서도 정확도가 크게 향상
compound scaling method
- 복합 계수 φ를 사용해 세 가지 차원을 동시에, 일관되게 확장하는 방법
- 는 각각 깊이, 너비, 해상도에 얼마만큼 자원을 분배할지 결정하는 상수값으로, small grid search를 통해 찾으며, φ는 사용자가 지정하는 계수로, 얼마나 많은 추가 자원을 사용할 것인지를 결정함. (ex) φ=1 → 기존보다 2배 많은 자원 사용
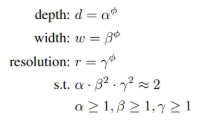
- FLOPS ∝
- FLOPS는 일반적으로 에 비례하므로 깊이를 2배 늘리면 FLOPS는 2배 증가하고, 너비나 해상도를 2배 늘리면 FLOPS는 4배 증가하므로 논문에선 다음과 같이 스케일링함.
- FLOPS ∝
- 이때, ≈ 2 → φ 1만큼 증가 시 FLOPS는 만큼 증가하도록 설정함.
EfficientNet Architecture
모델 스케일링은 기본 네트워크의 레이어 연산자를 변경하지 않기에 좋은 baseline network를 선택하는 것도 매우 중요하므로 모바일 사이즈 기본 네트워크를 별도 개발함. (EfficientNet)
EfficientNet-B0
- 정확도와 FLOPS를 줄이도록 두 가지를 동시에 고려하는 multi-objective NAS를 활용함.
- 특정 하드웨어를 타깃으로 하지 않으므로 latency가 아닌 FLOPS를 최적화하는 목적 함수를 최적화 대상으로 사용함
- 이때, ACC(m)는 정확도, T는 목표 FLOPS, w는 정확도와 FLOPS 간 trade-off 조절 하이퍼파라미터
- 이 NAS 탐색 결과로 얻은 네트워크를 EfficientNet-B0라고 하며, 네트워크의 기본 블록은 Mobile Inverted Bottleneck MBConv이며, 여기에 SE 최적화가 추가됨.
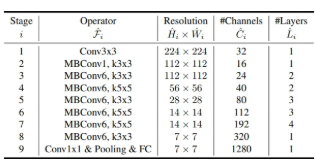
EfficientNet-B1~B7 : EfficientNet-B0을 시작으로 compound scaling 방법을 두 단계에 거쳐 적용
- Step 1 : 스케일링 계수 결정
- φ = 1 (자원이 2배 주어진 상황)을 가정하고, 식 2, 3 기반 α, β, γ 값을 grid search로 찾음.
- B0에 가장 적합한 값 : α = 1.2, β = 1.1, γ = 1.15 (이때, α · β² · γ² ≈ 2 조건 만족)
- Step 2 : 계수 고정 후 모델 확장
- 찾은 α, β, γ 값을 고정된 상수로 사용하며, φ 값을 점진적으로 증가시키며 네트워크를 확장해 B1~B7까지의 모델을 생성함.
- 이때, 큰 모델에서 α, β, γ 값을 탐색하면 높은 성능을 낼 수 있으나, 탐색 비용이 기하급수적으로 증가하므로 작은 모델(B0)에서 한 번만 계수를 탐색(Step 1)하고, 이후에는 동일한 계수를 사용해 모든 확장 모델을 자동으로 생성(Step 2)하는 방법을 활용함.
# MBConv + SE
# 일반 Bottleneck : 입력 -> 채널 줄이기 -> 연산 -> 다시 늘리기
# Inverted Bottleneck(MBConv) : 입력 -> 채널 늘리기 -> depthwise conv -> 채널 줄이기 -> 출력
# SE 구조 : Squeeze (GAP 각 채널 정보 요약) -> Excitation (채널별 가중치를 통해 중요한 채널은 크게, 아닌 채널은 작게) -> Rescale (원래 Feature map에 가중치 곱해 반영)
(2): Sequential(
(0): MBConv(
(block): Sequential(
# 채널 확장
(0): Conv2dNormActivation(
(0): Conv2d(16, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
# Depthwise 3*3 conv
(1): Conv2dNormActivation(
# 채널마다 독립적으로 3*3 convolution (groups=96)
(0): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=96, bias=False)
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
# Squeeze and Excitation -> SE 모듈
(2): SqueezeExcitation(
# Squeeze
(avgpool): AdaptiveAvgPool2d(output_size=1)
# Excitation (중요 채널 학습)
(fc1): Conv2d(96, 4, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(4, 96, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid() # 각 채널 사이 가중치 0~1 사이 조정 -> 즉, 채널별 가중치 부여
)
# 채널 축소
(3): Conv2dNormActivation(
(0): Conv2d(96, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
# stochastic_depth : residual 블록을 학습 중에 확률적으로 drop하는 방식
# mode값이 row면 샘플 단위, batch면 배치 전체 단위로 블록 drop
(stochastic_depth): StochasticDepth(p=0.0125, mode=row)
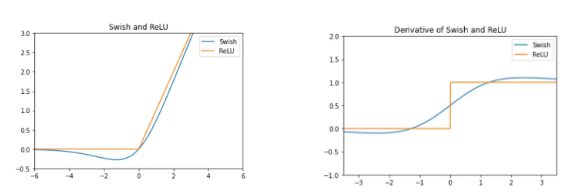
)SiLU : 입력 x에 sigmoid를 곱한 형태 ()
→ 항상 연속적이고, 부드러우며 음수도 일부 통과시키는 형태로, EfficientNet에서 SiLU를 통해 ReLU 대비 더 높은 정확도를 얻었으며, NAS 구조 탐색 결과도 성능 좋은 조합으로 SiLU 선택
- 논문 : https://arxiv.org/pdf/1905.11946
- NAS 관련 Survey : https://arxiv.org/pdf/1808.05377
간단한 정리 )
- MobileNet → 너비, 해상도를 사용자가 따로 조정함.
- EfficientNet → 너비, 깊이, 해상도를 공식 기반으로 균형 확장함. (셋 다 조절)

얼렁뚱땅 바보 학부생...