DenseNet
- DenseNet은 각 층을 피드포워드 방식으로 다른 모든 층과 직접 연결함.
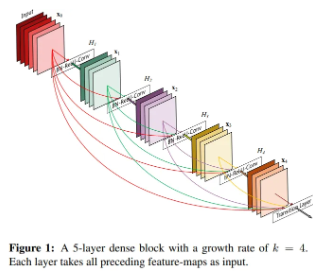
- 일반적인 합성곱 신경망은 L개의 층이 존재할 때, N개의 연결(즉, 각 층이 그 다음 층과만 연결됨)만을 지니는 반면, DenseNet은 L(L+1)/2 개의 직접 연결을 지님. (즉, 각 층은 이전 층의 모든 Feature map을 입력으로 사용하고, 자신의 Feature map을 모든 이후 층의 입력으로 전달함)
- 다시 말해, 동일한 Feature map 크기를 갖는 모든 층을 서로 직접 연결함.
- ResNet과 달리 feature 간 연결을 sum이 아닌 concatenate를 통해 수행하며, ResNet은 많은 층 중 일부가 학습 중 무작위로 생략될 수 있으나(unrolled RNN처럼), DenseNet은 새롭게 추가되는 정보와 보존되는 정보 명확하게 구분함.
→ DenseNet의 각 층이 출력하는 Feature map 수는 매우 적음. (대신 이전 층들의 Feature map 정보를 모두 보존해 입력에 포함)
→ 이로 인해 정보/기울기 흐름이 원활해지고 암묵적인 deep supervision 효과 / 정규화 효과를 얻을 수 있으며, 이를 통해 훈련 데이터가 적은 경우에도 과적합 줄이기 가능 - Gradient Vanishing 완화 / feature propagation 강화 / feature reuse 촉진 / 모델 파라미터 수 감소의 효과
ResNet
- skip connection을 도입해 비선형변환을 우회하는 identity function을 추가함.
- 기울기가 항등 경로를 통해 뒷부분 층에서 앞부분 층까지 직접 흐를 수 있으나, 의 출력과 입력이 sum으로 결합되므로 정보 흐름 제약 가능성이 존재함.
- (ex) 라면, 일부 정보가 손실되는 것을 확인 가능함
- residual connection이 Gradient 흐름은 도울 수 있으나, feature reuse에는 한계가 있음을 시사함.
Dense Connectivity
- 정보 흐름 향상을 위해 모든 이전 층에서 현재 층까지의 직접 연결을 도입함.
- 이때, 은 Feature map들을 채널 차원에서 concatenation한 것이며, 실제 구현 시엔 여러 입력을 하나의 텐서로 연결해 대입함.
- 밀집 연결 방식이므로 Dense Convolutional Network (DenseNet)이라고 부름.
def forward(self, init_features: Tensor) -> Tensor:
features = [init_features]
for name, layer in self.items():
new_features = layer(features) # features 입력 -> 새 출력
features.append(new_features) # 새 출력 append -> 다음 레이어 전달
return torch.cat(features, 1) # 채널 차원 dim=1에서 concatComposite function ()
- Batch Normalization / ReLU / 3*3 convolution 3단계 연산으로 정의함.
Pooling
- 에서 사용된 concatenation에 사용된 연결은 feature map 크기가 같을 때만 가능하나, 합성곱 신경망에선 featuer map의 크기를 변경하는 down sampling 계층이 핵심 구성 요소이므로, 전체 네트워크를 여러 개의 dense block으로 나누고, 그 사이에 transition layer를 배치함.
- transition layer는 Batch Normalization, 1x1 conv, 2x2 Average Pooling으로 구성됨.
- 이를 통해 feature map의 크기를 줄이면서도 다음 dense block에 맞게 적절히 연결되도록 도움.
Growth rate
- 각 이 k개의 Feature map을 생성한다 하면, 번째 층은 총 개의 feature map을 입력으로 받으며, 이때의 k를 Growth rate라고 하고, 이는 각 층이 네트워크 전체 상태에 얼마나 많은 새로운 정보를 추가하는지를 조절하는 하이퍼파라미터임.
- DenseNet에선 Feature map 전체를 네트워크의 global-state로 간주할 수 있고, 각 층은 이 상태에 자신의 Feature map k개만 덧붙이고, 이후의 모든 층에서 이 정보를 중복 없이 공유하므로 정보를 매 층마다 복사할 필요가 없음.
Bottleneck layers
- 출력 k개보다 많은 수의 Feature map을 받는 경우, 33 합성곱 연산 이전에 11 합성곱을 bottleneck layer로 도입하면 입력 Feature map 수를 줄이고 계산 효율성을 높일 수 있음
- (ex) DenseNet-B : BN → ReLU → Conv1(11) → BN → ReLU → Conv(33)
def forward(self, input: Tensor) -> Tensor: # noqa: F811
# 단일 Tensor -> list, else 그대로 사용
if isinstance(input, Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
# 중간값 계산 안 하고 역전파 시 계산 -> 메모리 효율
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return new_features# bottleneck conv 처리
def bn_function(self, inputs: List[Tensor]) -> Tensor:
concated_features = torch.cat(inputs, 1)
bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features))) # noqa: T484
return bottleneck_outputCompression
- 모델의 Compactness를 높이기 위해 transition layer에서 feature map 수를 줄일 수 있음.
- (ex) dense block이 m개의 feature map만 지닌다면, 다음 전이 계층은 θ⋅m개의 feature map만 출력하도록 압축 계수(θ)를 사용하며, 0 < θ ≤ 1이고, θ=1이면 feature map 수는 줄어들지 않음.
import torchvision.models as models
model = models.densenet121(weights='IMAGENET1K_V1')
print(model)정리
DenseNet은 이전의 모든 레이어의 결과인 feature map을 이후의 모든 레이어에 concat해서, 중복 없이 효율적으로 학습하고, gradient vanishing 문제도 완화할 수 있으나, concat 구조 특성상 연산량이 빠르게 늘어나기 때문에, 이를 줄이기 위해 1×1 conv를 포함한 bottleneck 구조를 활용하고, transition layer를 통해 feature map 크기와 채널 수를 압축하여 전체 모델을 메모리 효율적으로 만든다는 특징이 존재함.
또한, ResNet은 sum을 통한 연결이기에 메모리 걱정이 그나마 덜하지만 정보 흐름이 제한될 수 있음. 즉, 일정 부분의 정보들이 무시될 수 있는데 이에 반해 DenseNet은 이전 레이어의 모든 출력을 활용하기에 feature reuse가 뛰어남. (+ 높은 파라미터 효율성 → 과적합 억제)
참고 )
deep supervision : 중간 층마다 auxiliary classifier 또는 보조 손실 함수를 달아서, 그 층에서도 직접 학습이 일어나게 만드는 방식으로, DenseNet은 별도로 중간에 loss를 두진 않으나, 모든 층이 이전 층의 Feature map을 직접 입력으로 받아 출력층 loss가 거의 모든 층에 직접 영향을 주기에 Implicit Deep Supervision라고 이야기함.

얼렁뚱땅 바보 학부생...