SVM (Support Vector Machine)
서포트 벡터머신은 선형/비선형 분류, 회귀, 이상치 탐색 등 복잡한 분류 문제에 적합한 다목적 기계학습 모델로, 중간 이하 크기의 데이터셋에 적합한 방법이다. 이는 분류를 위한 최적의 결정 경계를 찾는 것을 목표로 하며, 최적의 결정 경계라는 것은 다수의 결정 경계 후보들 중에 최대 마진을 갖는 결정 경계를 의미한다.
이때, 서포트 벡터(support vectors)는 마진 결정에 영향을 끼치는 샘플 데이터로, 결정 경계와 가장 가까운 데이터 포인트를 의미한다. 마진(margin)은 결정 경계와 서포트 벡터 사이의 거리(minus-plane과 plus-plane 사이의 거리)로, 결정 경계와 서포트 벡터 사이에 직교하는 수직 선분을 그려 거리가 같아지는 지점을 의미한다.
SVM은 데이터를 가장 잘 구분하는 결정 경계선을 찾아 분류하는 지도 학습 알고리즘으로, 다수의 결정 경계 후보 중 최대 마진을 지니는 결정 경계를 찾는 것을 목적으로 한다.
- plus-plane :
- minus-plane :
- decision boundary :
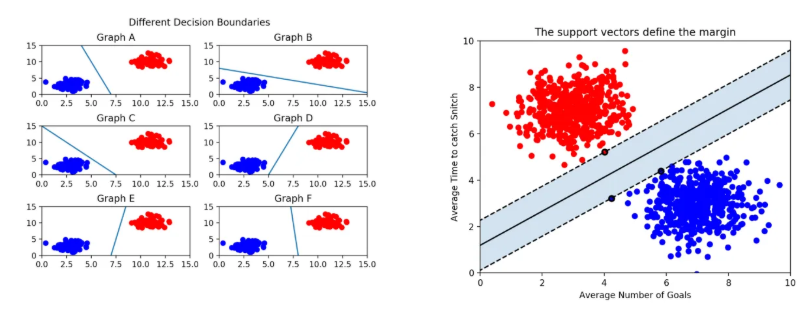
결정 경계(Decision Boundary)란, 머신러닝의 특징 공간 안에서 분류 모델이 각기 다른 클래스(범주)의 데이터를 나누는 기준이 되는 선, 면, 혹은 초평면을 의미한다. (샘플들의 카테고리를 구분할 수 있는 초평면) 쉽게 말해, 서로 다른 클래스에 속하는 데이터들을 구분하기 위한 경계라고 할 수 있다.
- N차원 공간상의 결정 경계 차원은 N-1이다. (2차원 - 직선, 3차원 - 평면, 3차원 이상 - 초평면 등)
- 원점에서 시작하는 벡터 w와 직교하고, 거리가 b인 직선의 방정식 ()
- 결정 경계는 입력 공간을 둘로 나누는 하이퍼플레인이며, 하이퍼플레인은 N차원 입력이라면 N-1차원의 표면이 됨. 그 경계는 보통 으로 나타나며, 이는 벡터 w에 직교하는 하이퍼플레인임.
참고 )
- 최적의 결정 경계선을 찾기 위해선 독립 변수가 k개일 때, 최소 k+1개의 서포트 벡터가 필요하다.
라그랑주 승수법 (Lagrange multiplier method)
라그랑주 승수법은 제약이 있는 최적화 문제를 푸는 방법을 의미한다. 즉, 목적 함수와 제약사항이 존재할 때, 제약사항을 목적 함수로 옮겨줌으로써 제약이 없는 단순한 문제로 바꿔주는 방법이다. 이를 위해 모든 제약식에 라그랑주 승수(Lagrange Multiplier) λ를 곱하고 등식 제약이 있는 문제를 제약이 없는 문제로 바꾸어 문제를 해결한다.
예를 들어 가 목적 함수이고, 이 함수를 minimize해야 최적화되는 것이며, w가 무조건 0 ~ 0.3 사이여야 한다고 했을 때, 0 <= w <= 0.3이라는 조건은 제약사항이다.
제약사항은 equality constraints, inequality constraints로 나눌 수 있으며, equality constraints는 h(x) = 0으로 나타낼 수 있는 constraint(h(x))를, inequality constraints는 h(x) <= 0을 만족하는 것을 의미한다.
제약사항을 만족시키는 목적 함수 값을 구하기 위해선 목적 함수와 제약사항 함수가 만나는 지점을 찾아야 하는데, 이를 위해 제약사항 수식도 목적 함수에 녹여 하나의 식으로 표현하는 것이 좋다. (-> 라그랑주 승수법)
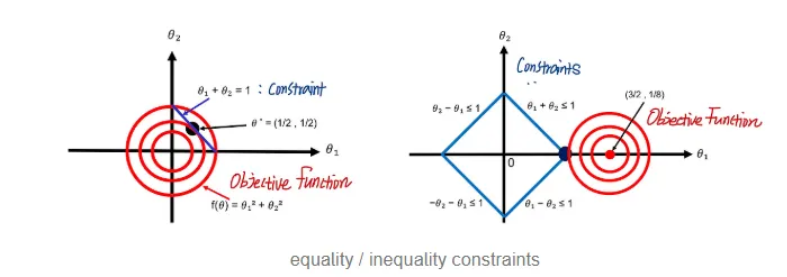
- 목적 함수 f(x, y, z, ...)와 제약 조건 g(x, y, z, ...) = 0이 있는 경우 Lagrangian은 다음과 같이 정의됨.
- L(x, y, z, …, λ) = f(x, y, z, …) + λ⋅g(x, y, z,…)
- f(x, y, z, …) : 목적 함수
- g(x, y, z, …) = 0 : 제약 조건
- λ : 라그랑주 승수
- 제약사항을 포함한 새로운 함수를 만들고, 모든 변수에 대해 미분하고 이 값을 전부 0과 동치시키는 연립 방정식을 풀고 최종적인 x, y 결과를 얻는 방식 = 라그랑주 승수법
- SVM은 부등식 제약이 있는 최적화 문제임.
KKT Condition
부등식 제약이 있는 최적화 문제에서 라그랑주 승수법을 적용하기 위해 만족해야 하는 조건
- 라그랑주 함수 L에 대해 모든 독립 변수 에 대한 미분 값이 0이다. (Stationarity)
- 모든 라그랑주 승수 와 제약 조건 부등식의 곱은 0이다. (Complementary Slackness)
- 모든 라그랑주 승수는 0보다 크거나 같아야 한다. (Dual Feasibility)
마진과 조건부 최적화 문제
마진은 결정 경계와 가장 가까운 점(서포트 벡터) 사이의 수직 거리(직교 거리)를 의미한다. 이때, 결정 경계의 수식은 이므로 직교 방향이 w의 방향이며, 서포트 벡터는 w 방향으로 ±1만큼 떨어져 있다.
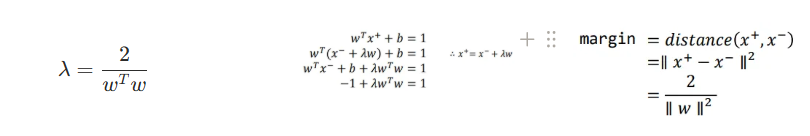
SVM의 목적은 이러한 마진을 최대화하는 결정 경계를 찾는 것이다. 따라서 다음과 같은 최적화 문제로 변환할 수 있다. 원래 SVM의 제약 조건은 과 두 가지이다. 이 두 가지를 한 번에 표현하기 위해선 이라는 성질을 이용할 수 있다. 따라서 두 조건을 포함하여 로 표현할 수도 있다. 그리고 이를 로 변형할 수 있다.
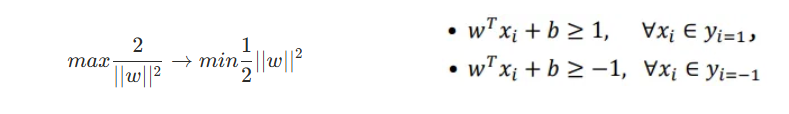
hinge 손실 함수
hinge 손실 함수는 SVM에서 주로 사용되는 손실 함수로, 다음과 같은 수식으로 표현한다.
hinge 손실은 예측이 잘못된 경우에만 패널티를 부여하며, 올바르게 분류된 경우 손실 값이 0이 된다. 분류가 잘 되는 margin 바깥 부분의 관측값이라면 손실을 무시(loss = 0)하고, 분류가 잘 되지 않는 margin 내의 관측값이라면 손실이 증가하도록 유도한다.
소프트 마진(Soft Margin)과 하드 마진 (Hard Margin)
결정 경계선을 나눌 때, 이상치를 허용하지 않을 경우 과적합 문제가 발생할 수 있다. 따라서 두 범주를 정확하게 나누지는 않지만 마진을 최대화하여 과적합을 방지하는 것을 소프트 마진, 이상치를 허용하지 않는 것을 하드 마진이라고 한다.
하드 마진의 경우엔 마진이 매우 작아지고, 개별적인 학습 데이터들을 모두 다 놓치지 않으려 하기에 오버피팅 문제가 발생할 수 있다. 반면, 소프트 마진의 경우엔 기준을 너그럽게 잡으므로 어느 정도 이상치를 마진 안에 포함하도록 기준을 설정할 수 있어 오버피팅을 방지할 수 있다는 장점이 있으나, 너무 많은 이상치를 허용할 경우 언더피팅 문제가 발생할 수 있다.
소프트 마진과 하드 마진을 조정해 주는 매개변수로 C와 Gamma가 사용되며, C는 마진 강화 정도(오류 허용 정도의 역수)를, Gamma는 커널 계수, 즉 얼마나 weight를 주는지를 의미한다. C 값과 Gamma 값은 작을수록 좋다. 그 이유는 C 값이 작으면 오류의 허용 범위가 커져 이상치에 덜 민감해지고, Gamma 값이 작으면 결정 경계가 유연해지는 경향성이 생긴다.
Gamma는 하나의 관측치가 영향력을 행사하는 거리를 조정해 주는 매개변수로, 작은 Gamma 값은 넓은 영향력을 의미하여 더 부드럽고 넓은 결정 경계선을 만들어 내고, 반대의 경우엔 좁은 영향력을 지니며, 더 민감한 결정 경계선을 형성하는데, 이 경우에는 과적합이 발생할 수 있다.
커널 트릭
현실 세계의 데이터는 대부분 Feature가 여러 개이고, 선형적으로만 데이터가 존재하지 않는다. 따라서 SVM으로 Non-Linear Data를 분류하기 위해서는 커널을 통해 차원을 변경해야 한다. 따라서 SVM은 커널 함수(ex. Linear Kernel, Polynomial Kernal 등)를 통해 데이터를 고차원 공간으로 매핑해 선형적으로 구분할 수 있게 만든다. 이는 데이터를 고차원 공간으로 직접적으로 매핑시키는 것이 아니다. 커널을 통해 복잡한 저차원 데이터를 선형 분리가 가능한 고차원으로 매핑시켜 처리하는 것이다.
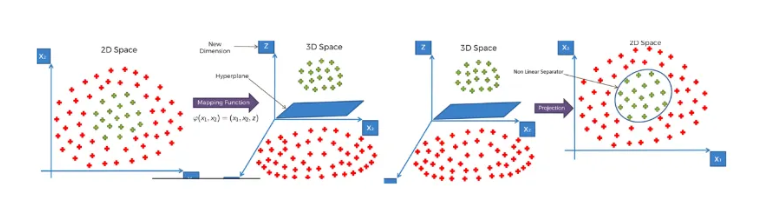
다항 회귀 (Polynomial Regression) : 비선형 데이터를 학습하기 위해 각 특성의 거듭제곱을 새로운 특성으로 추가하고, 해당 데이터셋에 대해 선형 모델을 학습시키는 방법으로, 각 특성을 주어진 Degree에 따라 제곱해 새로운 특성으로 추가한다.
PolynomialFeature(degree=2)- 하지만, 이런 Feature를 추가하는 방식은 모델 성능에 영향을 미칠 수 있다. (모델이 느려짐)
- 이를 해결하기 위해 커널 트릭을 사용한다. 커널 트릭은 높은 차수의 특성을 추가한 것과 같은 효과를 가지면서도 실제로 특성을 추가하지 않는다.
RBF 커널
- RBF Function은 기존 벡터와 입력 벡터의 유사도를 측정하는 함수로, 가우시안 함수 형태를 지닌다.
- 데이터를 고차원으로 보낼 때, 특정 점들과 얼마나 가까운지(유사한지)를 새로운 특징으로 추가하는 방법
- RBF 커널은 모든 데이터 점 x에 대해 기준점(랜드마크) z₁, z₂, z₃…와의 거리 유사도를 Feature로 추가함.
- 즉, 고차원 벡터 자체가 아닌 고차원 벡터들 간의 dot product만을 계산하여 고차원으로 매핑하는 함수를 직접 만들지 않아도 그 효과를 사용할 수 있게 해준다.
정리
- 커널(K)만 있으면 고차원 feature φ(x)의 내적을 직접 계산할 필요 없음
- RBF 커널은 "가우시안 거리 기반 유사도"
- 랜드마크들과의 거리 → 새로운 feature가 되어 고차원으로 올라감
- 그 공간에서는 직선으로 분리 가능
- SVM은 결국 만 이용해 분류함
- 즉, Feature를 추가하긴 하는데 고차원 함수 계산이 아니라 유사도 계산을 통한 비선형성 추가
결정 트리 (Decision Tree)
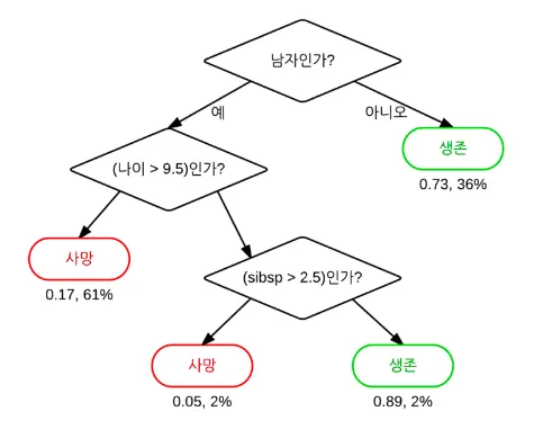
결정 트리란, 일련의 분류 규칙을 통해 데이터를 분류/회귀하는 지도학습 모델 중 하나로, 결과 모델이 트리 구조를 지녀 Decison Tree라는 이름을 지닌다. 아래의 그림처럼 특정 기준(질문)에 따라 데이터를 구분하는 모델을 의사 결정 트리 모델이라고 하며, 한 번의 분기마다 변수 영역을 두 개로 구분한다.
결정 트리에서 질문이나 정답을 노드(Node)라고 하고, 맨 처음 분류 기준을 Root Node, 중간 분류 기준을 Intermediate Node, 맨 마지막 노드를 Terminal Node 혹은 Leaf Node라고 한다. 이러한 결정 트리의 기본 아이디어는 Leaf Node가 가장 섞이지 않은 상태로 분류되는 것, 즉 복잡성(Entropy)이 낮아지는 방향으로 만드는 것이다
불순도 (Impurity)
불순도(Impurity)란 해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지 복잡성을 의미하며, 다양한 개체들이 섞여 있을수록 불순도가 높아진다.
결정 트리에서 분기 기준을 설정할 땐 현재 노드의 불순도에 비해 자식 노드의 불순도가 감소되도록 설정해야 하며, 현재 노드의 불순도와 자식 노드 불순도의 차이를 Information Gain(정보 이득)이라고 한다.
이러한 불순도를 수치적으로 나타내기 위한 함수에는 지니 계수(Gini)와 엔트로피(Entropy)가 있다.
-
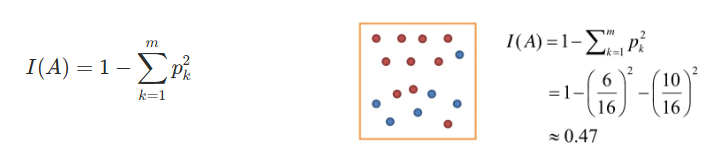
지니 계수(Gini) : 데이터의 혼합 정도(불순도)를 정량화하는 지표
- 0에서 0.5 사이의 값을 지니며, 값이 낮을수록 데이터의 순도가 낮음을 나타냄.
- 지니 계수가 0일 경우, 모든 데이터가 동일한 클래스에 속해 매우 순수한 상태임을 나타내고, 0.5에 가까운 값은 데이터가 여러 클래스에 혼합되어 높은 불순도를 지닌다는 것을 의미함.
- 지니 계수는 주로 의사결정트리에서 노드의 분할 기준으로 사용되며, 각 노드를 가능한 한 순수하게 만들기 위해 Gini 계수를 최소화하는 방향으로 학습이 이루어짐.
-
엔트로피 (Entropy) : 정보 이론에서 유래한 개념으로, 불확실성의 정도를 정령화하는 척도
- 엔트로피는 데이터의 혼합 정도, 즉 데이터의 무질서성을 표현하며, 의사결정트리에서 정보 이득(특정 속성을 기준으로 데이터를 분할했을 때 전체 데이터의 불확실성이 얼마나 감소했는지를 측정하는 지표)을 계산하는데 사용됨. 의사결정트리에서는 분기 시 이런 불순도 값이 줄어드는 방향으로 트리를 형성해야 함.
- 엔트로피 값은 0에서 사이의 값을 지니며, 클래스가 두 개인 경우 최댓값은 1임.
- 엔트로피가 0이라는 것은 모든 데이터가 동일한 클래스에 속해 불확실성이 없음을 의미하며, 엔트로피가 높아질수록 데이터의 혼합 정도가 증가하고, 불확실성도 커짐.

정보 이득 (Information Gain)
정보 이득이란, 분기 이전의 불순도와 분기 이후의 불순도 차이(Parent Node와 Child Node의 불순도 차이)를 의미한다. 예를 들어, 불순도가 1인 상태에서 0.7인 상태로 바뀌었다면 정보 이득은 0.3이다.
결정 트리 구성 단계
- Root Node의 불순도 계산
- 나머지 속성에 대해 분할 후 Child Node의 불순도 계산
- 각 속성에 대한 Information Gain 계산 후 Information Gain(Root노드와 자식노드의 불순도 차이)이 최대가 되는 분기 조건을 찾아 분기
- 모든 Leaf Node의 불순도가 0이 될때까지 2,3을 반복 수행한다.
가지치기 (pruning)
가지치기란, 결정 트리의 특정 노드 및 하부 트리를 제거해 일반화 성능을 높이는 것을 의미한다. 쉽게 말해, 데이터로부터 생성된 복잡한 트리 구조를 단순화하기 위해 가지를 많이 내려 생성된 나무로부터 몇 개의 가지를 쳐내 트리 구조를 단순화하는 것이다. 이러한 가지치기는 사전 가지치기와 사후 가지치기로 나눌 수 있다.
사전 가지치기는 의사결정트리의 분류 정지 조건을 사전에 설정해 분할을 멈추는 것을 의미하며, 트리 생성 시 트리의 깊이나 사용되는 Feature 개수, Leaf Node Sample 수 등과 같이 관련 하이퍼파라미터를 직접 설정하여 수행한다.
사후 가지치기는 Full Tree를 생성한 후 모델에 대한 해석과 평가가 완화되는 방향으로 가지를 결합하는 것을 의미한다. 대표적인 사후 가지치기 방법에는 Cost Complexity Pruning이 있으며, 이는 오차 제곱합(SSE)이 최소가 되는 트리를 찾는 방법이다.
아래의 식에서 오른쪽 두 번째 항은 일종이 패널티로써, 나무의 크기가 클수록 그 값이 커진다. 여기서 는 complexity 파라미터로, 이 값이 클수록 가지치기하는 노드의 수가 많아져 모델이 단순해지고, 작을 수록 복잡한 데이터를 표현할 수 있는 모델이 된다.
- ERR(T) : 검증 데이터에 대한 오분류율
- L(T) : Leaf Node 개수 (구조 복잡성)
결정 트리 단점
- 과적합으로 알고리즘 성능이 떨어질 수 있다.
- 이를 극복하기 위해서 트리의 크기를 사전에 제한하는 튜닝이 필요하다.
- 한 번에 하나의 변수만 고려하므로 변수 간 상호작용을 파악하기가 어렵다.
- 약간의 차이에 따라(레코드의 개수의 약간의 차이) 트리의 모양이 많이 달라질 수 있다.
- 두 변수가 비슷한 수준의 정보력을 갖는다고 했을 때, 약간의 차이에 의해 다른 변수가 선택되면 이 후의 트리 구성이 크게 달라질 수 있다.
- 계단 모양의 결정 경계를 만들기에 학습 데이터의 회전에 민감하다.
- 이같은 문제를 극복하기 위해 등장한 모델이 바로 랜덤 포레스트이다.
- 같은 데이터에 대해 결정 트리를 여러 개 만들어 그 결과를 종합해 예측 성능을 높이는 기법
코드
- SVC :
SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr’, break_ties=False, random_state=None)kernel: 커널 유형 지정- {‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}
C: 오류 허용 정도의 역수로 작을 수록 오류를 많이 허용함. (이상치 덜 민감)gamma: Kernel 계수 (커널의 유연성 : 계수로 조정)- for ‘rbf’, ‘poly’, ‘sigmoid’
- Decision Tree 시각화 :
plot_tree(decision_tree, max_depth=None, feature_names=None, class_names=None, filled=False, proportion=False, rounded=False, precision=3, fontsize=None)max_depth: if None, the tree is fully generated.feature_names: list of stringsclass_names: list of str or boolproportion: True로 지정하면, 값 대신 비율로 표현precision: number of digits of precisionfilled,rounded,fontsize: 노드의 모양과 폰트크기 설정
