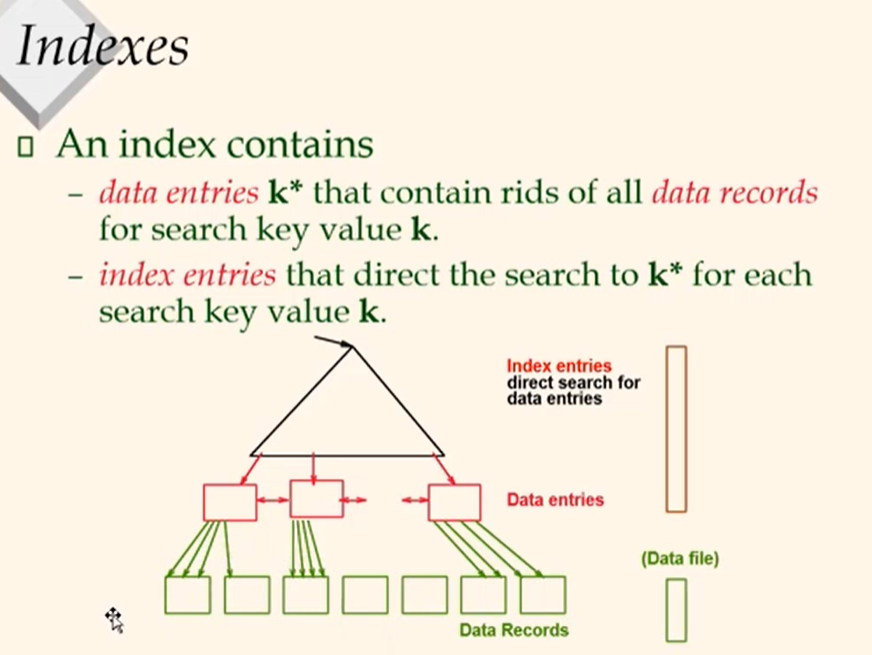
Indexing
Alternatives for Data Entry k*
- k* has three alternatives:
- <k, datarecord>
- <k, rid>
- <k, list of rids>
- k* are sorted by k for sorted index, or hashed by k for hased index
Alternative 1: <k, data record>
- Index itself is a file organization for data records- index is as large as the file
- At most one index on a given file can use Alternative 1. Why?
-> Alternative 1 stores copy of the data, so if more than one index means duplicated key
그림에서 data record가 실제 디스크상의 데이터다. 그래서 인덱스가 파일만큼이나 큰 것이다. clustered index가 하나밖에 존재하지 못하는 이유는 테이블은 두 개의 기준으로 정렬될 수 없기 때문이다. 이름 순으로도 정렬되어있으면서 나이순으로도 정렬되어있을 수는 없다.
Alternatives 2 and 3: <k, rid> or <k, list of rids>
- Data entries much smaller than data records, so index is much smaller than file
- Alternative 3 more compact than Alternaitve 2, but leads to variable sized data entries
- At most one index can use Alternative 1; rest must use Alternatives 2 or 3
Index Classification
- Unique index: Search key contains a candidate key.
- How many records will be returned for an equality search using a unique index?
-> 0 or 1
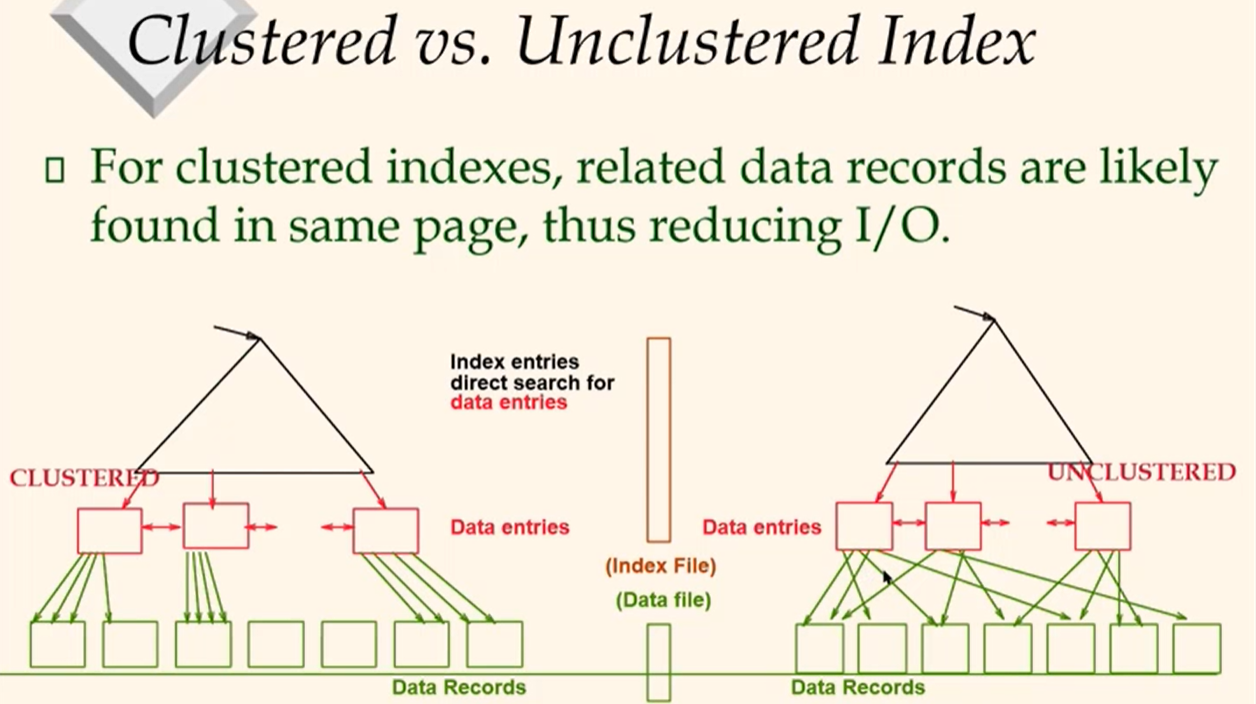
- Clustered vs. unclustered: For sorted index, data entries k* are sorted by search key k.
- If data records are also sorted by k, clustered index, otherwise, unclustered index.
- A file has at most one clustered index
- Alternative 1 leads to clustered index
- Be sure understand this page!
Example
Clustered Index
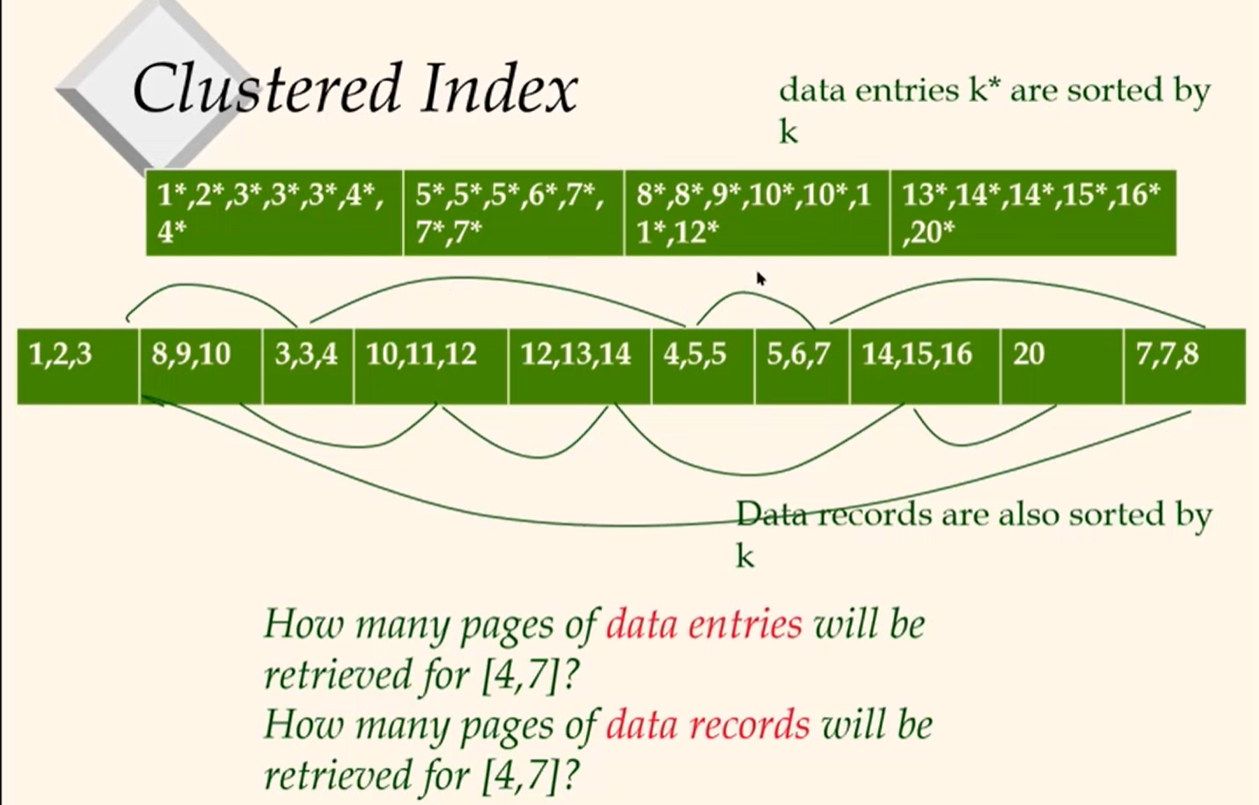
Data record에서 숫자는 나이를 타나낸다. 각 숫자의 나이를 가진 다른 record 들이다.
A1) 처음에는 위의 data entries에 접근한다. 4가 두개있는 것을 확인하고 밑의 data records에 처음 4에 바로 접근한다. data records는 정렬되어있기 때문에 가로로 이동하면서 7이 끝날때까지 찾는다. 따라서 처음에는 (1, 2, 3, 3, 3,4, 4)가 있는 페이지에 접근, 그 다음은 (3,3,4), (4,5,5), (5,6,7), (7,7,8)순으로 접근했다. 결론적으로 1 IO는 data entries를 읽는데 사용했고, 4 IO는 data records를 읽는데 사용됐다. 나중에 data entries는 어떻게 접근하는지 나올 것이다.
Unclustered Index

Data entries는 정렬되어 있지만 data records는 정렬되어 있지 않다.
운이 좋다면 메모리에 올라 와있는 페이지는 새로 안읽어도 되지만, 그렇지 않으면 각 Data Enries에 있는 k*만큼 읽어야한다.
4*, 4*, 5*, 5*, 5*, 6*, 7*, 7*, 7*만큼 IO가 발생한다. 최악의 경우에는 9 IO가 data records에서 발생하고 3 IO가 data entries에서 발생한다. (3인 이유는 data entries 두번째 읽고 오른쪽에도 7이 있을 수 있으니 읽어야하기 때문이다)
