Index Classification
- Dense vs. Sparse: If there is at least one data entry k* per search key value k, then dense.
- Alternative 1 leads to dense index
- Every sparse index must be clustered!
- Sparse indexes are smaller; however, some optimiaztions are based on dense indexes.
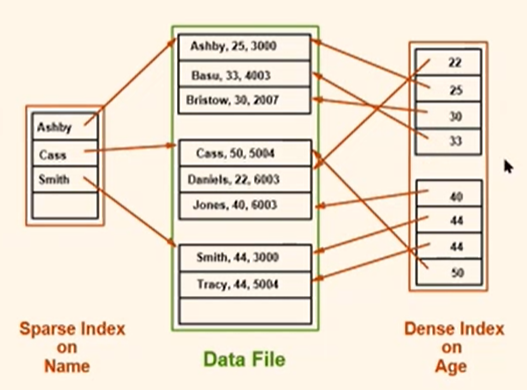
모든 sparse index는 clusted이어야하는 이유는, data record에 접근해서 그 다음 것들로 하나씩 넘어가야하므로, 정렬이 되어있어야하기 때문이다.
Composite Search Keys: Search key contains more than one field.
- Equality query: Every field value is a constant value:
-> age = 20 and sal = 75
<age, sal>, <sal, age>,<age>,<sal>모두 사용할 수 있다. 왜냐하면 data entries가 정렬되어있기 때문이다. 하지만<age>나<sal>의 경우 조금 더 느릴 것이다. age를 이용해서 찾고 나머지는 순서대로 찾아야하기 때문이다.
- Range query: Some field value is not a constant:
-> age = 20 and sal > 10
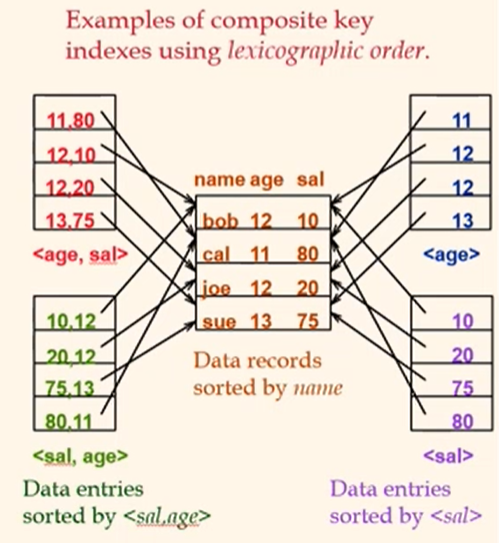
age, sal, <age, sal>, <sal, age> 모두 unclustered이다. 왜냐하면 data record는 name을 기준으로 정렬되었기 때문이다.
Summary
- Many alternative file organizations (heap files and indexed files) exist, each appropriate in some situation
- If seleciton queries are frequent, building an index is important
- Index is a collection of data entries plus a way to quickly find data entries k* for a given search key value k
- Sorted indexes good for range search and equality search
- Hashed indexes good only for equality search
- Data entries k* have one of the forms: <k, data record>, <k, rid>, or <k, rid-list>
- Can have several indexes on a given file, each with a different search key
- Indexes can be clustered vs. unclustered, dense vs. sparse. Choices depend on queries and have consequences for performance.
Tree-Structured Indexes (for Sorted Files)
Range Searches


binary search would not work because the pages on the disk are not sequential. You cannot get mid point.
ISAM
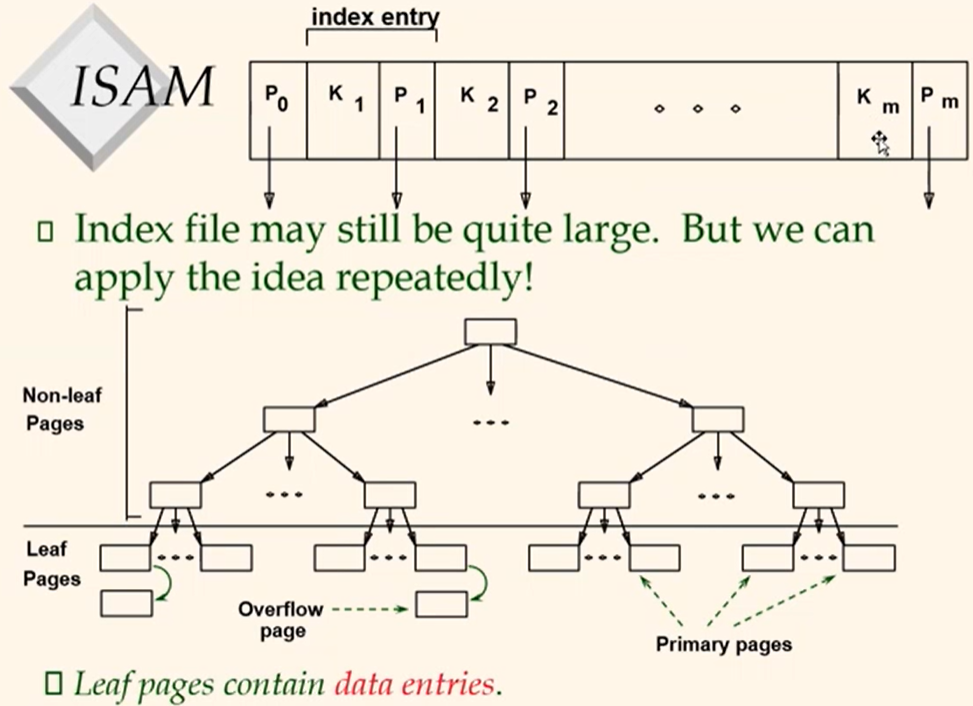
Example ISAM Tree
-> Since the entire tree structure is static. Each page is immediately after the previeous page
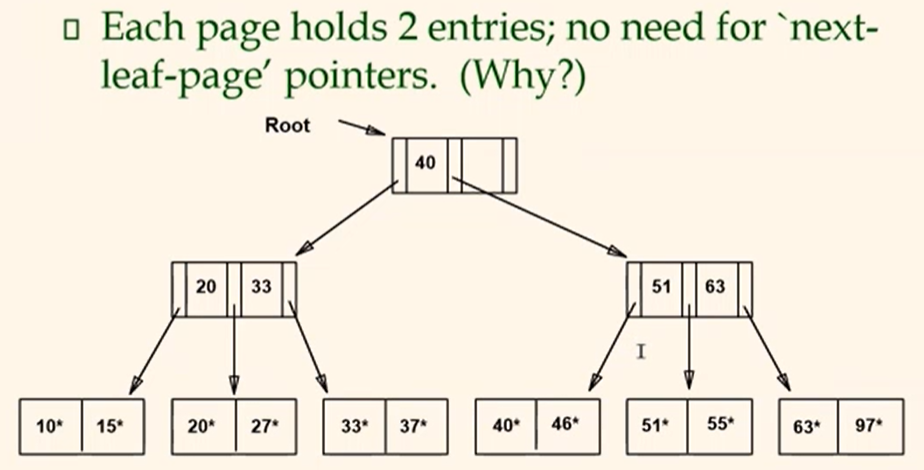
ISAM

After Inserting 23, 48, 41, 42 ...
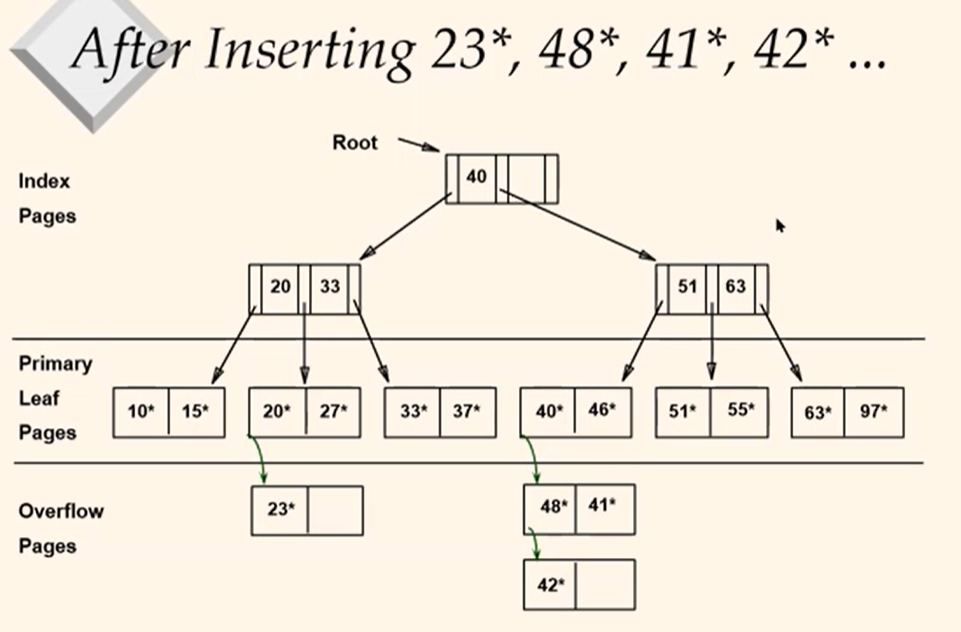
primary leaf pages까지는 static이므로 바뀌지 않는다. 그래서 overflow pages에서 순서가 다소 엉망이다.
...Then Deleting 48, 51, 97, 55
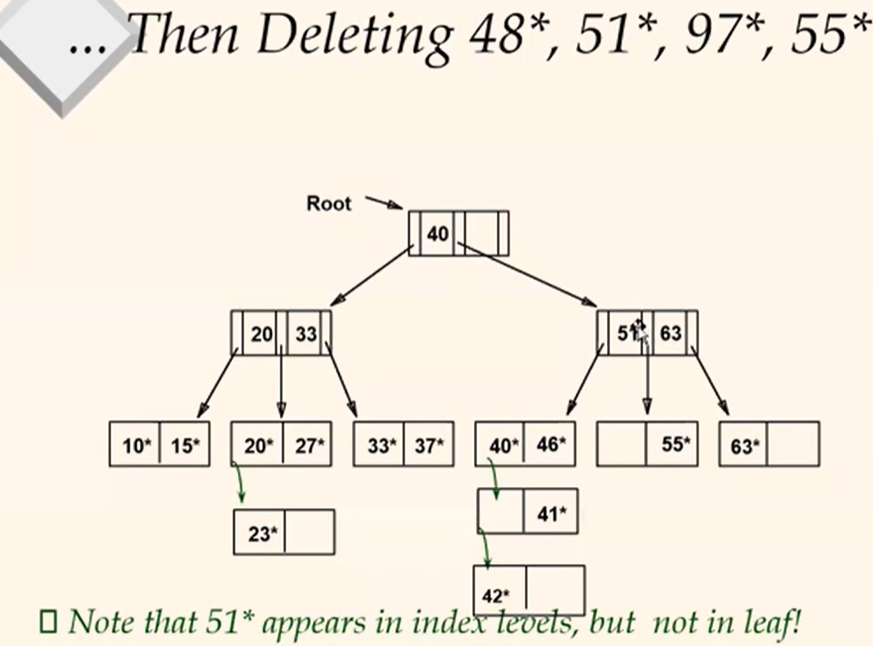
- 만약 마지막
55*가 지워졌다면 빈칸은 지워져야할까? 아니다. 안이 비워졌다하더라도 남아있어야한다. 하지만 overflow pages는 empty라면 delete 한다.- 만약
40*, 46*을 지운다하면 밑에 딸린 두 overflow pages를 지워야할까? 그렇지 않다.41*, 42*를 가져오려면 또 IO가 발생하므로 그냥 놔두면 된다.
