[Paper Review] PointRCNN: : 3D Object Proposal Generation and Detection from Point Cloud
LiDAR 3D object detection
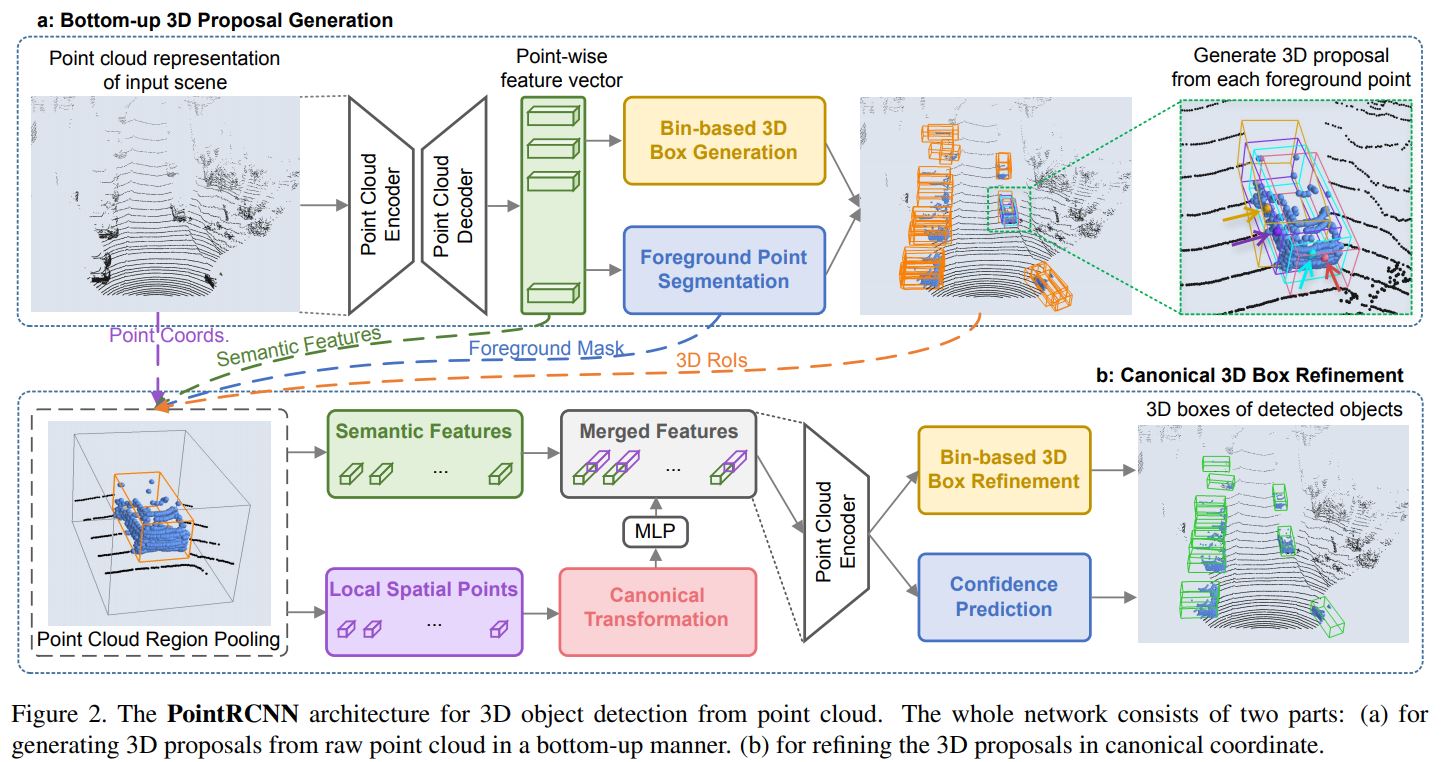
두 번째로 다룰 3D object detection 논문은 CVPR 2019에 나왔던 PointRCNN입니다. 첫 번째로 다루었던 VoxelNet이 1-stage였던 것에 반해 PointRCNN은 대표적인 2-stage detector입니다. 즉, region proposal이 먼저 이루어지고, 그 region에 대해 classification과 regression을 이어서 수행합니다.
그리고 VoxelNet은 3차원 공간을 3D voxel형태로 쪼개어 point cloud를 다루기 쉬운 형태로 바꾸어주는 voxel-based method였다면 PointRCNN은 point cloud 자체를 그대로 이용하는 point-based method라고 분류해서 말하기도 합니다. PointRCNN에서는 3D voxel을 이용하는 방법은 quantization에 따른 정보손실이 있을 뿐 아니라 3D CNN 연산이 비효율적인 점을 지적하며, point를 바로 region proposal에 사용하는 방법을 제안했습니다.
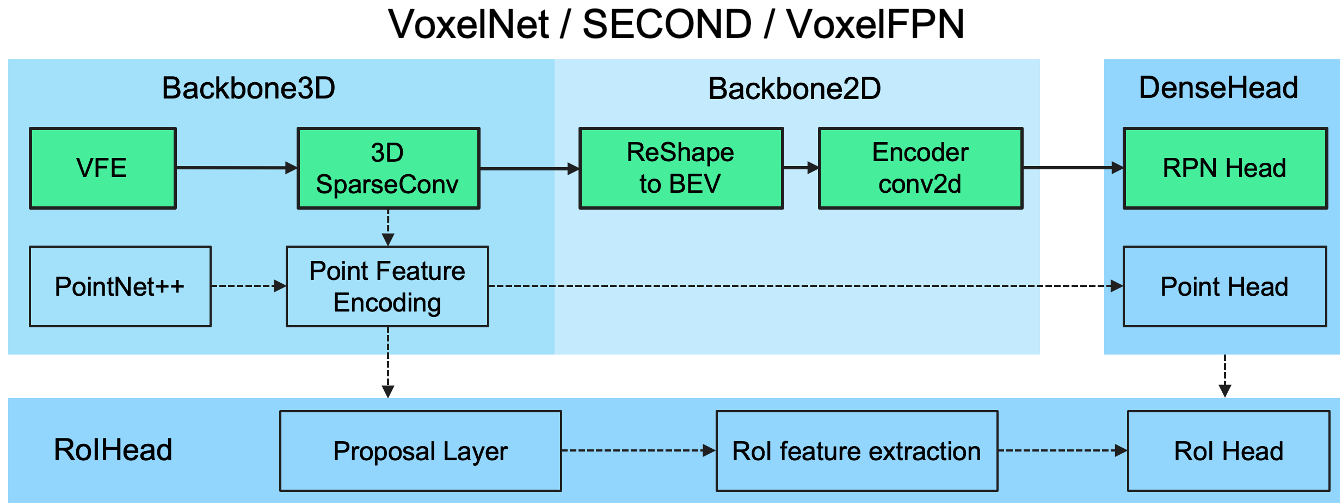
VoxelNet 글에서 언급드렸던 OpenPCDet github repository에 정리되어 있는 3D object detector 구조입니다. 한 눈에 봐도 구성하고 있는 module들이 다름을 확인하실 수 있습니다. 이렇게 VoxelNet과 PointRCNN은 서로 다른 구조를 갖지만 3D object detection 연구의 큰 2가지 흐름을 대표하는 논문이라고 생각합니다.

바로 정리로 들어가보겠습니다.
Abstract
앞서 설명드린대로, PointRCNN은 2-stage detector입니다. stage-1에서는 bottom-up 3D proposal generation을 수행하고, stage-2에서는 region proposal을 canonical coordinate로 바꾼 후 refinement를 수행하도록 하여 네트워크가 local spatial feature를 더 잘 학습할 수 있도록 합니다. 'bottom-up은 뭐고, canonical coordinate은 뭔데?'라는 의문이 드실텐데요, 뒤에서 차근차근 설명드리도록 하겠습니다.
Architecture
1. Bottom-up 3D proposal generation via point cloud segmentation
image 기반의 2D object detection에서의 2-stage detector를 3D object detection 문제로 그대로 확장하는 것은 말처럼 간단하지 않습니다. 3차원은 훨씬 더 큰 search space를 가질 뿐 아니라, LiDAR의 sparse하고 불규칙적인 특성 때문입니다. AVOD와 F-PointNet을 선행연구로서 언급하고 있는데요, 구조는 다음 그림과 같습니다.
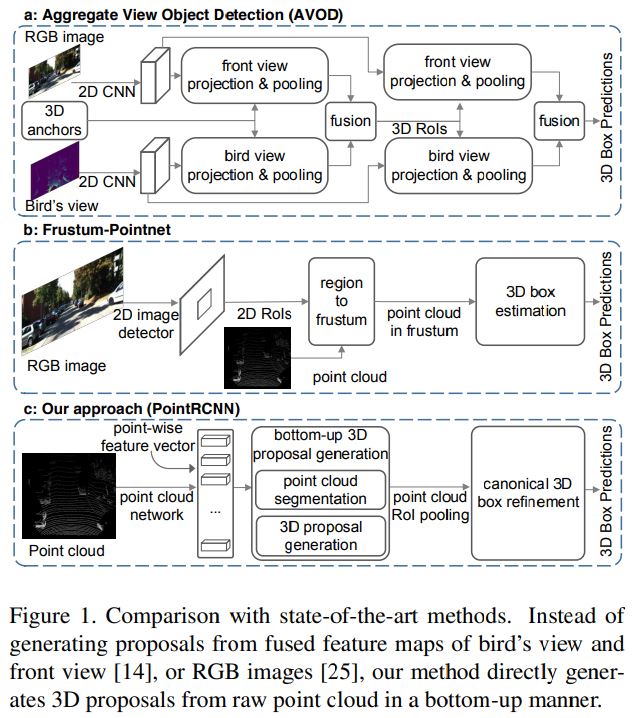
AVOD는 8만~10만 개의 anchor(3D RoI)를 3D space에 생성한 후에 각 anchor의 feature를 multiple view에서 pooling해 refinement를 수행했고, F-PointNet에서는 2D image 상에서 object detection을 수행한 후 2D detection 결과(2D RoI)를 기반으로 3D points를 crop하고, 그 point들을 PointNet에 통과시켜 3D bounding box estimation을 수행하였습니다.
위에서 언급한 방법들을 포함한 기존의 2-stage 3D object detection에서는 point를 직접 이용하지 않고 proposal(RoI)을 임의로 생성하거나 2D detection 결과를 기반으로 proposal을 만든 후, proposal의 feature를 통해 3D bbox estimation을 할 때 비로소 point가 사용이 됩니다. 이처럼 RoI를 먼저 생성하고 point를 이용하는 방식을 top-down 방식이라고 한다면, PointRCNN에서는 point로부터 RoI를 생성하는 bottom-up 방식의 proposal generation을 수행합니다. 그리고 proposal에 속한 point cloud를 이용해 refinement와 confidence prediction을 수행하고 NMS를 거쳐 최종적인 3D bbox들을 얻게 됩니다.
보다 자세히 들여다보기 전에 전체 구조 그림을 보고 가도록 하겠습니다.
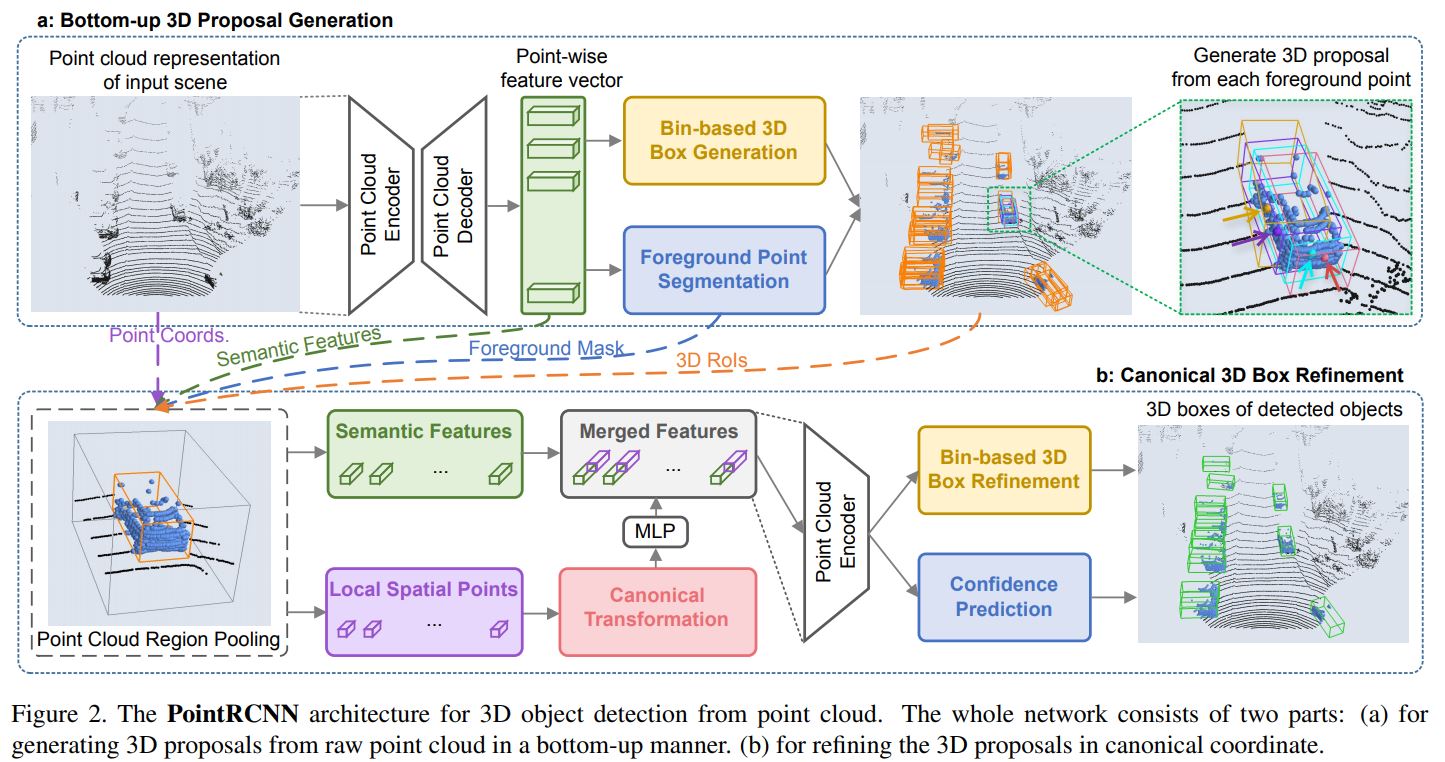
그림의 윗부분이 bottom-up 3D proposal generation을 수행하는 stage-1이 됩니다. 먼저 PointNet++가 backbone network(그림 상의 Encoder, Decoder)가 되어 point-wise feature vector를 얻게 되구요, 이 feature를 이용해 Bin-based 3D Box Generation과 Foreground Point Segmentation을 수행하게 됩니다. Bin-based 3D Box Generation은 region proposal을 생성하는 것 같은데, 갑자기 foreground point segmentation은 왜 튀어나온 걸까요?
먼저 foreground point는 object에 속하는 point를 말합니다. 즉, Foreground Point Segmentation은 point들을 object에 속하는 point들과 background 에 속하는 point들로 분류한다는 것입니다. segmentation을 학습하려면 label이 있어야할텐데 이 label들을 어떻게 얻었을까요? 저자들은 3차원 공간 상에서는 2D image와 달리 bounding box가 겹치는 일이 일어나지 않기 때문에, 3D bounding box를 segmentation label로 활용할 수 있다고 말합니다. 즉 3D bounding box에 들어있는 point들을 foreground, 들어있지 않은 point들은 background로 label하면 된다는 것이죠! 그리고 이를 이용해 segmentation loss를 계산하고, 네트워크는 point를 foreground, background로 분류하는 데 적합한 feature를 학습하게 될 것임을 기대할 수 있게 됩니다. 이는 3D box generation에도 좋은 feature가 됩니다.
그리고 segmentation을 통해 얻은 foreground point들에 대해서만 3D Box Generation을 수행하게 됩니다. 그림 상에서는 Bin-based 3D Box Generation과 Foreground Point Segmentation이 병렬로 동시에 수행되는 것으로 나와 있어서 헷갈릴 소지가 있는데요, training 시에는 3D bounding box GT를 갖고 있으므로, segmentation 결과를 기다릴 필요 없이 GT로부터 segmentation 정보를 얻어 바로 foreground point를 알 수 있습니다. 따라서 training 시에는 Bin-based 3D Box Generation과 Foreground Point Segmentation을 동시에 수행하게 되고, inference 시에는 Foreground Point Segmentation을 먼저 수행하고, 그 결과를 이용해 Bin-based 3D Box Generation을 수행하게 됩니다!
위 설명이 정확하게 이해가 가지 않으신다면 RNN 계열의 네트워크에서 자주 사용되는
Teacher Forcing에 대해서 공부해보시면 이해에 도움이 되실 듯 합니다.
stage-1에서는 Foreground Point Segmentation과 Bin-based 3D Box Generation를 수행하므로 각각 loss를 생성하게 됩니다.
Foreground Point Segmentation은 binary classification(foreground, background) 문제이고 background가 foreground point보다 훨씬 많으므로(class imbalance) focal loss를 사용합니다. 그리고 implementation detail에 나와있는 부분인데요, training 시에 ground truth 3D box의 크기를 0.2m씩 늘리게 됩니다. 이는 box 경계에 있는 background point들을 무시하기 위함인데요, bounding box가 아주 정확하지 않을 수 있으므로 경계에 있는 point들은 foreground, background 분류가 모호하게 됩니다. 따라서 이 경계에 있는 point들을 무시함으로써 segmentation을 좀 더 robust하게 합니다.
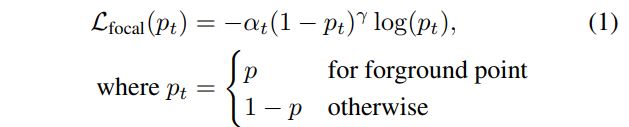
Bin-based 3D Box Generation에서는 loss를 크게 center() localization loss, size() estimation loss, orientation() loss로 나눌 수 있습니다.
그리고 center localization loss는 다시 축 loss와 축 loss로 나누어 생각할 수 있습니다. center localization은 다음과 같이 축을 discrete한 bin들로 쪼개는 것으로 시작합니다.
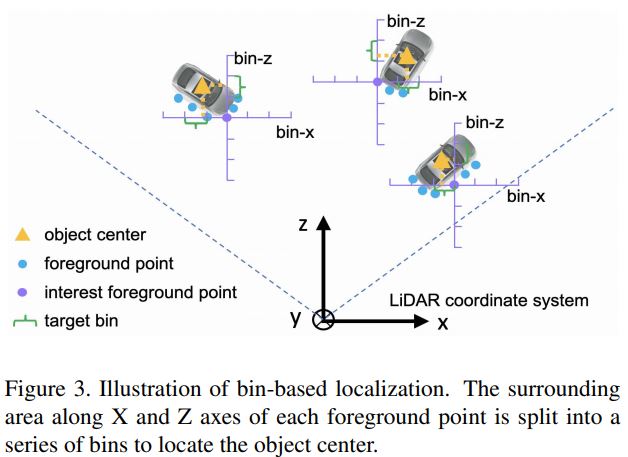
방향의 localization은 (1)bin-based classification, 어떤 bin에 속하는지 먼저 찾고, (2)residual reggression, 즉 bin 내에서의 미세 조정, 이렇게 두 단계로 이루어지게 됩니다. bin-based clasification은 말 그대로 object center가 현재 연산 중인 foreground point를 중심으로 하는 grid(implementation detail: grid 범위는 각 ±3m, cell 크기는 0.5m) 상에서 어디에 존재하는지를 분류하는 것이구요, residual regression은 cell 내에서 더 정확한 위치를 맞추는 것입니다.
방향 center localization은 보다 훨씬 작은 범위 내에서 변하므로 두 단계로 나눌 필요없이 smooth loss를 사용하게 됩니다.
size() estimation loss도 간단하게 smooth loss를 사용하게 되는데, 절대적인 값을 바로 regression하는 것이 아니라, 물체의 평균 크기(average object size)에 대한 residual 값을 regression하게 됩니다.
orientation() loss는 localization loss와 유사하게, 를 개(implementation detail: 12)의 bin으로 쪼개고 bin 안에서의 residual을 regression하게 됩니다.
Bin-based 3D Box Generation loss를 종합하면 다음과 같습니다!
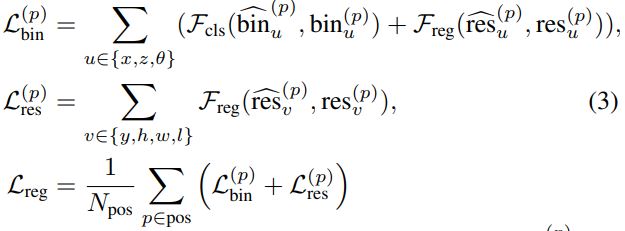
그리고 너무 많은 proposal을 stage-2로 넘기지 않기 위해서(모든 foreground point에서 proposal을 생성하면 너무 많겠죠?), training 시에는 BEV oriented IoU threshold 0.85로 NMS를 수행해서 top 300개만 남겨서 stage-2로 넘기고, inference 시에는 0.8로 NMS를 수행해서 top 100개만 stage-2로 넘긴다고 합니다.
2. Point cloud region pooling
Bottom-up 3D Proposal Generation 단계에서 3D box proposal을 얻었으니, 2-stage detector답게(?) 이 proposal에서 새롭게 feature를 뽑아주어야겠죠? 이를 point cloud region pooling이라고 합니다. 이는 stage-2의 첫번째 step이 됩니다. 아키텍처 그림을 다시 한 번 가져오겠습니다.
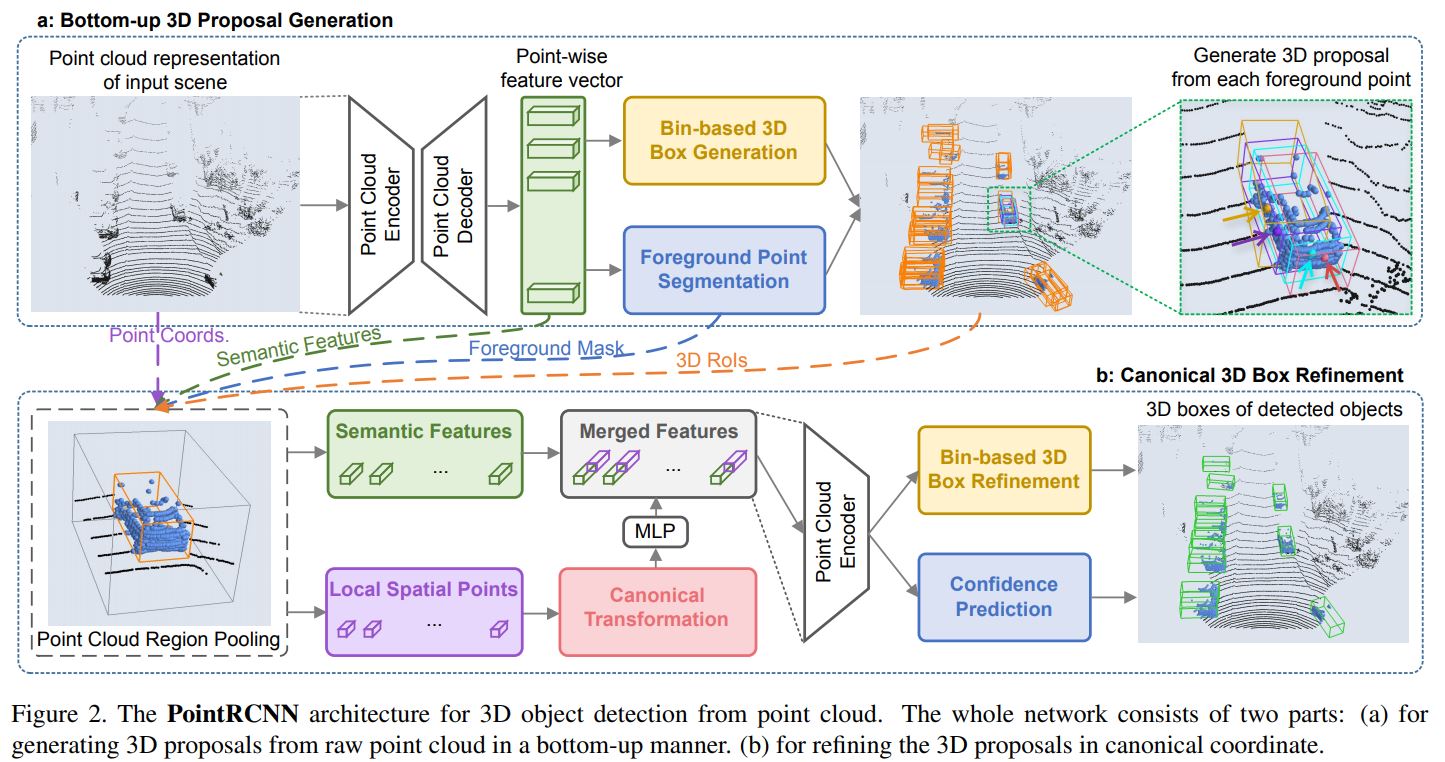
pooling을 하기 전에 proposal을 방향으로 각각 만큼 늘려주어(enlarge) 주변 정보(context)가 함께 encoding될 수 있도록 합니다. 그리고 모든 LiDAR point들에 대해 enlarged box 안에 있는지 아닌지를 판단하고(inside/outside test) enlarged box에 속하는 point들과 point의 feature를 해당 box의 refinement에 사용합니다. 어떤 feature들을 가져오게 되는지는 위 그림에서 위 아래 블록 사이의 점선을 보시면 알 수 있습니다.
(1)point coordinate and reflection intensity
(2)PointNet++를 거쳐 얻은 semantic feature
(3)foreground/ background segmentation mask
context 정보를 포함시키기 위해 box를 enlarge했으므로 box안의 모든 point들이 foreground는 아니겠죠? 그래서 segmentation mask도 포함시키게 된 것입니다. 그리고 당연하게도 point를 하나도 포함하지 않은 proposal은 제거를 하게 됩니다.
3. Canonical 3D bounding box refinement
이제 region proposal로부터 필요한 point과 feature를 가져왔고, 이것들로 bounding box refinement와 confidence prediction을 하게 됩니다. refinement는 말 그대로 bounding box를 좀 더 정확히 다듬는 과정이고, confidence prediction은 해당 region이 해당 object일 확률을 예측하는 것입니다. 여기서 짚고 넘어가야할 부분이, 많은 LiDAR 3D object detector들이 classification(Car인지, Cyclist인지, Pedestrian인지 분류)을 수행하는 것이 아니라, class마다 전용(?) detector를 따로 만들고 하나의 detector에서는 해당 class가 맞을 확률을 출력하게 되는 것입니다. 그래서 confidence prediction head는 binary classification 형태로 학습이 됩니다. GT와의 IoU에 따라 positive/negative label이 할당이 될 것입니다.
이제 refinement로 넘어오면, refinement를 하기 전에 Canonical transformation을 수행하게 됩니다. canonical transformation은 point들의 좌표를 box proposal의 local 좌표계로 변환해주는 과정이라고 보시면 됩니다. (1) 원점을 box proposal의 center로 옮기고, (2) 새로운 좌표축을 이라고 했을 때 지면에 수직인 은 기존의 와 동일하게 유지하고, 은 지면에 평행임을 유지하되 은 proposal의 head direction, 은 에 수직이 되도록 정하게 됩니다. 아래 그림을 참고해주세요.
![]()
이렇게 proposal 내의 point들의 좌표를 바꿔줌으로써 이후의 refinement stage가 local spatial feature를 더 잘 학습하도록 하기 위함이라고 합니다. stage-1, 즉 proposal generation 단계에서 PointNet++를 이용해 feature를 뽑았고, 그 feature를 가져왔음을 기억하실 겁니다.(위 아키텍처 그림에서 초록색 점선에 해당합니다) 이는 global 좌표를 이용해 얻은 feature이므로 global semantic feature라고 할 수 있고, stage-2에서는 여기에 local spatial feature를 덧붙여서 refinement를 수행하고자 하는 것입니다. 그래서 canonical transformation을 통해 local한 좌표로 바뀌면서 depth 정보를 잃게 되는 것을 알 수 있습니다. 예를 들어 LiDAR 특성 상 거리(depth)가 멀수록 point 수가 적을텐데, 그런 정보를 feature에 반영하기가 어려운 것이죠. 그래서 이를 보완하기 위해 LiDAR 원점에서 point까지의 거리(를 point마다 붙여주게 됩니다.
그래서 proposal에 포함된 점 의 local spatial feature를 결국 어떻게 만들까를 정리해보면,
(1) canonical coordiante으로 변환한 좌표
(2) point의 reflection intensity
(3) stage-1에서 가져온 foreground/background segmentation mask
(4) LiDAR 원점까지의 거리
을 모두 concatenate한 후 fully-connected layer들을 통과시켜 encoding하게 됩니다. 그리고 이렇게 얻은 local spatial feature를 global semantic feature와 다시 concatenate한 후(아키텍처 그림에서의 merged feature) confidence prediction과 box refinement를 수행하는 네트워크로 넣어주게 됩니다.
confidence prediction과 box refinement 네트워크의 학습을 위한 loss가 필요하겠죠. 먼저 GT box를 3D IoU가 0.55보다 큰 proposal에 할당합니다. confidence prediction에서 GT box가 할당된 proposal은 positive label을, 할당되지 않은 proposal은 negative label을 할당해서 cross entropy loss를 계산하게 됩니다.
box refinement는 GT box가 할당된 proposal에 대해서만 수행하게 됩니다. center refinement의 경우 proposal의 center에서 GT box center로의 regression을 stage-1에서의 bin-based localization과 동일한 방법으로 수행합니다(search range 만 줄여서 수행하는데, refinement 과정에서의 변화는 그리 크지 않기 때문입니다). size()역시 동일하게 average object size에 대한 residual을 regression하고, orientation은 IoU가 0.55이상인 proposal과 매칭한 점을 고려, 각도 residual을 []로 한정한 뒤 동일하게 bin-based로 regression을 수행합니다.
stage-2, 즉 3D bounding box refinement stage에서의 loss는 다음과 같습니다.
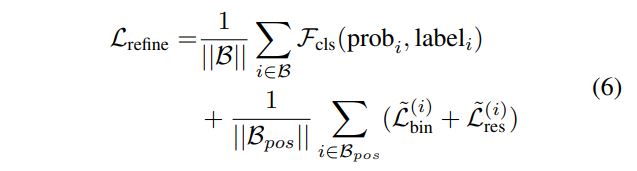
그리고 마지막으로 BEV IoU threshold 0.01로 oriented NMS를 수행하여 최종적인 3D bounding box를 남기게 됩니다!
이렇게 대표적인 point-based LiDAR 3D object detector인 PointRCNN에 대해 정리해보았습니다. 서두에서 말씀드렸듯이, 그리 오래되지 않은 논문이지만 LiDAR 3D object detection 분야에서는 VoxelNet과 함께 큰 두 개의 흐름을 만들어낸 논문이라고 생각합니다. VoxelNet과 비교하여 정리해보시면 도움이 되실 것 같습니다.
저도 가장 중요하게 생각한 2개의 논문을 정리하니 마음이 조금 가벼워지네요.
앞으로도 다양한 논문들을 소개하고 정리하도록 하겠습니다.
읽어주셔서 감사드립니다!
