[Paper Review] VoxelNet: End-to-end Learning for Point Cloud Based 3D Object Detection
LiDAR 3D object detection
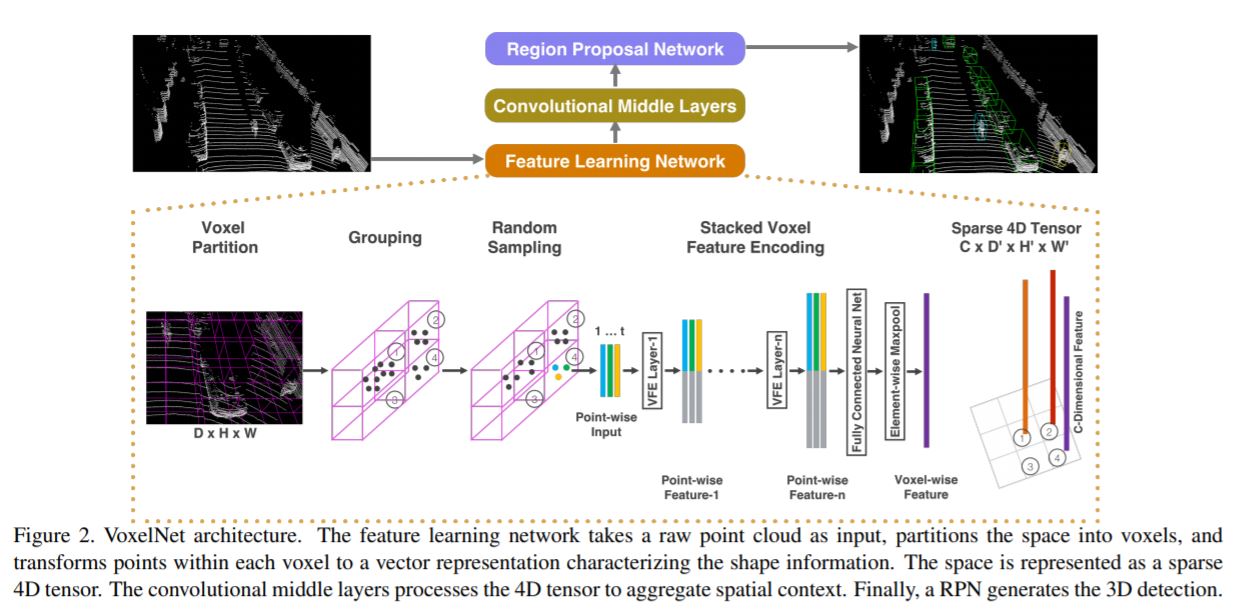
오늘 정리할 논문은 CVPR 2018에서 발표되었던 LiDAR기반의 3D object detection 분야의 대표 논문 중 하나인 VoxelNet: End-to-end Learning for Point Cloud Based 3D Object Detection입니다. 글을 쓰는 시점(20/10/31)에 800회에 가까운 인용수를 기록하고 있을 정도로, 딥러닝 기반의 LiDAR 3D object detection 분야에서 milestone이 된 논문 중 하나입니다.
앞으로 LiDAR 기반의 3D object detection 분야에서 중요하다고 생각하는 논문들을 하나씩 정리해보고자 합니다. LiDAR 3D object detection 분야를 공부하고자 한다면 다음 github 저장소가 좋은 시작점이 될 것이라고 생각합니다.
PointRCNN, A^2-Net, PV-RCNN 등 3D object detection 분야에서 좋은 논문들을 많이 쓰신 Shaoshuai Shi가 만든 코드인데요, 여러 가지 detector 모델들을 공통의 프레임워크로 구성해 쉽게 테스트해볼 수 있도록 구현되어 있습니다. visualization 코드까지 제공되어 결과를 확인해보기도 좋으니, 3D object detection 연구를 시작하시는 분이라면 이 코드를 가지고 놀아보는 게 좋다고 생각됩니다.
해당 코드에서 여러 detector 모델들을 다음과 같은 공통 프레임워크의 틀 안에서 정리할 수 있다고 하고 있습니다.
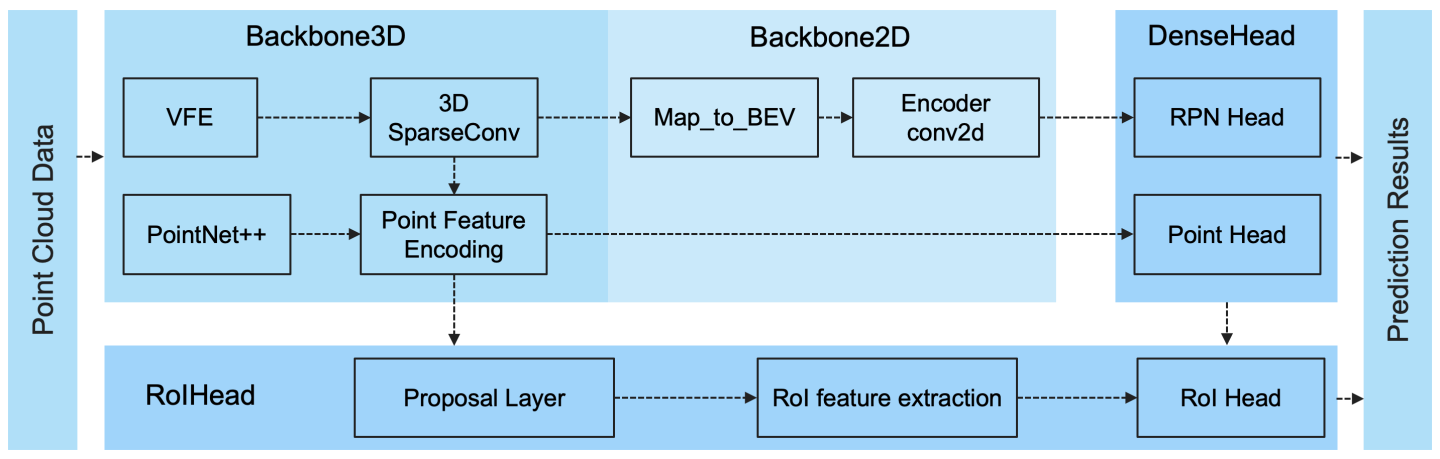
여러 가지 논문에 대한 이해없이 위 프레임워크에 대해 설명하는 것은 크게 의미가 없을 것 같아, 논문들을 소개하며 위 프레임워크의 모듈들에 대해 하나씩 이해해나가는 방식으로 글을 써나가려 합니다.
이 글에서 다룰 VoxelNet은 위 프레임워크 구조 속에서 다음과 같은 형태로 나타낼 수 있다고 합니다.
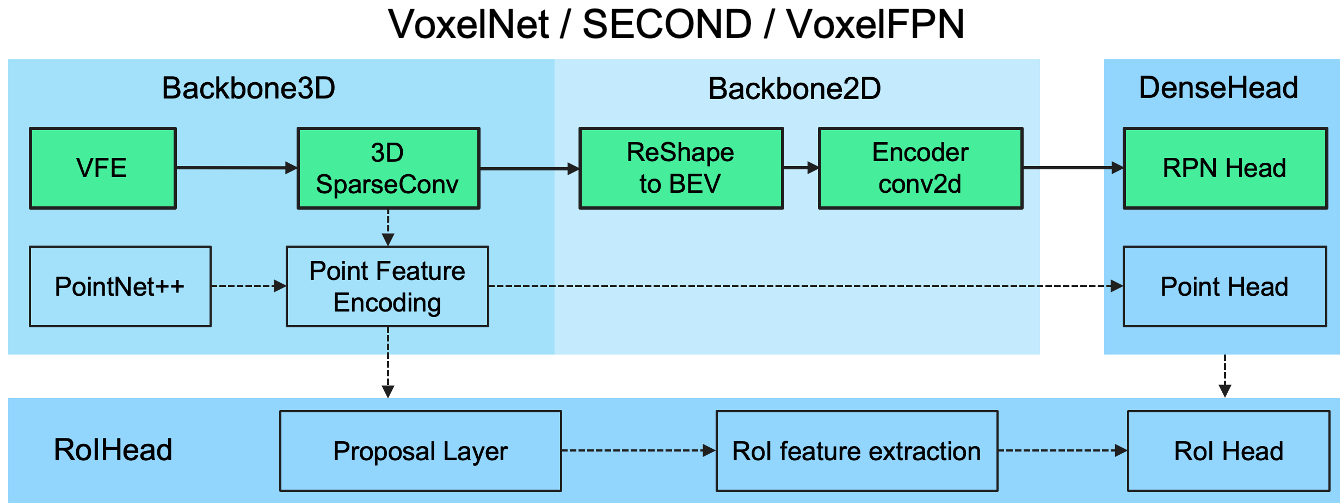
초록색으로 색칠된 모듈들이 사용되었다는 의미입니다. 논문 내용을 정리하며 위 구조에 대해 이해해봅시다.
Abstract
기존의 LiDAR 3D object detection 방법들은 LiDAR 데이터를 RPN(Region Proposal Network)에 넣기 위해 hand-crafted feature를 어떻게 만들 것인지에 대해 집중했다고 합니다. 이 논문에서는 hand-crafted feature를 제거하고 feature extraction과 bounding box prediction을 single stage로 통합하여 end-to-end로 학습 가능한 네트워크 VoxelNet을 제안했다고 합니다.
VoxelNet은 대표적인 1-stage(single-stage) detector입니다. 이미지 기반 detector와 마찬가지로, 먼저 object가 존재할 수 있는 region을 뽑고, 그 region의 feature를 이용해 최종적인 regression, classificaiton을 수행하는 2-stage detector와, 데이터 전체에서 feature를 뽑고 바로 bounding box prediction을 수행하는 1-stage detector가 있습니다.
VoxelNet은 point cloud를 같은 간격을 갖는 3D voxel로 쪼개고, VFE(Voxel Feature Encoding) layer를 통해 각 voxel 안의 point들을 이용해 voxel의 feature를 만들게 됩니다. 그리고 feature를 갖게 된 voxel들을 3D convolution을 통해 local voxel feature들을 통합하고, 이를 RPN에 넣어 bounding box를 생성하게 됩니다.
Architecture
먼저 논문에 제시된 전체적인 네트워크 구조를 봅시다.
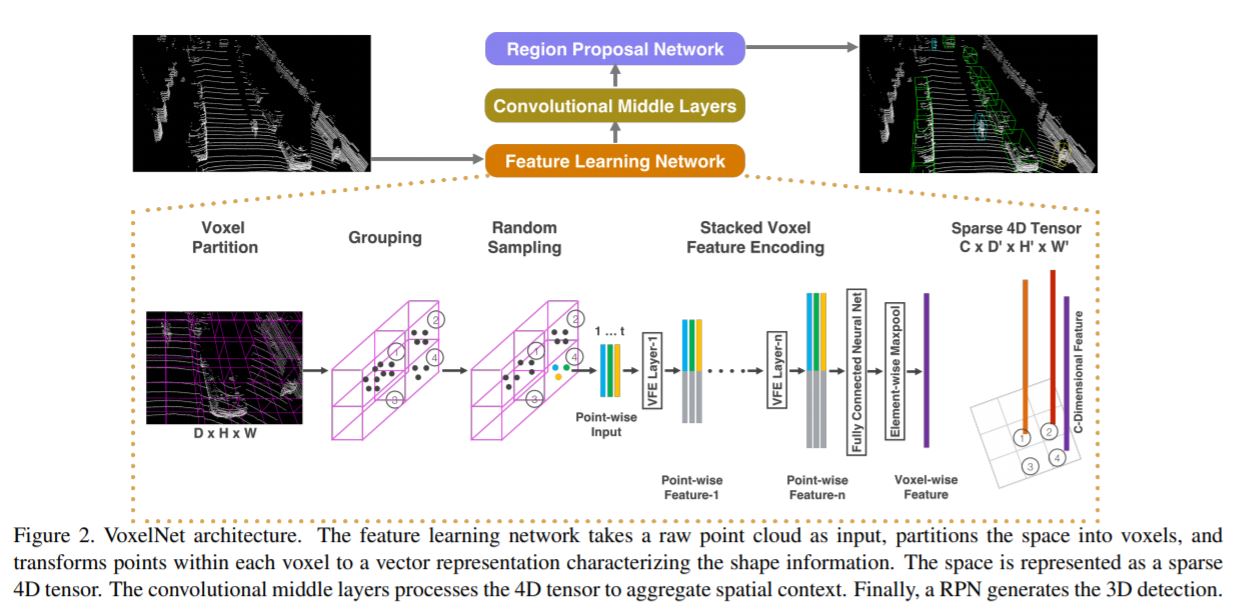
위 그림에 나타나 있듯이, 저자들은 VoxelNet을 크게 3가지 block으로 나눌 수 있다고 말합니다.
- Feature learning network
- Convolutional middle layers
- Region proposal network
1. Feature Learning Network
Voxel Partition
앞서 설명하였듯, 먼저 주어진 point cloud를 같은 크기의 직육면체들(voxel)로 쪼개야 합니다. 이를 voxelize한다고 합니다. KITTI 데이터에서 정의하는 LiDAR 좌표계는 위를 , 좌측을 , 전방을 로 정의합니다.
LiDAR point가 분포하는 영역의 축 길이를 , 축 길이를 , 축 길이를 라고 하고, 단위 voxel의 방향 길이를 각각 라 하면 point cloud 전체는 ()의 크기를 갖는 3D voxel grid로 쪼개질 것입니다.
KITTI 3D object detection task에서는 범위를 object class에 따라 다르게 정의하고 있습니다.
Car에 대해서는 범위를 X X 로,
Pedestrian, Cyclist에 대해서는 X X 로 정의하고 있습니다. Car보다 좁은 범위를 보는 이유는 Pedestrian, Cyclist가 훨씬 작아 거리가 멀면 너무 적은 point를 갖기 때문입니다.
또한 이미지에 projection했을 때 범위를 벗어나는 point들은 무시합니다. 이는 이미지에서 보이는 object들에 대해서만 labeling되어 있기 때문입니다.
해당 논문에서는 를 로 정했습니다. 논문에 따라 사용하는 voxel 크기가 다르고, class에 따라 voxel 크기를 다르게 정의하는 경우도 있습니다.
Grouping
point들을 속한 voxel에 할당하는 것을 말합니다. 이에 따라 point는 대응되는 voxel을, voxel은 대응되는 point group을 갖게 됩니다. LiDAR 데이터의 특성 상 voxel마다 다른 수의 point를 갖게 됩니다.
Random Sampling
10만 개 정도의 point를 갖는 LiDAR point cloud를 바로 처리하는 것은 엄청난 연산량을 요구할 뿐만 아니라, 위치에 따라 point의 밀도가 매우 크게 변하므로 density가 높은 곳으로 detection의 bias가 생길 수 있습니다. 따라서 voxel 당 최대 point 개수 를 정해 개 이상의 point를 갖는 voxel에 대해 개만을 sampling하여 남기게 됩니다. 이는 (1)연산량을 줄이고, (2)point density imbalance 문제를 줄여주며, (3)training에 variation을 더해주게 됩니다.
Stacked Voxel Feature Encoding
기존의 handcrafted feature에서 벗어나 end-to-end로 학습이 가능한, 이 논문에서 main contribution으로 내세우는 VFE layer입니다.
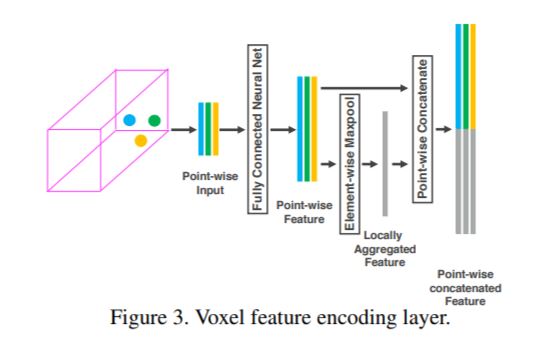
먼저 input으로 주어지는 LiDAR 데이터는 형태를 갖습니다. 3차원 좌표와 LiDAR의 beam이 반사된 세기를 나타내는 reflectance입니다. 먼저 voxel 안의 LiDAR point들의 3차원 좌표의 평균으로 무게중심(centroid)을 계산하고, 이 무게중심에 대한 각 point들의 상대위치를 계산해 원래 데이터에 concat해줍니다.
즉, 원래 point를 라고 하고 무게중심의 좌표를 라고 하면, 각 point의 feature는 가 됩니다.
그리고 이 feature를 FCN(Fully Connected Network)에 넣어 feature space로 보낸 후 voxel 내부의 모든 point들의 feature에 대해 element-wise max-pooling을 수행해 voxel-wise feature(위 그림의 Locally Aggregated Feature)를 얻은 뒤 각 point-wise feature와 연결해 최종적인 각 point의 feature(위 그림의 Point-wise concatenated Feature)를 얻게 됩니다.
FCN에 의한 feature space의 차원이 이었다면 voxel-wise feature와 concat까지 완료한 feature의 차원은 이 되겠죠! 그리고 이 새로운 point-wise feature들이 다음 VFE layer의 input이 됩니다.
여러 개의 VFE-layer를 거쳐 최종적으로 얻고자 하는 것은 point-wise feature가 아니라 voxel-wise feature입니다. VFE-layer를 모두 통과한 이후 얻어진 point-wise feature들을 마지막으로 FCN과 element-wise max-pooling을 통과시켜 최종적인 voxel-wise feature를 얻게 됩니다. Architecture 그림을 참고해주세요.
모든 non-empty voxel은 공통의 FCN을 통해 같은 방법으로 encoding 됩니다. 해당 논문에서는 VFE-layer 2개를 쌓아서 사용하고 있고, VFE-layer를 쌓는 것을 통해 voxel 내부의 point들의 shape information을 학습할 수 있다고 말합니다.
다시 한 번 강조하자면, VFE-layer는 voxel-wise feature를 뽑는 것이 목적입니다. point는 그 자체로 CNN을 적용하기 어렵기 때문에 3차원 공간을 직육면체 형태의 voxel들로 쪼개 3D CNN을 적용하기 적절한 구조를 만들고, 각 voxel의 feature를 계산한 것입니다.
Sparse Tensor Representation
sparse한 LiDAR point cloud의 특성 상, 90% 이상이 empty voxel이라고 합니다. 단순히 X X X 형태의 4차원 Tensor로 나타내면 엄청난 메모리, 연산량 낭비가 생길 것이므로, non-empty voxel들과 대응되는 feature를 list 형태로 관리하는 sparse tensor representation이 backpropagation 과정에서의 연산량과 메모리 사용량을 크게 줄여준다고 합니다.
2. Convolutional Middle Layers
voxel-wise feature를 뽑았으니, 이제 3D CNN을 수행해야겠죠? 논문에서 말하는 convolutional middle layer는 3D CNN + BN + ReLU를 가리킵니다. 해당 논문에서는 3개의 convolutional middle layer를 사용하고 있고, 이를 통해 receptive field를 넓혀가면서 voxel-wise feature들을 aggregation합니다.
3. Region Proposal Network
convolutional middle layers를 거쳐 얻은 feature들을 RPN에 넣어 최종적인 class score와 bounding box regression 결과를 얻게 됩니다. RPN의 구조는 다음과 같습니다.
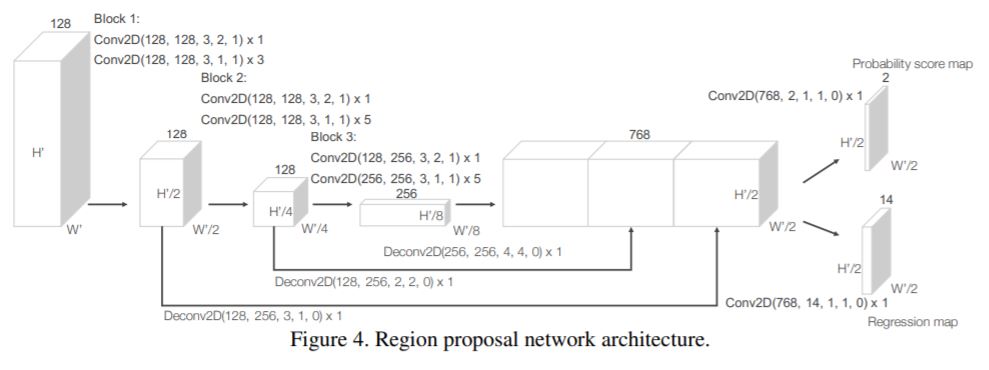
그림 상의 Conv2D, Deconv2D 괄호 안 숫자들은 (#input channel, #output channel, kernel size, stride size, padding size)이고, 곱해진 숫자는 해당 filter를 반복 적용한 횟수입니다.
3D convolution을 수행하면 4D feature map이 얻어졌을텐데, RPN에서 갑자기 2D convolution이 등장해서 당황스러울 수 있습니다. network details에서 답을 찾을 수 있는데요, convolutional middle layers로 얻은 64(channel) X 2(Z방향) X 400(Y방향) X 352(X방향) 형태의 4D tensor을 128 X 400 X 352로 reshaping하게 됩니다. 즉, BEV(Bird-Eye-View) feature map 형태로 변형하게 되는 것입니다.
총 3개의 fully convolutional layer block을 갖는데요, 각 block의 첫 번째 layer가 stride 2를 가져 feature map을 절반으로 downsampling하게 됩니다. 그리고 각 block을 거쳐 나온 feature들을 upsampling해서 같은 size로 만들어 준 후 concat해 주게 됩니다.
그리고 이 최종 feature map은 마지막 Conv2D layer를 통해 class score map과 regression map으로 mapping됩니다.
Loss function
네트워크 아키텍처를 살펴보았으니 loss function을 봅시다.
loss function을 정의하려면 먼저 ground truth가 어떤 형태인지부터 살펴봐야겠죠?
RPN에서 보았듯이, 네트워크의 최종적인 출력은 score와 bounding box regression이 됩니다. score map과 regression map이 어떤 값을 갖는지 이해하려면 anchor에 대해 짚고 넘어가야 합니다.
anchor는 많이들 알고 계시겠지만, pre-define된 bounding box를 가리킵니다. 3D object detection에서 bounding box의 parameter는 center의 3차원 좌표 , 길이, 폭, 높이 , 그리고 축에 대한 회전 로 총 7개입니다. anchor의 center 좌표는 feature map의 위치가 되고, 는 class에 따라 다르게 정해집니다. 예를 들어 Car의 경우, 해당 논문에서는 으로 세팅하였습니다. 는 ~의 범위를 갖습니다. 하나의 anchor로는 이 범위를 전부 커버하기 어려우므로 각각 의 를 갖는 anchor 2개를 각 위치마다 사용합니다.
위 RPN 그림에서 보시면 probability score map의 channel 수는 2이고, regression map의 channel 수는 14임을 볼 수 있습니다. 이는 각 BEV feature map 상의 위치마다anchor를 2개씩 사용하기 때문입니다. 각 anchor에 대해 해당 class가 맞을 확률을 나타내는 score를 계산하고, bounding box parameter 7개에 대한 regression을 수행하게 되므로 probability score map과 regression map의 채널이 각각 2, 14가 되는 것입니다.
하나의 anchor에 대해 계산하는 score가 1개인 이유는, anchor는 class에 따라 다르게 정의되고, 해당 anchor가 그 클래스 object가 맞을 확률을 출력하는 것이기 때문입니다. 'class가 car, cyclist, pedestrian 3갠데 score map의 channel 수가 6이어야 하지 않나?'라고 생각하실 수도 있을 것 같아(제가 그랬습니다 ㅎㅎ) 설명을 덧붙입니다.
이제 정말 loss function 얘기를 해봅시다. loss를 계산하려면 anchor와 ground truth를 연결지어야 합니다. 하나의 ground truth bounding box 주변에 무수히 많은 anchor들이 있을테니까요. 그 수많은 anchor들 중 ground truth bounding box와 IoU(Intersection over Union)가 특정값(이 논문에서 Car: 0.65, Pedestrian & Cyclist: 0.5)보다 큰 anchor들을 positive anchor, 특정값(모든 class 0.35)보다 작은 anchor들을 negative anchor로 정하게 됩니다. positive anchor에 대한 score는 1에 가깝게 출력이 되도록, negative anchor에 대한 score는 0에 가깝게 출력이 되도록 해야하므로 binary cross entropy loss로 학습이 이루어지도록 합니다.
그리고 positive anchor에 대해서는 regression loss를 계산하도록 합니다. 아래와 같이 residual로서 regression target을 정의하고 regression map이 이 residual 값들을 출력하도록 학습됩니다.
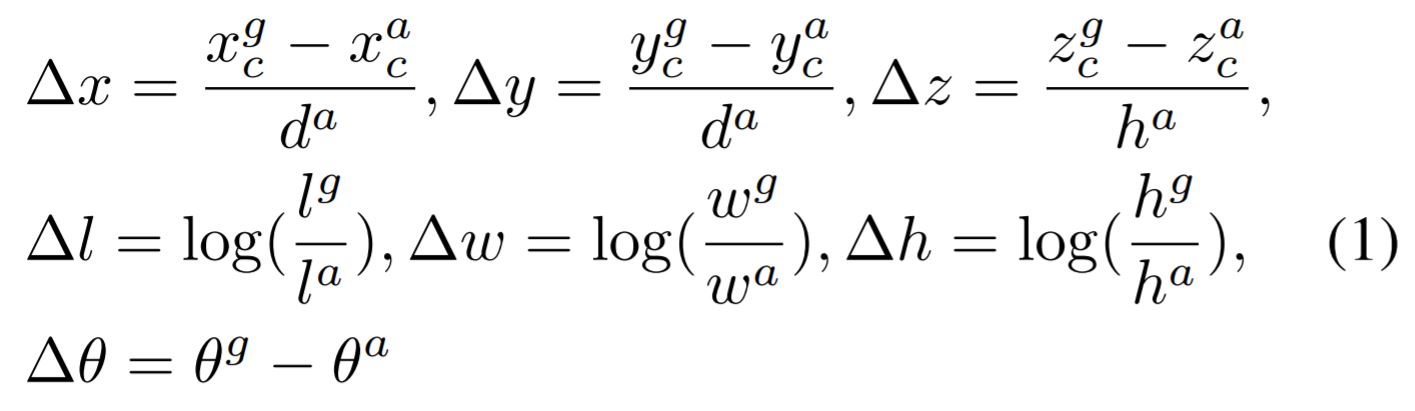
윗첨자 는 ground truth, anchor에 대응되고, 는 anchor 밑면의 대각선 길이이고 normalization을 위해 사용했다고 보시면 됩니다. regression loss는 위 target loss와 출력된 regression map 사이의 smooth L1 loss를 사용합니다.
모든 loss의 합은 다음과 같고, 는 loss 간의 balance를 위한 weight입니다.
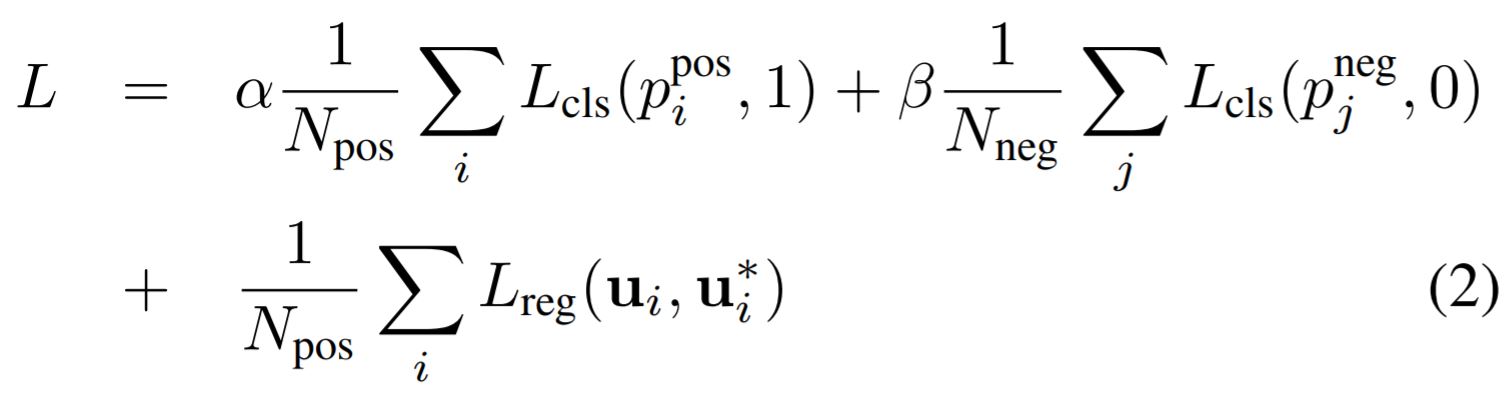
Efficient Implementation
저자들은 sparse한 point cloud의 특성을 이용하면서도(연산량, 메모리 사용량 절약) voxel grid 상에서 GPU 기반의 병렬처리가 가능한 방법을 제안한 것을 main contribution 중 하나로 소개하고 있습니다.
GPU는 dense한 tensor 연산에 특화되어 있습니다. 하지만 point cloud는 sparse하게 공간에 퍼져있고, 각 voxel마다 다른 개수의 point를 갖고 있으므로 GPU처리에 부적합합니다.
GPU 처리에 적합한 dense한 형태로 만들기 위해 다음 그림과 같은 과정을 수행합니다. VFE-layer에 input을 넣기 전에 수행하는 전처리 과정으로 보시면 됩니다.
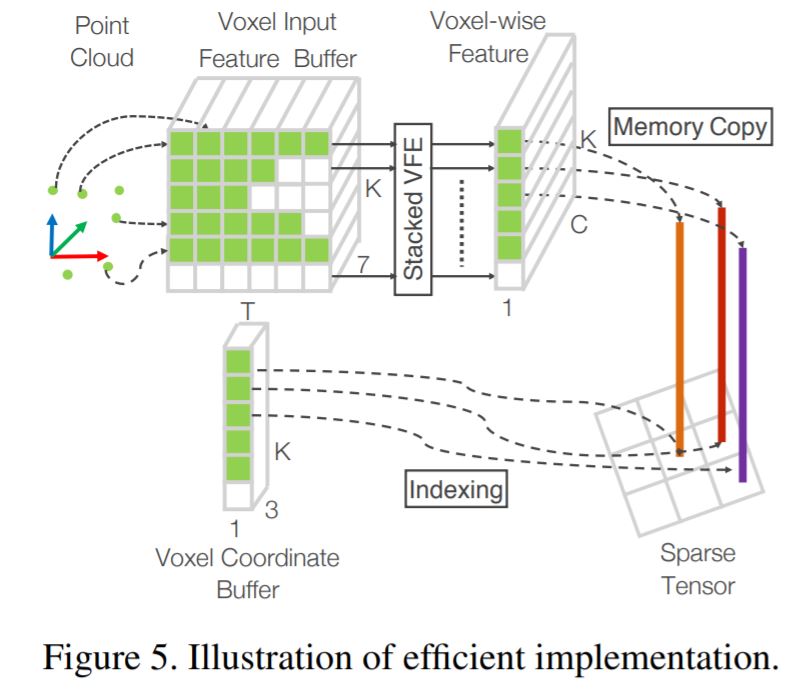
X X 차원의 tensor 구조를 갖는 Voxel Input Feature Buffer와 X X 차원의 Voxel Coordinate Buffer를 초기화합니다. 는 non-empty voxels의 최대 개수이고, 는 각 voxel이 가질 수 있는 point의 최대 개수입니다. 그리고 point를 쭉 돌면서 point가 속한 voxel이 초기화된 적이 없다면 voxel의 좌표를 voxel coordinate buffer에 추가하고 point를 형태의 7차원 벡터로 만들어 voxel input feature buffer의 해당 voxel 위치에 삽입합니다.
이렇게 Voxel Input Feature Buffer를 만들고 나면 point cloud가 dense한 tensor 구조로 표현되었으므로 VFE에 넣어 dense한 연산을 수행할 수 있게 되고, 이는 GPU에서 병렬처리됩니다. 모든 voxel이 개의 point를 갖는 것이 아니므로 비어 있는 곳들이 있을텐데요, 그곳은 0으로 채워 병렬 연산에 지장이 없도록 합니다.
VFE를 거쳐 Voxel-wise Feature를 얻고 나면, 만들어두었던 Voxel Coordinate Buffer를 이용해 해당 feature들을 다시 3D voxel grid 상으로 mapping시킬 수 있고, 이어지는 middle convolutional layer와 RPN로 들어가게 됩니다.
이러한 일련의 연산 과정을 하나의 contribution으로 내세운 것입니다. 3차원 공간 상에 불규칙하고 sparse하게 퍼진 point를 voxel input feature buffer라는 정해진 형태를 갖는 tensor로 바꾸어 처리를 하고, voxel의 feature를 얻은 다음에는 다시 3D CNN을 수행할 수 있는 3차원 공간 상으로 voxel feature를 다시 mapping하는 과정이 GPU 연산 효율을 높여주었다고 정리할 수 있겠습니다.
Data Augmentation
마지막으로 Voxelnet에서 사용한 data augmentation 기법들을 정리하고 글을 마무리하려 합니다.
1. GT bbox에 perturbation을 줍니다. bbox의 center를 중심으로 [] uniform distribution에서 sampling한 각도만큼 rotation시킨 후, 방향으로 각각 평균이 0이고 표준편차가 1인 Gaussian distribution에서 sampling한 값만큼 translation을 수행합니다. perturbation 결과로 충돌이 생기는지 확인하고 충돌이 있으면 원래대로 되돌리게 됩니다.
2. [0.95, 1.05] uniform distribution에서 sampling한 수만큼 모든 GT bbox들과 전체 point cloud에 global scaling을 적용합니다. 이는 다양한 거리, 다양한 크기를 갖는 object를 detection할 수 있도록, robustness에 도움을 준다고 합니다.
3. [] uniform distribution에서 sampling한 각도만큼 GT bbox들과 전체 point cloud에 원점을 중심으로 global rotation을 적용합니다. 1은 개별 bbox를 회전시킨 것이고, 3은 scene 전체를 회전시킨다는 점에서 다릅니다.
이렇게 대표적인 LiDAR 기반 1-stage detector인 VoxelNet을 정리해보았습니다. 이제 다시 아래 그림을 보시면 구조가 이해되실 거라 생각합니다.
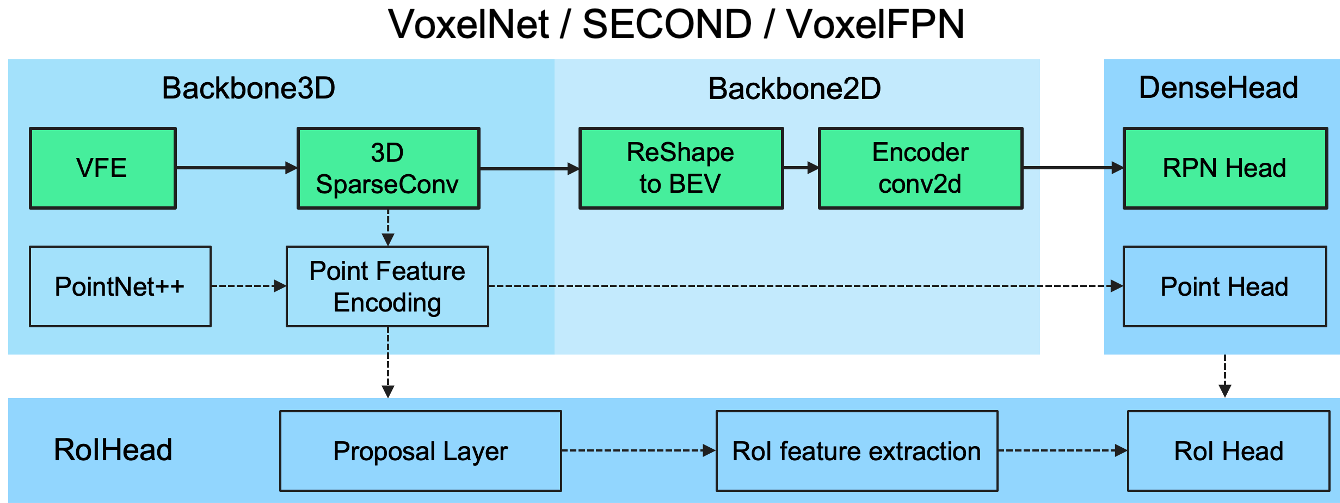
이렇게 VoxelNet은 간단한 구조로 sparse한 LiDAR point cloud를 handcrafted feature없이 end-to-end trainable한 1-stage detector를 제안한 훌륭한 논문입니다.
글재주가 부족하기도 하고, 웬만하면 대부분의 내용을 정리하려고 하다보니 글이 길어졌습니다. 1-stage detector의 시작점이 되는 논문인만큼 더 자세히 설명하려하였고, 이후 정리할 다른 1-stage detector들은 차이점을 중심으로 간결하게 정리할 수 있을 듯 합니다.
궁금하신 점이 있으시다면 댓글 부탁드립니다.
감사합니다.

감사합니다. 정리가 잘 되네요 ㅎㅎ