수학적인 함수, 수학적인 계산 담당.
- 넘파이 배열과 리스트의 차이점.
- 넘파이가 제공하는 다차원 배열 넘파이의 강력한 기능을 직접 사용하면서 익히기.
- 확률 분포와 난수 생성.
- 고차원 배열의 인덱싱 기법.
- 넘파이가 제공하는 데이터 분석 함수.
- 다수 변수들 간의 상관관계 계산.
리스트, 넘파이
- 리스트는 여러 개의 값들을 저장할 수 있는 자료구조 → 리스트는 다양한 자료형의 데이터를 여러 개 저장할 수 있으며 데이터를 변경하거나 추가, 제거할 수 있음.
- 하지만 데이터 과학에서는 파이썬의 기본 리스트로 충분하지 않음.
- 데이터를 처리할 때는 리스트와 리스트 간의 다양한 연산이 필요함.
- 따라서 데이터 과학자들은 기본 리스트 대신에 넘파이 선호.
Numpy란,
→ numpy는 C언어로 구현된 파이썬 라이브러리로써, 고성능의 수치계산을 위해 제작.
먼저, numpy를 이용하기 위해서는 numpy를 import해야 함.
import numpy as npnumpy 기초.
# numpy 사용하기.
import numpy as np
# Array 정의하기.
data1 = [1,2,3,4,5]
data1
data2 = [1,2,3,3.5,4]
data2
# numpy를 이용하여 array 정의.
# 1. 위에서 만든 python list를 이용.
arr1 = np.array(data1)
arr1
# array의 형태(크기)를 확인할 수 있음.
arr1.shape
# 2. 바로 python list를 넣어 줌으로써 만듦.
arr2 = np.array([1,2,3,4,5])
arr2
arr2.shape
# array의 자료형을 확인할 수 있음.
arr2.dtype
arr3 = np.array(data2)
arr3
arr3.shape
arr3.dtype
arr4 = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
arr4
arr4.shapeNumpy shape
numpy에서는 해당 array의 크기를 알 수 있음. shape 을 확인함으로써 몇개의 데이터가 있는지, 몇 차원으로 존재하는지 등을 확인할 수 있음. 위에서 arr1.shape의 결과는 (5,) 으로써, 1차원의 데이터이며 총 5라는 크기를 갖고 있음을 알 수 있음. arr4.shape의 결과는 (4,3) 으로써, 2차원의 데이터이며 4 * 3 크기를 갖고 있는 array.
Numpy 자료형.
arr1이나 arr2는 int64라는 자료형을 갖는 것에 반해 arr3는 float64라는 자료형을 갖음. 이는 arr3 내부 데이터를 살펴보면 3.5라는 실수형 데이터를 갖기 때문임을 알 수 있다. numpy에서 사용되는 자료형은 아래와 같다. (자료형 뒤에 붙는 숫자는 몇 비트 크기인지를 의미한다.)
- 부호가 있는 정수 int(8, 16, 32, 64)
- 부호가 없는 정수 uint(8 ,16, 32, 64)
- 실수 float(16, 32, 64, 128)
- 복소수 complex(64, 128, 256)
- 불리언 bool
- 문자열 string_
- 파이썬 오브젝트 object
- 유니코드 unicode_


Numpy 장점.
Numpy의 별칭 만드기와 간단한 배열 연산.

다차원 배열.

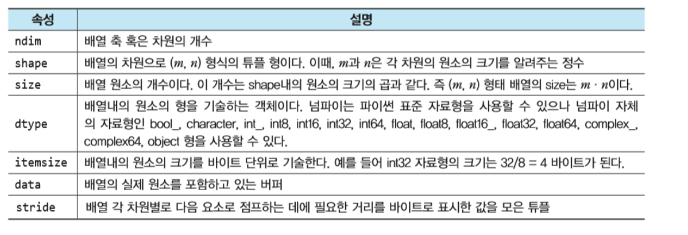
실습.
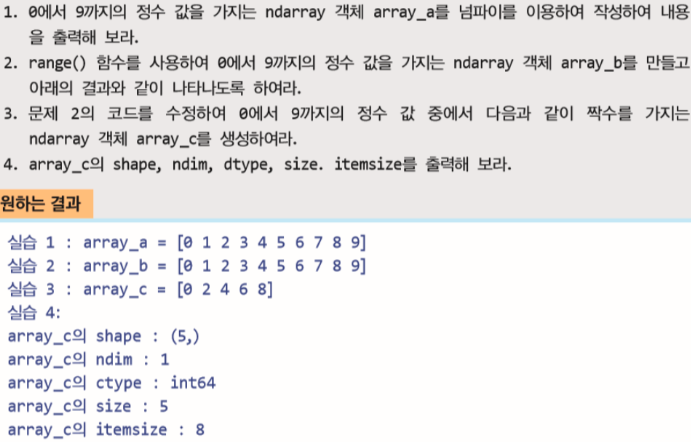
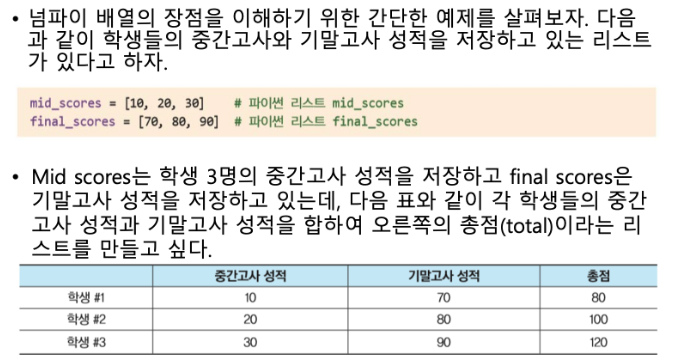
강력한 Numpy 배열의 연산 예제.
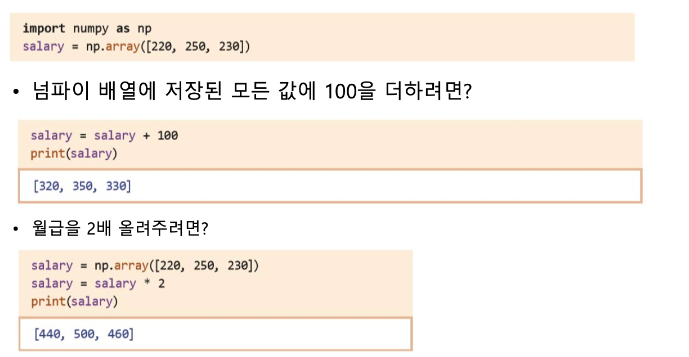

문제.

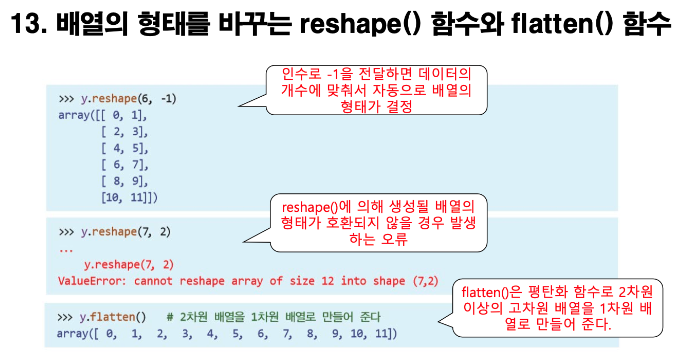
np.zeros(), np.ones(), np.arange() 함수.
→ numpy에서 array를 정의할 때 사용되는 함수들.
np.zeros(10)
np.zeros((3,5))
# np.ones() 함수는 인자로 받는 크기만큼, 모든요소가 1인 array를 만듦.
np.ones(9)
np.ones((2, 10))# np.arange() 함수는 인자로 받는 값 만큼 1씩 증가하는 1차원 array를 만듦.
# 이때 하나의 인자만 입력하면 0~ 입력한 인자, 값 만큼의 크기를 가짐.
np.arange(10)
np.arange(3, 10)Array 연산.
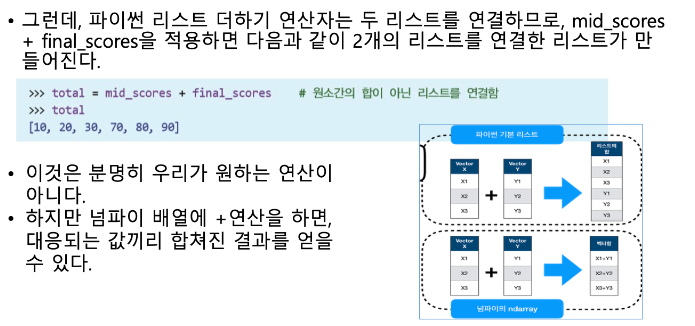
기본적으로 numpy에서 연산을 할때는 크기가 서로 동일한 array 끼리 연산이 진행된다.
이때 같은 위치에 있는 요소들 끼리 연산이 진행된다.
arr1 = np.array([[1,2,3], [4,5,6]])
arr1
arr1.shape
arr2 = np.array([[10, 11, 12], [13, 14, 15]])
arr2
arr2.shape
# array 덧셈.
arr1 + arr2
# array 뺄셈.
arr1 - arr2
# array 곱셈.
arr1 * arr2
# array 나눗셈.
arr1 / arr2
# array의 브로드 캐스트.
# 위에서는 array가 같은 크기를 가져야 서로 연산이 가능하다고 했지만,
# numpy에서는 브로드캐스트라는 기능을 제공
# 브로드캐스트란, 서로 크기가 다른 array가 연산이 가능하게 끔 하는 것.
arr1
arr1.shape
arr3 = np.array([10,11,12])
arr3
arr3.shape
arr1 + arr3
arr1 * arr3
arr1 * 10
# 각각의 데이터의 제곱처리.
arr1 ** 2Array 인덱싱.
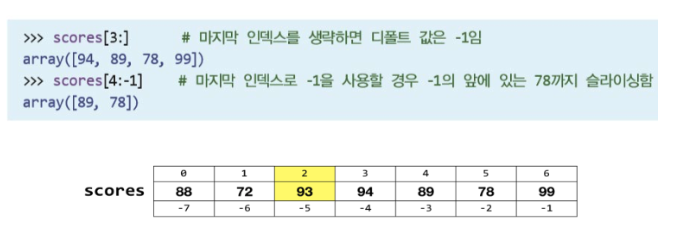
numpy에서 사용되는 인덱싱은 기본적으로 python 인덱싱과 동일. 이때, python에서와 같이 1번째로 시작하는 것이 아니라 0번째로 시작하는 것에 주의.
import numpy as np
arr1 = np.arange(10) # 0 ~ 9까지 숫자를 numpy배열에 표현이 되어짐.
arr1
# 1번째 데이터.
arr1[0]
# 3번째 데이터.
arr1[2]
# 4번째 요소부터 9번째 요소.
arr1[3:9]
# 전체 데이터를 뽑음.
arr1[:]arr2 = np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,12]])
arr2# 2차원의 array 에서 인덱싱을 하기 위해선 2개의 인자를 입력해야 함.
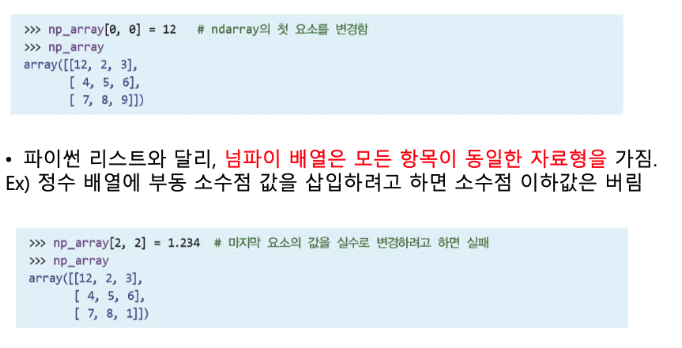
arr2[0, 0]# 3행의 모든 요소 꺼내기.
arr2[2, :]# 3행의 4번째 요소 꺼내기.
arr2[2, 3]# 모든 행, 열의 4번째 요소 꺼내기
arr2[:, 3]Array boolean 인덱싱(마스크)
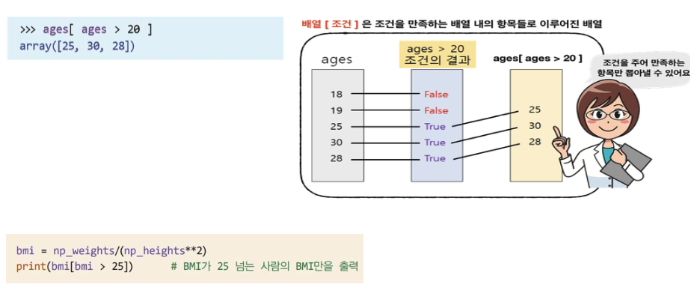
위에서 이용한 다차원의 인덱싱을 응용하여 boolean 인덱싱을 할 수 있음. 해당 기능은 주로 마스크라고 이야기하는데, boolean인덱싱을 통해 만들어낸 array를 통해 우리가 원하는 행 또는 열의 값만 뽑아낼 수 있음. 즉, 마스크처럼 우리가 가리고 싶은 부분은 가리고, 원하는 요소만 꺼낼 수 있음.
names = np.array(['Beomwoo','Beomwoo','Kim','Joan','Lee','Beomwoo','Park','Beomwoo'])
namesnames.shape# 아래에서 사용되는 np.random.randn() 함수는 기대값이 0이고, 표준편차가 1인 가우시안 정규 분포를 따르는 난수를 발생시키는 함수.
# 이 외에도 0~1의 난수를 발생시키는 np.random.rand() 함수도 존재함.
data = np.random.randn(8,4) # 가로(row) 8, 세로(col) 4 인 데이터 구조를 가지는 난수(랜덤한 숫자)를 생성해라.
datadata.shape위와 같은 names와 data라는 array가 있음. 이때, names의 각 요소가 data의 각 행과 연결된다고 가정해보자. 그리고 이 때, names가 Beomwoo인 행의 data만 보고 싶을 때 다음과 같이 마스크를 사용.
# 요소가 Beomwoo인 항목에 대한 mask 생성.
names_Beomwoo_mask = (names == 'Beomwoo')
names_Beomwoo_maskdata[names_Beomwoo_mask,:] # data[names == 'Beomwoo', :]# 요소가 Kim인 행의 데이터만 꺼내기
data[names == 'Kim',:]# 논리 연산을 응용하여, 요소가 Kim 또는 Park인 행의 데이터만 꺼내기
data[(names == 'Kim') | (names == 'Park'),:]# 먼저 마스크를 만든다.
# data array에서 0번째 열이 0보다 작은 요소의 boolean 값은 다음과 같음.
data[:,0] < 0# 위에서 만든 마스크를 이용하여 0번째 열의 값이 0보다 작은 행을 구함.
data[data[:,0]<0,:]이를 통해 특정 위치에만 우리가 원하는 값을 대입할 수 있다.
위에서 얻은, 0번째 열의 값이 0보다 작은 행의 2,3번째 열값에 0을 대입.
# 0번째 열의 값이 0보다 작은 행의 2,3번째 열 값.
data[data[:,0]<0,2:4]data[data[:,0]<0,2:4] = 0
dataNumpy 함수.
arr1 = np.random.randn(5,3)
arr1# 각 성분의 절대값 계산하기
np.abs(arr1)# 각 성분의 제곱근 계산하기 ( == array ** 0.5)
np.sqrt(arr1)# 각 성분의 제곱 계산하기
np.square(arr1)# 각 성분을 무리수 e의 지수로 삼은 값을 계산하기
np.exp(arr1)# 각 성분을 자연로그, 상용로그, 밑이 2인 로그를 씌운 값을 계산하기
np.log(arr1)
np.log10(arr1)
np.log2(arr1)# 각 성분의 부호 계산하기(+인 경우 1, -인 경우 -1, 0인 경우 0)
np.sign(arr1)# 각 성분의 소수 첫 번째 자리에서 올림한 값을 계산하기
np.ceil(arr1)# 각 성분의 소수 첫 번째 자리에서 내림한 값을 계산하기
np.floor(arr1)np.isnan(np.log(arr1))# 각 성분이 무한대인 경우 True를, 아닌 경우 False를 반환하기
np.isinf(arr1)# 각 성분에 대해 삼각함수 값을 계산하기(cos, cosh, sin, sinh, tan, tanh)
np.sin(arr1)두 개의 array에 적용되는 함수.
arr1arr2 = np.random.randn(5,3)
arr2# 두 개의 array에 대해 동일한 위치의 성분끼리 연산 값을 계산하기
# (add, subtract, multiply, divide)
np.multiply(arr1,arr2)# 두 개의 array에 대해 동일한 위치의 성분끼리 비교하여 최대값 또는 최소값 계산하기(maximum, minimum)
np.maximum(arr1,arr2)통계 함수.
통계 함수를 통해 array의 합이나 평균등을 구할 때,
추가로 axis라는 인자에 대한 값을 지정하여 열 또는 행의 합 또는 평균등을 구할 수 있음.
arr1
# 전체 성분의 합을 계산
np.sum(arr1)
# 행 간의 합을 계산
np.sum(arr1, axis=1)
# 열 간의 합을 계산
np.sum(arr1, axis=0)
# 전체 성분의 평균을 계산
np.mean(arr1)
# 행 간의 평균을 계산
np.mean(arr1, axis=0, 1)
# 전체 성분의 표준편차, 분산, 최소값, 최대값 계산(std, var, min, max)
np.std(arr1)
np.min(arr1, axis=0, 1)
# 전체 성분의 최소값, 최대값이 위치한 몇번째를 반환(argmin, argmax)
np.argmin(arr1)
np.argmax(arr1,axis=0, 1)
# 맨 처음 성분부터 각 성분까지의 누적합 또는 누적곱을 계산(cumsum, cumprod)
np.cumsum(arr1)
np.cumsum(arr1,axis=0, 1)
np.cumprod(arr1)넘파이에서의 인덱싱과 슬라이싱.

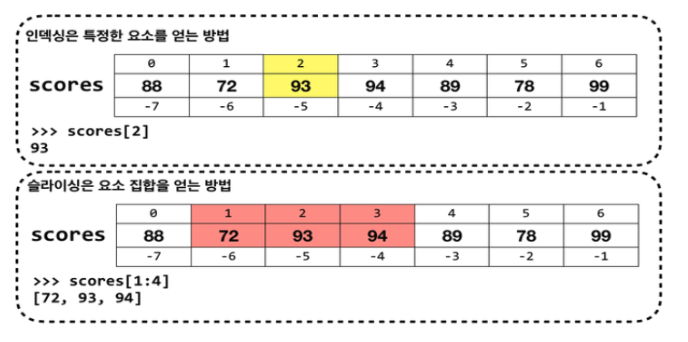
논리적인 인덱싱을 통한 값 추출.

2차원 배열의 인덱싱.