자료구조
시리즈, 데이터프레임.
- 시리즈 : 데이터프레임에서 하나의 열만 해당하는 부분.
- 데이터프레임 : 두 개 이상의 열들이 모여 프레임을 이루는 구조.
Pandas는 Python에서 사용되는 데이터 분석 라이브러리입니다. Numpy와 함께 사용되며, 데이터를 빠르게 처리하고, 다양한 방법으로 조작할 수 있습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plts = pd.Series([1,3,5,np.nan,6,8])
s→ datetime 인덱스와 레이블이 있는 열을 가지고 있는 numpy 배열을 전달하여 데이터프레임을 만듦.
dates = pd.date_range('20130101', periods = 6)datesdates = pd.date_range('20130101', periods = 8)datesdf = pd.DataFrame(np.random.randn(8, 4), index = dates, columns=list('ABCD'))df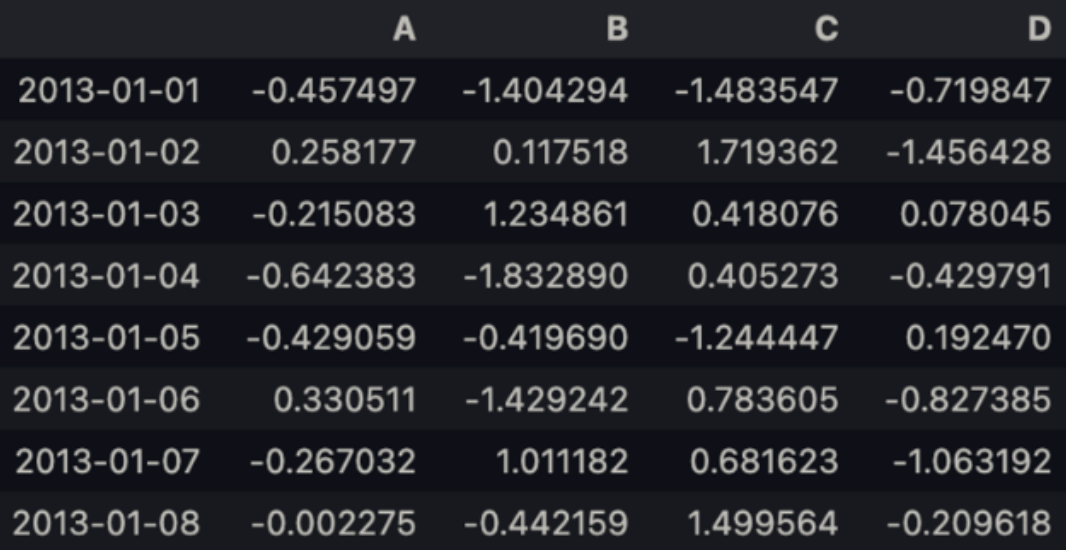
→ Series와 같은 것으로 변환될 수 있는 객체들의 dict로 구성된 데이터프레임을 만듦.
df2 = pd.DataFrame({'A' : 1.,
'B' : pd.Timestamp('2 'D' : np.array([3] * 4, dtype = 'int32'),
'E' : pd.Categorical(['test', 'train', 'test', 'train']),
'F' : 'foo'})df2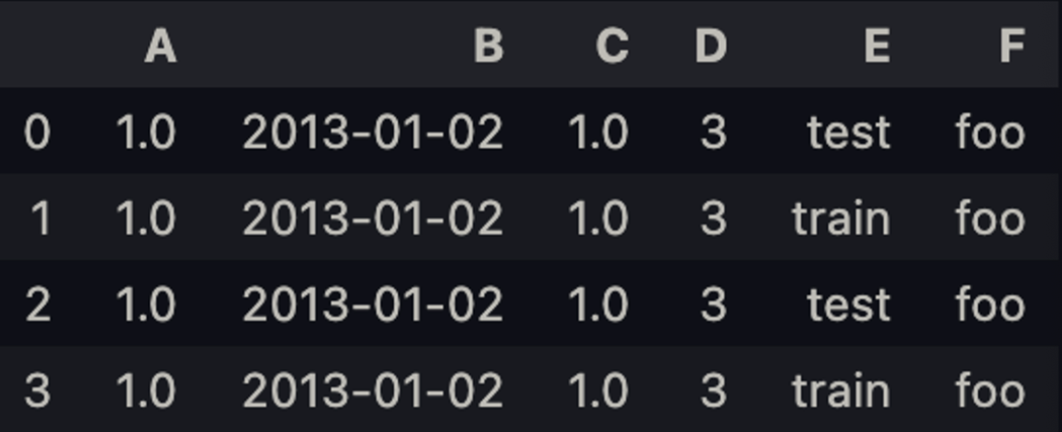
df2.dtypes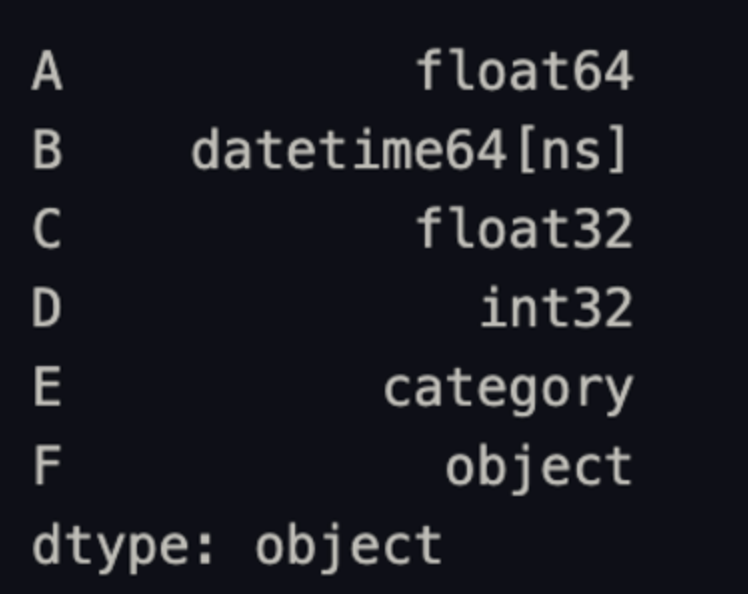
Viewing Data(데이터 확인.)
df.tail(3) # 끝에서 마지막 3줄을 불러옴.
df.tail() # 끝에서 마지막 5줄 불러옴.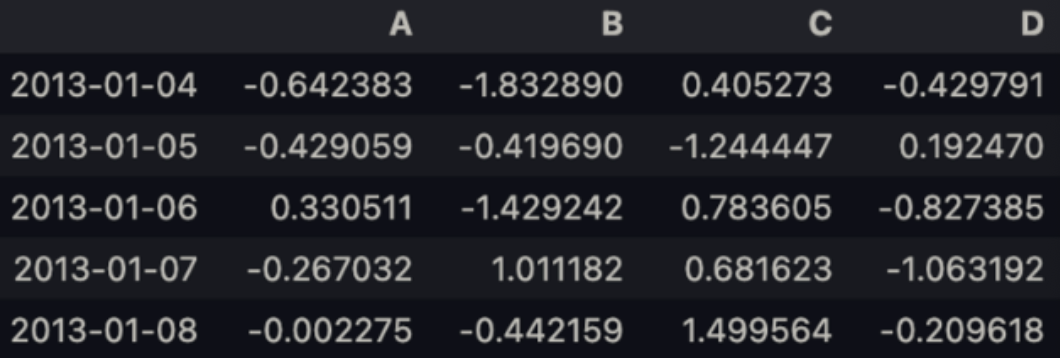
df.head()
df.head(3)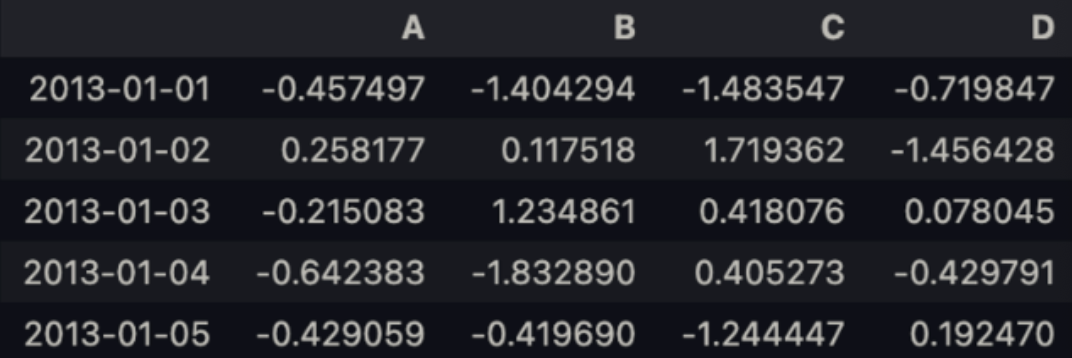
→ 인덱스, 열, numpy 데이터에 대한 세부정보를 볼 수 있음.
df.index
df.columns
df.values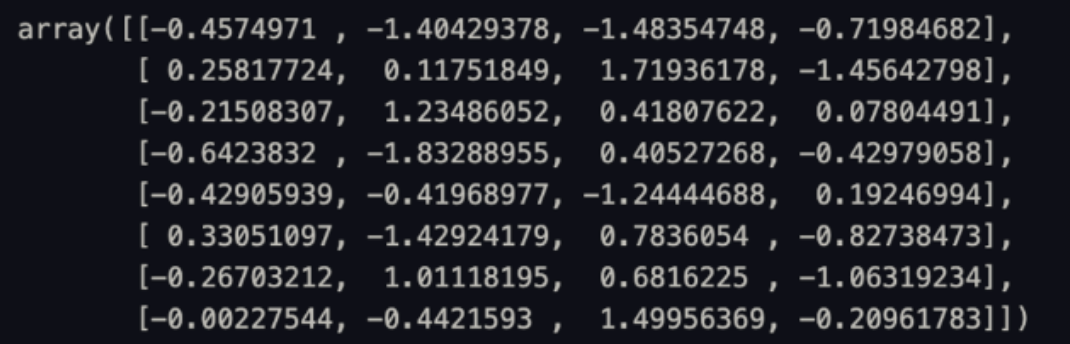
df.describe()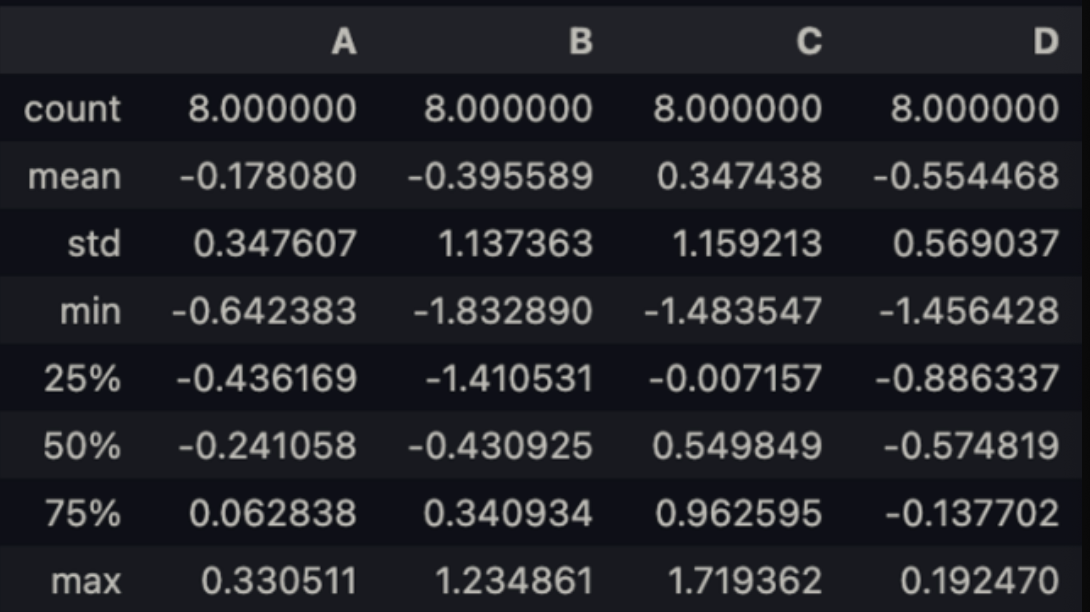
df.T # 전치 행렬. -> 열과 행을 바꾸는 함수.
df.sort_index(axis = 1, ascending=False)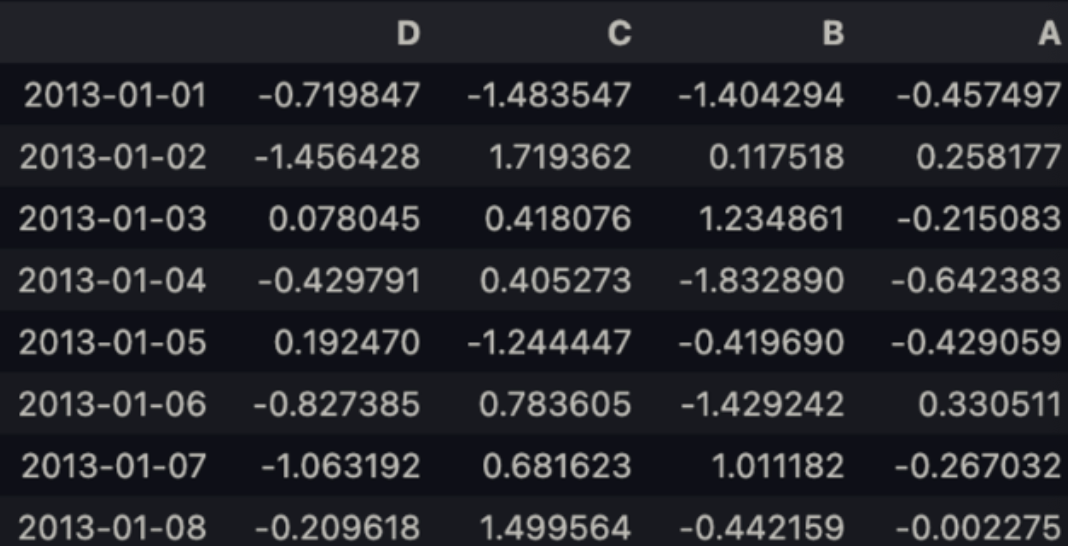
df.sort_values(by = 'B')
# ascending = False - 내림차순.(큰값 -> 작은값)
# ascending = True - 오름차순.(작은값 -> 큰값)
Selection (선택.)
Getting (데이터 얻기.)
df['A']→ 단일 열을 선택 함.
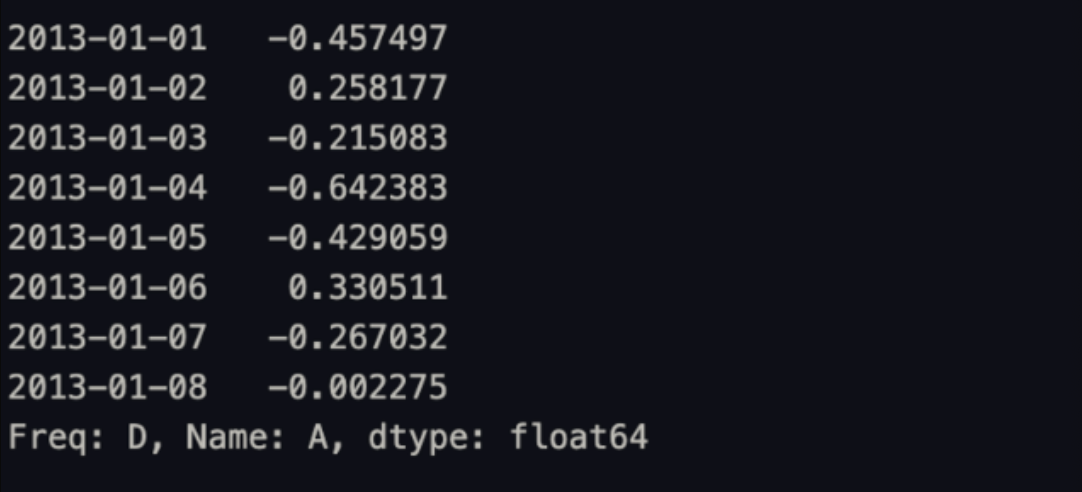
df[0:3]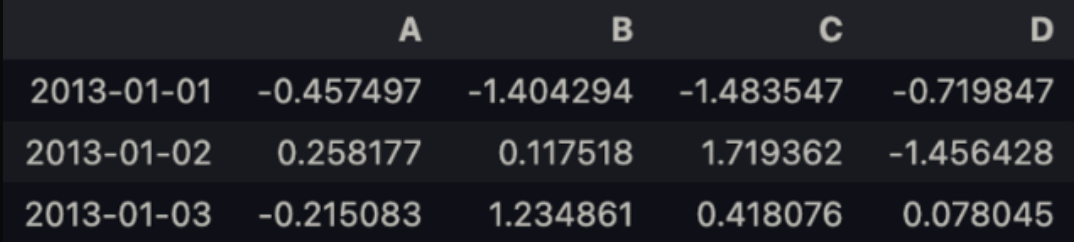
df['20130102':'20130104']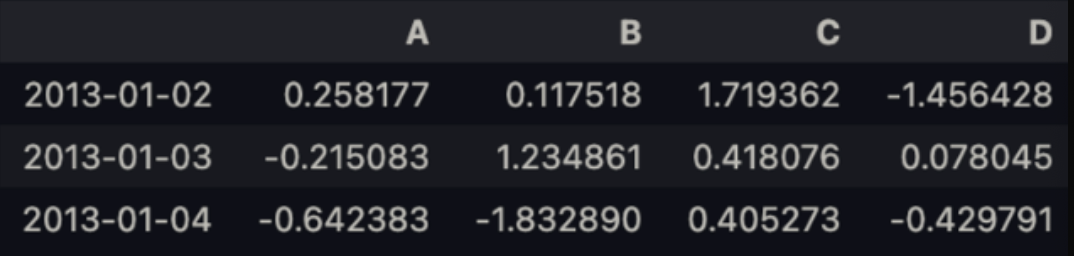
Selection by Label (Label 을 통한 선택.)
df.loc[dates[0]]
# loc, iloc 데이터 접근 하는 함수.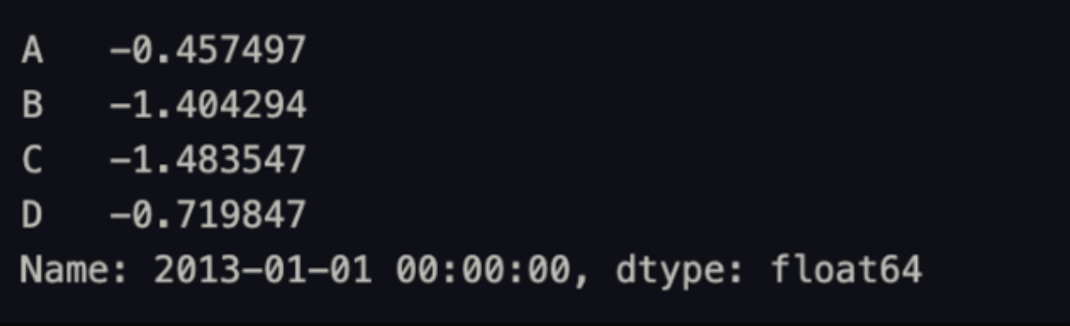
df.loc[:,['A','B']]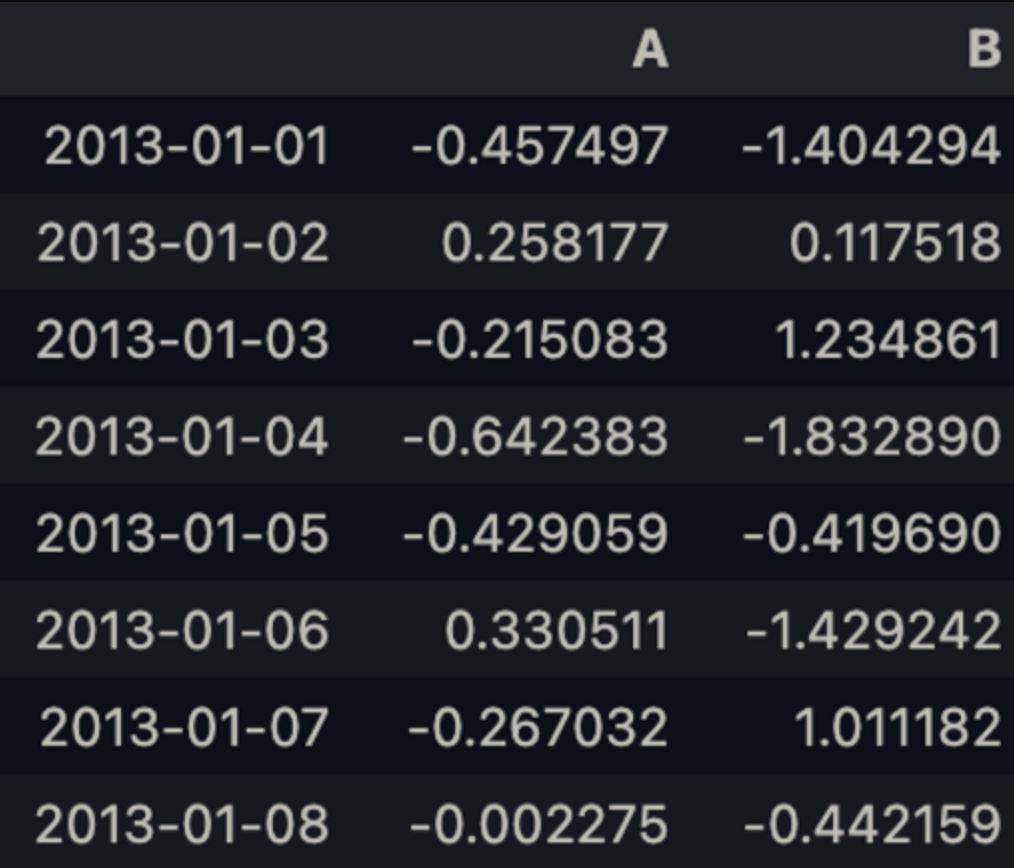
df.loc['20130102':'20130104', ['A', 'B']]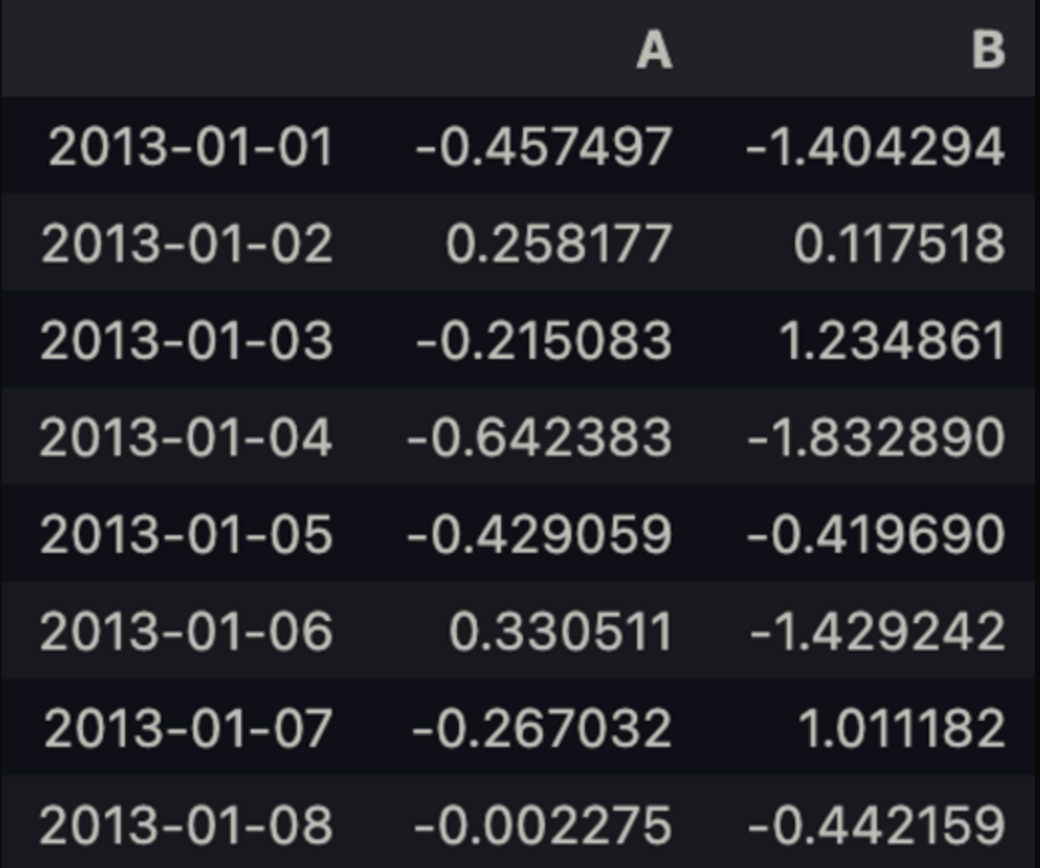
df.loc[dates[0], 'A']
selection by Position(위치로 선택.)
df.iloc[3]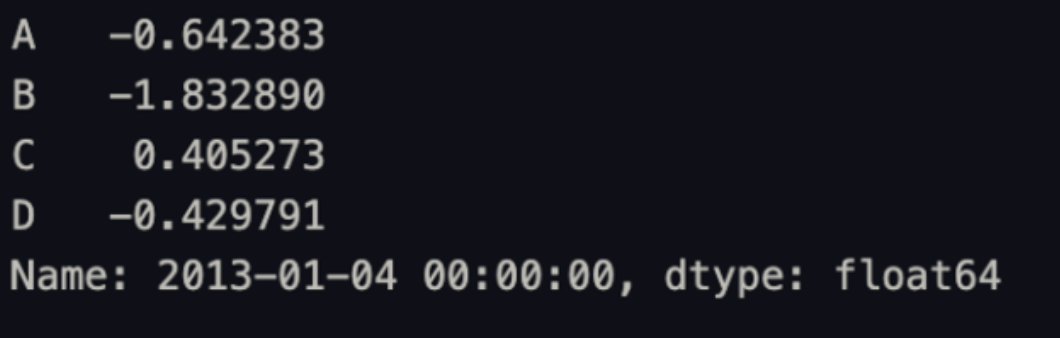
df.iloc[3:5, 0:2]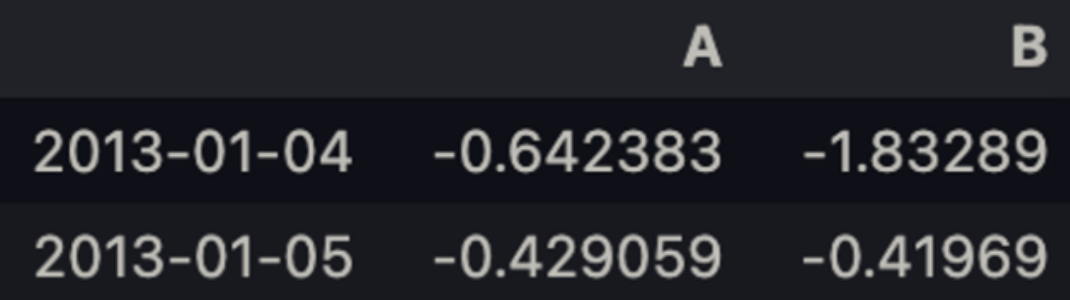
df.iloc[[1,2,4], [0,2]]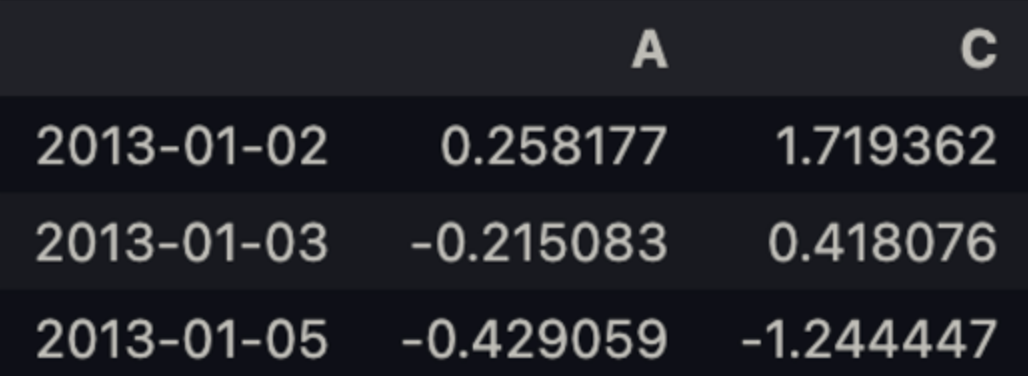
df.iloc[1:3, :]
df.iloc[:,1:3]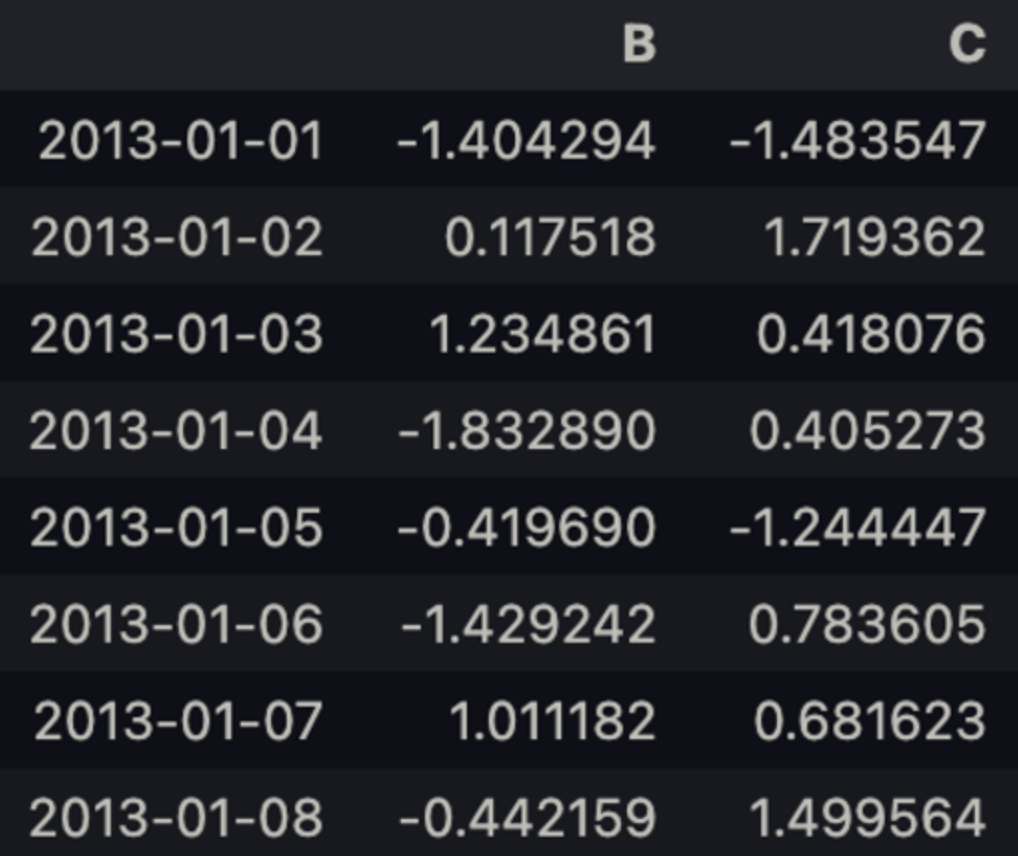
df.iloc[1,1]
Boolean Indexing.
df[df.A > 0]
→ 데이터를 선택하기 위해 단일 열의 값을 사용.
df[df > 0]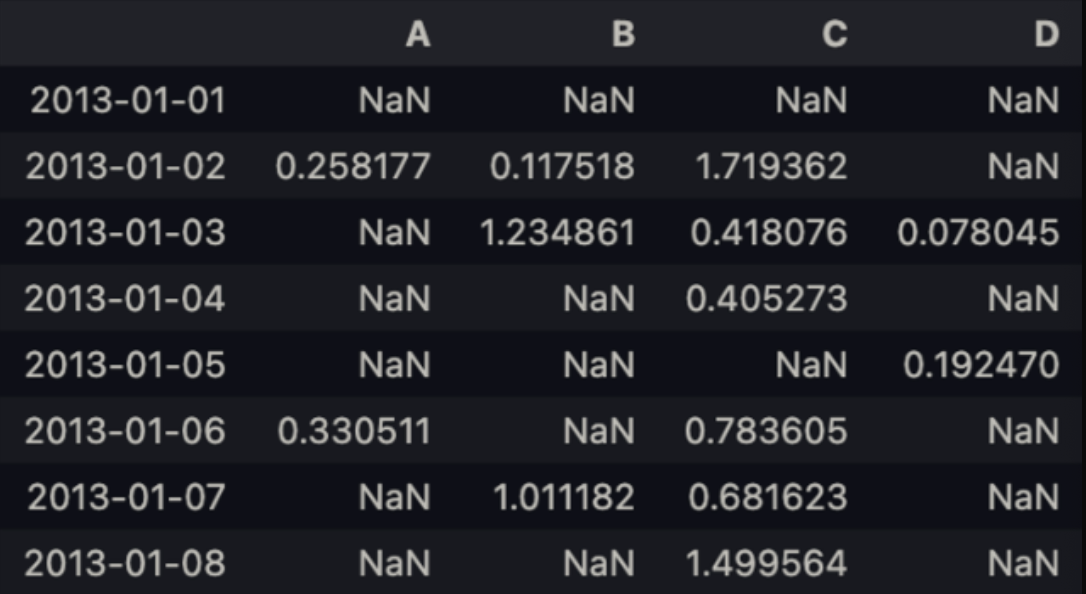
📌 필터링을 위한 메소드 isin()을 사용.
df2 = df.copy()df2['E'] = ['one', 'one', 'two', 'three', 'four',
'three', 'Three', 'four']df2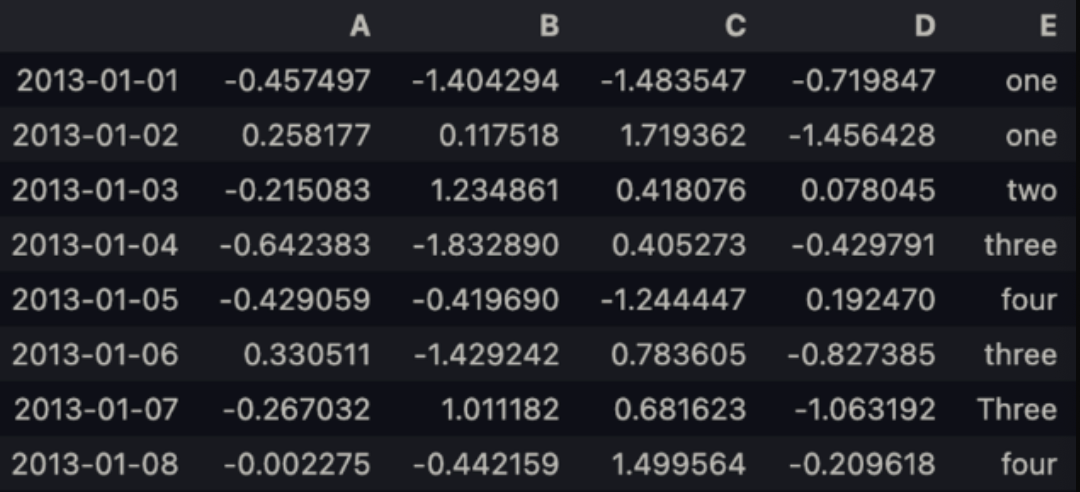
df2[df2['E'].isin(['two','four'])]
# categorical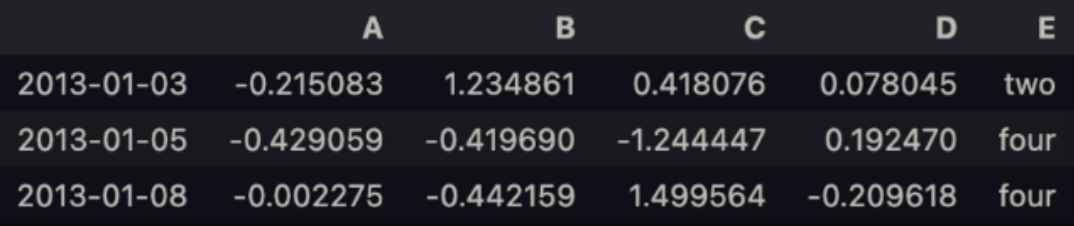
s1 = pd.Series([1,2,3,4,5,6,7,8], index=pd.date_range('20130102', periods=8))s1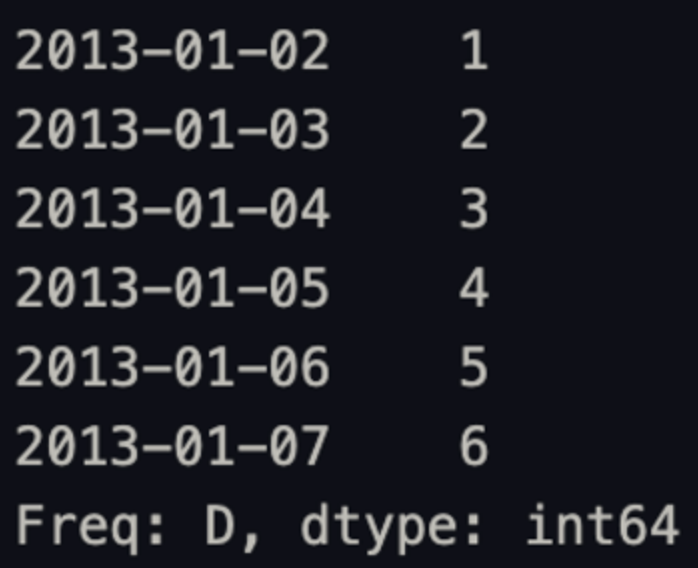
df['F'] = s1df
→ 라벨에 의해 값을 설정.
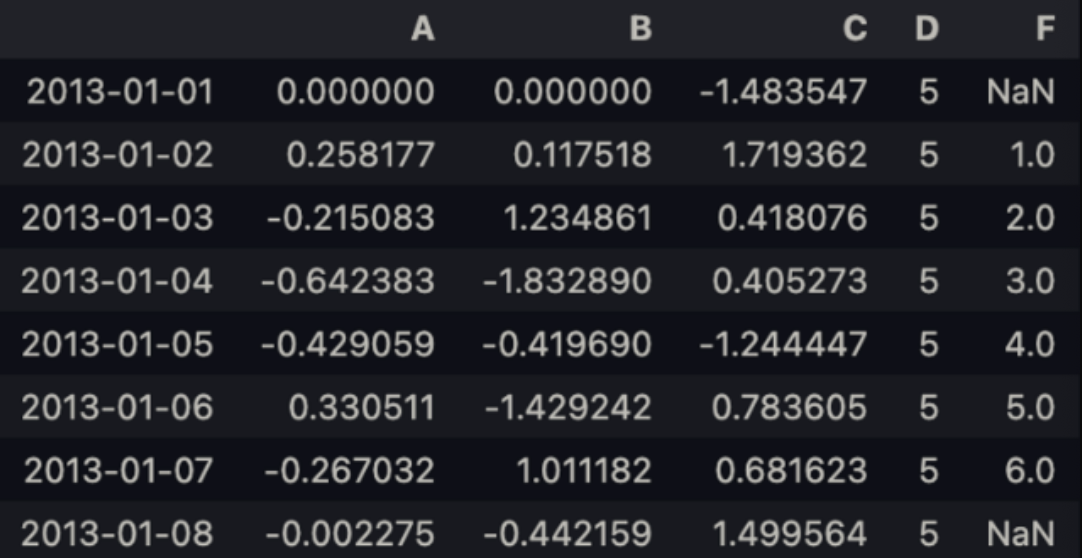
df.loc[dates[0],'A'] = 0위치에 의해 값을 설정.
df.iloc[0,1] = 0→ Numpy 배열을 사용한 할당에 의해 값을 설정.
df.loc[:,'D'] = np.array([5] * len(df))위 설정대로 작동한 결과.
→ where 연산을 설정.
df2 = df.copy()
df2[df2 > 0] = -df2
df2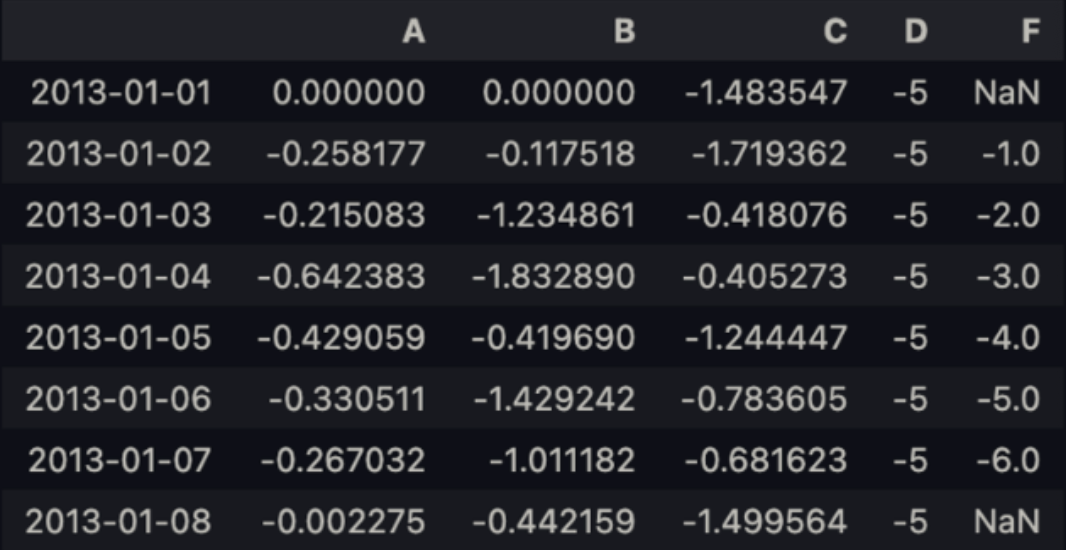
Missing Data.
→ Pandas는 결측치를 표현하기 위해 주로 np.nan 값을 사용. Reindexing으로 지정된 축 상의 인덱스를 변경 / 추가 / 삭제.
df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E'])df1.loc[dates[0]:dates[3],'E'] = 1df1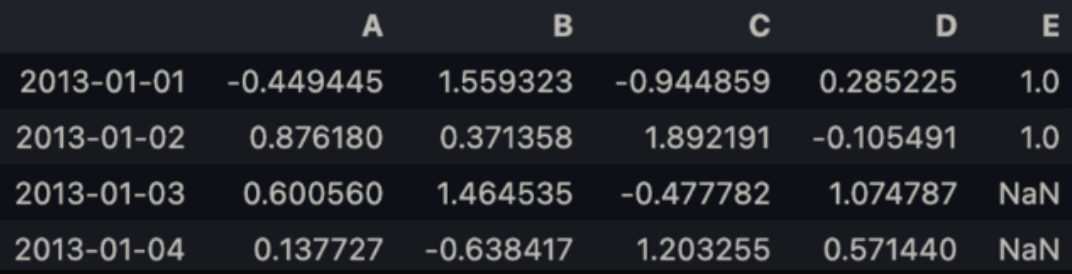
→ 결측치를 채워 넣음.
df1.dropna(how = 'any')
→ 결측치를 채워 넣음.
df1.fillna(value=5)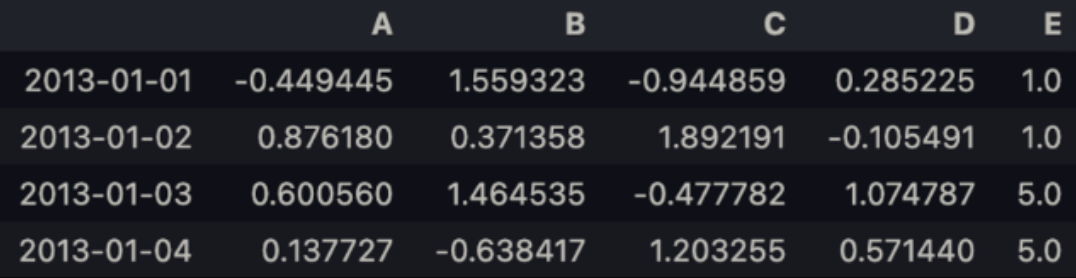
pd.isna(df1)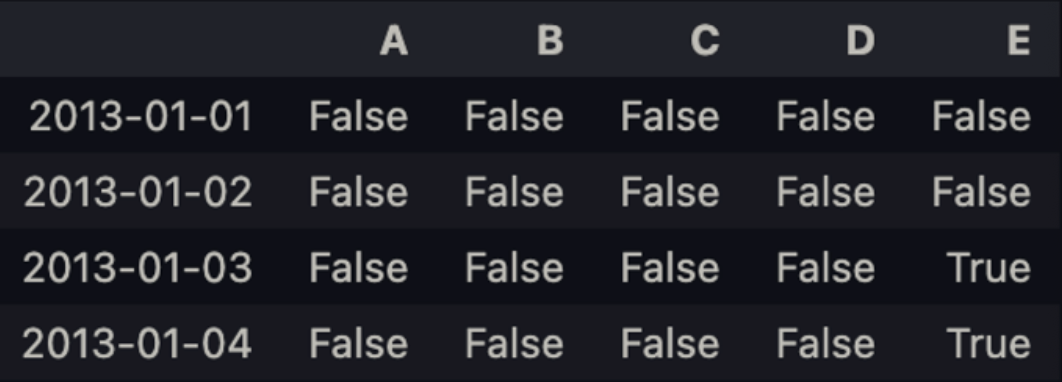
Operation (연산).
df.mean()
df.mean(1)
s = pd.Series([1,3,5,np.nan,6,8,9,10], index=dates).shift(2)
s
df.sub(s, axis='index')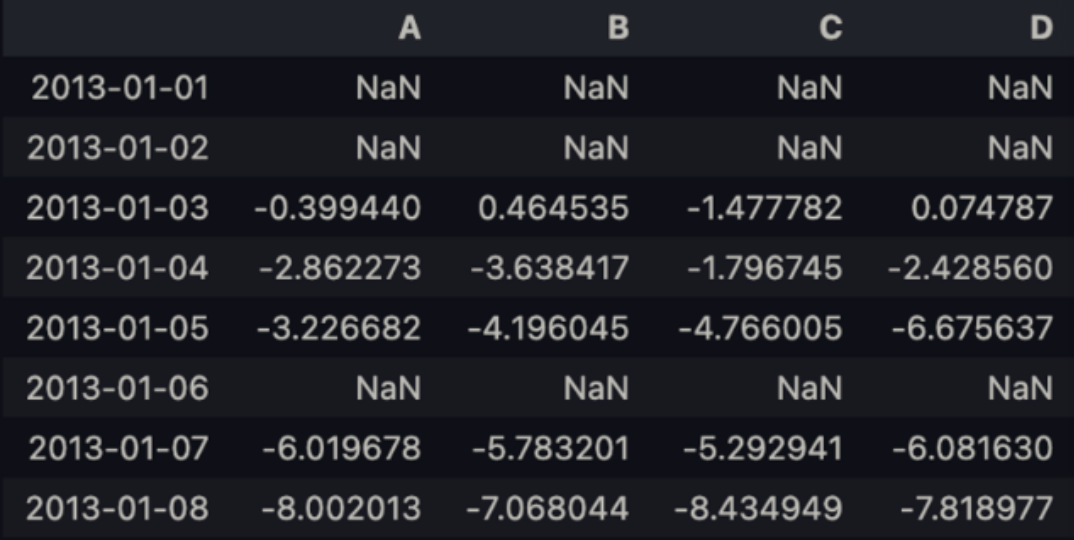
→ 인덱스 기준, 각 데이터가 계산되어 짐.
Apply (적용.)
df.apply(np.cumsum) # 누적합 구하기.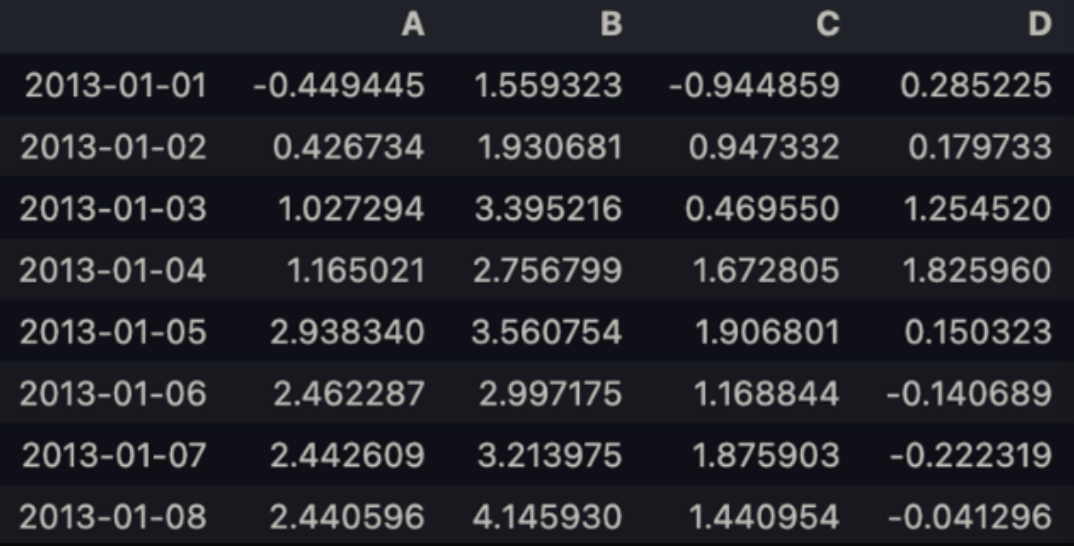
df.apply(lambda x: x.max() - x.min())
람다 함수.
파이썬에서는 람다함수를 통해 이름이 없는 함수를 만들 수 있음.
람다함수의 장점은 코드의 간결함 메모리의 절약이라고 생각할 수 있음.
def 키워드.
def my_func():
람다함수는 lambda라는 키워드로 생성할 수 있음.
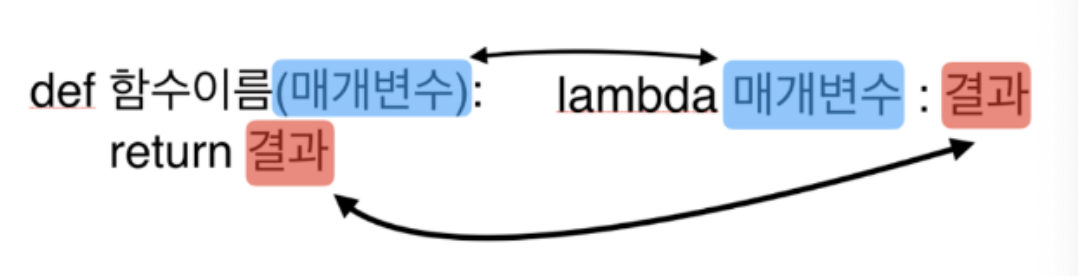
- 람다함수는 결과부분된 부분을 return 키워드 없이 자동으로 return 해줌.
lambda x : x + 1(lambda x : x+1)(3)def hap(x, y):
return x + yhap(10, 20)(lambda x,y: x + y)(10, 20)Map() 함수.
map(함수, 리스트).
이 함수는 함수와 리스트를 인자로 받음. 리스트로부터 원소를 하나씩 꺼내서 함수를 적용시킨 다음, 그 결과를 새로운 리스트에 담아줌.
list(map(lambda x: x ** 2, range(5)))reduce() 함수.
reduce(함수, 시퀀스)from functools import reduce
reduce(lambda x, y: x + y, [0,1,2,3,4])→ 예제는 먼저 0, 1을 더하고, 그 결과에 2를 더하고, 거기다가 3을 더하고, 또 4를 더한 값을 출력
filter() 함수.
filter(함수, 리스트)list(filter(lambda x: x < 5, range(10)))
list(filter(lambda x: x % 2 == 0, range(10)))
list(filter(lambda x: x % 2 == 1, range(10)))
Histogramming(히스토그래밍).
s = pd.Series(np.random.randint(0, 7, size=10))
s
s.value_counts()
string Methods(문자열 메소드)
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])s.str.lower() # 소문자로 변경.s.str.upper() # 대문자로 변경.
Merge(병합).
Concat (연결).
``결합 (join) / 병합 (merge) 형태의 연산에 대한 인덱스, 관계 대수 기능을 위한 다양한 형태의 논리를 포함한 Series, 데이터프레임, Panel 객체를 손쉽게 결합할 수 있도록 하는 다양한 기능을 pandas 에서 제공.
df = pd.DataFrame(np.random.randn(10, 4))
df
pieces = [df[:3], df[3:7], df[7:]]
pieces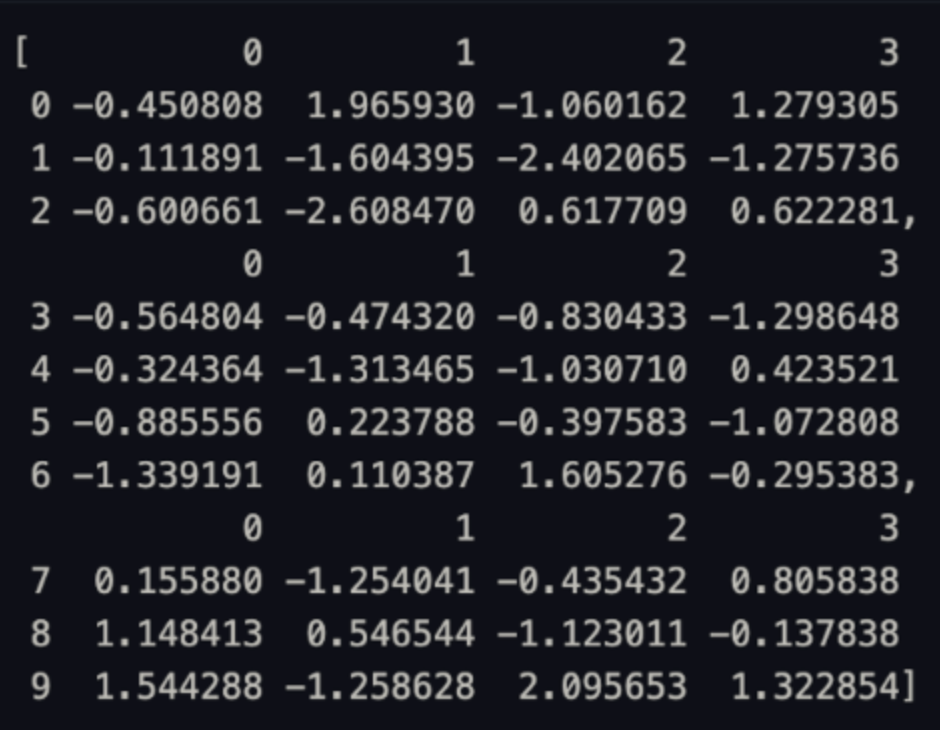
pd.concat(pieces)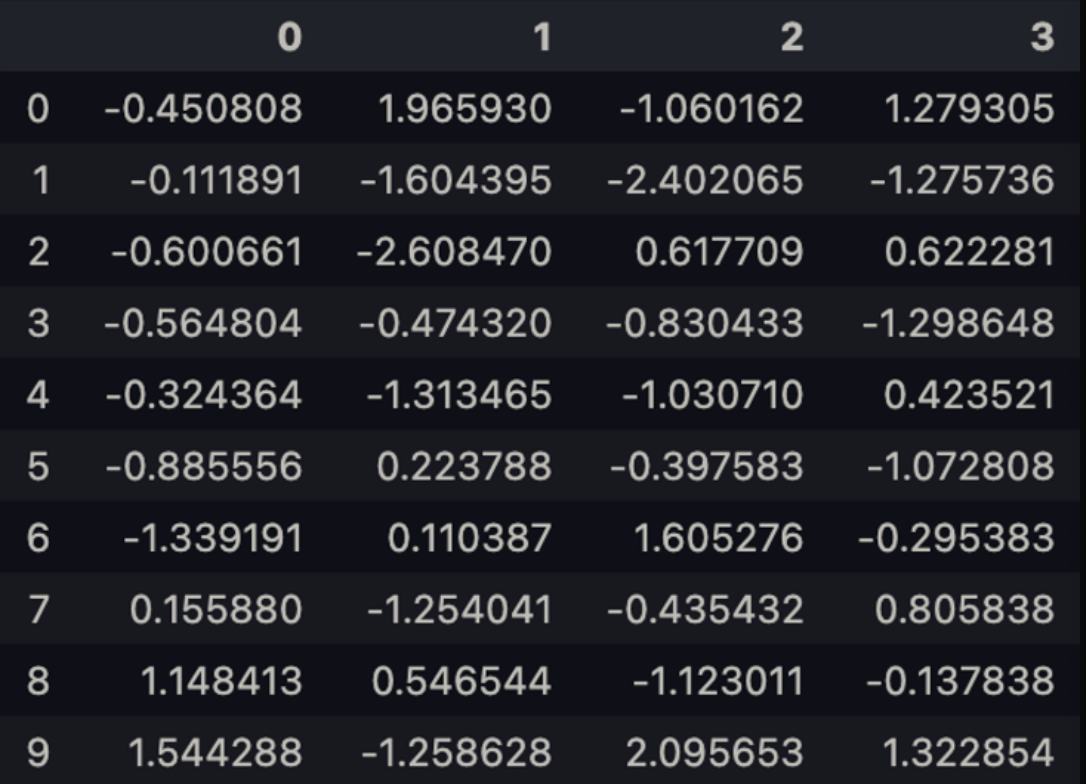
Join(결합).
left = pd.DataFrame({'key': ['foo', 'foo'], 'lval': [1, 2]})
right = pd.DataFrame({'key': ['foo', 'foo'], 'rval': [4, 5]})
left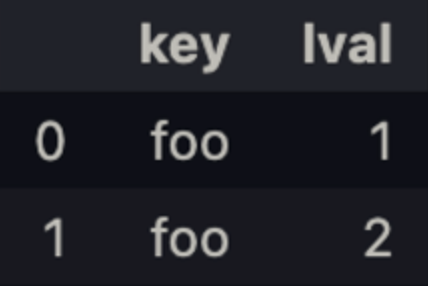
right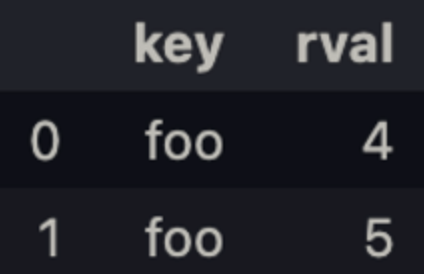
pd.merge(left, right, on= 'key')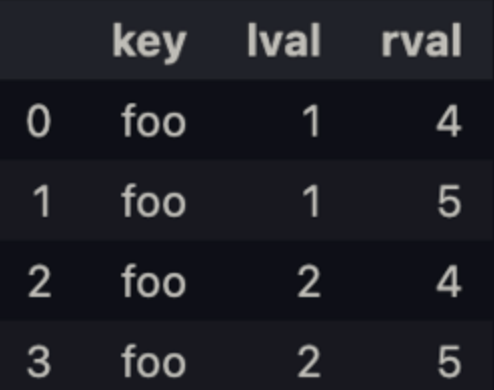
Append(추가).
df = pd.DataFrame(np.random.randn(8, 4), columns = list('ABCD'))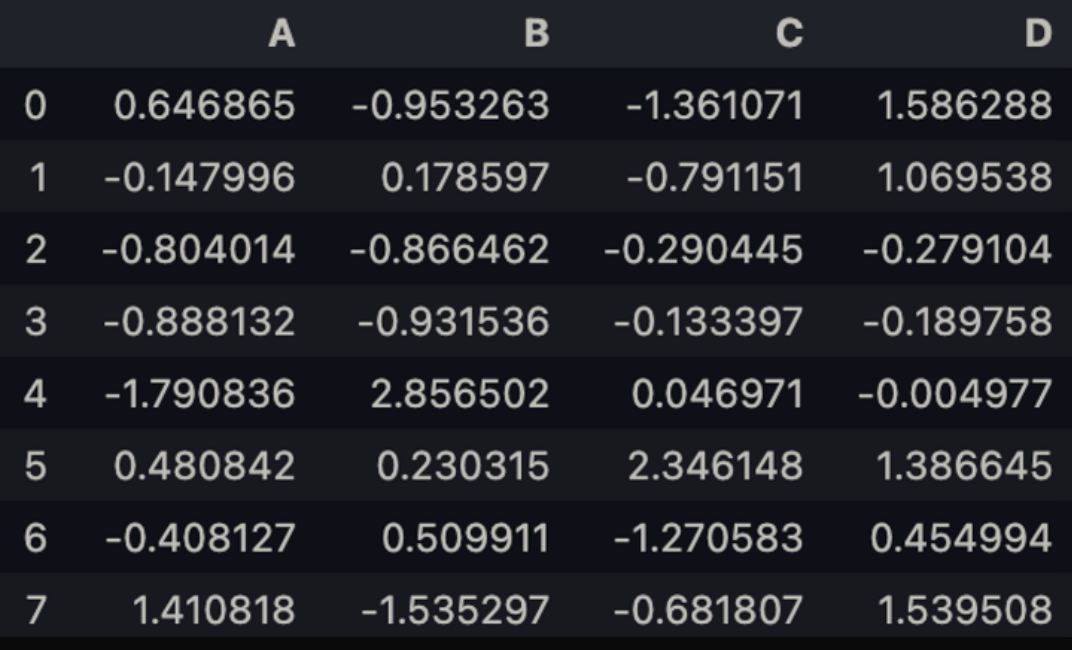
s = df.iloc[3]df.append(s, ignore_index=True)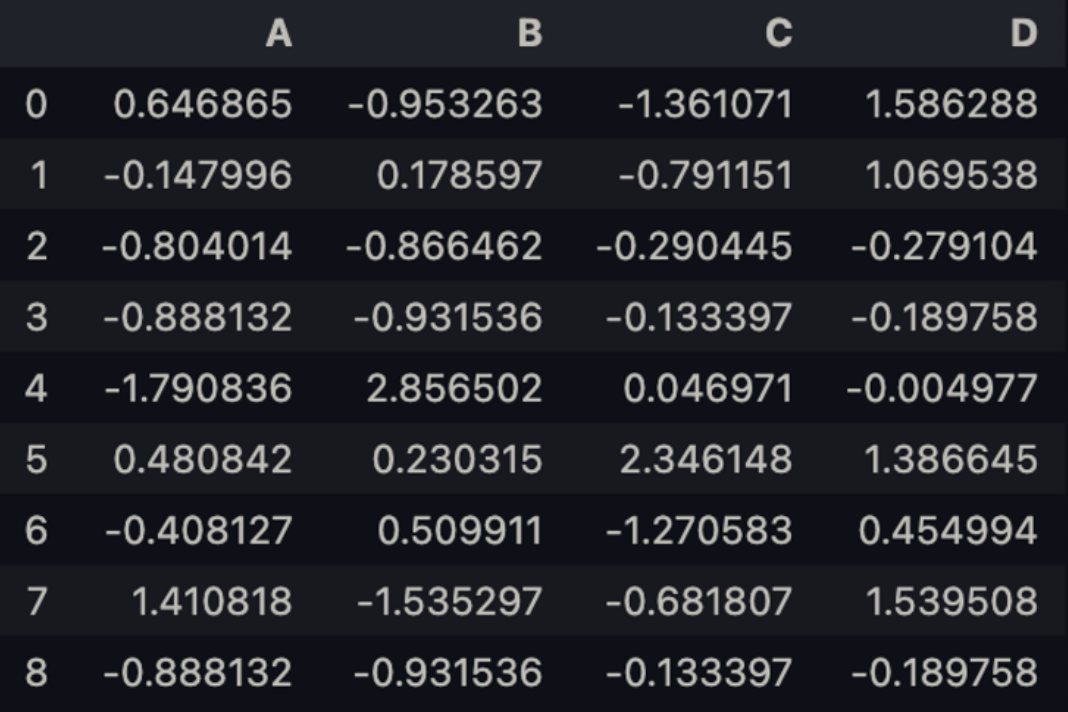
Grouping (그룹화).
df = pd.DataFrame(
{
'A' : ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],
'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C' : np.random.randn(8),
'D' : np.random.randn(8)
})df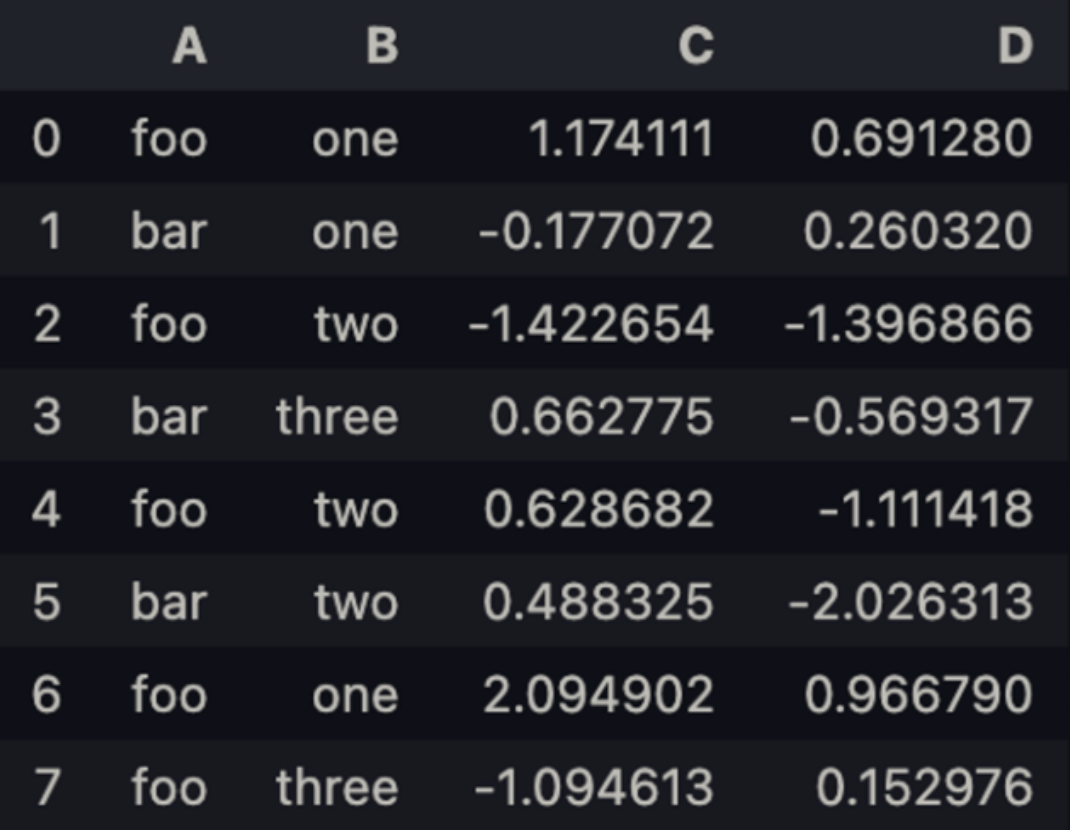
생성된 데이터프레임을 그룹화한 후 각 그룹에 sum() 함수를 적용.
df.groupby('A').sum()여러 열을 기준으로 그룹화하면 계층적 인덱스가 형성.
df.groupby(['A','B']).sum()