import pandas as pd
df1 = pd.DataFrame({'A' : ['A0', 'A1', 'A2', 'A3'],
'B' : ['B0', 'B1', 'B2', 'B3'],
'C' : ['C0', 'C1', 'C2', 'C3'],
'D' : ['D0', 'D1', 'D2', 'D3']},
index = [0,1,2,3])
df2 = pd.DataFrame({'A' : ['A4', 'A5', 'A6', 'A7'],
'B' : ['B4', 'B5', 'B6', 'B7'],
'C' : ['C4', 'C5', 'C6', 'C7'],
'D' : ['D4', 'D5', 'D6', 'D7']},
index = [4,5,6,7])
df3 = pd.DataFrame({'A' : ['A8', 'A9', 'A10', 'A11'],
'B' : ['B8', 'B9', 'B10', 'B11'],
'C' : ['C8', 'C9', 'C10', 'C11'],
'D' : ['D8', 'D9', 'D10', 'D11']},
index = [8,9,10,11])df1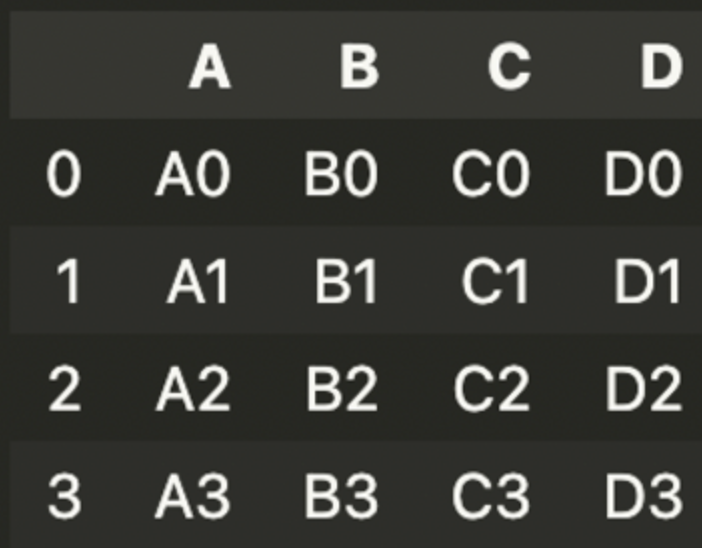
df2
df3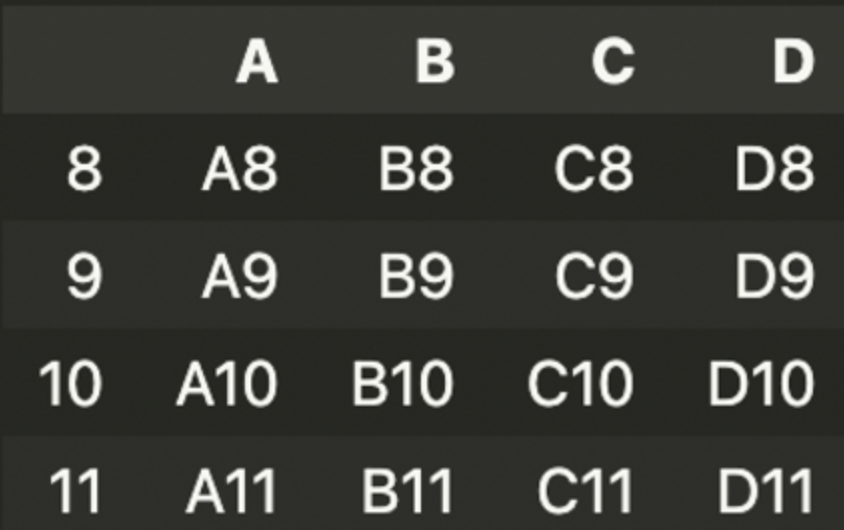
result = pd.concat([df1, df2, df3])
print(result)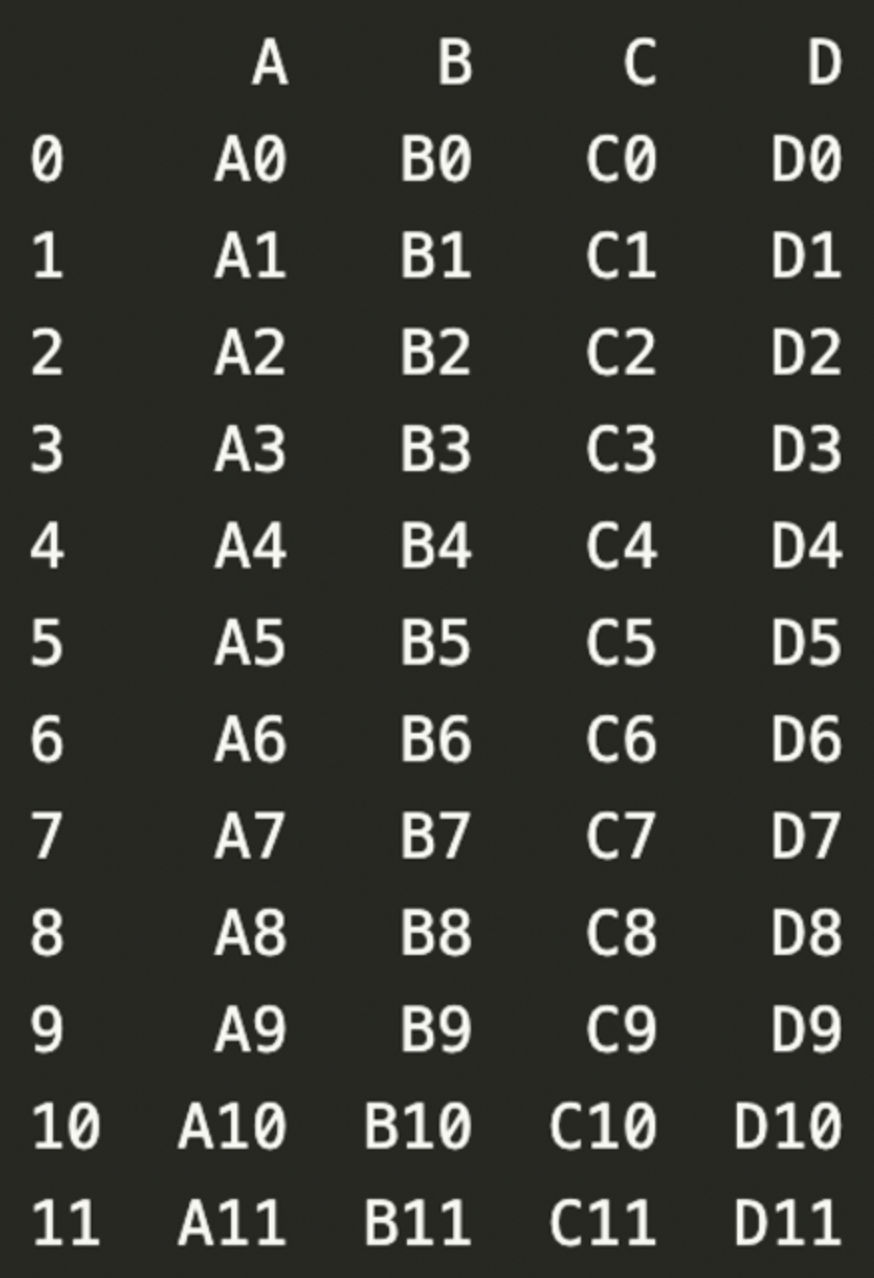
concat 함수 : 데이터를 열 방향으로 단순히 합치는 것
result = pd.concat([df1, df2, df3], keys = ['x', 'y', 'z'])
print(result)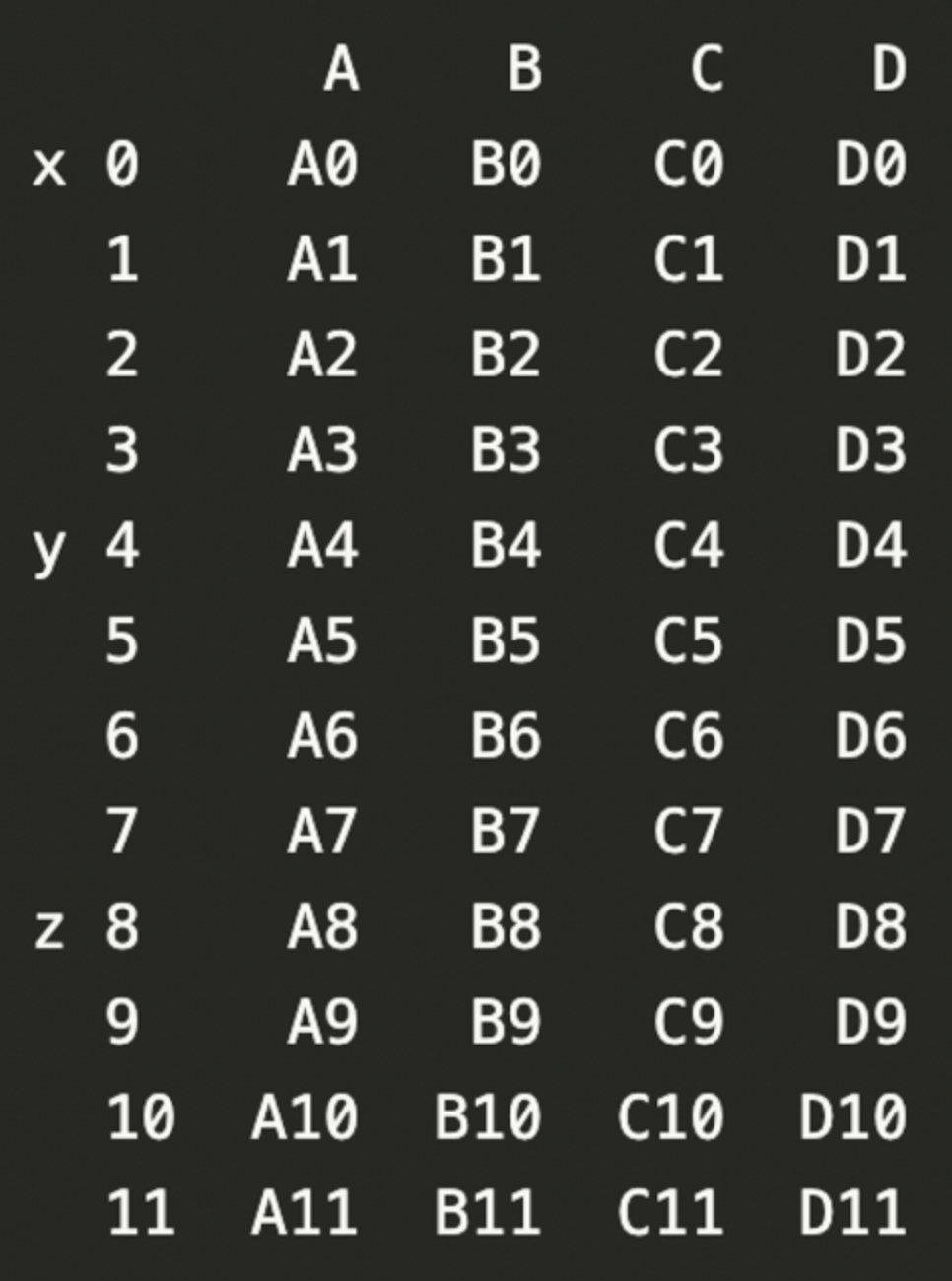
concat 함수에 keys 옵션으로 구분할 수 있음. 이렇게 key 지정된 구분은 다중 index가 되어 level을 형성.
result.index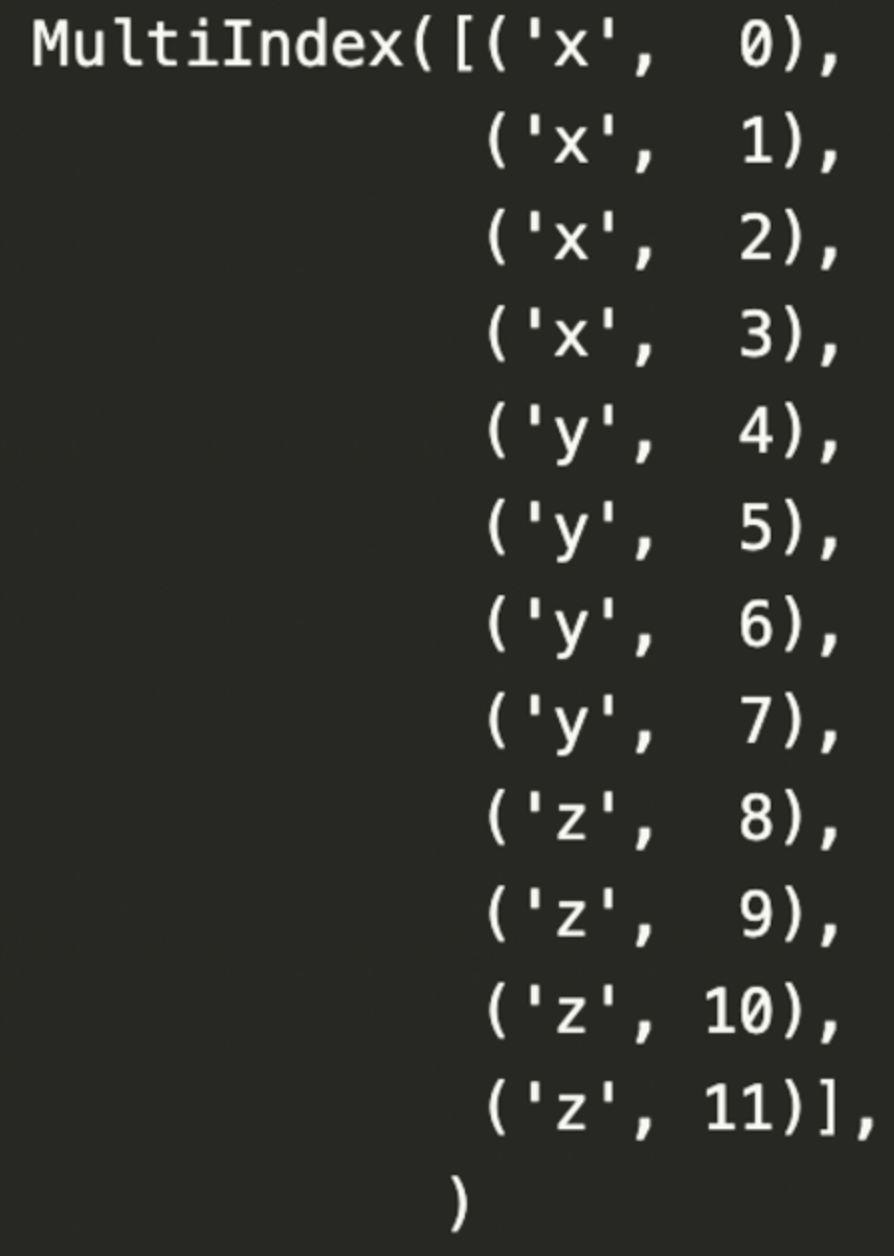
result.index.get_level_values(0)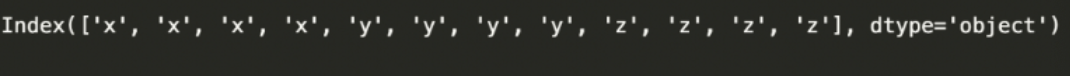
result.index.get_level_values(1)
df4 = pd.DataFrame({'B' : ['B2', 'B3', 'B6', 'B7'],
'D' : ['D2', 'D3', 'D6', 'D7'],
'F' : ['F2', 'F3', 'F6', 'F7']},
index = [2, 3, 6, 7])
result = pd.concat([df1, df4], axis = 1)df1
df4
result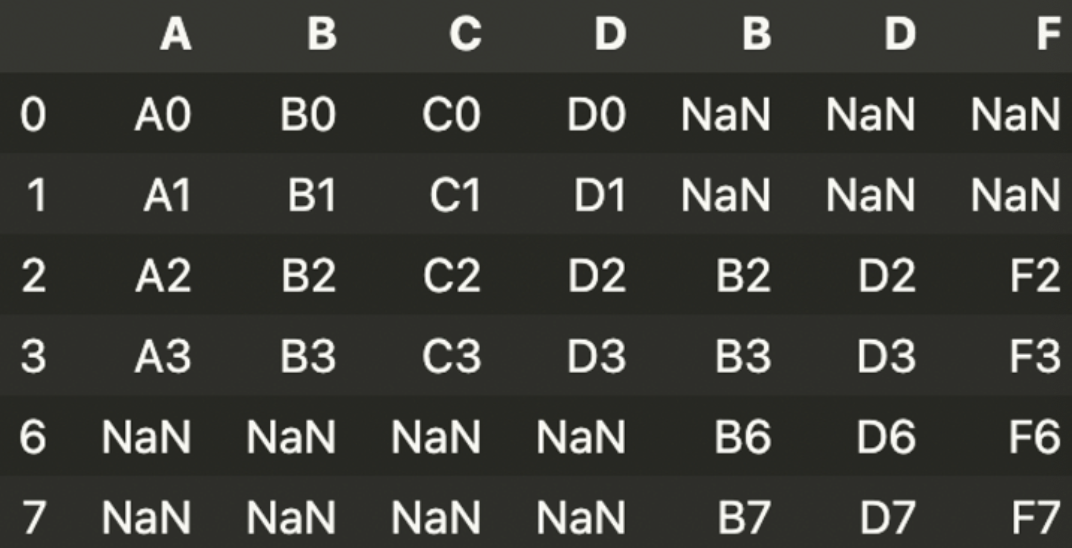
df1의 index가 0, 1, 2, 3이고, df4의 index가 2, 3, 6, 7인데 concat 명령은 index를 기준으로 데이터를 합치기 때문.
공통된 index로 합치고 공통되지 않은 index의 데이터는 버리도록 하는 옵션 >>> join = 'inner'
result = pd.concat([df1, df4],axis = 1, join = 'inner')
result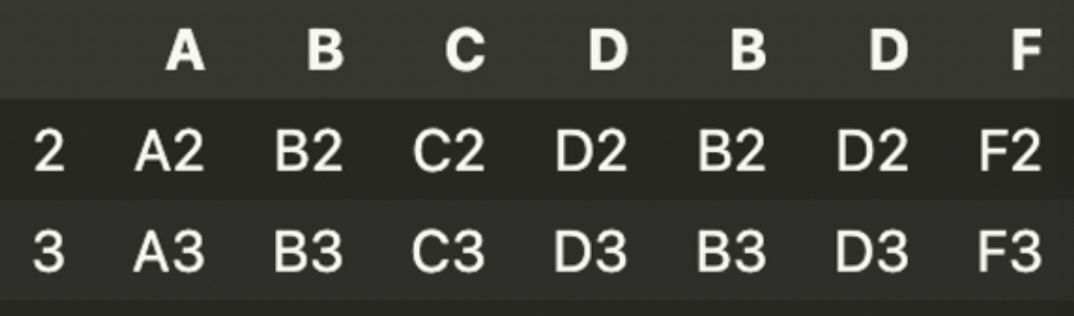
result = pd.concat([df1, df4], ignore_index=True)
result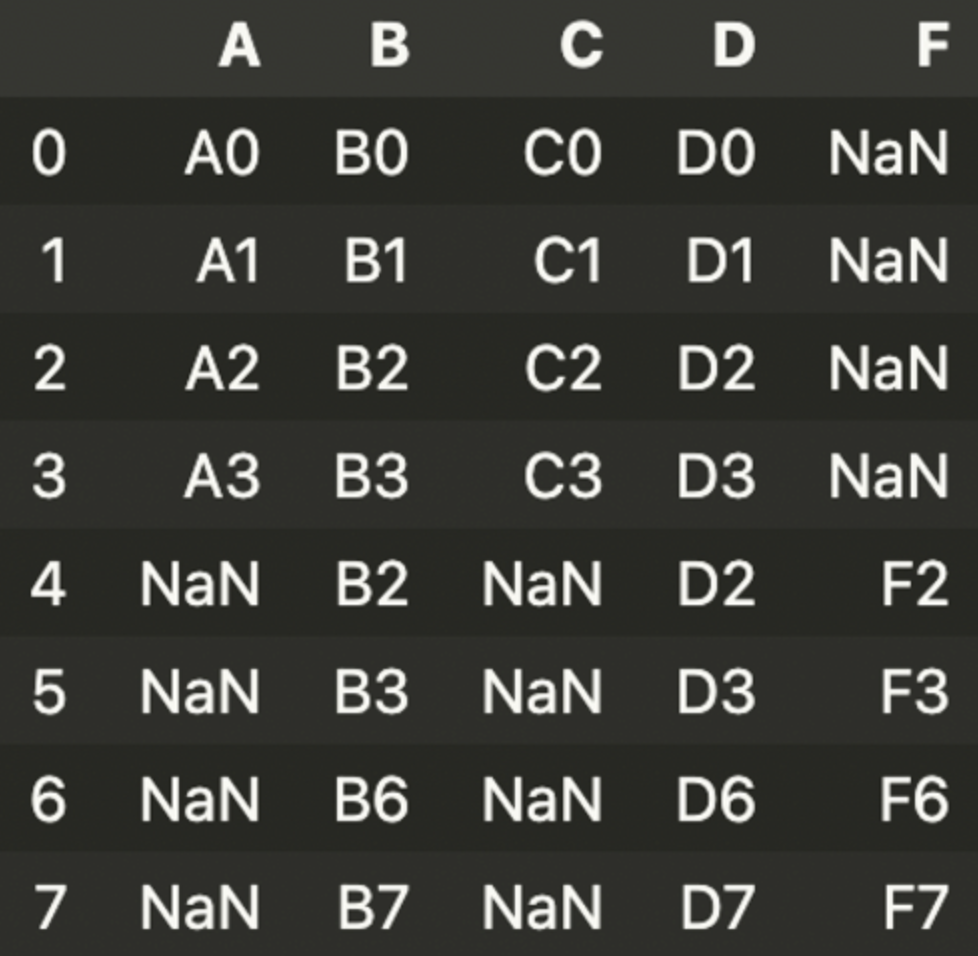
left = pd.DataFrame({'Key' : ['K0', 'K4', 'K2', 'K3'],
'A' : ['A0', 'A1', 'A2', 'A3'],
'B' : ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'Key' : ['K0', 'K1', 'K2', 'K3'],
'C' : ['C0', 'C1', 'C2', 'C3'],
'D' : ['D0', 'D1', 'D2', 'D3']})
print(left)
print(right)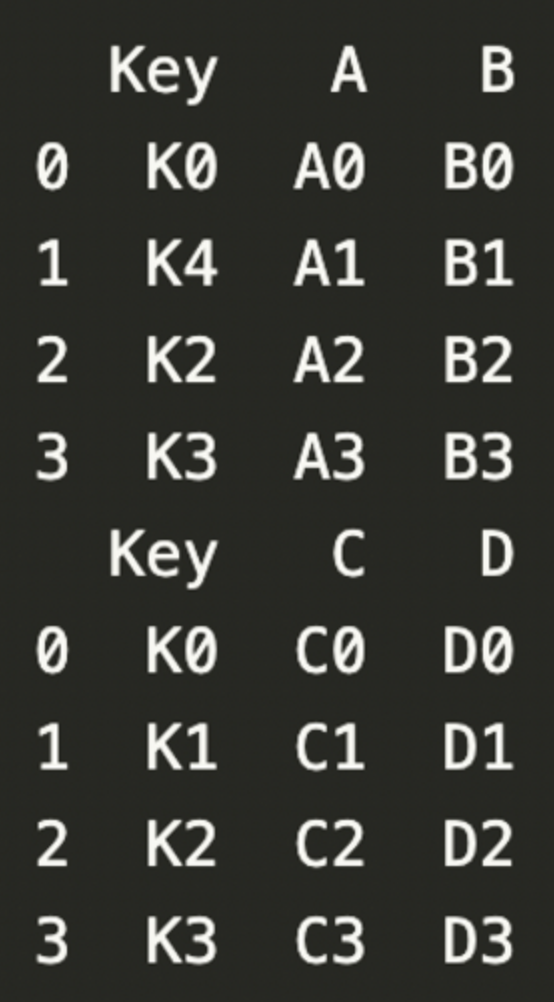
merge 명령에서 merge기준을 설정(공통된 key에 대해서만 합침)
pd.merge(left, right, on = 'Key')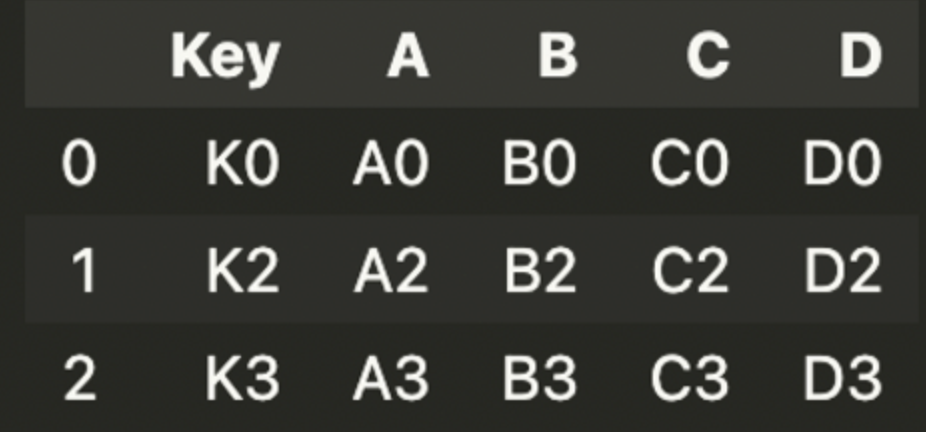
pd.merge(left, right, how = 'left', on = 'Key')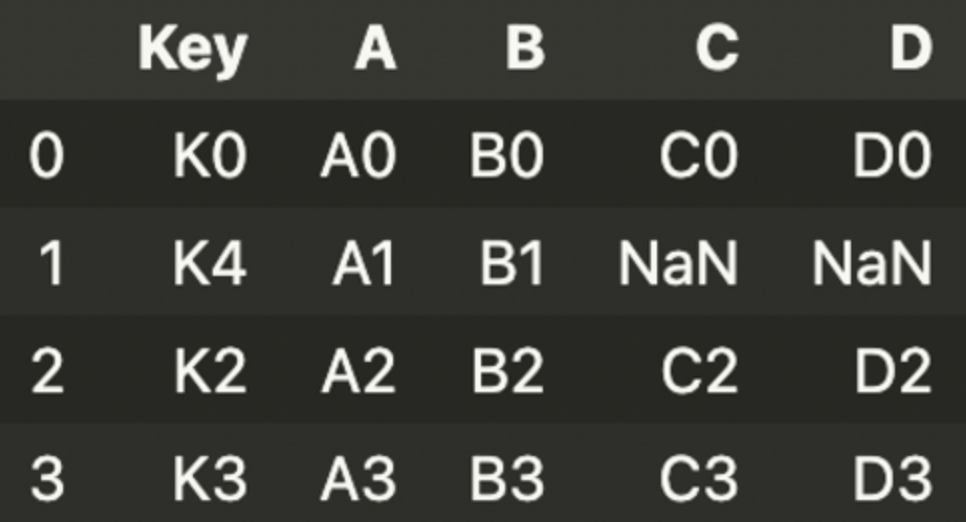
pd.merge(left, right, how = 'right', on = 'Key')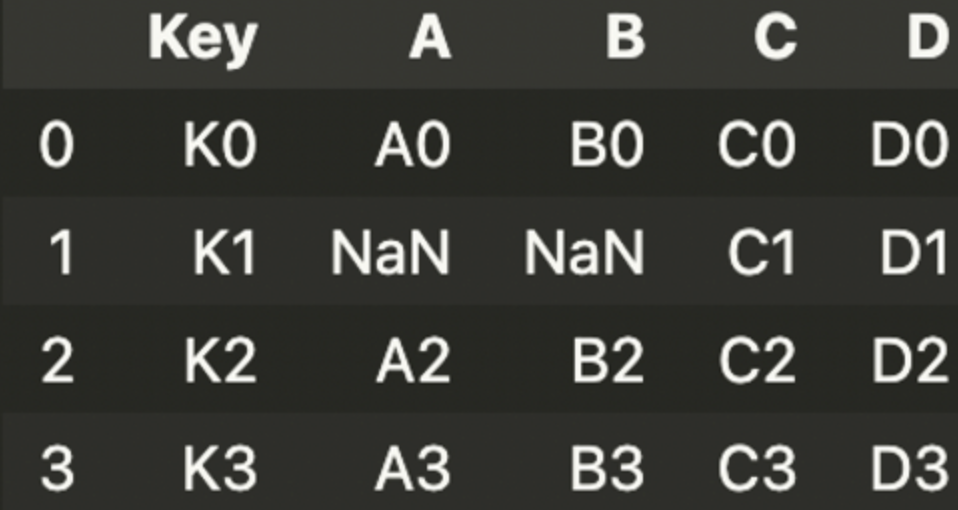
pd.merge(left, right, how='outer', on='Key')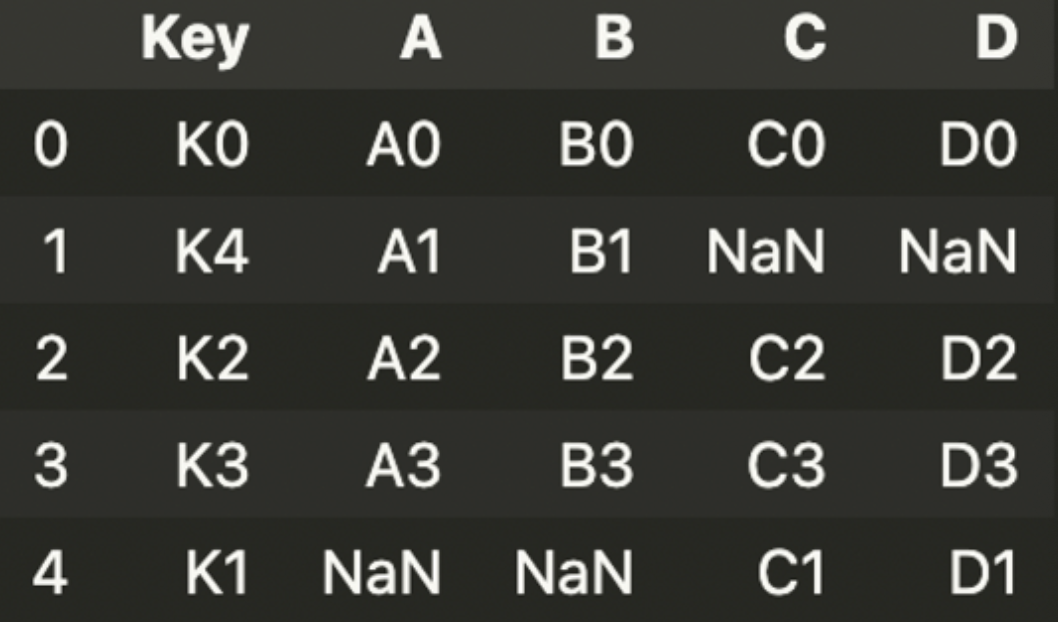
outer는 공통된 것이 아니면 NaN으로 처리.
pd.merge(left, right, how = 'inner', on = 'key')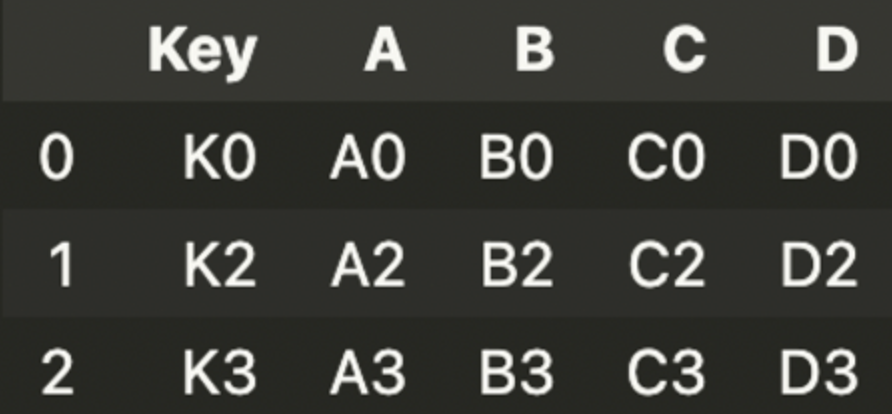
inner는 교집합처럼 공통된 요소만 가짐.

Data Science. DevOps.