
Abstract
- CNN depth is very importatnt for image super-resolution
- Howevere, deeper networks for image SR are more difficult.(Gradient Vanishing 때문)
- residual을 활용한 deep learning인 RCAN(Residual Channel Attention Network)를 제안
Architecture
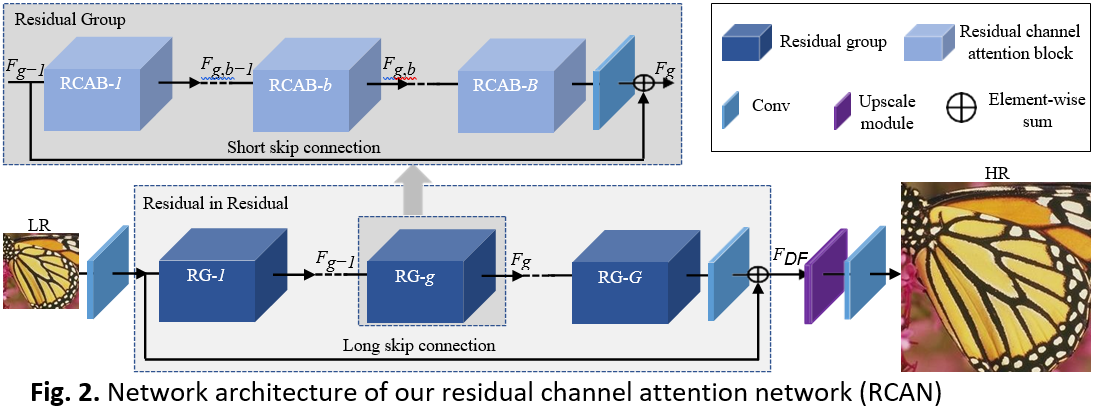
- Shallow feature extraction
- 하나의 convolutional layer이 shallow feature인 f0를 LR input으로부터 extract
- Residual-In-Residual deep feature extraction
- shallow feature extraction에서의 f0를 deep feature extraction에 이용
- 각 Residual 구조들은 image SR의 높은 성능을 위해 굉장히 깊은 CNN을 train해야하는데 이 때 deep network train이 어려워서 성능 향상을 기대하기 어렵다. 따라서 Residual group(RG)를 basic model로 제시한다.
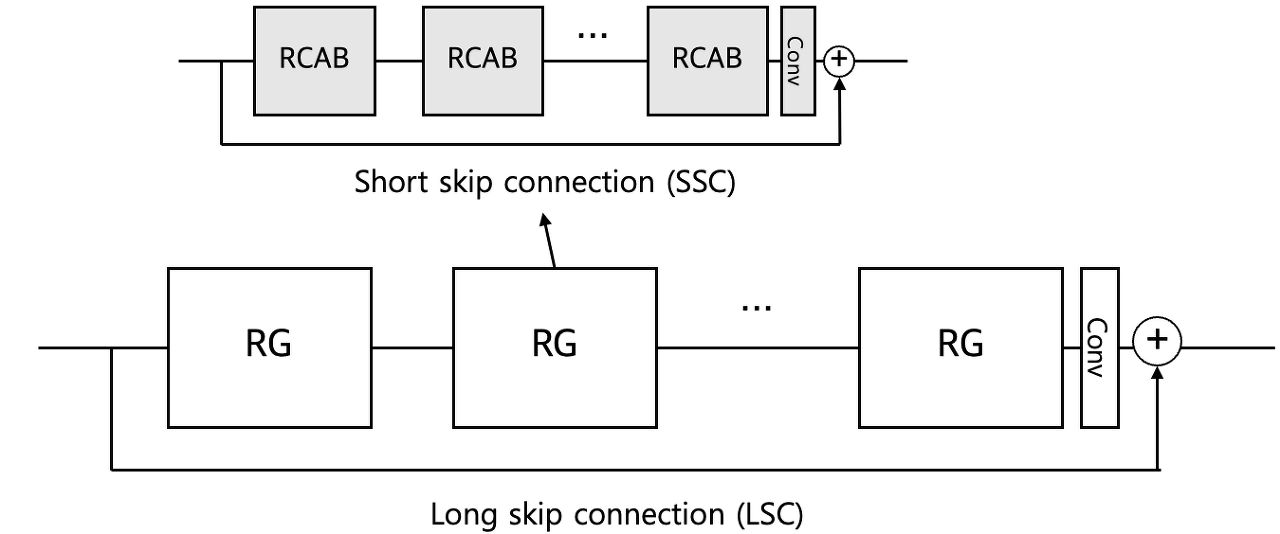
- Residual-In-Residual(RIR)은 shor skip connection(SSC)와 residual channel attention block(RCAB)여러 개로 이루어진 residual group(RG) 여러 개로 이루어져 있다.
- SSC와 LSC의 단순합이 아닌, residual block을 통과한 feature에 convolutional layer 1개를 통과시킨 후에 통과하지 않았던 feature를 더한다. (Long skip connenction을 이용)
- RIR은 residual block의 단순한 stack보다 학습 안정성이 높고, LR 이미지에서 추출한 low-frequency 정보를 쉽게 전달할 수 있다.
- RIR structure 에서 RG nuber is set as G = 10
- In each RG, RCAB number is set as 20
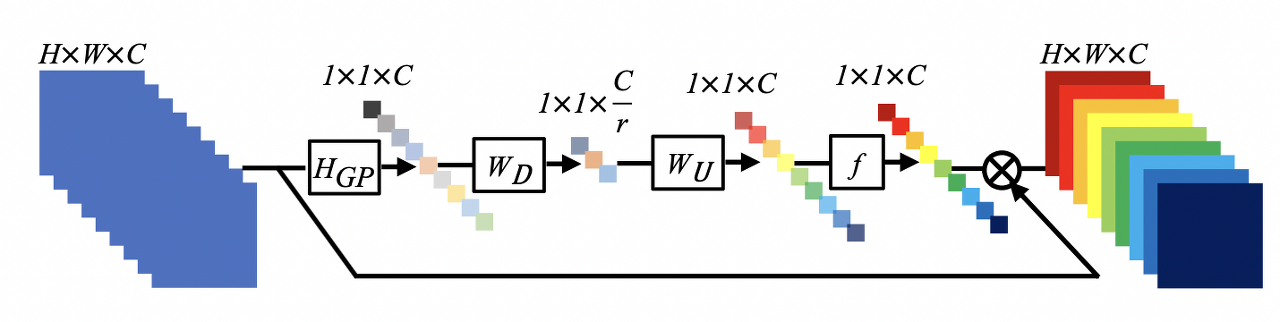
- 이 때 RCAB의 구조에서 channel attention이 핵심이다.
- 기존의 SR에서는 저해상도 채널별 feature를 동등하게 다루었는데, 실제 케이스에서는 유연하게 작용하지 않으므로, feature channel 간의 상호 의존성을 이용하는데 이 mechanism을 channel attention이라고 한다.
- global average pooling을 통해서 고주파 성분의 정보를 이용, 채널별 global spatial information을 취한다.
- channel attention의 역할은 residual의 크기를 재조정한다. (= gap, convolutional layer, ReLU, sigmoid를 통해 각 채널의 가중치를 정하고, channel descriptor를 각 채널에 곱해서 residual을 daptively rescale.
- As shown above, the interdependencies among feature channels are exploited, resulting in a channel attention mechanism.
- This is originated in SENet
- channel attention을 통해 RCAM의 residual componet들이 adaptively하게 rescale된다.
- Upscale Module :ESPCN(pixel shuffle)
- Scale에 맞게 이미지 크기를 키움(RIR로부터의 결과 feature를)
- Reconstruction part
- Upscale 과정에서 손실되는 High-frequency 정보를 복원
- loss function으로 optimize하는데 l1 loss를 사용한다
- LR image를 convolutional layer에 통과시켜 feature(shallow feature extraction)추출
- shallow feature extraction과 residual block이 stack된 구조인 RIR을 통과한 feature은 가중함
- upsampling과 reconstruction module을 거쳐 hr image가 된다.
- 모든 Conv layer는 3x3의 kernel size를 가지는데 downscaling, upsacling은 1x1의 kernel size를 가지게 된다. 그리고 3x3의 conv layer에는 zero padding을 사용하여 크기를 고정시킨다.

Department of Artificial Intelligence, EWHA