
오늘의 한줄 요약
- Jupyter/Pandas 를 익히려면 아직 한참 멀었구나... 나는 파일도 제대로 못 여는..바보니까...ㅎㅎ
Pandas_데이터 합치기
크게 3가지 있음
1. pd.concat()
2. pd.merge()
3. pd.join()
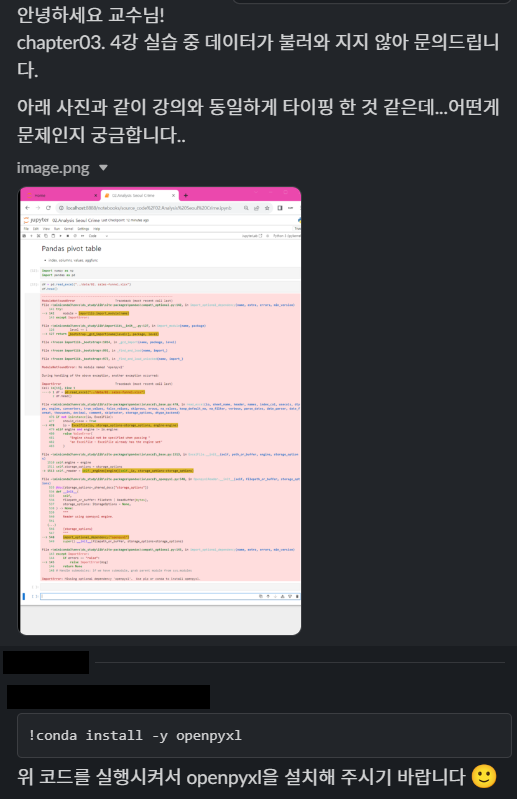
Pandas_pivot_table
(쓰임) 특정 군을 기준으로 데이터를 재정렬하고 싶을 때 사용
1. 이론
index=["00"]
- pd.pivot_table(df, index=["Name"]
- df에서 Name을 기준으로 재정렬(정리) 해라
values=["00"]
- pd.pivot_table(df, index=["Name"], values=["price"])
- df에서 Name을 기준으로 재정렬(정리)한 뒤 Price 값만 보여줘
aggfunc=np.sum
- 중복을 정리하는 '디폴트'는 '평균'이다
- '평균'이 아닌 '합계' 외 다른 것을 사용하고 싶다면
aggfunc=np.000을 사용한다. - pd.pivot_table(df, index=["Name"], values=["price"], aggfunc=np.sum)
aggfunc=[np.mean, len]
- 중복의 개수 파악
- pd.pivot_table(df, index=["Name"], values=["price"], aggfunc=[np.mean, len])
fill_value=
- 그래프 생성 시 없는 값은 'NaN'으로 표시됨
- 'NaN'을 다르게 표현하고 싶다면
fill_value=000을 사용하면 'NaN'값이 '000'으로 바뀜
2. 실습
Pandas_for() 반복문
Python의 반복문
- MATLAB은 반복, 조건, 함수 이든 END로 끝나게 해서 구분
- C/C++은 중괄호로 구문의 시작과 끝을 구분
- Python은 들여쓰기(intent)로 구분
원라인 코드
[1] python
for n in [1,2,3,4]
print("Number is", n)[2] python
for n in range(0,10):
print(n**2)▼
[Pandas]
[n**2 for n in range(0,10)]0부터 9까지의 숫자 하나씩을 가져와서, 각각의 제곱한 다음에 리스트에 저장해라
iterrows()
Pandas에서 잘 맞춰진 반복문용 명령 iterrows()
- Pandas 데이터 프레임은 대부분 2차원
- 이럴 때 for문을 사용하면 n번째 하는 지정을 반복해서 가독률이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들때 itterows() 옵션을 사용하면 편함
- 받을 때, 인덱스와 내용으로 나누어 받는 것만 주의

비전공자의 데이터 공부법