1. 강의 목표 및 주요 주제 소개
- 강의의 최종 목표: 수강생들이 컴퓨터 비전의 응용을 이해하고, 시각 데이터를 다루는 모델을 직접 개발 및 훈련하며, 해당 분야의 최신 동향과 미래를 파악하는 것을 목표로 합니다.
- 강의의 4가지 핵심 주제: 강의는 크게 딥러닝 기초, 시각 세계 인식 및 이해, 생성적 및 대화형 시각 지능, 그리고 인간 중심 응용 및 함의이라는 네 가지 주제로 구성됩니다.
2. 딥러닝 기초

- 컴퓨터 비전의 정의: 기계가 이미지를 보고 이해하도록 만드는 학문입니다.
- 이미지 분류: 가장 기본적인 컴퓨터 비전 과제로, 모델이 이미지를 보고 '고양이'와 같이 정해진 레이블로 출력하는 것을 의미합니다.
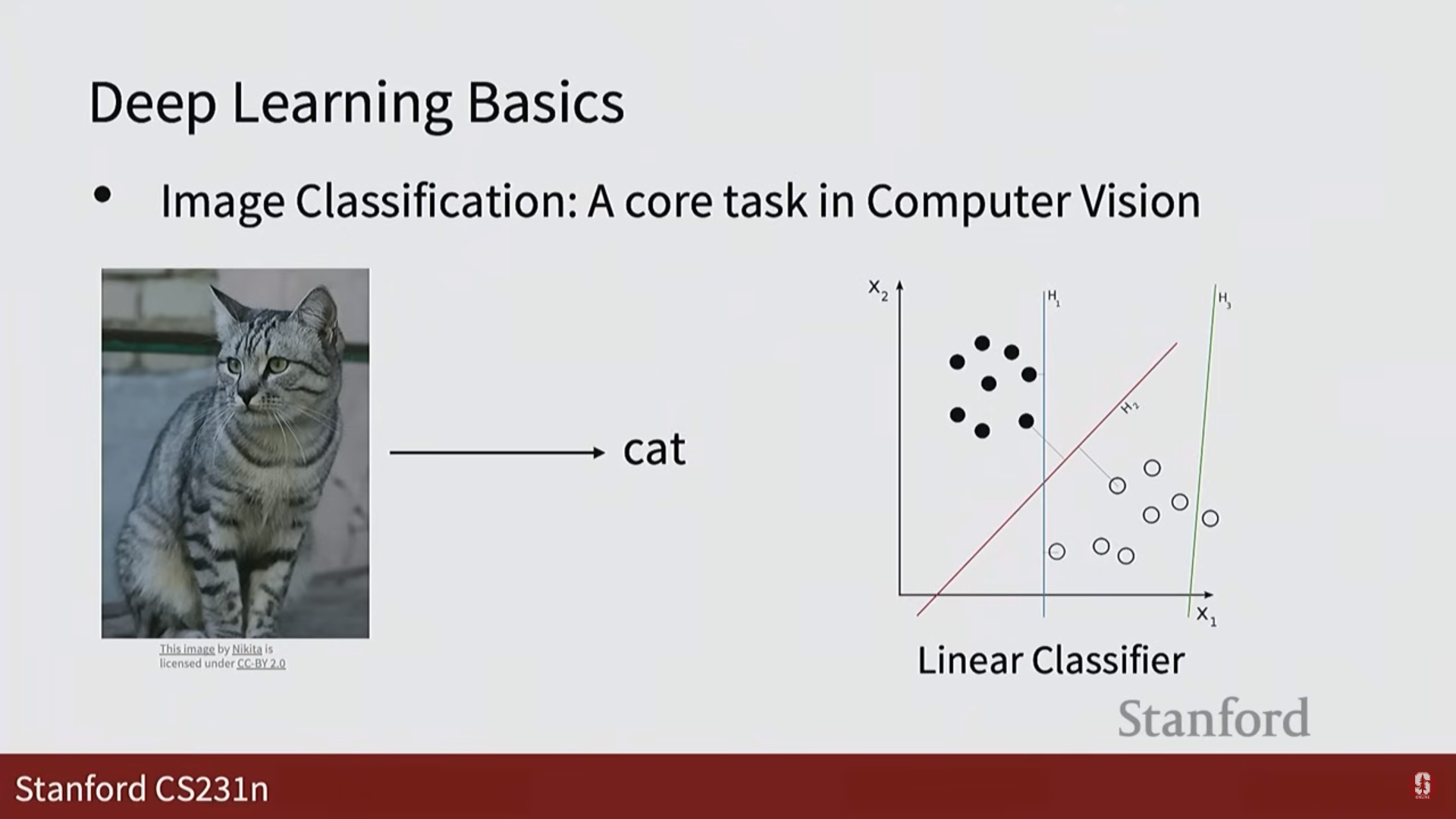
- 선형 분류기: 이미지를 특징 공간의 점으로 간주하고, 이 점들을 선형 함수(초평면)를 이용해 구분하는 모델입니다. 하지만 데이터가 직선으로 명확히 나뉘지 않을 경우 한계를 가집니다.
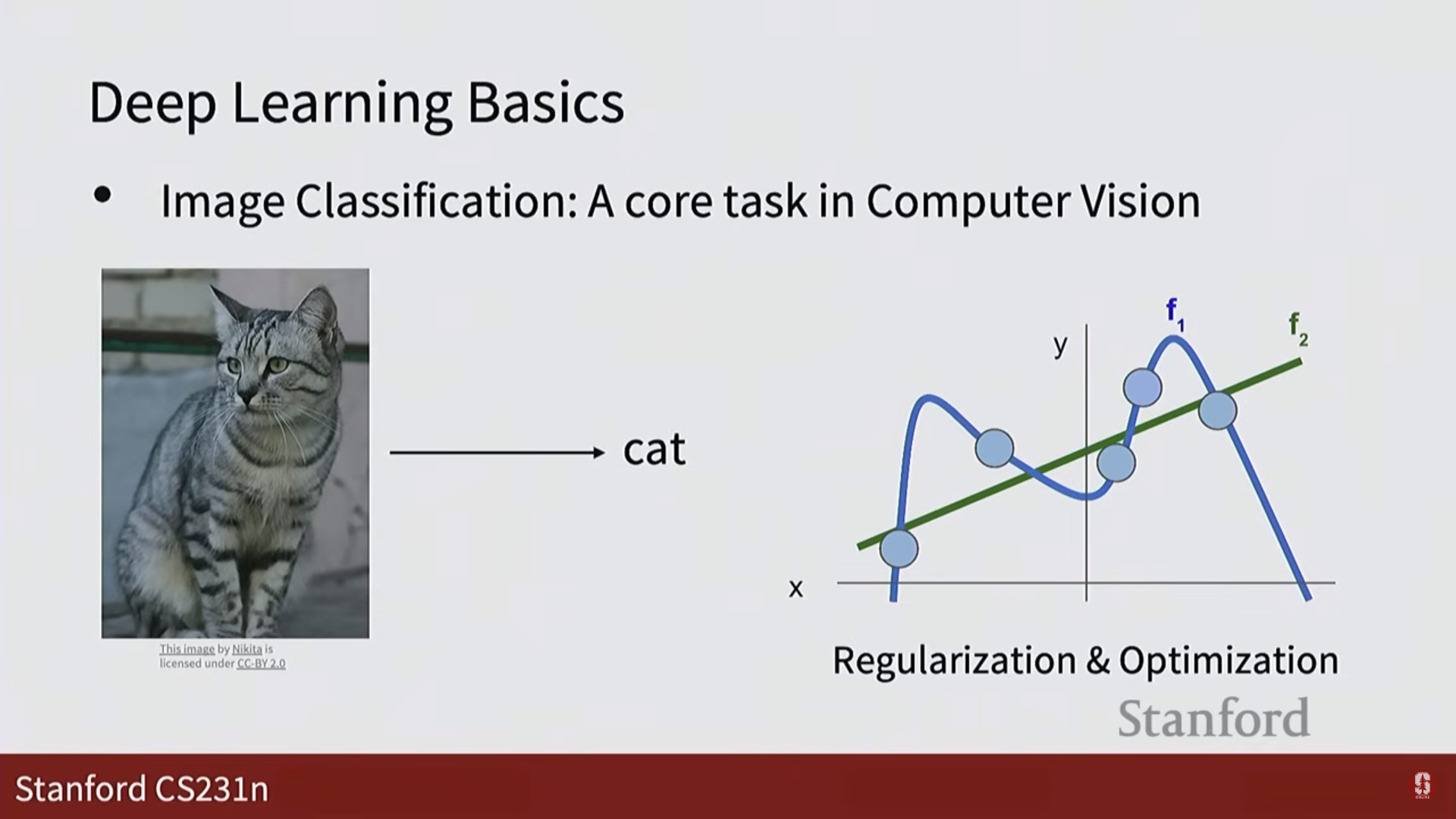
- 주요 개념: 복잡한 패턴을 모델링할 때 발생하는 과적합(Overfitting) 및 과소적합(Underfitting) 문제와, 이를 해결하기 위한 정규화(Regularization) 및 최적화(Optimization) 기법을 다룰 예정입니다.
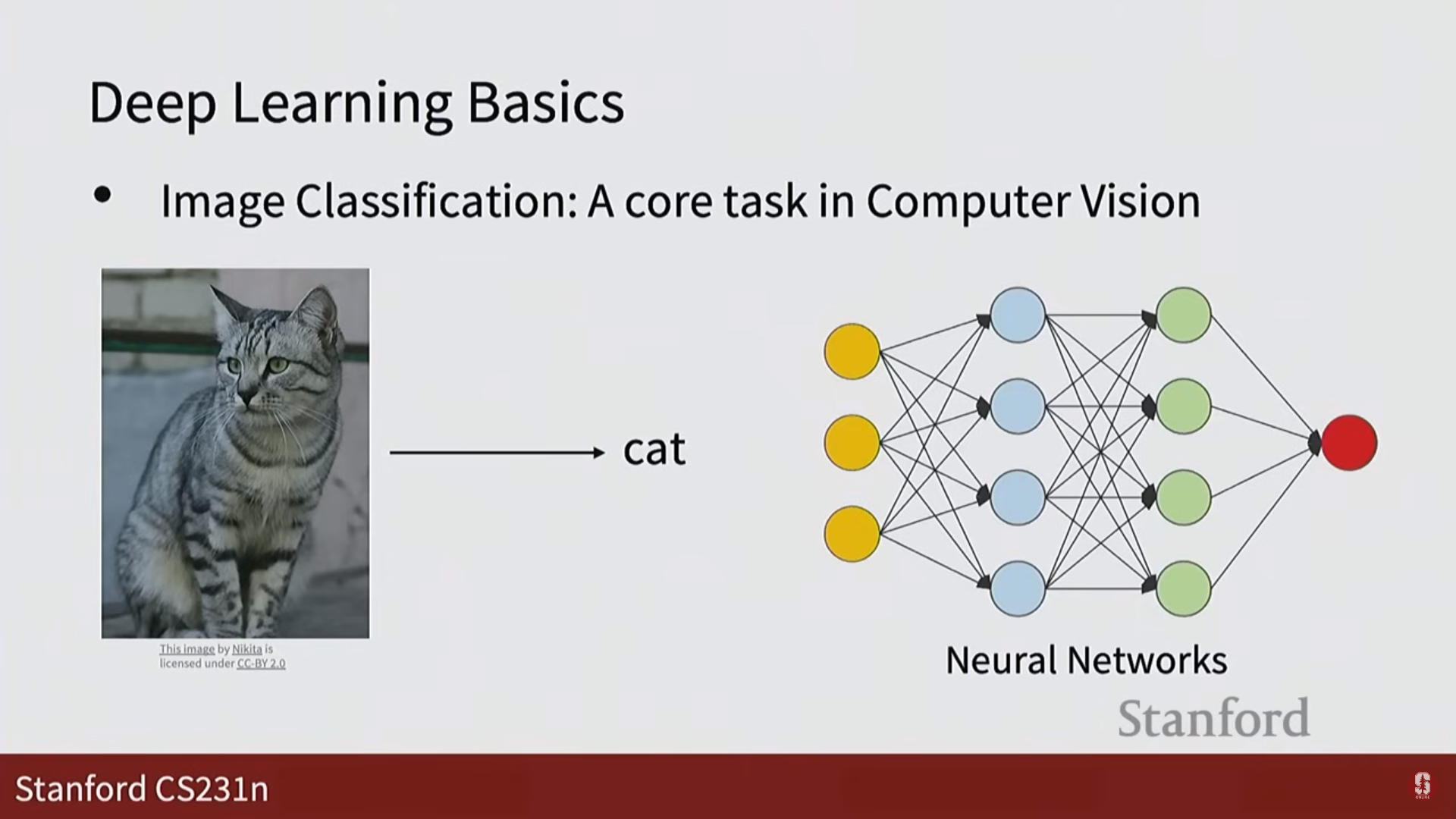
- 신경망 (Neural Networks): 여러 계층의 연산을 통해 비선형 함수를 모델링하는 강력한 모델입니다. 이는 선형 분류기의 한계를 극복하며, 오늘날 Google 포토부터 ChatGPT의 비전 모델까지 모든 것의 기반이 됩니다.
3. 시각 세계 인식 및 이해

- 컴퓨터 비전의 과제: 이미지 분류를 넘어 더 복잡하고 세분화된 작업을 다룹니다.
- 의미론적 분할 (Semantic Segmentation): 이미지의 모든 픽셀에 '풀', '나무', '하늘'과 같은 레이블을 할당합니다.
- 객체 탐지 (Object Detection): 이미지 속 객체의 종류와 함께 바운딩 박스로 위치까지 파악합니다.
- 인스턴스 분할 (Instance Segmentation): 각 객체 인스턴스를 고유한 마스크로 구분하는 가장 정교한 작업입니다.

- 시간적 차원의 이해: 정적인 이미지를 넘어 동적인 비디오를 이해하는 과제도 포함됩니다.
- 비디오 분류: 비디오에서 '달리기', '점프' 등 어떤 행동이 일어나는지 이해합니다.
- 멀티모달 비디오 이해: 시각 정보와 소리 같은 다른 양식의 정보를 결합하여 더 깊이 이해합니다.

- 모델 시각화: 모델이 올바른 판단을 위해 이미지의 어느 부분에 주목하는지 어텐션 맵(Attention Map) 등을 통해 해석하고 이해하는 방법을 다룹니다.
- 주요 모델 아키텍처:
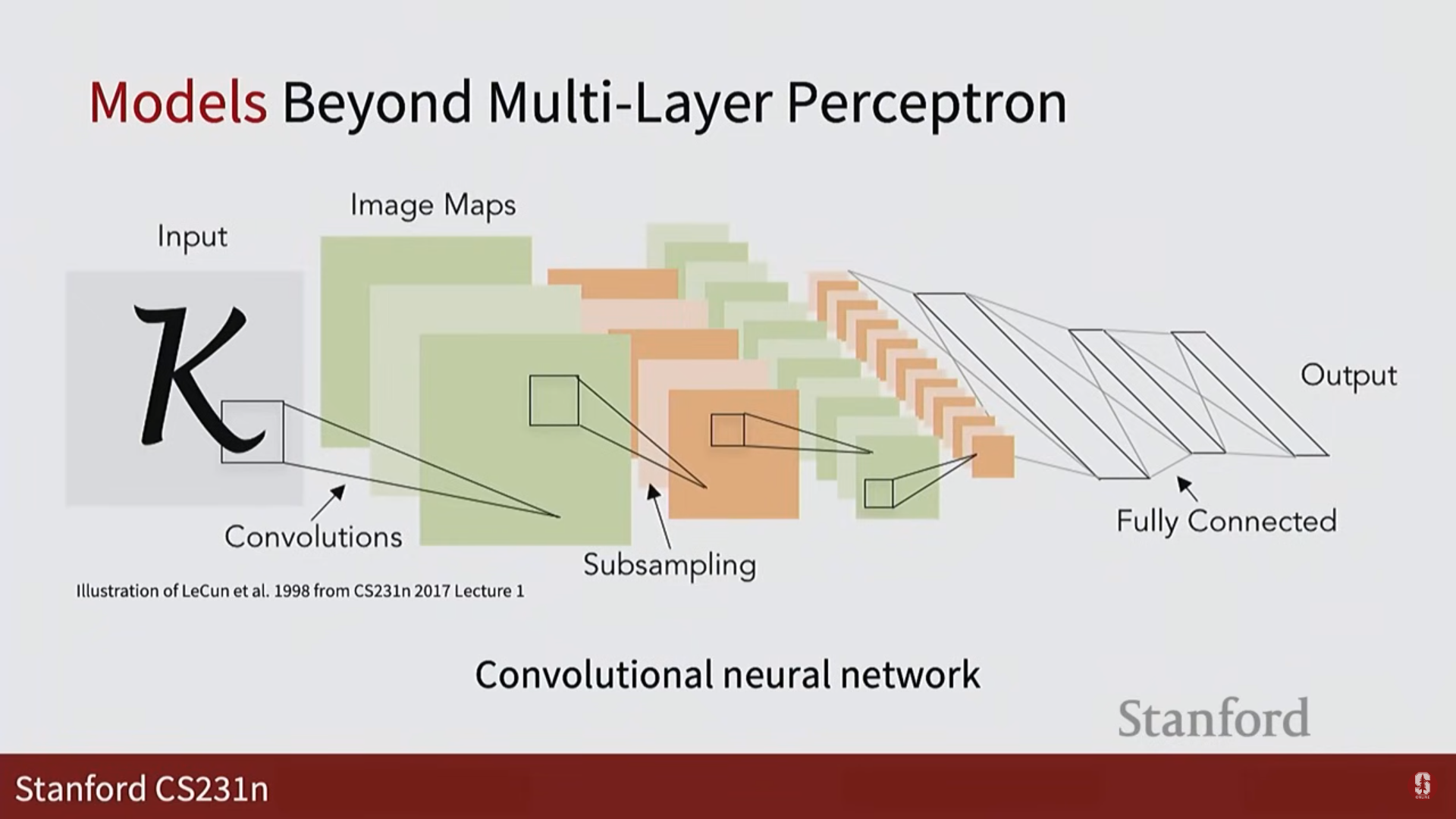
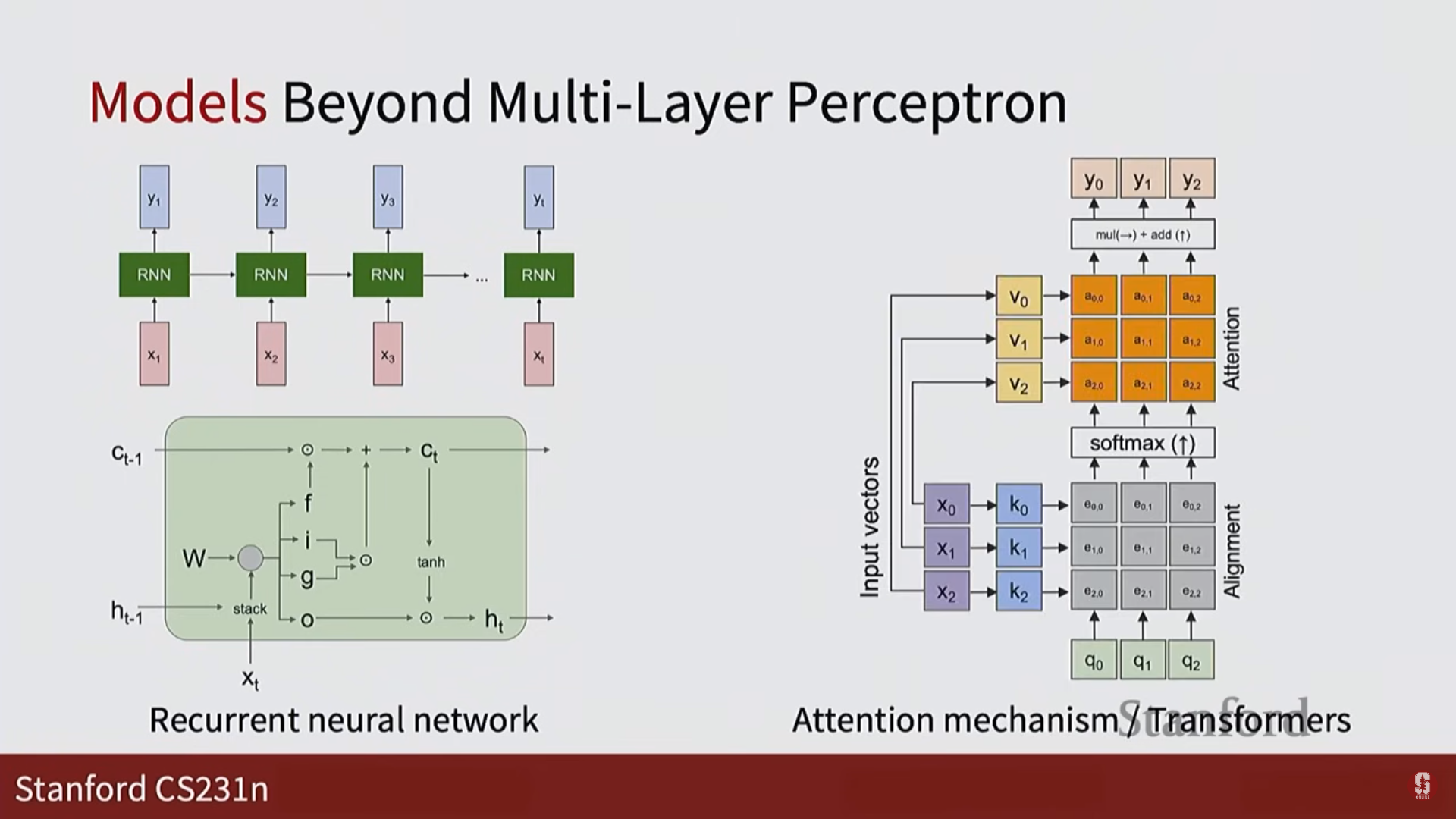
- CNN (Convolutional Neural Network): 이미지 처리를 위한 핵심 모델입니다.
- RNN (Recurrent Neural Network): 비디오와 같은 순차적 데이터를 다룹니다.
- 트랜스포머 및 어텐션: 최신 아키텍처로 비전 분야에서도 널리 사용됩니다.
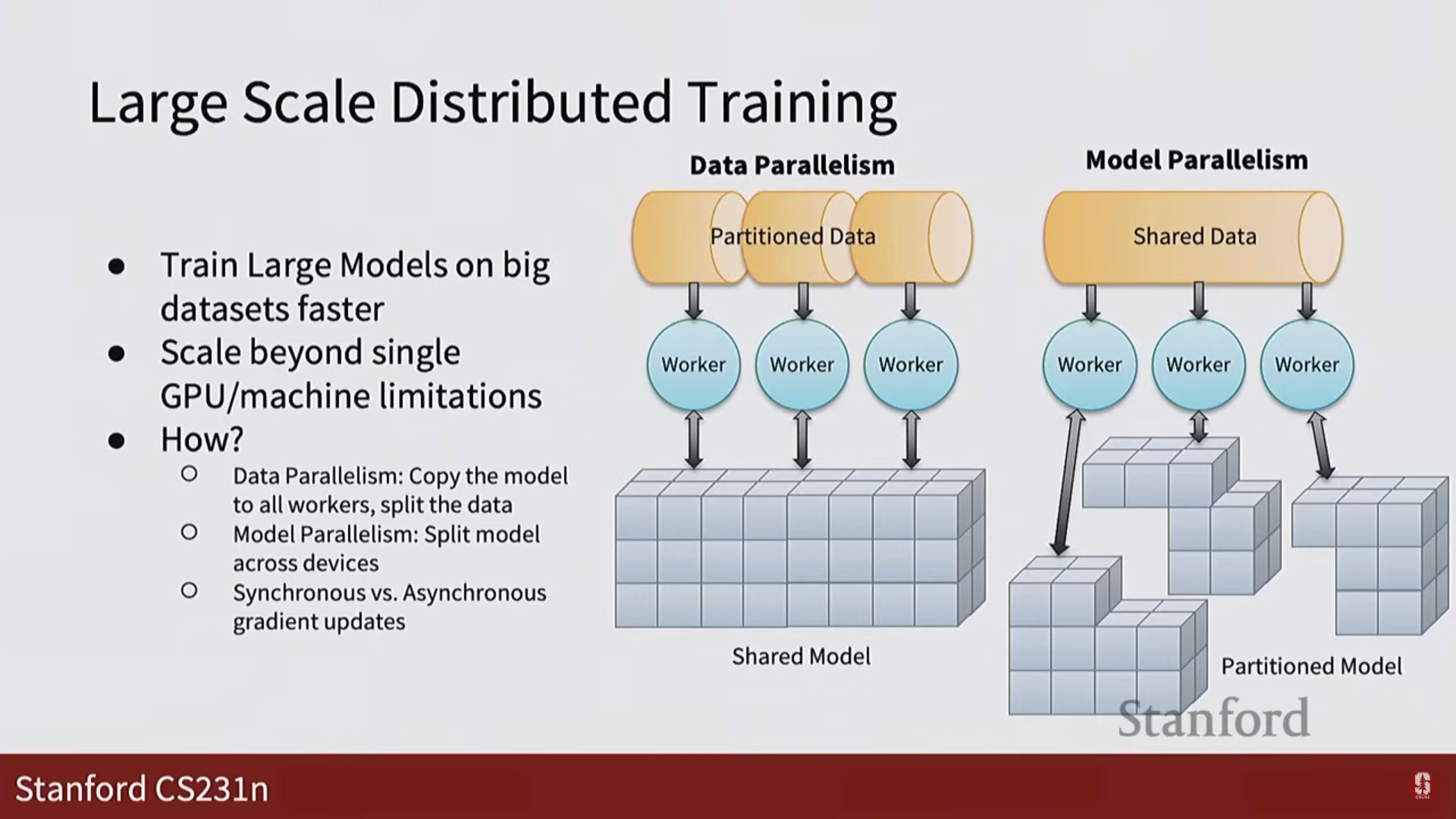
4. 대규모 분산 훈련
- 대규모 훈련의 필요성: 데이터셋과 모델의 규모가 계속 커짐에 따라, 효율적인 훈련을 위한 새로운 전략이 필요합니다.
- 분산 훈련 전략: 데이터 병렬화(Data Parallelism), 모델 병렬화(Model Parallelism)와 같이 여러 장비에 작업을 분산하여 훈련하는 기법에 대해 학습합니다.
5. 생성적 및 대화형 시각 지능

-
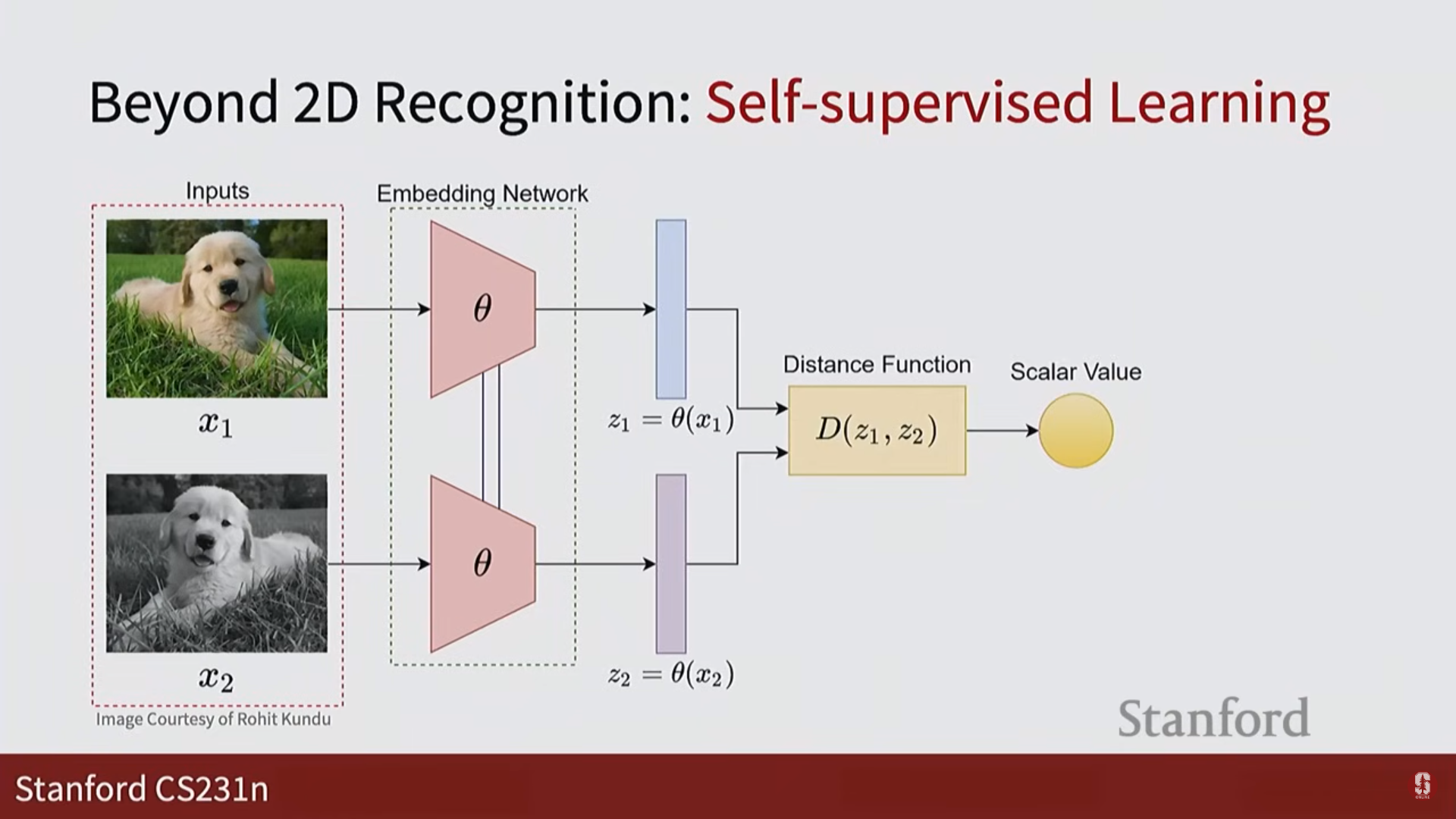
자기 지도 학습 (Self-supervised learning): 레이블이 없는 방대한 데이터를 활용해 모델 스스로 데이터의 표현(representation)을 학습하는 패러다임입니다. 이는 최근 컴퓨터 비전 분야의 핵심적인 돌파구를 만들었습니다.
-
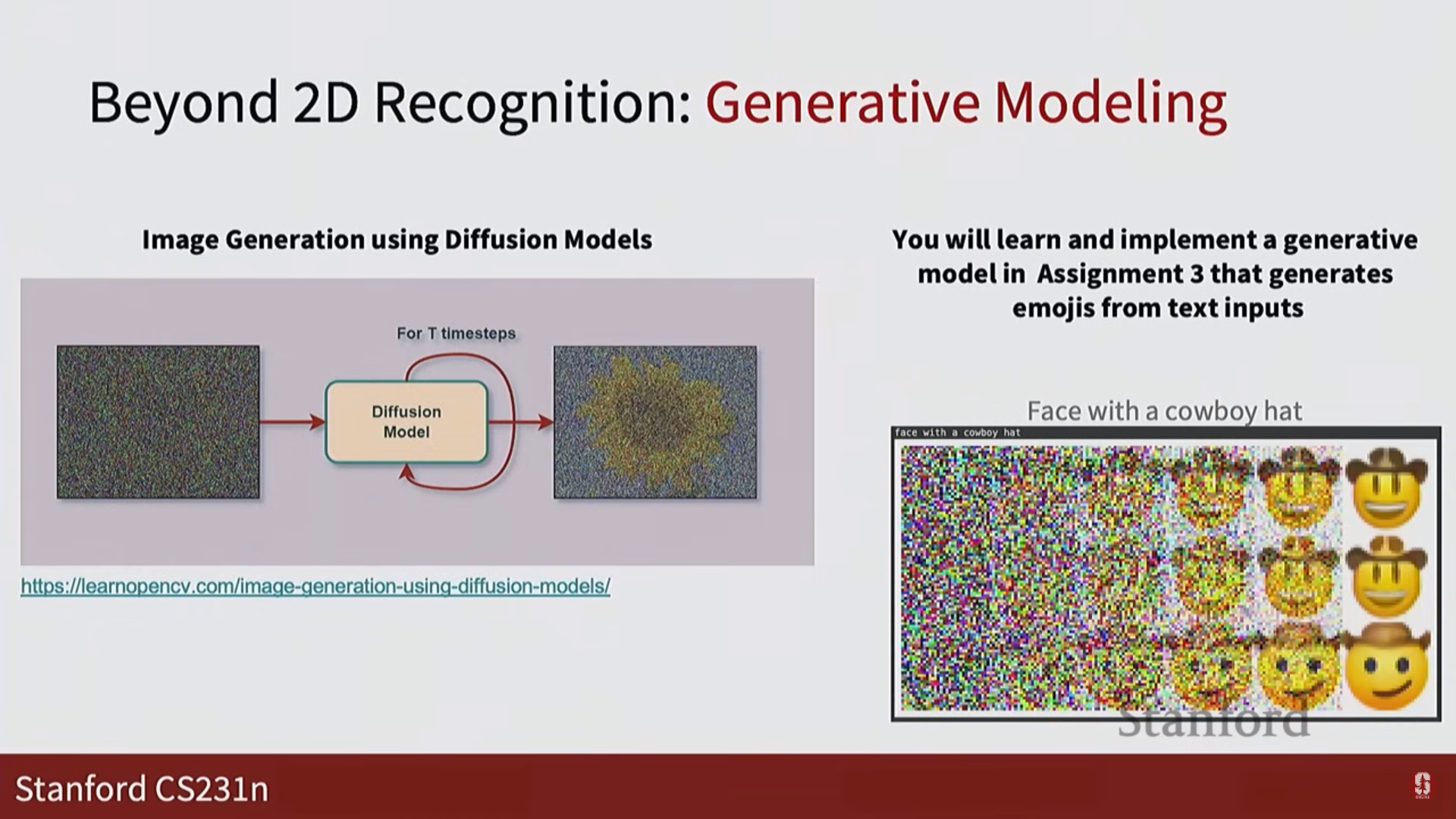
생성 모델 (Generative Models): 기존 데이터를 인식하는 것을 넘어 새로운 콘텐츠를 생성합니다.
- 스타일 전이 (Style Transfer): 특정 사진을 반 고흐 스타일의 그림으로 바꾸는 것과 같은 기술입니다.


- 확산 모델 (Diffusion Models): 점진적인 노이즈 제거 과정을 통해 고품질 이미지를 생성하는 최신 기술입니다.
- 스타일 전이 (Style Transfer): 특정 사진을 반 고흐 스타일의 그림으로 바꾸는 것과 같은 기술입니다.
-
비전-언어 모델: 텍스트와 이미지를 공유된 공간에서 함께 이해하고 처리하며, 시각적 질의응답(Visual Question Answering)과 같은 과제를 수행합니다.
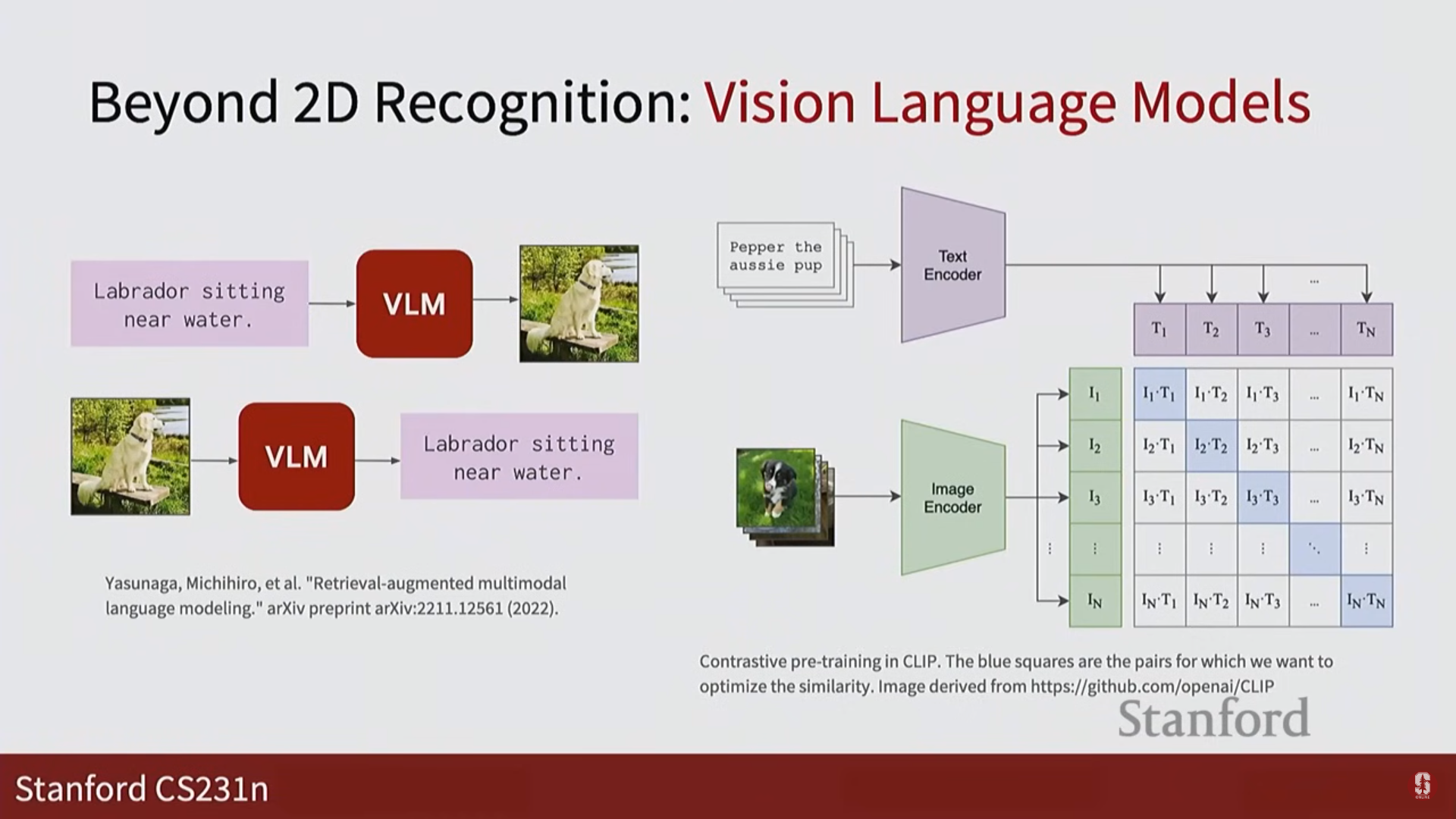
-
3D 재구성 및 생성: 2D 이미지로부터 3D 표현을 만들고 생성하는 기술로, 로보틱스 및 AR/VR 분야에 필수적입니다.
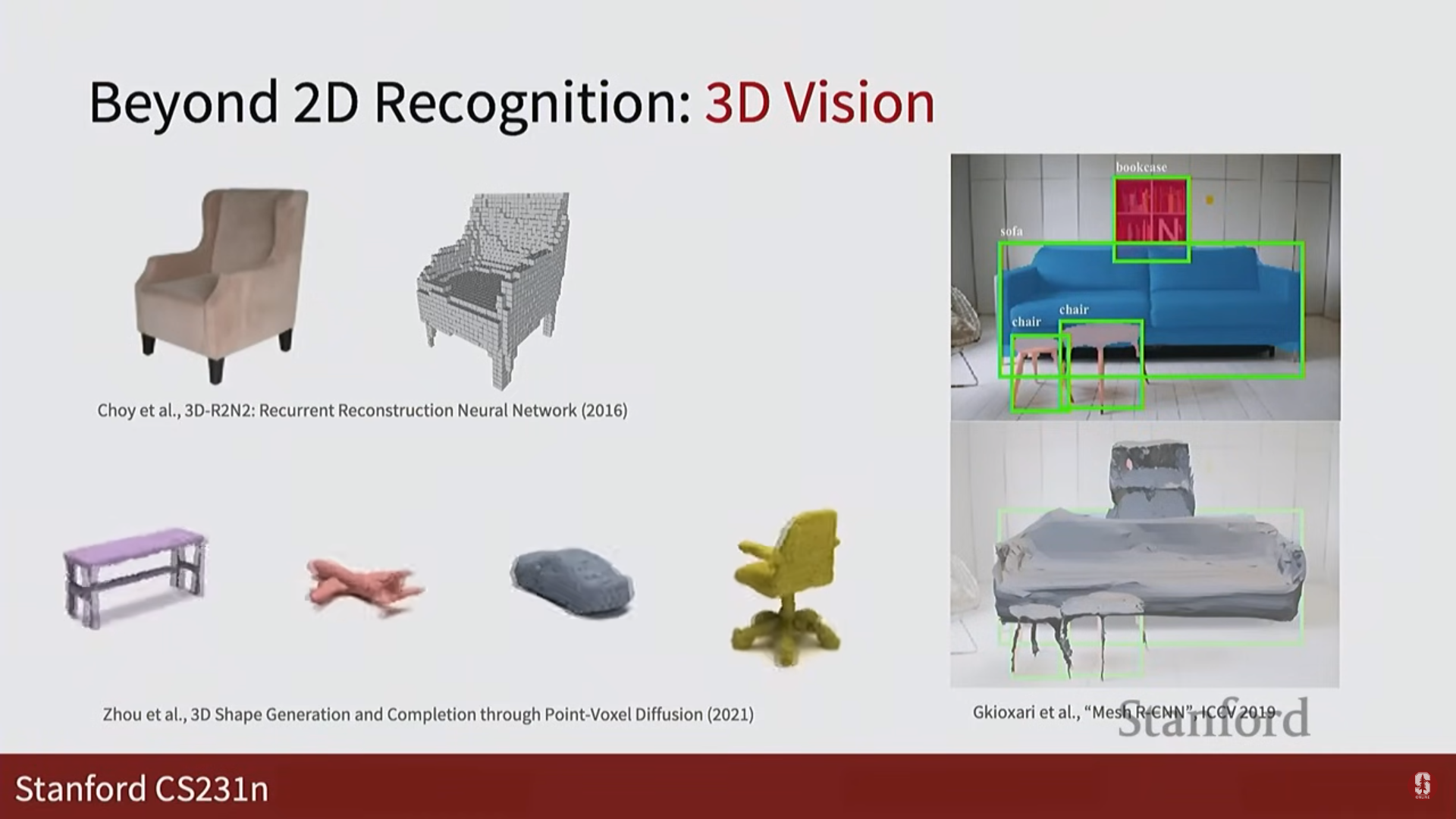
-
구현된 에이전트 (Embodied Agents): 시각 지능을 바탕으로 물리적 세계에서 특정 임무(예: 방 청소)를 수행하는 에이전트를 다룹니다.

6. 인간 중심 응용 및 함의

- 분야의 영향력: 컴퓨터 비전과 AI는 사회에 큰 영향을 미치고 있으며, 이 분야의 선구자들(Hinton, Bengio, LeCun)은 2018년 튜링상을, Hinton 교수는 2024년 노벨 물리학상을 수상했습니다.
- 최종 학습 목표: 강의를 통해 수강생들은 컴퓨터 비전의 여러 과제를 이해하고, 딥러닝 기초부터 시작하여 다양한 모델을 훈련하며, 최종적으로 인간 중심의 AI와 컴퓨터 비전에 대한 통찰을 얻게 될 것입니다.



AI 공부합니다