CV
1.[CV] CS231N 1강 정리 [Intro]

강의의 최종 목표: 수강생들이 컴퓨터 비전의 응용을 이해하고, 시각 데이터를 다루는 모델을 직접 개발 및 훈련하며, 해당 분야의 최신 동향과 미래를 파악하는 것을 목표로 합니다.강의의 4가지 핵심 주제: 강의는 크게 딥러닝 기초, 시각 세계 인식 및 이해, 생성적 및
2.[CV] CS231N 2강 정리 [Image Classification with Linear Classifiers]

이미지 분류(Image Classification)란? 🖼️컴퓨터 비전의 가장 핵심적인 문제입니다. 주어진 이미지에 대해 미리 정해진 여러 레이블(예: '고양이', '개', '자동차') 중 하나를 정확히 할당하는 작업입니다.컴퓨터가 이미지를 인식하는 방식:컴퓨터에게
3.[CV] CS231N 3강 정리 [Regularization and Optimization]

지난 시간 복습:이미지 분류: 컴퓨터에게 이미지를 보여주고 미리 정해진 레이블 중 하나를 맞추게 하는 작업입니다.선형 분류기: 이미지 픽셀(x)에 가중치(W)를 곱해 각 클래스에 대한 점수(score)를 계산하는 간단한 모델입니다. f(x, W) = Wx손실 함수 (L
4.[CV] CS231N 4강 정리 [Neural Networks and Backpropagation]

지난 시간 복습:이미지 분류는 컴퓨터에게 이미지를 보여주고 미리 정해진 레이블 중 하나를 맞추게 하는 작업입니다.선형 분류기는 데이터를 하나의 선으로 나누는 방식이었습니다. 하지만 현실 세계의 복잡한 데이터는 선 하나만으로 나눌 수 없는 경우가 많습니다.손실 함수 (L
5.[CV] CS231N 5강 정리 [Image Classification with CNNs]
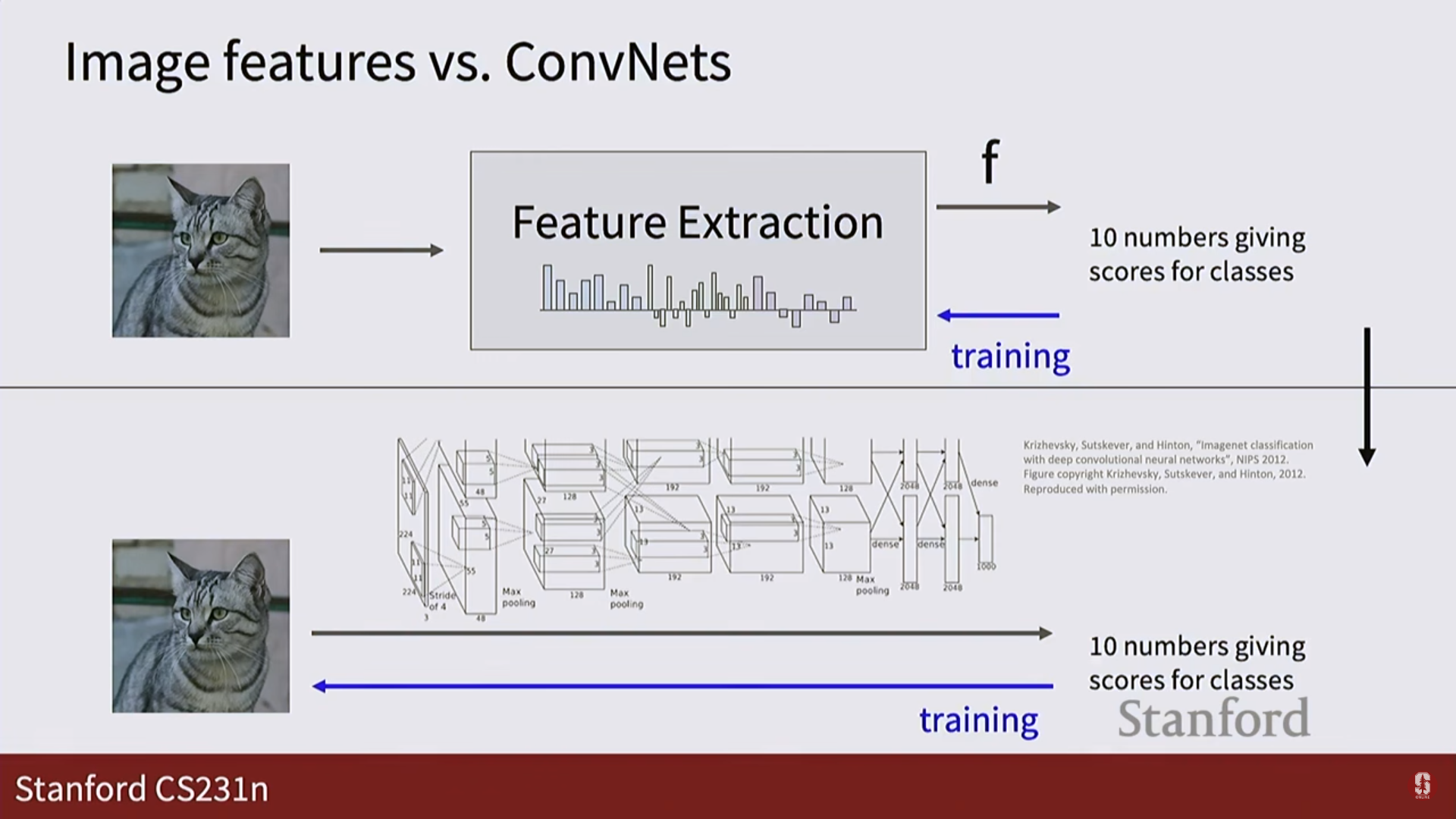
딥러닝 레시피: 딥러닝은 어떤 문제든 5단계로 해결할 수 있습니다.텐서(Tensor)로 문제 정의하기: 입출력을 숫자의 배열(텐서)로 표현합니다.아키텍처 설계: 계산 그래프를 이용해 입력을 출력으로 바꾸는 신경망 구조를 만듭니다.데이터셋 수집: 수많은 입출력(정답) 쌍
6.[CV] CS231N 6강 정리 [CNN Architectures]

1. CNN의 기본 구성 요소 1) 컨볼루션 계층 (Convolutional Layer) 컨볼루션 계층은 CNN의 근간을 이루는 핵심 연산 계층입니다. 이 계층의 주된 역할은 입력 데이터에 필터(Filter 또는 커널, Kernel)를 적용하여 특징 맵(Feature
7.[CV] CS231N 7강 정리 [Recurrent Neural Networks]

1. 순환 신경망(RNN)의 개념 1) 순차적 데이터 모델링의 필요성 이전 강의에서 다룬 CNN과 같은 모델들은 이미지처럼 고정된 크기의 입력을 가정합니다. 하지만 현실 세계의 많은 데이터는 문장, 음성, 주식 가격처럼 길이가 가변적인 순서가 있는 데이터(시퀀스)입니
8.[CV] CS231N 8강 정리 [Attention and Transformers]
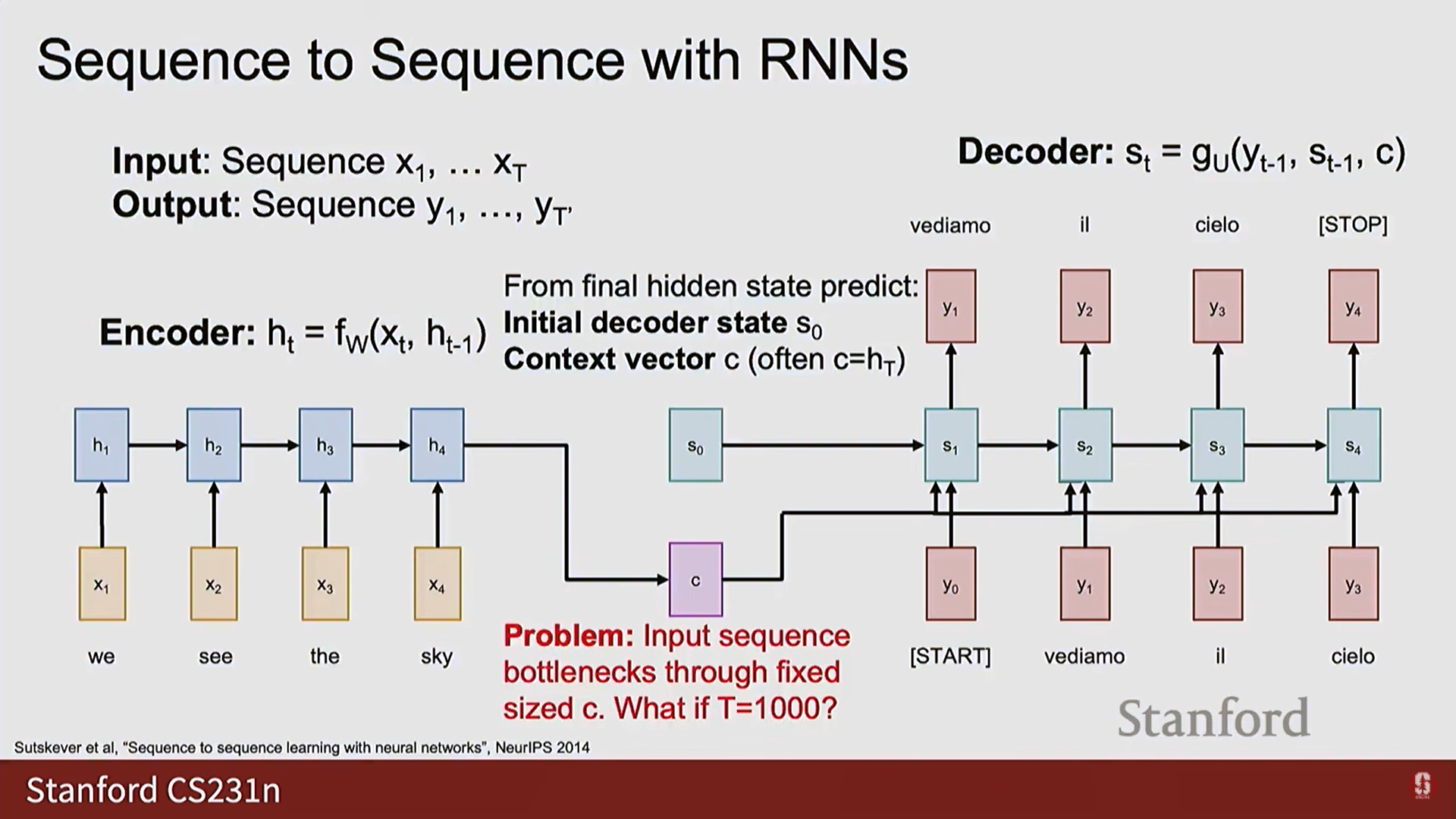
RNN (Recurrent Neural Networks): 순차적인 데이터(Sequence Data)를 처리하기 위해 설계된 신경망 아키텍처입니다. 텍스트, 음성 등 시간적 순서가 중요한 데이터 처리에 강점을 가집니다.활용 분야: 이미지 캡셔닝 (하나의 이미지 입력,
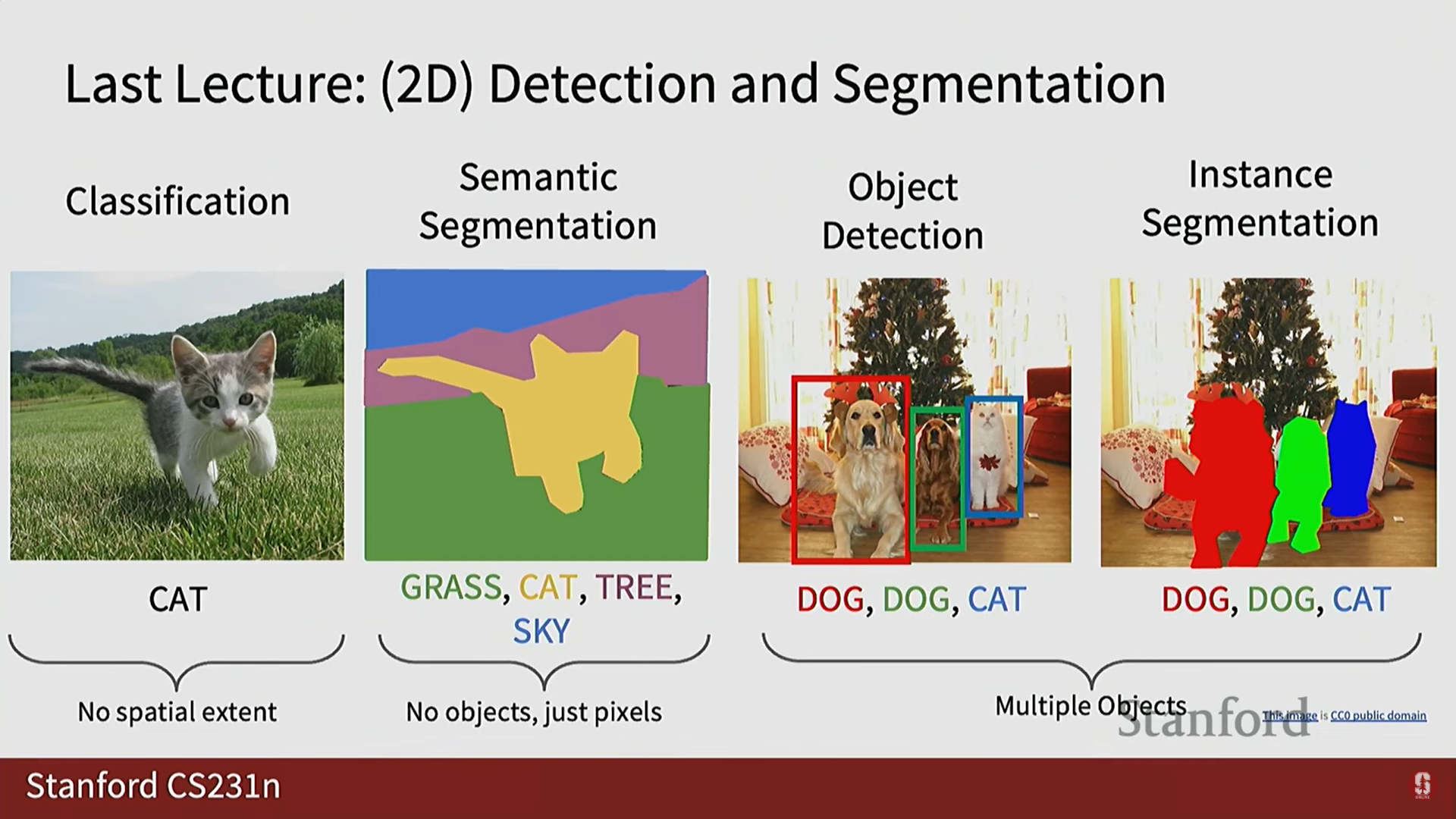
9.[CV] CS231N 9강 정리 [Object Detection, Image Segmentation, Visualizing]
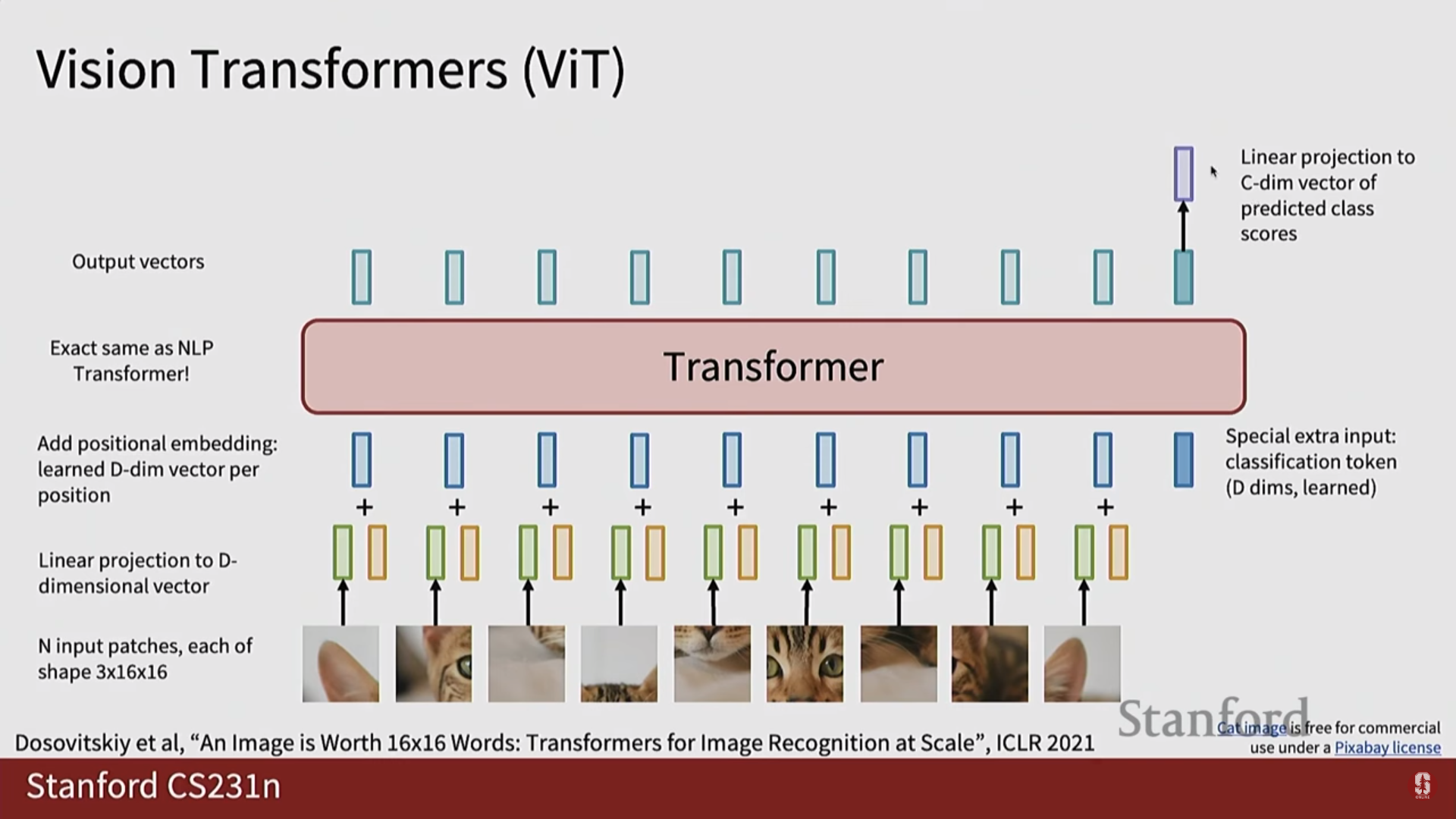
기존의 RNN 기반 시퀀스-투-시퀀스 모델의 한계를 극복하기 위해 등장한 Transformer는 멀티 헤드 셀프 어텐션(Multi-Head Self-Attention) 메커니즘을 핵심으로 사용합니다.셀프 어텐션은 시퀀스 내의 모든 토큰들이 서로 어떻게 상호작용하는지를
10.[CV] CS231N 10강 정리 [Video Understanding]
본 강의는 초청 강연으로, 컴퓨터 과학부 조교수이자 다중 감각 기계 지능 연구소(Multi-sensory Machine Intelligence Lab)를 이끌고 있는 Dr. Rohan Gao가 진행했습니다.Dr. Gao는 컴퓨터 비전뿐만 아니라 오디오, 촉각 등 다른
11.[CV] CS231N 11강 정리 [Large Scale Distributed Training]

오늘날 모든 신경망(Neural Networks)은 대규모 분산 방식으로 훈련되며, 대규모(Large Scale)는 딥러닝의 새로운 표준이 되었습니다.10년 전만 해도 모델을 단일 GPU, 즉 하나의 디바이스에서 훈련하는 것이 일반적이었으나, 이제는 수십, 수백, 수천
12.[CV] CS231N 12강 정리 [Self-Supervised Learning]

지난 강의에서는 GPU 사용법, 대규모 훈련 확장, 그리고 이미지 분류, 의미론적 분할, 객체 탐지 등 핵심적인 컴퓨터 비전(CV) 태스크에 대해 다루었습니다.초기에는 픽셀 공간에서의 최근접 이웃(Nearest Neighbor) 방식을 논했지만, 이는 효율적이지 않습니
13.[CV] CS231N 13강 정리 [Generative Models 1]

자기 지도 학습 (Self-Supervised Learning, SSL) 패러다임: 레이블(Labels) 없이 데이터로부터 직접 구조를 학습하려는 흥미로운 접근 방식이다.전형적인 구조: 레이블이 없는 대규모 데이터셋(X)을 인코더(Encoder)에 통과시켜 특징 표현(
14.[CV] CS231N 14강 정리 [Generative Model 2]

1. 개요 생성 모델링 (Generative Modeling) 개요 지난 시간에 생성 모델에 대해 논의를 시작했다. 확률론적 모델은 판별 모델(discriminative models)과 생성 모델(generative models)로 나뉘는데, 이는 우리가 무엇을 예측
15.[CV] CS231N 15강 정리 [3D Vision]
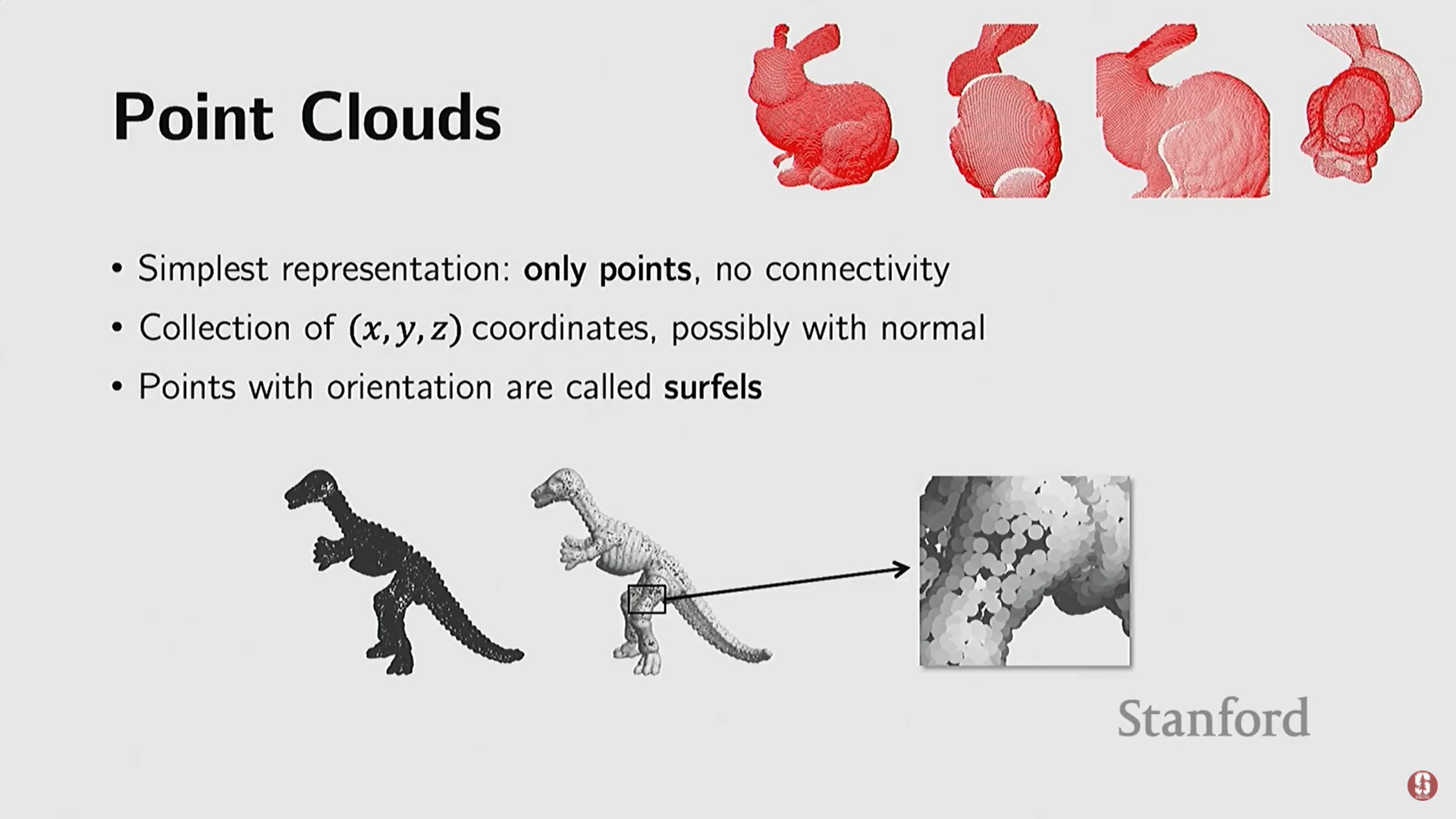
본 강의는 Stanford 컴퓨터 과학과 조교수인 Jajun Wu 교수가 진행하며, 3D 비전(3D understanding)을 주제로 다룬다.Wu 교수는 장면 이해(Scene Understanding), 멀티모달 지각(Multimodal Perception), 로보틱
16.[CV] CS231N 16강 정리 [Vision and Language]
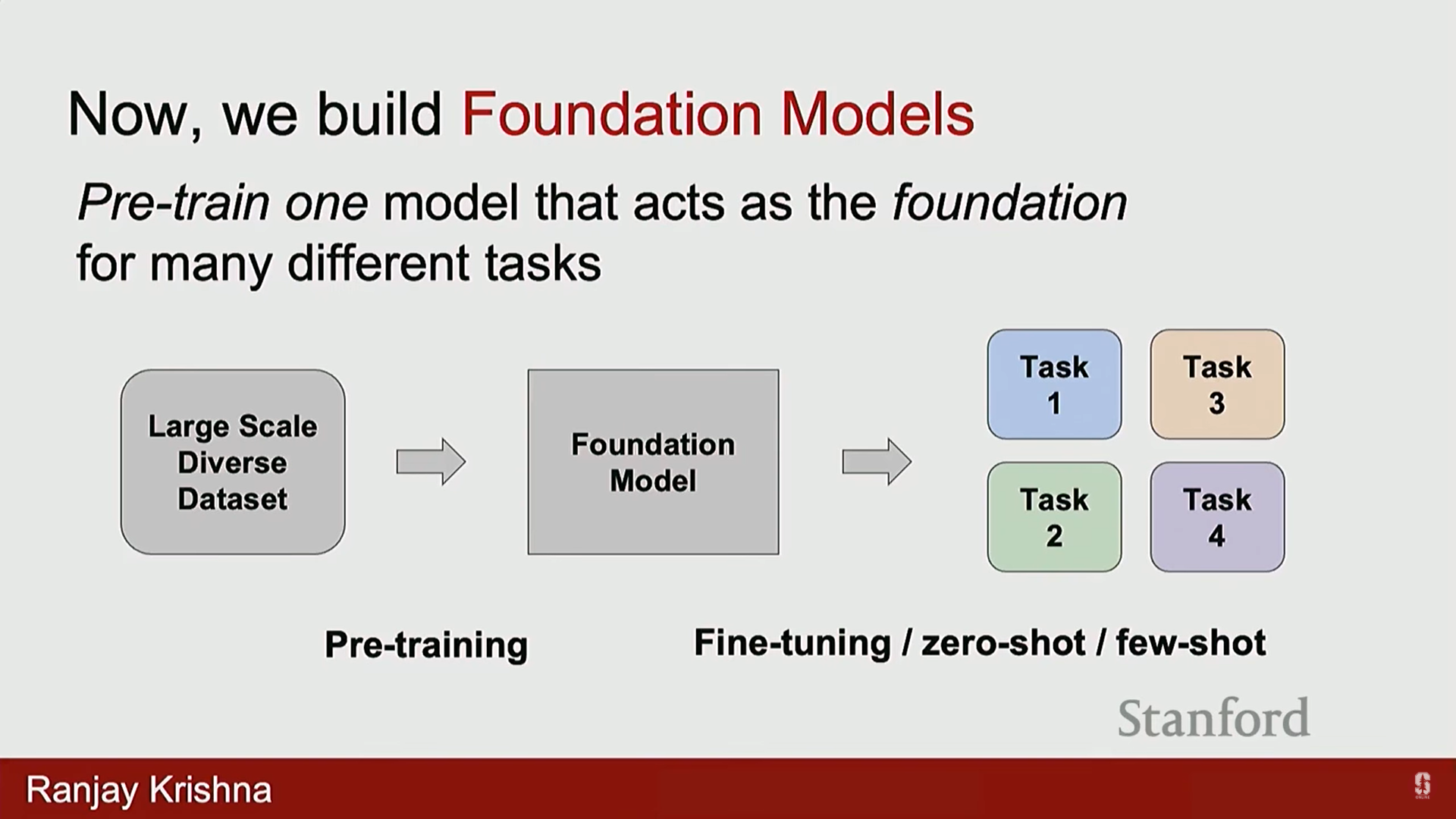
기존의 딥러닝 강의는 개별 태스크를 위한 개별 모델 구축에 중점을 두었습니다.이 과정은 데이터셋 수집(훈련 및 테스트 세트), 특정 모델 훈련(예: 이미지 분류, 이미지 캡셔닝 모델), 그리고 테스트 세트에서의 평가 단계를 따릅니다.최근 몇 년간 분야의 변화는 개별 모
17.[CV] CS231N 17강 정리 [Robot Learning]
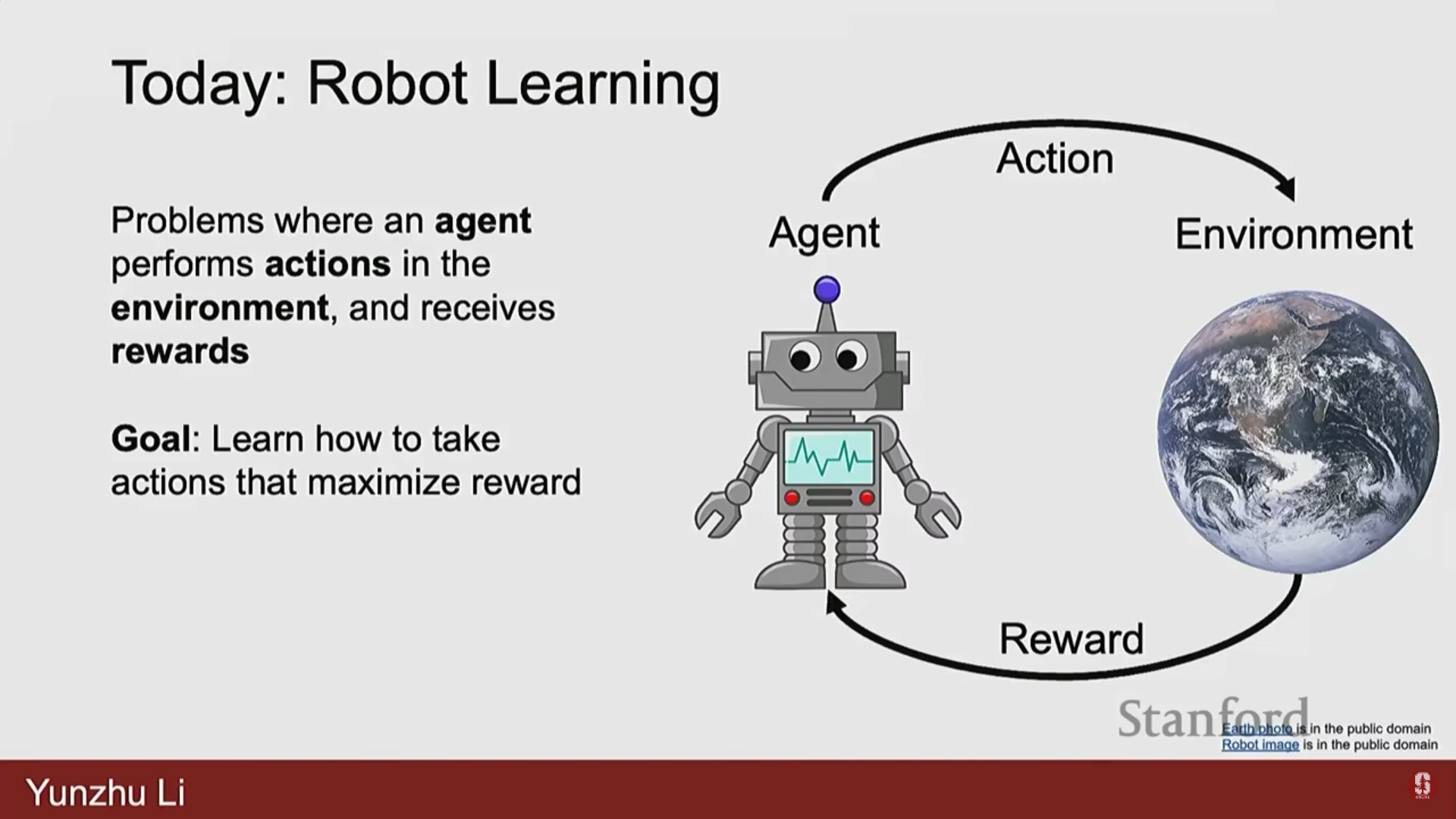
본 강의는 Columbia 대학교 컴퓨터 과학과 조교수이자 Robotic Perception, Interaction, and Learning Lab을 이끄는 Yunju Lee 박사가 진행했다.Yunju Lee 박사는 2023년에 CS231N 강사로 활동했으며, 그의 연
18.[CV] CS231N 18강 정리 [Human-Centered AI]
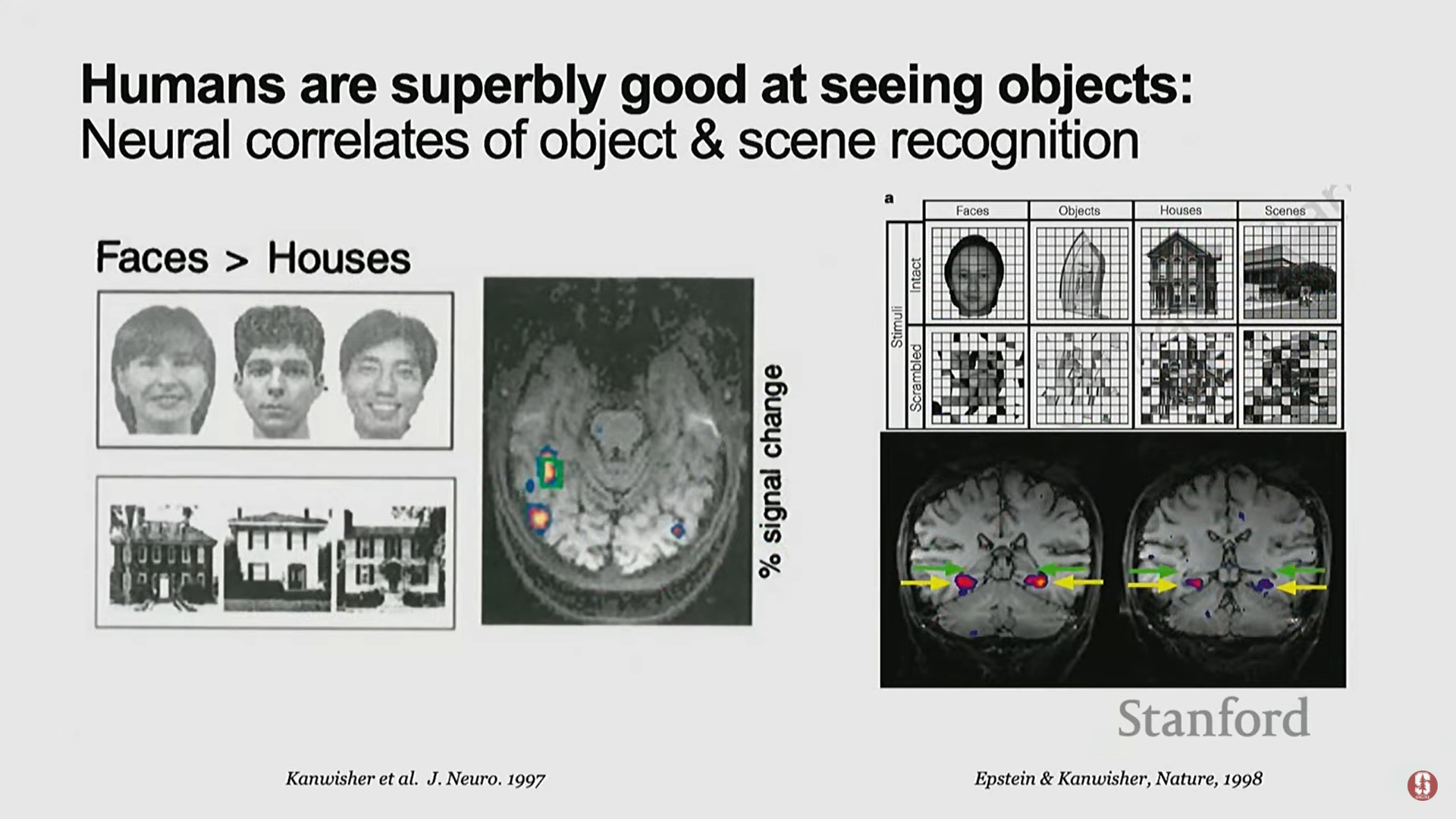
이번 강의는 CS231N 학기의 마지막 강의로, 알고리즘보다는 AI의 장기적인 연구 발전 방향과 오늘날 AI에서 중요한 인간의 관점(human perspective)에 대한 통찰을 제공한다.강의 제목은 "우리가 보는 것과 우리가 소중히 여기는 것: 인간의 관점을 가진
19.[CV] CS236 1강 정리 [Introduction]
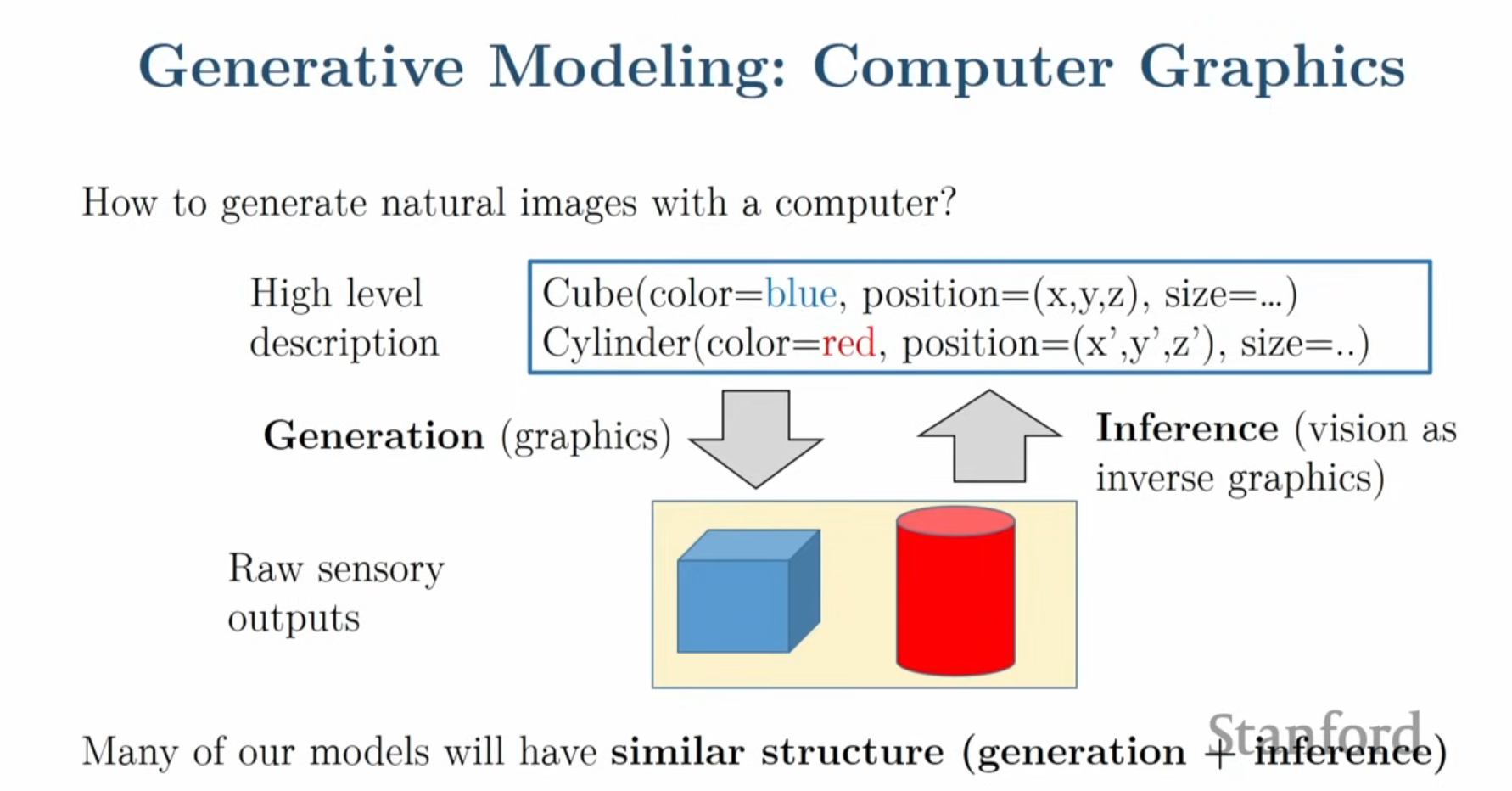
고차원 신호의 이해: 컴퓨터 비전, NLP, 음성 인식 등 AI의 다양한 분야에서 직면하는 근본적인 과제는 이미지, 오디오, 텍스트와 같은 복잡한 고차원 신호(High-dimensional signal)를 처리하는 것입니다.데이터의 표현: 컴퓨터 입장에서 이미지는 단순
20.[CV] CS236 2강 정리 [Background]

생성 모델(Generative Model)이란 복잡한 데이터셋(이미지, 텍스트 등)의 기본이 되는 확률 분포를 학습하는 모델을 의미합니다.우리가 다루는 데이터 포인트들은 알 수 없는 실제 확률 분포($P\_{data}$)로부터 샘플링되었다고 가정합니다.생성 모델링의 핵
21.[CV] CS236 3강 정리 [Autoregressive Models]

생성 모델을 학습시키기 위해서는 데이터(IID 샘플)와 모델 패밀리, 그리고 데이터 분포와 모델 분포 사이의 유사성 또는 발산(Divergence)을 정의하는 과정이 필요합니다. 자기회귀 모델(Autoregressive Models)은 이러한 생성 모델의 한 종류로,
22.[CV] CS236 4강 정리 [Maximum Likelihood Learning]
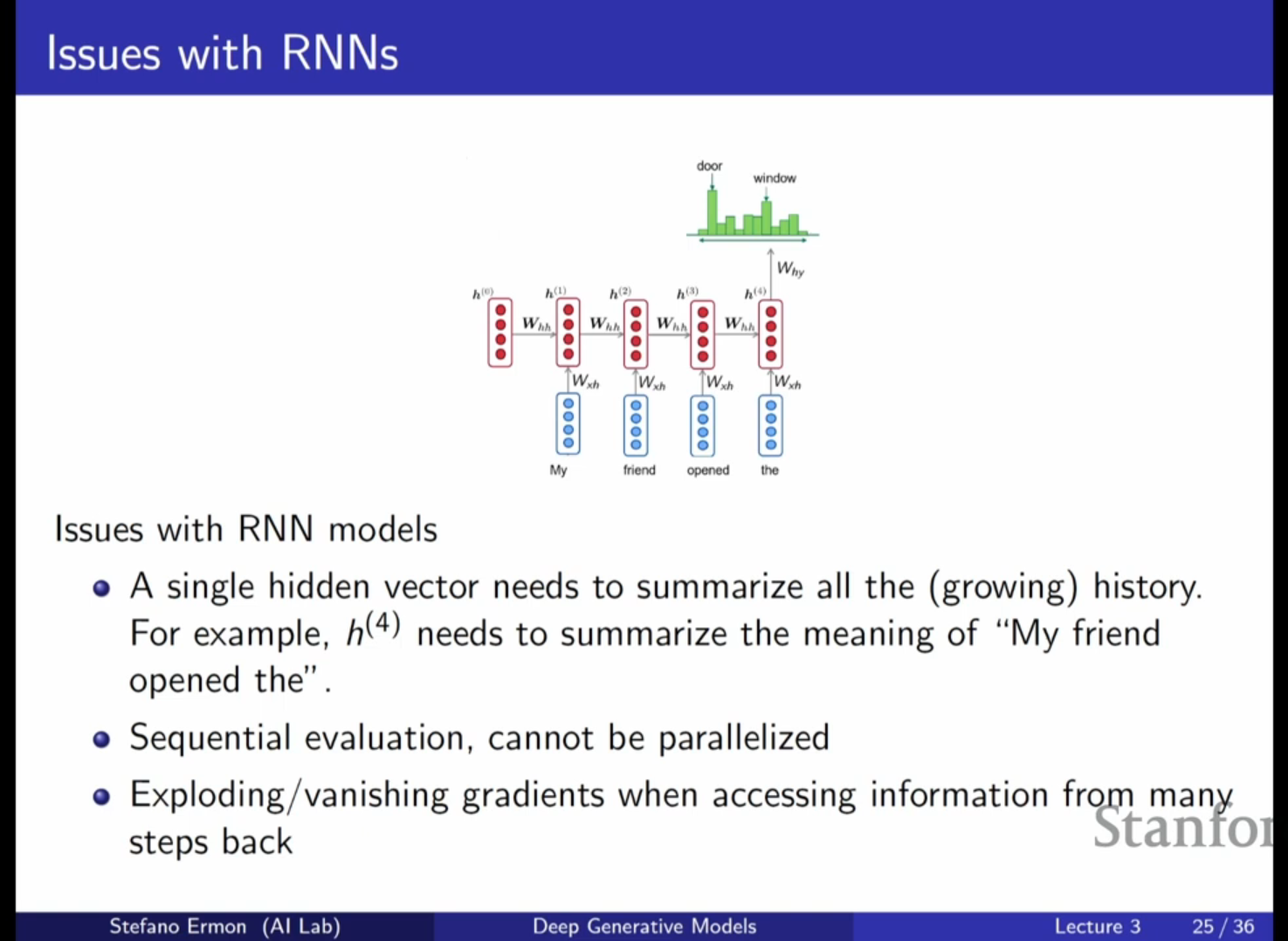
RNN 기반 자기회귀 모델의 특징: 지난 시간에 다룬 RNN은 시퀀스의 길이에 상관없이 고정된 수의 파라미터를 사용하여 이전의 문맥(Context)을 추적합니다. RNN은 이전까지 본 정보를 하나의 은닉 벡터(Hidden Vector, $h$)에 요약하여 다음 토큰이나
23.[CV] CS236 5강 정리 [VAEs]
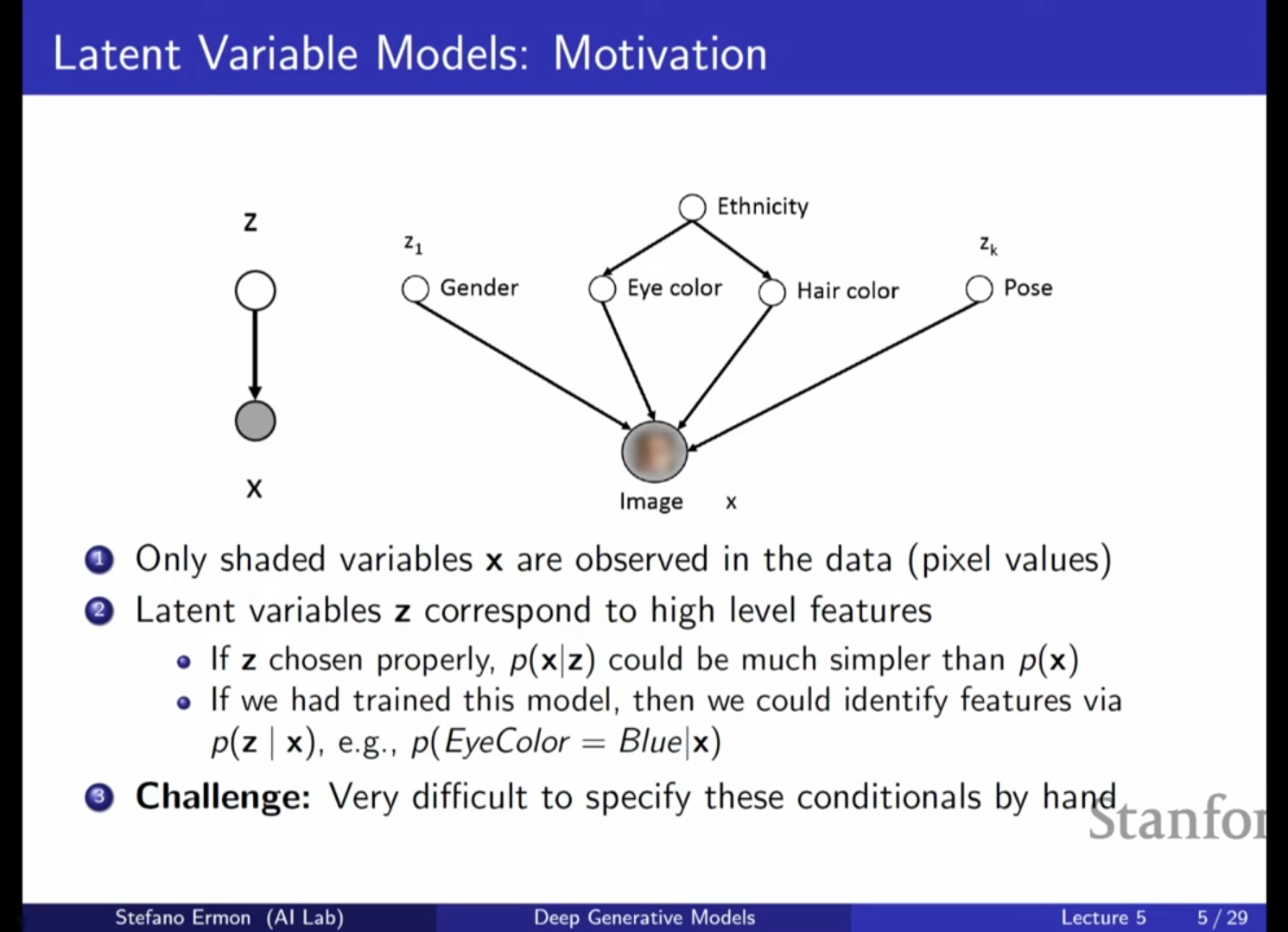
지난 시간에는 자기회귀 모델(Auto-regressive models)에 대해 배웠습니다. 이 모델들은 연쇄 법칙(Chain rule)을 사용해 결합 확률 분포를 조건부 확률의 곱으로 근사하며, RNN, CNN, 트랜스포머 등을 활용해 우도(Likelihood)에 직접
24.[CV] CS236 6강 정리 [VAEs]

VAE의 정의: 단순한 잠재 변수(Latent Variable) 모델을 신경망을 통해 매우 유연한 생성 모델로 확장한 형태예요.데이터 생성 프로세스:잠재 변수 $Z$ 샘플링: 단순한 분포(예: 평균이 0이고 공분산이 단위 행렬인 다변량 가우시안 분포, $P(Z)$)에서
25.[CV] CS236 7강 정리 [Normalizing Flows]
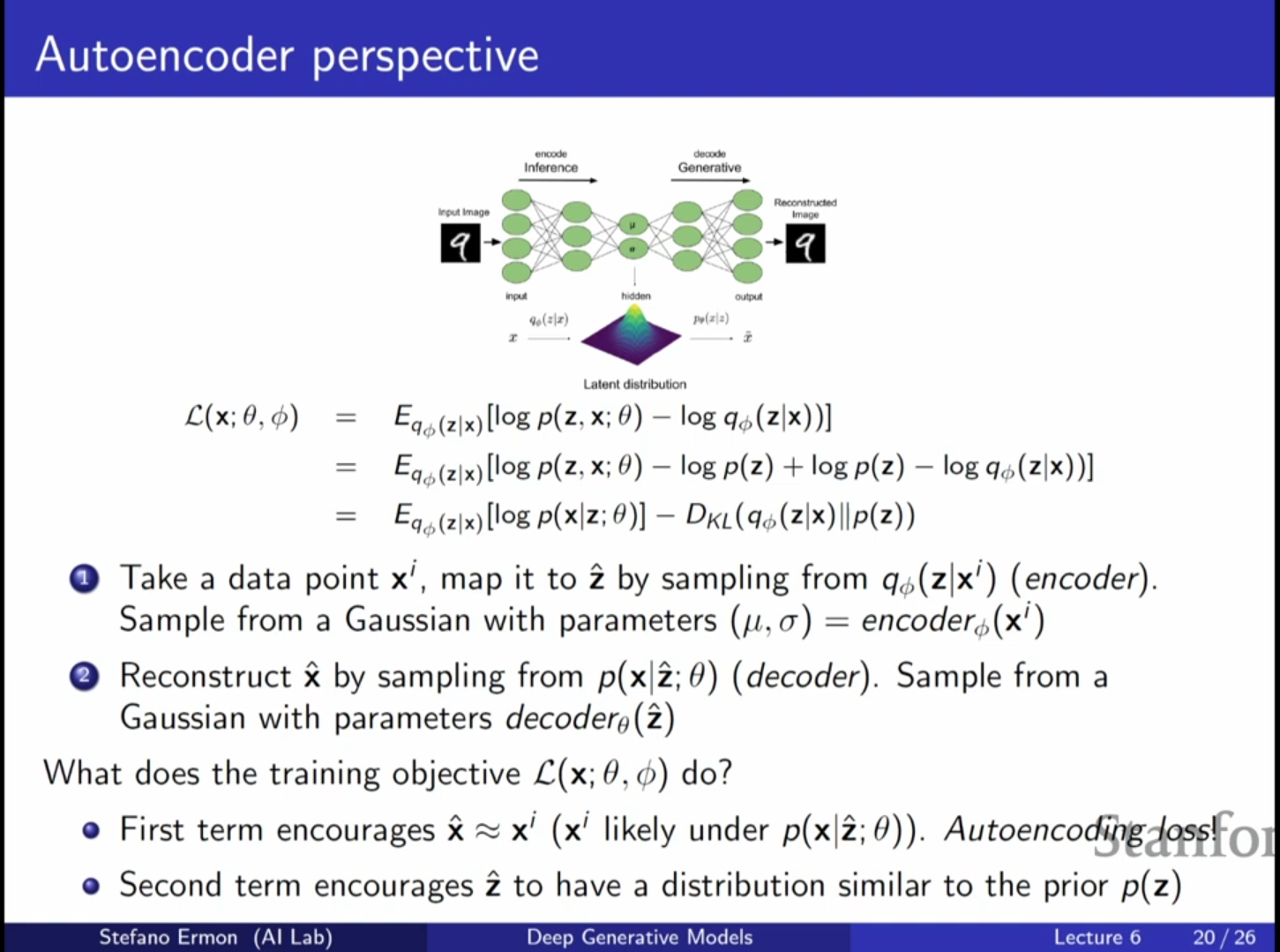
VAE의 훈련 목표와 오토인코더의 관계: 지난 강의에 이어 변분 오토인코더(VAE)를 오토인코더(Autoencoder)의 관점에서 해석하는 것으로 강의를 시작합니다. VAE의 목적 함수인 ELBO(Evidence Lower Bound)는 두 부분으로 나눌 수 있으며,
26.[CV] CS236 8강 정리 [Normalizing Flows]

Normalizing Flow 모델은 잠재 변수(Latent Variable) 모델의 일종으로, 가변 추론(Variational Inference)에 의존하지 않고 정확한 우도(Exact Likelihood)를 계산할 수 있다는 장점이 있습니다.VAE(Variation
27.[CV] CS236 9강 정리 [GANs]
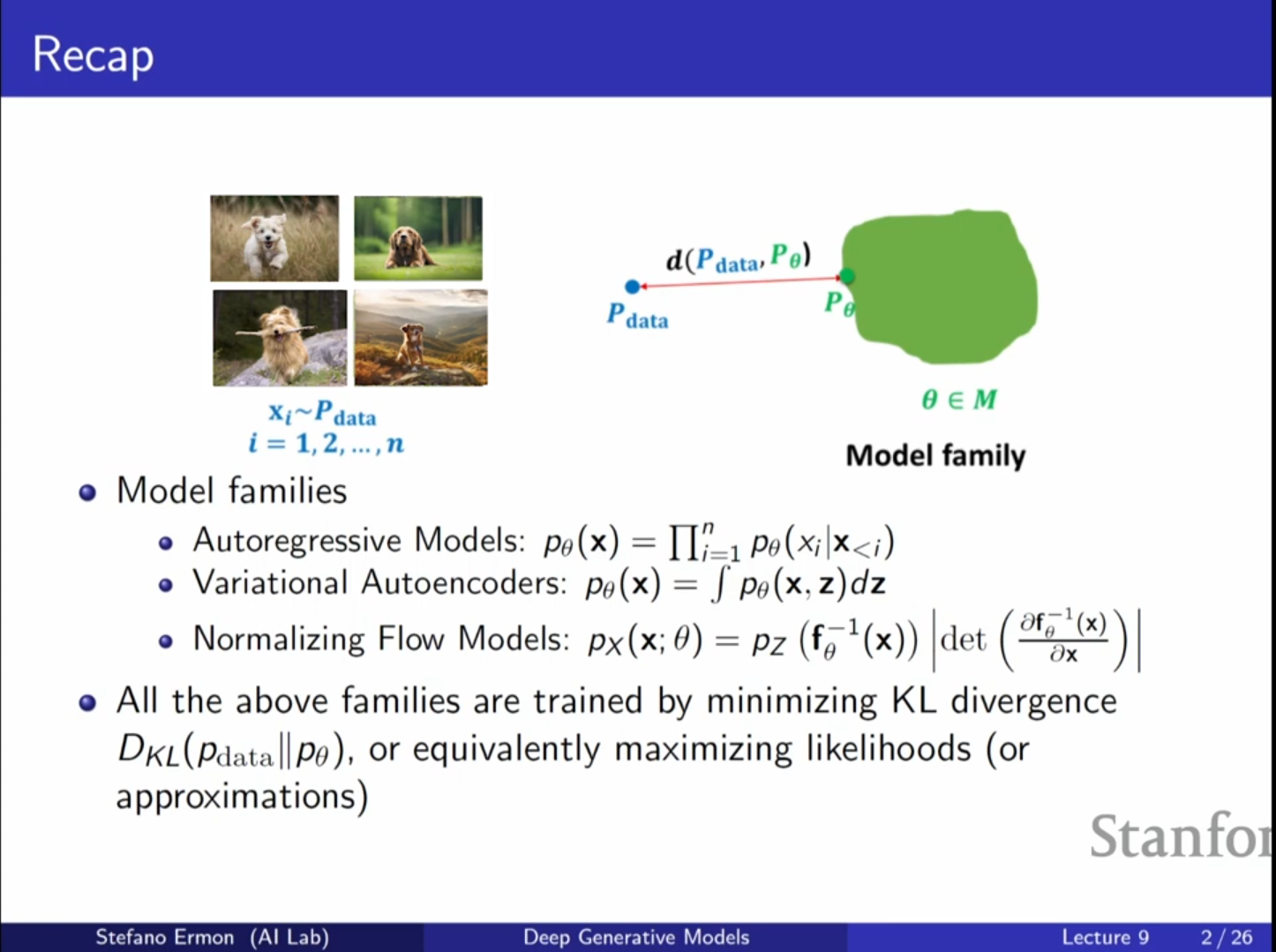
지금까지 다룬 모델들(Autoregressive Model, VAE, Normalizing Flow)은 모두 최대 우도(Maximum Likelihood) 학습을 기반으로 했습니다.이들은 데이터 분포($P{data}$)와 모델 분포($P{\\theta}$) 사이의 KL
28.[CV] CS236 10강 정리 [GANs]

Likelihood-free 학습: 생성적 적대 신경망(GAN)의 가장 큰 장점은 모델의 확률 밀도 함수를 명시적으로 정의하거나 연쇄 법칙(chain rule)에 따라 분해할 필요 없이, 우도(Likelihood)를 계산하지 않고도 모델을 학습시킬 수 있다는 점입니다.
29.[CV] CS236 11강 정리 [Energy Based Models]
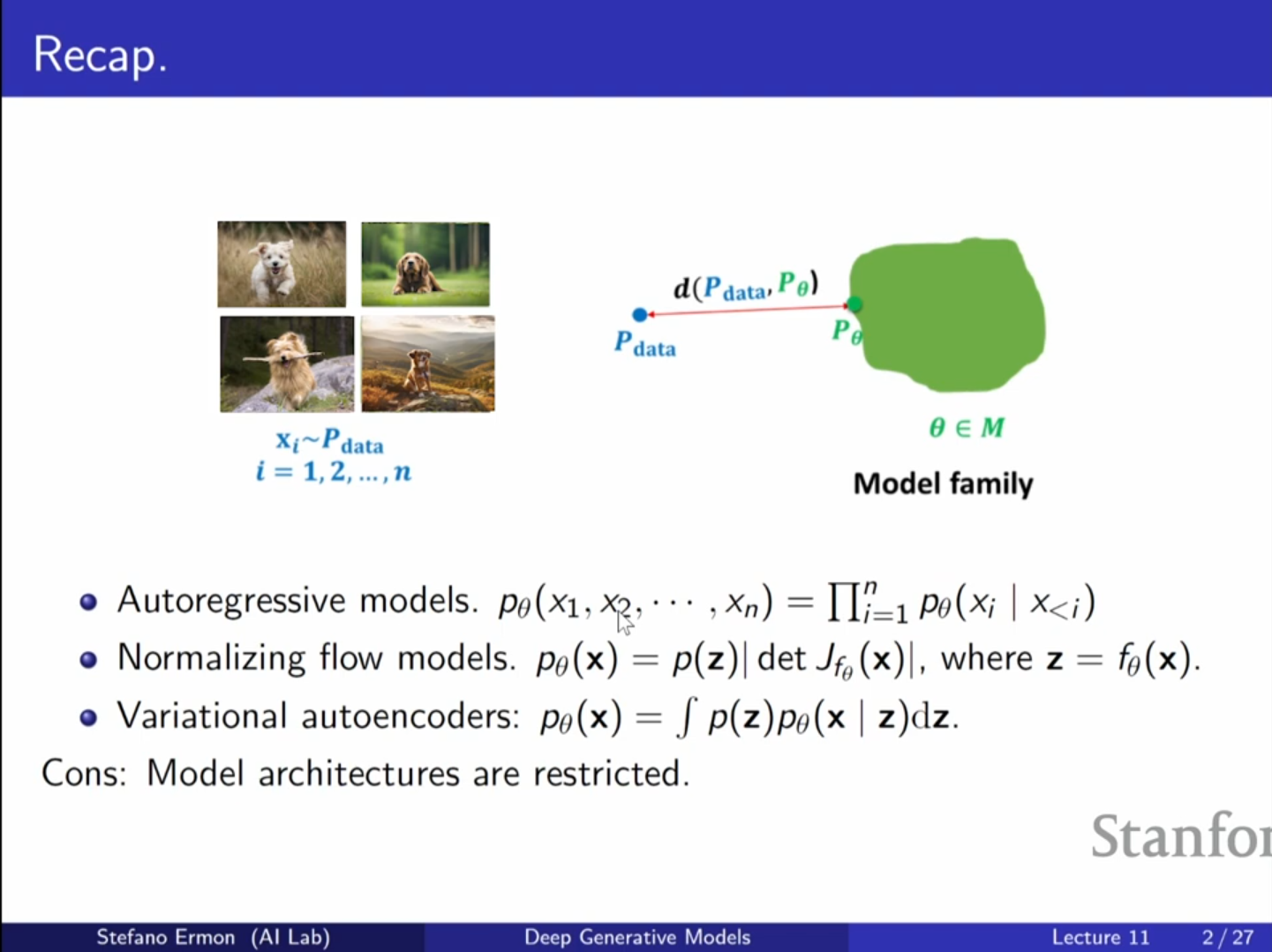
오늘 강의에서는 에너지 기반 모델(Energy Based Models, EBM)에 대해 다룹니다. 이는 확산 모델(Diffusion Models)과 밀접하게 관련된 생성 모델의 한 종류입니다.생성 모델을 구축할 때 우리는 알려지지 않은 데이터 분포에서 온 데이터를 가지
30.[CV] CS236 12강 정리 [Energy Based Models]

에너지 기반 모델은 정규화되지 않은 확률 분포(unnormalized probability distribution)를 정의하는 매우 유연한 방법입니다.
31.[CV] CS236 13강 정리 [Score Based Models]
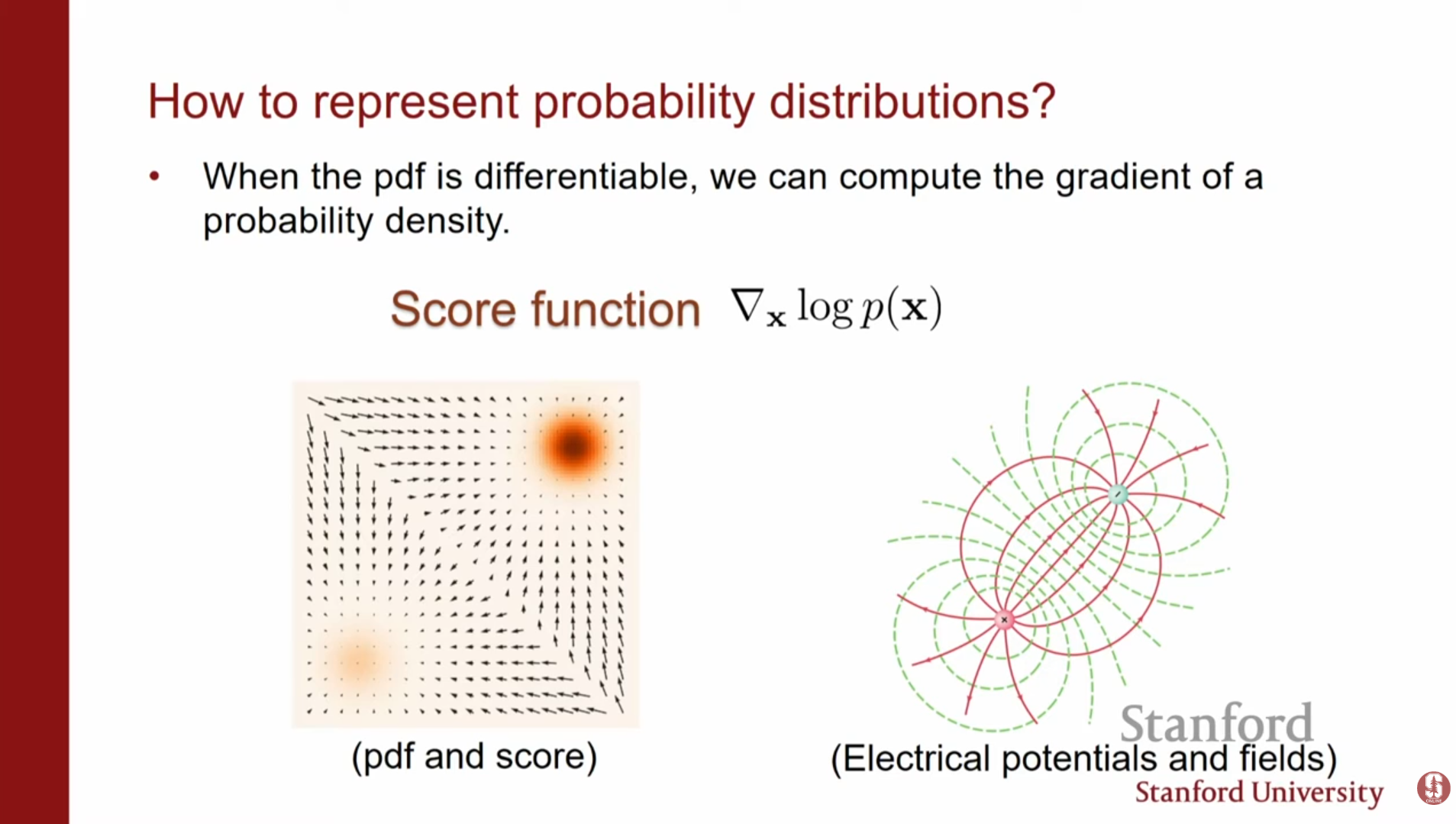
강의 초반부에서는 지금까지 다룬 생성 모델들의 장단점을 복습하며 스코어 기반 모델의 필요성을 설명합니다.우도 기반 모델(Likelihood-based models): Autoregressive 모델이나 Flow 모델 등은 확률 밀도 함수(PDF)를 직접 모델링합니다.
32.[CV] CS236 14강 정리 [Energy Based Models]

지난 강의에 이어 스코어 기반 모델(Score-based Models)에 대한 논의를 심화합니다. 스코어 모델은 신경망을 통해 데이터 분포의 로그 우도 그라디언트(Vector Field, $\\nabla_x \\log p(x)$)를 학습하는 것을 목표로 합니다. 그러나
33.[CV] CS236 15강 정리 [Evaluation of Generative Models]

생성 모델(Generative Models)의 평가는 매우 까다로운 주제이며, 현재까지 완벽한 합의(Consensus)가 이루어지지 않은 분야입니다. 모델링 방법론(Autoregressive, Flow, VAE, GAN, Score-based 등)과 훈련 목적함수(KL
34.[CV] CS236 16강 정리 [Score Based Diffusion Models]
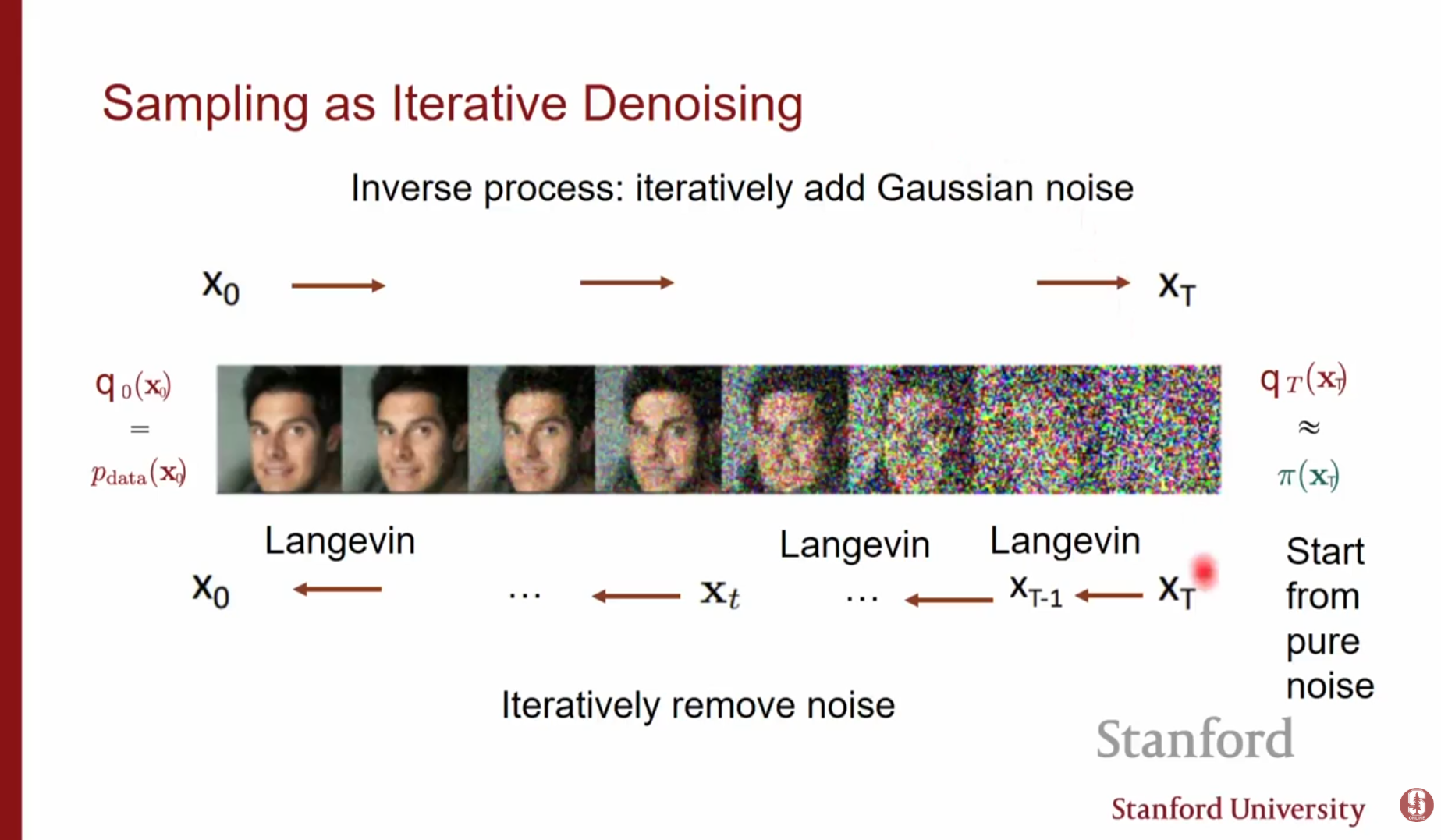
강의 초반부에서는 지난 시간에 다루었던 스코어 기반 모델의 핵심 개념을 복습합니다.스코어 함수(Score Function) 모델링: 확률 분포를 모델링하기 위해 로그 우도(log-likelihood)의 그라디언트인 스코어 함수를 사용합니다. 이는 우도를 증가시키기 위해
35.[CV] CS236 17강 정리 [Discrete Latent Variable Models]
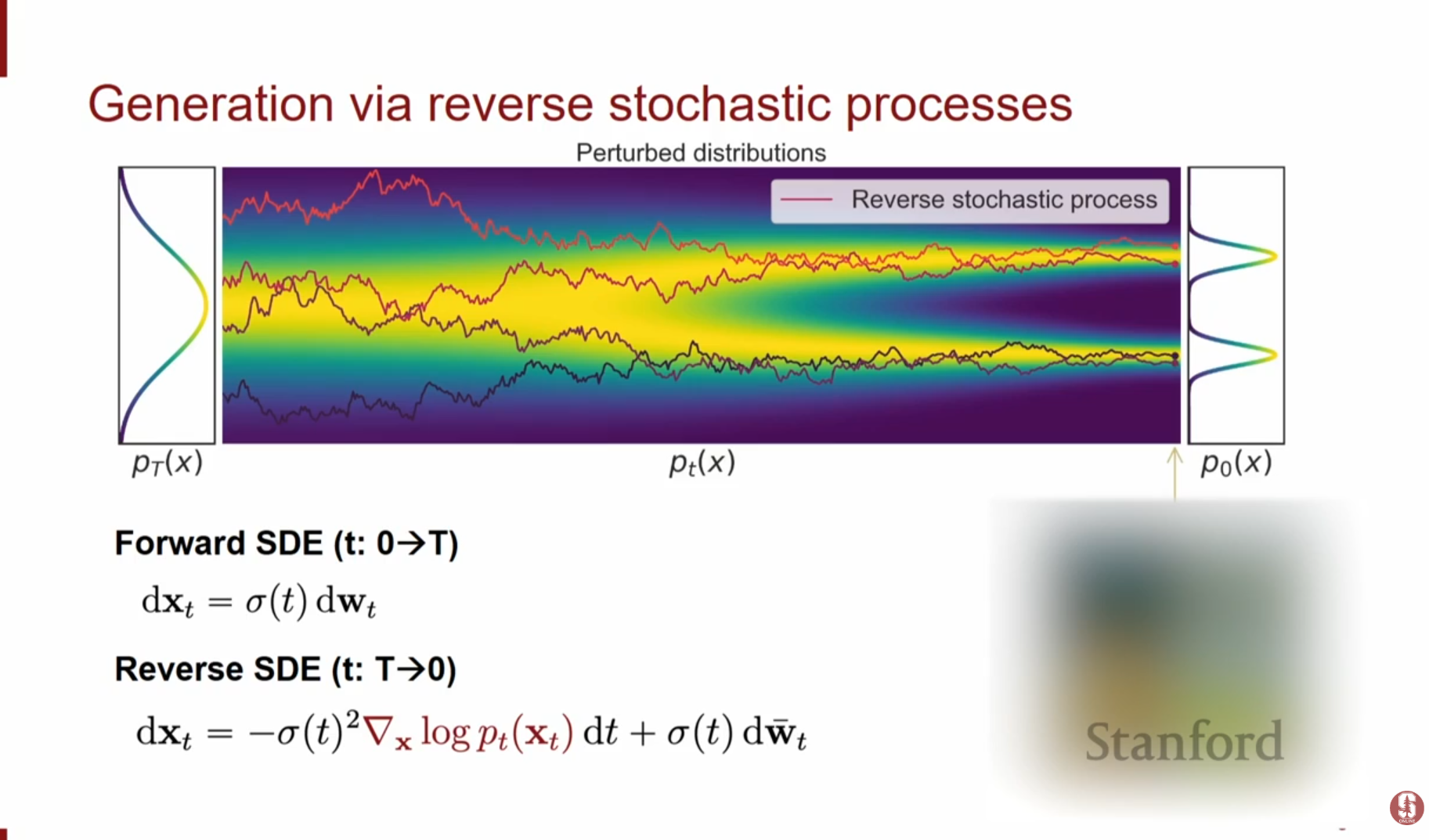
강의 초반부에서는 지난 시간에 이어 Diffusion Model(DDPM)과 Score-based Model 간의 밀접한 연관성을 다시 한 번 짚어봅니다.DDPM과 VAE의 유사성: DDPM은 데이터를 노이즈로 만드는 인코더(Forward Process)와 노이즈에서
36.[CV] CS236 18강 정리 [Diffusion Models for Discrete Data]

생성 모델링의 목표는 데이터 분포 $P{data}$에서 추출된 데이터셋 $X_1, \\dots, X_n$이 주어졌을 때, 이를 근사하는 파라미터화된 모델 $P\\theta$를 학습하는 것입니다. 모델이 잘 학습된다면, 우리는 새로운 흥미로운 샘플을 생성할 수 있게 됩니