
1. 이미지 분류의 정의와 도전 과제
- 이미지 분류(Image Classification)란? 🖼️
- 컴퓨터 비전의 가장 핵심적인 문제입니다. 주어진 이미지에 대해 미리 정해진 여러 레이블(예: '고양이', '개', '자동차') 중 하나를 정확히 할당하는 작업입니다.
- 컴퓨터가 이미지를 인식하는 방식:
- 컴퓨터에게 이미지는 단순히 거대한 숫자들의 배열, 즉 픽셀(pixel) 값으로 이루어진 행렬(matrix) 또는 텐서(tensor)에 불과합니다.
- 예를 들어, 800x600 해상도의 컬러 이미지는 800 x 600 x 3 (RGB 3개 채널) 크기의 텐서로 표현됩니다.

- 이미지 분류의 어려움 (Semantic Gap):
- 인간에게는 쉬운 일이지만, 컴퓨터에게는 다음과 같은 다양한 변수 때문에 매우 어려운 문제입니다. 이를 '의미론적 차이(Semantic Gap)'라고 부릅니다.
- 시점 변화 (Viewpoint variation): 카메라의 각도가 조금만 바뀌어도 모든 픽셀값이 변해 컴퓨터는 완전히 다른 이미지로 인식합니다.

- 조명 변화 (Illumination): 같은 물체라도 조명 조건에 따라 픽셀값이 크게 달라집니다.

- 배경 혼잡 (Background clutter): 인식하려는 물체가 배경과 비슷하여 구분이 어려울 수 있습니다.
- 크기 변화 (Scale variation): 이미지 속 물체의 크기가 다양하게 나타날 수 있습니다.
- 가려짐 (Occlusion): 물체의 일부가 다른 물체에 의해 가려진 경우입니다.
- 변형 (Deformation): 고양이처럼 형태가 고정되지 않고 다양하게 변형될 수 있는 물체는 인식하기 어렵습니다.

- 클래스 내 변형 (Intra-class variation): '고양이'라는 하나의 클래스 안에도 매우 다양한 종류, 색상, 형태의 고양이가 존재합니다.


- 시점 변화 (Viewpoint variation): 카메라의 각도가 조금만 바뀌어도 모든 픽셀값이 변해 컴퓨터는 완전히 다른 이미지로 인식합니다.
- 인간에게는 쉬운 일이지만, 컴퓨터에게는 다음과 같은 다양한 변수 때문에 매우 어려운 문제입니다. 이를 '의미론적 차이(Semantic Gap)'라고 부릅니다.
2. 데이터 기반 접근법과 K-최근접 이웃 (KNN)
-
데이터 기반 접근법 (Data-Driven Approach):
- 과거에는 사람이 직접 규칙(예: '고양이 귀는 뾰족하다')을 코드로 짜서 이미지를 분류하려 했지만, 이는 확장성이 매우 떨어집니다.
- 현대의 머신러닝은 데이터 기반 접근법을 사용하며, 다음 3단계로 이루어집니다.
- 데이터셋 수집: 이미지와 해당 이미지의 정답 레이블을 수집합니다.
- 분류기 학습: 수집한 데이터를 이용해 머신러닝 알고리즘으로 모델(분류기)을 학습시킵니다.
- 평가: 학습에 사용되지 않은 새로운 이미지로 모델의 성능을 평가합니다.

-
K-최근접 이웃 (K-Nearest Neighbor, KNN) 분류기:
- 가장 간단한 분류기 중 하나로, 데이터 기반 접근법의 핵심 개념을 이해하는 데 도움이 됩니다.

- 학습 (
train): 모든 학습 데이터를 그저 메모리에 저장합니다. 계산이 필요 없어 매우 빠릅니다. - 예측 (
predict): 새로운 (테스트) 이미지가 들어오면, 저장된 모든 학습 이미지와의 거리를 계산하여 가장 가까운 이미지를 찾고, 그 이미지의 레이블을 정답으로 예측합니다. 이 과정은 모든 데이터와 거리를 비교해야 하므로 느립니다.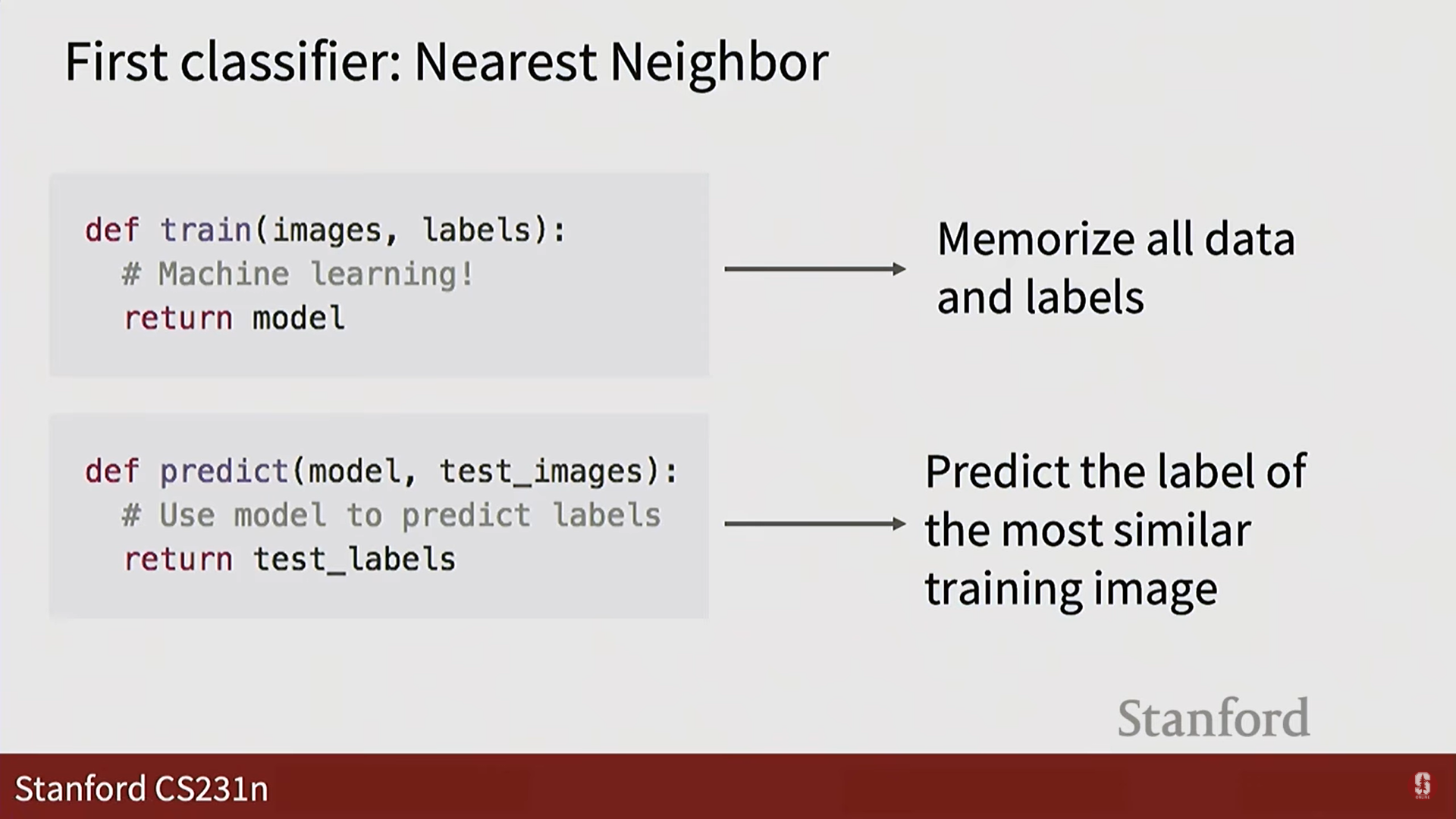



- 가장 간단한 분류기 중 하나로, 데이터 기반 접근법의 핵심 개념을 이해하는 데 도움이 됩니다.
-
거리 측정 방식:
- L1 거리 (맨해튼 거리): 각 픽셀값 차이의 절댓값을 모두 더한 값입니다. 좌표축에 민감하게 반응합니다.
- L2 거리 (유클리드 거리): 각 픽셀값 차이를 제곱하여 모두 더한 후 제곱근을 씌운 값입니다. 우리가 흔히 아는 두 점 사이의 직선 거리입니다.


-
K값의 의미와 하이퍼파라미터 튜닝:
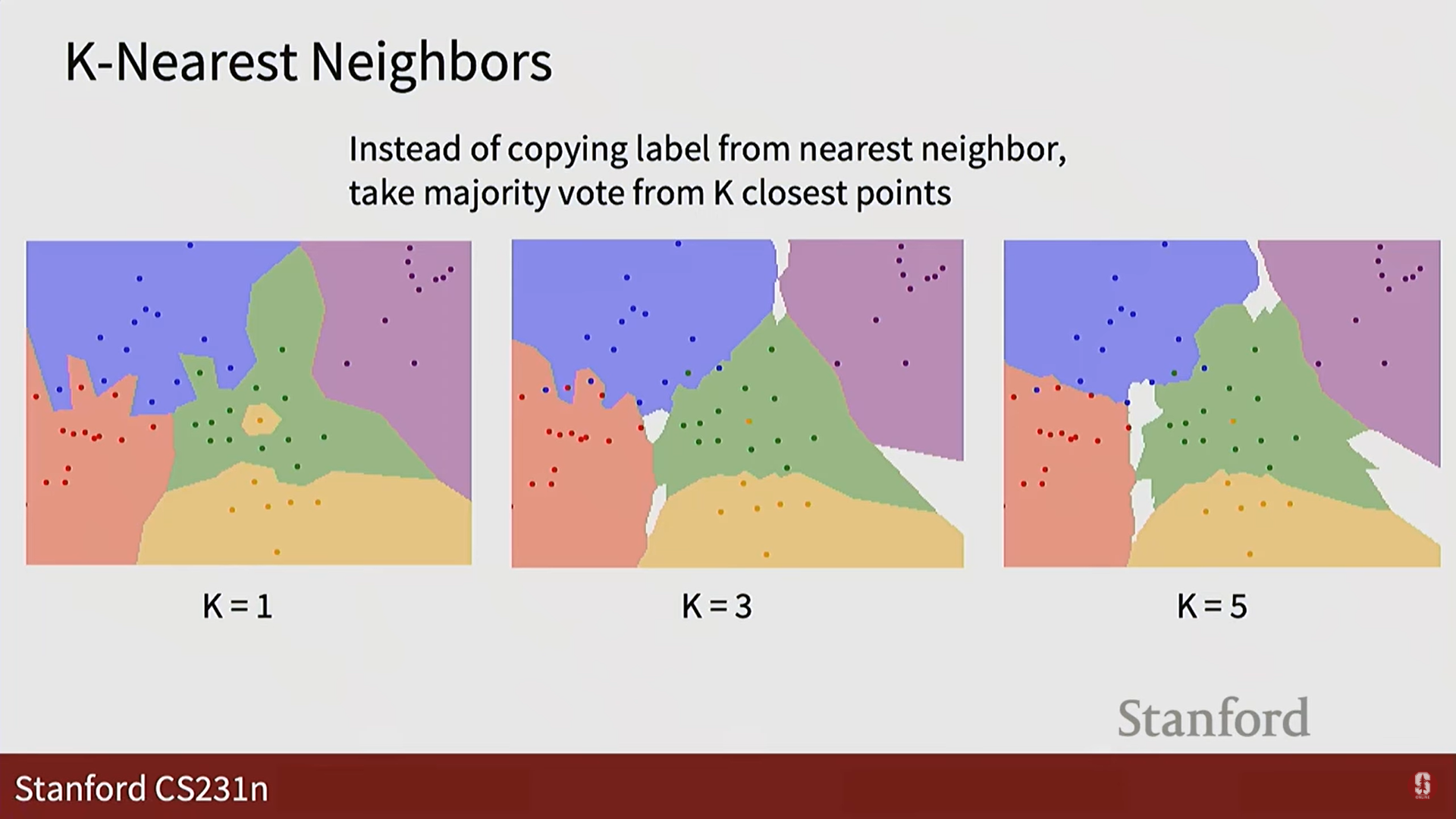
- K: 예측 시 가장 가까운 1개의 이웃만 보는 대신, K개의 가까운 이웃을 보고 다수결 투표를 통해 레이블을 결정하는 방식입니다. 이를 통해 좀 더 안정적인 예측이 가능합니다.
- 하이퍼파라미터(Hyperparameter): K값이나 거리 측정 방식처럼, 알고리즘이 학습을 시작하기 전에 사람이 미리 정해야 하는 값들을 말합니다.
- 최적의 하이퍼파라미터 찾기:
- 나쁜 방법: 학습 데이터나 테스트 데이터에 맞춰 하이퍼파라미터를 정하는 것은 과적합(overfitting)을 유발하거나, 미래 성능을 보장할 수 없는 '속임수'와 같습니다.
- 좋은 방법 (검증 세트): 학습 데이터를 다시 학습 세트(training set)와 검증 세트(validation set)로 나눕니다. 학습 세트로 모델을 훈련시키고, 검증 세트로 여러 하이퍼파라미터 조합의 성능을 평가하여 최적의 조합을 찾습니다.
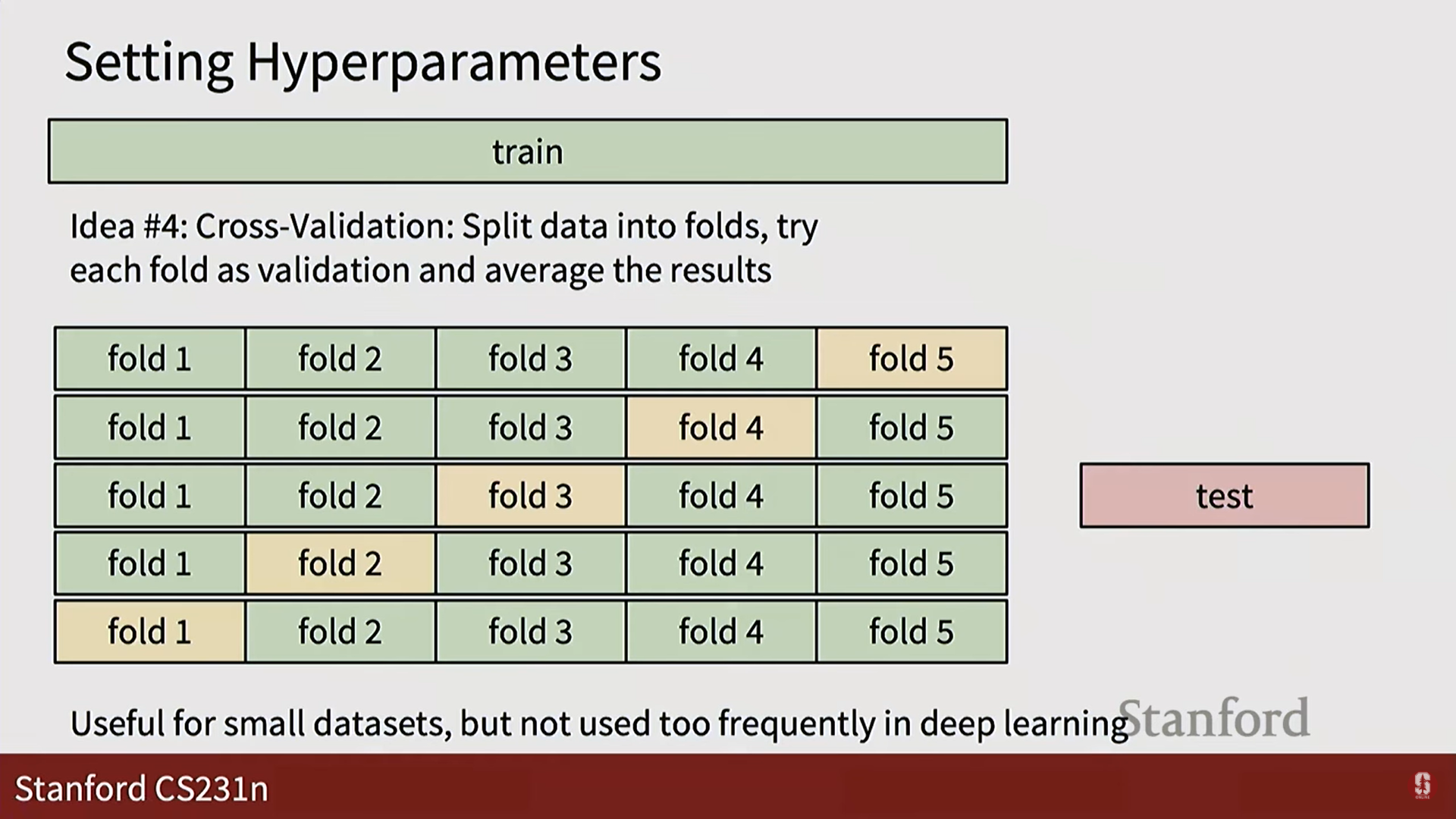
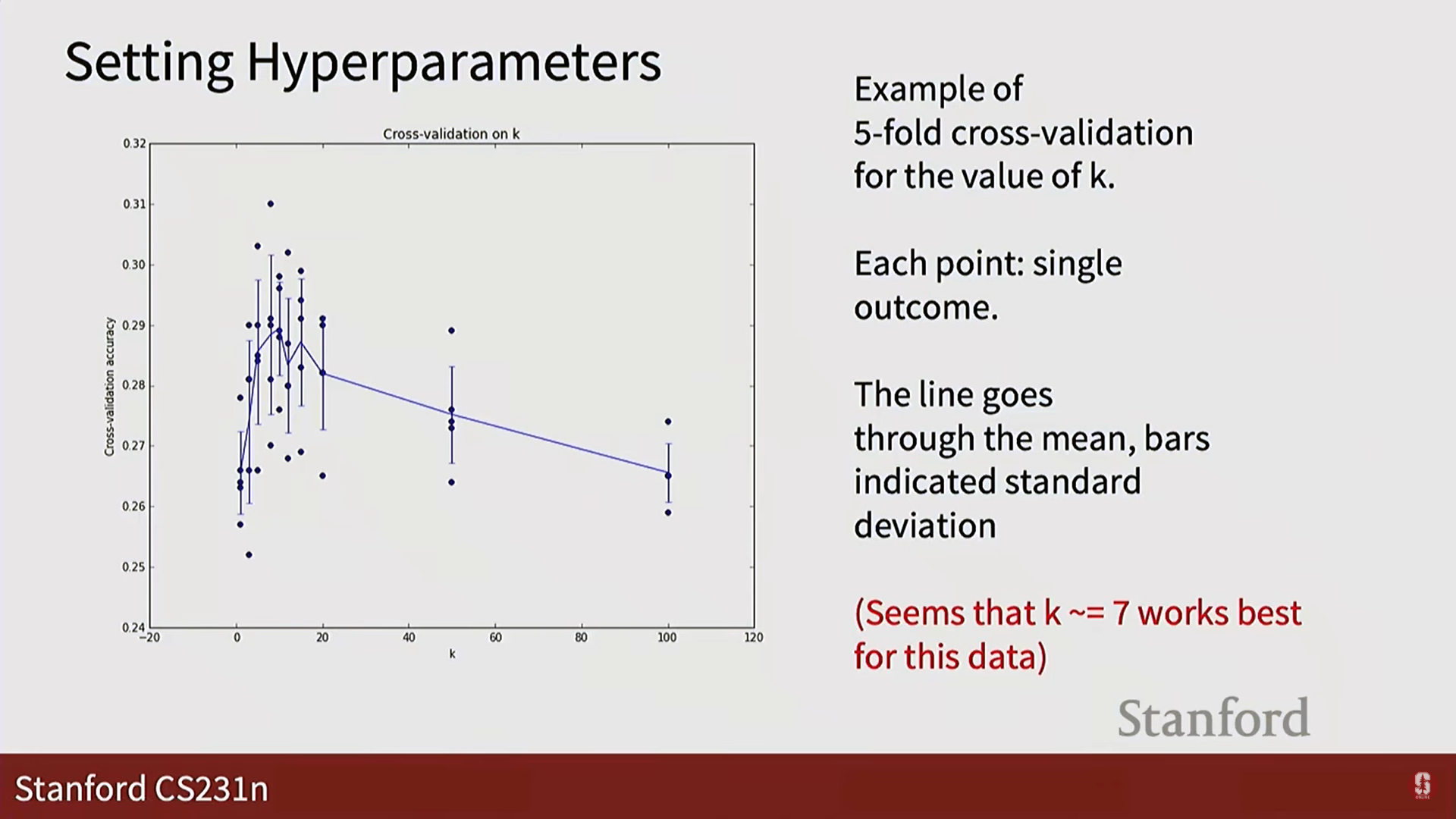
- 가장 좋은 방법 (교차 검증): 데이터를 여러 개(fold)로 나누고, 각 fold가 한 번씩 검증 세트가 되도록 반복하여 성능을 평균냅니다. 더 신뢰도가 높지만 계산 비용이 많이 듭니다.


3. 선형 분류기 (Linear Classifier)
- KNN의 한계: 픽셀 간의 거리(L1, L2)는 이미지의 의미론적 유사성을 잘 반영하지 못합니다. (예: 이미지를 한 픽셀만 옆으로 옮겨도 L2 거리는 매우 커질 수 있습니다.)

- 파라미터 기반 접근법: KNN과 달리, 선형 분류기는 데이터로부터 파라미터(가중치 W, 편향 b)를 학습하여 이미지를 클래스 점수로 변환하는 함수를 만듭니다. 이는 신경망의 가장 기본적인 구성 요소입니다.

- 선형 함수의 정의:
- f(x, W, b) = Wx + b
- x: 입력 이미지 픽셀값을 일렬로 펼친 벡터 (예: 32x32x3 이미지 → 3072x1 벡터)
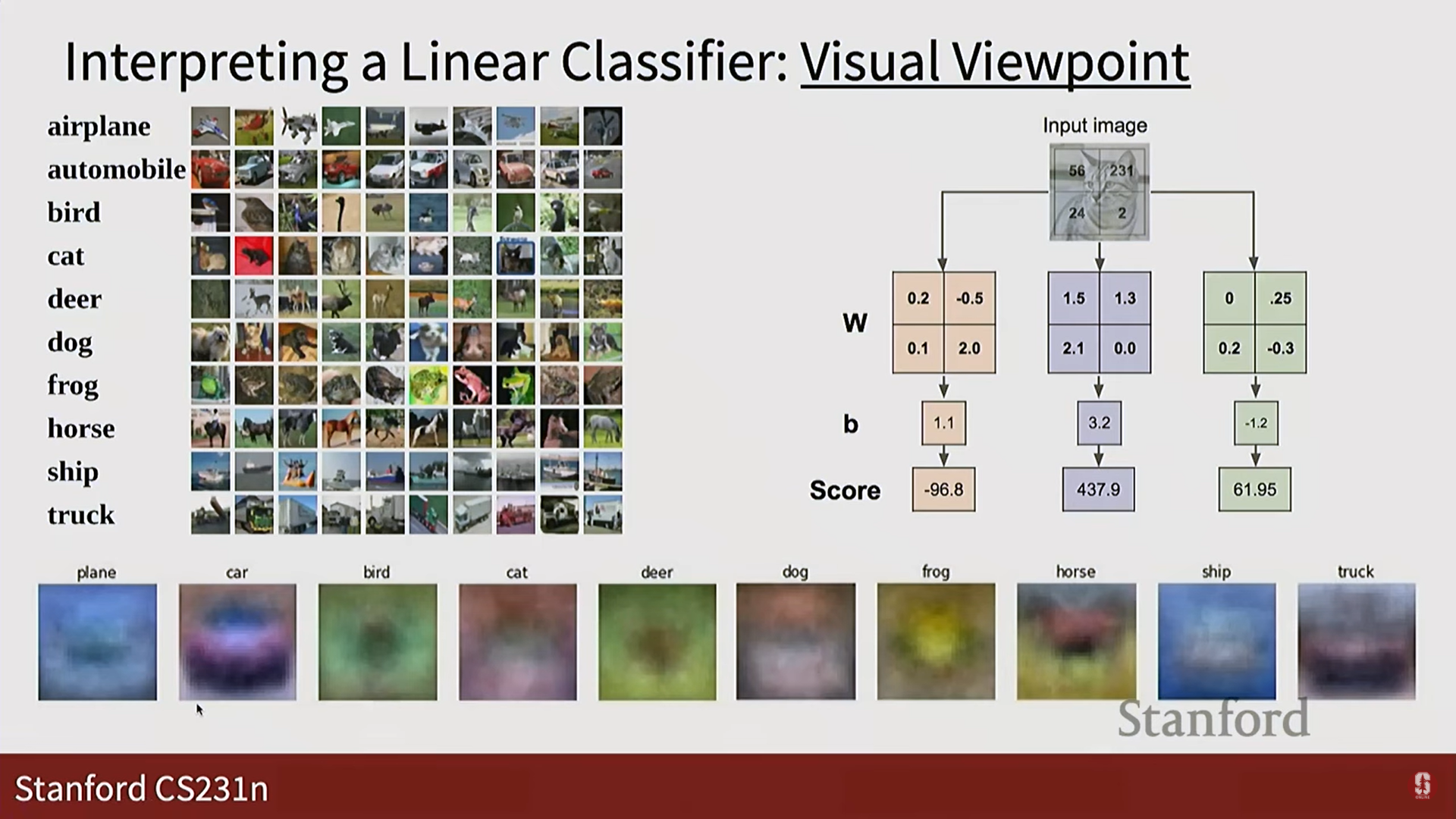
- W: 학습을 통해 찾아야 할 가중치(weights) 행렬. 각 클래스에 대한 '템플릿' 역할을 합니다.
- b: 편향(bias) 벡터. 결정 경계를 유연하게 이동시키는 역할을 합니다.


- f(x, W, b) = Wx + b
- 선형 분류기의 한계:
- 이름 그대로 선형적으로 분리 가능한 데이터에만 작동합니다. XOR 문제나, 데이터가 여러 그룹으로 흩어져 있는 경우에는 클래스를 제대로 구분할 수 없습니다.
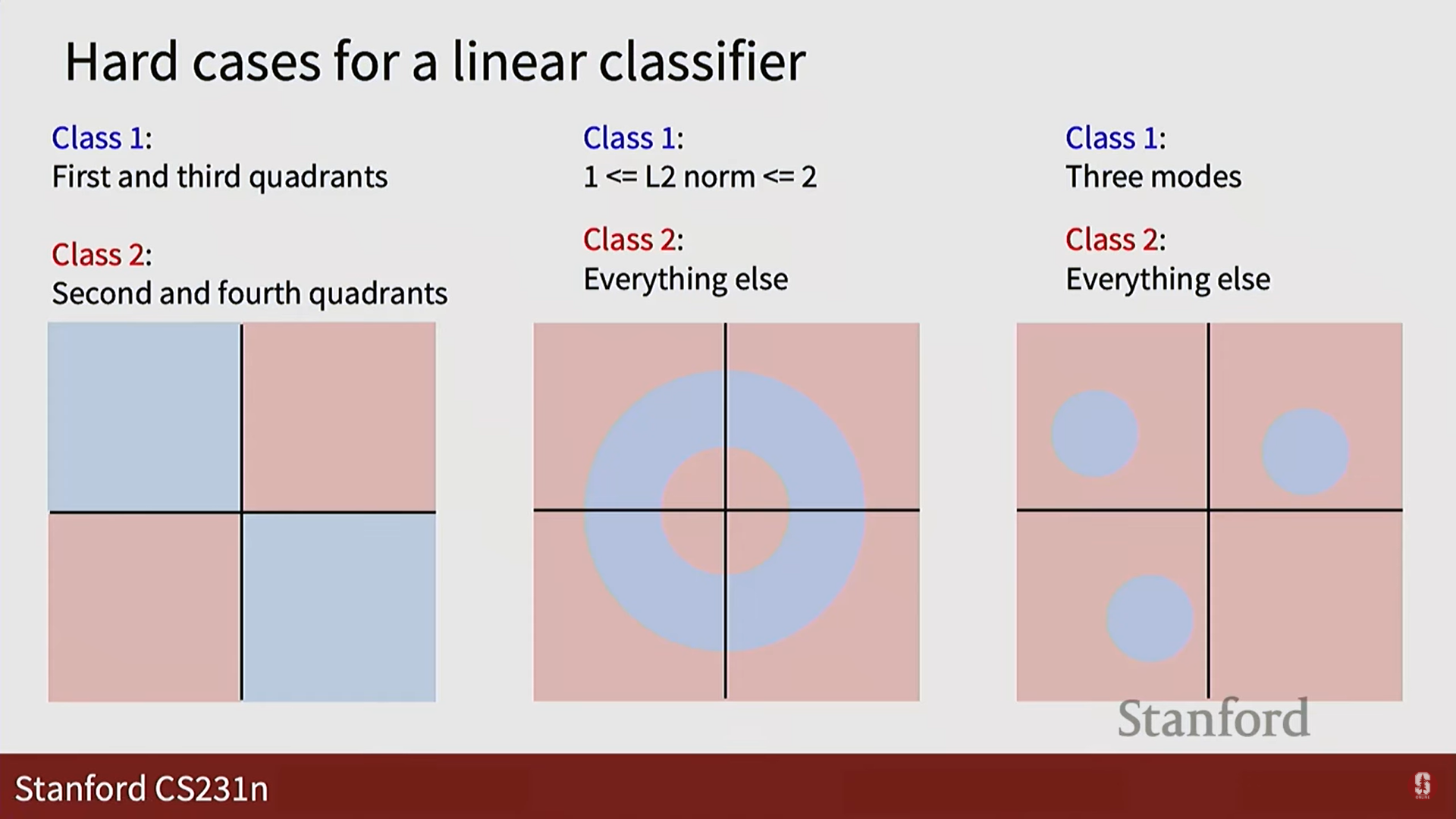
- 이름 그대로 선형적으로 분리 가능한 데이터에만 작동합니다. XOR 문제나, 데이터가 여러 그룹으로 흩어져 있는 경우에는 클래스를 제대로 구분할 수 없습니다.
4. 손실 함수와 최적화

- 손실 함수 (Loss Function)의 역할:
- 현재 모델(파라미터 W)이 얼마나 나쁜지를 정량적으로 측정하는 함수입니다. "불행의 정도"라고 비유할 수 있습니다. 손실 값이 높으면 모델이 나쁘다는 뜻이고, 0에 가까우면 좋다는 뜻입니다.
- 우리의 목표는 이 손실 함수 값을 최소화하는 최적의 W를 찾는 것입니다.

- 소프트맥스 분류기 (Softmax Classifier):
- 선형 분류기가 출력한 원시 점수(score)를 각 클래스에 대한 확률로 변환해주는 역할을 합니다.
- 점수 → 확률 변환 과정:
- 점수에 지수(exponential)를 취해 모든 값을 양수로 만듭니다. (
exp(s)) - 이 값들을 모두 더한 총합으로 각각을 나누어 정규화(normalize)합니다. 이렇게 하면 모든 확률의 합이 1이 됩니다.

- 점수에 지수(exponential)를 취해 모든 값을 양수로 만듭니다. (
- 손실 값 계산 (교차 엔트로피 손실):
- 소프트맥스가 계산한 확률 분포와, 실제 정답의 확률 분포(정답 레이블만 1이고 나머지는 0) 사이의 차이를 측정합니다.
- 실제로는 정답 클래스에 해당하는 확률값에 음의 로그(-log)를 취하는 간단한 형태로 계산됩니다. (
L = -log(정답 클래스의 확률))- 정답 확률이 1에 가까우면 손실은 0에 가까워집니다. (매우 만족)
- 정답 확률이 0에 가까우면 손실은 무한대에 가까워집니다. (매우 불행)


- 최적화 (Optimization):
- 손실 함수라는 '산'에서 가장 낮은 지점(최소값)을 찾아 내려가는 과정입니다.
- 이 과정은 손실 함수의 기울기(gradient)를 계산하여 W를 점진적으로 업데이트하는 방식으로 이루어지며, 경사 하강법(Gradient Descent)과 같은 알고리즘을 사용합니다. (자세한 내용은 다음 강의에서 다룹니다.)
5. 심화 내용: 손실 함수와 최적화의 중요성
- 기술적 배경: 손실 함수는 모델 학습의 '나침반' 역할을 합니다. 어떤 손실 함수를 선택하느냐에 따라 모델의 학습 방향과 최종 성능이 결정됩니다. 교차 엔트로피 손실은 분류 문제에서 모델의 예측 확률 분포와 실제 분포 사이의 정보량 차이를 측정하는 가장 표준적이고 효과적인 방법으로, 정보 이론의 쿨백-라이블러 발산(KL-Divergence) 개념에서 파생되었습니다.
- 최신 동향: 최근에는 단순히 정답을 맞히는 것을 넘어, 모델이 더 강건하고(robust) 일반화 성능이 좋도록 만들기 위해 다양한 정규화(regularization) 항을 손실 함수에 추가하거나, 레이블이 없는 데이터에서도 학습이 가능하도록 하는 대조 학습(Contrastive Learning)과 같은 새로운 형태의 손실 함수들이 활발히 연구되고 있습니다.
- 명확한 한계점: 손실 함수는 미분 가능해야만 경사 하강법과 같은 최적화 알고리즘을 적용할 수 있습니다. 또한, 손실 함수의 표면은 매우 복잡하여 수많은 지역 최솟값(local minima)에 빠질 위험이 있습니다. 최적화 알고리즘은 가장 낮은 지점인 전역 최솟값(global minimum)을 찾는 것을 보장하지 않으며, 단지 현재 위치에서 가장 가파른 경사를 따라 내려갈 뿐입니다. 이 문제를 해결하기 위해 Adam, RMSProp과 같은 진보된 최적화 기법들이 개발되었습니다.

AI 공부합니다