1. 딥러닝 학습 과정 복습
- 딥러닝 레시피: 딥러닝은 어떤 문제든 5단계로 해결할 수 있습니다.
- 텐서(Tensor)로 문제 정의하기: 입출력을 숫자의 배열(텐서)로 표현합니다.
- 아키텍처 설계: 계산 그래프를 이용해 입력을 출력으로 바꾸는 신경망 구조를 만듭니다.
- 데이터셋 수집: 수많은 입출력(정답) 쌍을 모읍니다.
- 손실 함수 정의: 모델의 예측이 얼마나 틀렸는지 측정하는 방법을 정합니다.
- 최적화: 역전파(Backpropagation)로 기울기를 계산하고, 경사 하강법(Gradient Descent)으로 손실을 줄여나가며 모델을 학습시킵니다.
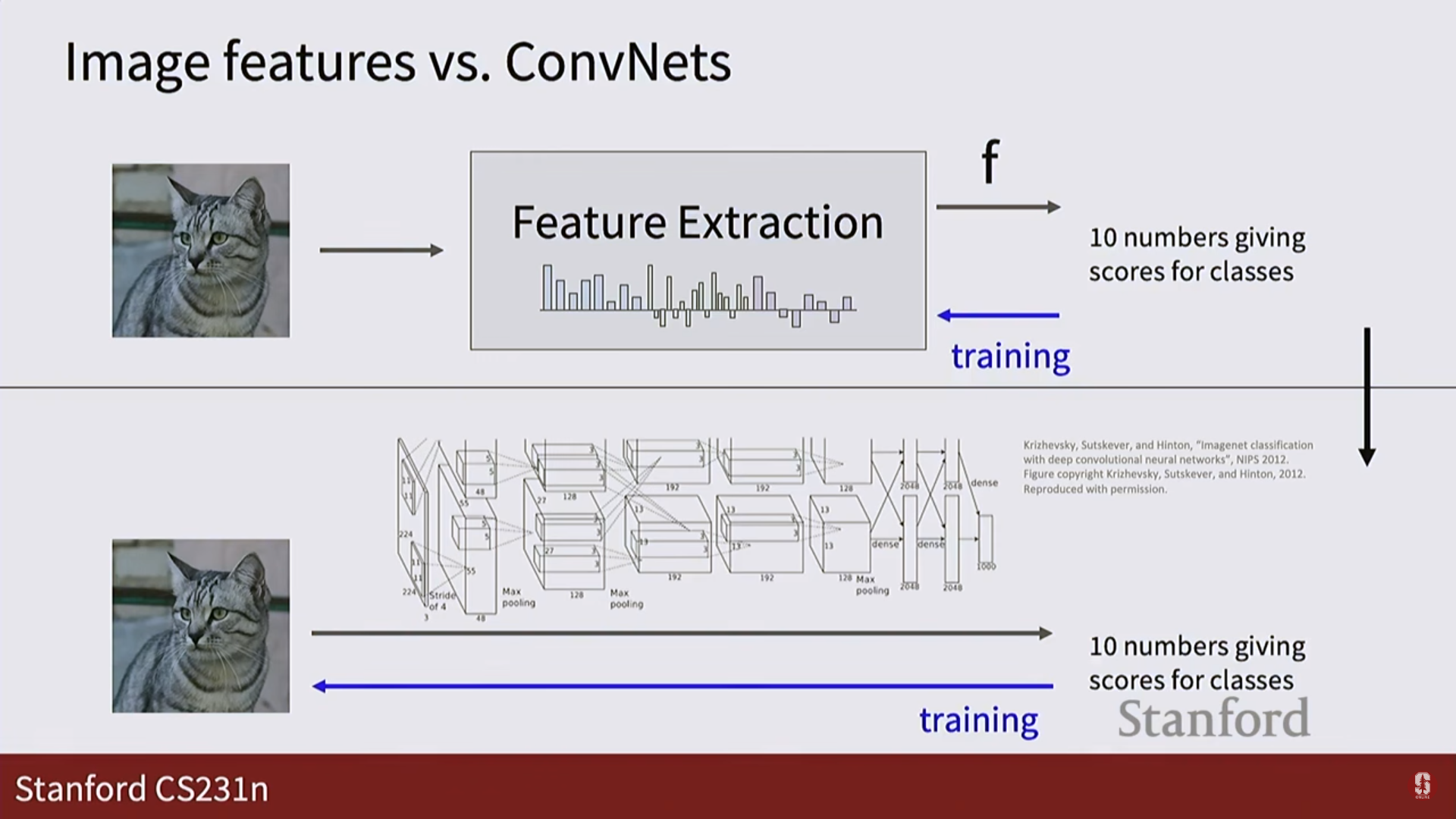
- 선형 분류기의 한계와 신경망:
- 선형 분류기는 각 클래스마다 하나의 템플릿만 학습하기 때문에, 같은 고양이라도 다양한 모습(자세, 색상)을 인식하지 못했습니다.
- 신경망은 여러 계층과 비선형 활성화 함수를 통해 훨씬 더 복잡하고 유연한 표현을 학습할 수 있습니다.
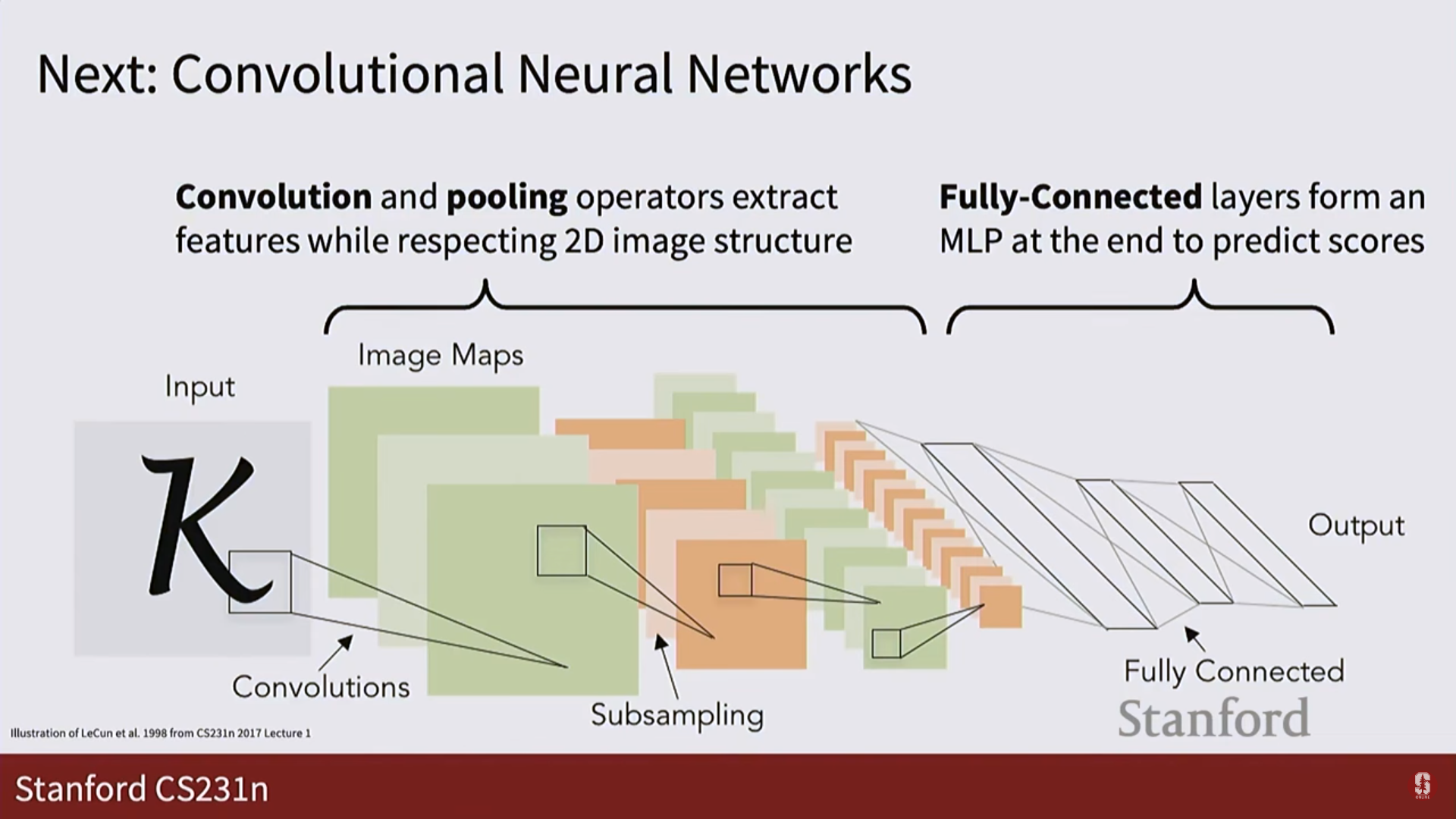
2. CNN: 이미지를 '보는' 신경망
- 완전 연결 신경망(FCN)의 문제점:
- 이미지를 길게 펼친 1차원 벡터로 만들기 때문에, 픽셀 간의 중요한 공간적 구조(spatial structure) 정보가 파괴됩니다.

- 이미지를 길게 펼친 1차원 벡터로 만들기 때문에, 픽셀 간의 중요한 공간적 구조(spatial structure) 정보가 파괴됩니다.
- 합성곱 신경망 (Convolutional Neural Network, CNN):
- 이 문제를 해결하기 위해 등장한, 이미지 처리에 특화된 신경망입니다.
- 핵심 아이디어: 전체 이미지를 한 번에 보는 대신, 작은 필터(filter) 또는 커널(kernel)이 이미지 위를 훑고 지나가면서(sliding window) 특징을 포착합니다.
- CNN의 작동 방식:
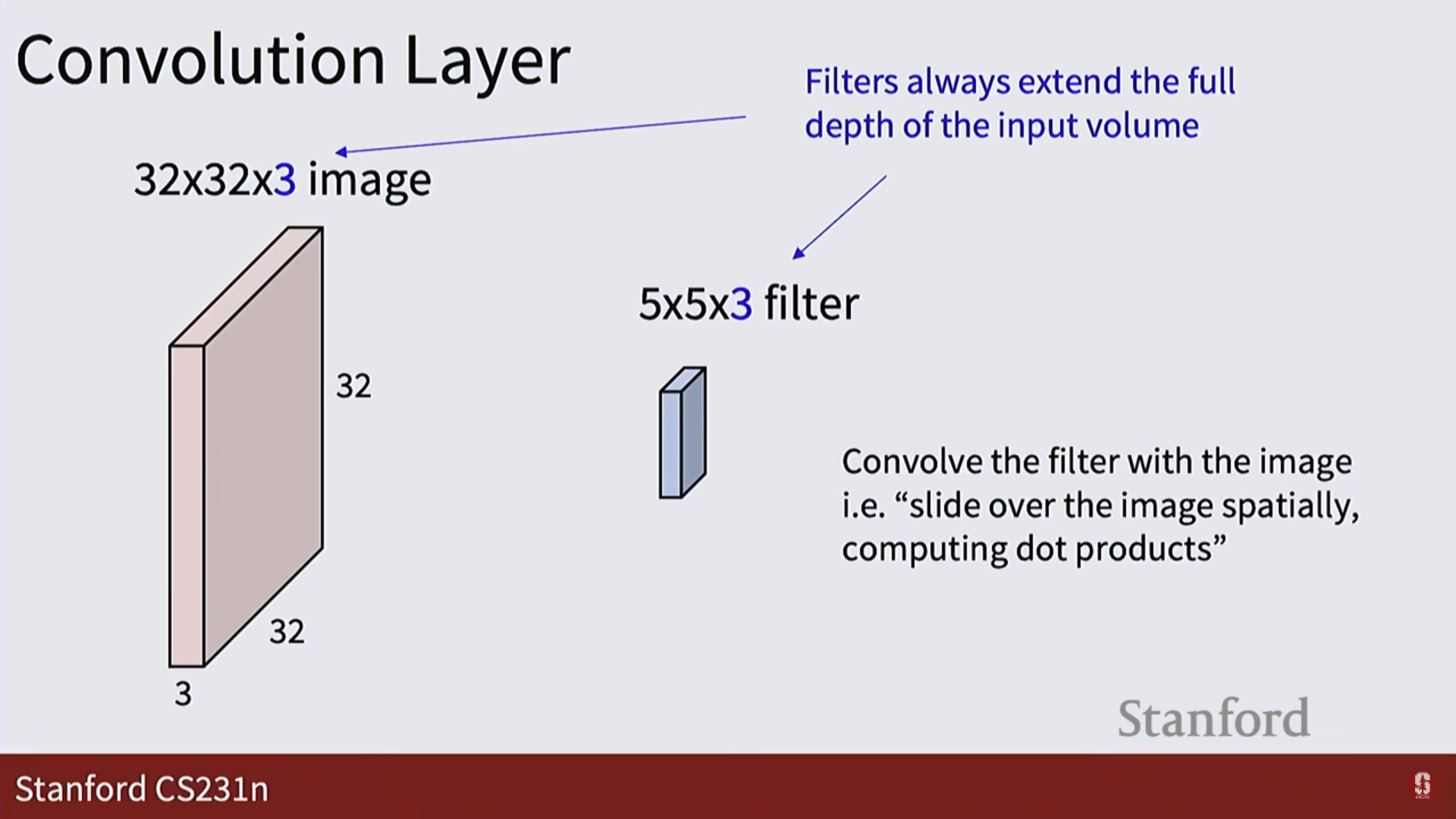
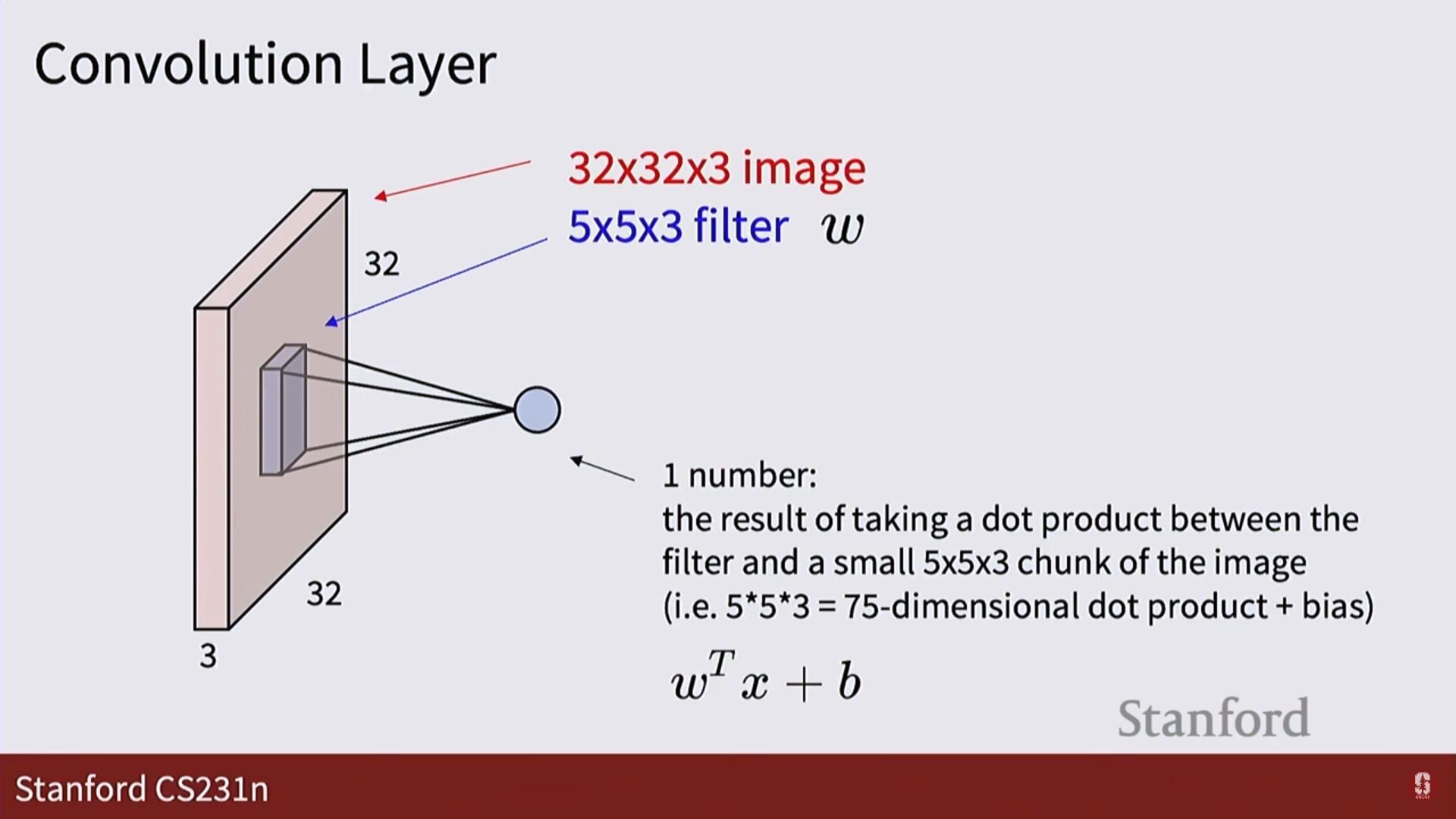
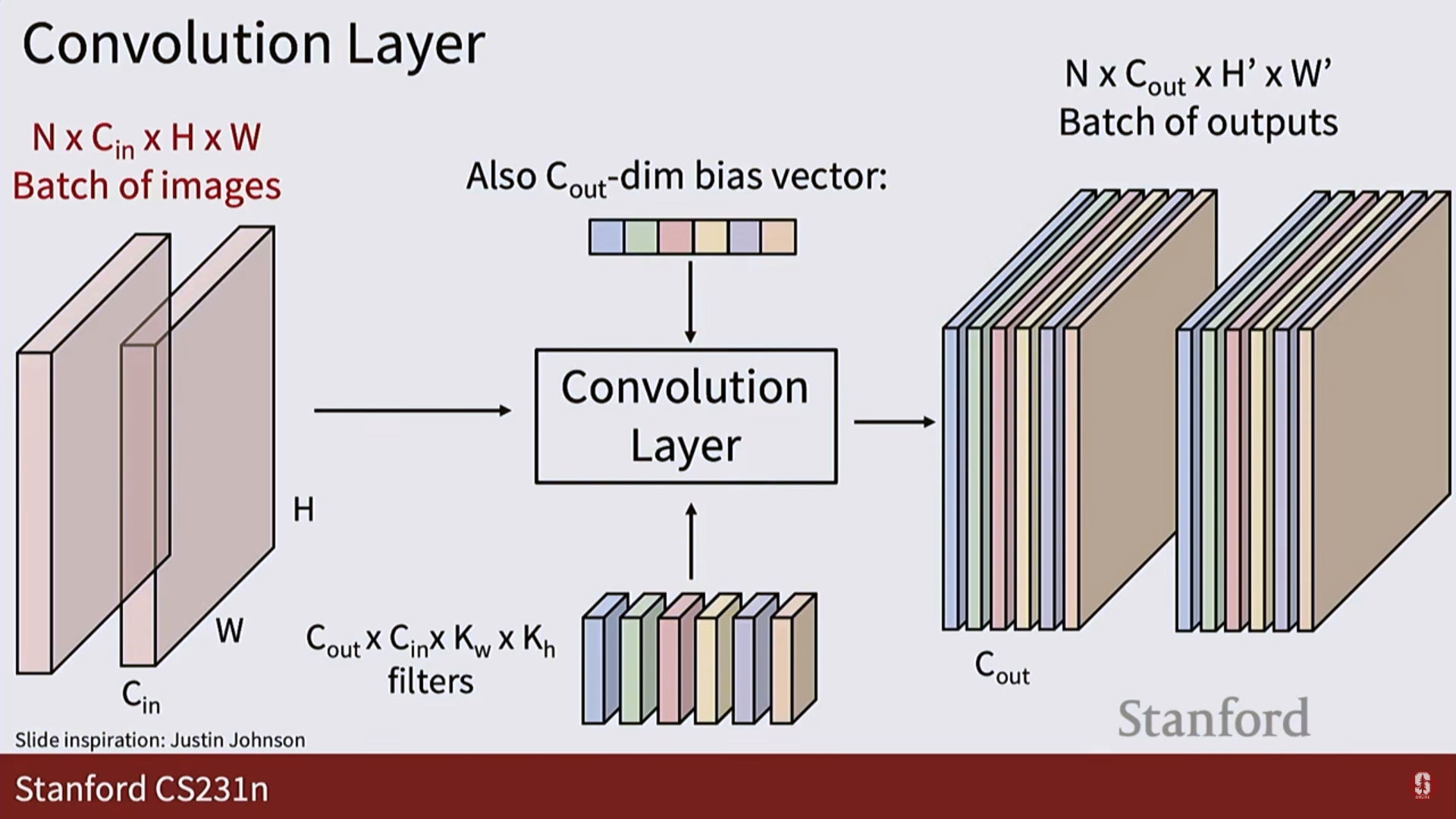
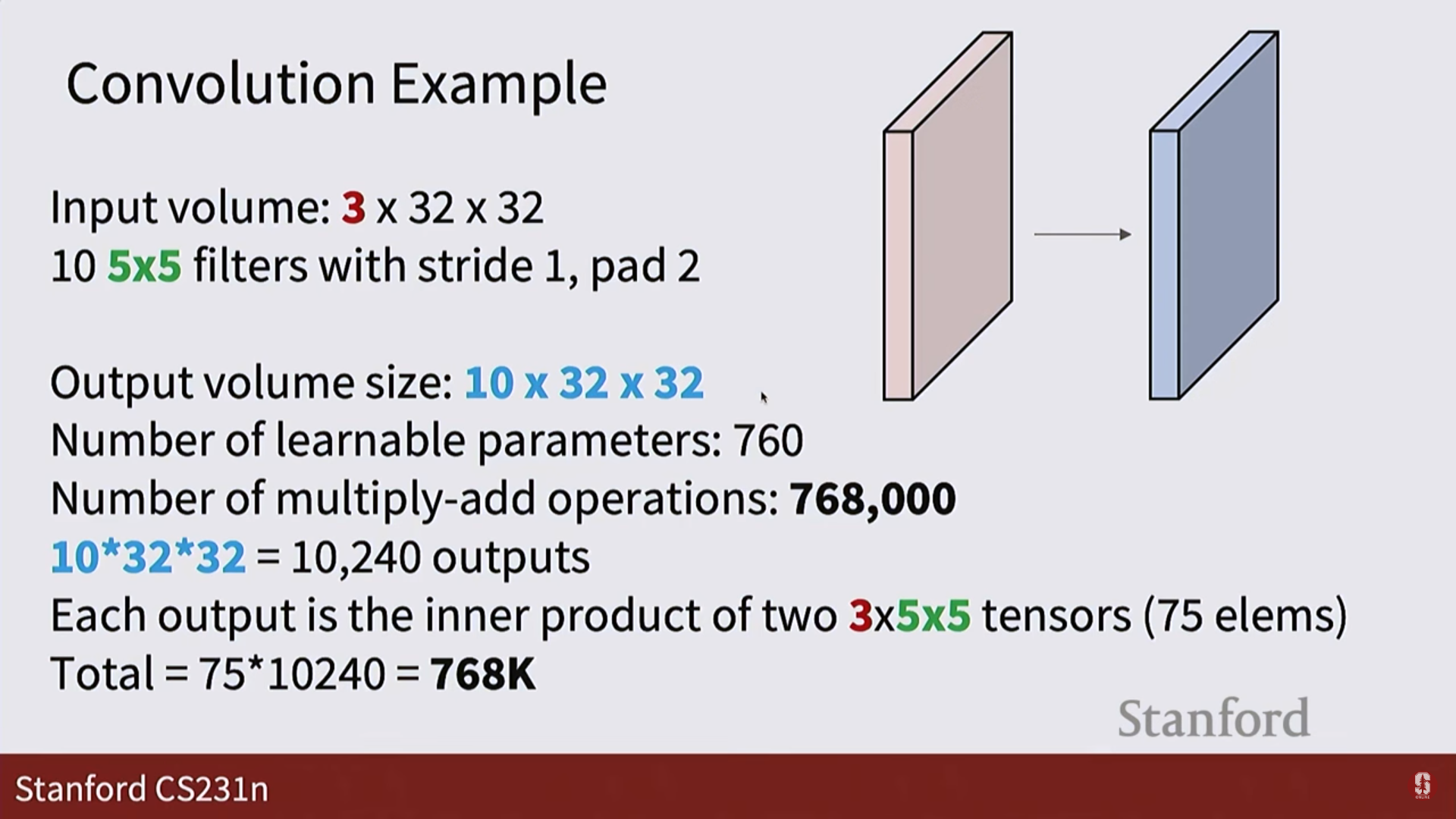
1. 입력: 이미지를 3차원 텐서(높이 x 너비 x 채널) 형태 그대로 받습니다.
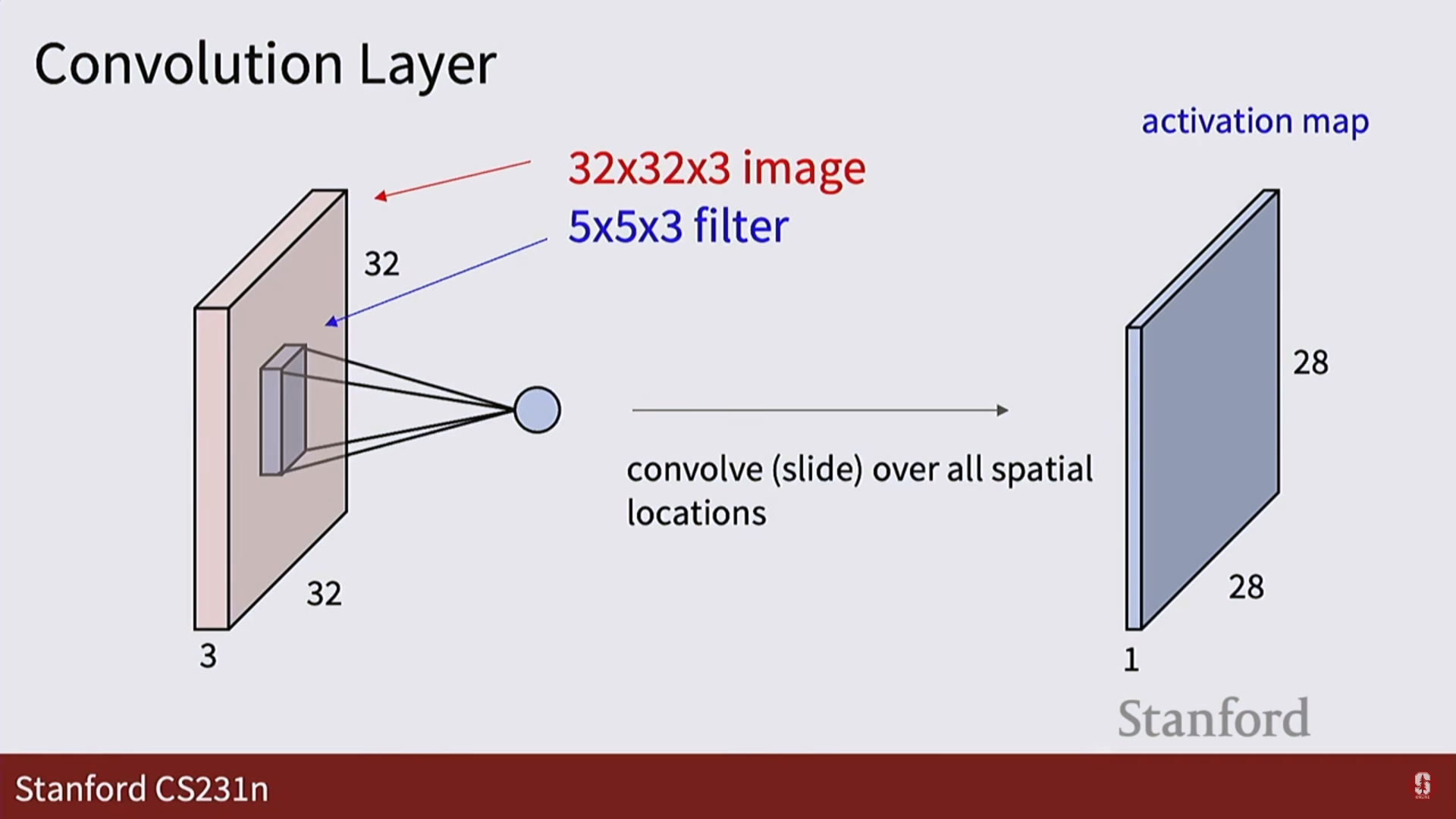
2. 필터: 5x5처럼 작은 크기의 필터가 이미지의 한 부분과 내적(dot product) 연산을 수행합니다. 이는 그 부분과 필터(템플릿)가 얼마나 닮았는지를 측정하는 것과 같습니다.
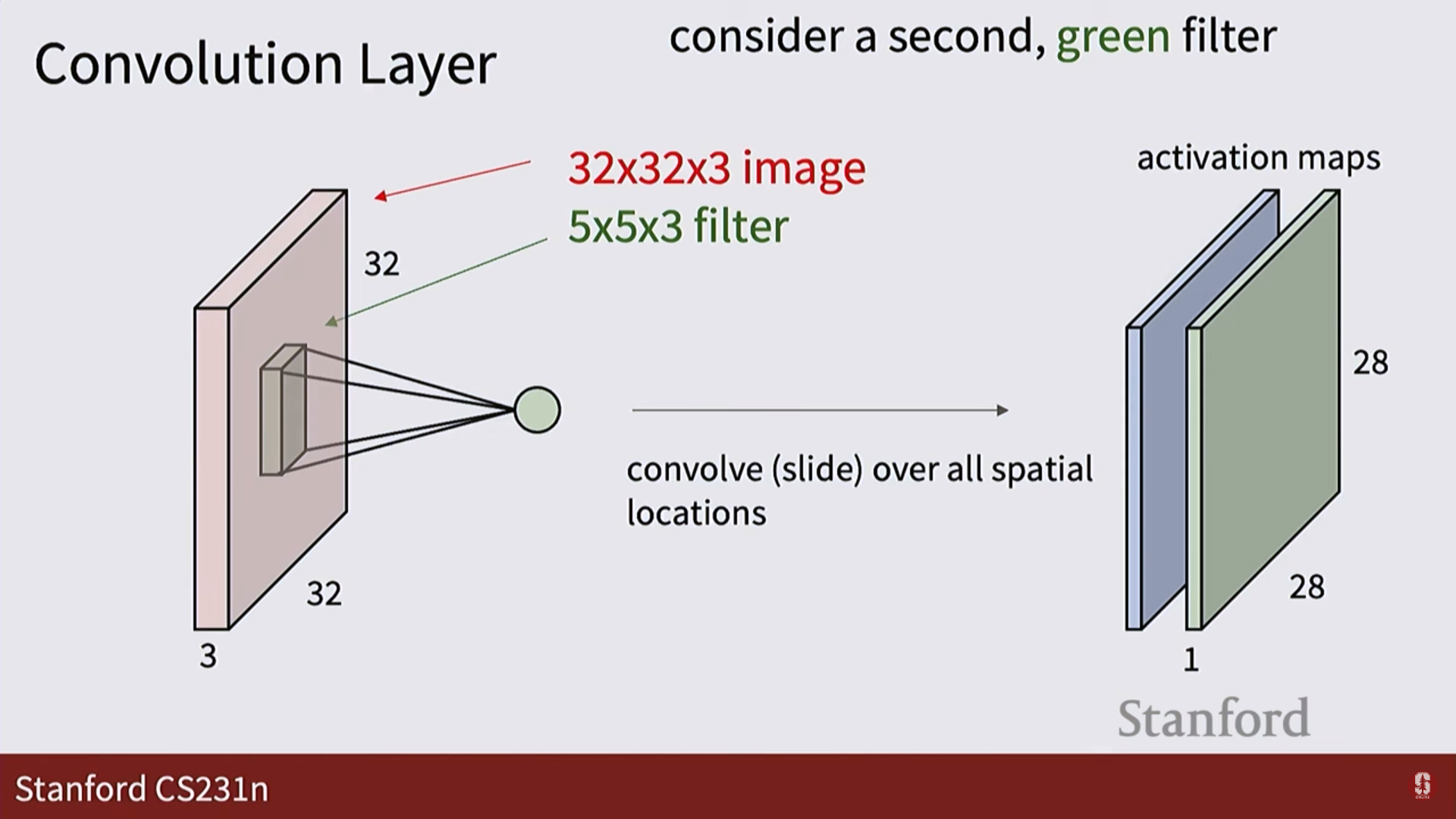
3. 활성화 맵 (Activation Map): 필터가 이미지 전체를 훑고 지나가며 계산한 결과들을 모아놓은 2차원 평면입니다. 특정 필터가 이미지의 어느 위치에서 '활성화'되었는지를 보여줍니다.
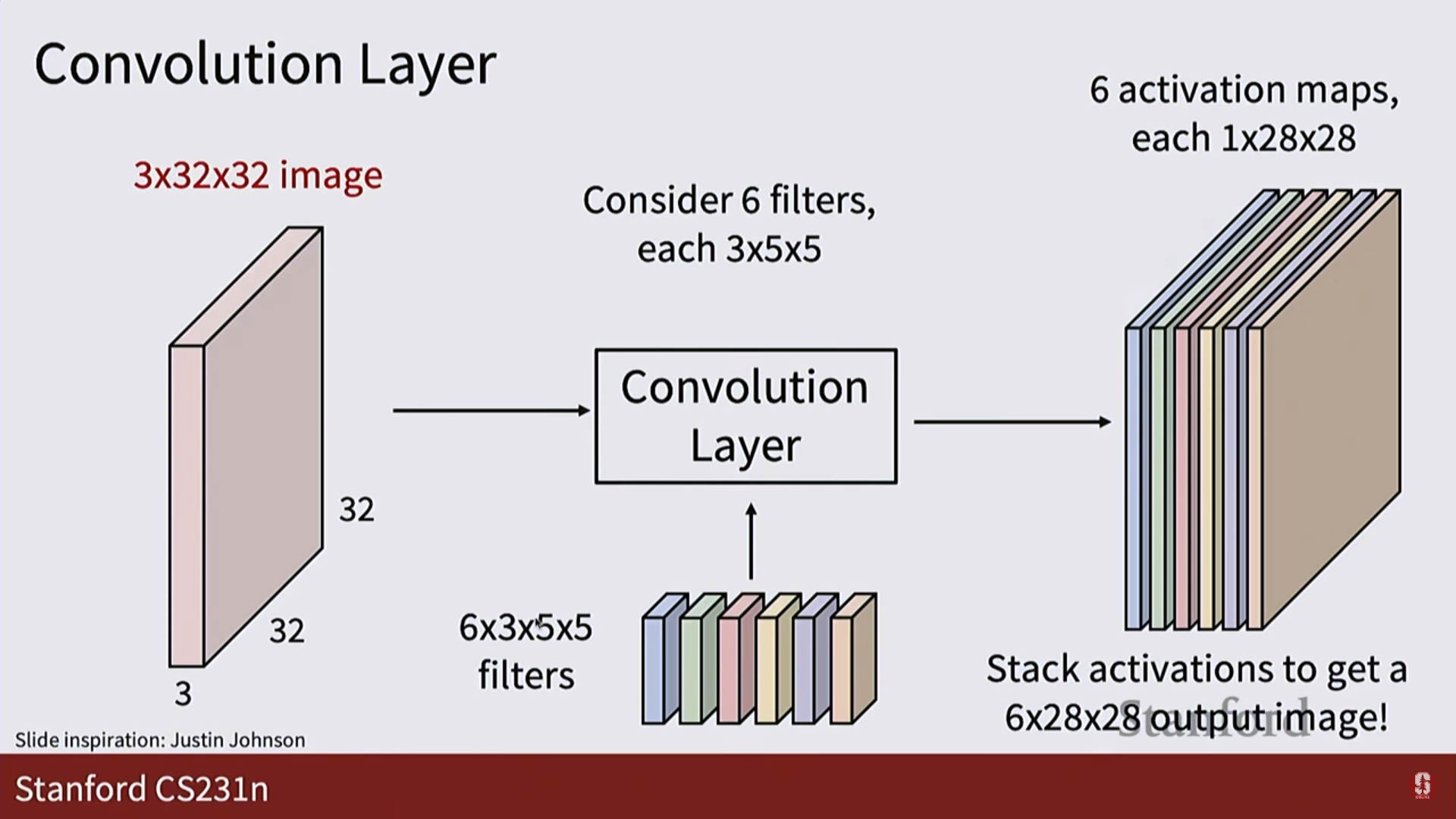
4. 출력: 여러 개의 필터를 사용하면, 그 수만큼의 활성화 맵이 쌓여 새로운 3차원 텐서가 출력됩니다.



3. CNN의 구성 요소와 하이퍼파라미터
-
CNN 아키텍처:
- 일반적으로
[CONV -> RELU -> POOL]과 같은 블록을 여러 겹 쌓아서 이미지의 특징을 추출하고, 마지막에 완전 연결 계층(FCN)을 붙여 최종적으로 이미지를 분류합니다.
- 일반적으로
-
필터 (Filter / Kernel):
- 필터의 값들은 사람이 정하는 게 아니라, 무작위로 초기화된 후 경사 하강법을 통해 데이터로부터 자동으로 학습됩니다.
- 첫 번째 계층의 필터들은 주로 색상 대비나 특정 방향의 엣지(edge)처럼 단순한 특징을 학습하고, 더 깊은 계층으로 갈수록 눈, 텍스트, 원과 같이 더 복잡하고 추상적인 특징을 학습하게 됩니다.

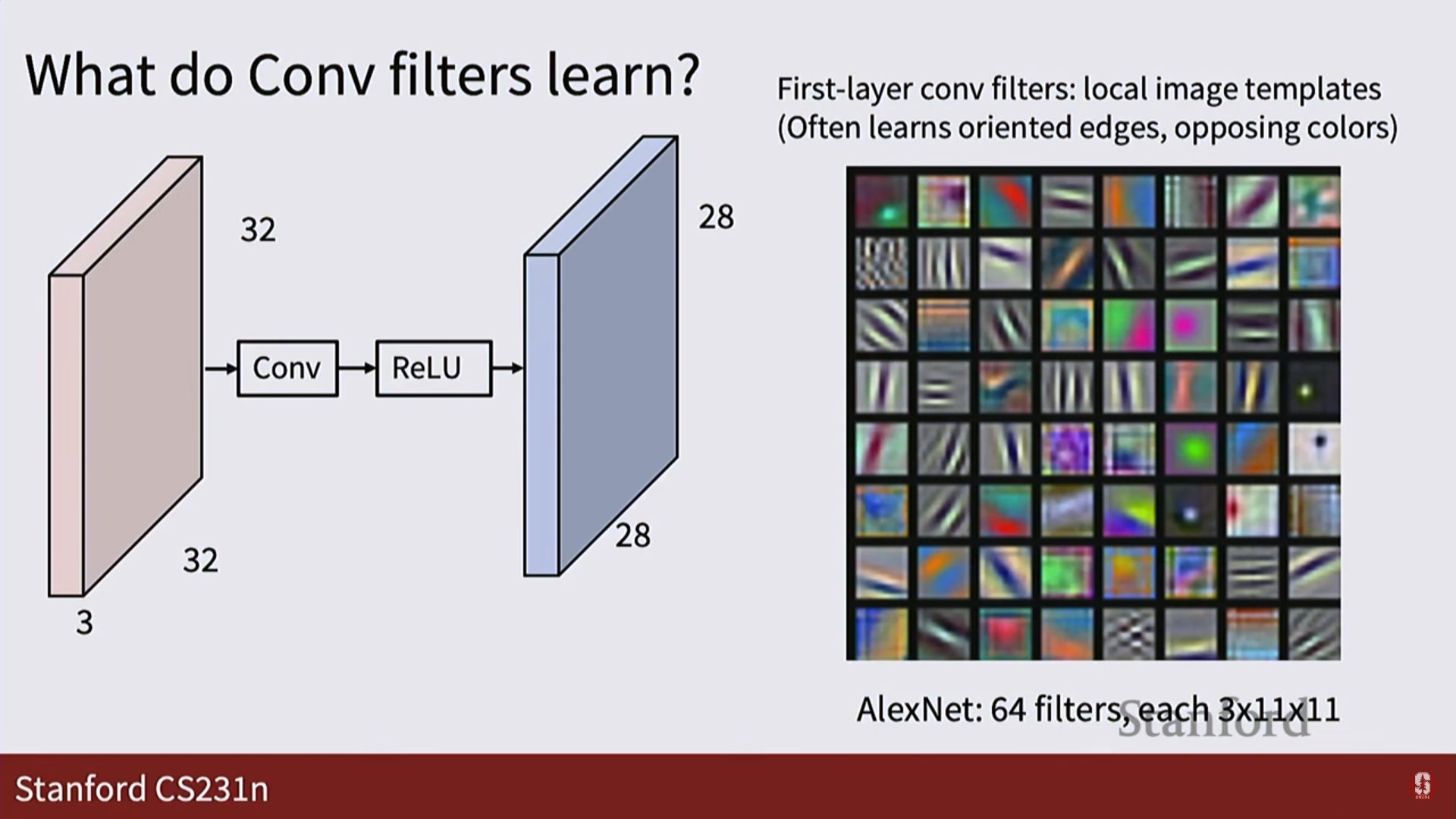
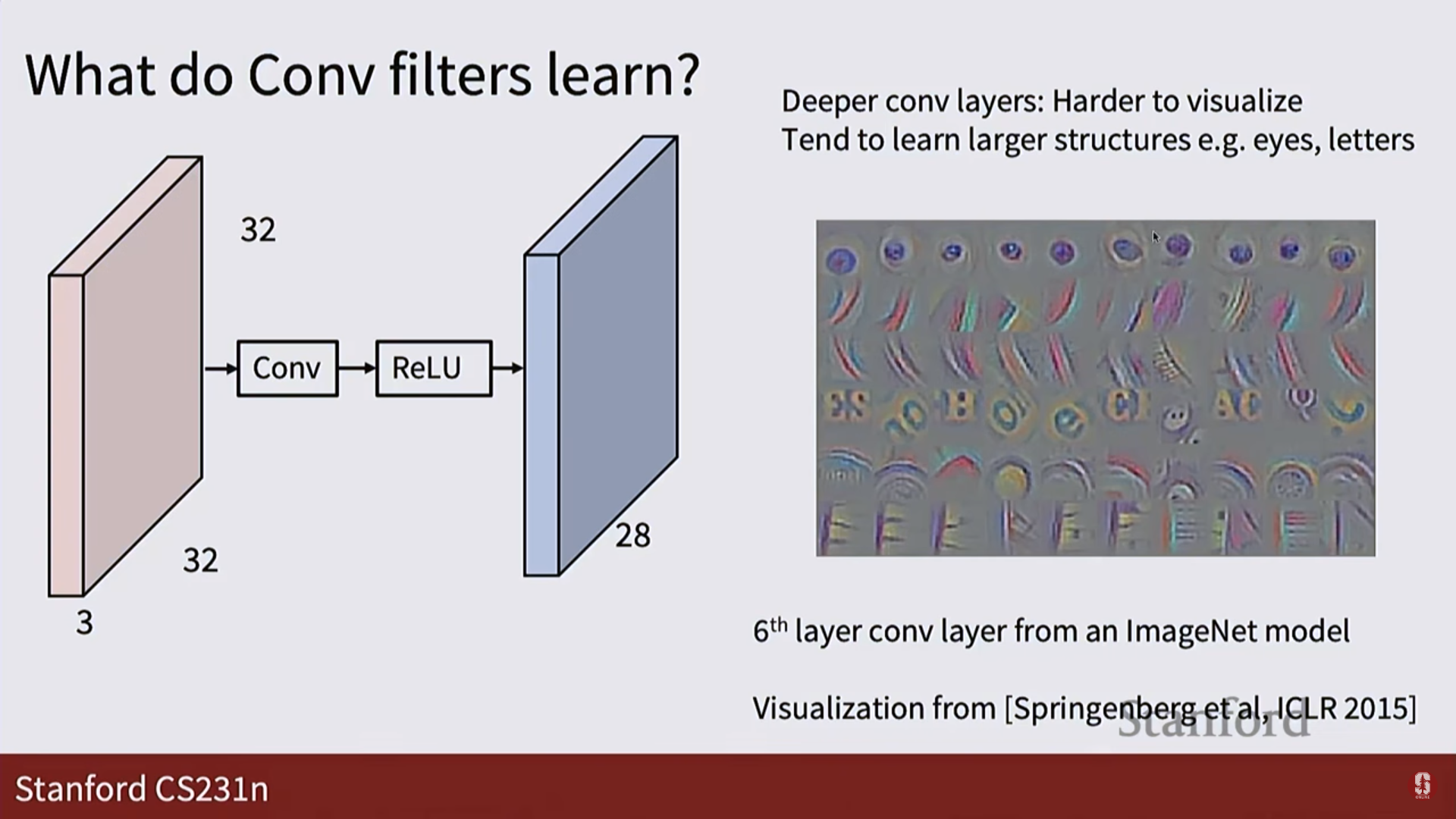
-
스트라이드 (Stride):
- 필터가 몇 칸씩 건너뛰며 움직일지를 정하는 값입니다. 스트라이드가 1보다 크면 출력의 크기가 작아지는 다운샘플링(downsampling) 효과가 있습니다.
-
패딩 (Padding):
- 합성곱 연산을 하면 출력의 크기가 줄어드는데, 이를 방지하기 위해 입력 이미지의 가장자리에 0과 같은 값을 채워 넣는 것입니다.
- 출력 크기 공식:(W: 입력 크기, K: 커널 크기, P: 패딩 크기, S: 스트라이드)
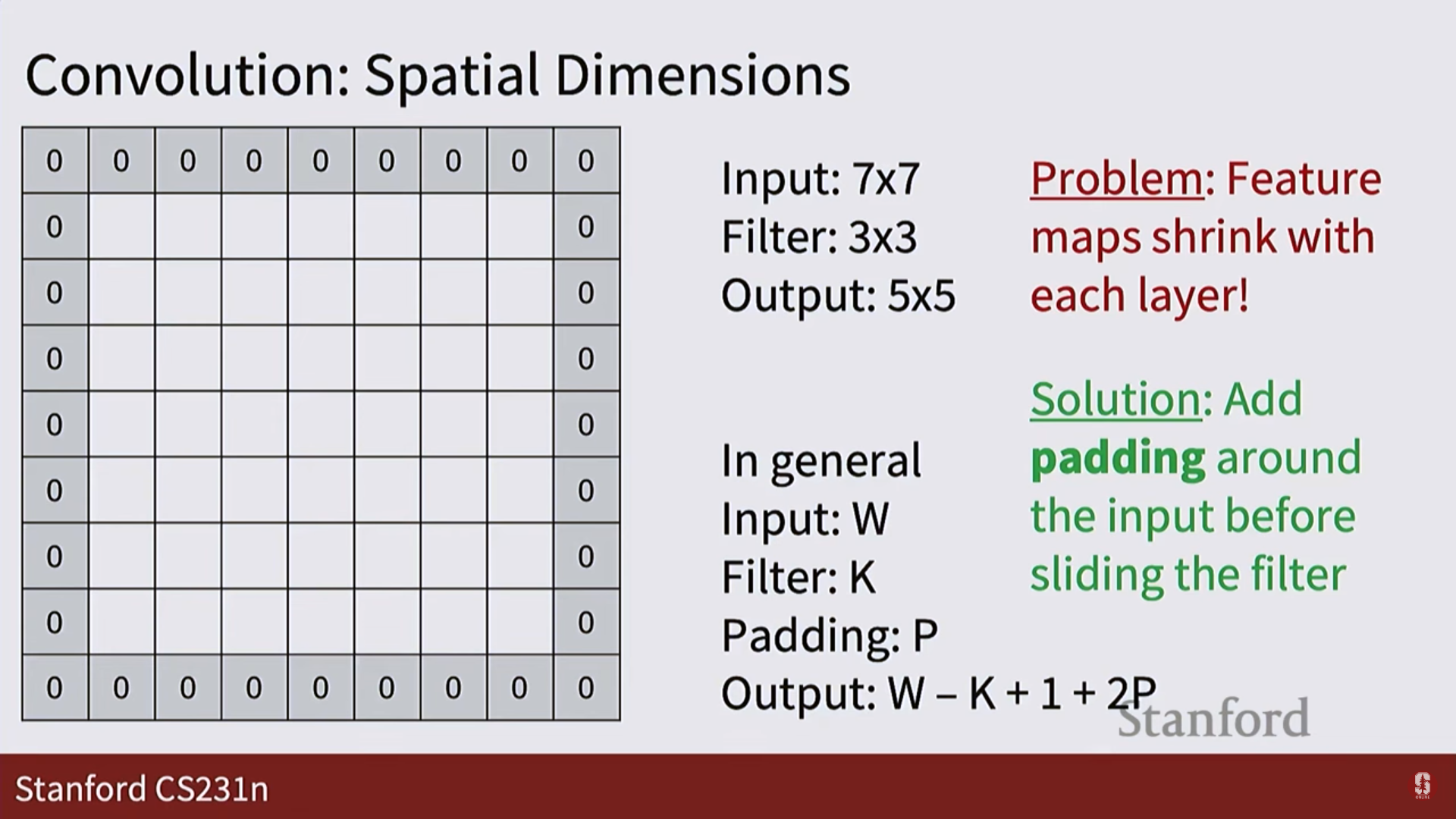
-
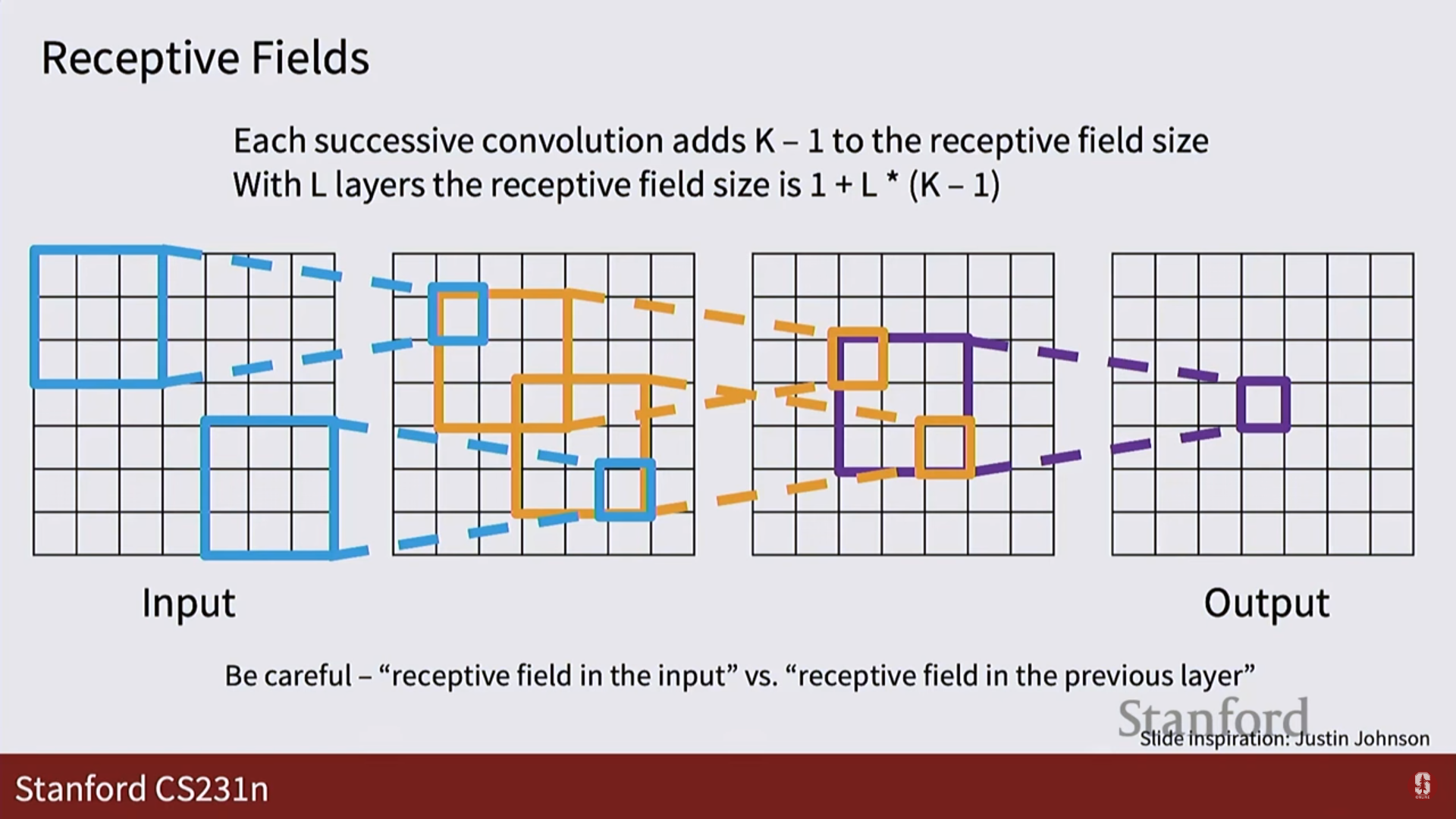
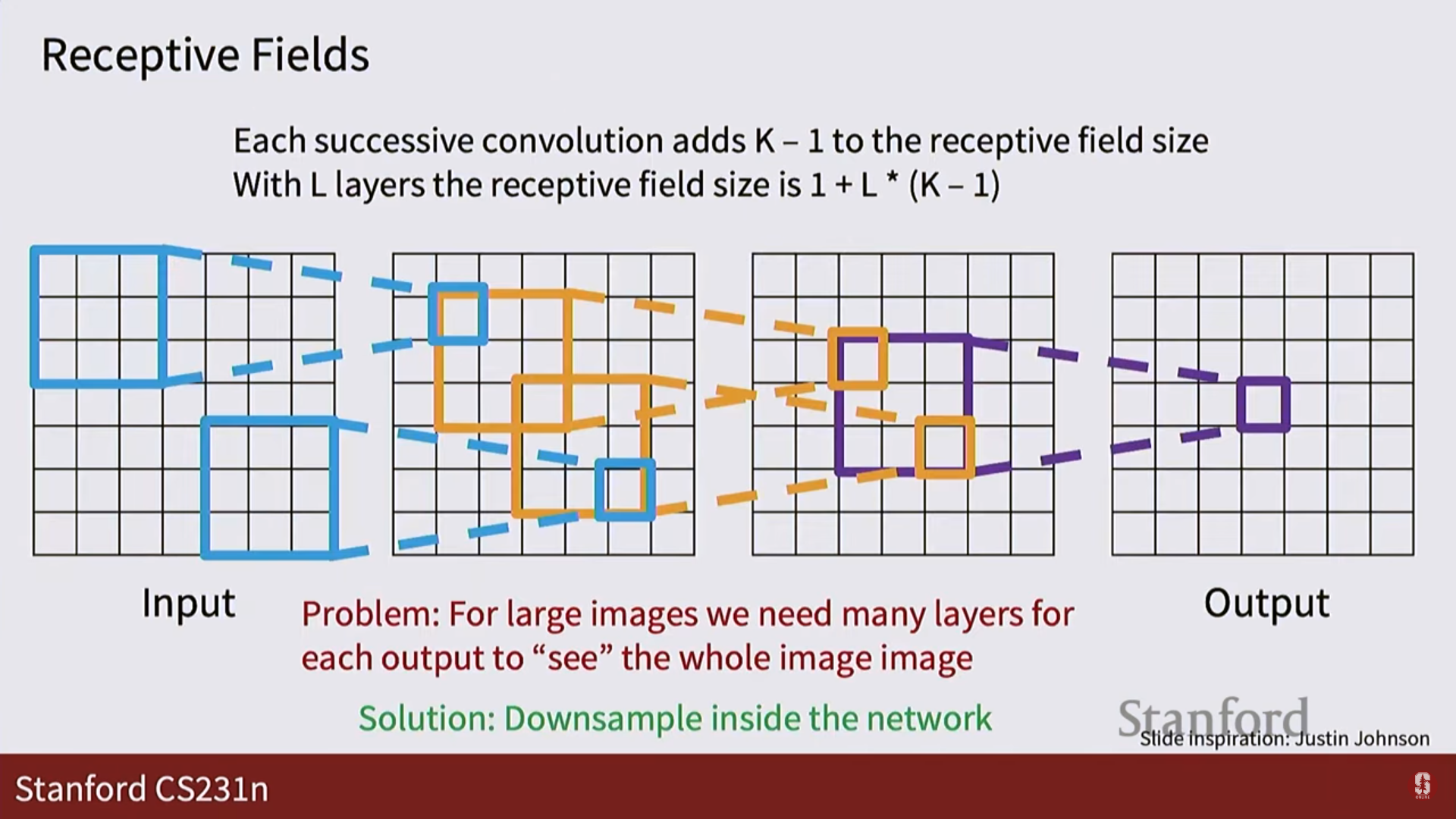
수용장 (Receptive Field):
- 출력 맵의 한 픽셀에 영향을 미치는 입력 이미지의 영역입니다.
- 층을 깊게 쌓고, 스트라이드를 사용하면 수용장이 기하급수적으로 넓어져서, 네트워크의 후반부에서는 이미지 전체의 맥락을 파악할 수 있게 됩니다.
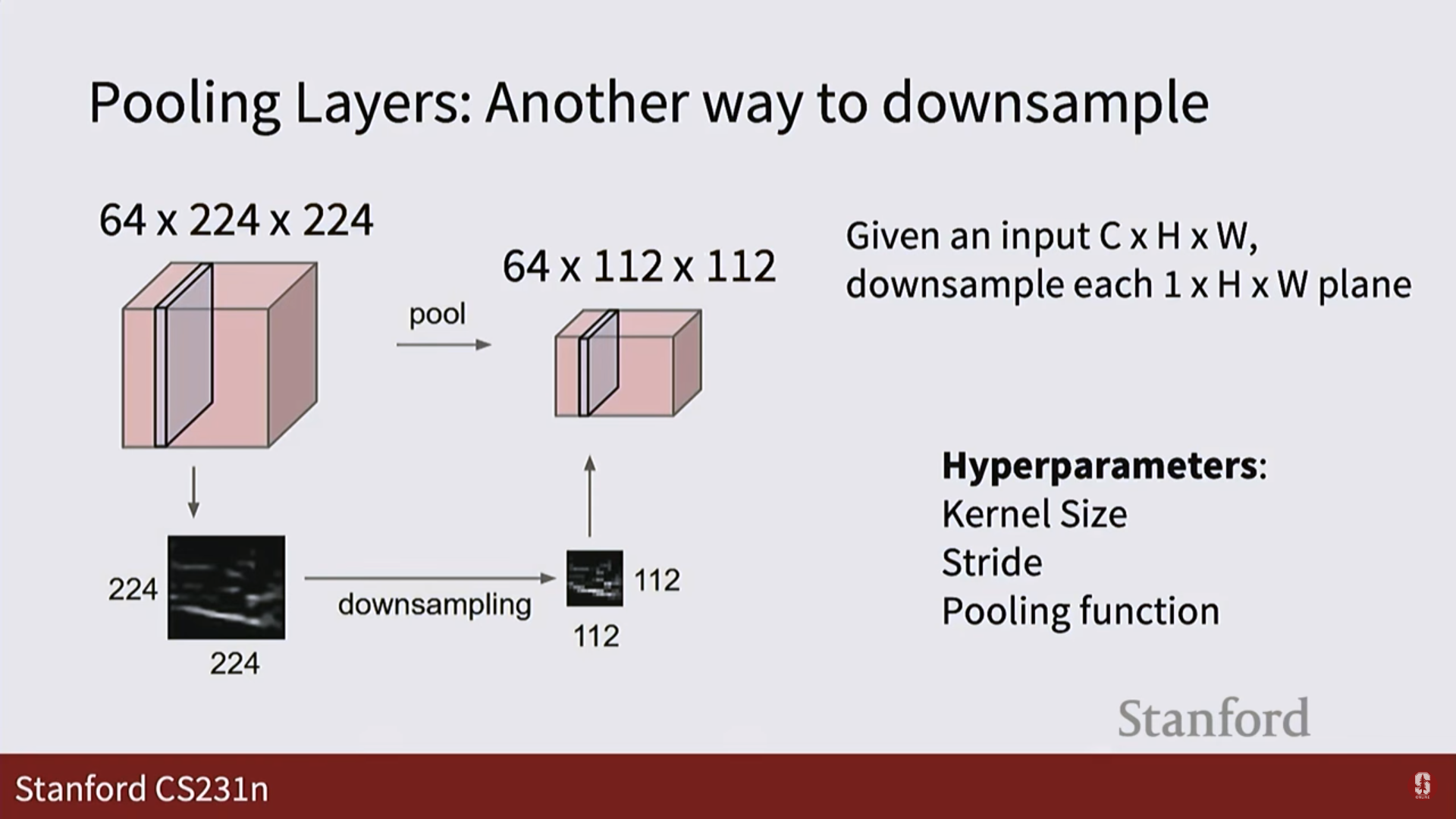
- 풀링 계층 (Pooling Layer):
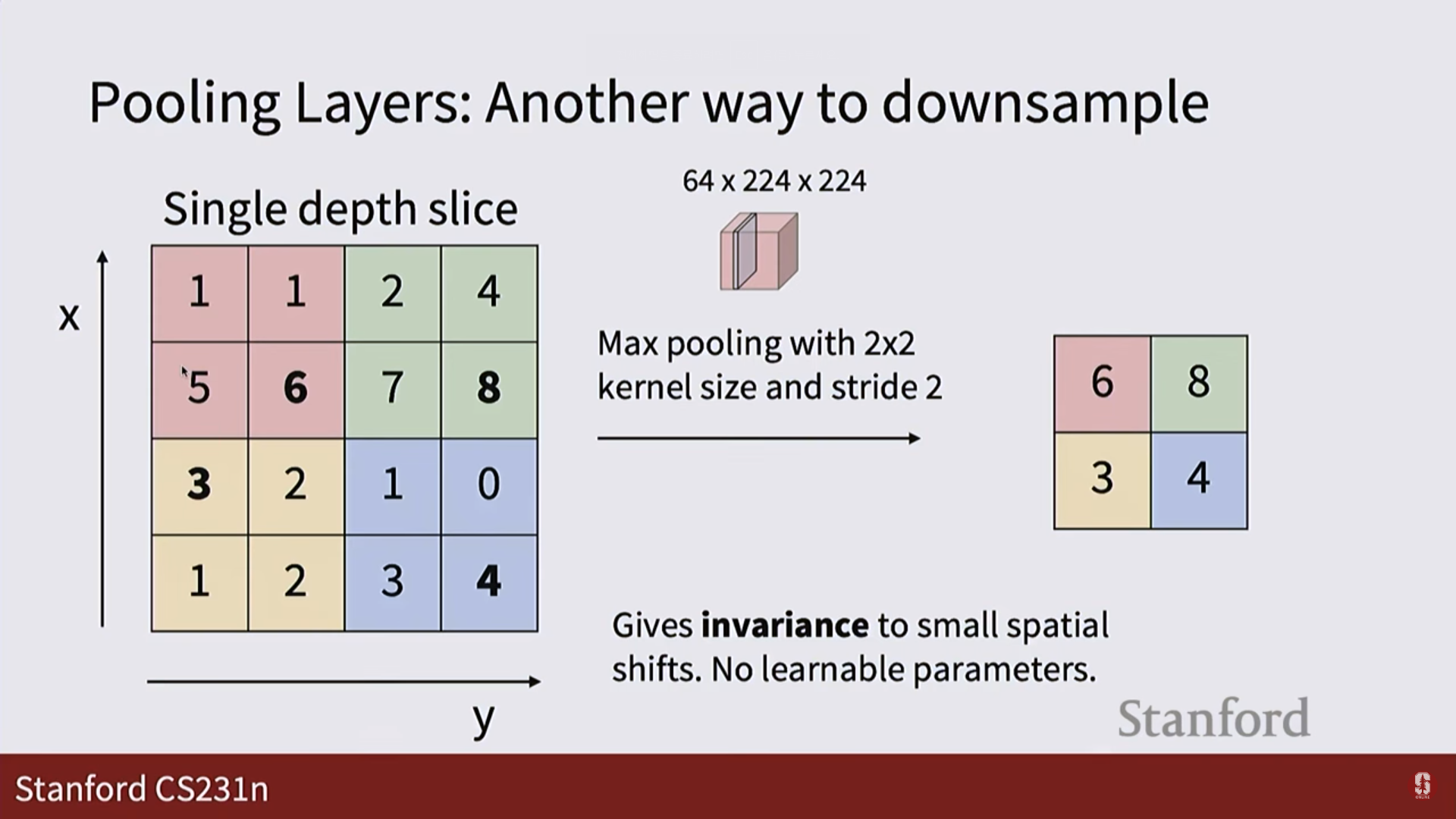
- 특징 맵의 크기를 줄이는 또 다른 방법입니다. 계산량을 줄이고 모델을 좀 더 강건하게(robust) 만들어줍니다.
- 맥스 풀링 (Max Pooling): 특정 영역에서 가장 큰 값(가장 강한 신호)만 남기는 방식으로, 가장 널리 쓰입니다.

4. 심화 내용: CNN 더 깊게 이해하기
-
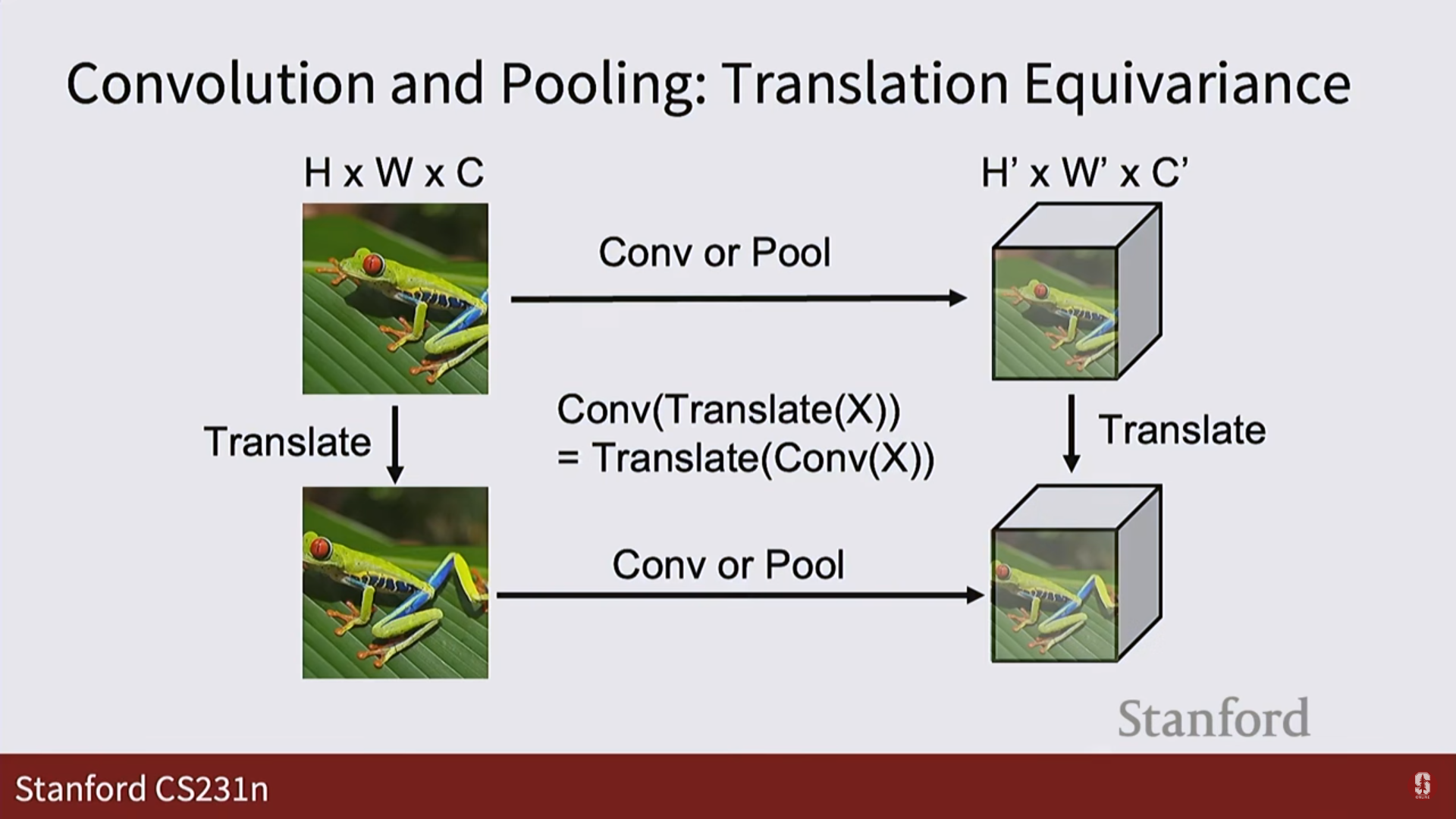
번역 등변성: CNN이 이미지를 잘 다루는 근본 원리:
- '등변성'과 '불변성'의 차이:
- 번역 불변성 (Translation Invariance)은 최종 목표입니다. 이미지 속 고양이의 위치가 바뀌어도, 최종 출력은 여전히 '고양이'라고 나와야 합니다. 즉, 입력의 변화에도 출력이 변하지 않는 것입니다.
- 번역 등변성 (Translation Equivariance)은 이 목표를 달성하기 위한 과정입니다. 이미지 속 고양이가 왼쪽으로 이동하면, CNN 내부의 특징 맵(feature map)에 나타나는 '고양이 특징'도 똑같이 왼쪽으로 이동합니다. 즉, 입력의 변화에 따라 출력(특징 맵)도 일관되게 변하는 성질입니다.
- 등변성이 강력한 이유: 파라미터 공유 (Parameter Sharing):
- 등변성 덕분에 CNN은 이미지의 특정 위치에서 '고양이 귀'를 감지하는 필터를 한 번만 학습하면 됩니다. 그리고 이 필터를 이미지의 모든 위치에 슬라이딩(sliding) 시키면서 적용하기만 하면, 어느 위치에 있든 '고양이 귀'를 찾아낼 수 있습니다.
- 만약 완전 연결 신경망(FCN)이었다면, 이미지의 왼쪽 위 귀, 오른쪽 위 귀, 중앙의 귀를 감지하기 위해 각각 별도의 파라미터를 모두 학습해야 했을 것입니다.
- 이처럼 하나의 필터(파라미터 셋)를 이미지 전체에 공유해서 사용하는 파라미터 공유는 CNN을 엄청나게 효율적이고 강력하게 만드는 핵심적인 메커니즘입니다.
-
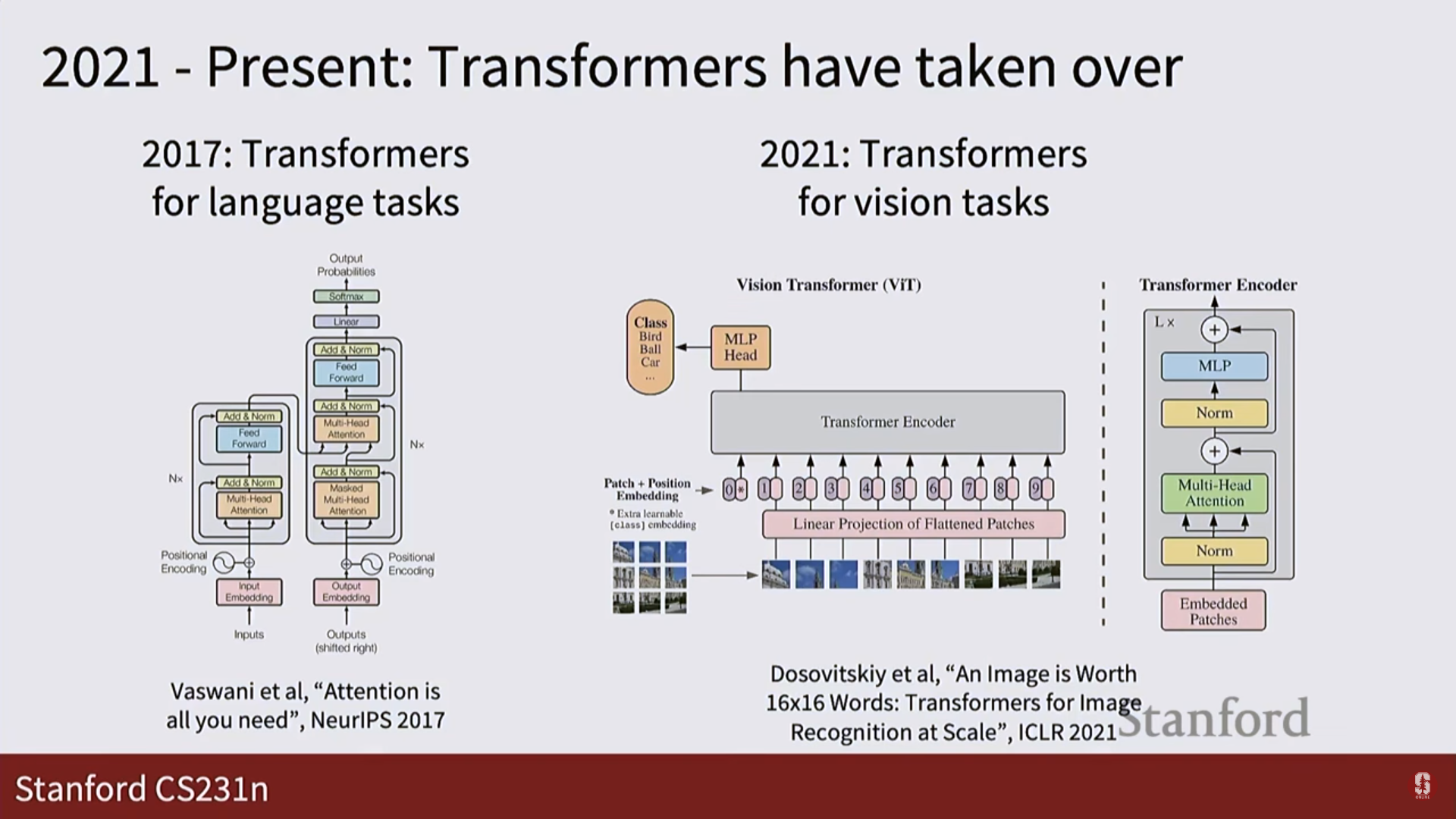
CNN vs. 트랜스포머: 세상을 보는 두 가지 관점:
- CNN의 관점: 강력한 '귀납적 편향' (Inductive Bias):
- CNN은 "이미지에서 중요한 정보는 주변 픽셀들과 밀접하게 관련되어 있다"는 매우 강력한 가정(귀납적 편향)을 내장하고 있습니다.
- 작은 크기의 필터가 바로 이 가정의 물리적인 구현체입니다. CNN은 이 필터를 통해 처음에는 선, 모서리 같은 지역적(local) 특징을 학습하고, 층을 깊게 쌓아가면서 이들을 조합해 더 복잡하고 전역적(global)인 특징을 이해하는 상향식(bottom-up) 구조를 가집니다.
- 이 편향은 매우 효과적이어서, 비교적 적은 데이터로도 빠르게 좋은 성능을 낼 수 있습니다.
- 트랜스포머의 관점: 편견 없는 '전역적 관계':
- 비전 트랜스포머(ViT)는 이미지를 여러 개의 패치(patch)로 나눈 뒤, 이 패치들을 문장의 단어처럼 취급합니다.
- 그리고 셀프 어텐션(self-attention) 메커니즘을 통해 처음부터 이미지의 모든 패치가 다른 모든 패치와 어떤 관계를 맺고 있는지를 한 번에 계산합니다. 왼쪽 위의 '고양이 귀' 패치는 수십 픽셀 떨어진 오른쪽 아래의 '고양이 꼬리' 패치와 직접적으로 소통할 수 있습니다.
- 이러한 방식은 지역성에 대한 가정이 없기 때문에 CNN보다 훨씬 유연하며, 데이터가 충분히 많을 경우 CNN이 놓칠 수 있는 장거리 의존성(long-range dependency)을 더 잘 학습하여 뛰어난 성능을 보일 수 있습니다. 하지만 이 '편견 없음' 때문에, 이미지의 기본적인 공간 구조를 배우기 위해 CNN보다 훨씬 더 많은 데이터를 필요로 합니다.
- CNN의 관점: 강력한 '귀납적 편향' (Inductive Bias):
-
CNN의 명확한 한계점:
- 기하학적 변환에 대한 취약성:
- CNN의 필터는 고정된 형태로 학습됩니다. 수직선 필터는 수직선만 잘 감지할 뿐, 45도 기울어진 선은 잘 감지하지 못합니다.
- 이 때문에 CNN은 객체의 회전(rotation), 크기 변화(scale), 시점 변화에 강건하지 못합니다. 이러한 변형을 모두 학습하려면, 사실상 모든 경우의 수에 해당하는 필터를 데이터로부터 배우거나, 방대한 양의 데이터 증강(data augmentation)에 의존해야만 합니다.
- '질감 편향 (Texture Bias)':
- 여러 연구에 따르면 CNN은 객체의 전체적인 형태(shape)보다 부분적인 질감(texture)에 더 의존하여 판단하는 경향이 있습니다.
- 예를 들어, 코끼리 피부 질감을 가진 고양이 이미지를 보여주면, CNN은 이를 '코끼리'로 분류할 가능성이 높습니다. 이는 CNN이 지역적인 패턴을 조합하는 방식으로 작동하기 때문에 발생하는 한계로, 인간의 시각과는 다른 판단 방식입니다.
- 계층적 관계 이해의 부재:
- CNN은 이미지에서 '눈', '코', '입'과 같은 특징들을 각각 잘 찾아낼 수는 있습니다. 하지만 이 특징들이 '얼굴'이라는 상위 개념을 구성하기 위해 어떤 계층적, 공간적 관계를 맺고 있는지를 명시적으로 학습하지는 않습니다.
- 이로 인해 얼굴의 파츠들이 뒤죽박죽 섞여 있는 비현실적인 이미지도 '얼굴'로 인식하는 실수를 저지를 수 있습니다.
- 기하학적 변환에 대한 취약성:
5. Q&A
필터는 어떻게 학습되나요?
- Q: 필터의 값들은 어떻게 얻어지나요? 사람이 직접 설정하나요?
- A: 아닙니다. 필터의 값들은 학습 가능한 파라미터입니다. 처음에는 무작위 값으로 초기화된 후, 역전파와 경사 하강법을 통해 데이터로부터 자동으로 학습됩니다. 각 필터가 어떤 특징을 감지할지는 전적으로 데이터와 손실 함수에 의해 결정됩니다.
필터 크기와 같은 하이퍼파라미터는 어떻게 정하나요?
- Q: 필터 크기(예: 5x5)나 필터의 개수는 어떻게 정하나요?
- A: 필터 크기, 개수, 스트라이드, 패딩 등은 모두 하이퍼파라미터입니다. 이는 모델이 학습하는 값이 아니라, 연구자가 직접 설정해야 하는 값입니다. 보통은 기존에 좋은 성능을 보인 다른 연구들의 설정을 참고하거나, 교차 검증(cross-validation)을 통해 최적의 값을 찾습니다.
여러 크기의 필터를 함께 사용할 수 있나요?
- Q: 한 계층에서 3x3 필터와 5x5 필터를 동시에 사용할 수 있나요?
- A: 네, 가능합니다. 대표적으로 구글의 인셉션(Inception) 아키텍처가 그런 방식을 사용합니다. 여러 크기의 필터를 동시에 적용한 후 그 결과(활성화 맵)를 합쳐서 다음 계층으로 전달하는 구조입니다. 이를 통해 모델이 다양한 스케일의 특징을 한 번에 포착할 수 있습니다.
필터들이 서로 다른 특징을 학습하게 하려면 어떻게 하나요?
- Q: 모든 필터가 똑같은 특징만 학습하면 어떡하나요?
- A: 매우 중요한 질문입니다. 이를 방지하기 위해, 학습 시작 시점에 각 필터들을 서로 다른 무작위 값으로 초기화해야 합니다. 만약 모든 필터를 똑같은 값으로 초기화하면, 역전파 과정에서 계산되는 그래디언트도 모두 같아져서 결국 모든 필터가 똑같은 특징을 학습하게 됩니다. 무작위 초기화는 이러한 대칭성을 깨뜨리는 중요한 역할을 합니다.
풀링(Pooling)도 비선형적인가요?
- Q: 풀링 계층도 활성화 함수처럼 비선형성을 추가해주나요?
- A: 풀링의 종류에 따라 다릅니다. 맥스 풀링(Max Pooling)은 최댓값을 고르는 비선형(non-linear) 연산입니다. 따라서 맥스 풀링 주변에는 ReLU를 굳이 사용하지 않는 경우도 있습니다. 반면 평균 풀링(Average Pooling)은 선형(linear) 연산이므로, 비선형성을 추가하기 위해 주변에 ReLU를 함께 사용하는 것이 좋습니다.
