1. CNN의 기본 구성 요소
1) 컨볼루션 계층 (Convolutional Layer)
- 컨볼루션 계층은 CNN의 근간을 이루는 핵심 연산 계층입니다. 이 계층의 주된 역할은 입력 데이터에 필터(Filter 또는 커널, Kernel)를 적용하여 특징 맵(Feature Map) 또는 활성화 맵(Activation Map)을 생성하는 것입니다.
- 필터는 학습 가능한 가중치(weights)를 가진 작은 행렬로, 입력 데이터 위를 일정 간격(stride)으로 이동하며 내적(dot product) 연산을 수행합니다. 이 과정을 통해 필터가 담당하는 특정 시각적 패턴(예: 경계선, 질감, 색상 조합)이 입력 데이터의 어느 위치에서 활성화되는지를 나타내는 맵이 생성됩니다.
2) 풀링 계층 (Pooling Layer)
- 풀링 계층은 특징 맵의 공간적 차원(가로, 세로)을 축소하는 다운샘플링(Downsampling) 역할을 수행합니다. 이를 통해 모델의 계산 효율성을 높이고, 객체의 위치 변화에 대해 강건한 위치 불변성(Translational Invariance) 특성을 갖도록 유도합니다.
- 최대 풀링(Max Pooling): 가장 널리 사용되는 기법으로, 지정된 영역 내에서 가장 큰 활성화 값을 선택합니다. 이는 가장 두드러진 특징을 보존하는 효과가 있습니다.
- 평균 풀링(Average Pooling): 지정된 영역 내 모든 활성화 값의 평균을 계산합니다.
3) 정규화 계층 (Normalization Layer)
- 정규화 계층은 신경망의 각 계층을 통과하는 데이터의 분포를 안정화시켜 학습 과정을 원활하게 만드는 역할을 합니다. 이는 내부 공변량 변화(Internal Covariate Shift) 문제를 완화하여 학습 속도를 높이고 초기값 설정에 대한 민감도를 줄입니다.
- 계층 정규화(Layer Normalization): 각 개별 데이터 샘플 내의 모든 특성(features)에 대해 평균과 분산을 계산하여 정규화를 수행합니다. 특히 트랜스포머(Transformers) 아키텍처에서 핵심적인 역할을 합니다.
- 배치 정규화(Batch Normalization): 미니배치(mini-batch) 내의 동일 채널에 해당하는 모든 활성화 값들을 함께 사용하여 평균과 분산을 계산합니다.
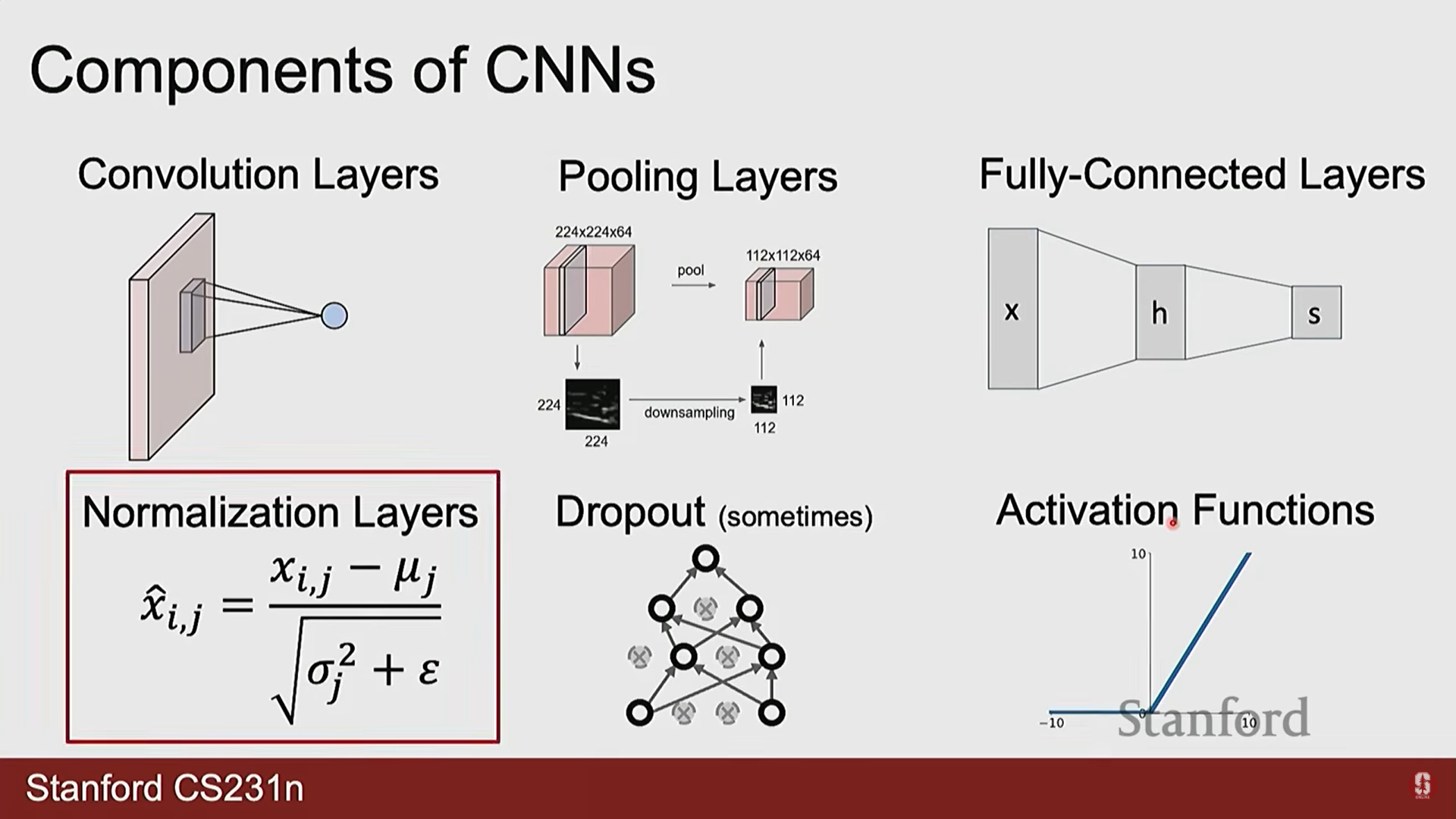


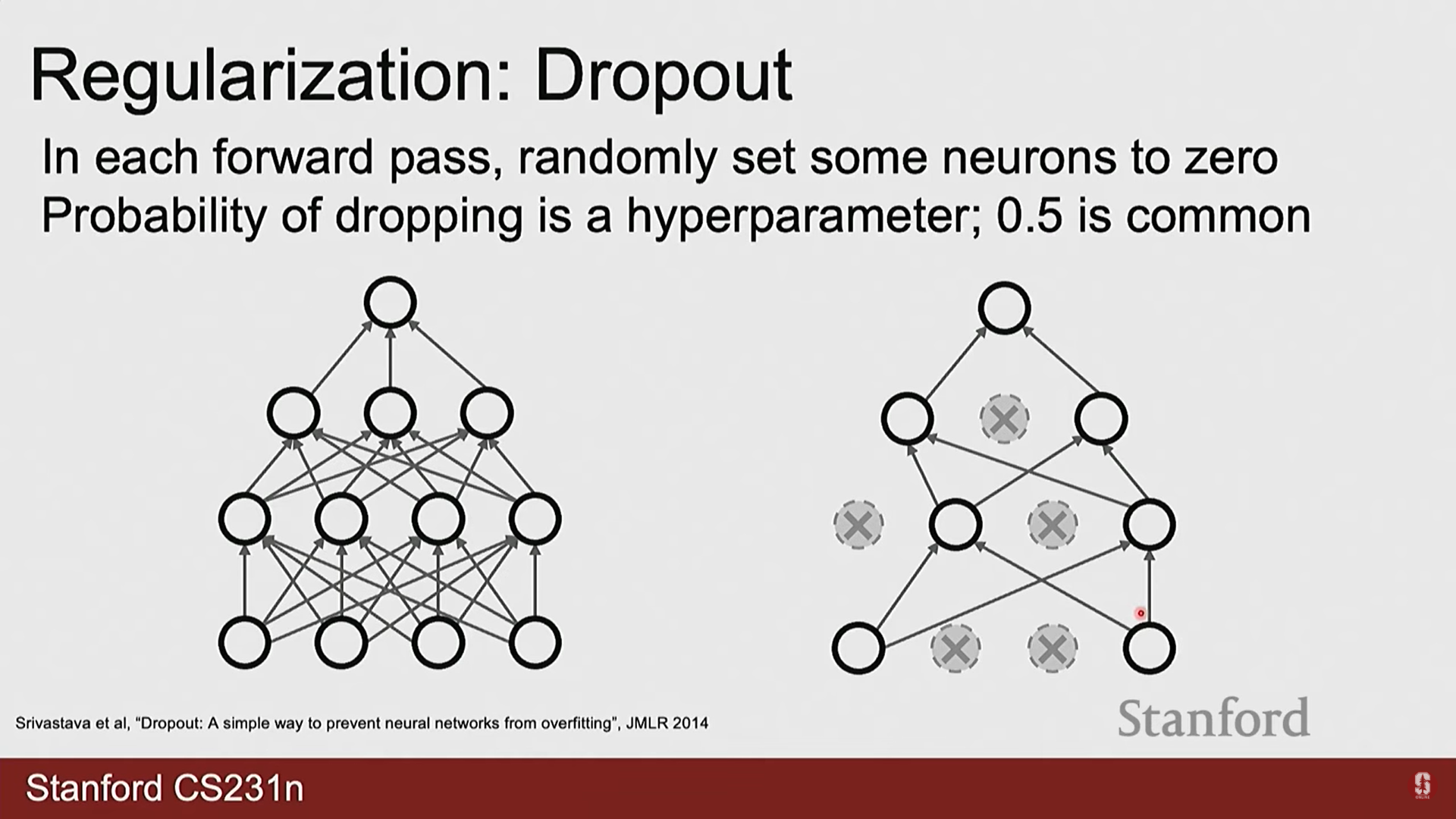
4) 드롭아웃 (Dropout)
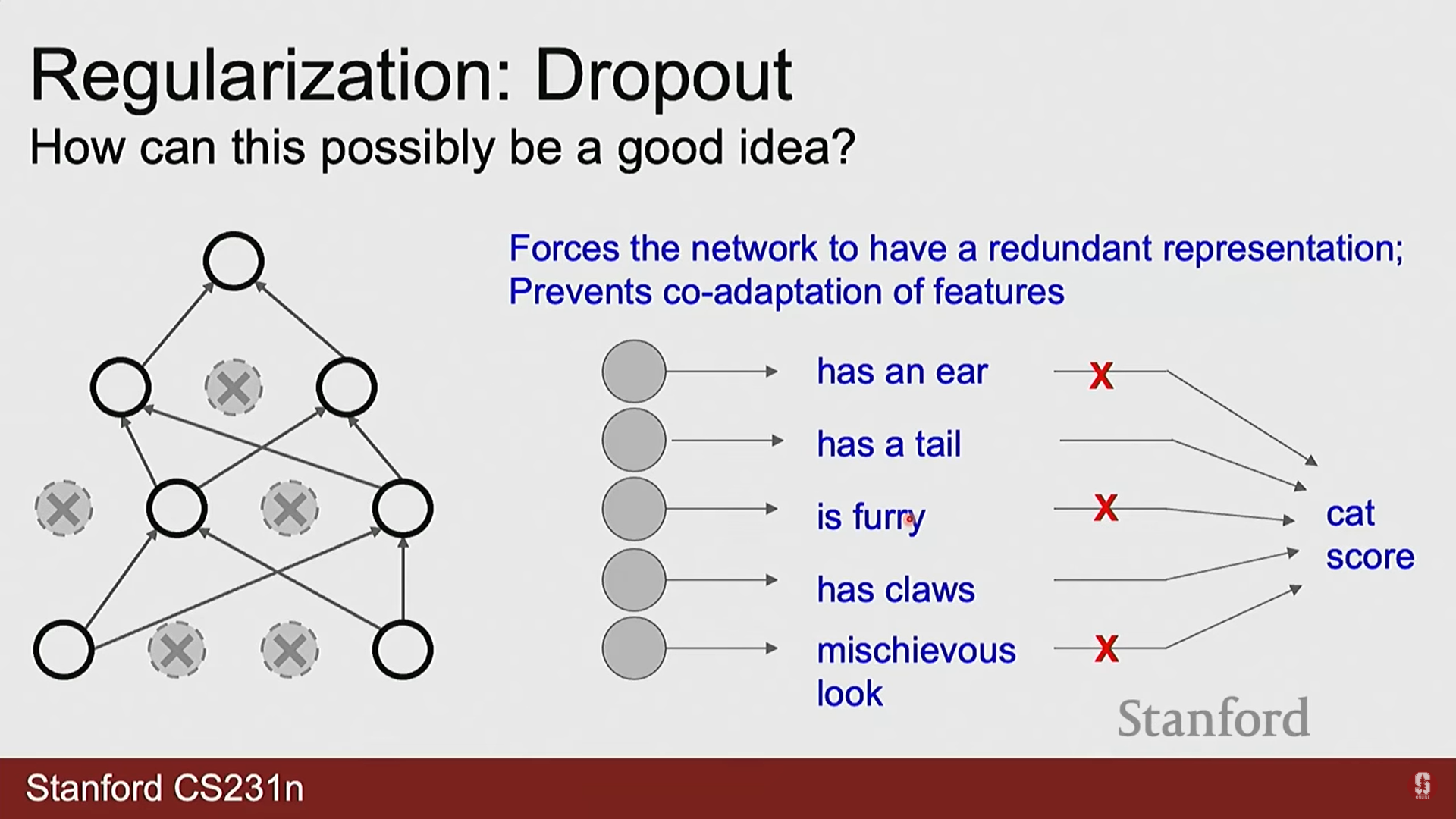
- 드롭아웃은 모델의 과적합을 방지하기 위한 대표적인 정규화(Regularization) 기법입니다.
- 훈련 단계에서 각 뉴런의 출력을 확률 로 무작위하게 0으로 만듭니다. 이 과정은 매 학습 반복마다 다른 구성을 가진 신경망 앙상블을 학습시키는 것과 유사한 효과를 내어, 모델이 특정 뉴런이나 특징에 과도하게 의존하는 것을 방지하고 일반화 성능을 향상시킵니다.
- 테스트 시에는 모든 뉴런을 사용하되, 훈련 시와 출력의 기댓값을 맞춰주기 위해 모든 가중치에 를 곱해주는 스케일링을 적용합니다.


5) 활성화 함수 (Activation Function)
- 활성화 함수는 선형 연산의 결과에 비선형성(Non-linearity)을 부여하는 필수적인 요소입니다. 비선형성이 없다면, 신경망은 단순히 선형 변환의 연속이 되어 복잡한 데이터 패턴을 학습할 수 없습니다.
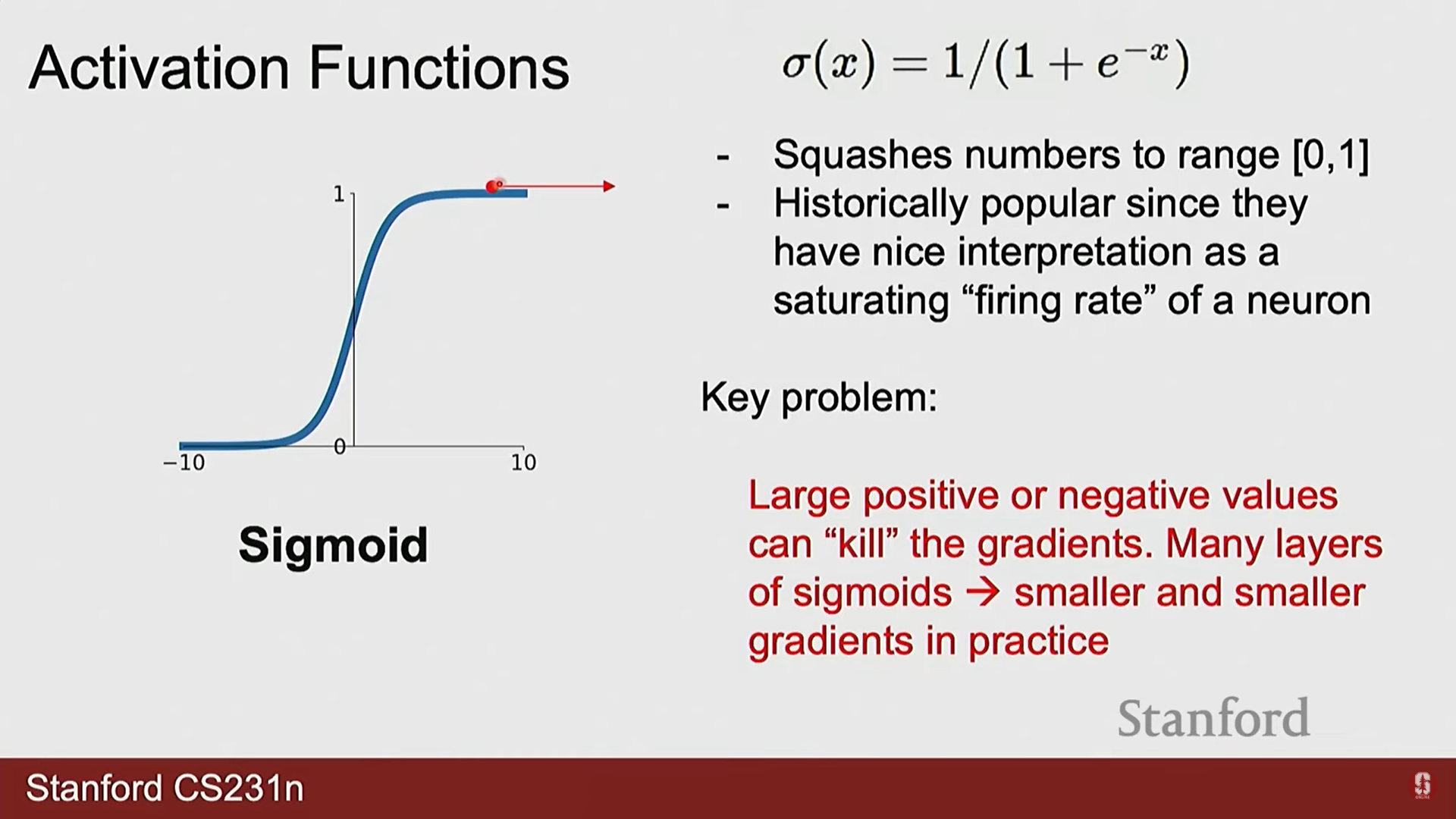
- Sigmoid: . 출력값이 (0, 1) 사이로 제한되나, 입력의 절댓값이 커지면 미분값이 0에 수렴하는 기울기 소실(Vanishing Gradient) 문제가 발생하여 현재는 잘 사용되지 않습니다.
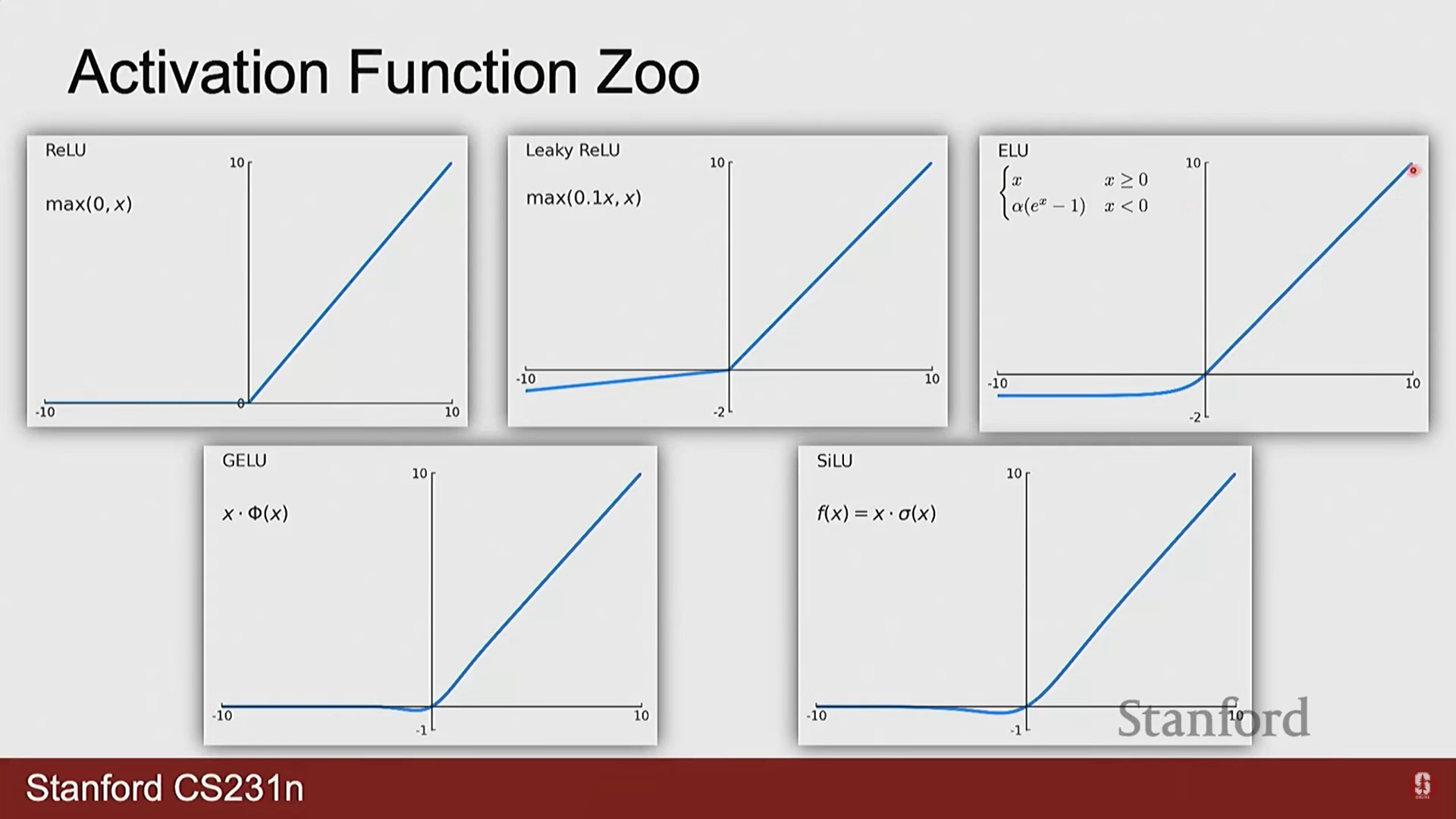
- ReLU (Rectified Linear Unit): . 계산이 매우 간단하고 기울기 소실 문제를 완화하여 널리 사용되었습니다. 그러나 입력이 음수일 때 기울기가 0이 되어 해당 뉴런이 학습 과정에서 비활성화될 수 있습니다.
- GELU (Gaussian Error Linear Unit): (여기서 $ \Phi(x) $는 정규분포의 누적분포함수). ReLU를 부드럽게 근사한 형태로, 0 근처에서 미분값이 존재하여 더욱 안정적인 학습이 가능합니다. 트랜스포머 계열 모델에서 표준으로 채택되었습니다.



2. 대표적인 CNN 아키텍처
1) VGGNet
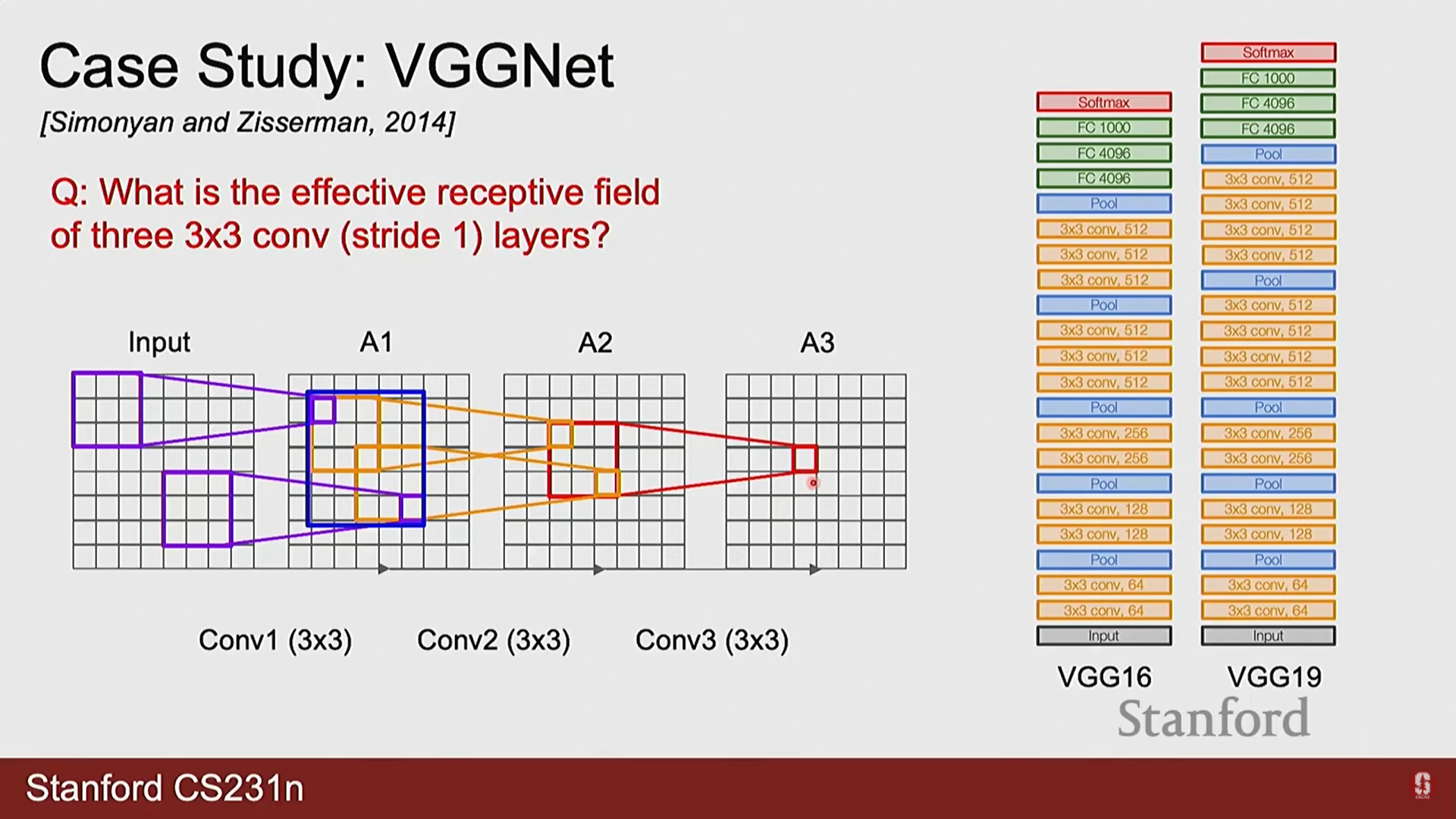
- VGGNet은 3x3 크기의 작은 컨볼루션 필터를 깊게 쌓는 단순하고 균일한 구조의 유효성을 입증한 모델입니다.
- 3x3 필터의 효율성: 7x7 필터 1개를 사용하는 것보다 3x3 필터 3개를 쌓는 것이 동일한 수용장(Receptive Field)을 가지면서도 파라미터 수를 줄일 수 있습니다. (예: 채널 수가 C일 때, 개의 파라미터는 개보다 효율적입니다). 또한, 더 많은 활성화 함수를 통과시키므로 비선형 표현력이 증대됩니다.


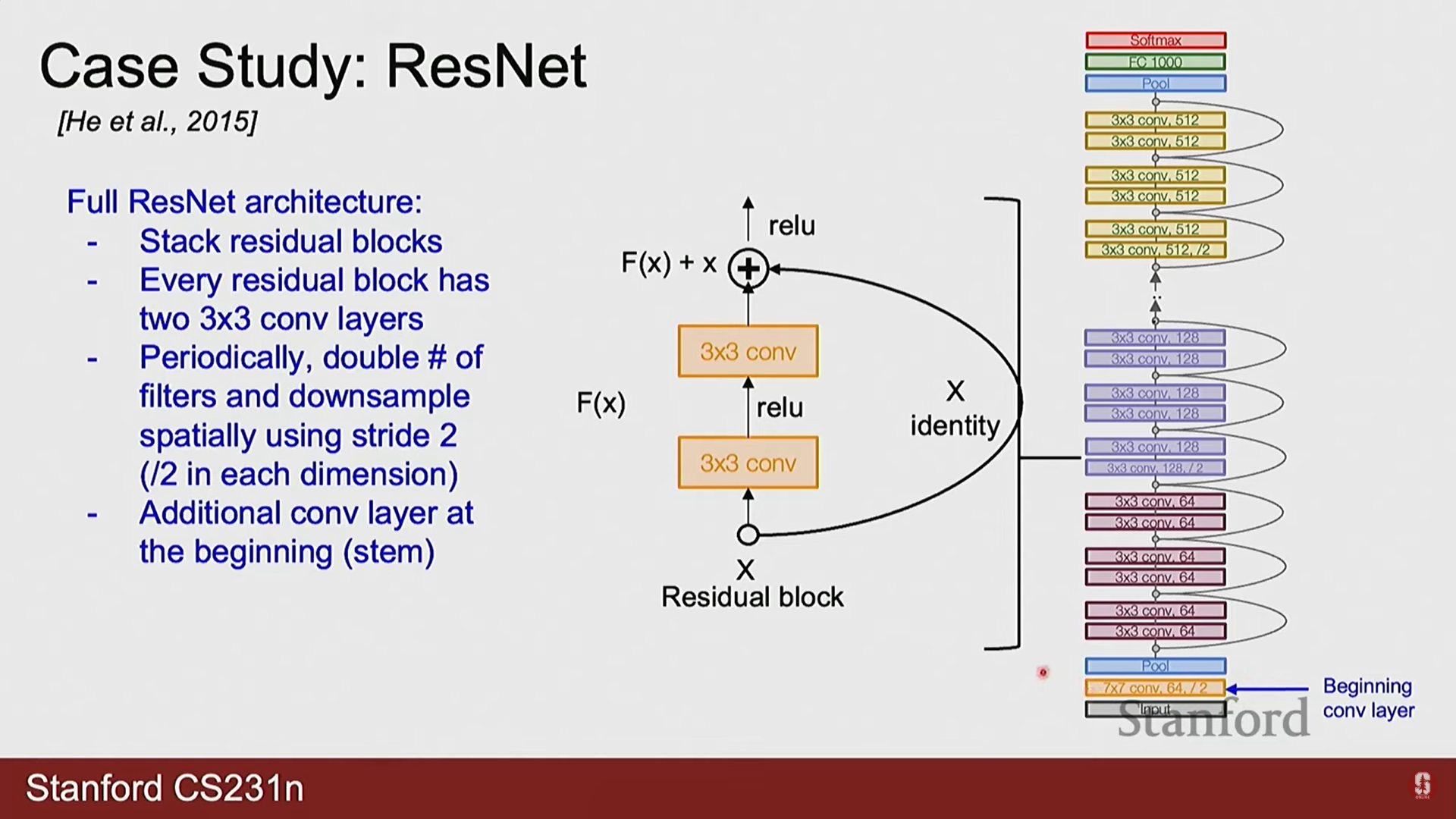
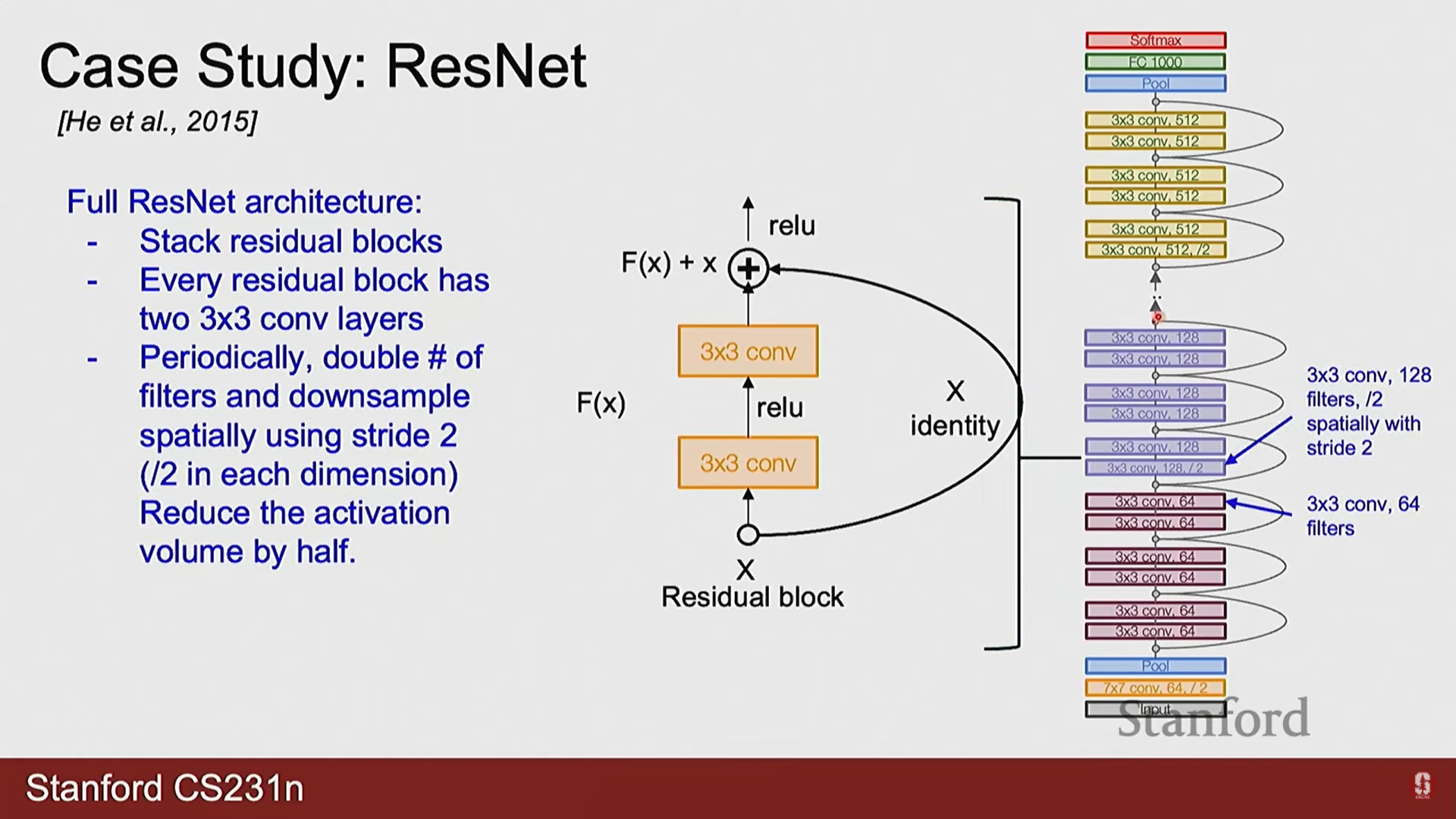
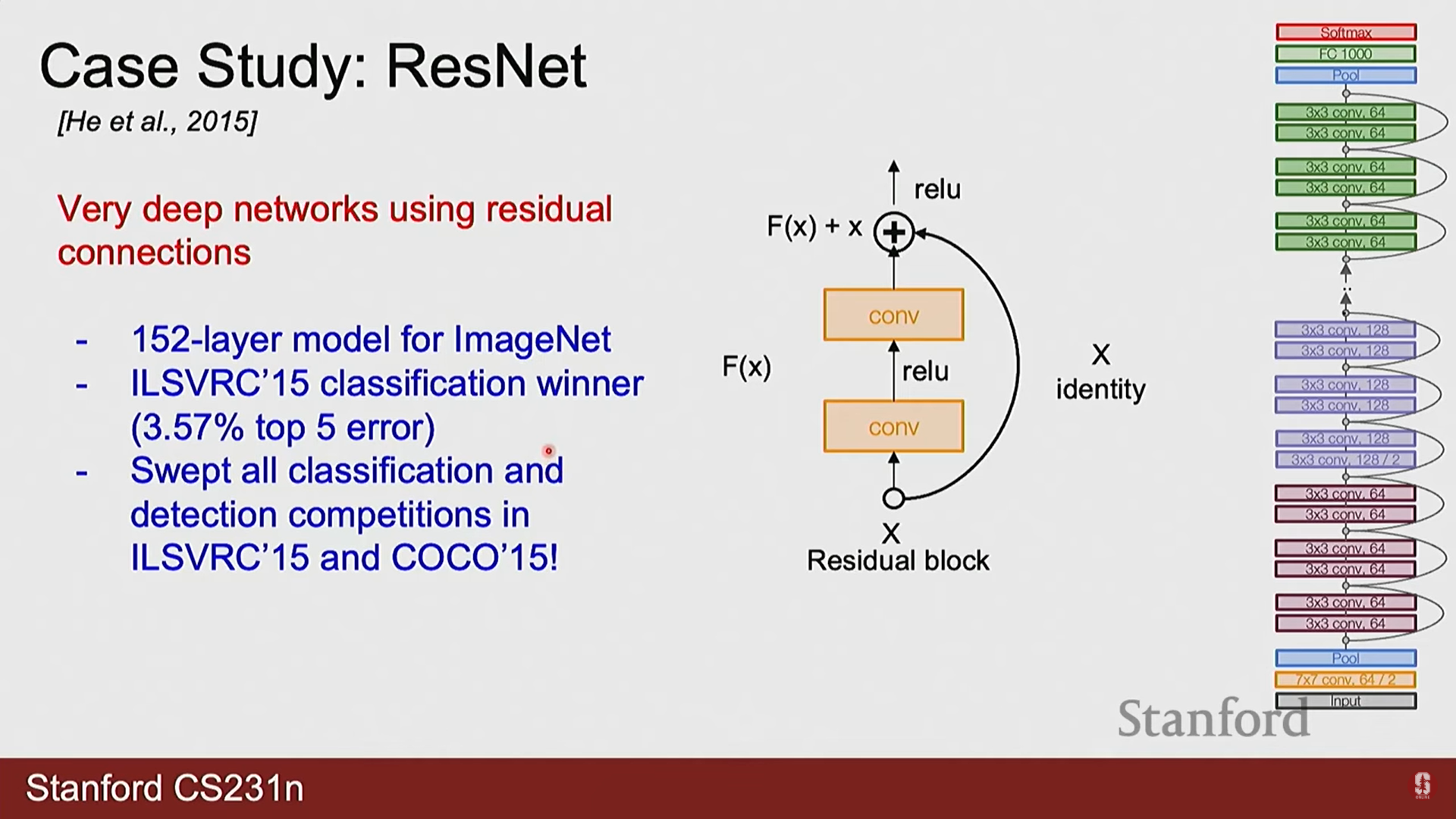
2) ResNet (Residual Networks)
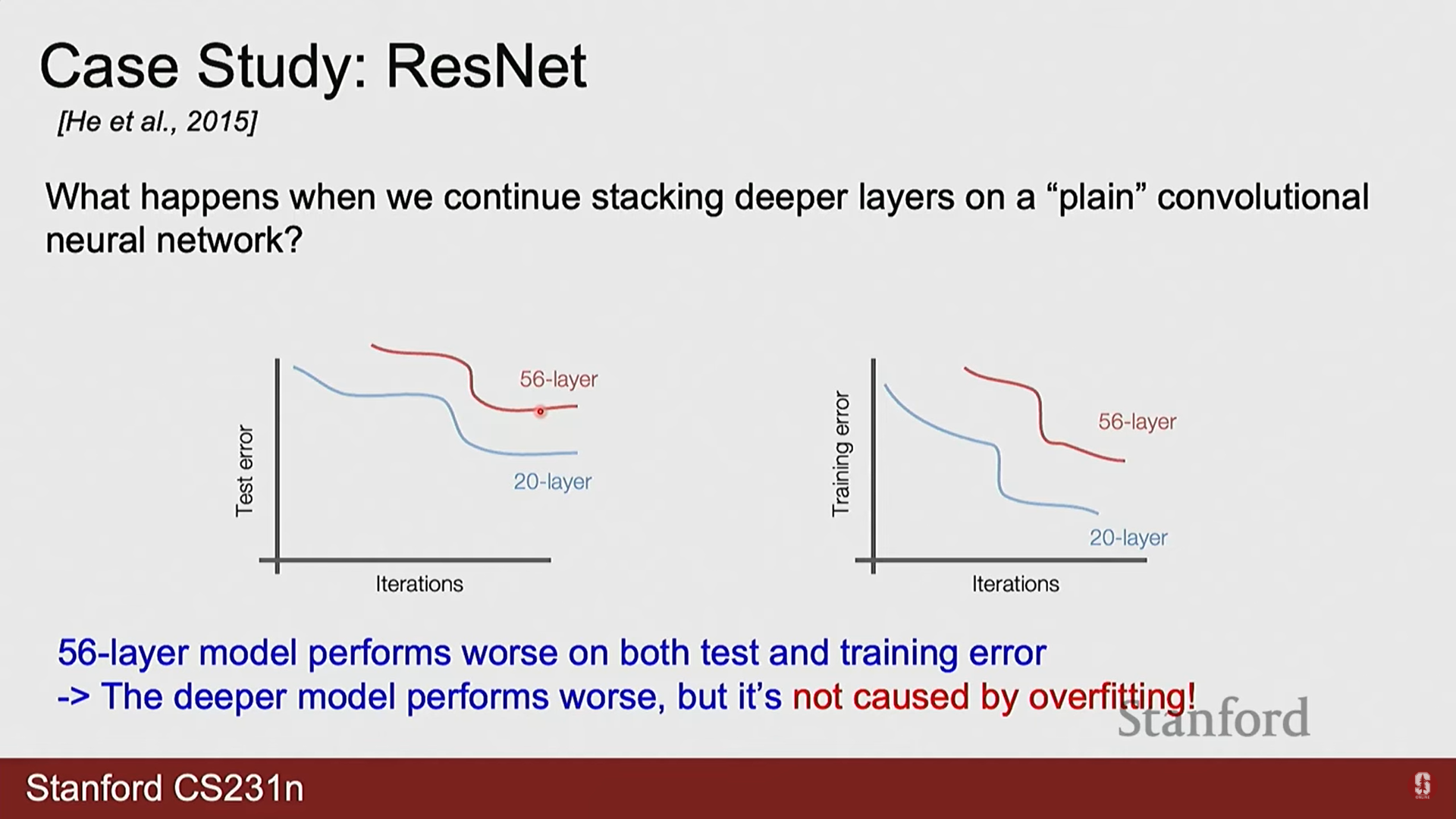

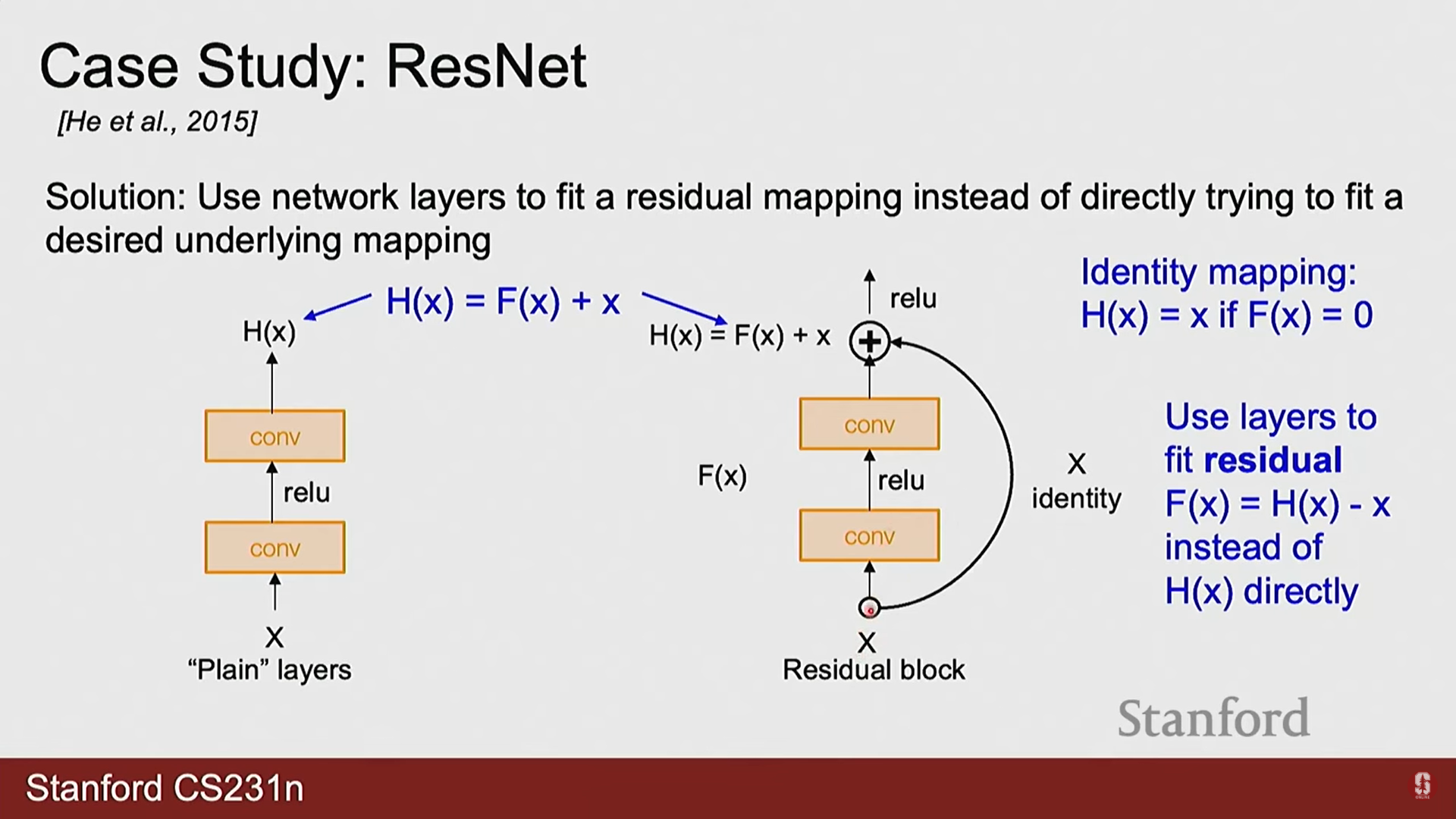
- ResNet은 신경망의 깊이가 깊어질수록 오히려 성능이 저하되는 퇴화(Degradation) 문제를 해결하기 위해 설계되었습니다.
- 핵심 아이디어: 잔여 학습(Residual Learning) 개념을 도입했습니다. 특정 계층이 학습해야 할 목표 함수를 라고 할 때, 이를 직접 학습하는 대신 입력 와의 차이인 잔여 함수(Residual Function) 를 학습하도록 구조를 변경했습니다.
- 수학적 표현: 이는 스킵 커넥션(Skip Connection)을 통해 구현되며, 블록의 출력은 다음과 같이 표현됩니다.
여기서 는 블록의 입력, 는 출력, 는 학습할 잔여 매핑을 의미합니다. 이 구조 덕분에 최적의 함수가 항등 함수(identity mapping)일 경우, 네트워크는 가중치를 0으로 만들어 를 0에 가깝게 학습하면 되므로 최적화가 매우 용이해집니다. 이를 통해 100계층 이상의 매우 깊은 네트워크를 성공적으로 훈련할 수 있었습니다.
3. 성공적인 모델 훈련을 위한 실전 기법
1) 가중치 초기화 (Weight Initialization)
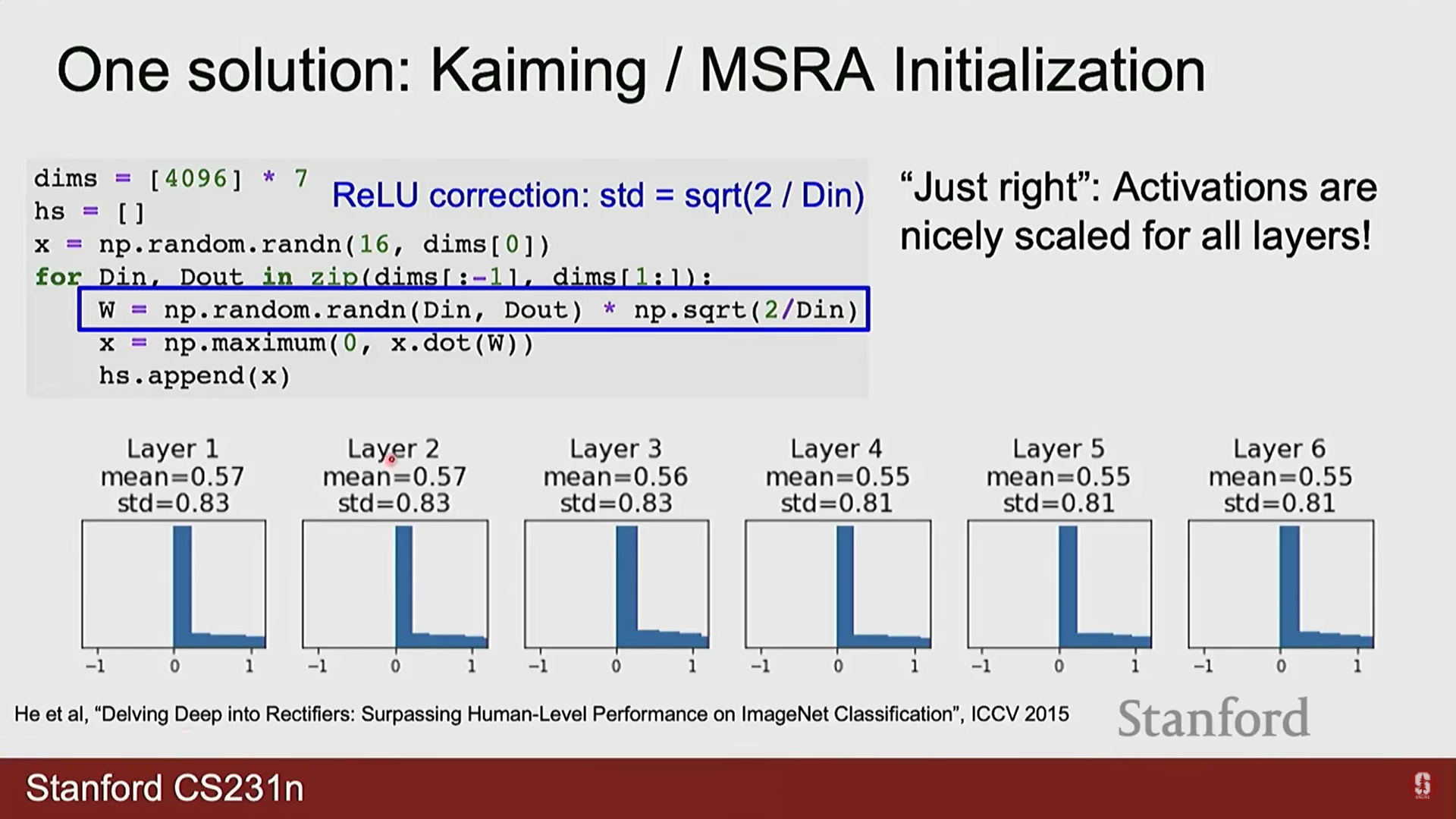
- 가중치 초기화는 학습의 안정성과 속도에 지대한 영향을 미칩니다. 부적절한 초기화는 기울기 소실 또는 폭주(exploding)를 유발할 수 있습니다.
- Kaiming 초기화 (He Initialization): ReLU 활성화 함수를 사용하는 네트워크에 최적화된 초기화 기법입니다. 각 계층의 출력 분산이 입력 분산과 동일하게 유지되도록 설계되었습니다. 가중치를 평균 0, 표준편차 인 정규분포에서 샘플링하며, 이때 표준편차는 다음과 같이 정의됩니다.
(여기서 은 해당 계층의 입력 노드 수(fan-in)를 의미합니다.)



2) 데이터 전처리 및 증강 (Data Preprocessing & Augmentation)
- 데이터 전처리: 훈련 데이터셋 전체의 채널별 평균과 표준편차를 계산하여 모든 입력 데이터를 표준화(Standardization)하는 것이 일반적입니다. 이는 데이터를 평균 0, 분산 1인 분포로 만들어 학습을 안정화시킵니다.
- 데이터 증강: 제한된 훈련 데이터에 다양한 변환을 적용하여 데이터셋의 크기를 인위적으로 늘리는 기법입니다. 이는 모델이 학습 데이터에만 존재하는 특정 패턴에 과적합되는 것을 방지하고, 일반화 성능을 극대화하는 데 필수적입니다.
- 주요 기법: 좌우 반전(Horizontal Flipping), 무작위 크기 조절 및 자르기(Random Resized Crop), 색상 변형(Color Jittering), 이미지 일부 가리기(Cutout) 등이 포함됩니다.

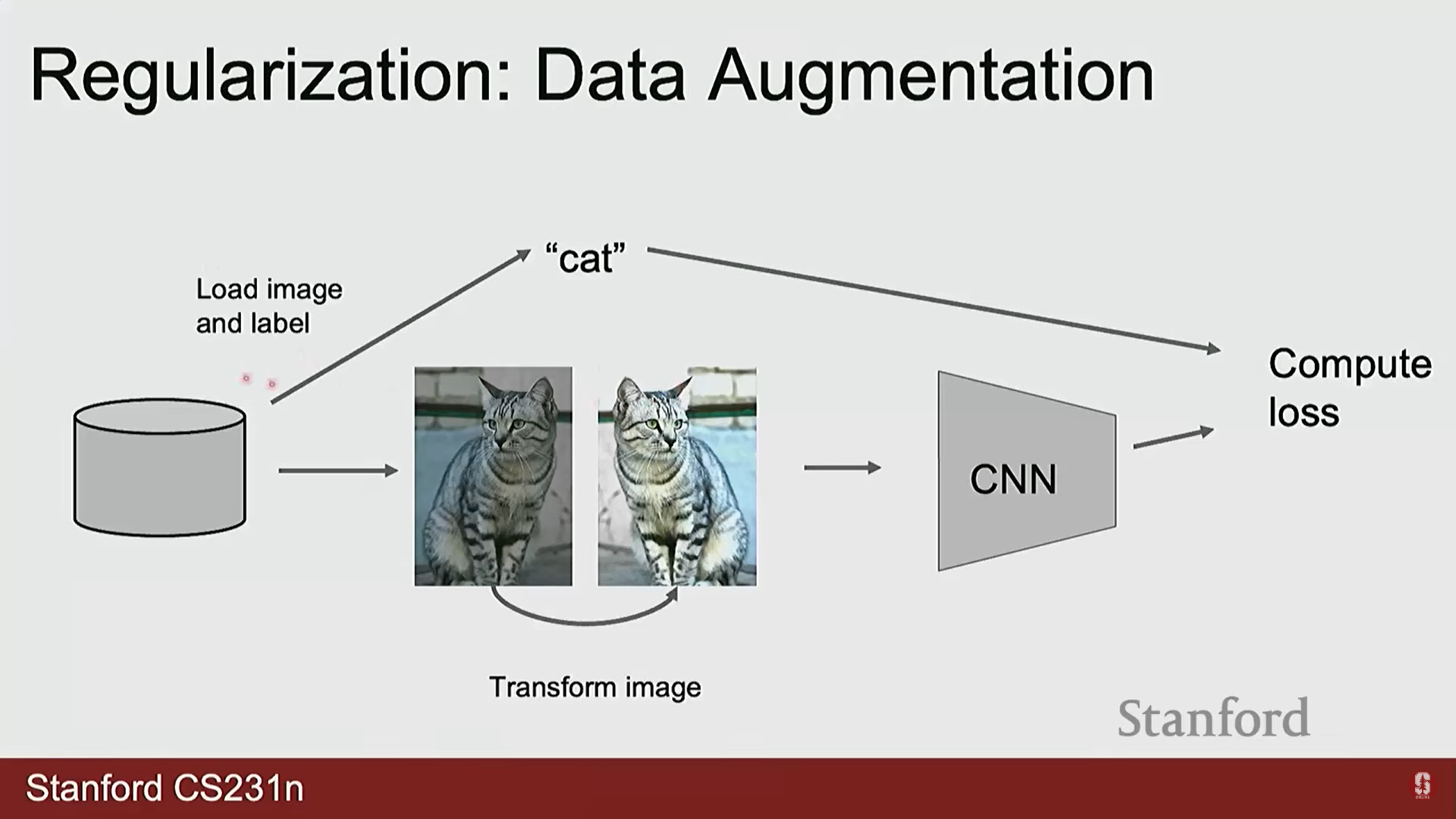



- 주요 기법: 좌우 반전(Horizontal Flipping), 무작위 크기 조절 및 자르기(Random Resized Crop), 색상 변형(Color Jittering), 이미지 일부 가리기(Cutout) 등이 포함됩니다.
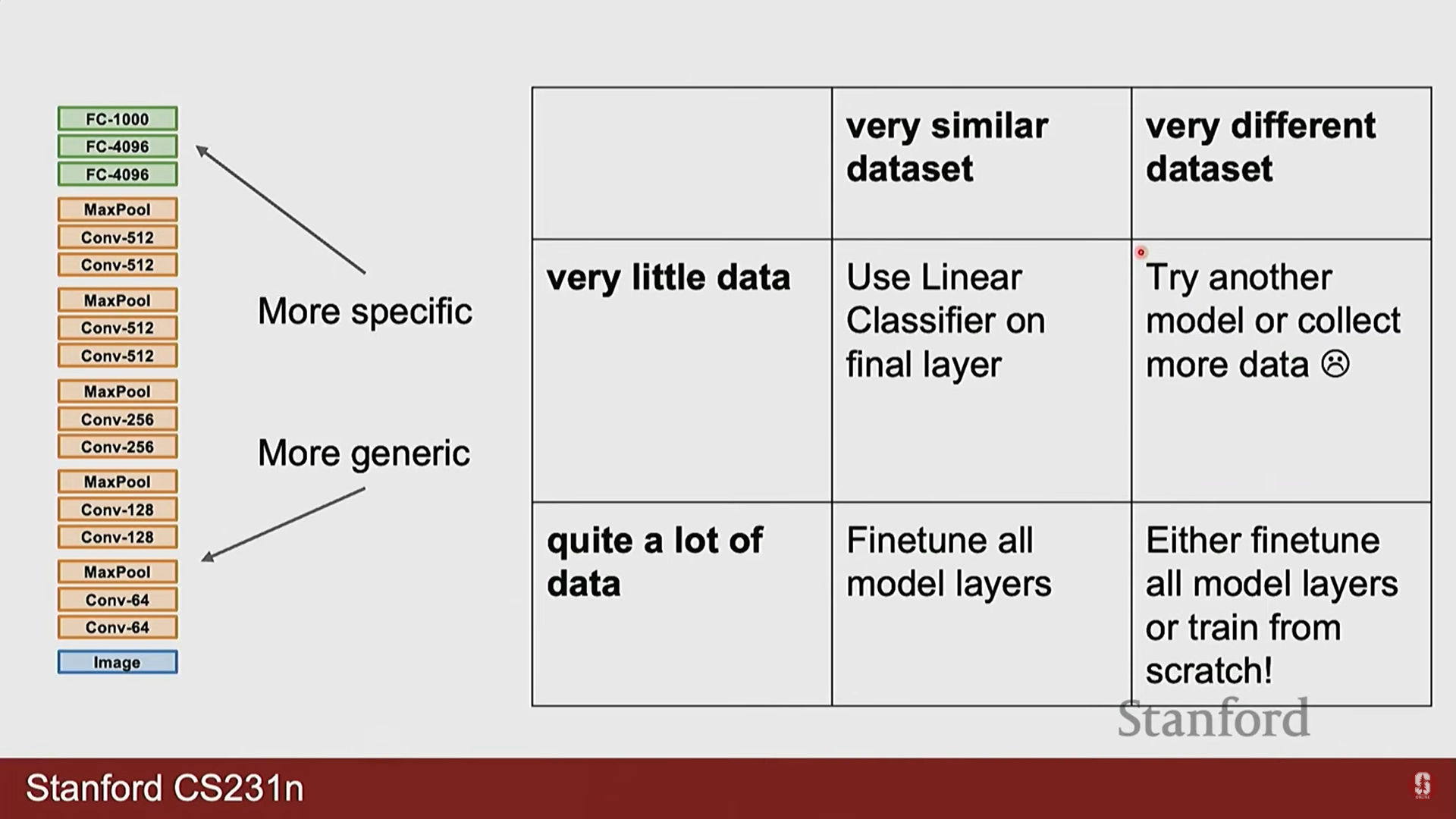
3) 전이 학습 (Transfer Learning)

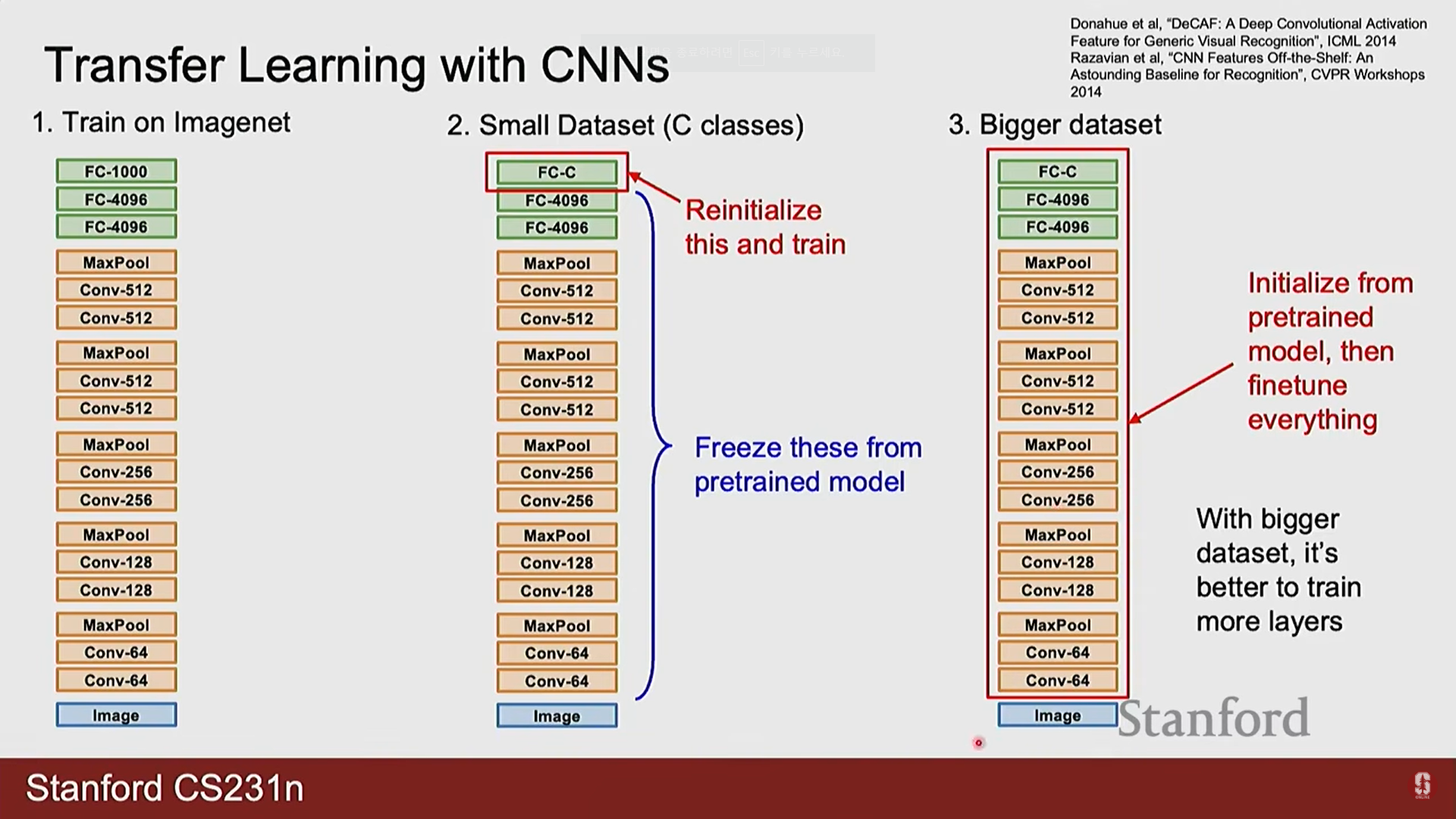
- 전이 학습은 대규모 데이터셋(예: ImageNet)으로 사전에 훈련된 모델의 지식을 새로운 과제에 적용하는 강력한 기법입니다.
- 전략:
- Feature Extractor: 보유한 데이터셋이 작을 경우, 사전 훈련된 모델의 컨볼루션 기반(특징 추출기)은 동결(freeze)하고, 마지막 분류 계층만 새로 훈련합니다.
- Fine-tuning: 보유한 데이터셋이 충분히 클 경우, 모델 전체의 가중치를 새로운 데이터로 미세하게 재조정(미세 조정)하여 성능을 극대화합니다.

4) 하이퍼파라미터 튜닝 (Hyperparameter Tuning)
- 소규모 데이터 과적합 테스트: 본격적인 훈련에 앞서, 한두 개의 배치와 같은 극소량의 데이터로 모델이 100%의 훈련 정확도를 달성하는지 확인합니다. 이는 코드의 논리적 오류를 검증하고 학습률의 적정 범위를 가늠하는 효과적인 디버깅 단계입니다.
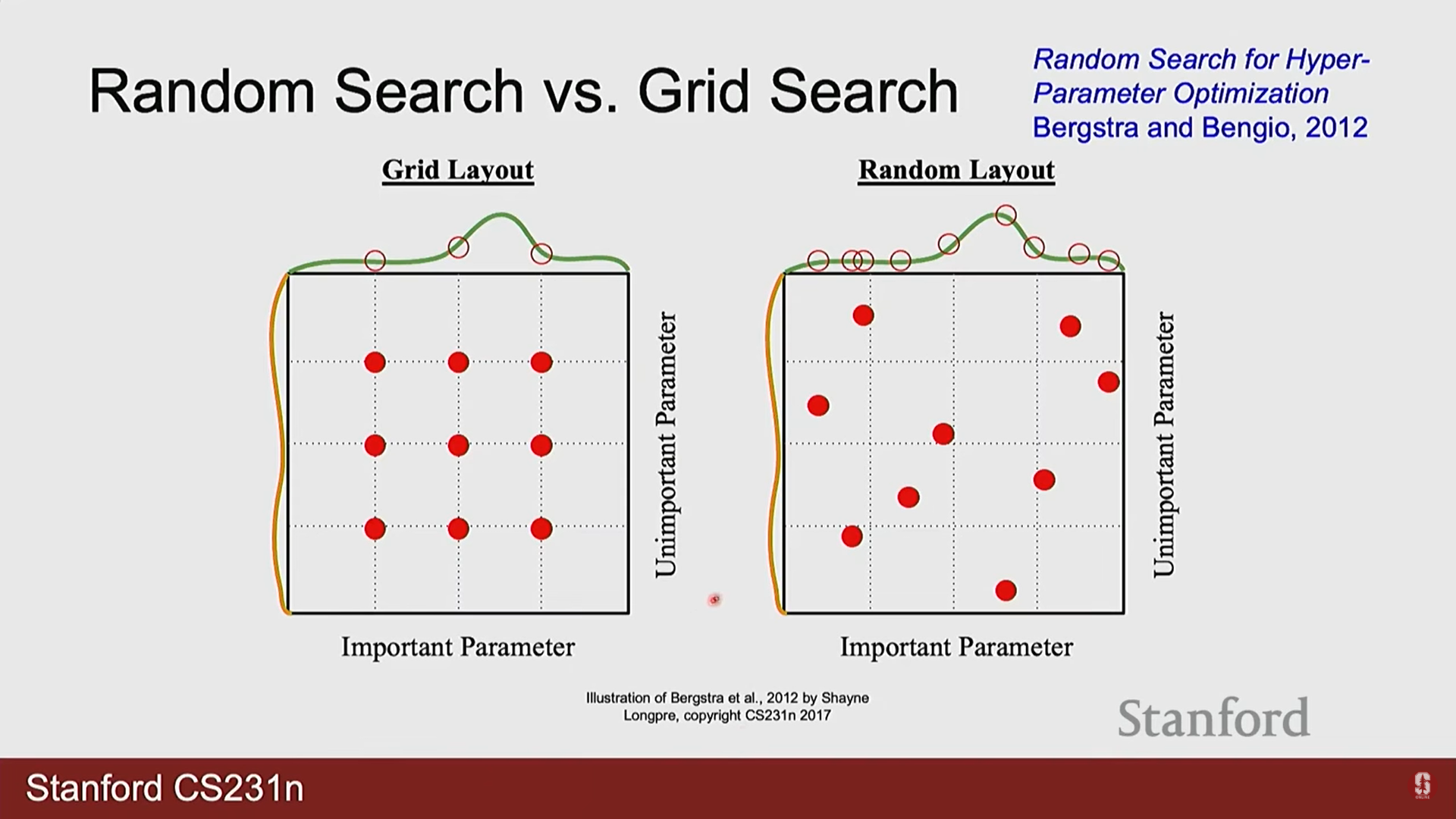
- 랜덤 검색 (Random Search): 정해진 값들의 조합을 모두 시도하는 그리드 검색(Grid Search)보다, 지정된 범위 내에서 하이퍼파라미터 값들을 무작위로 샘플링하는 랜덤 검색이 일반적으로 더 효율적입니다. 이는 일부 하이퍼파라미터가 다른 것들보다 성능에 훨씬 더 큰 영향을 미치기 때문입니다.
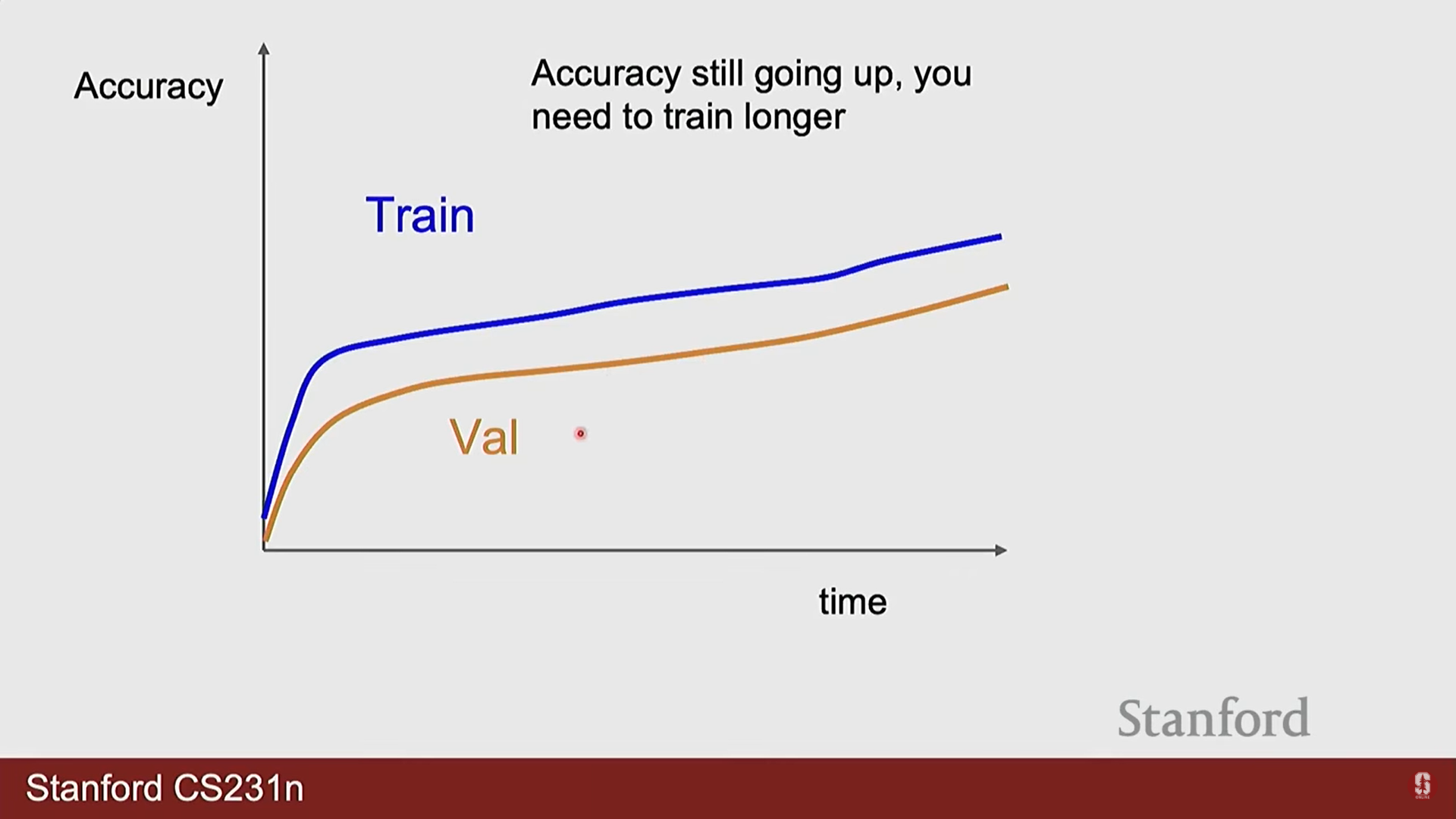
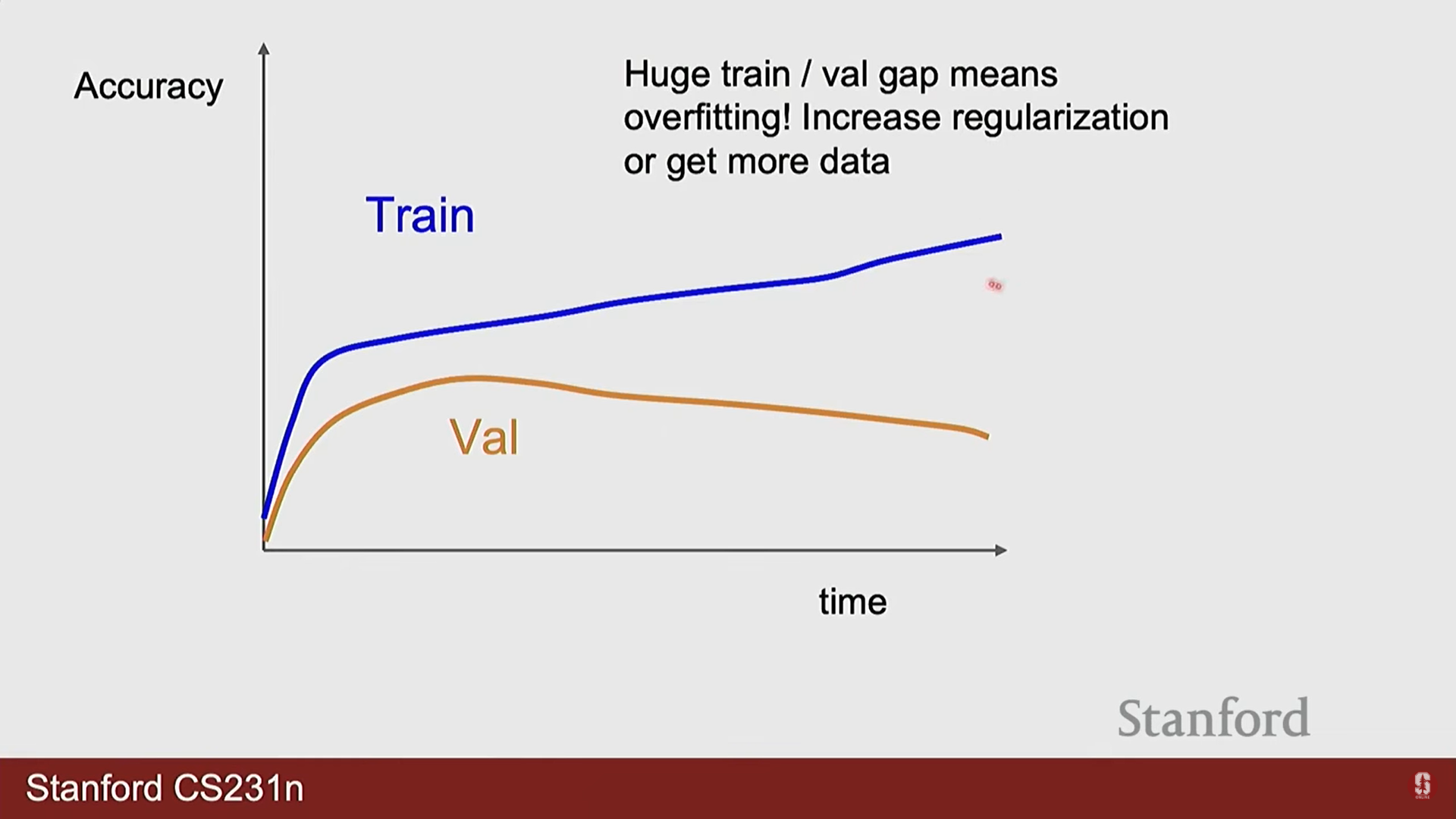
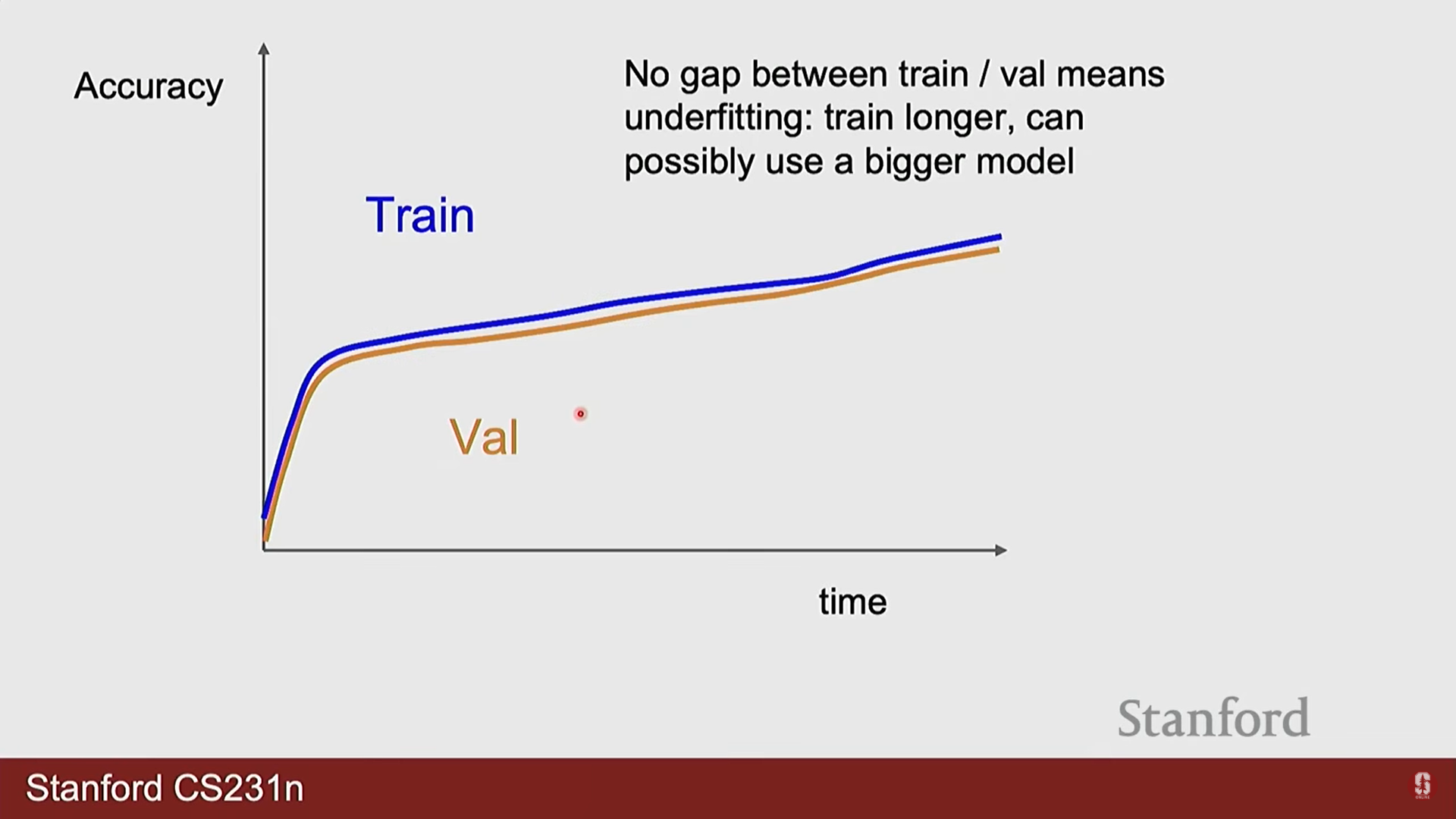
- 학습 곡선 분석: 훈련 및 검증 데이터에 대한 손실(loss)과 정확도(accuracy) 곡선을 시각화하여 모델의 학습 상태를 지속적으로 모니터링해야 합니다. 검증 손실이 증가하기 시작하면 과적합의 신호로 판단할 수 있습니다.



4. 강의 Q&A 심층 분석
1) Q. 컨볼루션 계층 출력의 깊이(depth)는 어떻게 결정됩니까?
- A. 컨볼루션 계층 출력의 깊이는 해당 계층에서 사용된 필터의 개수와 동일합니다. 각 필터는 입력 데이터로부터 서로 다른 종류의 특징을 추출하도록 학습되므로, 6개의 필터를 사용하면 6개의 채널(깊이=6)을 가진 활성화 맵이 생성됩니다. 이 활성화 맵이 다음 컨볼루션 계층의 입력이 됩니다.
2) Q. 드롭아웃(Dropout) 과정에서 특정 뉴런을 비활성화하는 기준은 무엇이며, 역전파는 어떻게 처리됩니까?
- A. 뉴런 비활성화에는 어떠한 특정 기준도 없으며, 완전히 무작위적입니다. 정해진 확률(예: 0.5)에 따라 각 뉴런이 독립적으로 선택됩니다. 역전파 시, 0으로 설정된 뉴런은 해당 경로로 기울기를 전달하지 않습니다. 이는 해당 뉴런과 연결된 가중치가 그 학습 단계에서는 업데이트되지 않음을 의미합니다.
3) Q. 깊은 모델이 얕은 모델보다 성능이 저하되는 퇴화(Degradation) 문제는 더 긴 훈련 시간으로 해결할 수 없습니까?
- A. 해결되지 않았습니다. 이 문제는 과적합이 아니라, 네트워크가 불필요하게 깊어지면서 최적화가 극도로 어려워지는 현상입니다. 심층 모델이 경사 하강법 과정에서 좋지 않은 지역 최솟값(local minimum)에 빠지기 쉬우며, 잔차 연결(residual connection)은 이러한 최적화 경로를 단순화하여 문제를 완화합니다.
4) Q. ResNet의 잔여 블록에서 덧셈 연산을 위해 텐서의 크기는 항상 동일해야 합니까?
- A. 네, 그렇습니다. 요소별 덧셈(element-wise addition)을 위해서는 입력 와 잔여 매핑의 출력 의 텐서 차원이 정확히 일치해야 합니다. 이를 위해 ResNet 블록 내의 컨볼루션 연산은 주로 스트라이드 1, 패딩 1을 사용하여 공간적 차원을 보존합니다. 풀링 등으로 차원이 변경되는 지점에서는 차원을 맞춰주기 위한 추가적인 기법(예: 1x1 컨볼루션)이 사용됩니다.
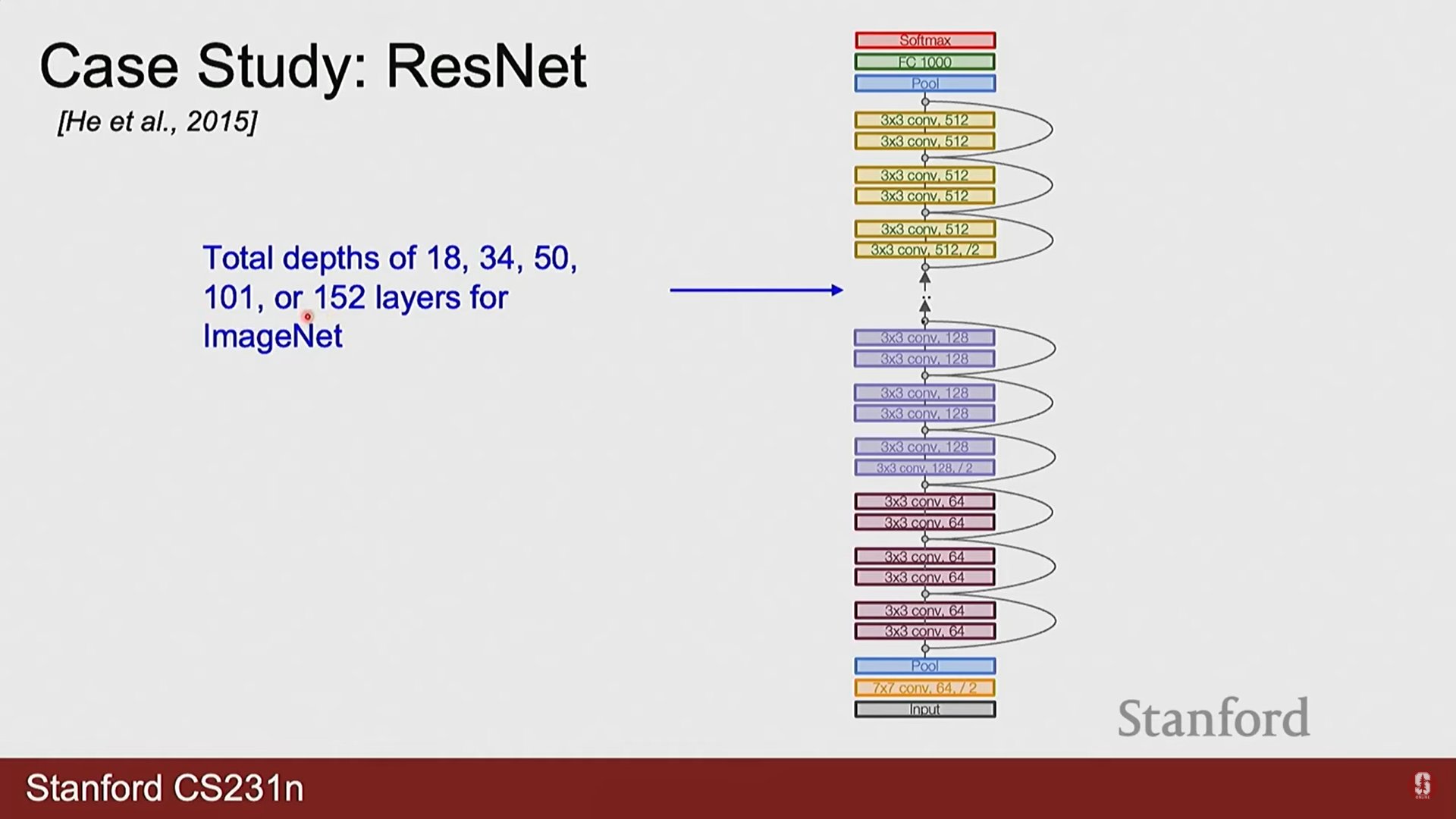
5) Q. ResNet과 같은 아키텍처의 레이어 수(예: 152)는 어떻게 결정되었습니까?
- A. 이는 주로 경험적 실험을 통해 결정됩니다. 연구자들은 다양한 깊이의 모델(18, 34, 50, 101, 152 등)을 구성하여 성능을 비교했고, 특정 지점부터는 깊이를 늘려도 성능 향상이 미미해지거나(diminishing returns) GPU 메모리 같은 계산 자원의 한계에 도달하게 됩니다. 152는 이러한 실험 결과와 자원 제약을 고려한 선택입니다.
6) Q. 가중치 초기값이 너무 클 경우 활성화 값이 폭주(exploding)하는 수학적 이유는 무엇입니까?
- A. 선형 계층의 연산을 라고 가정해 봅시다. 만약 가중치 의 원소들이 큰 분산으로 초기화되고, ReLU와 같이 출력을 제한하지 않는 활성화 함수를 통과하면 각 계층을 지날 때마다 출력의 분산이 기하급수적으로 커질 수 있습니다. 이는 재귀 관계와 유사하게 작용하여, 수치적 불안정성을 초래하고 학습을 불가능하게 만듭니다.
7) Q. 전이 학습 시, 사전 훈련 데이터와 현재 데이터의 분포가 다를 경우(Out-of-Distribution)의 대처 방안은 무엇입니까?
- A. 이는 도메인 적응(Domain Adaptation)과 관련된 중요한 문제입니다. 만약 보유한 데이터가 충분히 많다면, 사전 훈련된 가중치를 초기값으로 사용하여 전체 모델을 미세 조정(Fine-tuning)하는 것이 효과적일 수 있습니다. 데이터가 매우 적고 분포 차이가 크다면, ImageNet과 같은 일반적인 데이터셋보다 현재 데이터와 더 유사한 도메인의 데이터로 사전 훈련된 모델을 찾는 것이 더 나은 출발점이 될 수 있습니다.
8) Q. 전이 학습 시 마지막 계층만 훈련하는 것과 전체를 훈련하는 것 사이에 다른 대안이 존재합니까?
- A. 네, 존재합니다. 예를 들어, LoRA(Low-Rank Adaptation)와 같은 파라미터 효율적 미세 조정(PEFT) 기법들은 원본 가중치는 동결한 채, 각 계층에 소수의 학습 가능한 파라미터를 추가하여 적은 비용으로 모델을 적응시키는 방법입니다. 이는 전체 미세 조정과 특징 추출기의 중간에 해당하는 효율적인 접근법입니다.

AI 공부합니다