1. Transformer 재검토 및 Vision Transformer (ViT)의 등장
1) Transformer 아키텍처 복습
- 기존의 RNN 기반 시퀀스-투-시퀀스 모델의 한계를 극복하기 위해 등장한 Transformer는 멀티 헤드 셀프 어텐션(Multi-Head Self-Attention) 메커니즘을 핵심으로 사용합니다.
- 셀프 어텐션은 시퀀스 내의 모든 토큰들이 서로 어떻게 상호작용하는지를 한 번에 계산하여, 장거리 의존성 문제를 해결하고 병렬 처리를 가능하게 합니다.
- (수학적 내용) 셀프 어텐션의 핵심 연산인 Scaled Dot-Product Attention은 다음과 같은 수식으로 표현됩니다.
- Q (Query), K (Key), V (Value): 입력된 토큰 벡터 시퀀스로부터 생성된 세 가지 벡터입니다. 각 토큰은 자신의 '쿼리'를 모든 토큰의 '키'와 내적하여 연관도를 계산합니다.
- : Key 벡터의 차원()에 제곱근을 취한 값으로 나누어 스케일링하여 학습을 안정화시킵니다.
- softmax: 계산된 연관도 점수를 합이 1인 확률 분포(어텐션 가중치)로 변환합니다.
- 최종적으로 이 어텐션 가중치를 Value 벡터와 가중합하여 해당 토큰의 최종 출력값을 얻습니다.
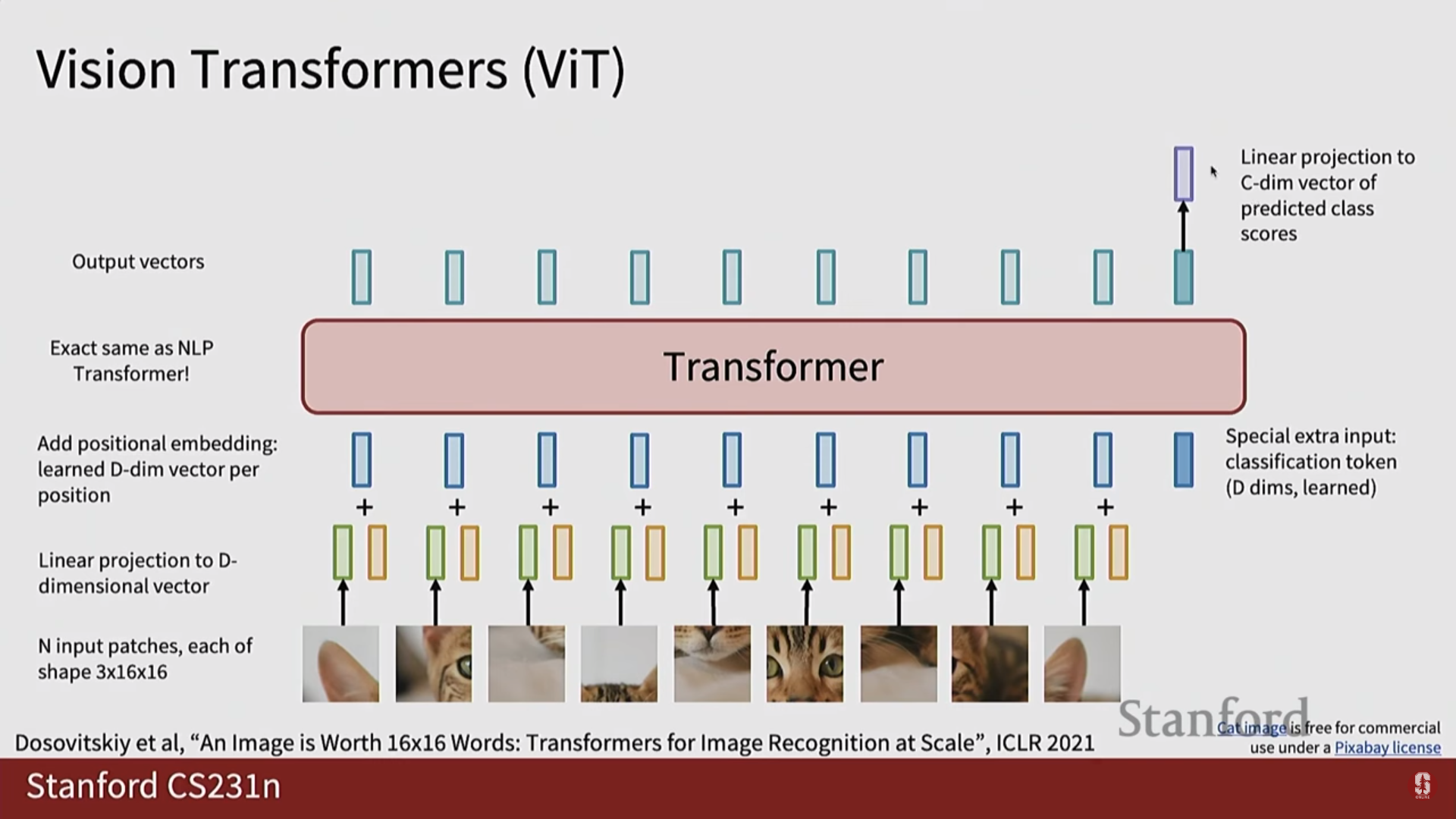
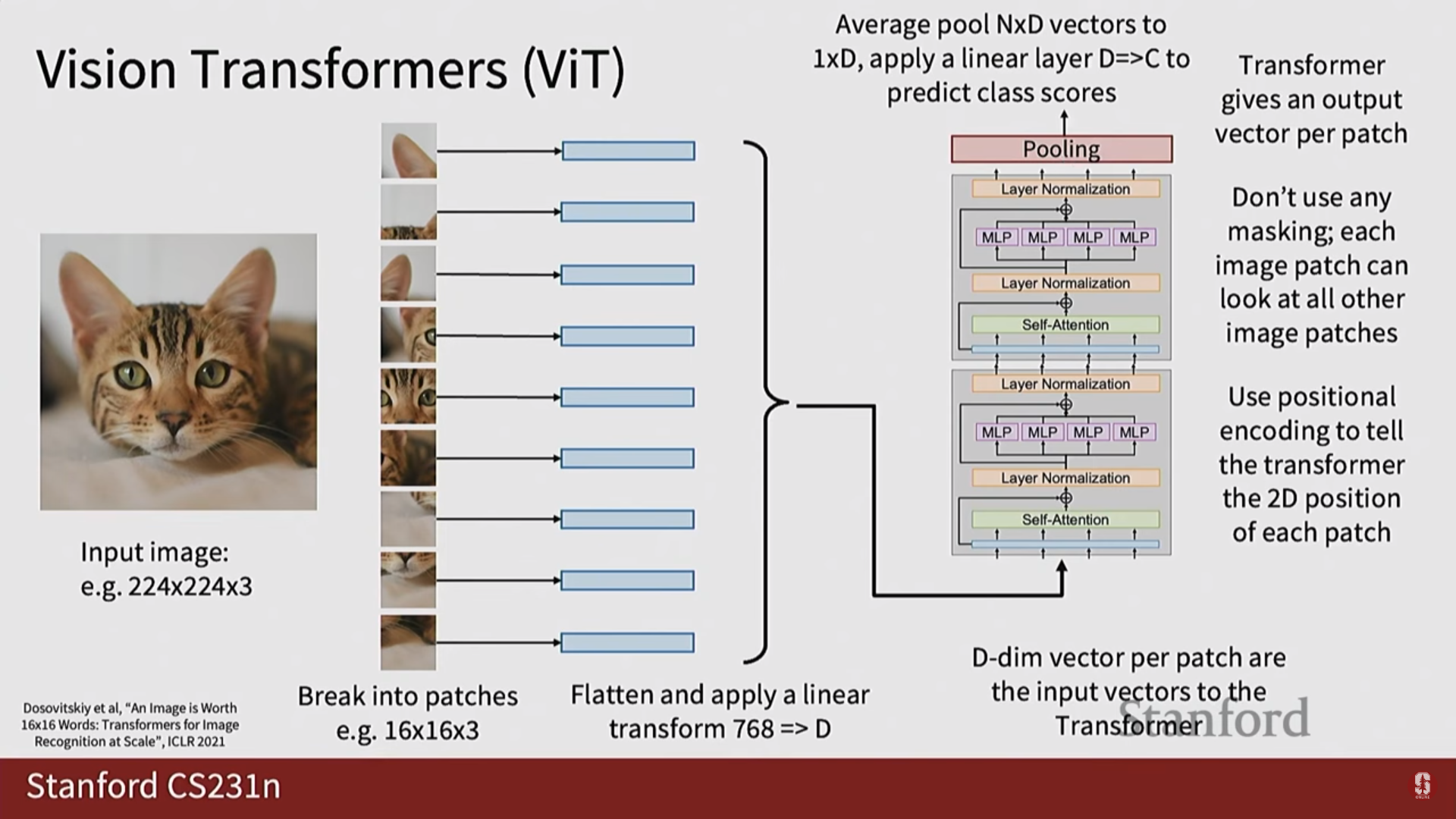
2) Vision Transformer (ViT) 상세 설명
Vision Transformer(ViT)는 Transformer 아키텍처를 이미지 인식 문제에 적용한 모델입니다.
- 이미지 패치화 (Image Patching): ViT는 이미지를 바둑판처럼 고정된 크기의 여러 작은 패치(patch)로 자릅니다.
- 패치 임베딩 (Patch Embedding): 각 이미지 패치는 1차원 벡터로 펼쳐진(flatten) 후, 학습 가능한 선형 투영(linear projection)을 통해 Transformer가 처리할 수 있는 벡터(토큰)로 변환됩니다.
- 위치 임베딩 (Positional Embedding): 패치로 나누는 과정에서 사라진 위치 정보를 보완하기 위해, 학습 가능한 위치 임베딩 벡터를 각 패치 토큰에 더해줍니다.
- (수학적 내용) 이 과정은 수식으로 와 같이 표현할 수 있습니다.
- 분류 토큰 (
[CLS]Token): 이미지 전체를 대표하는 특징을 학습하기 위해, 패치 토큰 시퀀스의 맨 앞에 특별한 분류([CLS]) 토큰을 추가합니다. - MLP 블록 구조: Transformer 인코더 내의 MLP 블록은 2개의 선형 레이어와 그 사이의 GELU 활성화 함수로 구성됩니다. 첫 번째 레이어는 차원을 확장하고, 두 번째 레이어는 다시 축소하는 구조를 가집니다.
심화 내용: Vision Transformer (ViT)
- 기술적 배경: ViT는 NLP에서 검증된 Transformer의 셀프 어텐션 메커니즘이 이미지의 전역적인 컨텍스트를 이해하는 데 효과적일 것이라는 아이디어에서 출발했습니다.
- 최신 동향: 초기 ViT는 대규모 데이터셋에서 사전 훈련해야만 좋은 성능을 보였지만, Swin Transformer 등 최신 모델들은 일반 데이터셋에서도 뛰어난 성능을 보입니다.
- 명확한 한계점: ViT는 CNN에 비해 데이터 효율성(data efficiency)이 떨어지는 경향이 있으며, 고해상도 이미지를 처리할 때 계산 복잡도가 제곱으로 증가하는 문제점을 가집니다.
- (깊이 있는 내용 추가) 귀납적 편향 (Inductive Bias)의 부재: CNN은 지역성(Locality)과 평행 이동 등변성(Translation Equivariance)이라는 강력한 귀납적 편향을 내장하고 있습니다. 즉, '픽셀들은 주변 픽셀과 연관이 깊다'는 가정을 구조 자체에 가지고 있어 적은 데이터로도 효율적인 학습이 가능합니다. 반면 ViT는 이러한 가정이 없어 모든 패치가 동등한 관계로 시작하므로, 데이터로부터 이미지의 구조 자체를 학습해야 해서 훨씬 더 많은 데이터를 필요로 합니다.
- (깊이 있는 내용 추가) 사전학습-미세조정 전략: ViT는 JFT-300M이나 ImageNet-21k와 같은 대규모 데이터셋으로 먼저 사전학습(pre-training)을 진행한 후, ImageNet-1k나 CIFAR-100 같은 더 작은 목표 데이터셋에 맞게 미세조정(fine-tuning)하는 전략을 통해 성능을 극대화합니다.
2. Transformer 모델 최적화
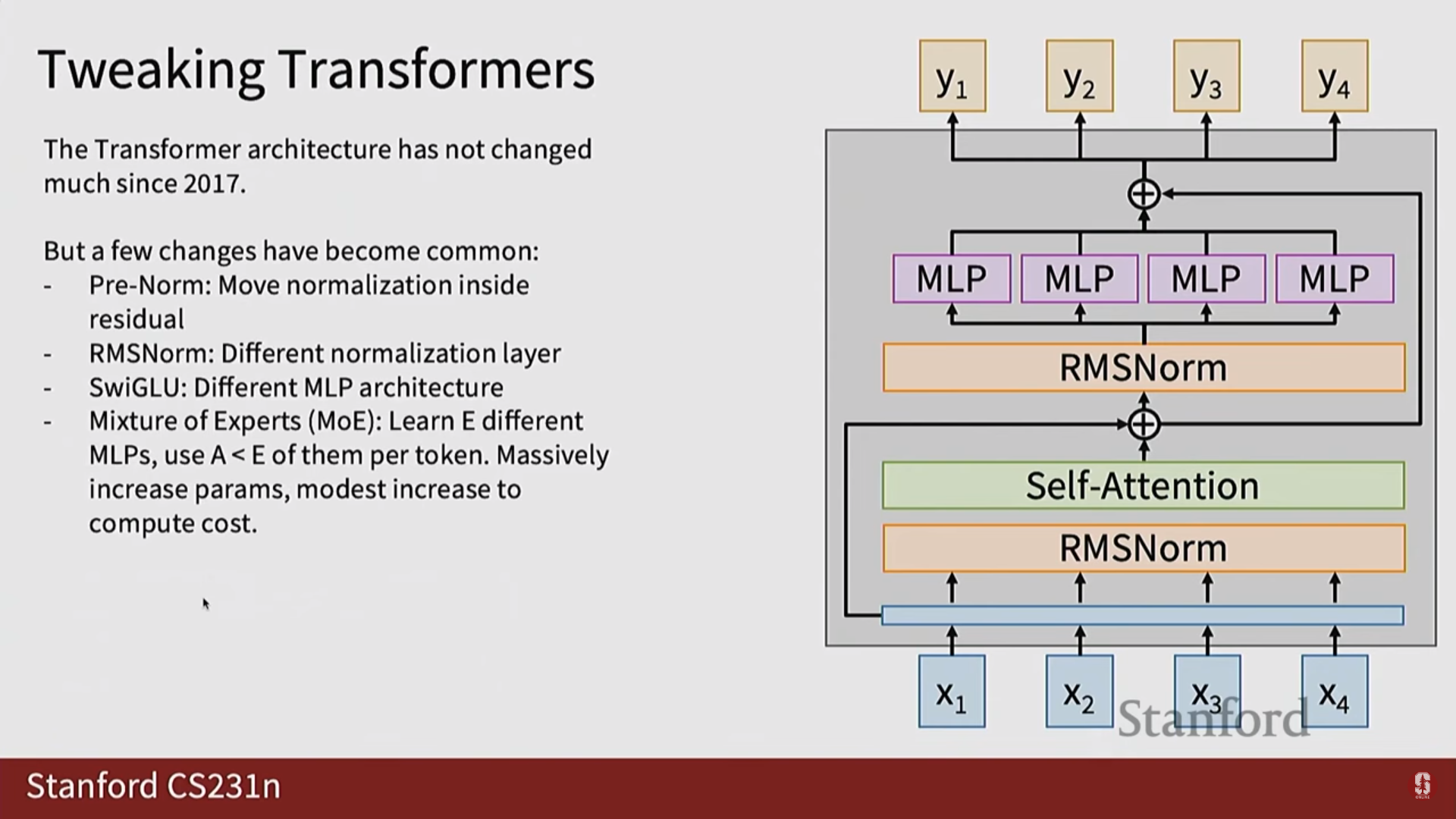
1) 훈련 안정성 및 성능 향상 기법
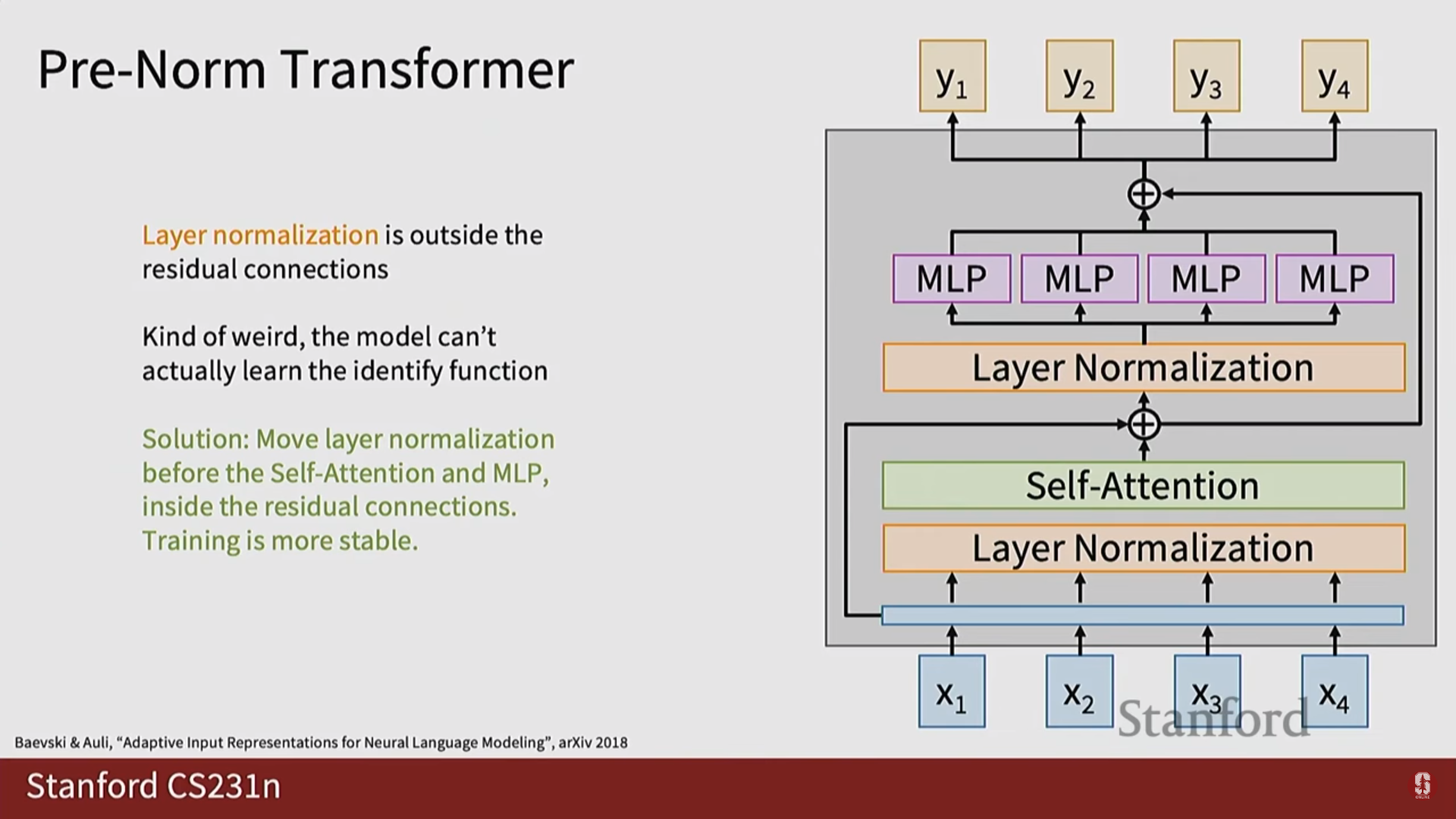
- Pre-Norm Layer Normalization: 서브 레이어에 입력을 넣기 전에 레이어 정규화를 적용하여 깊은 모델의 훈련 불안정성 문제를 해결합니다.
- 잔차 연결 (Residual Connection): 레이어의 입력을 출력에 더해주는 방식으로, 기울기 소실 문제를 완화합니다.
- RMS 정규화 (RMS Normalization): 기존의 레이어 정규화를 단순화하여 계산 효율성을 높인 기법입니다.
- 게이트된 비선형성 (Gated Nonlinearity): SwiGLU와 같은 활성화 함수를 사용하여 MLP 레이어의 성능을 향상시킵니다.
- 전문가 혼합 (Mixture of Experts): 모델의 특정 부분을 희소하게 활성화하여, 모델의 크기를 키우면서도 계산 비용을 효율적으로 관리합니다.
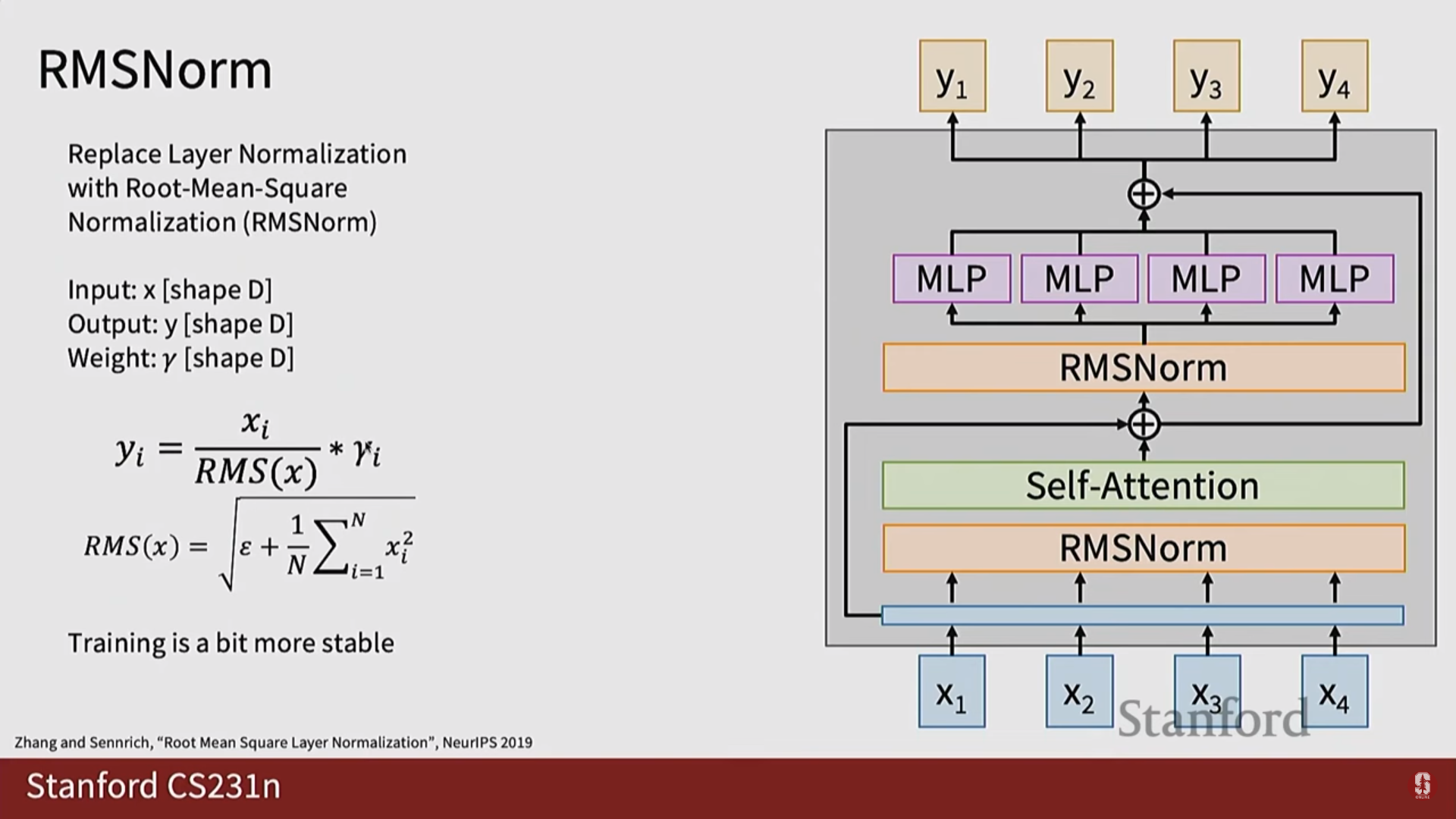
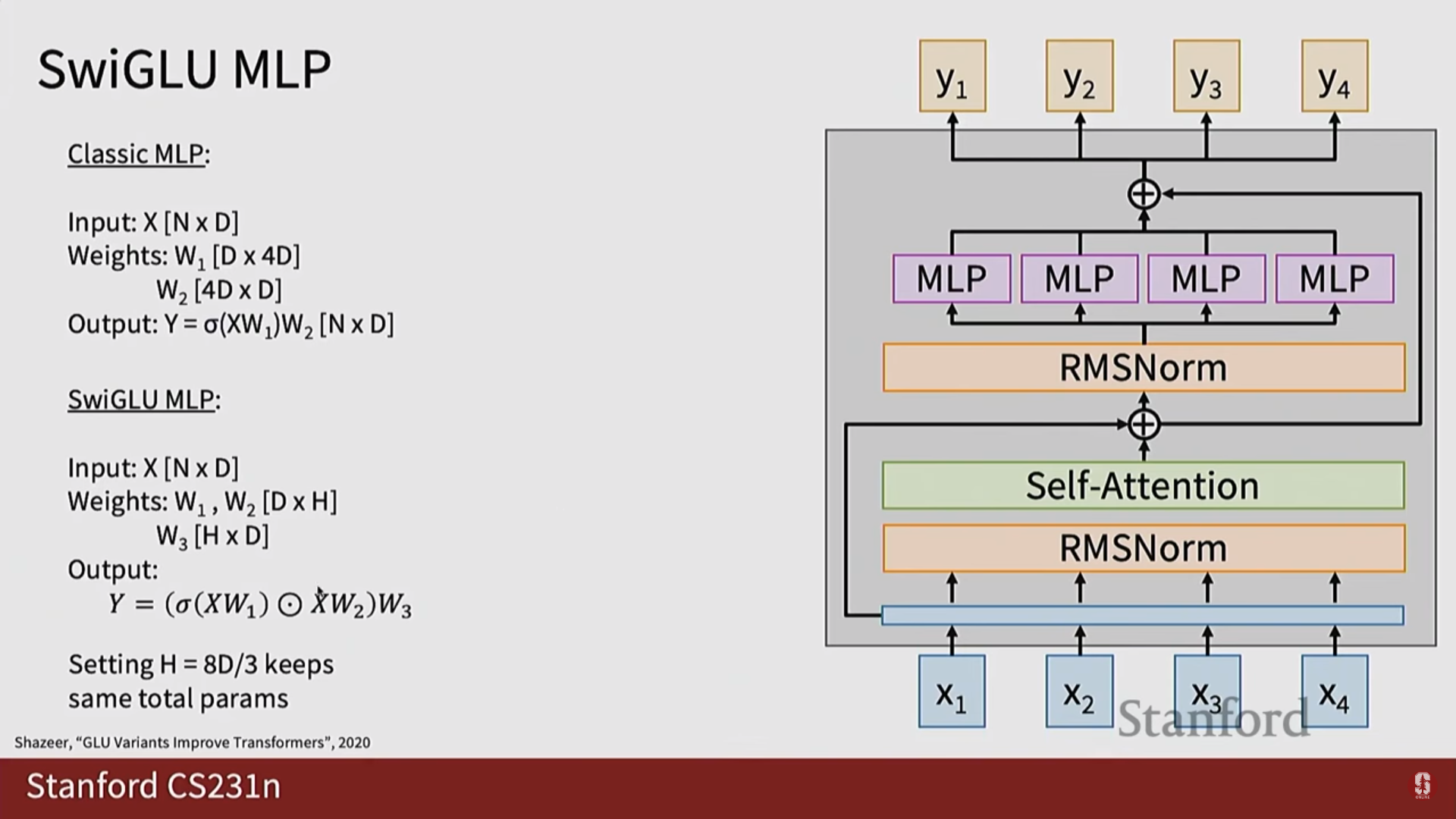
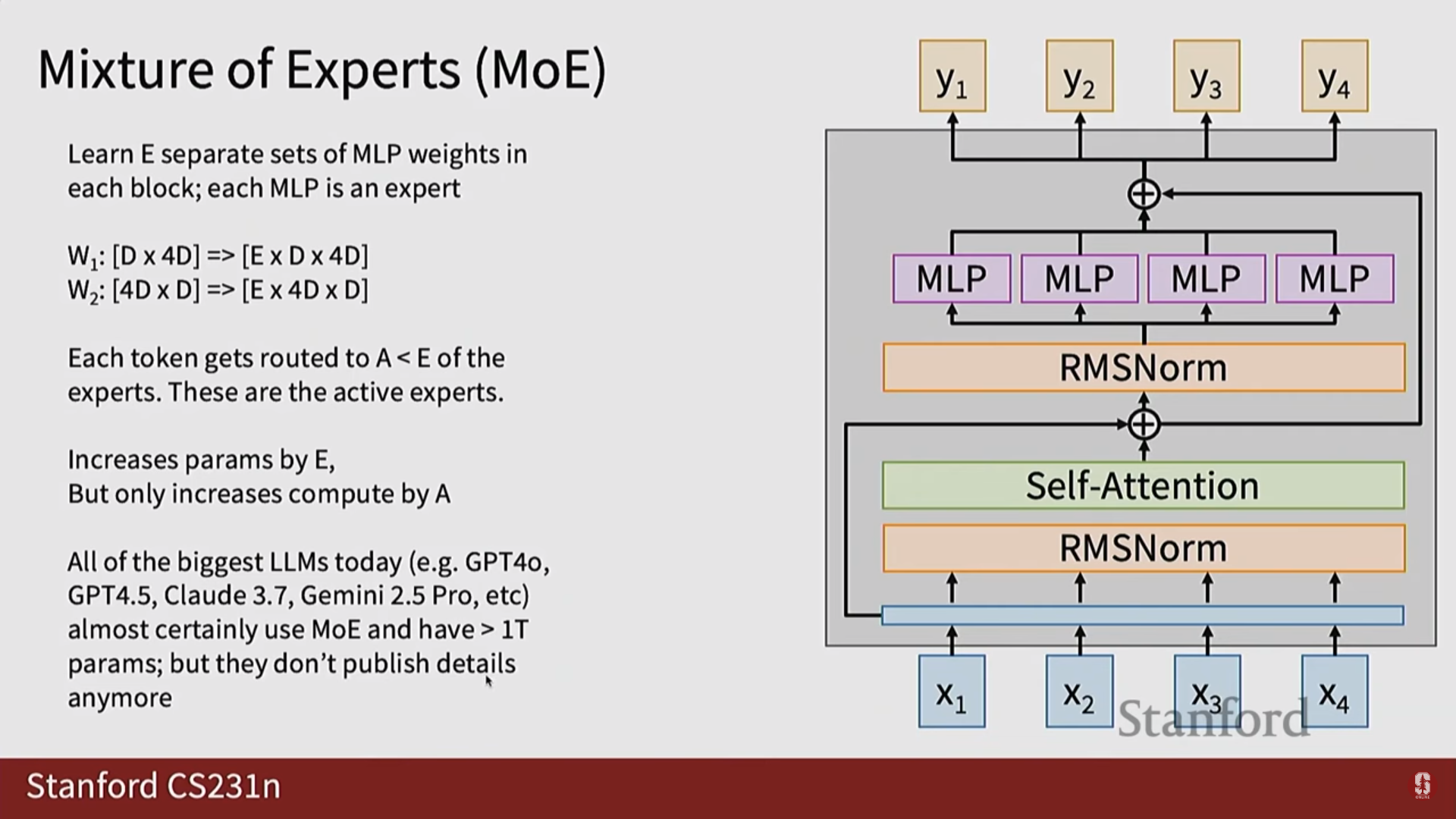
3. 의미론적 분할 (Semantic Segmentation)

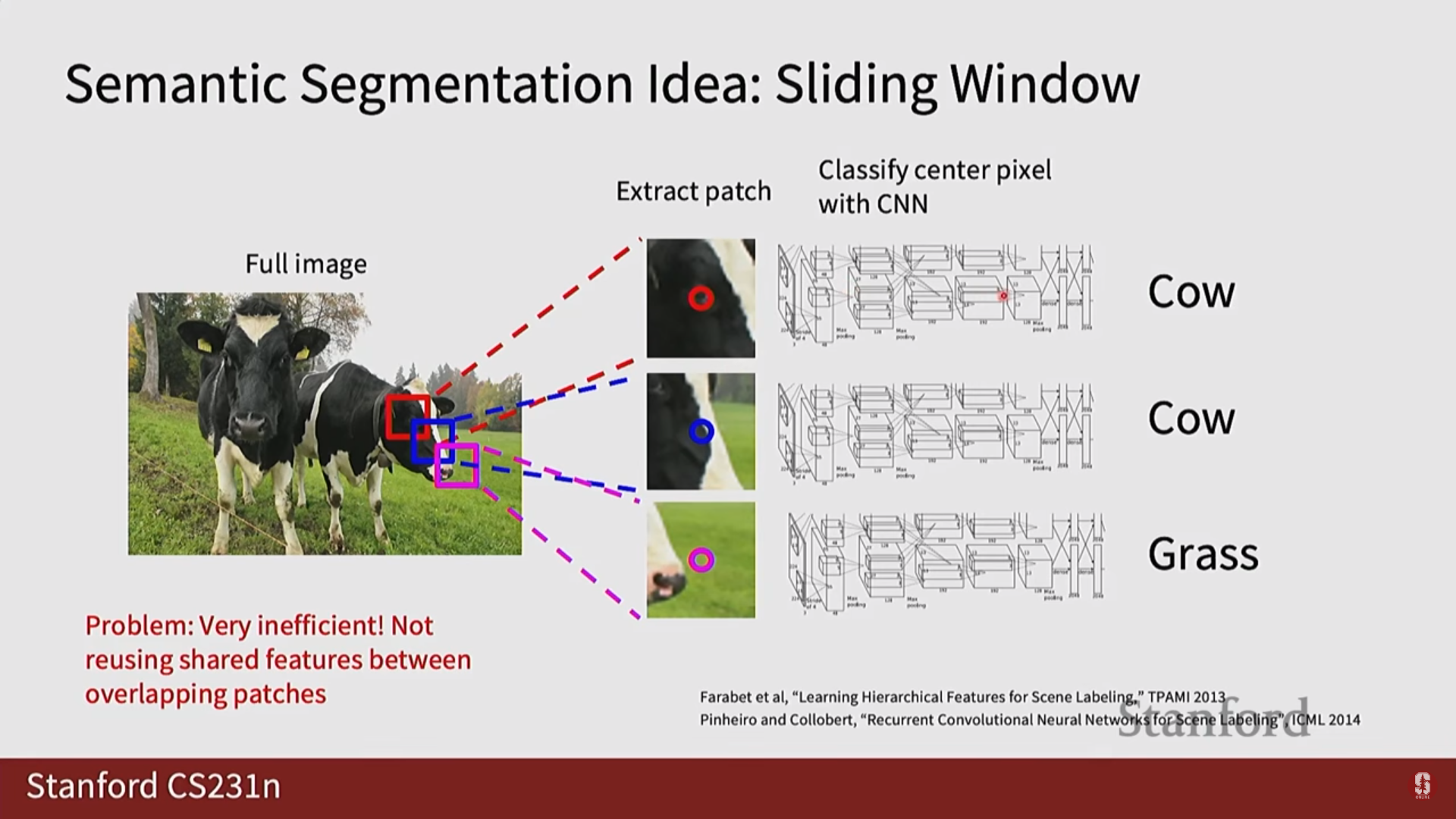

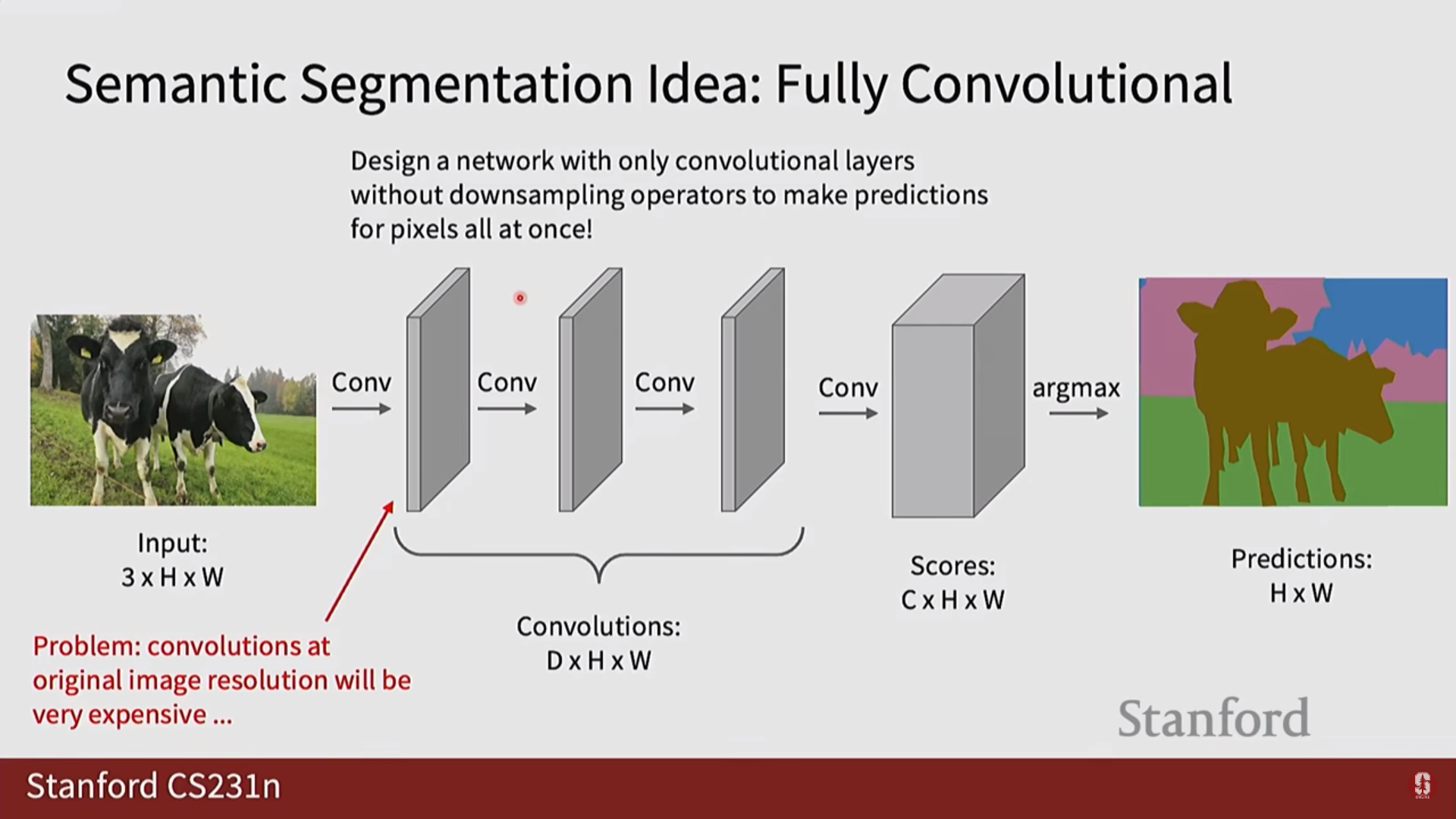
- 손실 함수: 각 픽셀을 독립적인 데이터로 보고 분류 문제를 푸는 것과 같으므로, 일반적으로 각 픽셀에 대해 Cross-Entropy Loss를 계산하여 사용합니다.
- (수학적 내용) 픽셀 에 대한 Cross-Entropy Loss는 입니다.
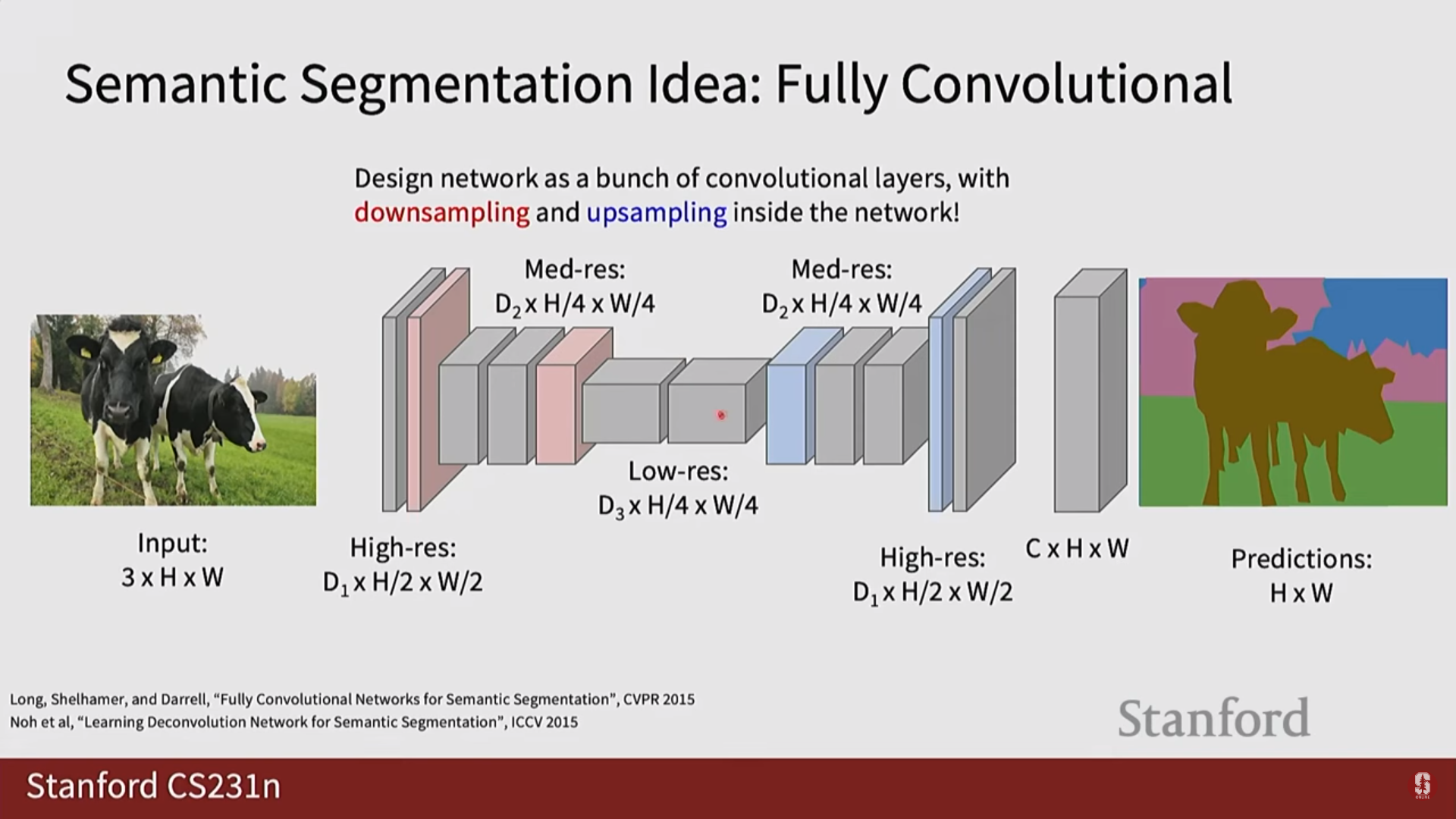
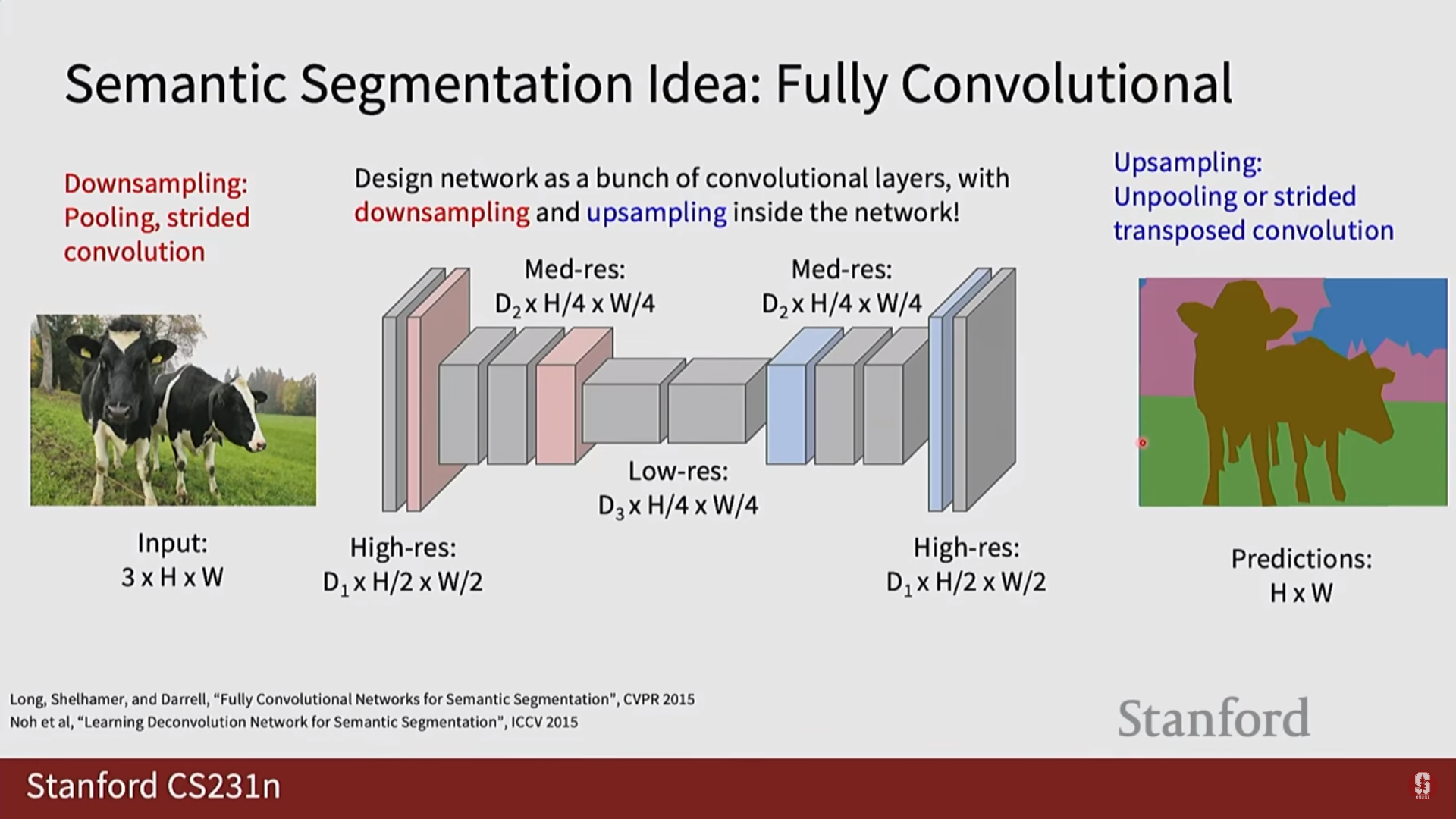
1) 다운샘플링과 업샘플링 (Downsampling & Upsampling)
- 의미론적 분할 모델은 보통 인코더-디코더 구조를 가집니다.
- 인코더에서는 컨볼루션과 풀링을 통해 특징 맵의 해상도를 줄여나가고(다운샘플링), 디코더에서는 줄어든 해상도를 다시 원래 이미지 크기로 키우는(업샘플링) 과정이 필요합니다.
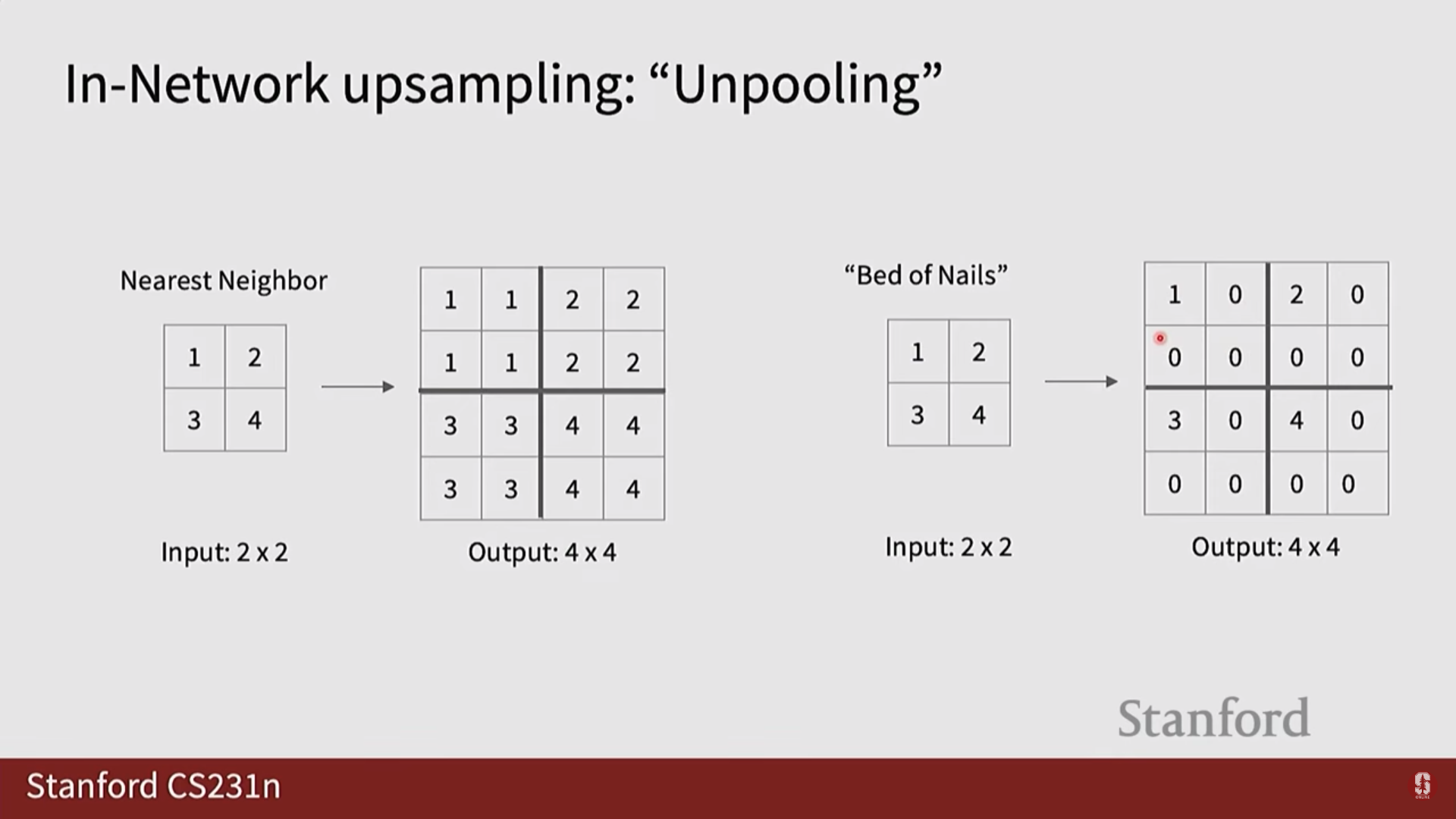
업샘플링 기법 종류
- 최근접 이웃 / 이중 선형 보간법 (Nearest Neighbor / Bilinear Interpolation): 가장 단순한 방식으로, 학습할 파라미터 없이 고정된 규칙에 따라 픽셀 값을 복제하거나 주변 픽셀 값을 보간하여 해상도를 키웁니다.
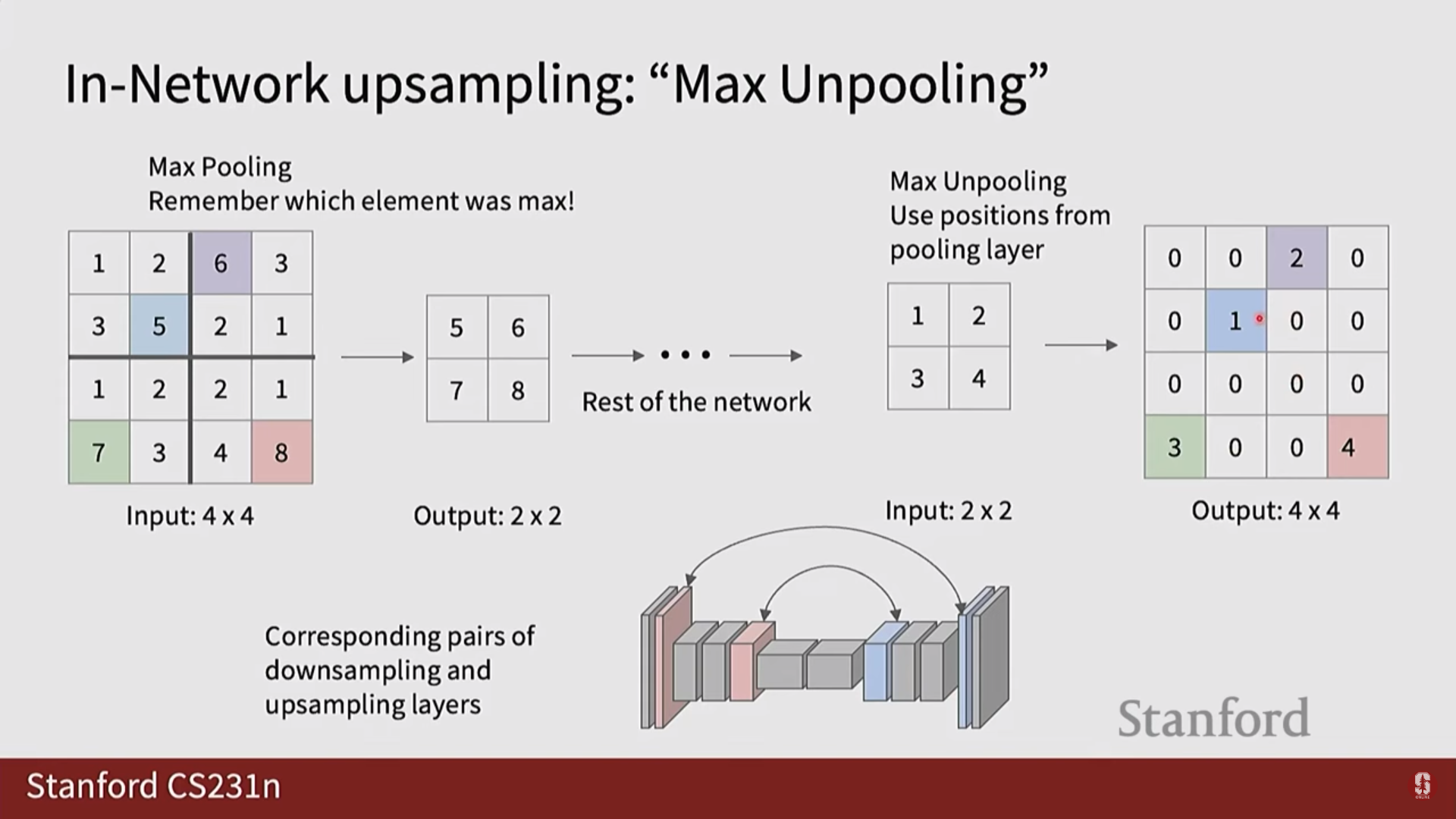
- Max Unpooling: Max Pooling 연산을 거꾸로 되돌리는 기법입니다. Pooling 과정에서 가장 컸던 값의 위치(index)를 기억해두었다가, 그 위치에만 값을 복원하고 나머지는 0으로 채우는 방식입니다. 원본 위치 정보를 활용하는 장점이 있습니다.
- 전치 컨볼루션 (Transpose Convolution): '학습 가능한 업샘플링'이라고도 불립니다. 일반 컨볼루션 연산을 반대로 수행하는 것처럼 보이며, 학습 가능한 커널을 통해 네트워크가 데이터로부터 최적의 업샘플링 방법을 스스로 학습하도록 합니다. 가장 널리 사용되며 일반적으로 가장 좋은 성능을 보입니다.
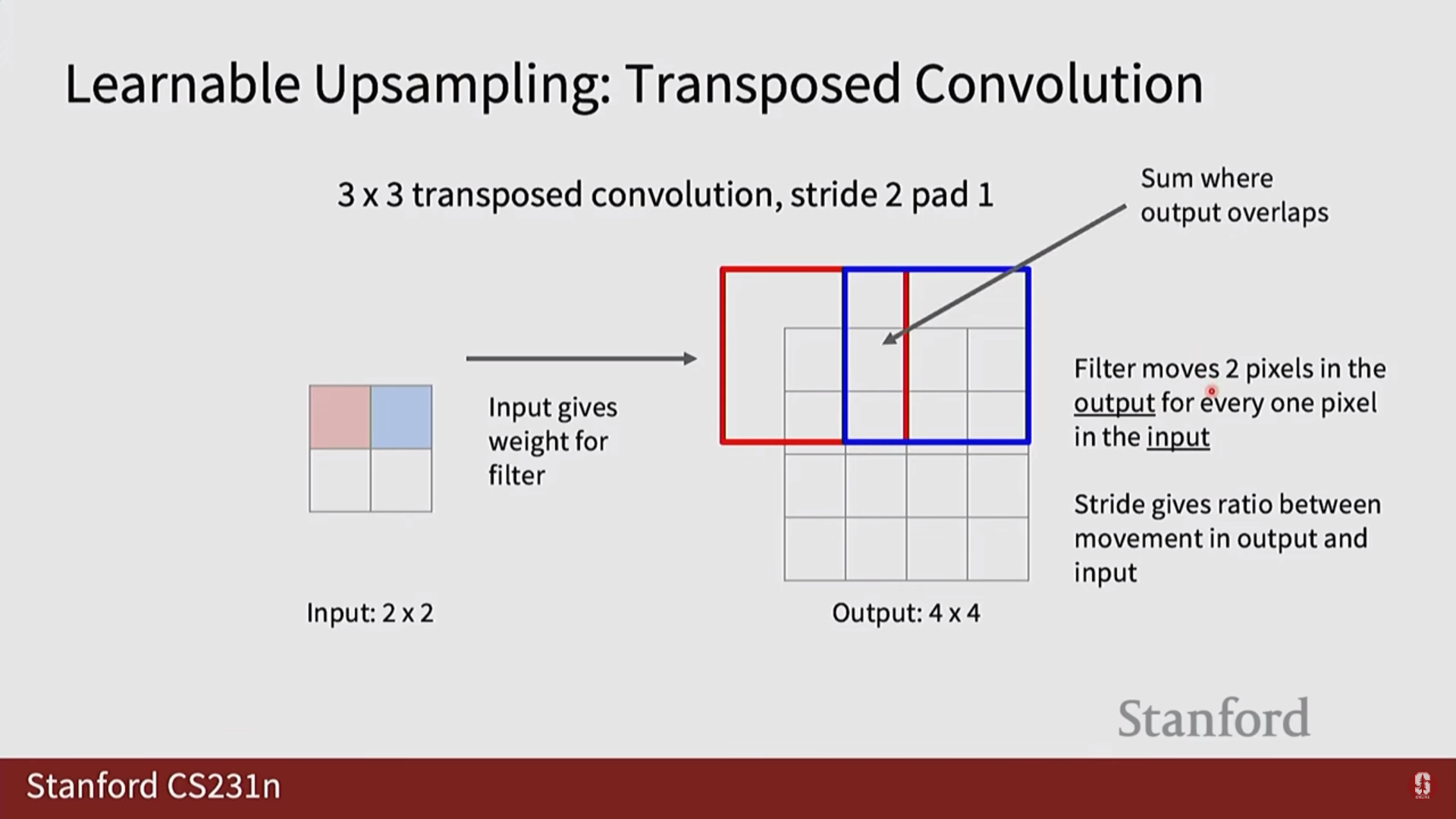
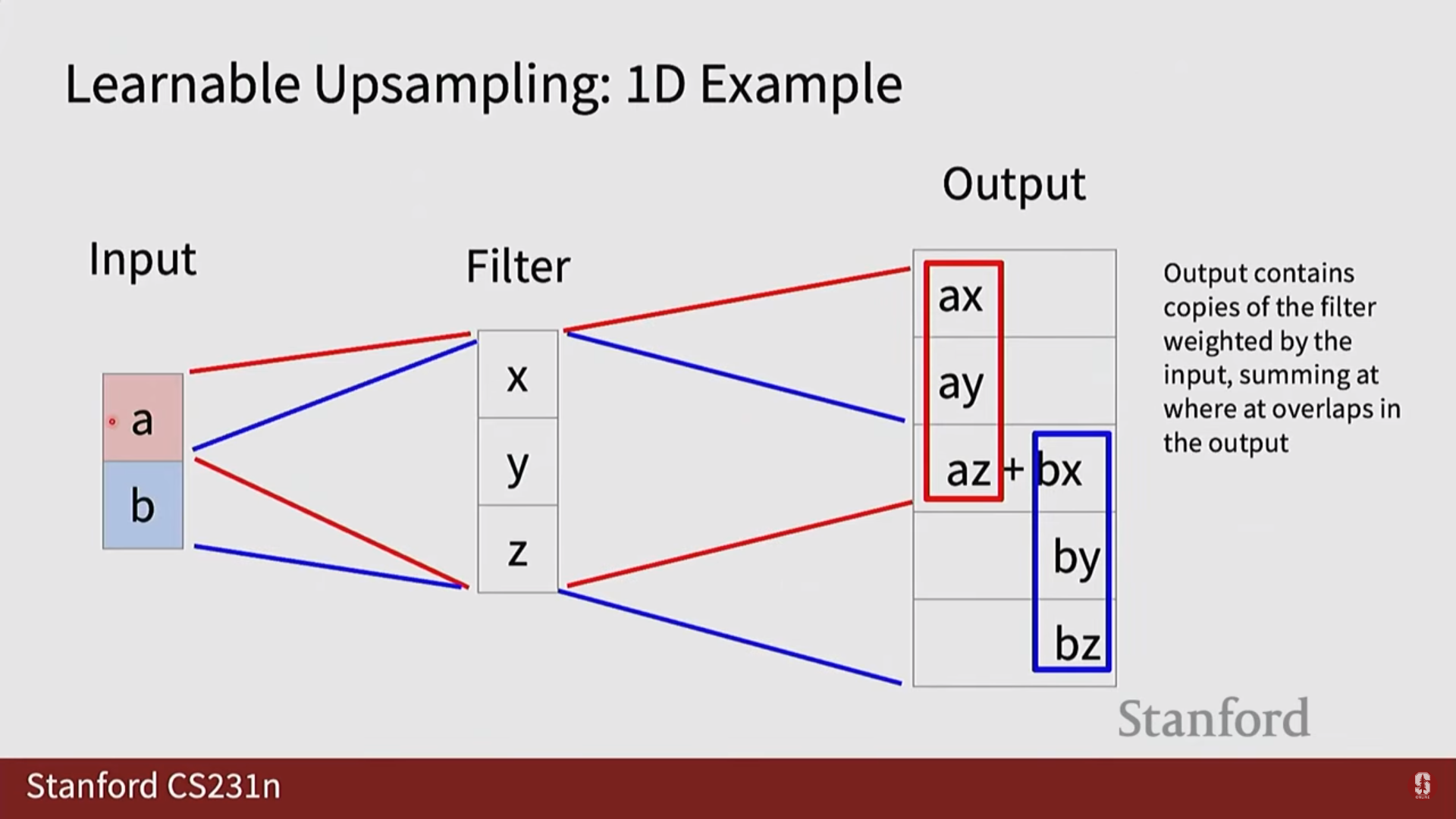
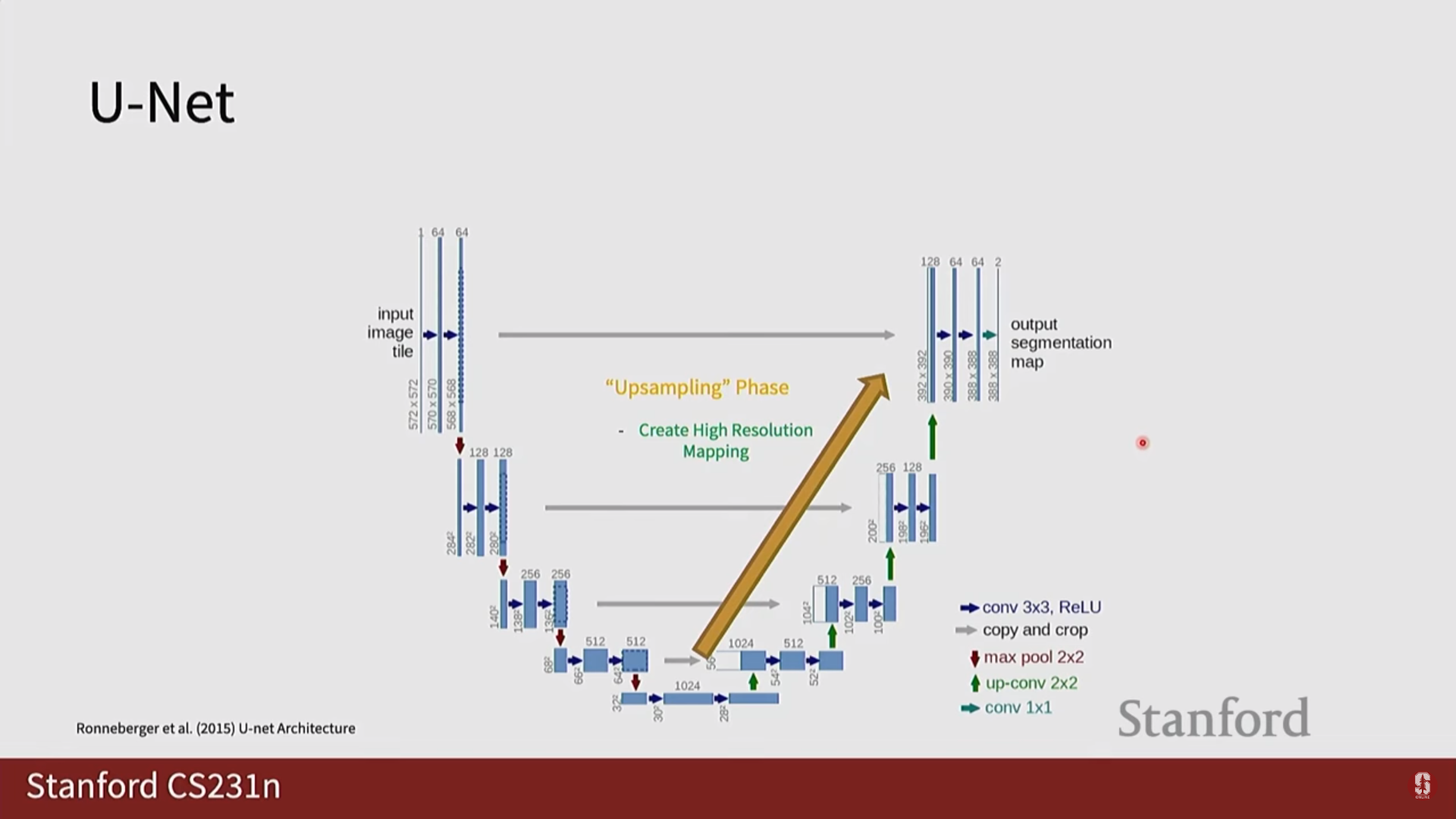
2) U-Net 상세 설명
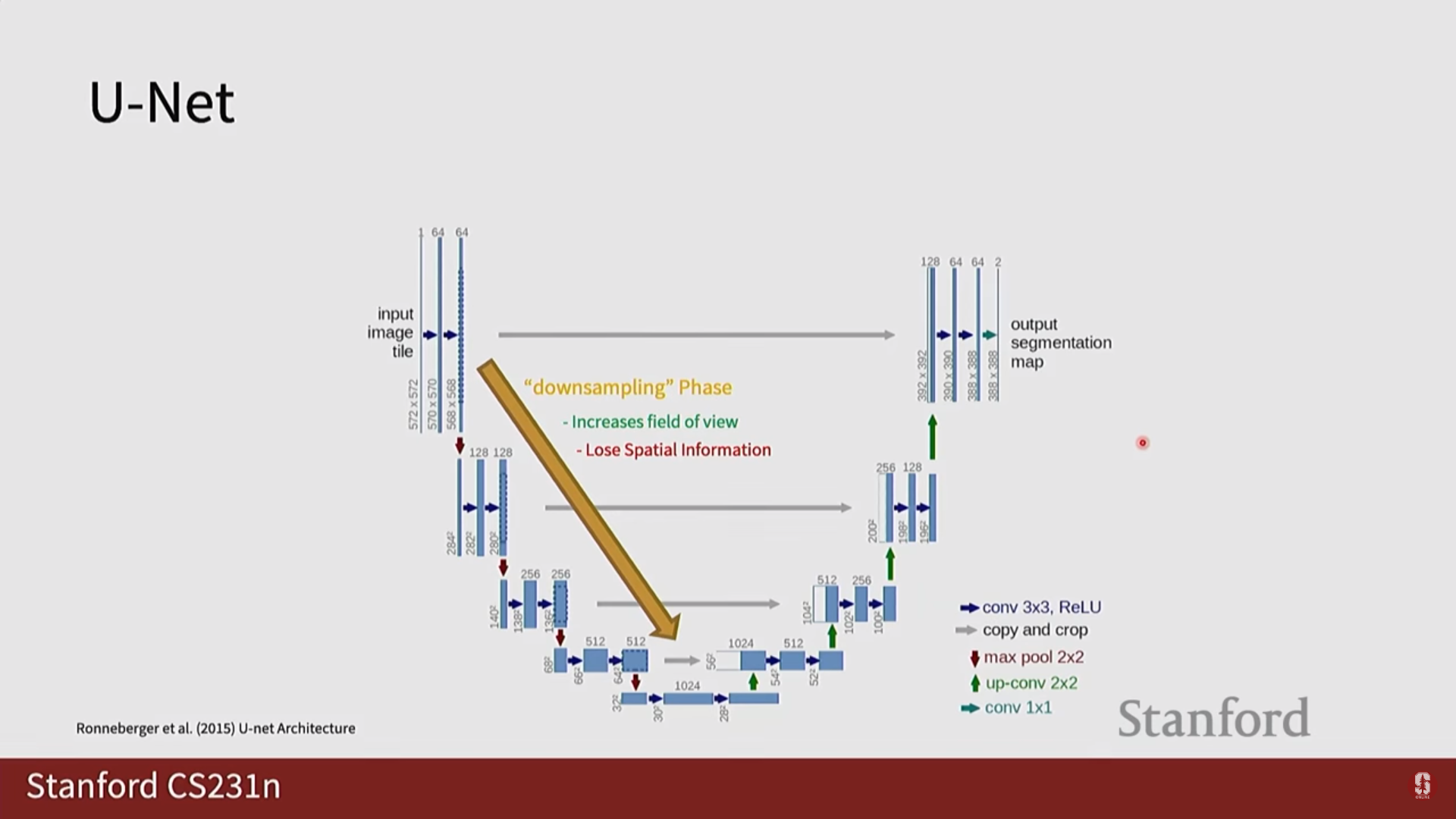
U-Net은 주로 의료 이미지 분할 분야에서 뛰어난 성능을 보이는 모델입니다.
- 인코더-디코더 구조: 인코더에서 특징을 압축하고, 디코더에서 다시 원래 크기로 복원하는 대칭적인 구조를 가집니다.
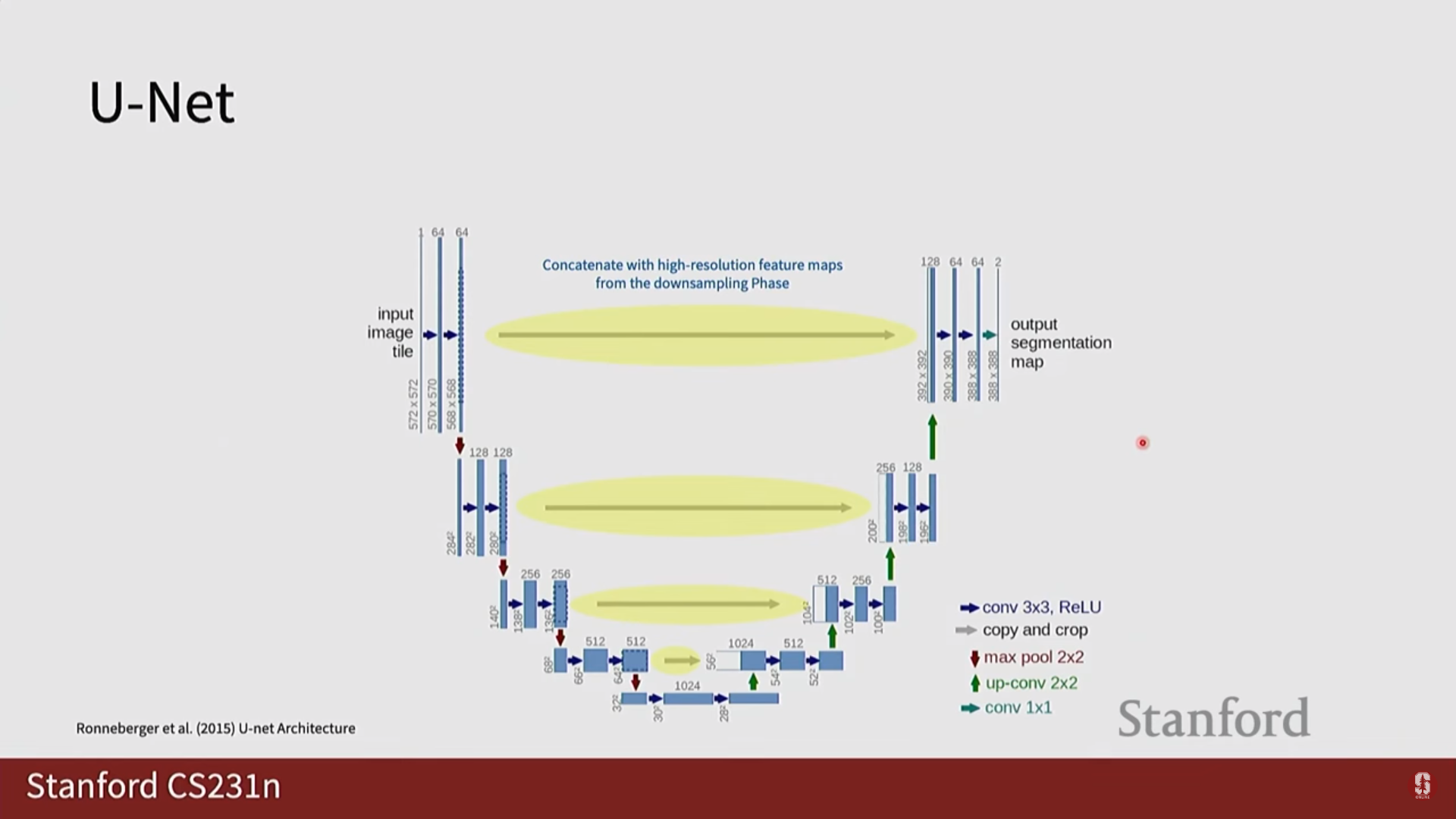
- 스킵 커넥션 (Skip Connection): 인코더의 특징 맵을 디코더에 직접 연결하여 다운샘플링 과정에서 손실될 수 있는 정밀한 위치 정보를 보존합니다.
- 의료 영상 분야에서의 강점: 의료 영상은 데이터 양이 적고, 객체의 경계가 모호하지만 정확한 분할이 매우 중요한 분야입니다. U-Net의 스킵 커넥션 구조는 적은 데이터로도 효율적인 학습이 가능하게 하고, 정밀한 위치 정보를 잘 복원하여 의료 영상 분할에서 표준 모델처럼 사용되고 있습니다.
- 한계점: 구조가 비교적 단순하여 매우 복잡하고 다양한 형태의 객체를 처리하는 데는 한계가 있을 수 있으며, 여러 객체가 심하게 겹쳐 있을 때 인스턴스별로 분리하는 데 어려움을 겪습니다.

4. 객체 탐지 (Object Detection)
1) 객체 탐지란? (The Core Problem)
- 객체 탐지는 단순히 이미지 안에 '무엇'이 있는지(분류)를 넘어 '어디'에 있는지(위치)까지 알아내는 문제입니다. 이를 위해 모델은 두 가지를 동시에 예측해야 합니다.
- 클래스 레이블 (Class Label): 해당 객체가 어떤 종류인지 (예: '고양이', '자동차').
- 바운딩 박스 (Bounding Box): 객체의 위치를 나타내는 사각형 좌표. 보통
(x_center, y_center, width, height)혹은(x_min, y_min, x_max, y_max)형식으로 표현됩니다.
- 이처럼 분류와 위치 회귀(regression)를 함께 수행해야 하므로, 손실 함수는 두 함수의 가중합으로 구성됩니다.



2) 평가지표: IoU와 mAP (Evaluation Metrics)
- 모델의 성능을 평가하기 위해 독특한 지표를 사용합니다.
- IoU (Intersection over Union): 모델이 예측한 바운딩 박스와 실제 정답 바운딩 박스가 얼마나 겹치는지를 나타내는 지표입니다. 겹치는 영역(Intersection)을 전체 영역(Union)으로 나눈 값으로, 0과 1 사이의 값을 가집니다. 1에 가까울수록 정확하게 예측한 것입니다.
- mAP (mean Average Precision): 객체 탐지 모델의 성능을 나타내는 표준 평가 지표입니다. 보통 IoU 임계값(threshold, 예: 0.5)을 정하고, 이 값 이상인 예측을 '정답(True Positive)'으로 판단합니다. 이후 각 클래스별로 모델의 정밀도(Precision)와 재현율(Recall)을 종합하여 AP(Average Precision)를 계산하고, 모든 클래스에 대해 이를 평균 낸 값이 mAP입니다.
- IoU (Intersection over Union): 모델이 예측한 바운딩 박스와 실제 정답 바운딩 박스가 얼마나 겹치는지를 나타내는 지표입니다. 겹치는 영역(Intersection)을 전체 영역(Union)으로 나눈 값으로, 0과 1 사이의 값을 가집니다. 1에 가까울수록 정확하게 예측한 것입니다.
3) 객체 탐지 모델의 발전
2-Stage Detectors: 정확도를 위한 접근
- '후보 영역을 먼저 찾고, 각 영역을 정밀하게 분석'하는 2단계 방식입니다.
- Region Proposal (영역 제안): 이미지 내에서 "여기에 객체가 있을 것 같다"고 추정되는 후보 영역들을 미리 찾아내는 과정입니다.
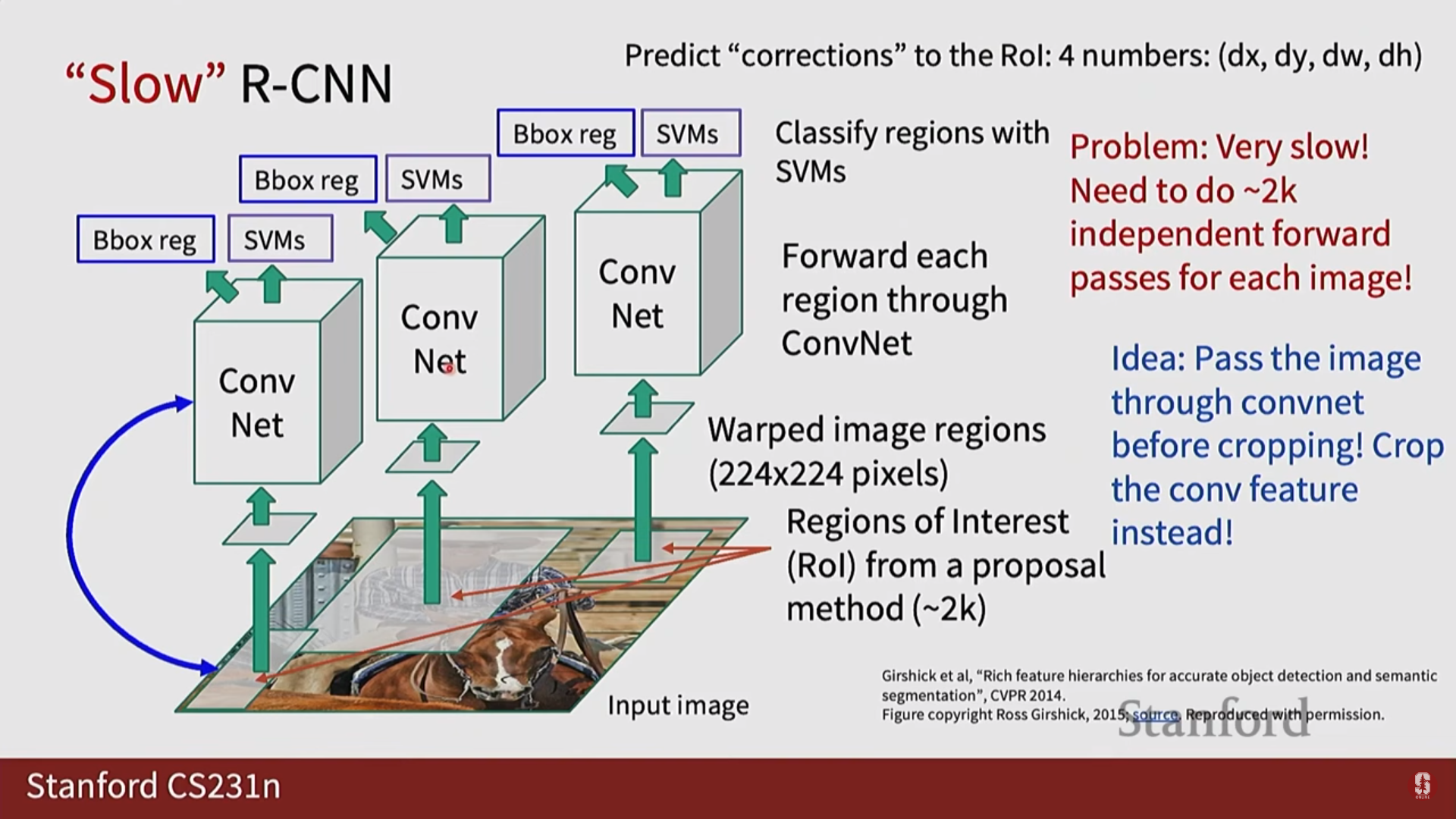
- R-CNN: (1) Selective Search로 약 2,000개의 후보 영역을 찾고 (2) 각 영역을 독립적으로 CNN에 입력하는 최초의 딥러닝 기반 탐지기입니다. 매우 정확했지만 속도가 치명적으로 느렸습니다.
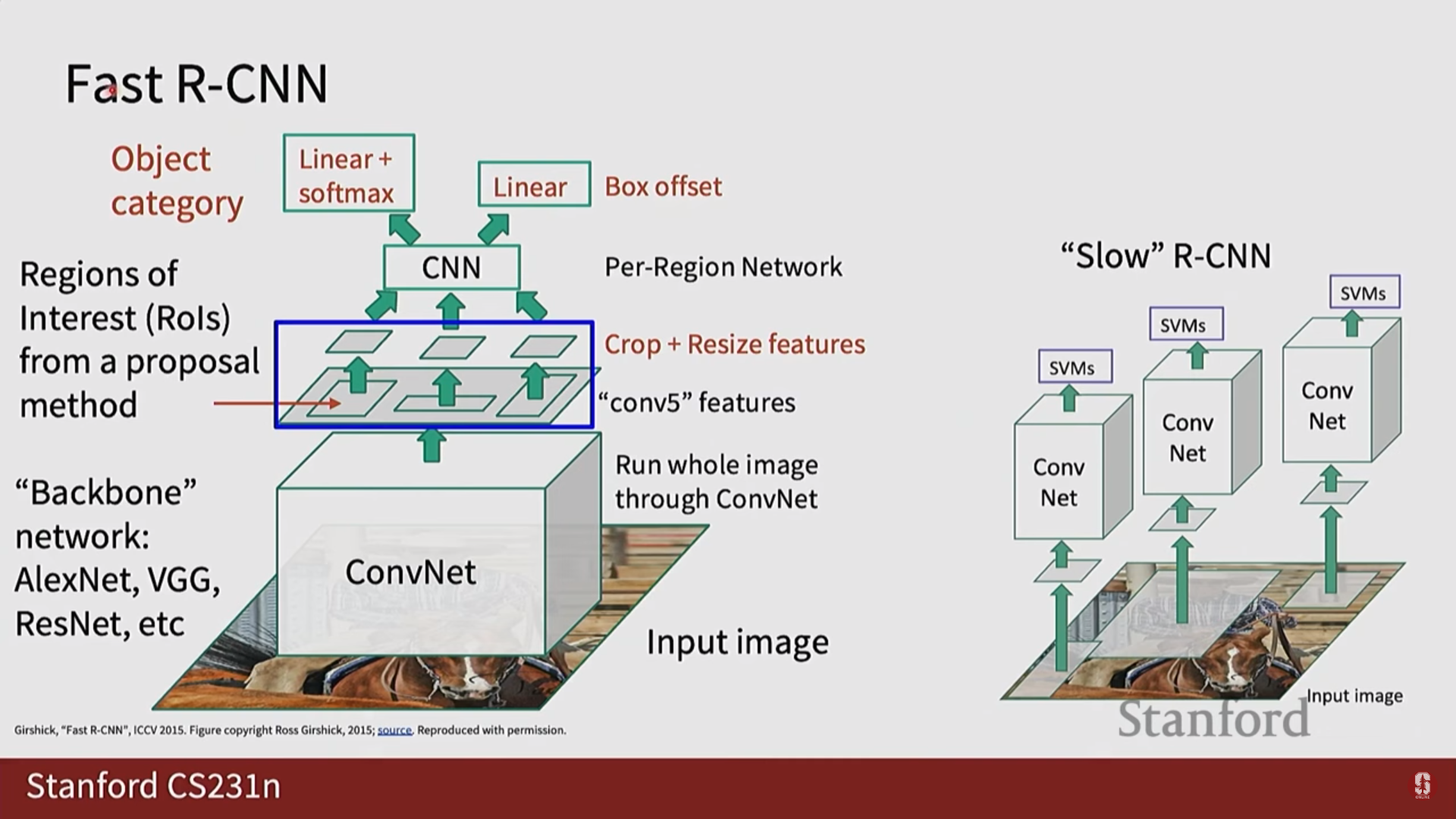
- Fast R-CNN: 이미지 전체에 대해 CNN을 단 한 번만 실행하고, RoIPool이라는 기법으로 특징 맵에서 후보 영역의 특징을 추출하여 속도를 크게 개선했습니다.
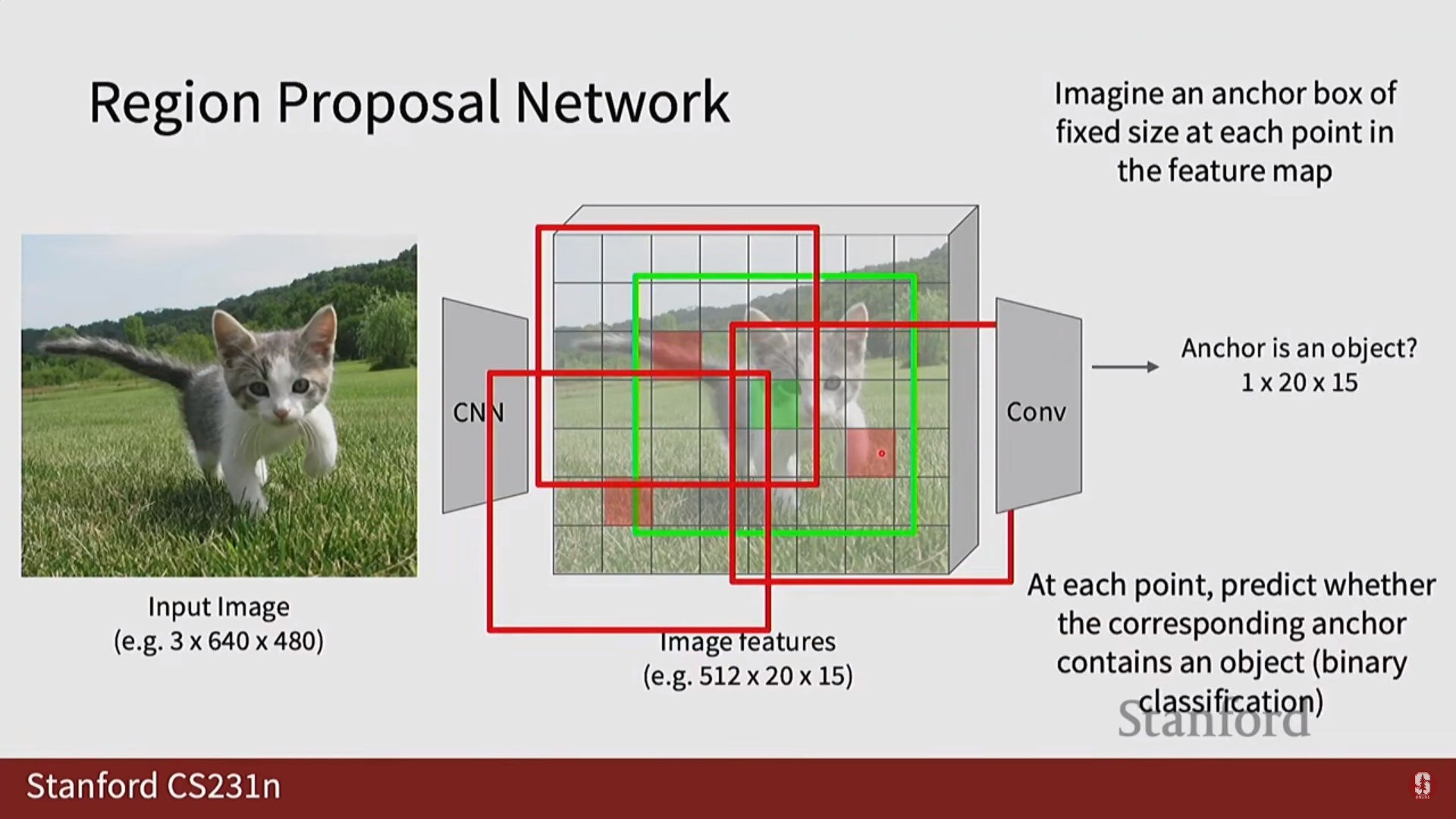
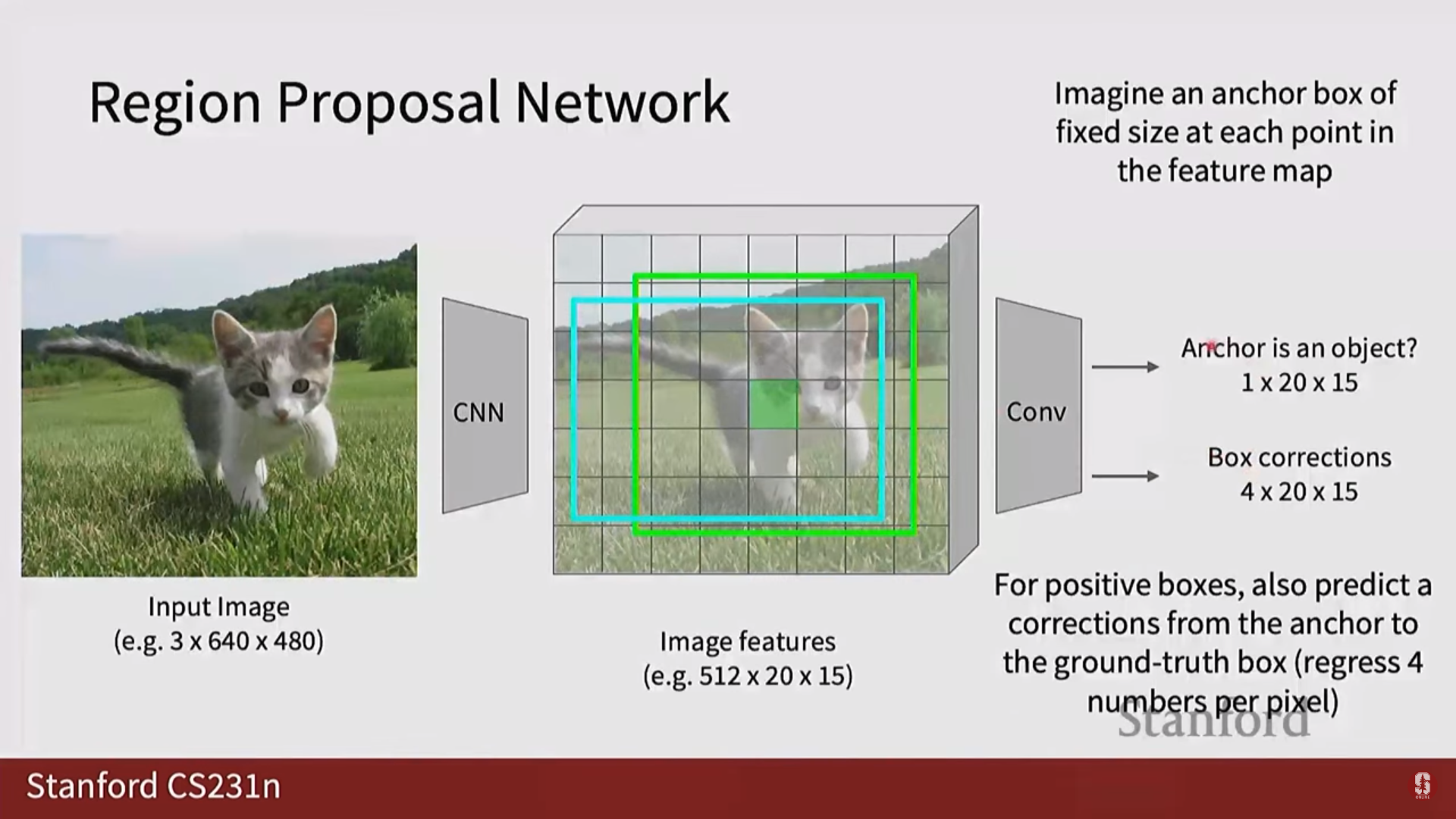
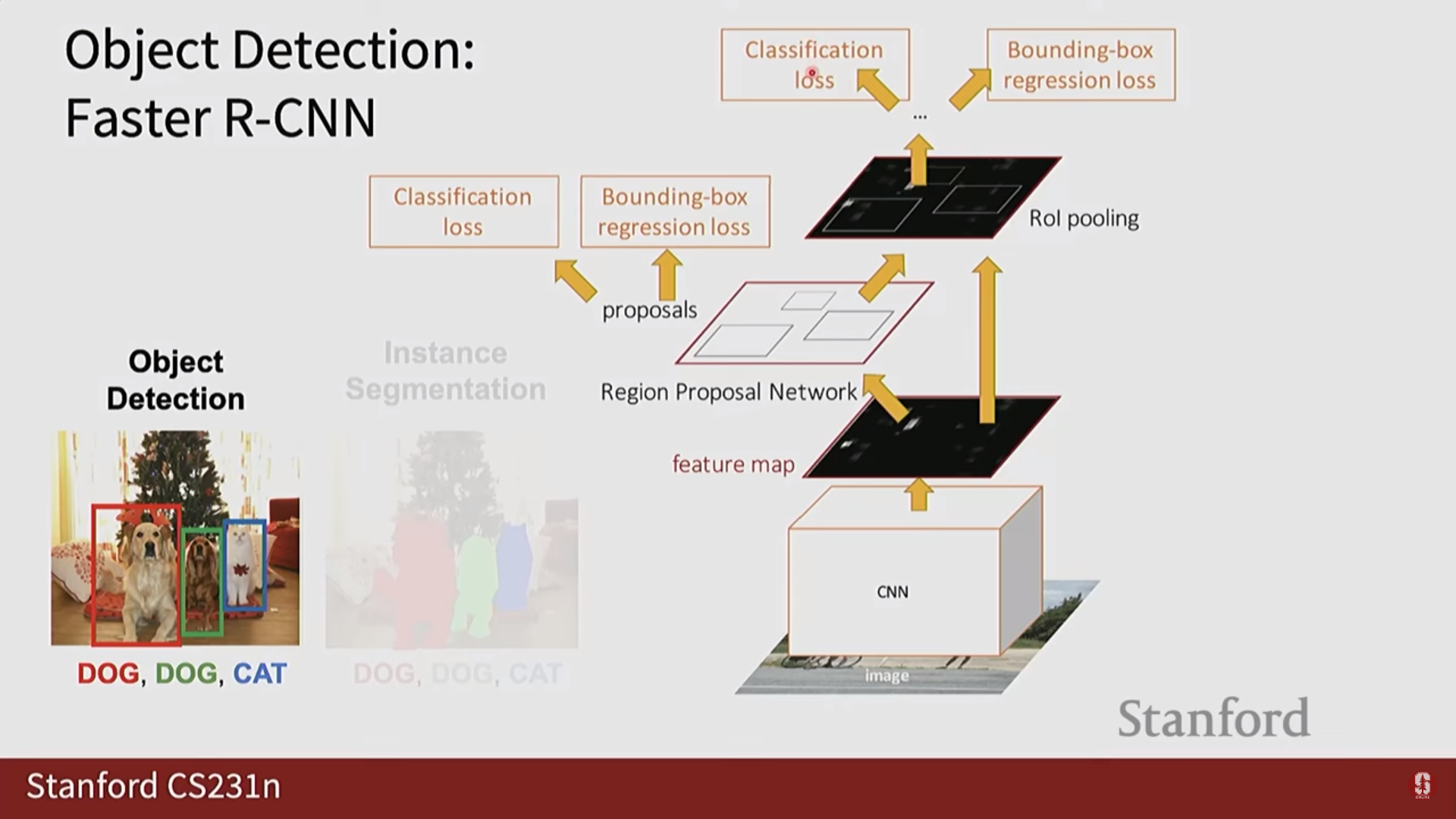
- Faster R-CNN: 외부 알고리즘(Selective Search)에 의존하던 영역 제안 과정을 RPN(Region Proposal Network)이라는 내부 신경망으로 대체하여, 전체 과정을 End-to-End로 학습 가능한 완전체로 만들었습니다. RPN은 특징 맵 위에서 미리 정의된 앵커 박스(Anchor Box)들을 기준으로 객체의 존재 유무와 위치를 빠르고 효율적으로 제안합니다.


1-Stage Detectors: 속도를 위한 접근
- 후보 영역 제안 단계를 생략하고, '이미지 전체를 한 번에 분석'하여 위치와 클래스를 동시에 예측합니다.
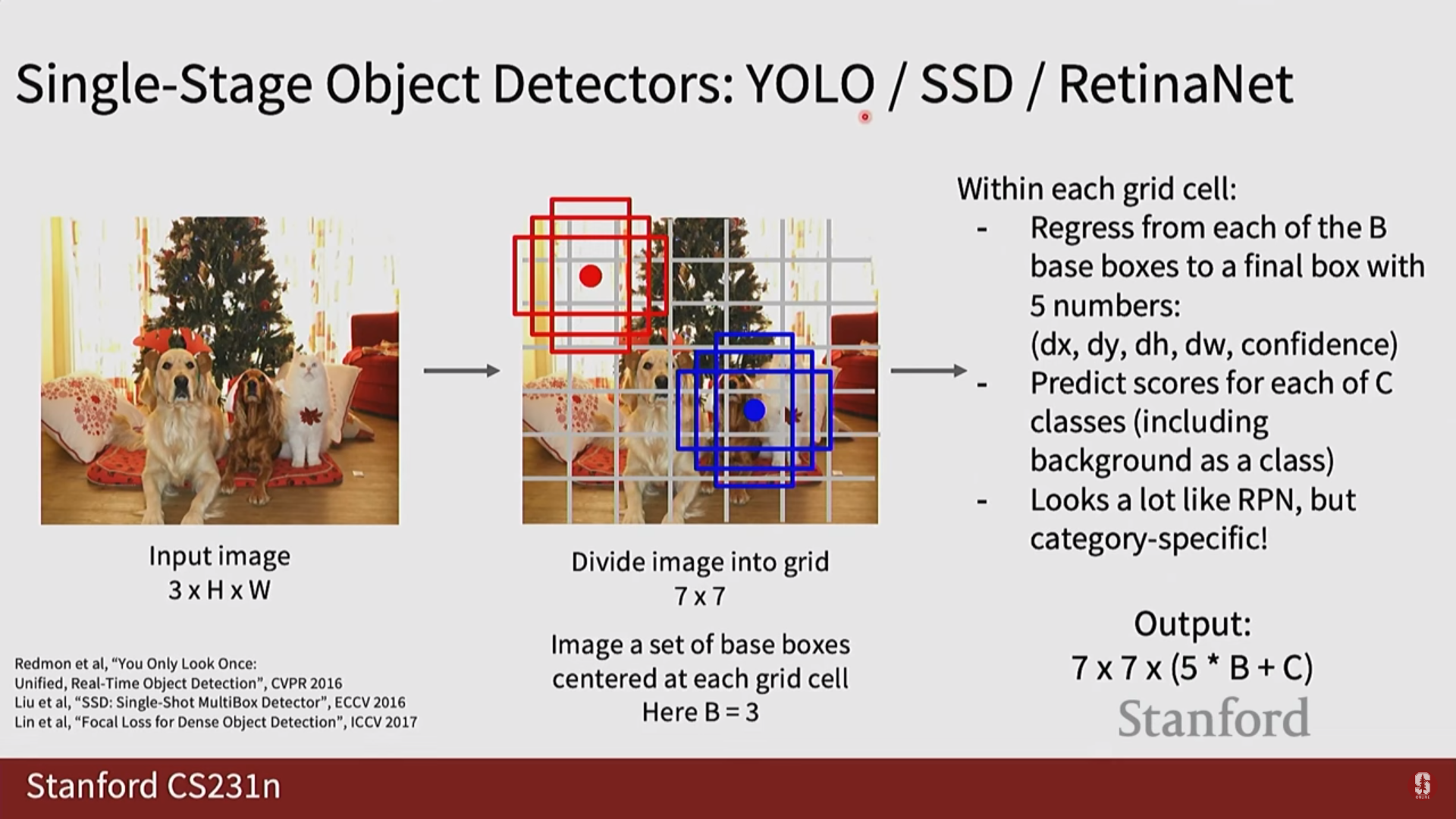
- YOLO (You Only Look Once):
- 핵심 아이디어: 이미지를 S x S 그리드로 나누고, 각 그리드 셀이 자신에게 속한 객체를 탐지하도록 책임을 할당합니다. 각 셀은 바운딩 박스 좌표(x, y, w, h)와 신뢰도(confidence) 점수, 그리고 클래스 확률을 직접 예측합니다. 이는 객체 탐지를 하나의 회귀 문제처럼 푸는 접근법입니다.
- Non-Maximum Suppression (NMS, 비최대 억제): YOLO와 같은 1-Stage detector는 필연적으로 하나의 객체에 대해 여러 개의 바운딩 박스를 예측하게 됩니다. NMS는 이 중복된 박스들을 제거하는 필수적인 후처리 과정입니다. 가장 신뢰도 점수가 높은 박스를 선택하고, 그 박스와 IoU가 높은 다른 박스들을 모두 제거하는 과정을 반복합니다.


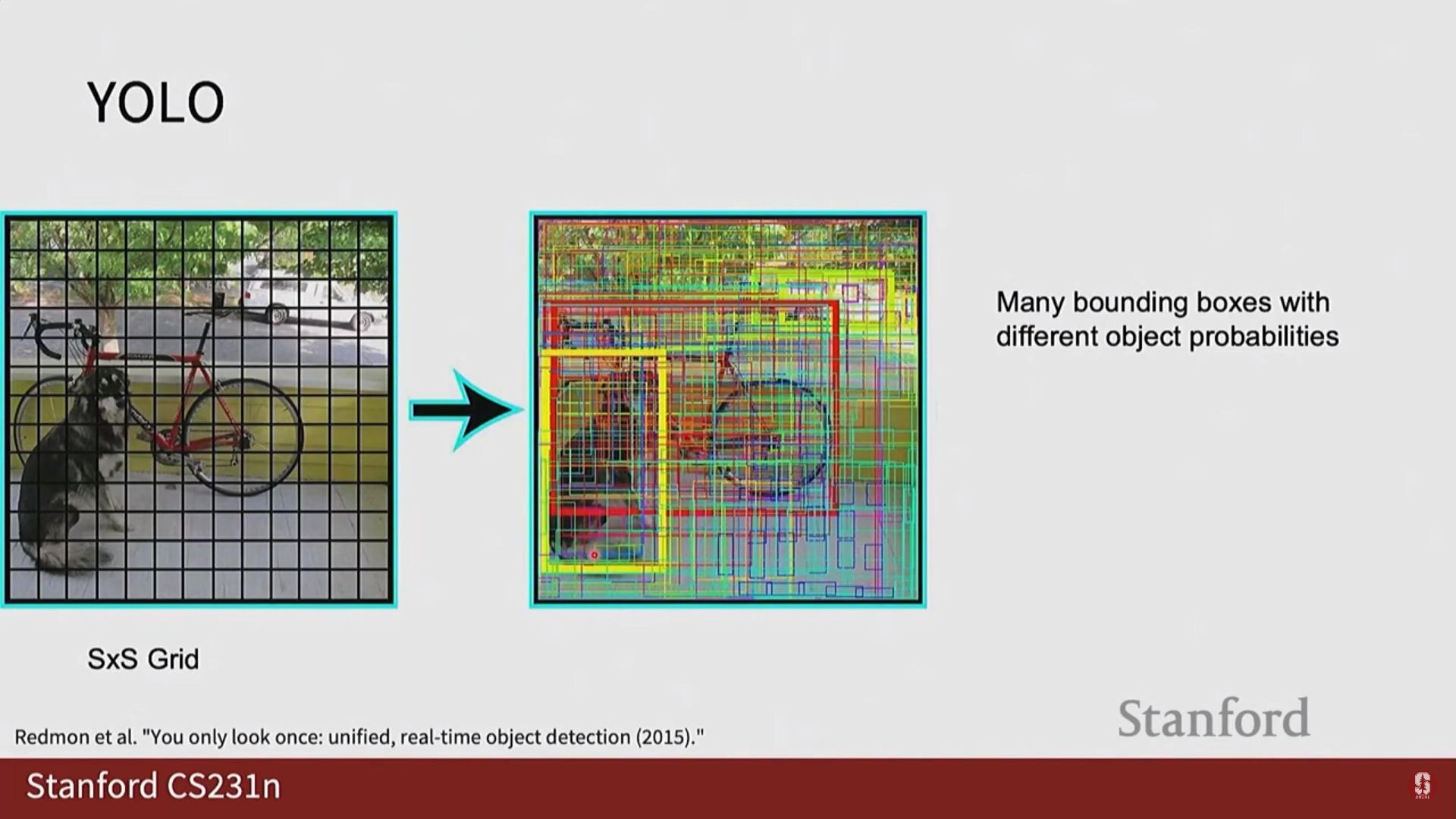
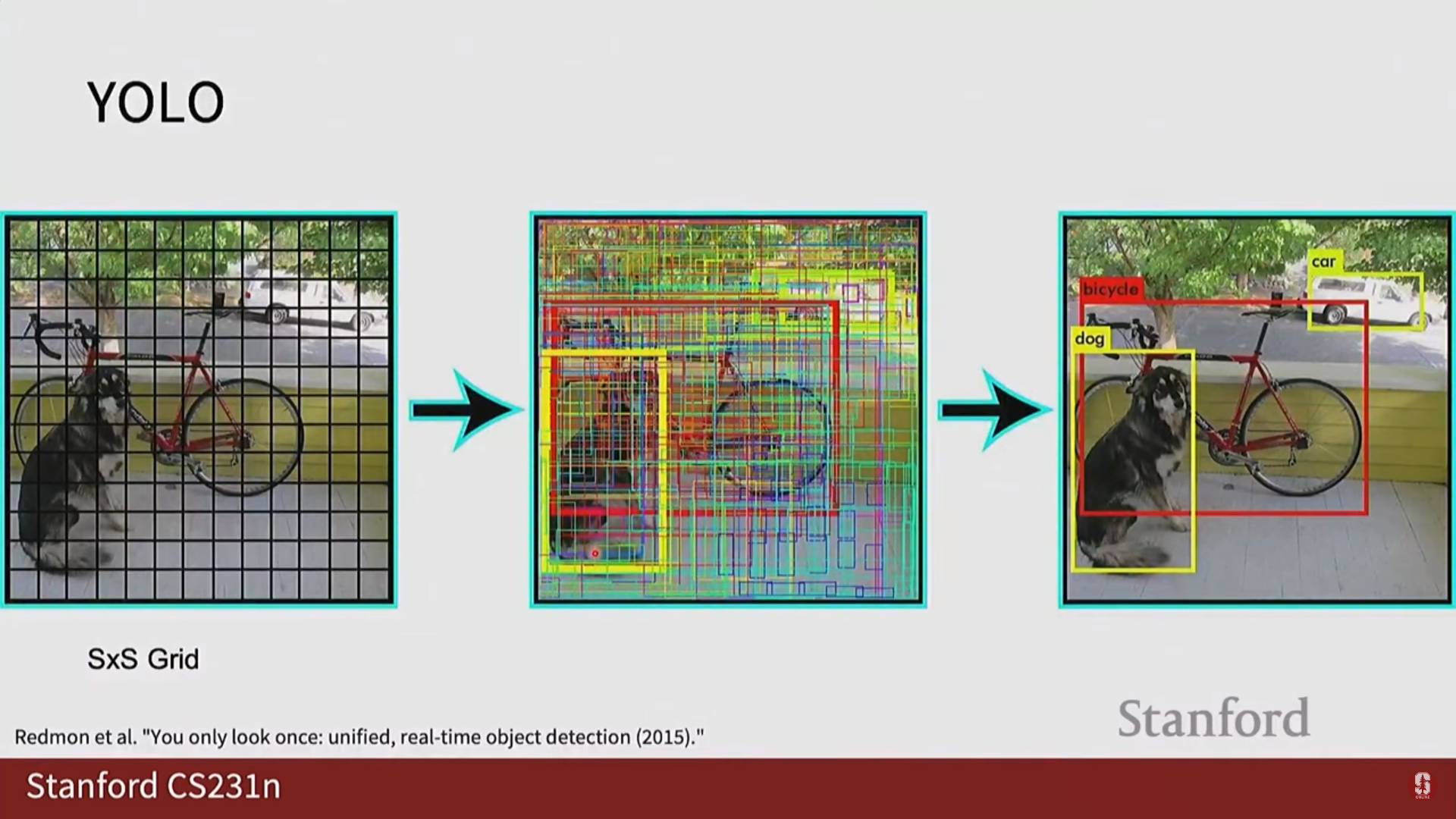
- YOLO (You Only Look Once):
Transformer-based Detectors: 새로운 패러다임
- DETR (DEtection TRansformer):
- 핵심 아이디어: 앵커 박스, NMS 등 복잡한 수작업 요소를 모두 제거하고, 객체 탐지를 '집합 예측(set prediction)' 문제로 재정의했습니다.
- 동작 방식: CNN으로 이미지 특징을 추출한 후, Transformer의 인코더-디코더 구조를 통과시킵니다. 디코더는 객체 쿼리(Object Queries)라는 고정된 수의 학습 가능한 슬롯을 입력받아, 이미지 전체의 맥락을 고려하여 각각의 슬롯이 하나의 객체(클래스+박스)를 예측하도록 합니다. 디코더 내부의 셀프 어텐션이 쿼리들 간의 상호작용을 통해 중복 예측을 스스로 억제하므로 NMS가 필요 없습니다.
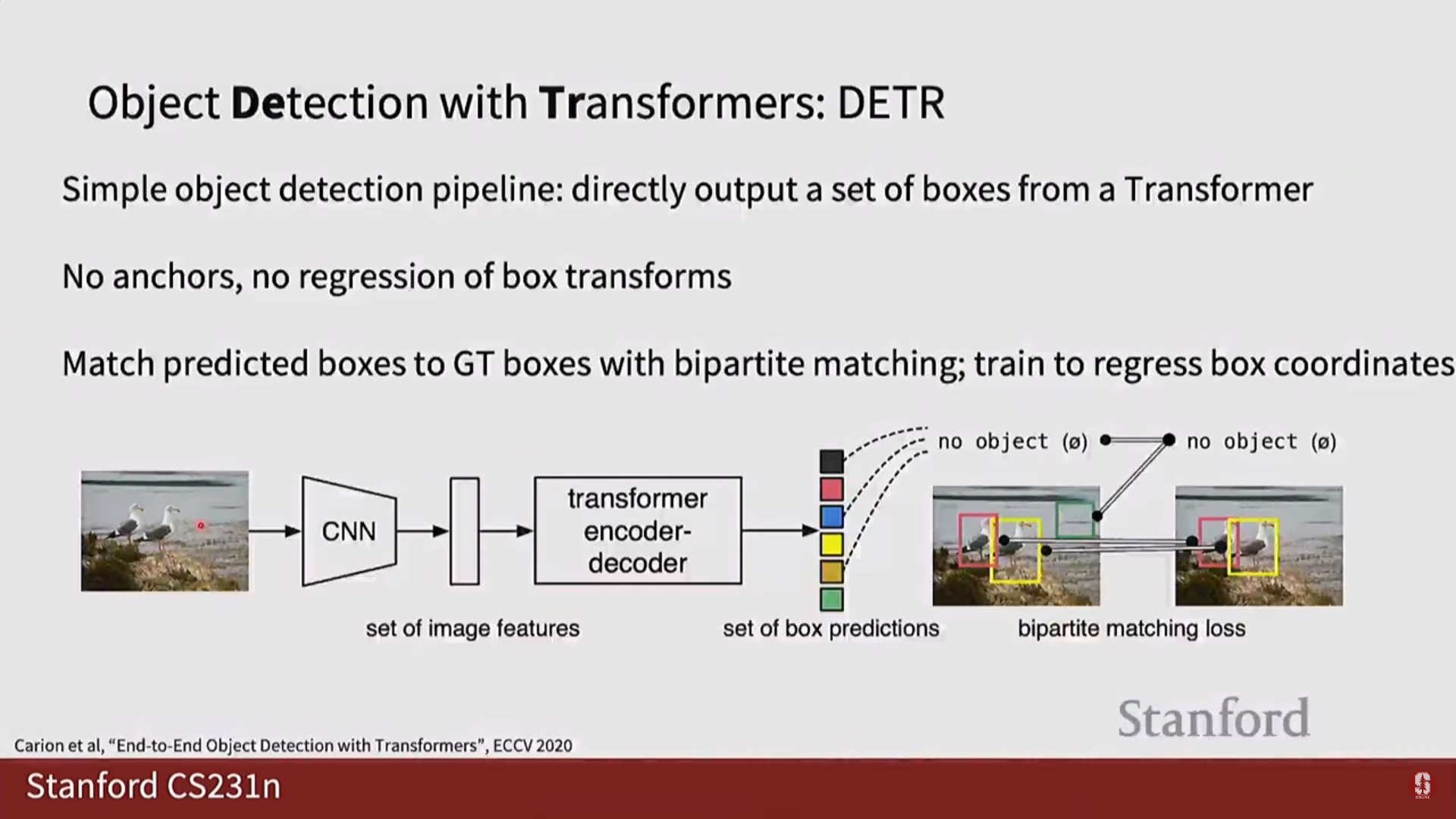
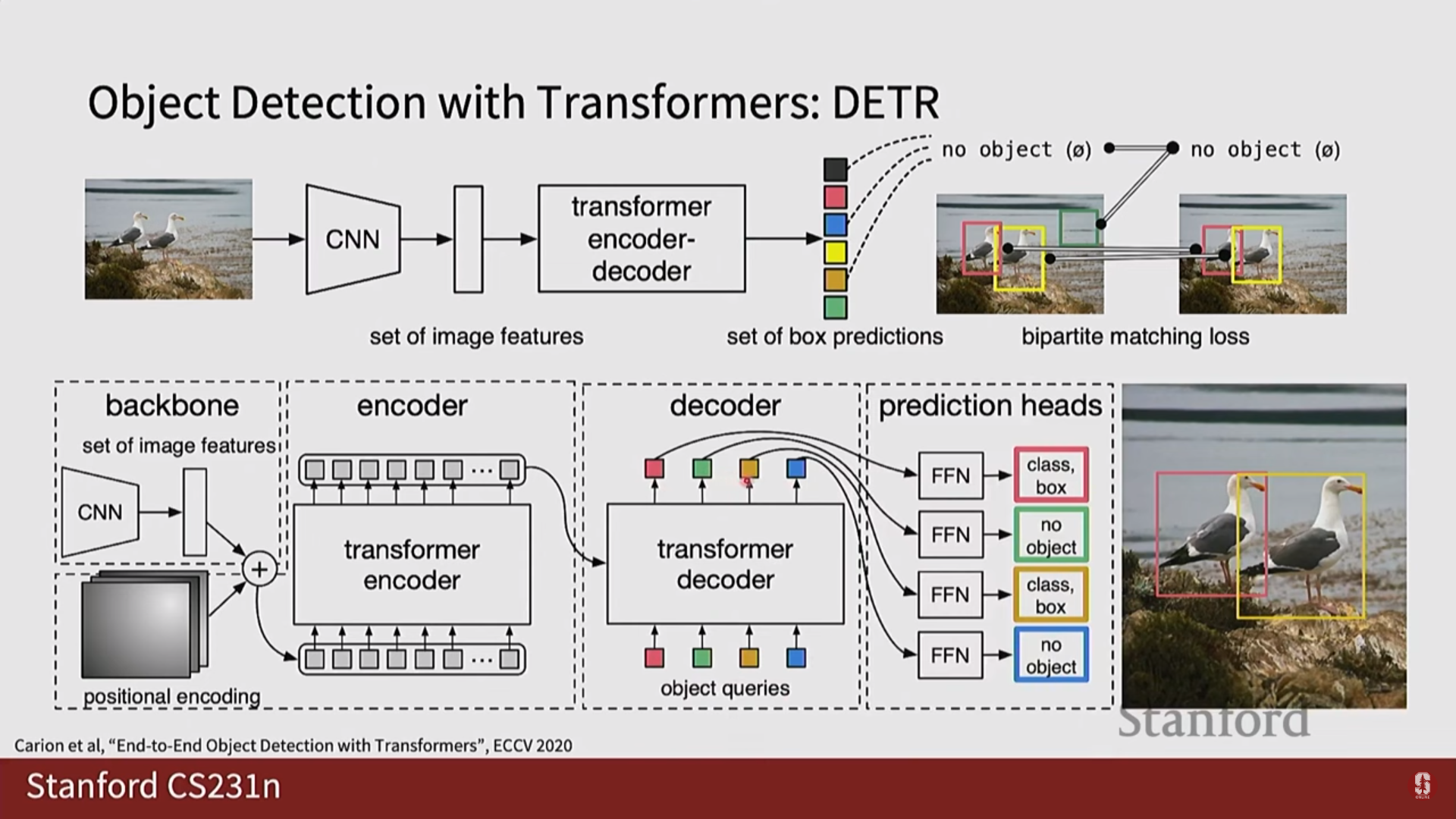
4) 핵심 비교: 1-Stage vs 2-Stage
- 2-Stage (Faster R-CNN 등): 후보 영역을 먼저 정하고 정밀하게 분석하므로 정확도, 특히 작은 객체에 대한 탐지 성능이 높은 경향이 있습니다. 하지만 파이프라인이 길어 속도가 느립니다.
- 1-Stage (YOLO 등): 전체 이미지를 한 번에 처리하므로 속도가 매우 빠르지만, 일반적으로 2-Stage 모델에 비해 정확도는 다소 낮습니다.
5. 인스턴스 분할 (Instance Segmentation)
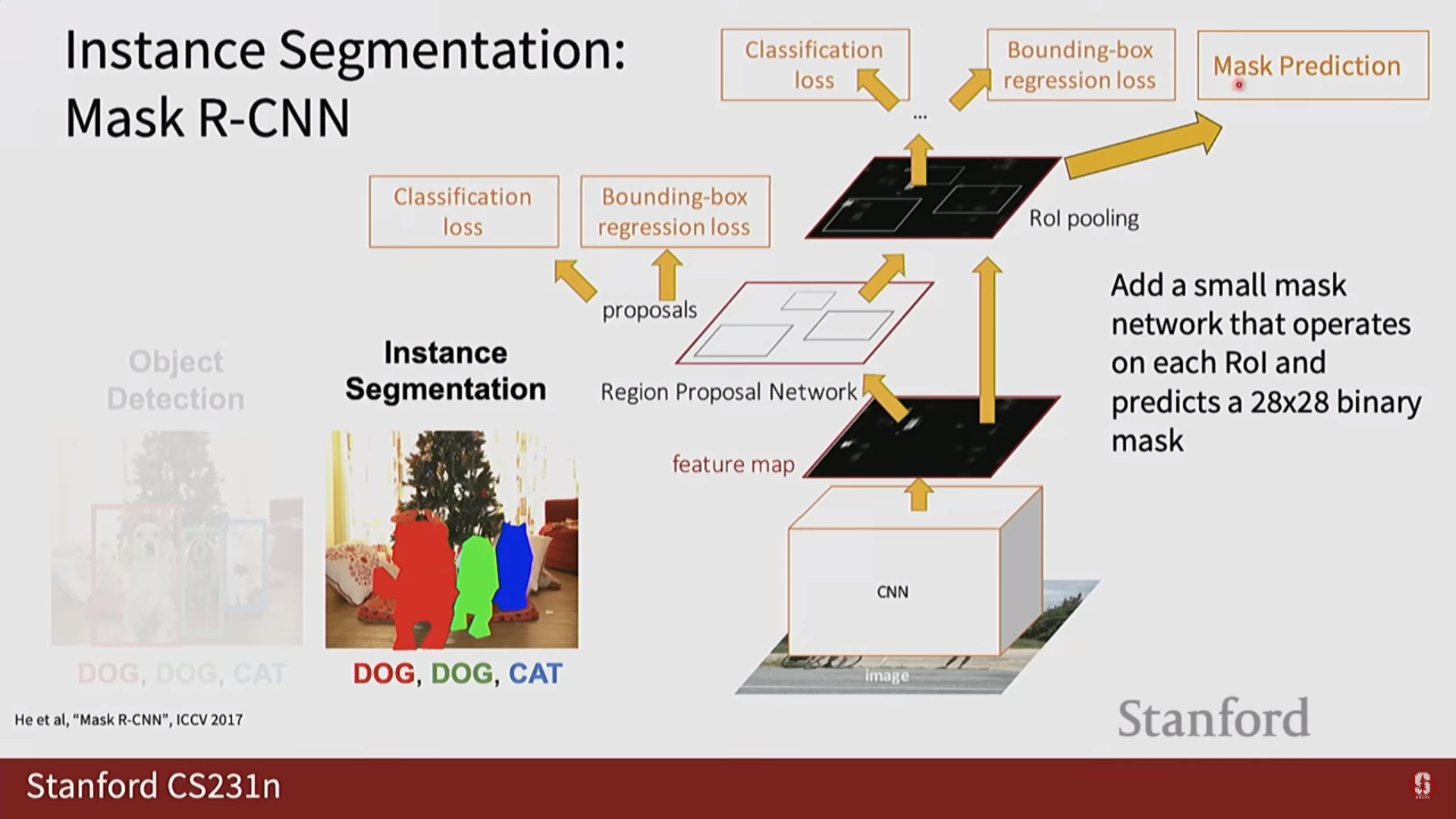
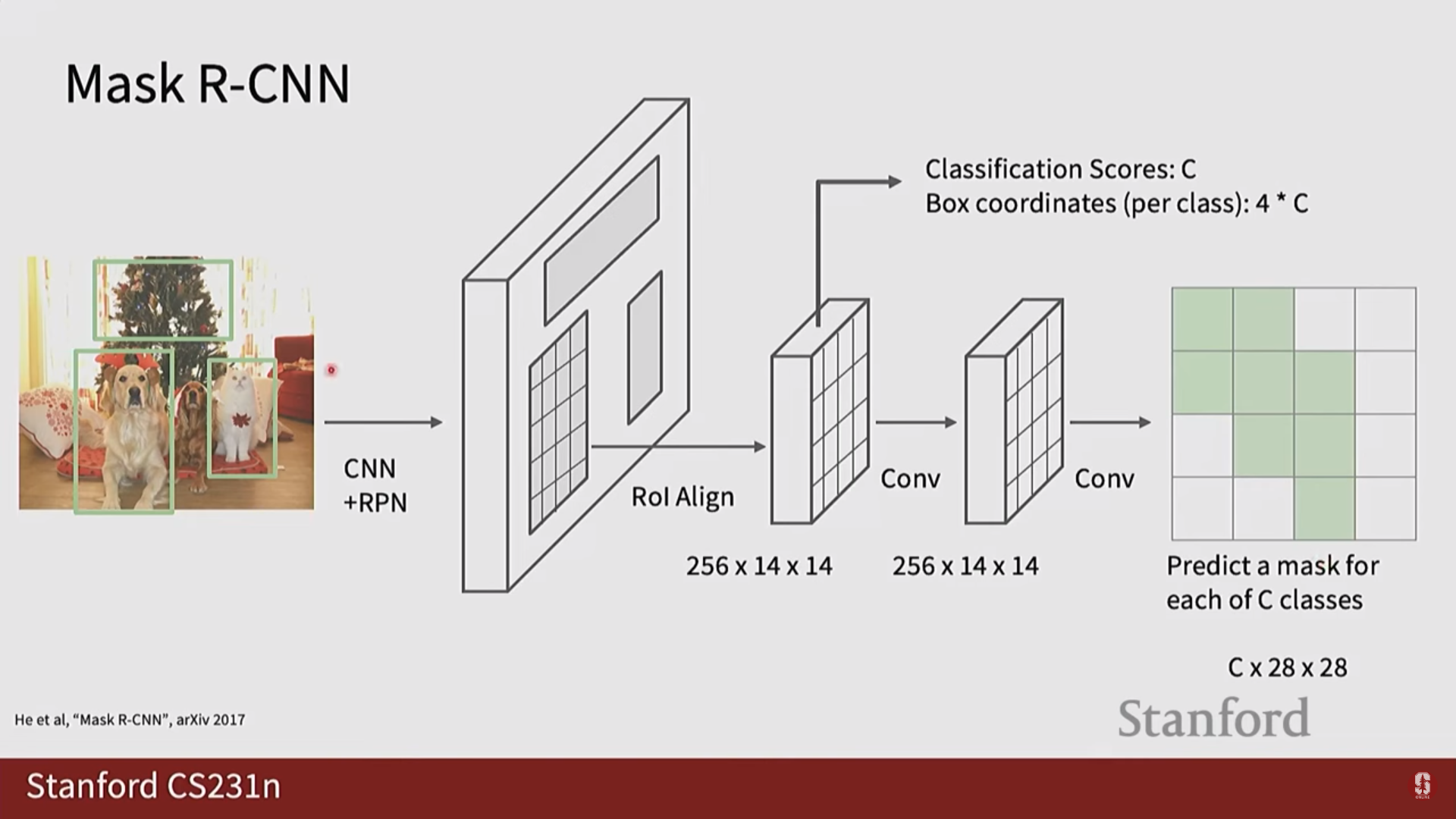
1) Mask R-CNN 상세 설명
- Mask R-CNN은 Faster R-CNN을 인스턴스 분할 과제에 맞게 확장한 모델입니다.
- 마스크 브랜치 추가: Faster R-CNN의 기존 구조에 병렬로 마스크 예측을 위한 작은 FCN 브랜치를 추가하여 픽셀 단위 분할을 수행합니다.
- 핵심 기술: RoIAlign
- Faster R-CNN의 RoIPool은 후보 영역의 특징을 추출할 때 소수점 좌표를 반올림하여 공간적 양자화(quantization)를 수행합니다.
- 이는 바운딩 박스 예측에는 큰 문제가 없지만, 픽셀 단위의 정교함이 요구되는 마스크 예측에서는 픽셀 불일치(misalignment) 문제를 일으킵니다.
- Mask R-CNN은 이를 해결하기 위해 RoIAlign을 제안했습니다.
- RoIAlign은 반올림 없이 이중 선형 보간법(bilinear interpolation)을 사용하여 특징을 추출하므로, 원본 후보 영역과 특징 맵 간의 공간적 정합성을 완벽하게 유지하여 훨씬 더 정확한 마스크를 생성할 수 있습니다.


6. 모델 시각화 및 이해
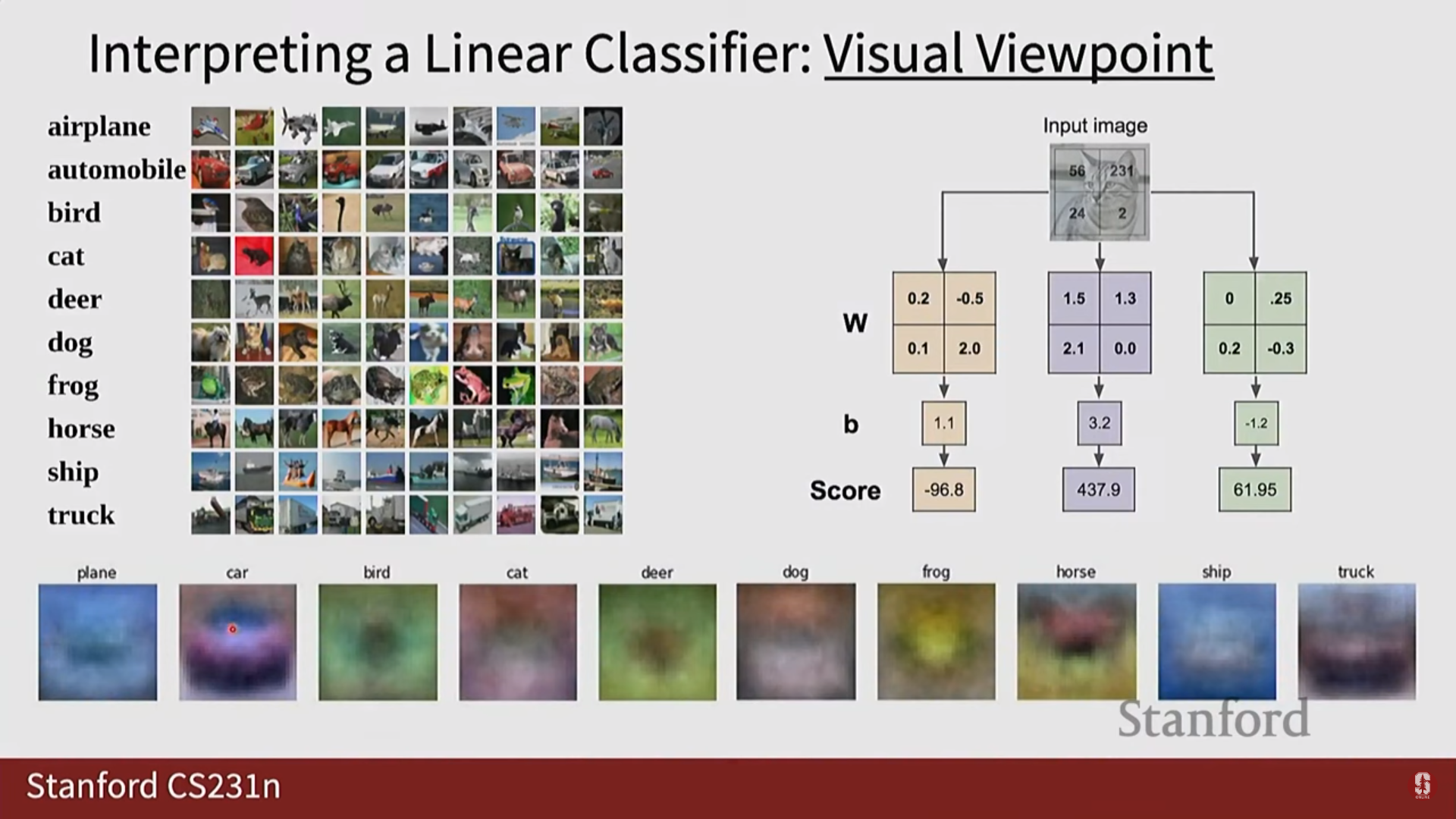
1) Filter Visualization (필터 시각화)
- CNN의 각 컨볼루션 레이어에 있는 필터의 가중치를 직접 이미지로 그려보는 기법입니다.
- 초기 레이어는 주로 색상, 엣지, 코너 등 단순한 패턴을 감지하도록 학습합니다.
- 후기 레이어는 초기 패턴들을 조합하여 질감, 객체의 일부 등 더 복잡하고 추상적인 패턴을 감지합니다.

2) Saliency Map 및 관련 기법
- Saliency Map: 모델의 결정에 각 픽셀이 미친 영향을 기울기로 계산하여 시각화합니다.
- Guided Backpropagation: Saliency Map의 변형으로, 음수 기울기를 차단하여 더 선명한 시각화 결과를 제공합니다.

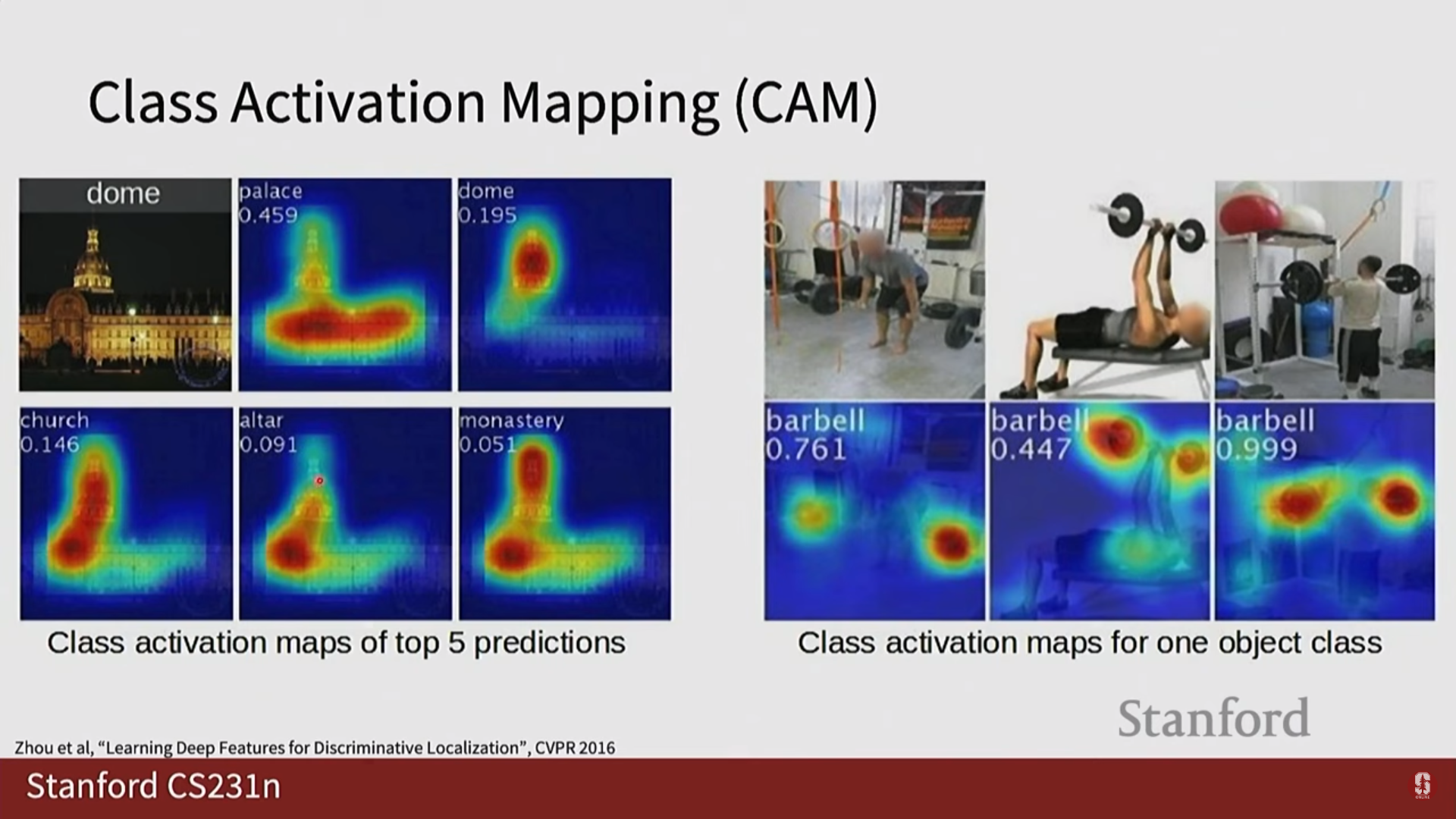
3) Class Activation Mapping (CAM) 계열 (추가된 내용)
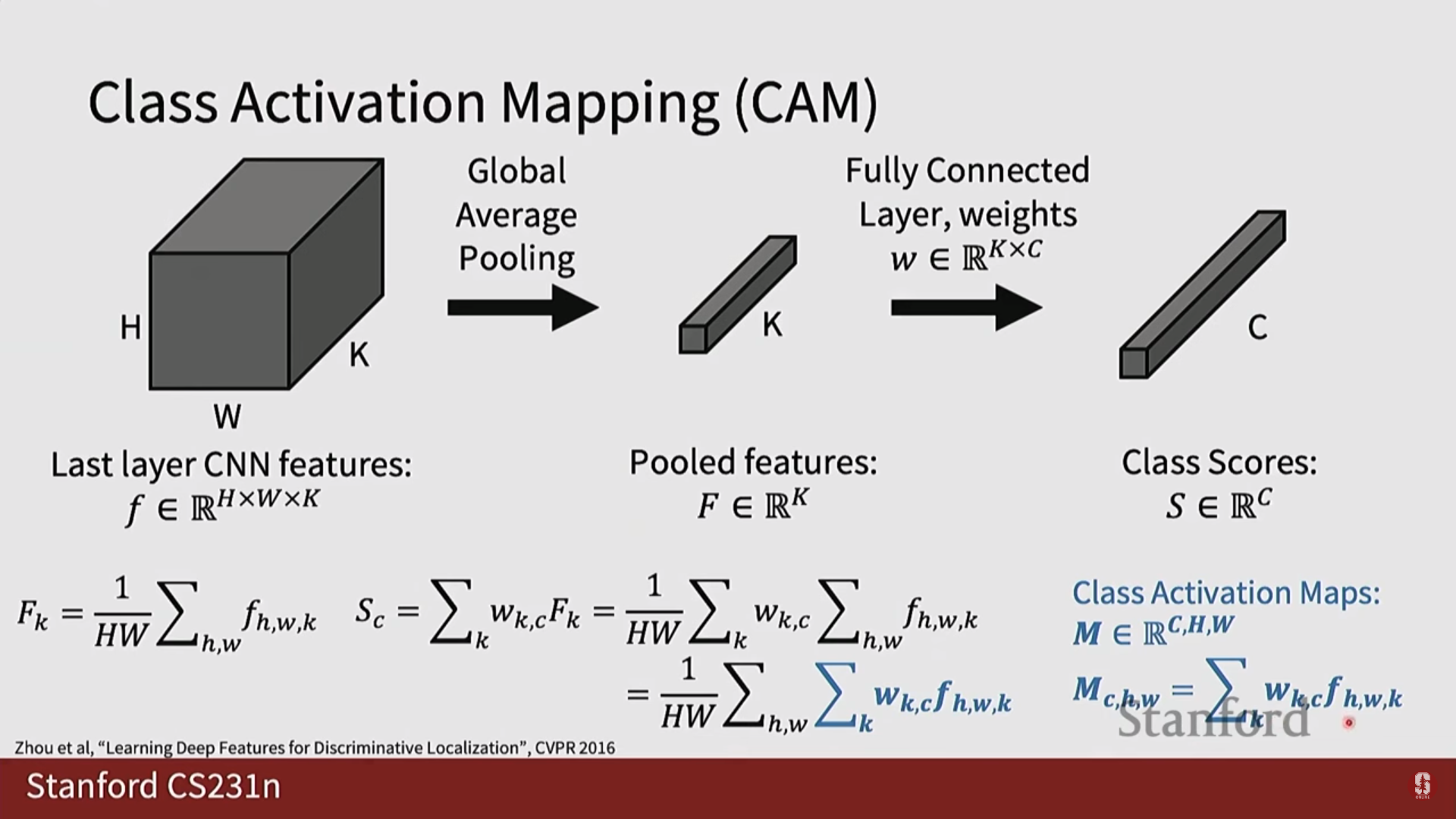
- CAM (Class Activation Mapping): 모델이 특정 클래스로 예측하는 데 결정적인 역할을 한 이미지의 '핵심 영역'이 어디인지를 히트맵 형태로 보여주는 기법입니다. 단, 마지막 레이어에 Global Average Pooling(GAP)이 사용되는 등 네트워크 구조에 제약이 있다는 명확한 한계점을 가집니다.
- Grad-CAM: CAM의 한계점을 극복한 일반화된 버전입니다. 그래디언트 정보를 활용하여 모델 구조에 상관없이 어떤 CNN 모델에도 적용할 수 있어 널리 사용됩니다.


4) Vision Transformer의 어텐션 맵 시각화
- ViT는 셀프 어텐션 메커니즘 덕분에 모델의 어느 부분이 이미지의 다른 부분에 집중하는지를 자연스럽게 시각화할 수 있습니다.

7. Q&A (자주 묻는 질문)
Q1. CNN과 Vision Transformer(ViT)의 가장 근본적인 차이점은 무엇인가요?
A. 처리 방식의 차이입니다. CNN은 컨볼루션 필터를 통해 이미지의 지역적인(local) 패턴을 점진적으로 학습합니다. 반면 ViT는 이미지를 여러 패치로 나누고, 셀프 어텐션을 통해 이미지 전체 패치들 간의 전역적인(global) 관계를 한 번에 파악합니다.
Q2. U-Net에서 스킵 커넥션(Skip Connection)이 왜 그렇게 중요한가요?
A. 정밀한 위치 정보 보존 때문입니다. 스킵 커넥션은 다운샘플링으로 인해 손실될 수 있는 인코더의 정밀한 위치 정보를 디코더로 직접 전달하여, 객체의 경계선을 매우 정확하게 복원하도록 돕습니다.
Q3. 앵커 박스(Anchor Box)는 정확히 어떤 문제를 해결하기 위해 도입되었나요?
A. 예측 공간의 효율화 문제를 해결합니다. '객체는 보통 이런 형태와 크기일 것이다'라는 사전 지식을 모델에 제공하여, 모델이 예측해야 할 범위를 크게 줄여주므로 학습이 훨씬 빠르고 안정적으로 이루어집니다.
Q4. 1-Stage Detector(YOLO)와 2-Stage Detector(Faster R-CNN)의 핵심 차이는 무엇인가요?
A. 처리 단계의 수입니다. 2-Stage는 '후보 영역 찾기'와 '분류/조정'으로 나뉘어 정확도에 강점이 있고, 1-Stage는 이 과정을 통합하여 속도에 강점이 있습니다.
Q5. DETR이 기존 객체 탐지기들과 다른 혁신적인 점은 무엇인가요?
A. 앵커 박스와 NMS(비최대 억제)를 제거하고 객체 탐지를 집합 예측(set prediction) 문제로 재정의했다는 점입니다. 복잡한 수작업 요소들을 제거하고 완전한 End-to-End 학습 파이프라인을 구축한 것이 가장 큰 혁신입니다.
