1. 비디오 이해를 위한 딥러닝 (Deep Learning for Video Understanding)
1) 강의 소개 및 2D 컴퓨터 비전 복습
- 본 강의는 초청 강연으로, 컴퓨터 과학부 조교수이자 다중 감각 기계 지능 연구소(Multi-sensory Machine Intelligence Lab)를 이끌고 있는 Dr. Rohan Gao가 진행했습니다.
- Dr. Gao는 컴퓨터 비전뿐만 아니라 오디오, 촉각 등 다른 감각 양식을 활용하여 다중 감각 세계를 인지하고 이해하며 상호작용하는 다중 모델(multi-model) 연구에 깊은 관심을 두고 있습니다.
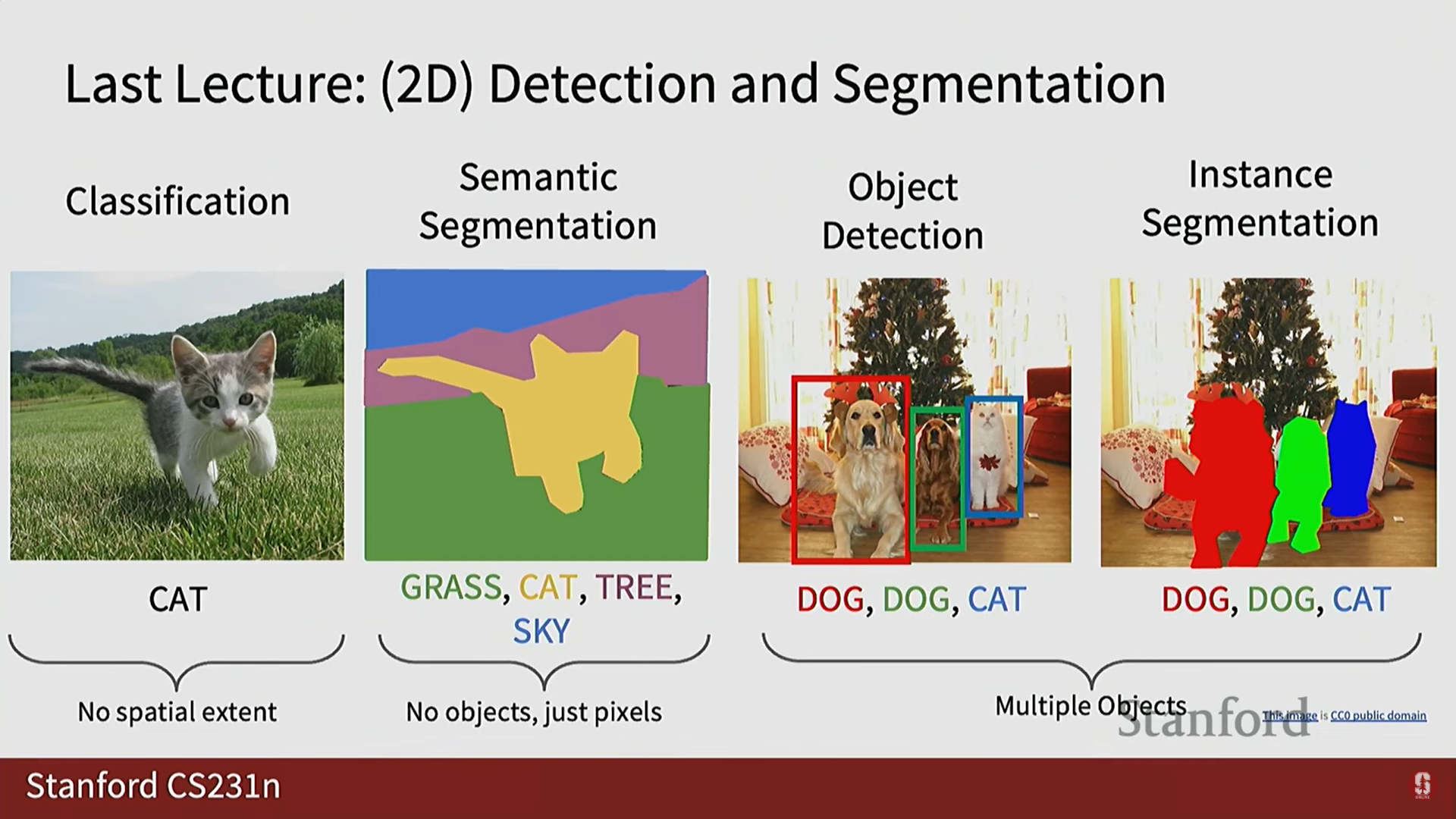
- 지금까지 수강생들은 2D 이미지 기반의 컴퓨터 비전에 익숙해져 있으며, 다음을 포함한 다양한 작업을 학습했습니다:
- 이미지 분류 (Image Classification): 2D 이미지를 입력받아 단일 레이블(예: 개, 고양이, 트럭)을 할당하는 작업.
- 시맨틱 분할 (Semantic Segmentation): 이미지를 잔디, 고양이, 나무 등 의미론적 구성 요소로 분할하는 작업.
- 객체 탐지 (Object Detection): 이미지 내의 객체 위치에 경계 상자(Bounding Box)를 배치하는 작업.
- 인스턴스 분할 (Instance Segmentation): 카테고리뿐만 아니라 각 객체 인스턴스별로 별도의 분할 마스크를 생성하는 작업.
2) 비디오 이해의 정의와 과제
- 비디오(Video)는 기본적으로 2D 이미지에 시간 차원(Temporal Dimension)이 추가된 형태입니다.
- 비디오 데이터는 이제 공간 차원(H, W)과 시간 차원(T)을 포함하는 4D 데이터()로 간주됩니다. 이는 이미지 프레임들의 볼륨과 같습니다.
- 비디오 분류 (Video Classification)는 이러한 비디오(프레임의 시간 흐름)를 입력으로 받아, 해당 비디오에서 수행되는 행동(Action)을 분류하는 작업입니다 (예: 수영, 달리기, 점프).
- 이미지 분류가 주로 장면이나 객체 카테고리에 초점을 맞춘다면, 비디오 이해는 일반적으로 사람이나 동물이 수행하는 활동(actions)을 분류하는 데 중점을 둡니다.


비디오 데이터의 거대한 크기와 처리 문제
- 비디오 이해의 주요 과제 중 하나는 비디오가 매우 크다는 점입니다.
- 표준 해상도(Standard Definition) 비디오는 분당 약 1.5GB를 차지할 수 있습니다.
- 고해상도(1920x1080) 비디오는 분당 약 10GB를 차지할 수 있습니다.
- 이러한 거대한 데이터를 GPU에 직접 처리하기는 불가능하며, 심지어 원본 데이터를 저장하는 데도 막대한 공간이 필요합니다.
- 해결책: 데이터 축소 및 클립 기반 학습
- 공간적/시간적 축소: 비디오를 시간적, 공간적으로 축소합니다 (예: 초당 5프레임 샘플링, 해상도 112x112로 축소).
- 클립 학습: 매우 긴 비디오(수분 또는 수시간 분량) 전체를 학습하는 대신, 짧은 클립(chunks of video frames) 단위로 모델을 학습시킵니다.
- 추론(Inference) 시 처리: 테스트 시에는 여러 클립을 샘플링하여 모델을 실행한 후, 그 예측 결과를 평균 내어 최종 예측으로 사용합니다.


3) 2D CNN 기반 비디오 분류 모델 (Single Frame, Fusion)
(1) 단일 프레임 CNN (Single Frame CNN)
- 가장 간단한 접근 방식은 비디오 프레임을 개별 이미지로 간주하고, 기존의 2D CNN 이미지 분류기를 적용하는 것입니다.
- 비디오 프레임 간 변화가 적은 경우 (예: 사람이 달리는 장면), 이 방식은 매우 강력한 기준선(very strong baseline)이 될 수 있으며 종종 괜찮은 성능을 보입니다.
- 프레임 샘플링 (Frame Sampling): 긴 비디오에서 어떤 프레임을 선택할지는 매우 중요한 문제입니다.
- 무작위 샘플링 (Random Sampling): 1분마다 프레임을 샘플링하는 등 무작위로 선택.
- 스마트 샘플링 (Smarter Sampling Strategy): 어느 프레임을 샘플링할지 결정하는 더 똑똑한 전략을 모색하는 것은 활발한 연구 영역입니다.

(2) 융합 전략 (Fusion Strategies)
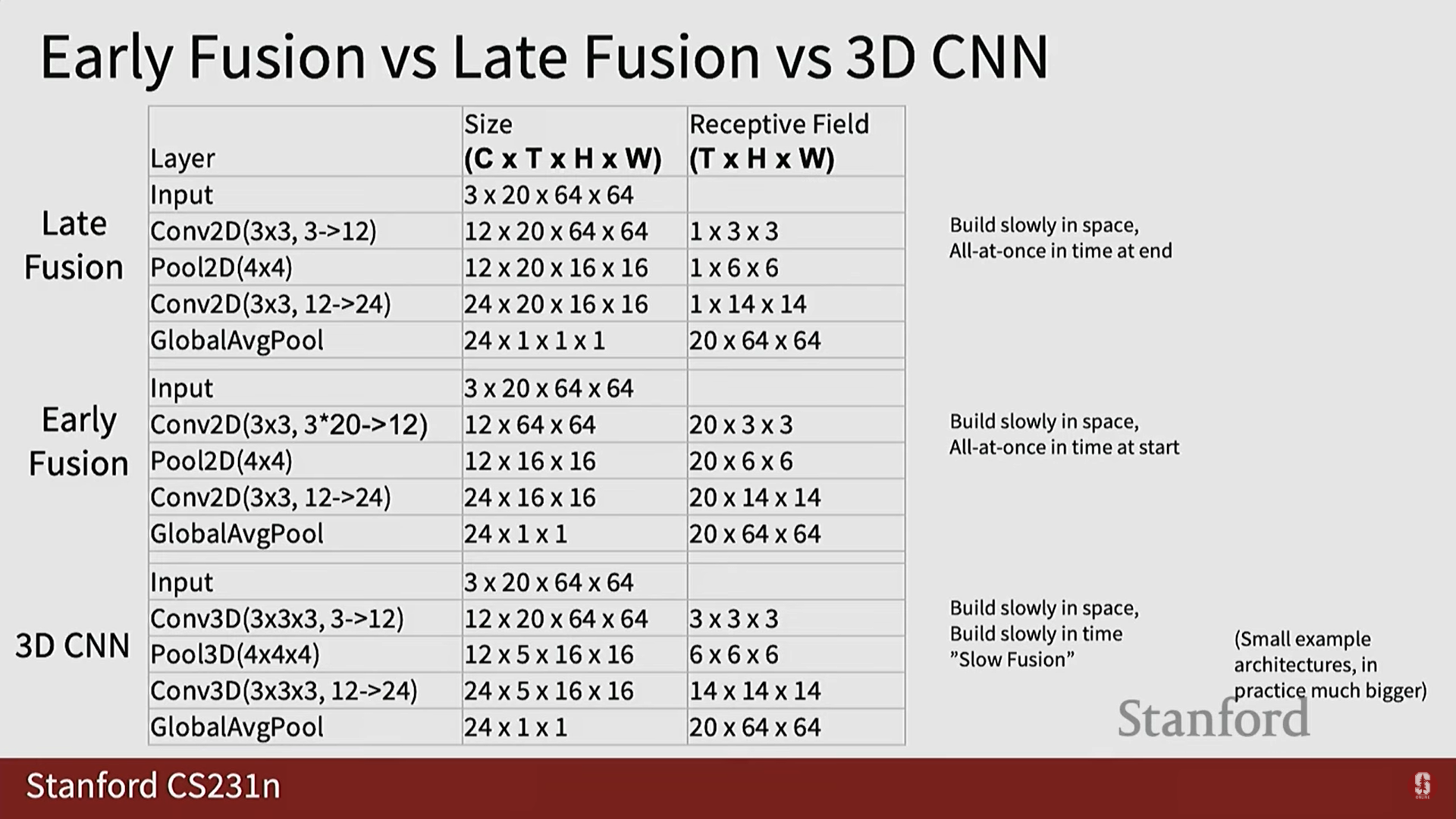
2.1. 레이트 퓨전 (Late Fusion)

- 아이디어: 각 프레임을 독립적으로 2D CNN으로 처리하여 특징을 추출한 후, 매우 늦은 단계에서 특징들을 결합합니다.
- 과정:
- 프레임 각각을 2D CNN으로 처리하여 개의 특징 맵()을 얻습니다.
- 시간 차원()을 따라 모든 특징 벡터를 평탄화하고 연결(concatenate)합니다.
- 이 거대한 특징 벡터를 완전 연결 네트워크(Fully Connecting Networks, MLP)에 통과시켜 클래스 점수 로 매핑합니다.
- 대안 (풀링): 특징 벡터를 연결하는 대신, 시간 차원을 따라 풀링(Pooling) (예: 평균 풀링, 최대 풀링)을 수행하여 벡터 길이를 로 유지하고 선형 레이어를 통해 클래스 점수로 매핑할 수 있습니다.

- 한계점:
- 파라미터 폭증 (Concatenation): 특징 벡터가 거대해지므로, 후속 완전 연결 계층의 파라미터 수가 매우 많아져 비효율적입니다.
- 저수준 모션 정보 손실: 2D CNN이 각 프레임을 독립적으로 처리하고 컨볼루션 및 풀링을 반복하면, 움직임(예: 발의 상하 움직임)과 같은 저수준 모션 정보가 특징 맵의 늦은 단계에서는 이미 손실될 가능성이 높습니다.
2.2. 얼리 퓨전 (Early Fusion)
- 아이디어: 시간 정보를 아주 초기 레이어에서부터 통합하여, 비디오 프레임에 더 가까운 특징 벡터를 사용합니다.
- 과정:
- 입력 비디오 프레임()을 시간 차원()과 채널 차원(3)을 결합한 채널로 재구성(reshape)합니다.
- 첫 번째 2D 컨볼루션 레이어를 사용하여 채널을 채널로 직접 매핑하며, 모든 시간 정보를 이 단일 레이어에서 붕괴(collapse)시킵니다.
- 네트워크의 나머지 부분은 표준 2D CNN과 동일합니다.
- 한계점: 단일 레이어에서 모든 시간 정보를 포착하려는 시도는 지나치게 의욕적이며, 원하는 목표를 달성하지 못할 수 있습니다.

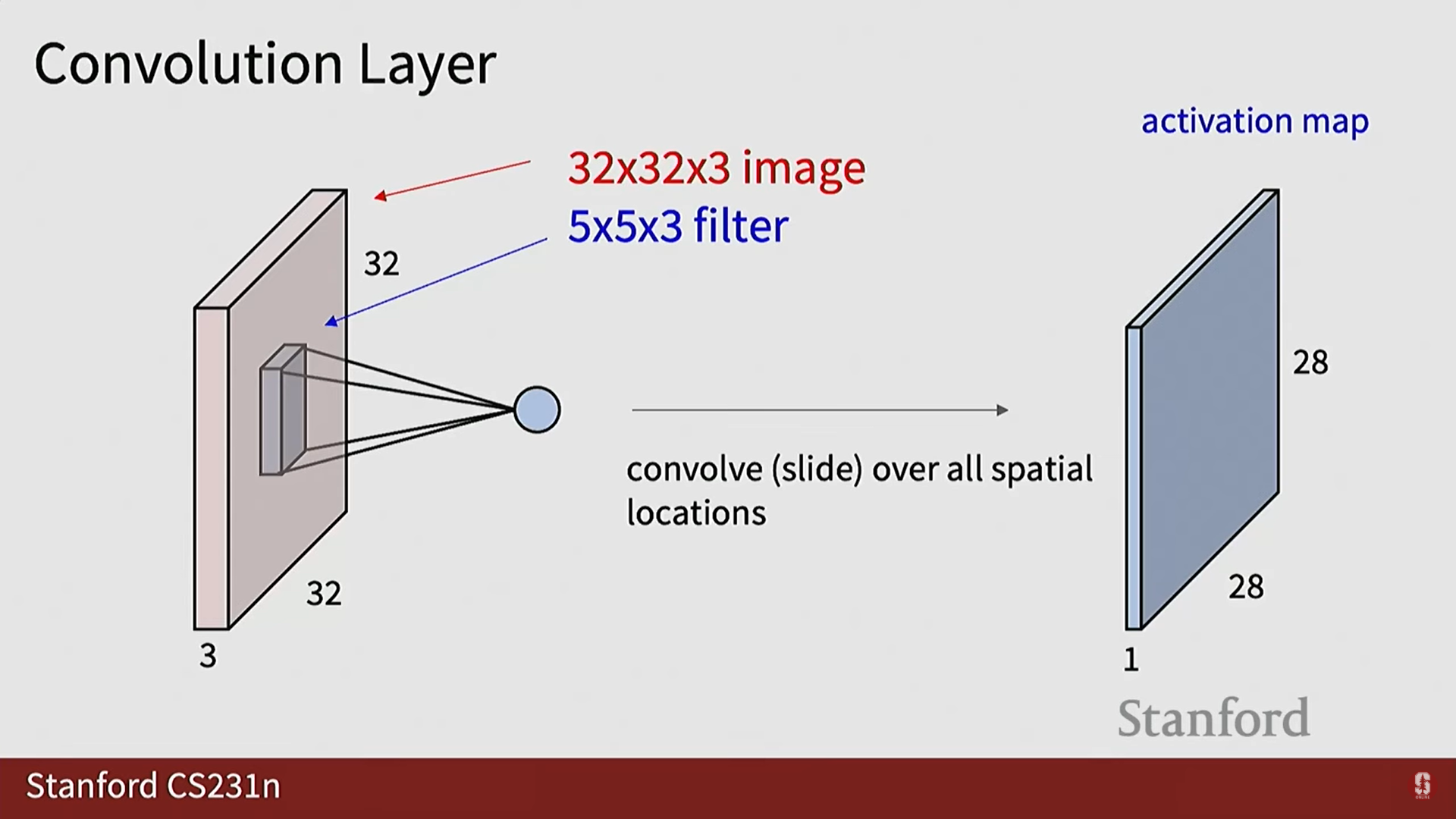
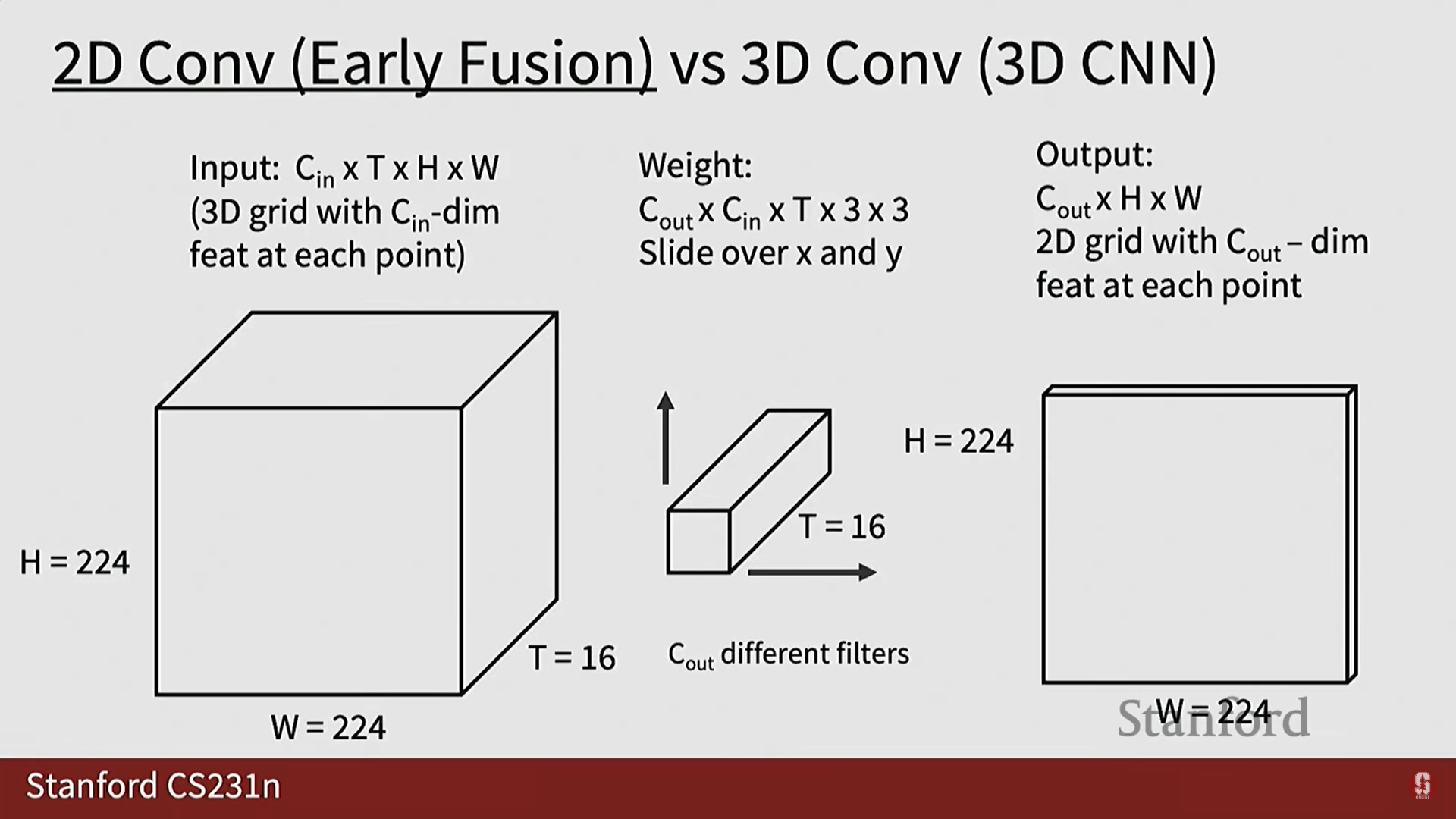
2. 3D 컨볼루션 신경망 (3D CNN): 느린 융합 (Slow Fusion)
1) 3D CNN의 개념

- 아이디어: 얼리 퓨전이나 레이트 퓨전 대신, 네트워크가 진행되는 동안 시간 차원과 공간 차원에 걸쳐 정보를 점진적으로 융합(Slow Fusion)합니다.
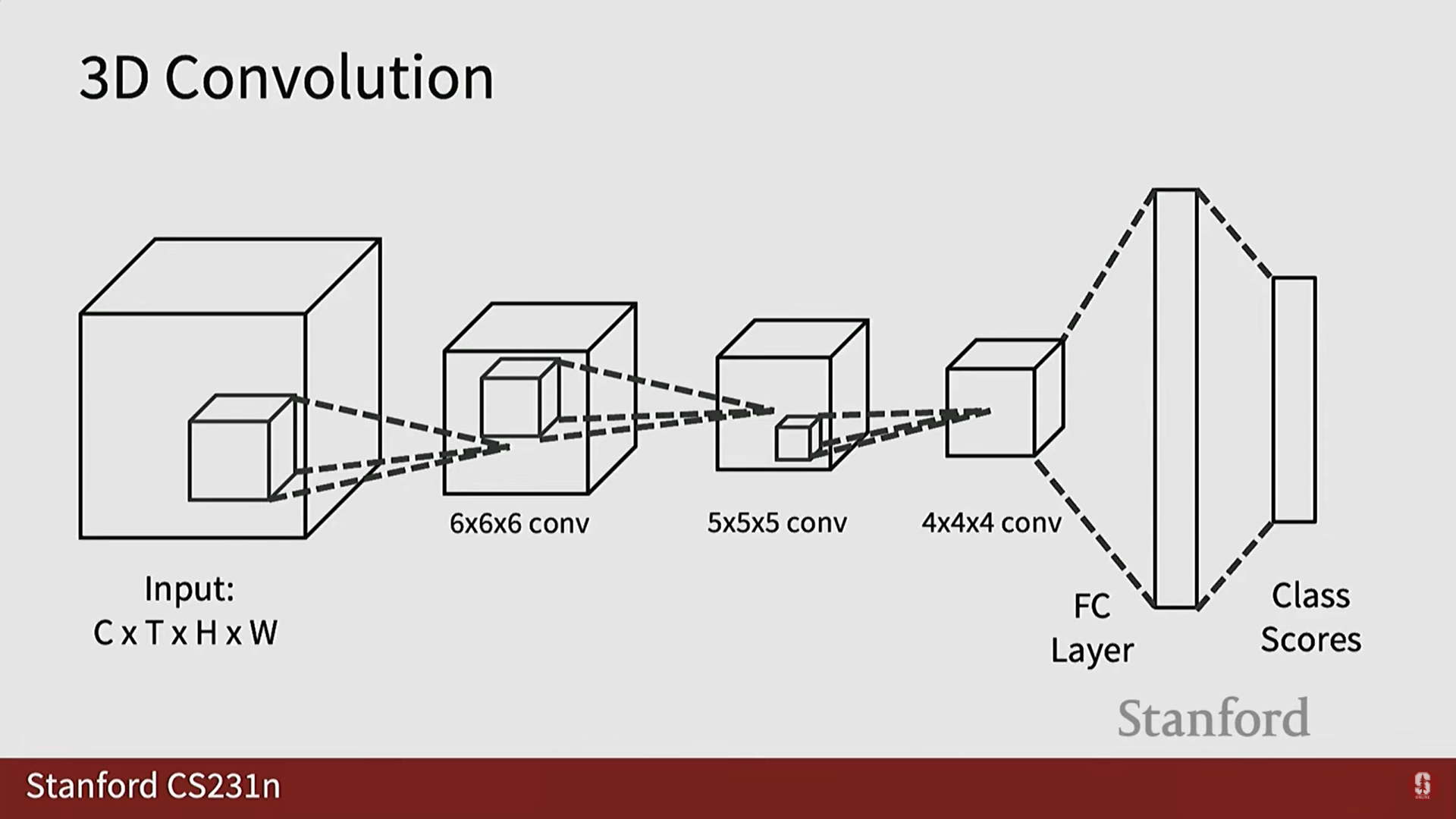
- 3D 컨볼루션 연산:
- 2D 컨볼루션 필터()가 공간()과 채널()을 따라 슬라이딩되는 것과 달리, 3D 컨볼루션 필터()는 시간() 차원을 포함하여 큐브 형태로 슬라이딩됩니다.
- 3D CNN은 3D 컨볼루션 및 3D 풀링 연산을 사용하여 3D 특징 맵을 점진적으로 축소합니다.
- 최종적으로 특징 벡터를 평탄화하고 완전 연결 레이어를 사용하여 클래스 점수로 매핑합니다.
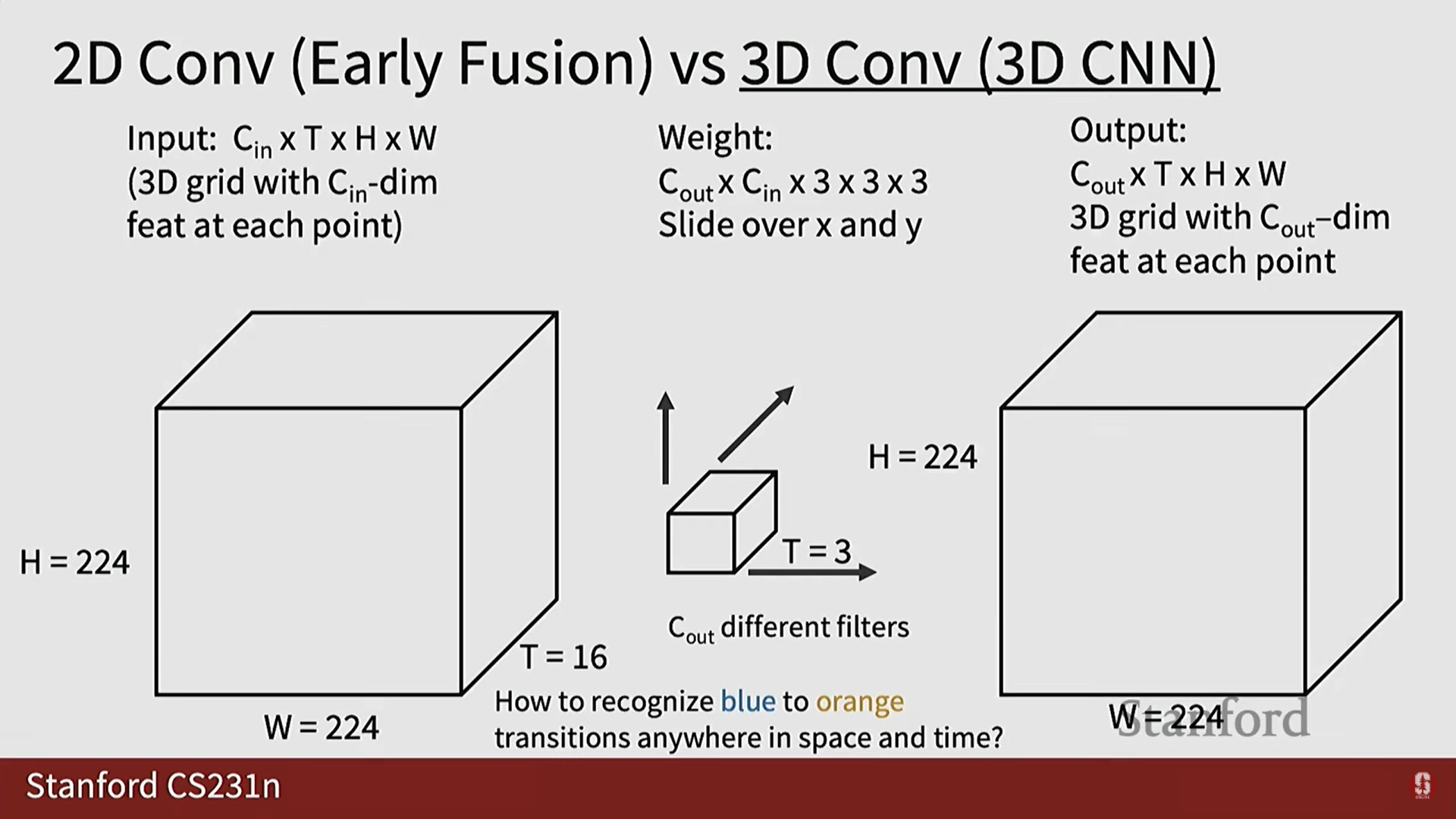
2) 3D CNN의 이점: 시간적 이동 불변성
- 문제점 (2D CNN/Early Fusion): 2D 컨볼루션 필터가 시간 차원 전체에 걸쳐 확장되는 경우 (예: 일 때 시간 차원 전체를 훑음), 시간적 이동 불변성(temporal shift invariance)이 없습니다.
- 만약 파란색에서 주황색으로의 색상 전환 패턴이 시간 단계 4와 시간 단계 15에서 모두 발생한다면, 이 두 패턴을 인식하기 위해 완전히 별개의 필터를 학습해야 합니다.
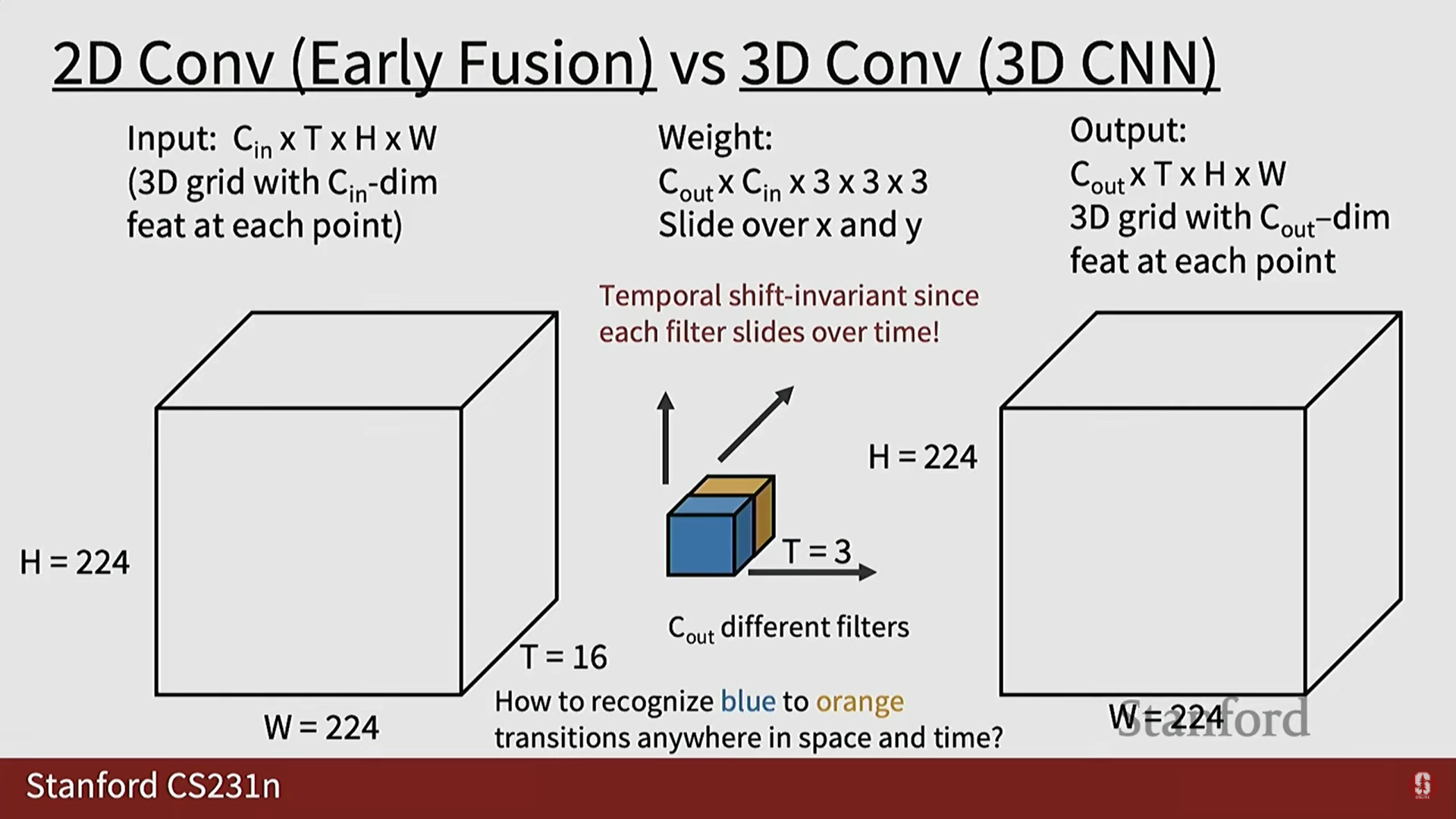
- 해결책 (3D CNN): 3D 컨볼루션 필터는 시간 내의 지역적 창(local window in time)만을 포착하고, 시간 차원을 따라 슬라이딩됩니다.
- 이로 인해 시간적 이동 불변성이 생깁니다. 동일한 필터를 재사용하여 시간 흐름의 어느 순간에서든 동일한 동작 패턴을 인식할 수 있습니다.
- 이는 2D 이미지 분류에서 커널을 공유하여 공간적 불변성을 달성하는 것과 유사한 개념입니다.



3) C3D 네트워크: 3D CNN의 VGG (심화)
- C3D (Convolutional 3D) Networks는 3D 컨볼루션 네트워크의 초기 인기 버전입니다 (2014년경).
- 기술적 배경: 2D 이미지 분류에 사용되는 VGG 아키텍처와 매우 유사하게 설계되었으나, 모든 2D 연산을 3차원(예: 컨볼루션, 풀링)으로 변환했습니다. 이 때문에 "3D CNN의 VGG"라고 불립니다.
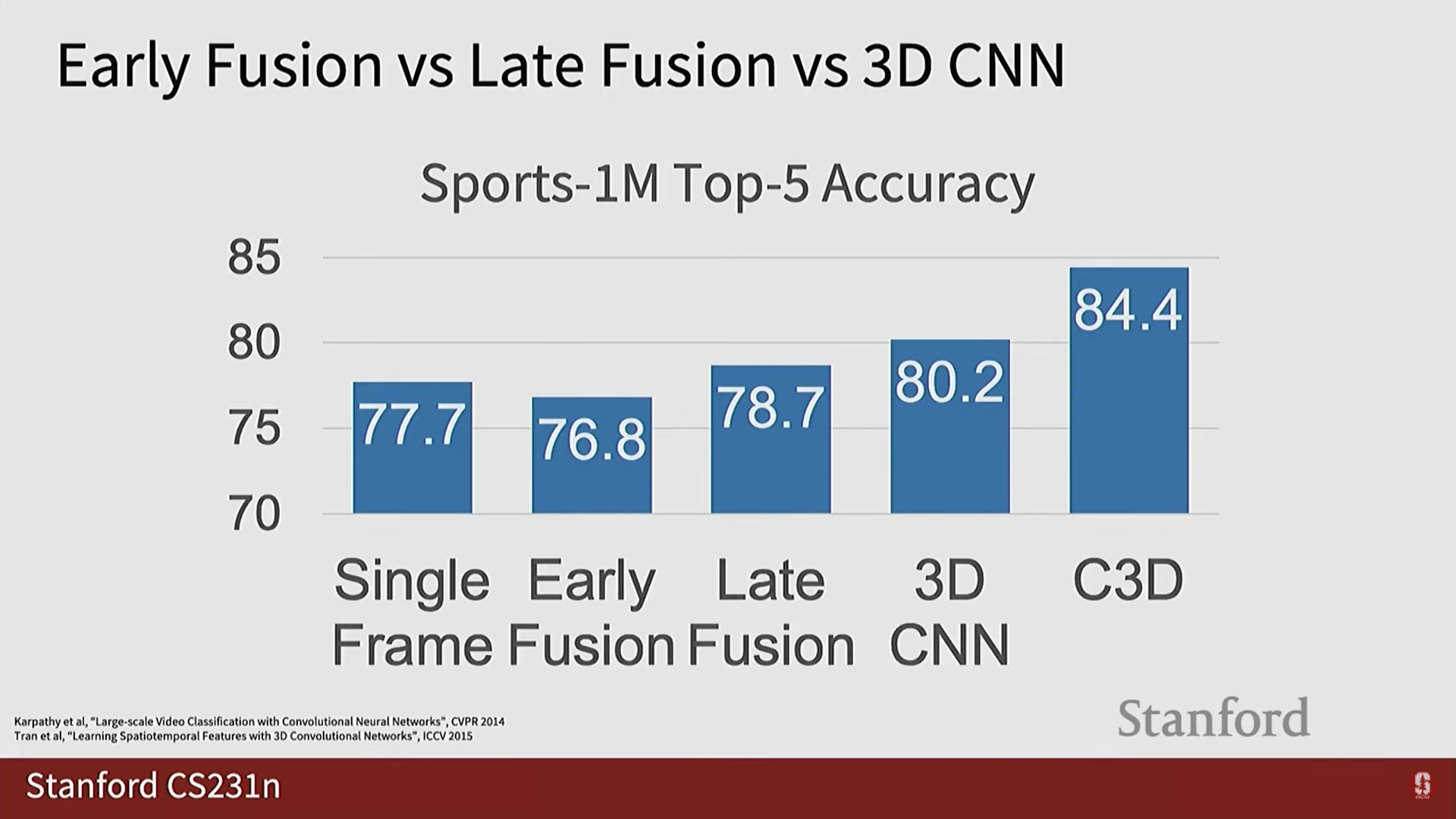
- 성능 및 한계점:
- C3D는 계산 비용이 매우 높습니다. 단일 정방향 통과(forward pass)에 39.5 GFLOPs가 필요하며, 이는 VGG16 (13.6 GFLOPs)보다 약 2.9배 더 큽니다. (GFLOPs는 네트워크의 효율성을 측정하는 부동 소수점 연산 횟수입니다).
- 활용 및 영향: C3D는 Sports 1 Million 데이터셋으로 훈련되었으며, 당시에 많은 GPU 자원이 없던 연구자들이 이 사전 훈련된 가중치(pre-trained weights)를 비디오 특징 추출기(feature extractor)로 활용하면서 대중화되었습니다.
- 결과: Sports 1 Million 데이터셋에서 C3D는 단일 프레임 모델 대비 약 4%의 Top-1 정


3. 동작(Motion) 명시적 모델링 및 장기 시간 구조
1) 광학 흐름과 두 스트림 네트워크 (Two-Stream Networks)
-
동기: 인간은 외형(Appearance) 정보가 거의 없더라도 움직임(Motion)만으로도 활동을 매우 잘 인식합니다. 외형과 동작을 분리하여 처리하는 네트워크가 필요하다는 아이디어가 제기되었습니다.
-
광학 흐름 (Optical Flow): 동작을 명시적으로 측정하는 방법입니다.
- 정의: 인접한 두 프레임(와 ) 사이에서 픽셀이 얼마나 움직였는지를 측정합니다 (픽셀의 속도 추정).
- 수학적 표현: 프레임 에서 픽셀 위치 의 움직임은 로 표현되며, 가 됩니다 (밝기 불변 가정).
- 특징: 수평 흐름()과 수직 흐름() 두 차원으로 구성되며, 저수준 동작 단서(low-level motion cues)를 포착합니다.

-
두 스트림 네트워크 (Two-Stream Network):
- 공간 스트림 (Spatial Stream, 외형): 단일 프레임 2D CNN을 사용하여 외형 정보를 분류합니다.
- 시간 스트림 (Temporal Stream, 동작): 인접한 프레임 쌍에서 계산된 다중 프레임 광학 흐름 맵(수평/수직 흐름을 쌓은 것)을 입력으로 받아 Temporal Stream CNN으로 처리하여 동작을 분류합니다.
- 결합: 두 스트림의 예측 결과를 종합하여 최종 예측을 얻습니다.

-
심화 내용 (UCF 101 결과): UCF 101 데이터셋에서 테스트했을 때, 동작 스트림(Temporal Only)의 성능이 외형 스트림(Spatial Only)보다 훨씬 뛰어난 것으로 나타났습니다.
- 해석: 동작 스트림은 배경 정보(불필요할 수 있는)에 덜 영향을 받고, 활동 인식에 핵심적인 움직임 단서에 집중하므로 과적합(overfit)이 더 어렵기 때문일 수 있습니다.
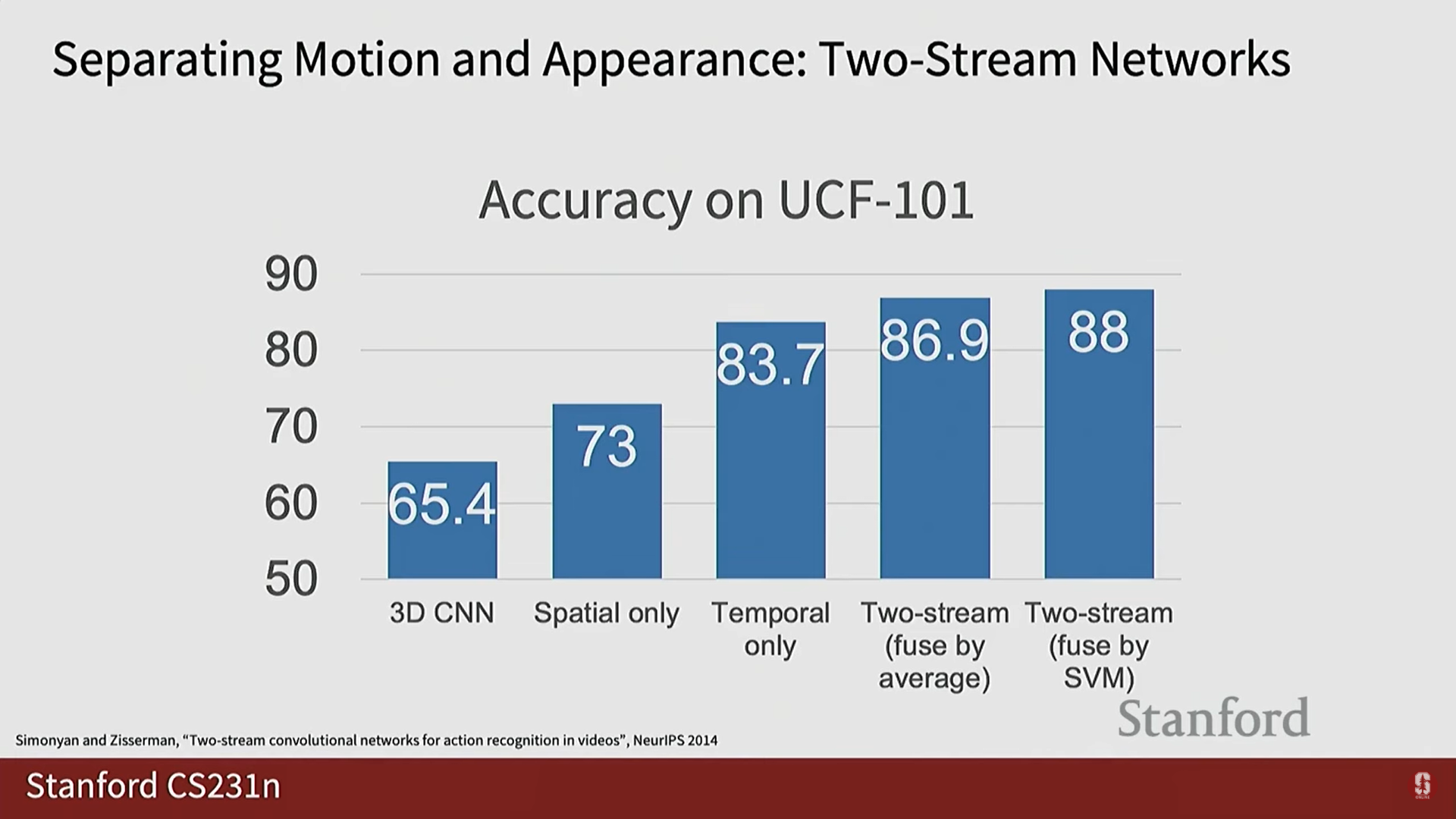
- 해석: 동작 스트림은 배경 정보(불필요할 수 있는)에 덜 영향을 받고, 활동 인식에 핵심적인 움직임 단서에 집중하므로 과적합(overfit)이 더 어렵기 때문일 수 있습니다.
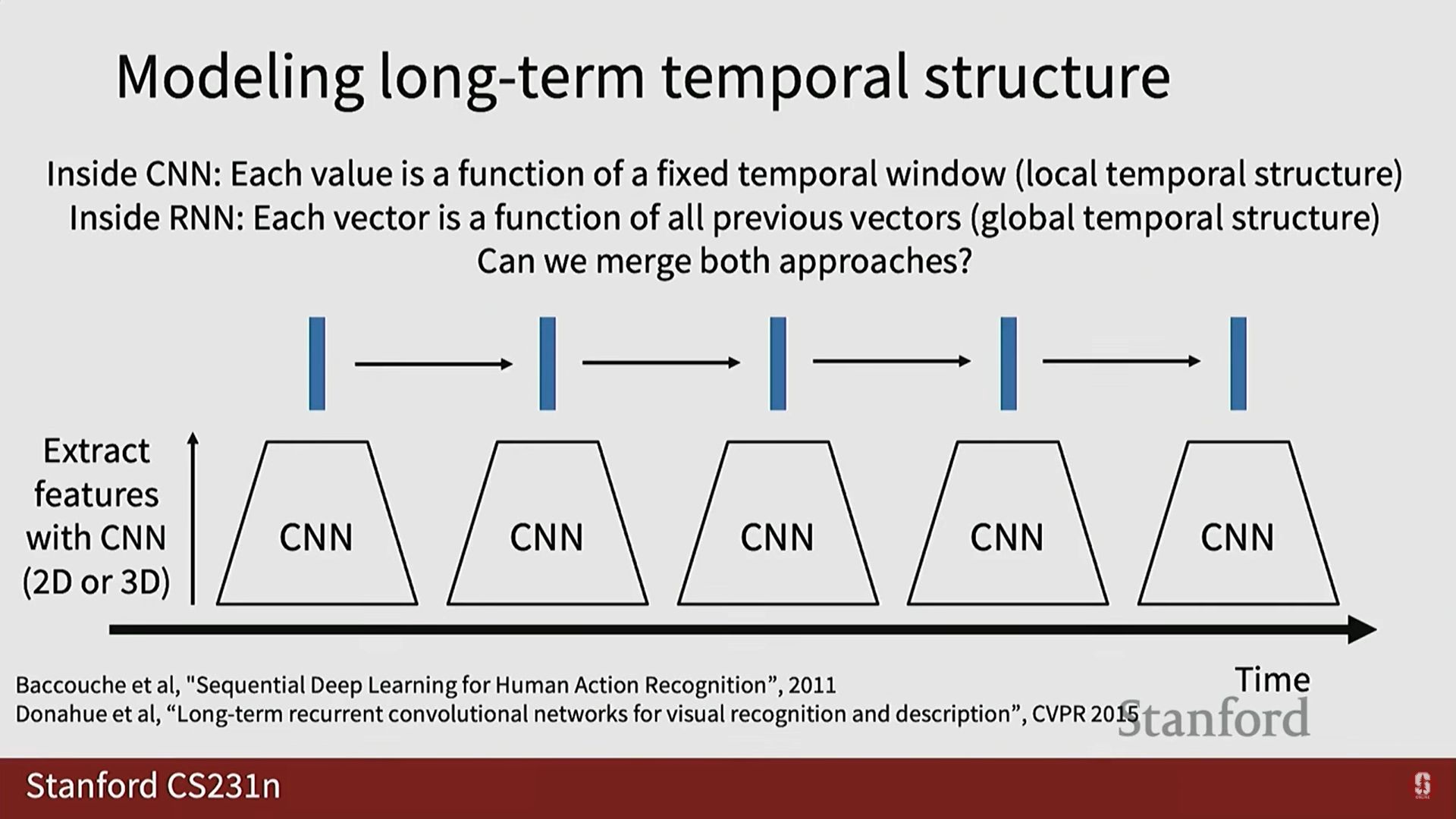
2) 순환 신경망 (RNN/LSTM)을 이용한 장기 구조 모델링
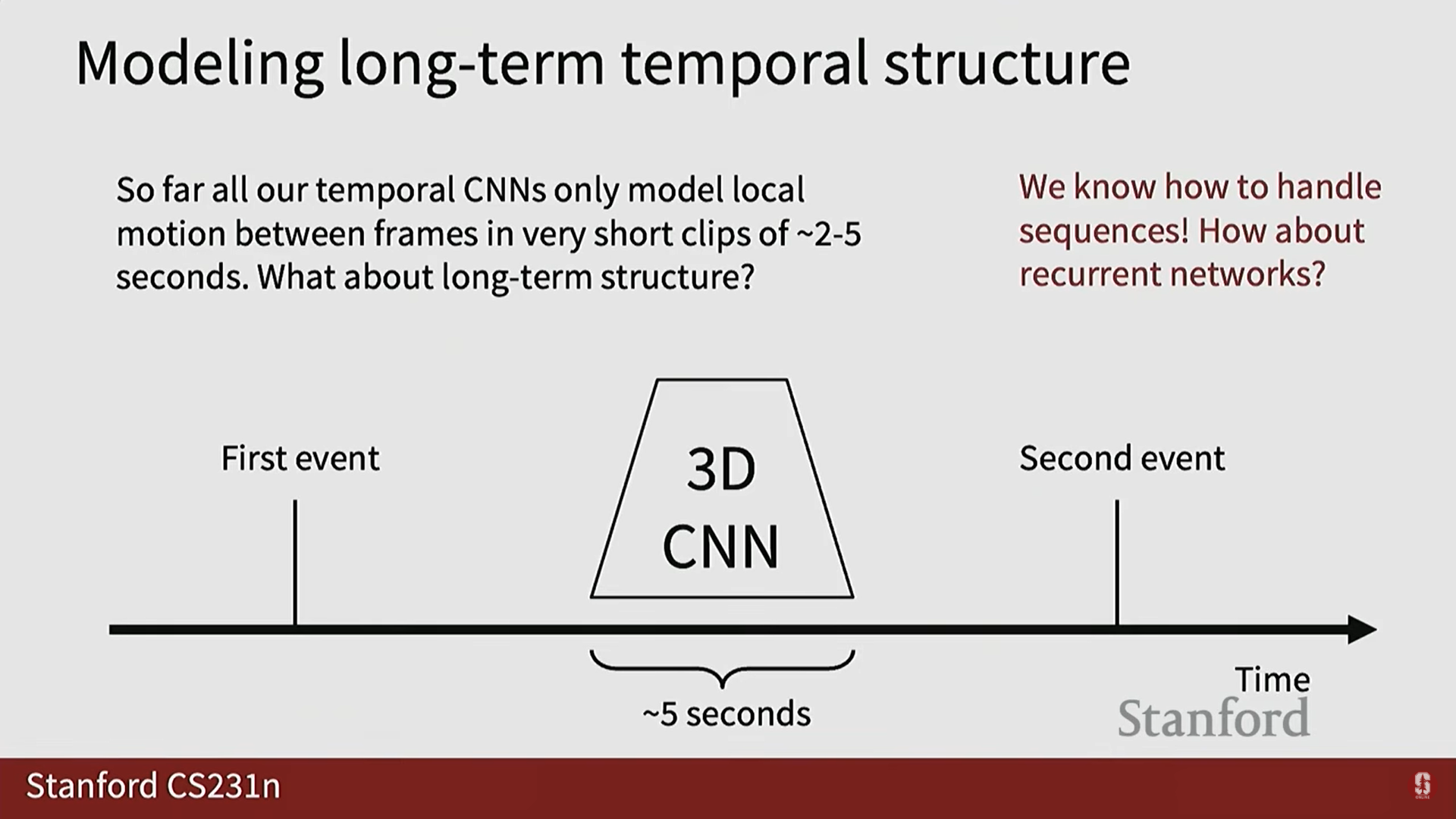
- 짧은 클립이 아닌 장기적인 시간 구조(long-term temporal structure)를 모델링하는 것도 중요합니다.
- 활용: 단어 시퀀스 처리에 사용되는 순환 신경망(RNN) 또는 LSTM을 활용합니다.
- 로컬 특징(Local Features): 2D CNN이나 3D CNN을 사용하여 짧은 클립에서 특징 벡터를 추출합니다.
- 시퀀스 처리: 추출된 로컬 특징 시퀀스를 RNN/LSTM에 입력하여 장기적인 시간 구조를 모델링합니다.
- 다대일 매핑 (Many-to-One): 비디오의 마지막 시점에서 단일 비디오 레벨 분류 예측을 수행합니다.
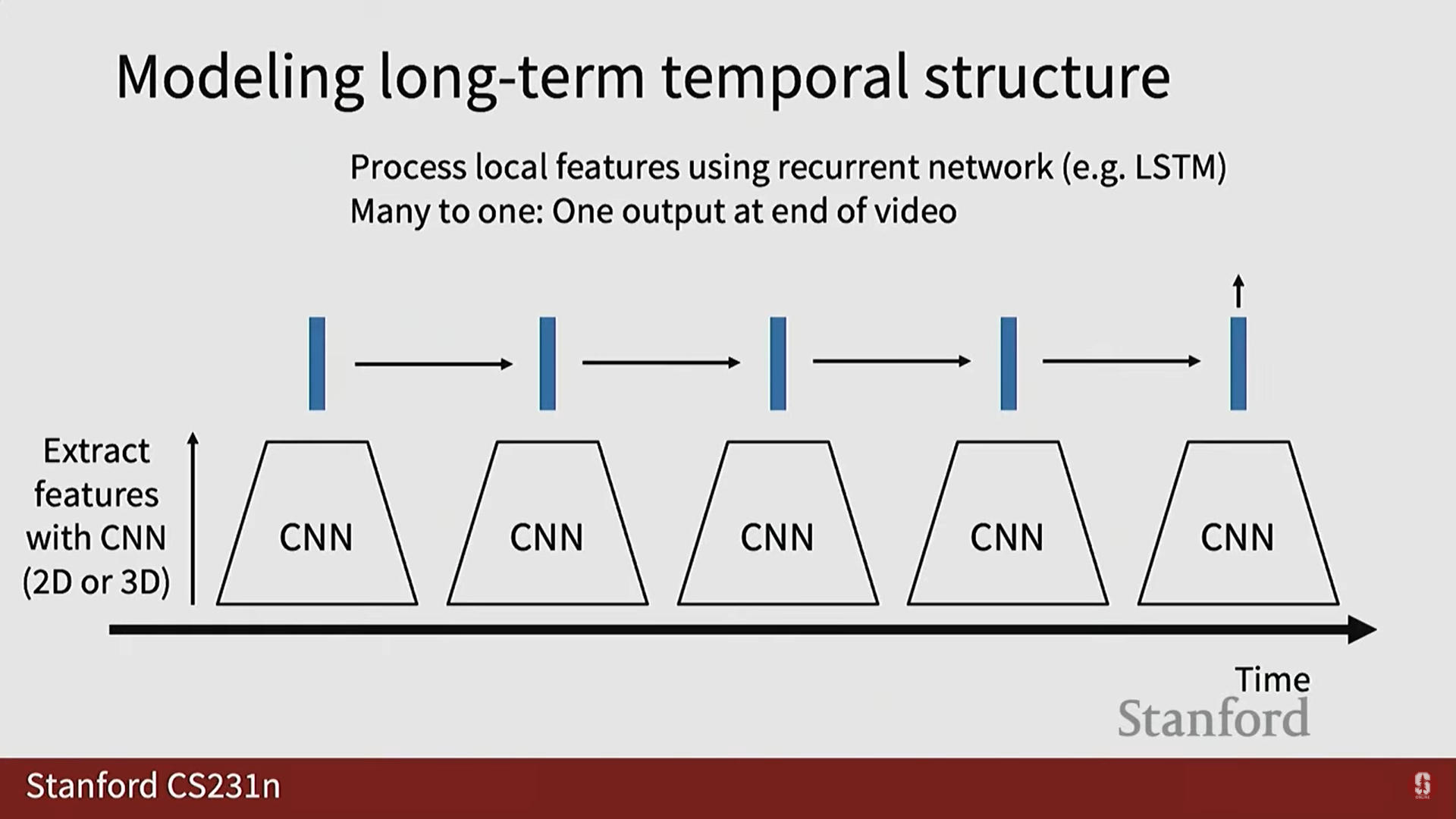
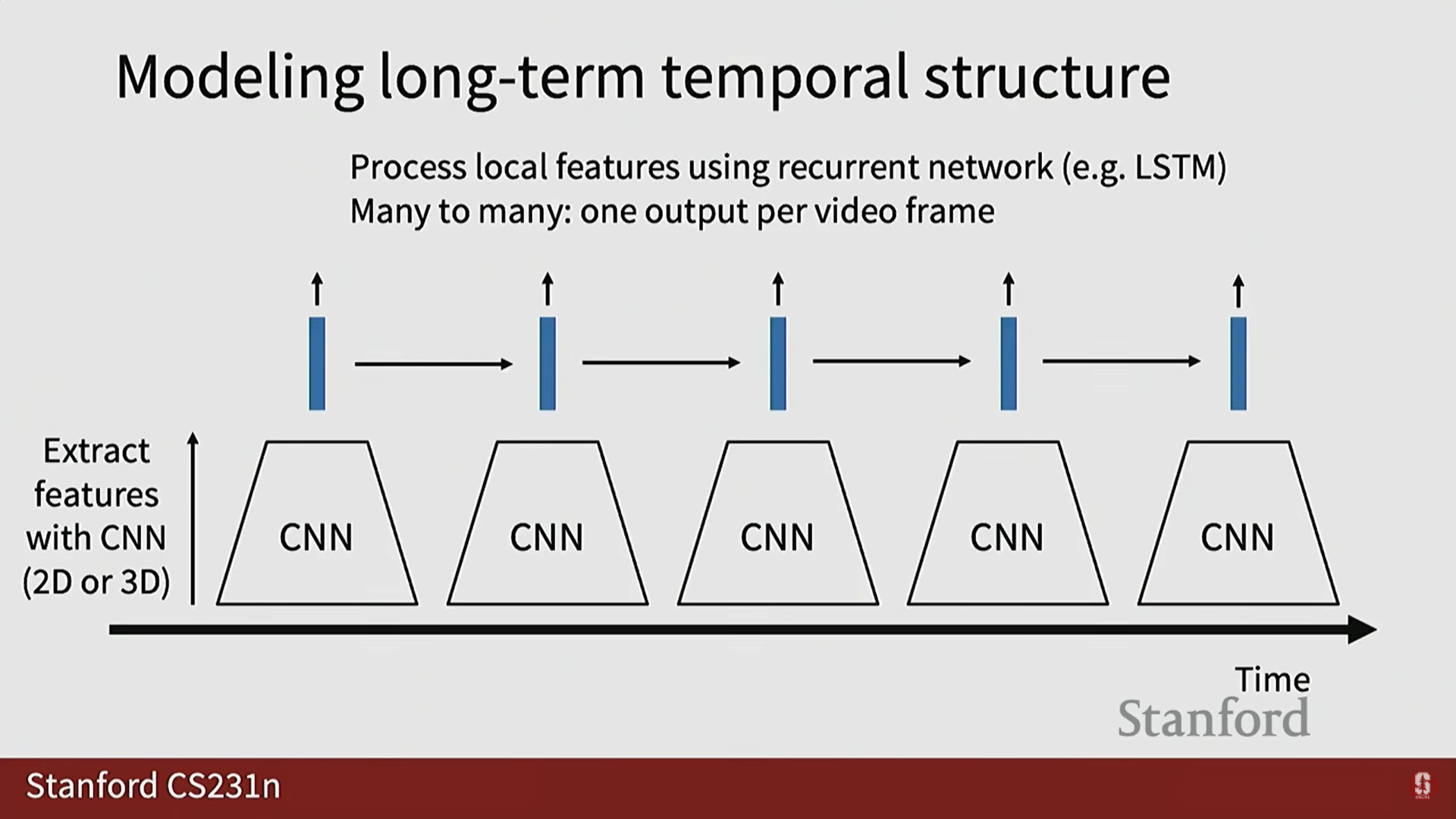
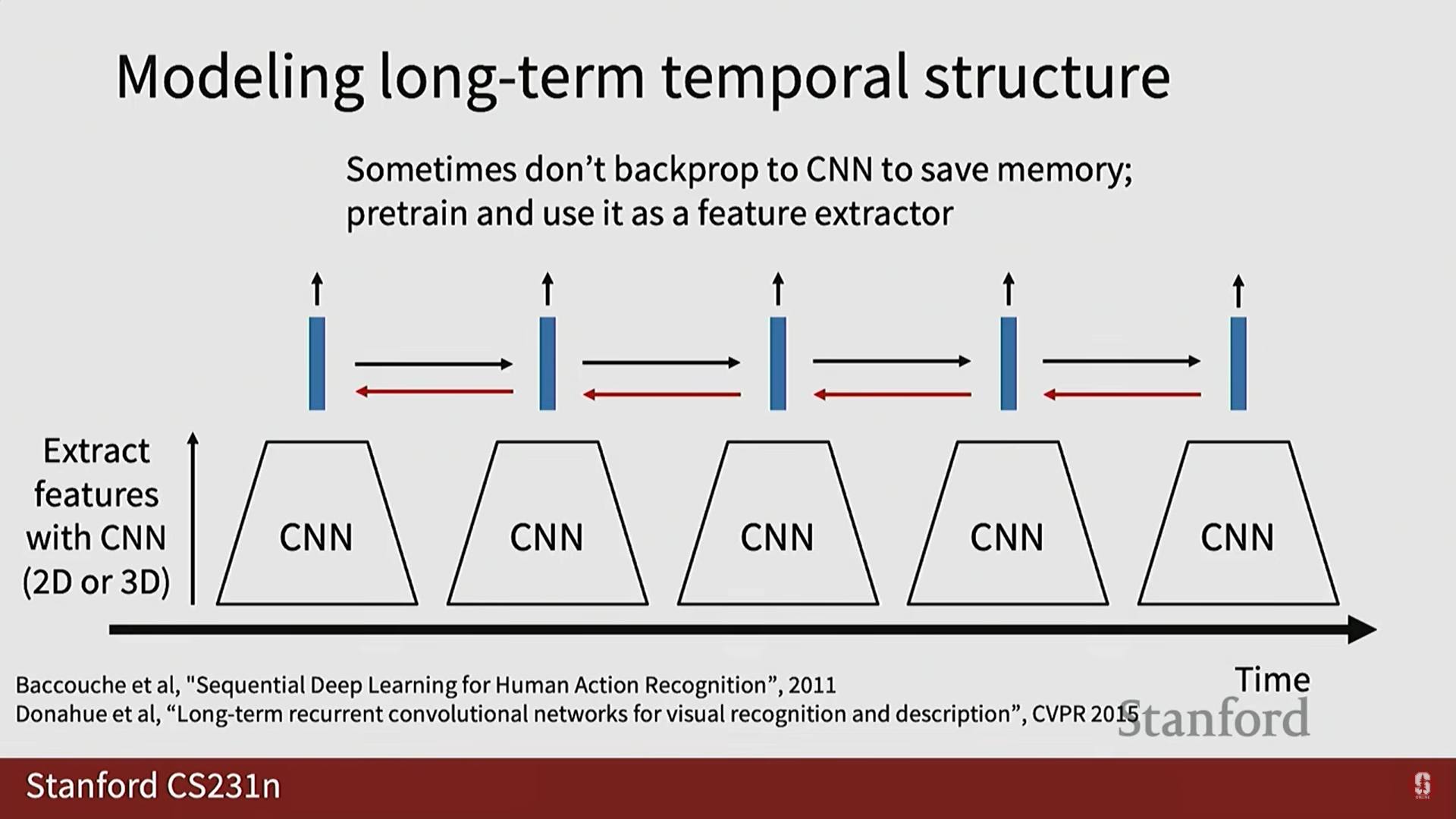
- 학습 전략: 전체 네트워크를 종단 간(end-to-end) 학습하기 어려울 경우, 컨볼루션 네트워크(예: C3D)를 특징 추출기로 사용하고 RNN 레이어만을 역전파(backpropagate)하여 학습할 수 있습니다.
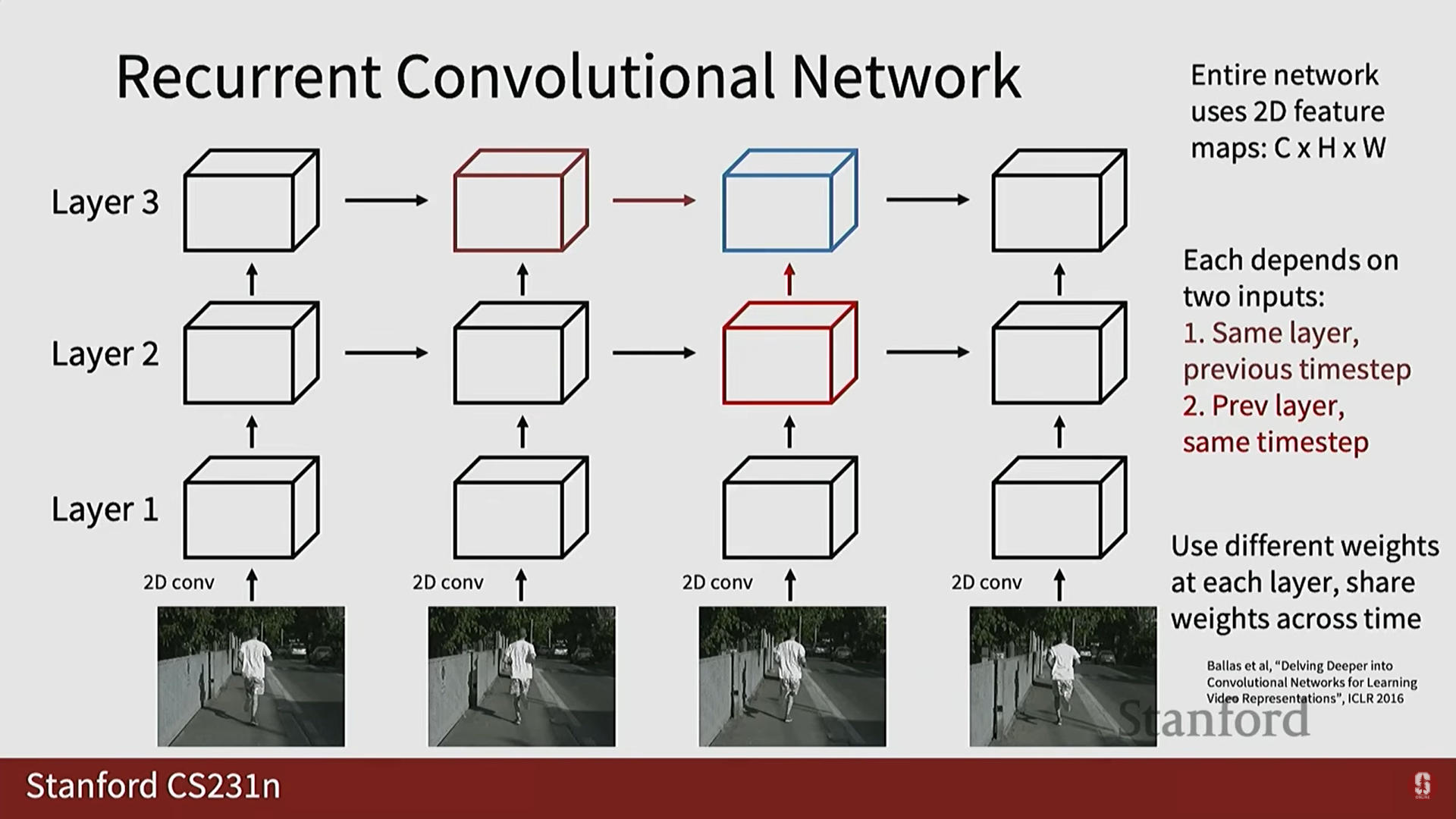
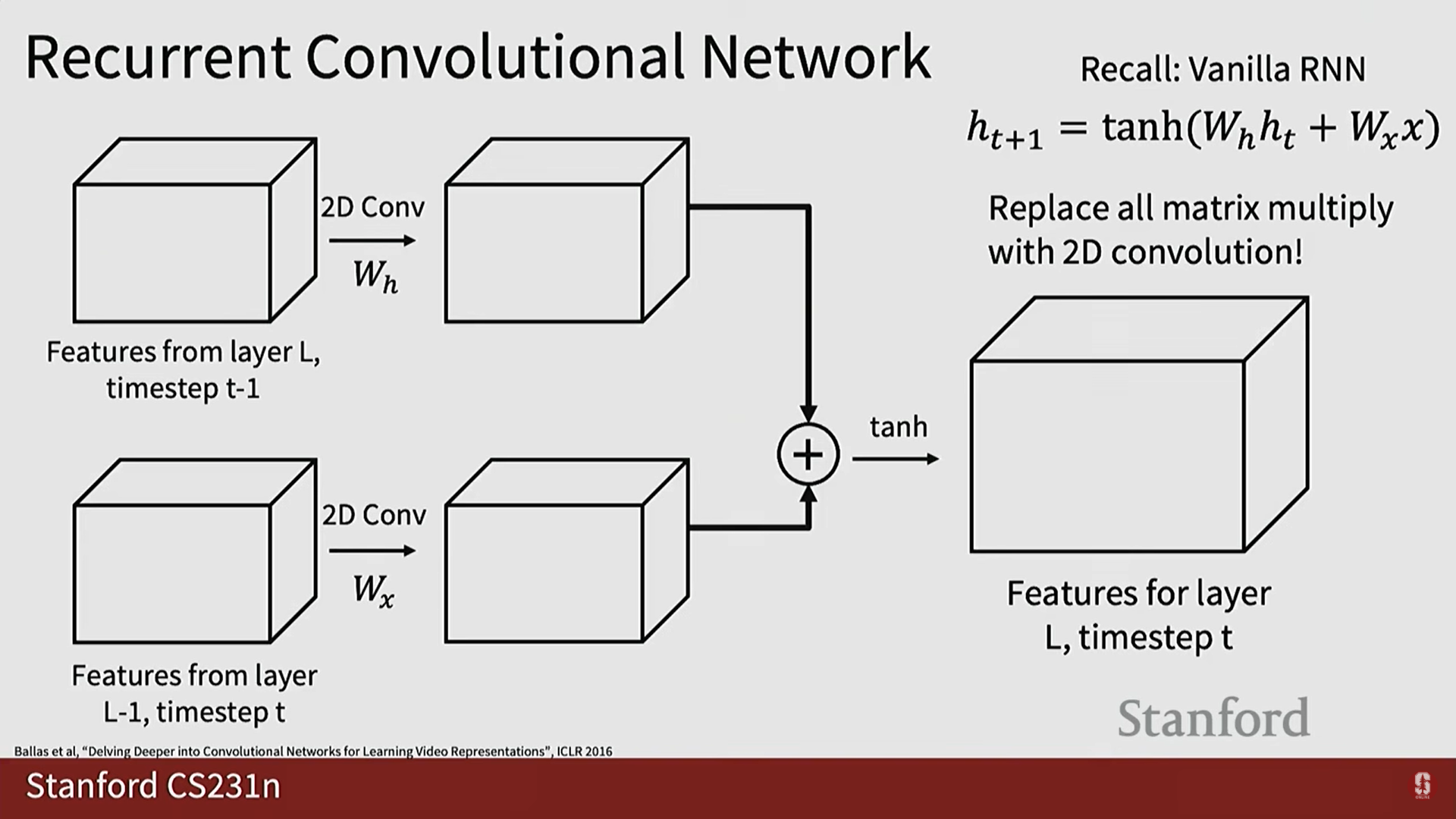
3) 순환 컨볼루션 신경망 (RCNN)
- 아이디어: 컨볼루션의 장점과 RNN의 장점을 하나의 아키텍처에 결합합니다.
- 구조: 다층 RNN에서 영감을 받았습니다. 각 시점의 특징 맵()은 다음 두 입력을 받습니다:
- 같은 레이어의 이전 시간 단계 특징 맵.
- 이전 레이어의 같은 시간 단계 특징 맵.
- 연산: RNN의 핵심인 행렬 곱셈 연산을 2D 컨볼루션 연산으로 대체합니다.
- 형태에서 행렬 곱 를 2D 컨볼루션 로 대체합니다.
- 한계점 (심화): RCNN은 공간적/시간적 융합을 동시에 수행할 수 있지만, RNN 계열의 근본적인 단점인 느린 처리 속도를 가지며, 비디오처럼 긴 시퀀스에 대해 병렬화(parallelization)가 매우 어렵습니다.

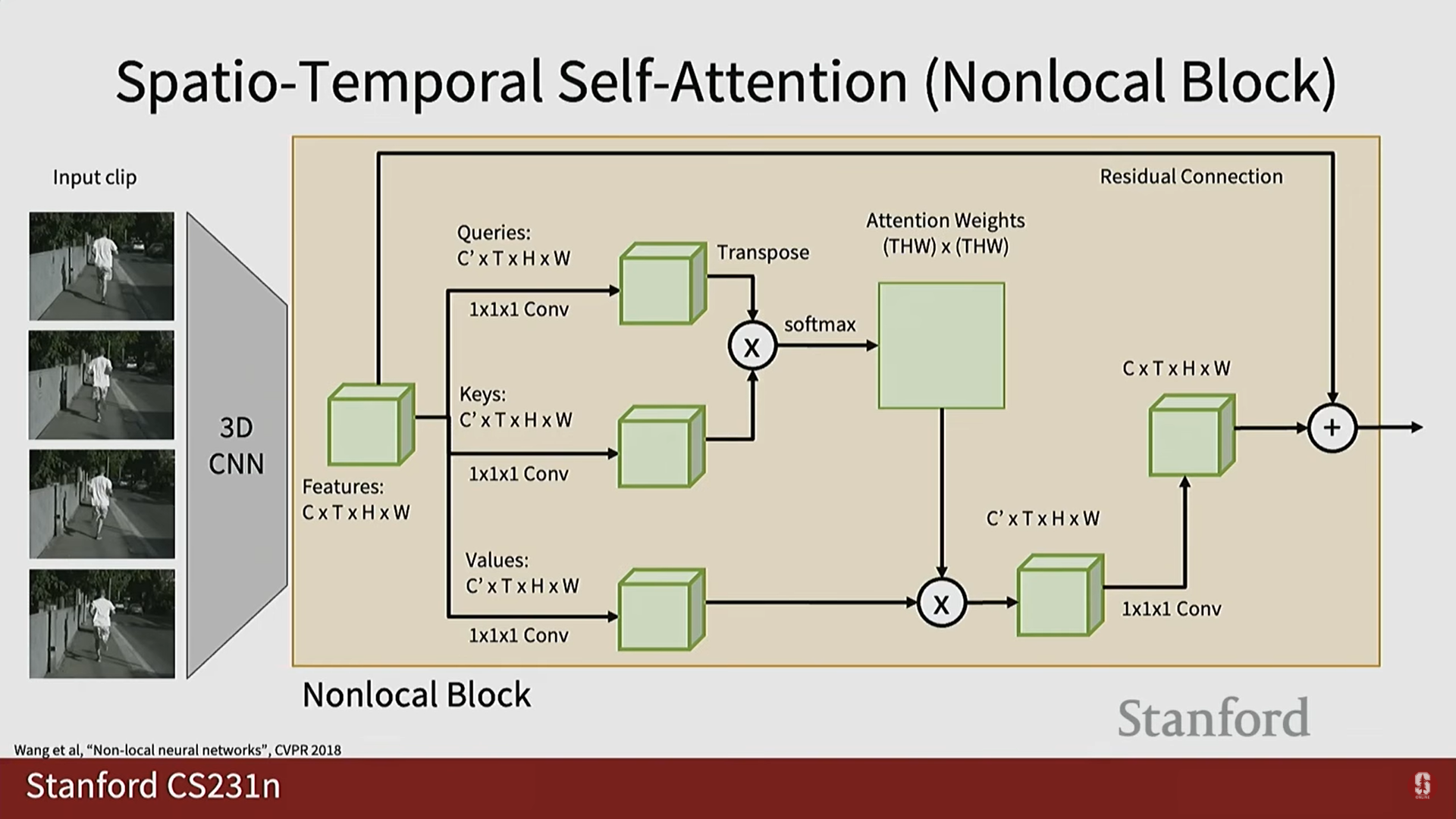
4) 자기 주의 (Self-Attention)와 비지역적 네트워크 (Non-Local Networks)
- 대안: RNN의 느린 속도를 극복하기 위해 자기 주의(Self-Attention) 메커니즘을 사용합니다. 자기 주의는 정렬 및 점수 계산이 완벽하게 병렬화 가능하다는 큰 장점이 있습니다.
- 비지역적 네트워크 (Non-Local Networks): 자기 주의 메커니즘을 3D 비디오 처리로 확장한 것입니다.
- 과정: 3D CNN에서 추출된 특징 맵()을 1x1x1 3D 컨볼루션을 사용하여 쿼리(Query), 키(Key), 값(Value) 특징 맵으로 변환합니다.
- 연산: 쿼리와 키의 내적을 통해 어텐션 점수를 계산하고, 이를 값에 적용하여 최종 출력 특징 맵을 얻습니다.
- 특징: Non-Local 블록은 공간과 시간을 가로질러 융합하는 강력한 빌딩 블록으로, 기존 3D CNN 아키텍처에 추가하여 성능을 향상할 수 있습니다.

4. 2D 모델의 재활용: I3D 아키텍처
1) 2D 네트워크의 3D 팽창 (Inflation)
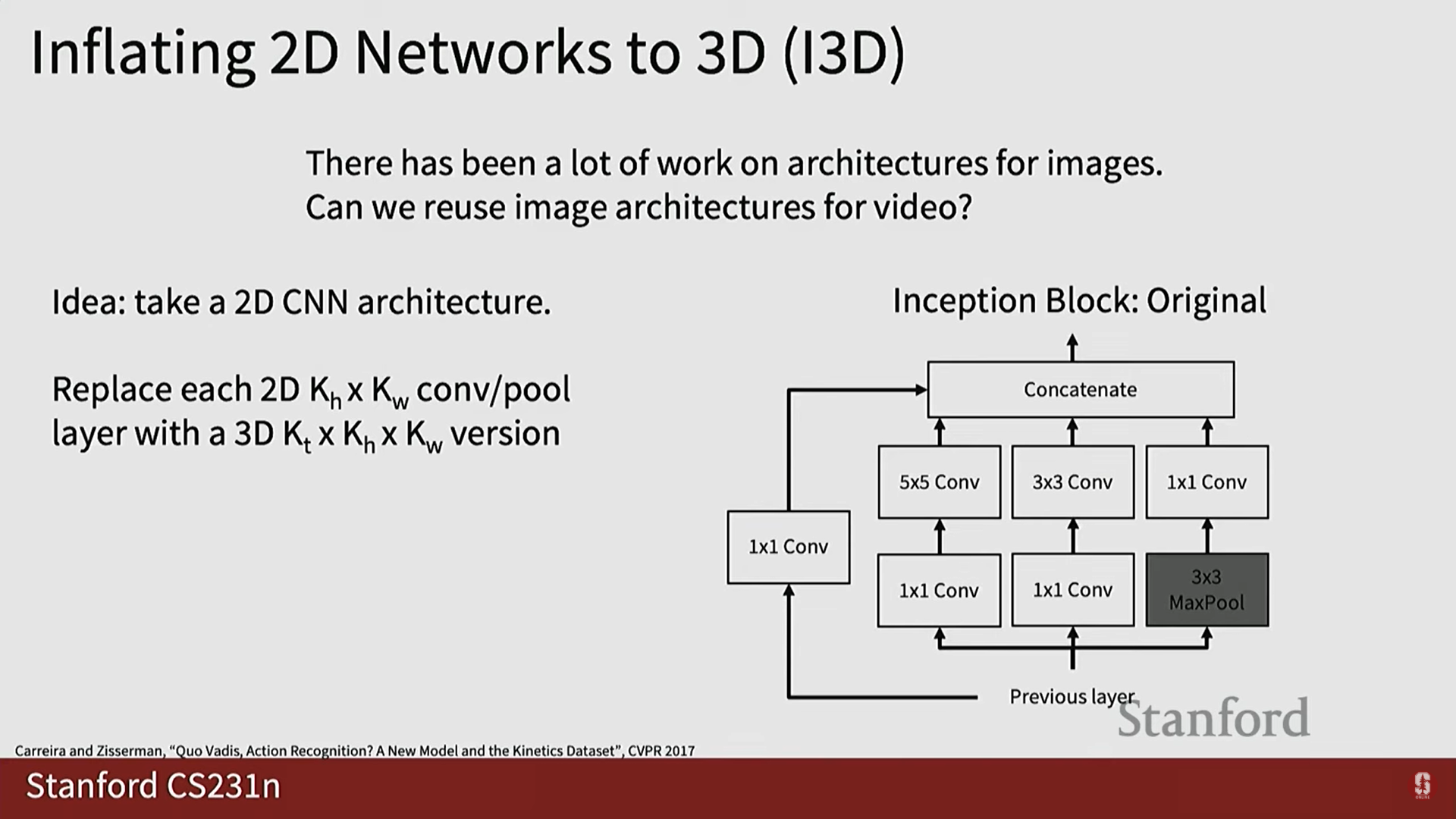
- 아이디어: 2D 이미지 분류에서 성공적인 아키텍처들을 3D로 재사용하는 방법입니다.
- I3D (Inflated 3D) Architecture:
- 기존의 2D CNN 아키텍처(예: Inception Block)에서 각 2D 컨볼루션 및 풀링 레이어를 3D 버전으로 팽창(Inflate)하여 대체합니다.
- 차원의 커널을 차원으로 확장하여 3D CNN 아키텍처를 만듭니다.
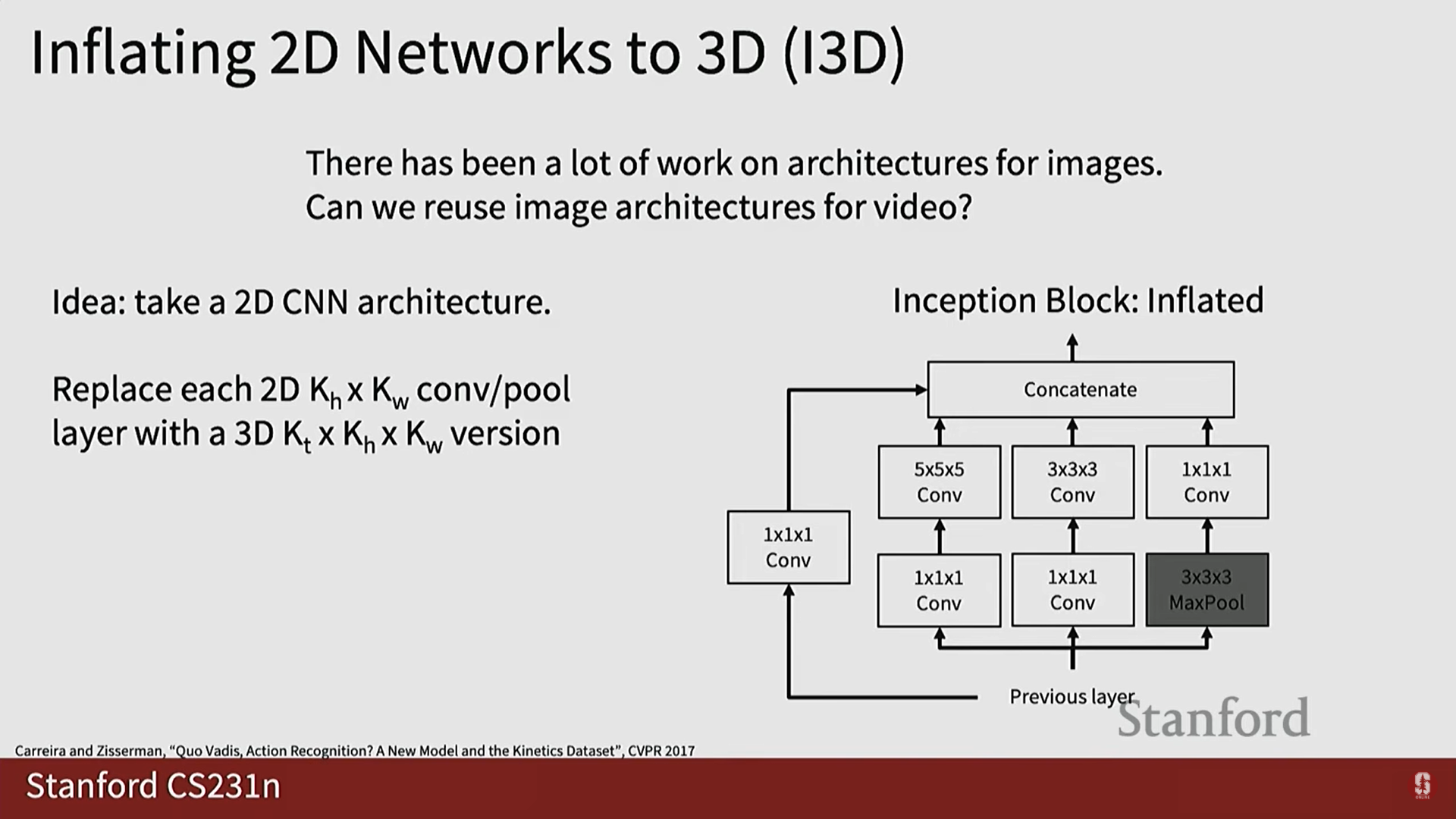


2) 가중치 전이 (Weight Transfer)
- 아이디어: 아키텍처뿐만 아니라, 이미지 데이터셋에서 사전 훈련된 2D 모델의 가중치도 3D 모델로 전이하여 초기화에 활용할 수 있습니다.
- 과정:
- 2D 컨볼루션 커널을 시간 차원 만큼 복사합니다.
- 복사된 커널 값을 로 나누어 초기화합니다.
- 이점: 이렇게 팽창된 3D CNN을 단일 프레임 이미지에 입력하면 원본 2D CNN과 동일한 출력을 얻게 됩니다. 이를 통해 2D 이미지 이해에서 학습된 좋은 사전 정보(prior information)를 활용하여 비디오 모델 훈련의 좋은 초기화 지점(good initialization)을 제공합니다.
- 성능: I3D는 두 스트림 네트워크보다 더 나은 성능을 보였으며, 외형 스트림뿐만 아니라 동작 스트림(Optical Flow)에도 팽창 기법을 적용하여 추가적인 개선을 달성할 수 있습니다.
5. 최신 동향, 시각화 및 기타 비디오 이해 작업
1) 최신 비디오 트랜스포머 모델 (최신 동향)
- 2014년 이후 3D CNN이 발전해왔으며, 최근에는 트랜스포머 기반 모델이 큰 발전을 이루었습니다.
- 주요 모델:
- 시공간 어텐션 (Space-Time Attention): 공간과 시간을 분리하여 효율적인 어텐션을 수행합니다.
- 마스크 오토인코더 (Mask Autoencoders): 효율적이고 확장 가능한 비디오 레벨 사전 학습을 위해 활용됩니다.
- 성능 향상: Kinetics 400 대규모 비디오 데이터셋에서 단일 프레임 모델의 정확도가 62.2%에서 비디오 마스크 오토인코더 같은 최신 모델은 90%에 도달했습니다.
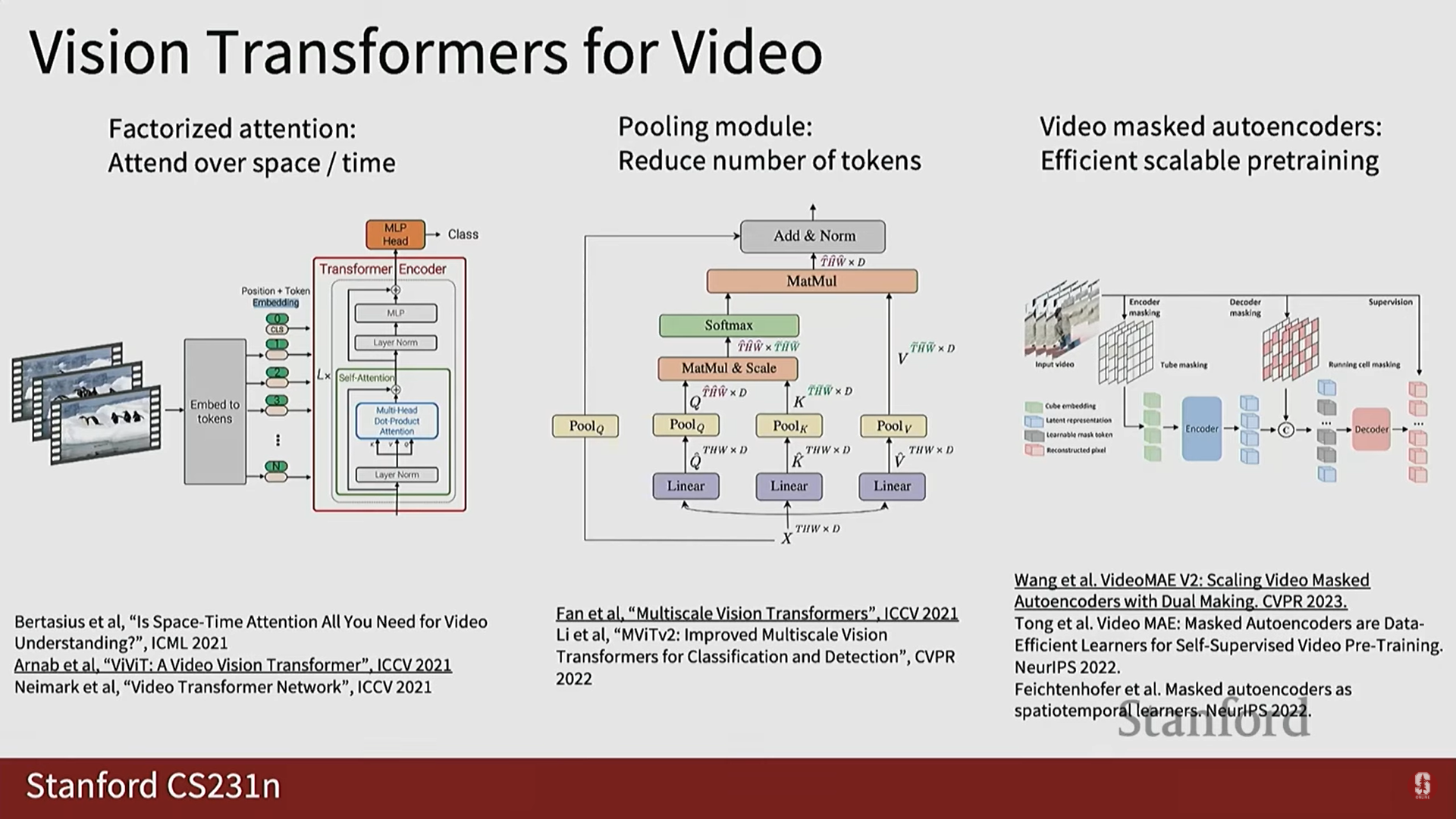
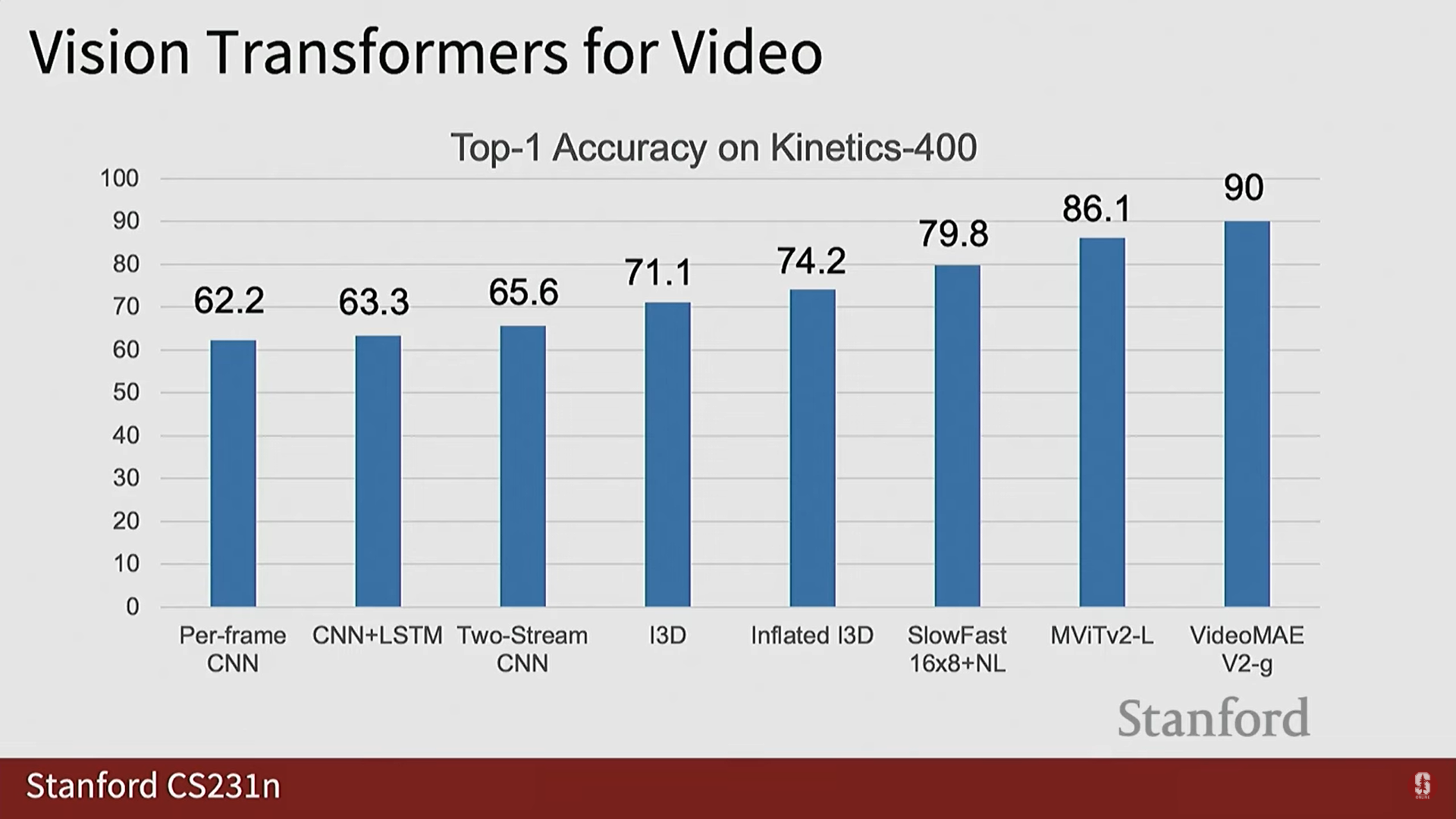
2) 모델 시각화 (Visualization)
- 2D 이미지 모델 시각화와 유사하게, 비디오 모델도 해석이 가능합니다.
- 방법: 특정 클래스의 점수를 최대화하도록 (Gradient Ascent 사용) 외형 이미지와 광학 흐름 이미지를 최적화하여 모델이 학습한 내용을 시각화합니다.
- 결과: 이 방법을 통해 비디오 모델, 특히 동작 모델이 역도(weight lifting)와 같은 특정 활동의 움직임 패턴을 성공적으로 학습하고 있음을 확인할 수 있습니다.
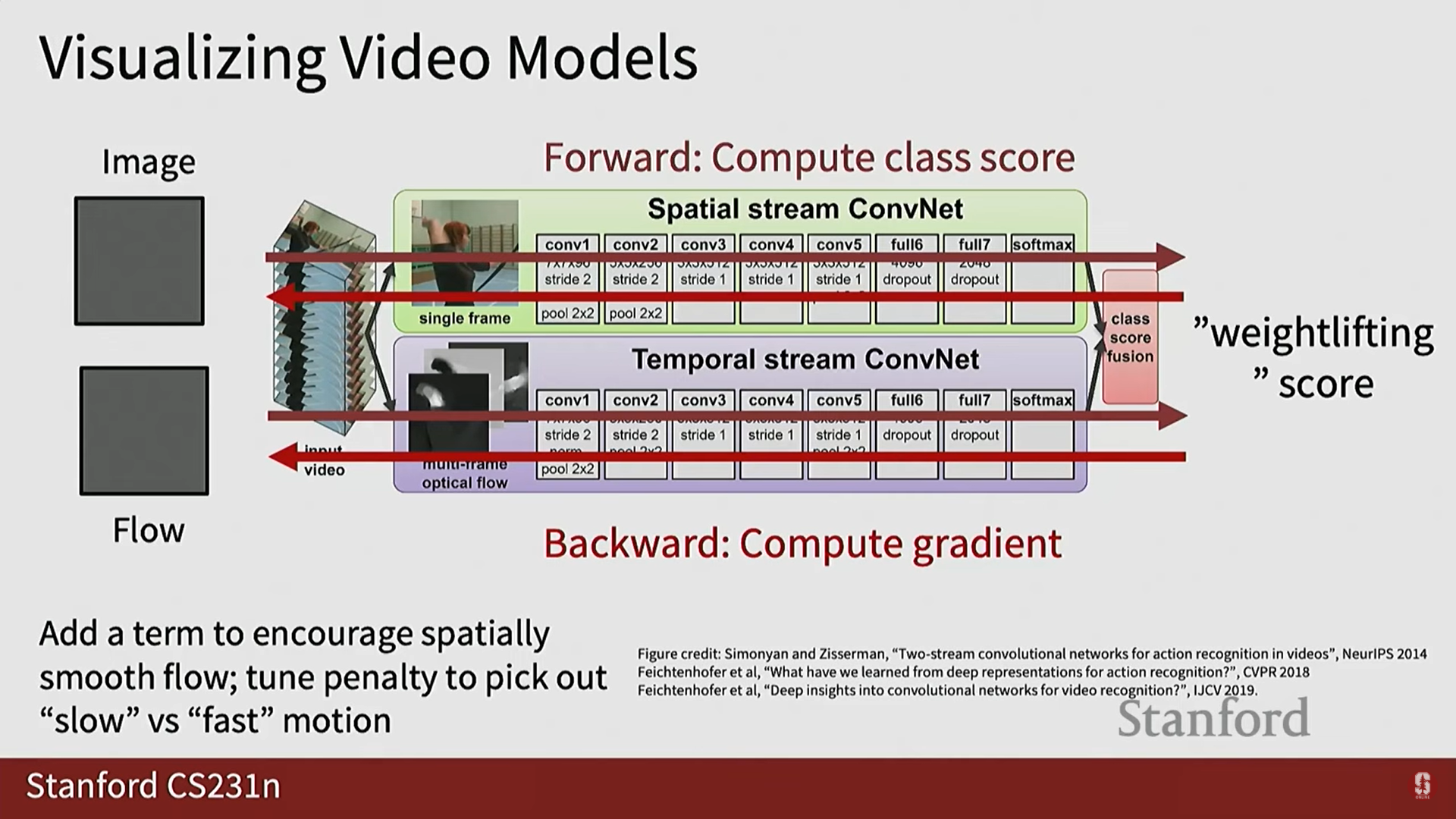


3) 비디오 이해의 다른 핵심 작업
- 시간적 행동 위치 파악 (Temporal Action Localization): 클립 수준 분류를 넘어, 비디오 내에서 활동이 언제(temporal proposal) 발생하는지 시간적으로 위치를 파악하는 작업입니다. Fast R-CNN과 유사한 아이디어를 적용할 수 있습니다.
- 시공간 탐지 (Spatial Temporal Detection): 활동이 비디오 내에서 어디서(공간), 그리고 언제(시간) 발생하는지를 모두 위치 파악하는 작업입니다.


6. 다중 감각 비디오 이해 (Multimodal Video Understanding)
1) 오디오-비주얼(Audio-Visual) 통합
- 비디오는 시각 정보 외에도 오디오(소리)라는 중요한 양식을 포함하고 있습니다.
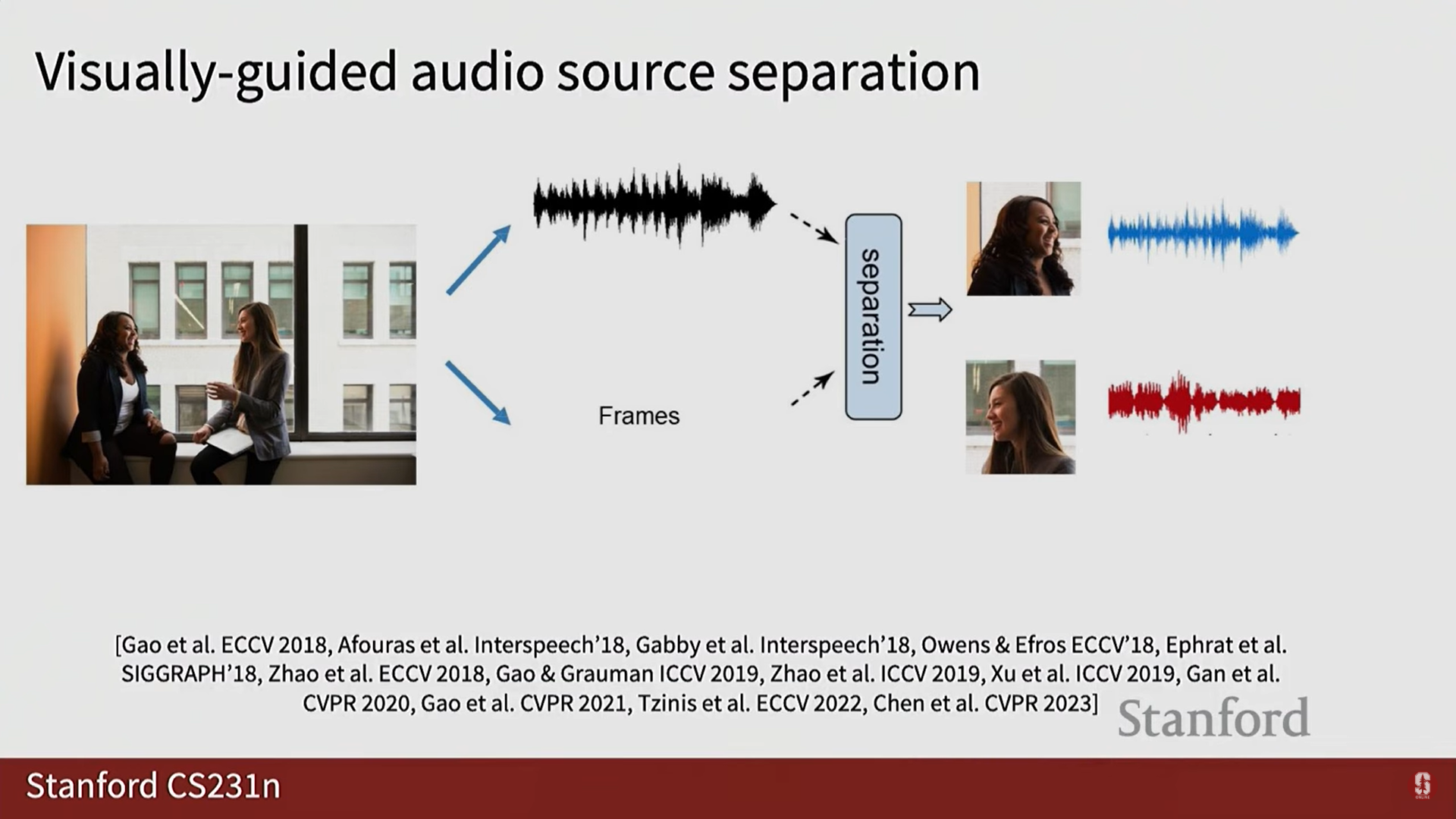
- 비주얼 가이드 오디오 소스 분리 (Visually Guided Audio Source Separation): 시각 정보를 사용하여 혼합된 음향 구성 요소(Mixture)를 분리하는 작업입니다.
- 예시: 여러 화자(Speaker)가 있는 경우, 각 사람의 시각 정보를 사용하여 개별 목소리를 분리하거나, 악기의 움직임을 분석하여 음악 악기를 분리하는 작업.
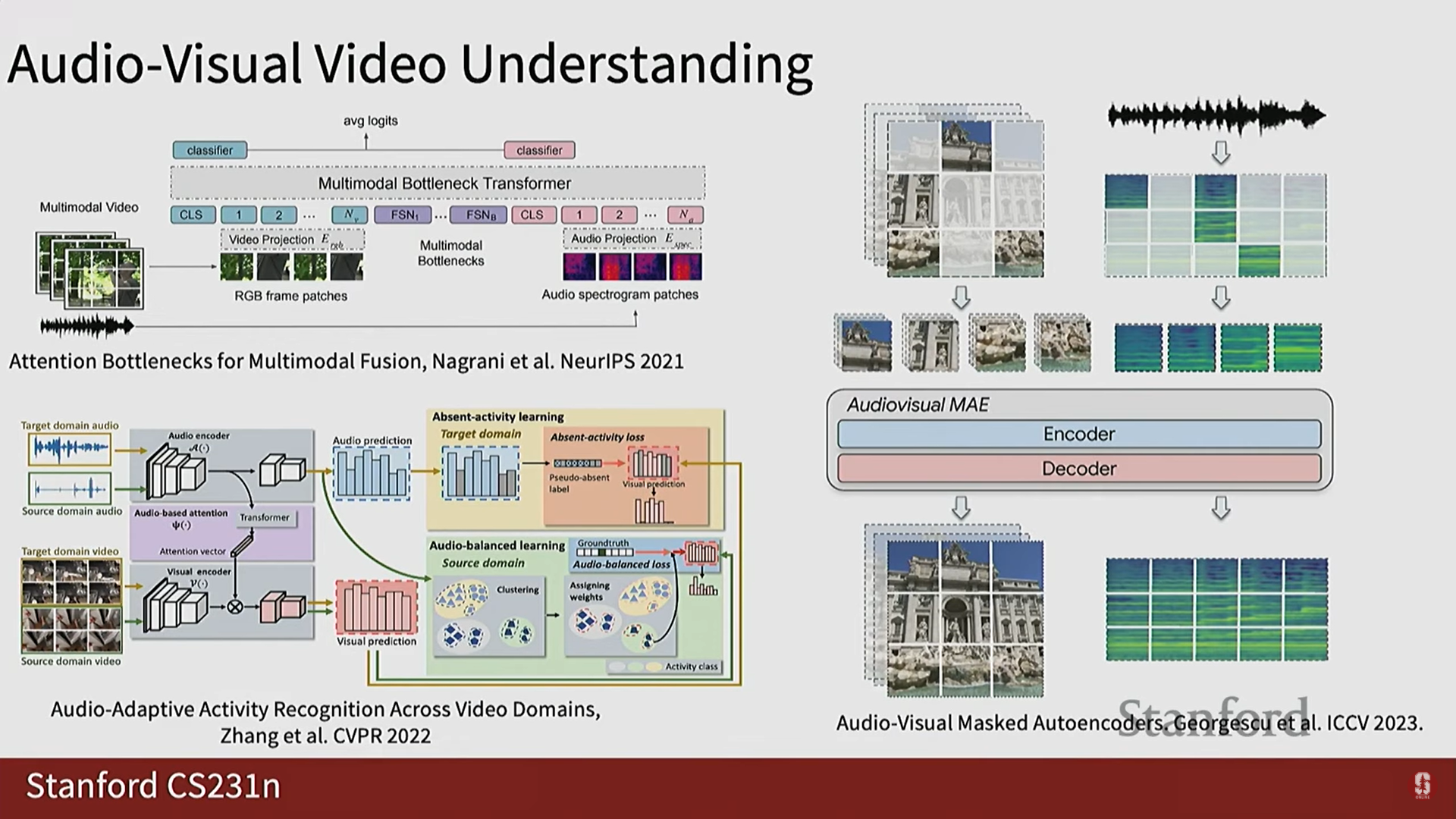
- 오디오-비주얼 분류 모델: 오디오 스펙트로그램을 이미지 패치처럼 패치로 매핑하고, 트랜스포머 아키텍처를 사용하여 시각 정보와 함께 분류를 수행합니다.

2) 효율적인 비디오 이해 (Efficient Video Understanding)
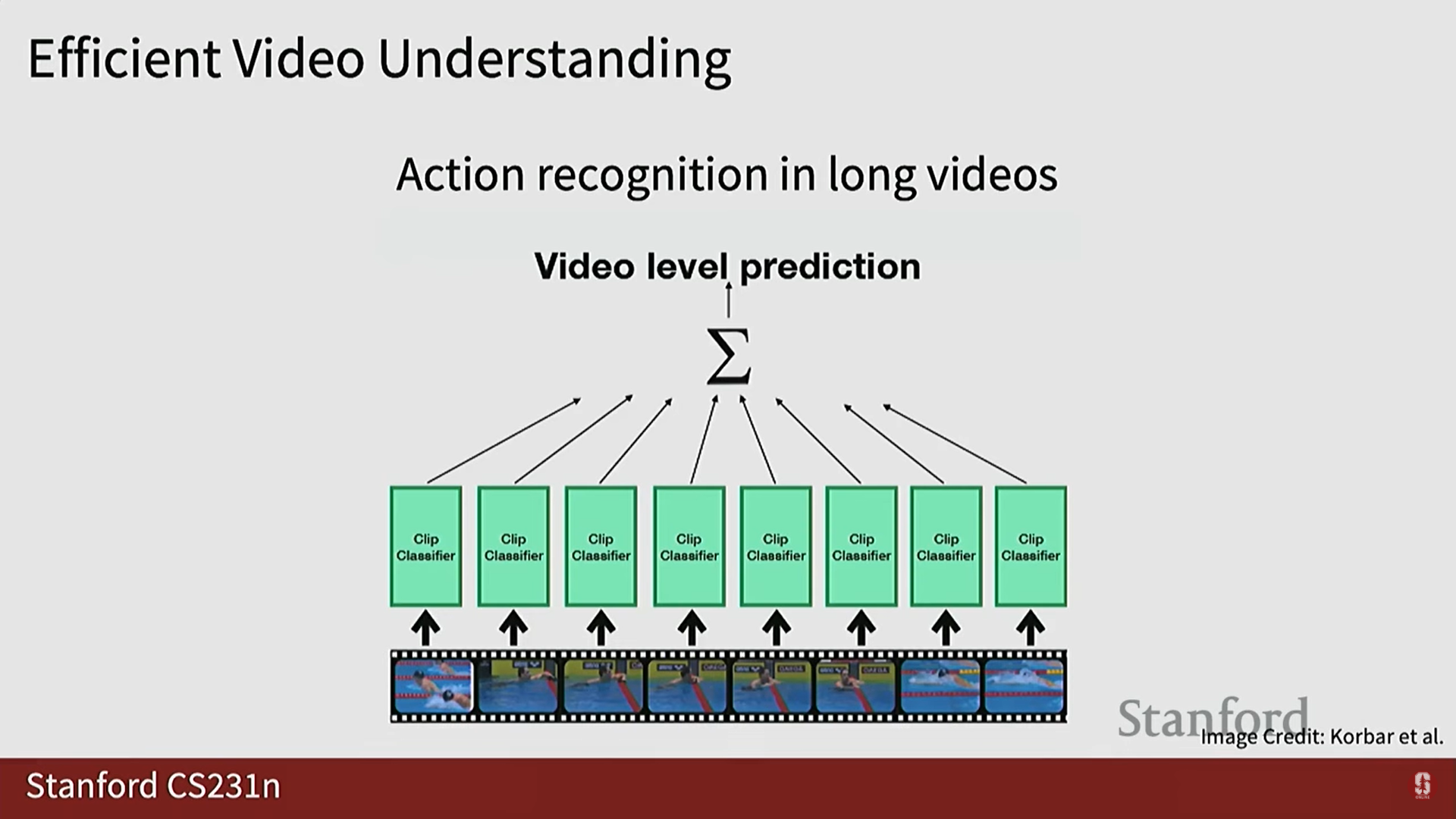
- 비디오가 매우 길기 때문에 모든 클립을 처리할 수 없습니다.
- 효율성 증진 기법:
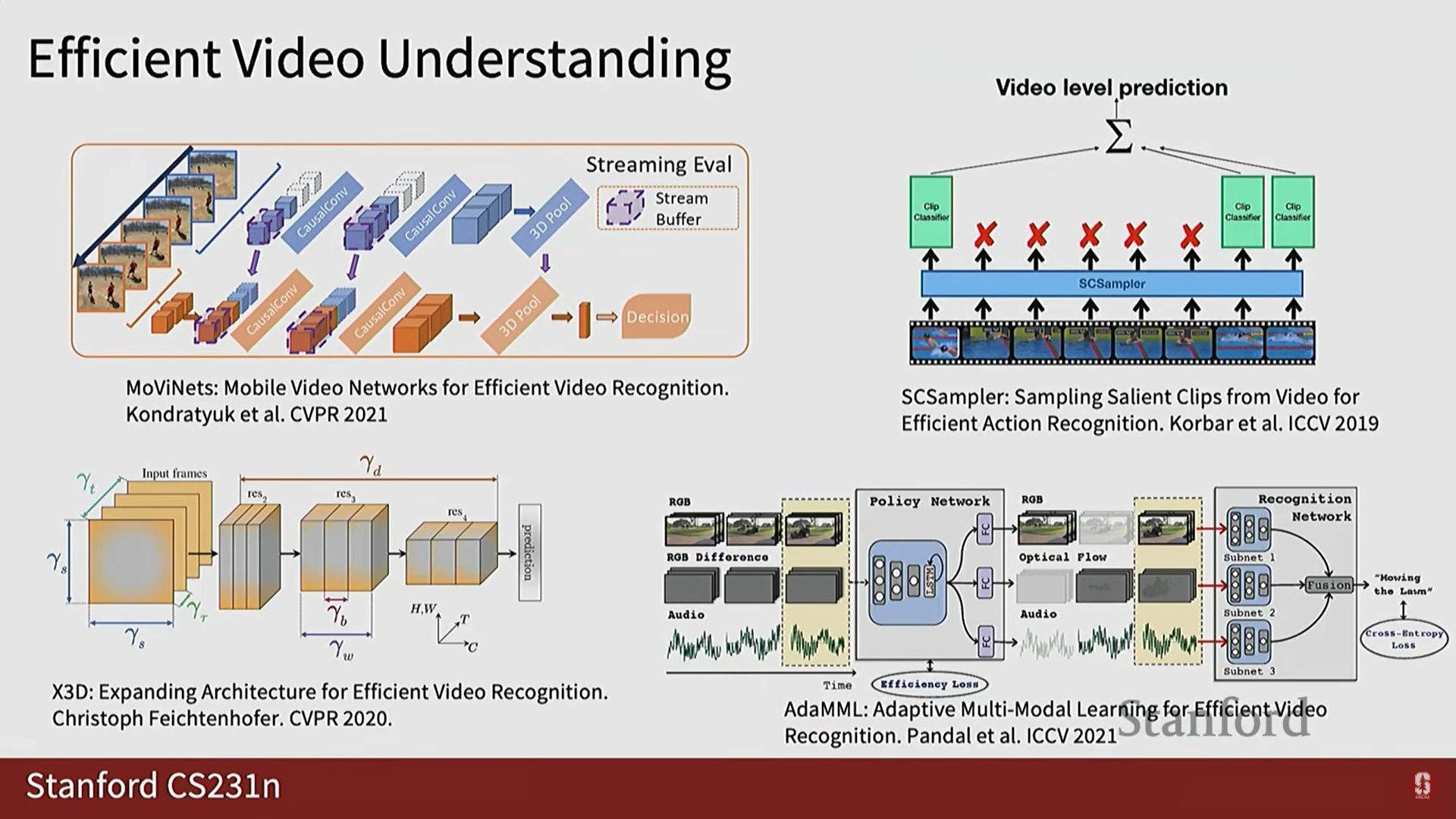
- X3D: 더 나은 3D CNN 아키텍처를 구축하여 단일 클립 처리 효율을 높입니다.
- SD 샘플러 (SD sampler): 가장 중요하거나 유용한 클립을 예측하여 해당 클립에만 분류기를 실행합니다.
- 정책 학습 (Policy Learning): 어떤 양식(비디오, 오디오 등)을 얼마나 사용할지 예측하여 효율성을 높입니다.
- 오디오를 미리보기 메커니즘으로 활용: 오디오를 가이드로 사용하여 비디오 내의 중요한 순간을 예측하고 해당 클립만 처리합니다.
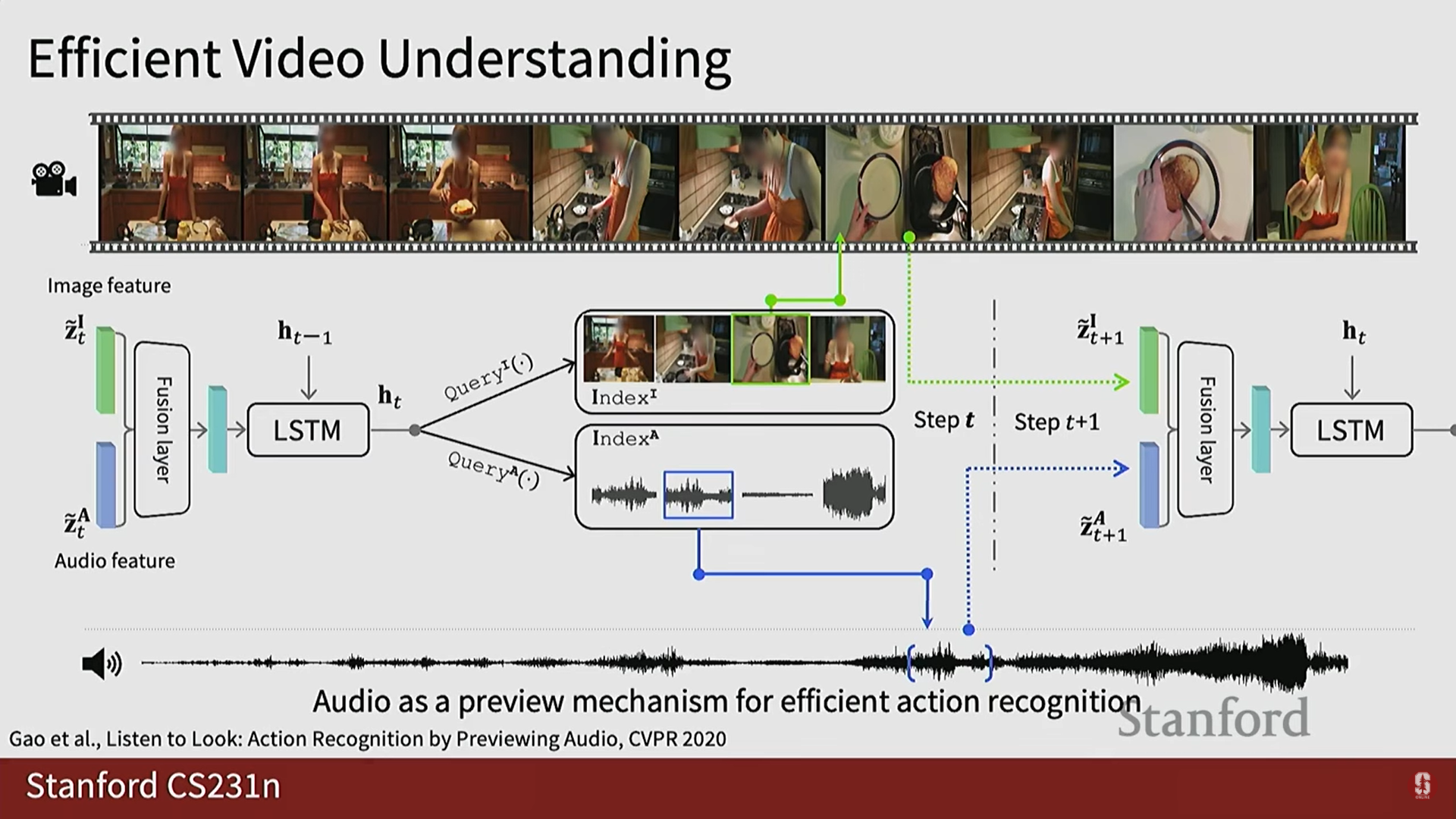
3) 미래 동향: Egocentric 비디오와 LLM 연결
- Egocentric Video Streams: VR/AR 및 스마트 안경의 확산으로, 사용자 시점(egocentric) 비디오 스트림이 중요해지고 있습니다. 이는 다중 마이크 배열 오디오 등 다중 채널 오디오와 시각 정보를 함께 포함합니다.
- 연구 예시: 시각 및 다중 채널 오디오 정보를 사용하여 누가 누구에게 말하고 듣고 있는지 예측하는 작업.

- 연구 예시: 시각 및 다중 채널 오디오 정보를 사용하여 누가 누구에게 말하고 듣고 있는지 예측하는 작업.
- 대규모 언어 모델(LLMs)과의 연결: 비디오 이해를 LLM과 연결하려는 연구가 활발합니다.
- 방법: 비디오를 토큰화하고 이를 LLM 임베딩 공간에 매핑하여, 사용자 프롬프트를 통해 비디오 모델에게 비디오 내용(예: 누가 무엇을 하는지)을 텍스트로 설명하도록 요청합니다.

- 방법: 비디오를 토큰화하고 이를 LLM 임베딩 공간에 매핑하여, 사용자 프롬프트를 통해 비디오 모델에게 비디오 내용(예: 누가 무엇을 하는지)을 텍스트로 설명하도록 요청합니다.
7. 핵심 개념 질의응답 (Q&A for Deep Dive Review)
1) 비디오 이해의 기초 및 도전 과제
-
Q: 비디오 데이터는 2D 이미지와 비교하여 어떻게 정의되며, 일반적인 비디오 이해 작업은 이미지 분류와 무엇이 다른가요?
- A: 비디오는 2D 이미지에 시간 차원(Temporal Dimension, T)이 추가된 형태이며, 공간 차원(H, W)을 포함하는 4D 데이터()로 간주됩니다.
- 이미지 분류가 주로 장면이나 객체 카테고리에 초점을 맞춘다면, 비디오 이해는 일반적으로 사람이나 동물이 수행하는 활동(actions/activities) 분류에 중점을 둡니다.
-
Q: 비디오 데이터의 거대한 크기가 야기하는 주요 문제점과 이를 해결하기 위한 학습 전략은 무엇인가요?
- A: 고해상도 비디오는 분당 약 10GB를 소모할 정도로 매우 크며, 이 데이터를 GPU에 직접 입력할 수 없습니다.
- 이를 해결하기 위해, 비디오를 시간적/공간적으로 축소하고, 매우 긴 비디오 전체 대신 짧은 클립(chunks of video frames) 단위로 모델을 학습시킵니다.
- 추론(Inference) 시에는 여러 클립을 샘플링하여 예측 결과를 평균(average) 내어 최종 예측으로 사용합니다.
2) 3D CNN의 구조적 이점과 효율성
-
Q: 레이트 퓨전(Late Fusion)의 주요 한계점 중 하나인 '저수준 모션 정보 손실'이 발생하는 이유는 무엇인가요?
- A: 레이트 퓨전은 각 프레임을 독립적으로 2D CNN으로 처리합니다. 2D CNN이 컨볼루션 및 풀링을 반복하는 동안, 사람의 발이 상하로 움직이는 것과 같은 저수준 모션 정보는 네트워크의 후반부 레이어에서는 이미 손실되어, 고수준의 외형 정보(예: 사람)만 남기 때문입니다.
-
Q: 3D 컨볼루션 신경망(3D CNN)이 2D 컨볼루션(특히 Early Fusion)보다 갖는 주요 이점인 '시간적 이동 불변성(temporal shift invariance)'에 대해 설명해주세요.
- A: 2D 컨볼루션 필터가 시간 차원 전체에 걸쳐 확장되는 경우(Local in space, extends fully in time), 시간적 이동 불변성이 사라집니다. 예를 들어, '파란색에서 주황색으로의 색상 전환'과 같은 동일한 패턴이 다른 시간대(예: 시간 단계 4와 15)에서 발생하면, 이를 인식하기 위해 완전히 별개의 필터를 학습해야 합니다.
- 반면, 3D CNN 필터는 시간 내의 지역적 창(local window in time)만을 포착하고 시간 차원을 따라 슬라이딩되므로, 필터를 재사용하여 시간 흐름의 어느 순간에서든 동일한 동작

AI 공부합니다