0. 3줄 요약
-
본 논문은 비마르코프(Non-Markovian) 환경의 장기(Long-horizon) 로봇 조작 한계를 극복하기 위해, 지속적인 '의미론적 그래프(Semantic-Graph)' 상태와 '코드 기반 계획기(Code-as-Planner)'를 결합한 CodeGraphVLP 프레임워크를 제안합니다.
-
매 스텝 VLM을 호출하는 대신 초기 1회 생성된 실행 가능한 코드로 작업 진척도를 효율적으로 추적하며, 서브태스크와 관련된 객체만 남긴 '클러터 제거 시각-언어 프롬프트'를 생성하여 저수준 VLA(Vision-Language-Action) 모델의 시각적 그라운딩 성능을 극대화했습니다.
-
실제 로봇 실험 결과, 기존의 메모리 증강 VLA나 VLM-in-the-loop 방식보다 계획 지연 시간을 약 1/10 수준으로 단축하면서도, 복잡하고 방해물(Clutter)이 많은 환경에서의 작업 성공률을 비약적으로 향상시켰습니다.
1. 배경 및 문제 정의
연구의 배경
최근 대규모 로봇 데이터를 바탕으로 사전 학습된 VLM을 행동 예측에 적용하는 VLA 모델이 로봇 제어의 범용성을 크게 확장하고 있습니다. 그러나 대부분의 VLA 모델은 '현재 시점의 관찰값만으로 다음 행동을 결정할 수 있다'는 마르코프(Markovian) 가정에 기반한 단기(Short-horizon) 정책으로 학습 및 배포됩니다.
기존 방법의 접근 방식과 한계
실제 환경의 장기 조작 작업은 과거의 관찰이 현재의 결정에 필수적인 비마르코프적 특성을 지닙니다. 이를 해결하기 위해 두 가지 주요 접근법이 존재했습니다.
- 메모리 증강 VLA (Memory-augmented VLA): 과거 프레임, 메모리 토큰, 또는 과거 경험 검색을 활용합니다. 하지만 메모리 용량과 연산 효율성 간의 상충 관계(Trade-off)가 발생하며, 긴 시계열에서 희소한 핵심 증거를 놓치기 쉽습니다.
- 계층적 VLM-VLA (Hierarchical VLM-VLA): 거대 VLM을 고수준 계획기로 두고 서브태스크를 VLA에 전달합니다. 하지만 매 스텝 VLM을 호출하여 막대한 추론 지연(Latency)이 발생하며, 언어만으로 전달되는 지시는 방해물이 많은(Cluttered) 환경에서 VLA의 잘못된 시각적 그라운딩을 유발합니다.
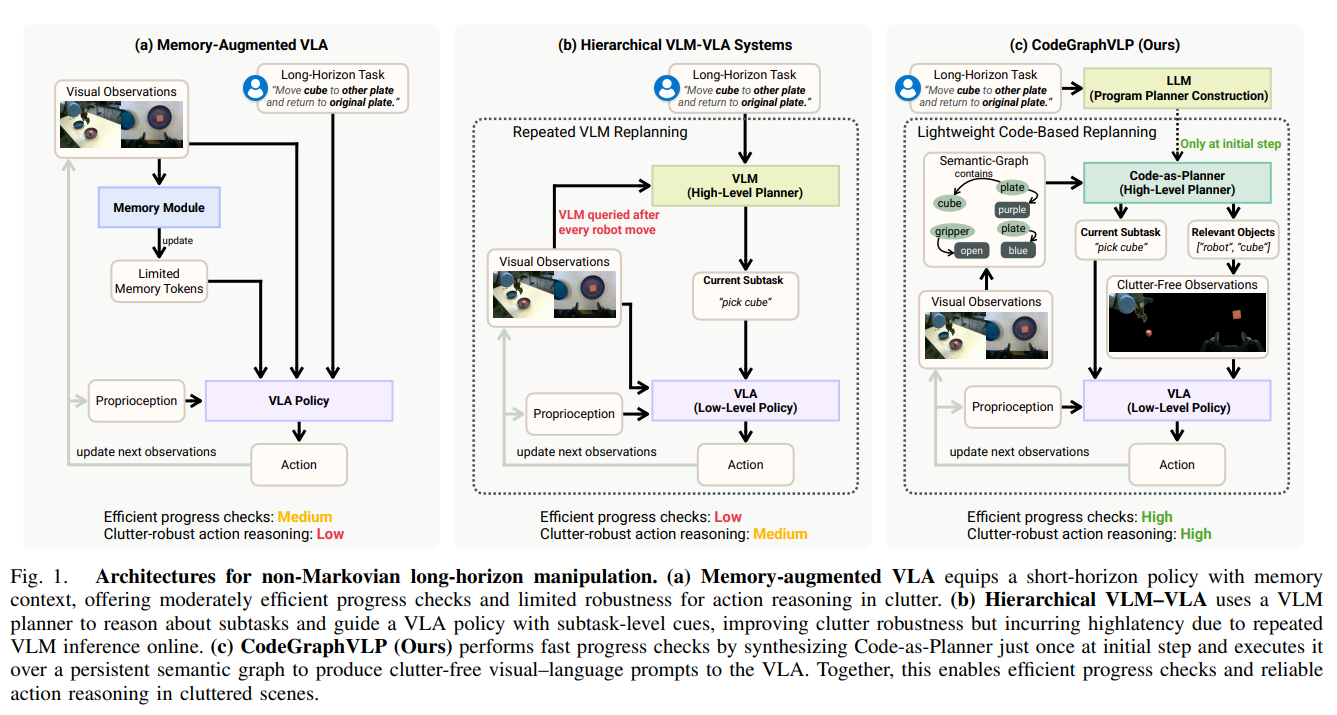
핵심 문제 정의
본 논문은 "어떻게 하면 막대한 추론 지연 없이 과거의 관찰 정보를 포함한 '작업 상태'를 명시적으로 유지하면서, 동시에 복잡한 환경에서도 저수준 제어기(VLA)가 방해물에 흔들리지 않고 정확한 시각-언어적 행동 추론을 수행할 수 있을 것인가?"를 핵심 문제로 정의하고 이를 해결하고자 합니다.
2. 제안 방법 (Method)
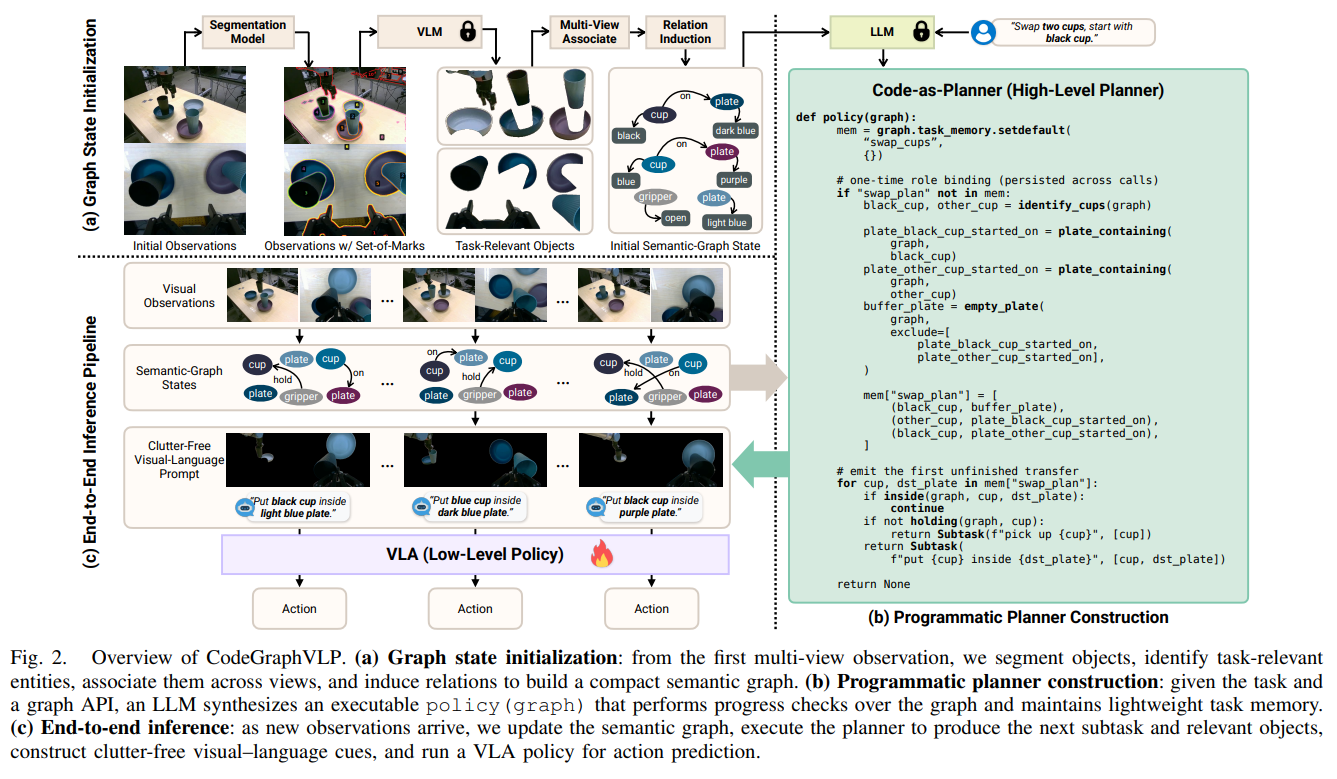
전체 핵심 아이디어
CodeGraphVLP는 부분적 관찰 가능성을 극복하기 위해 (1) 물체와 그 관계를 기록하는 의미론적 그래프(Semantic-graph) 상태를 지속적으로 유지하고, (2) LLM이 초기 1회 작성한 코드 기반 계획기(Code-as-Planner)를 통해 그래프를 조회하여 작업 진척도를 파악하며, (3) 계획기가 반환한 관련 물체들만 남긴 방해물 제거 시각-언어 프롬프트(Clutter-free Visual-Language Prompting)를 VLA에 주입하여 정확한 동작을 유도합니다.
입력 데이터의 표현 및 전처리 (그래프 초기화 및 업데이트)
입력 데이터인 다중 시점 RGB 이미지 는 그래프 상태 로 변환됩니다.
- 분할 및 관련성 필터링: YOLOE를 통해 인스턴스 마스크를 추출하고, Set-of-Mark 기법을 적용해 VLM에 질의하여 작업과 관련된 객체만 필터링합니다.
- 다중 시점 연관 (Multi-view Association): 시점 간 객체 매칭을 위해 먼저 CLIP 특징 벡터의 코사인 유사도를 임계값 로 평가합니다. 남은 객체들은 기하학적 거리를 기반으로 매칭합니다. 마스크 의 무게중심 와 앵커 의 거리를 다음 수식으로 계산합니다.이후 각 시점의 스케일 차이를 보정하기 위해 최대 앵커 거리로 정규화한 서명(Signature) 을 임계값 와 비교하여 최종 매칭을 수행합니다.
- 온라인 업데이트: 추론 중에는 Cutie 트래커를 사용하여 의 마스크를 현재 관찰값 로 갱신하며, 놓친 객체는 YOLOE로 재탐지하여 갱신합니다.
모델 세부 구조 및 알고리즘 프름
1. Code-as-Planner의 구조 및 작동
작업 초기, LLM은 전체 지시어 과 초기 그래프 를 바탕으로 파이썬 함수 형태의 정책 를 1회 합성합니다. 이 코드는 graph.task_memory라는 리스트를 통해 완료된 서브태스크를 캐싱하여 중복 실행을 방지합니다.
추론 시 매 스텝 계획기를 호출하면 다음과 같은 서브태스크 지시어와 관련 객체 집합을 반환합니다.
2. 방해물 제거 프롬프팅 (Clutter-Free Visual-Language Prompting)
단순 언어 지시어 만 VLA에 넘기면 방해물에 취약합니다. 따라서 뷰 에서 객체 의 이진 분할 마스크 를 활용하여, 서브태스크와 관련된 객체만 남기는 유지 마스크(Retention Mask) 를 생성합니다.
원본 이미지 에 이를 원소별 곱(Element-wise multiplication)하여 방해물이 제거된 이미지 를 만듭니다.
3. 학습 및 추론 파이프라인
- 학습(Training): 원본 텔레오퍼레이션(Teleoperation) 궤적을 제안된 파이프라인을 통해 전처리하여 방해물이 제거된 관찰 , 로봇 상태 , 행동 궤적 , 서브태스크 지시어 쌍으로 구성된 데이터셋 를 구축합니다. VLA(본 논문에서는 활용)는 최대 우도 추정(MLE)을 통해 다음 수식으로 미세조정(Fine-tuning)됩니다.
- 추론(Inference): 새로운 관찰 가 들어오면 의미론적 그래프 업데이트 실행하여 획득 방해물 제거 이미지 생성 VLA가 행동 를 예측하여 실행하는 사이클을 반복합니다. 이는 VLM 호출 없이 가벼운 코드 실행만으로 이루어집니다.
3. 실험 결과 (Experiments)
실험 세팅 및 비교 대상
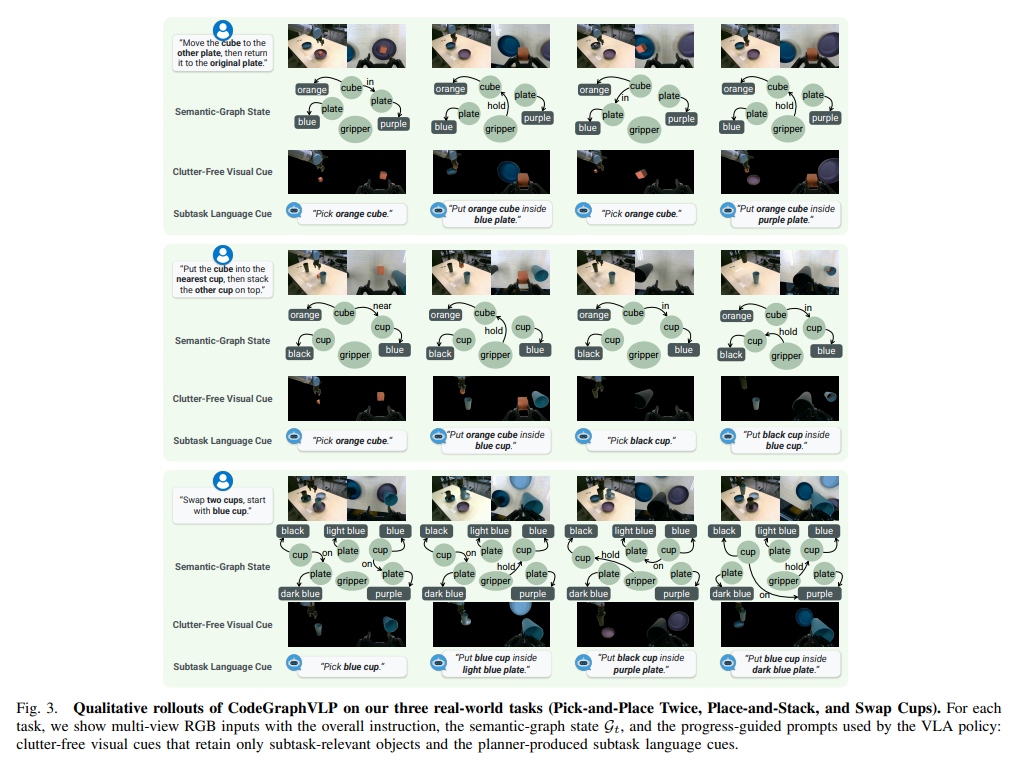
UR10e 다관절 로봇과 평행 그리퍼, 2개의 카메라(전역 및 손목 뷰)를 활용하여 실제 환경의 3가지 비마르코프/클러터 환경 과제(Pick-and-Place Twice, Place-and-Stack, Swap Cups)를 설계했습니다.
비교 대상(Baseline)으로는 최신 VLA 모델인 , FAST, , Gr00T N1.5와, 과거 4프레임을 추가로 입력받는 다중 프레임(Multi-frame) Gr00T N1.5를 사용했습니다.
핵심 성능 및 해석
- 정량적 성공률: CodeGraphVLP는 3개 과제 평균 81.7%의 성공률을 기록하여, 가장 성능이 좋았던 Multi-frame Gr00T N1.5(56.7%)를 큰 격차로 압도했습니다.
- 계획 효율성 (Latency): 매 스텝 VLM을 호출하는 기존 방식(VLM-in-the-loop)이 스텝 당 3.142초가 걸린 반면, Code-as-Planner는 0.328초로 지연 시간을 획기적으로 낮춰 폐루프(Closed-loop) 제어의 실효성을 증명했습니다.
- 어블레이션 스터디 (방해물 제거 효과): Swap Cups 과제에서 서브태스크 관련 객체만 남기는 시각적 마스킹(Clutter-free visual)을 제거하자 성공률이 85%에서 40%로 급락했습니다. 이는 복잡한 씬에서 언어만으로는 VLA의 시각적 그라운딩을 이끌기 부족하며, 본 논문의 시각-언어 프롬프팅이 핵심적인 역할을 함을 증명합니다.
4. 한계점 및 시사점
한계점 및 실제 적용 시 제약
- 파운데이션 모델 의존성: 시스템 초기화 단계에서 VLM과 LLM의 성능에 전적으로 의존합니다. VLM이 객체의 속성이나 관계를 잘못 추론(환각 현상)하거나 분할 모델(YOLOE)이 실패할 경우, 잘못된 그래프와 코드 계획기가 생성되어 복구가 불가능해집니다.
- 개방형 세계(Open-world)의 제약: 현재는 사전에 지정된 뷰와 정적 관계 유추 규칙(in, on, near)에 의존하고 있어, 형태가 고정되지 않은 유연한 물체나 매우 복잡한 기하학적 결합에는 적용하기 어렵습니다.
연구의 의의 및 향후 방향
본 연구는 대규모 VLM의 강력한 인지 및 추론 능력을 초기 1회의 '코드 생성'과 '그래프 초기화'로 응축하고, 실제 제어는 가벼운 VLA와 코드 스크립트로 분리하여 실행 속도와 시각적 견고함을 동시에 달성했다는 점에서 엔지니어링적 가치가 매우 높습니다.
향후 연구로는 자동화된 검증(Verification)을 통해 LLM이 생성한 파이썬 플래너의 오류를 스스로 수정하는 메커니즘을 추가하거나, 동적인 3D 환경을 포괄할 수 있는 개방형 의미론적 그래프 생성 모듈을 개발하는 방향으로 확장될 수 있습니다.
