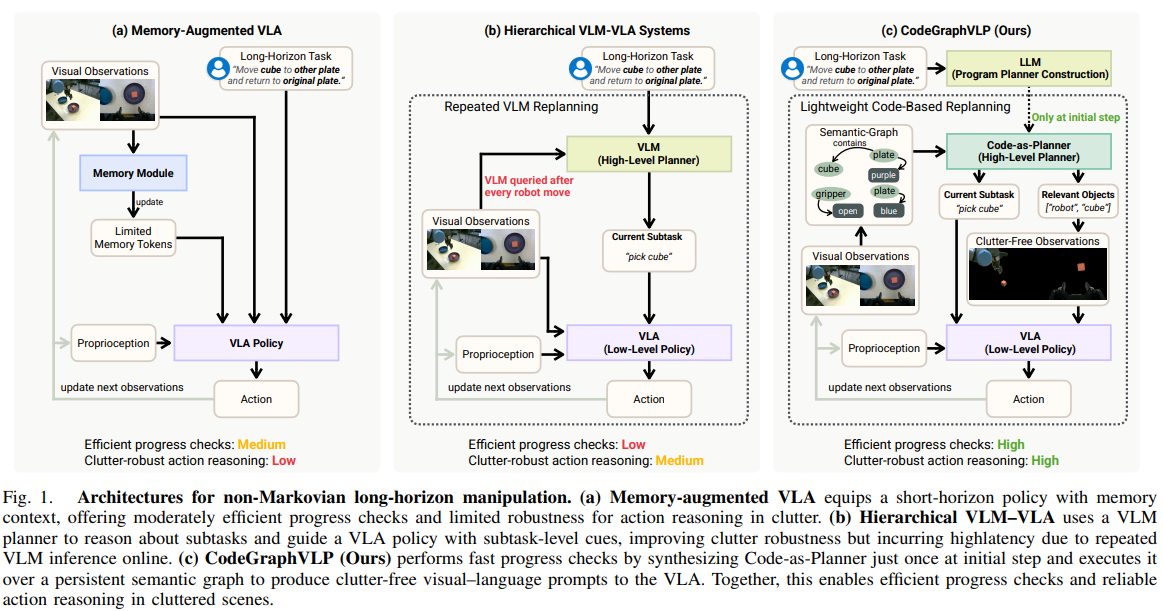
0. 3줄 요약
- 목적 및 제안 방법: 긴 시계열(Long-horizon) 로봇 조작의 복잡성을 해결하기 위해 고수준의 작업 관리자(VLM)와 저수준의 실행기(VLA)를 분리하고, 2D 시각적 궤적(Trace)을 매개체로 연결하는 LoHo-Manip 프레임워크를 제안함.
- 기술적 차별성: 매 스텝마다 '남은 계획(Remaining Plan)'과 '시각적 궤적'을 예측하는 후퇴 지평(Receding-horizon) 제어 방식을 도입하여, 별도의 복구 로직 없이도 실행 오류로부터 자가 수정 및 재계획이 가능한 폐루프(Closed-loop) 시스템을 구축함.
- 성과 및 의의: 시뮬레이션 및 실제 로봇 실험에서 기존 단일 구조 VLA 대비 월등한 장기 작업 성공률을 보였으며, 특히 학습되지 않은 물체와 환경에 대한 강력한 제로샷 일반화 성능을 입증함.
1. 배경 및 문제 정의
기존 연구의 흐름과 한계
최근 VLA(Vision-Language-Action) 모델의 발전으로 단기적인(Short-horizon) 로봇 기술(집기, 놓기 등)은 비약적으로 향상되었습니다. 그러나 여러 단계가 복합적으로 얽힌 장기적 작업(예: "주전자에 물 채우기")에서는 다음과 같은 치명적인 한계가 존재합니다.
- 오류의 누적(Compounding Errors): 단일 모델이 전체 과정을 추론할 경우, 중간 단계의 미세한 실행 오류가 다음 단계의 입력 왜곡으로 이어져 전체 작업이 실패하는 취약성을 보입니다.
- 모듈성 결여: 계획(Planning)과 실행(Execution)이 단일 네트워크에 강하게 결합되어 있어, 새로운 로봇 하드웨어나 환경에 맞춰 모델을 업그레이드하거나 교체하기가 매우 어렵습니다.
- 분포 외 데이터(OOD)에 대한 취약성: 학습 데이터에 존재하지 않는 복합 지시어나 생소한 물체 배치에 대해 추론 능력이 급격히 저하됩니다.
핵심 문제 정의
본 논문은 "고수준의 인지적 판단(무엇을 할 것인가)"과 "저수준의 물리적 제어(어떻게 움직일 것인가)"를 어떻게 효과적으로 분리하면서도 긴밀하게 연결할 것인가를 핵심 문제로 정의합니다. 특히, 실행 중 발생하는 예외 상황을 인간의 개입 없이 스스로 인지하고 수정할 수 있는 견고한 작업 관리 메커니즘의 부재를 해결하고자 합니다.
2. 제안 방법 (Method)
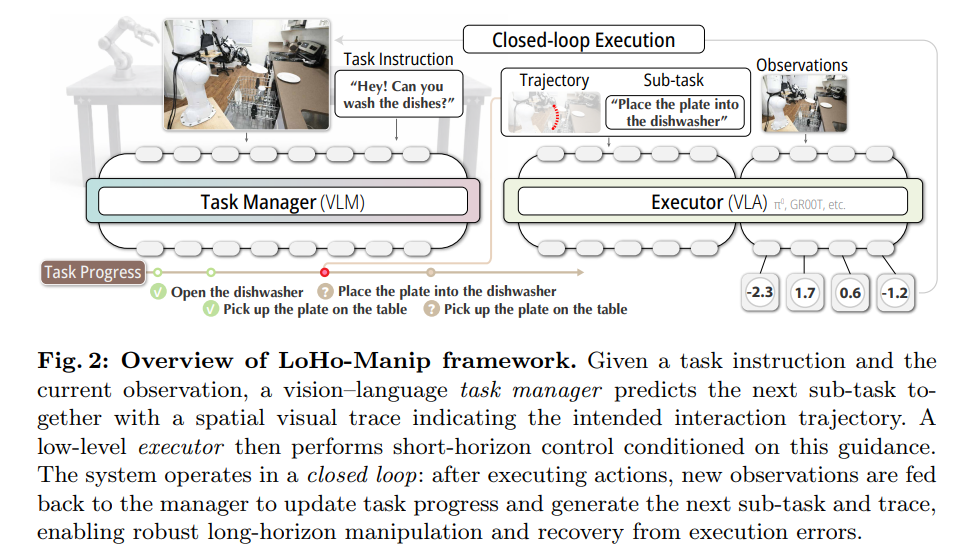
전체 아이디어: Task Manager와 Executor의 분리
LoHo-Manip은 복잡한 지시어를 원자 단위의 서브태스크(Sub-task)로 분해하는 Task Manager(VLM)와, 전달받은 시각적 가이드를 따라 로봇을 움직이는 Executor(VLA)로 구성된 계층적 구조를 가집니다.
데이터 표현 및 전처리 방식
모델에 주입되는 데이터는 단순한 RGB 이미지를 넘어 고도의 정제 과정을 거칩니다.
- 서브태스크 분해: 비디오 데이터를 VLM을 통해 분석하여 상호작용 이벤트(Grasp, Place 등) 단위로 세그멘테이션하고 자연어 레이블을 생성합니다.
- 2D Visual Trace 추출: 로봇의 엔드 이펙터(End-effector) 위치를 픽셀 좌표 로 추출하여, 이를 정규화된 2D 웨이포인트(Waypoint) 시퀀스로 변환합니다. 이 궤적은 이후 이미지 위에 렌더링되어 실행기에 "시각적 프롬프트"로 주입됩니다.

모델 세부 구조 및 핵심 수식
Task Manager는 현재 관찰값 와 이전까지의 수행 이력 을 입력받아 진행 상황 인지 계획(Progress-aware plan)을 생성합니다.
-
텍스트 기반 메모리: 전체 작업 시퀀스를 수행 완료된 부분()과 남은 부분()으로 명시적으로 분리하여 관리합니다.
여기서 는 현재 시점에서 수행해야 할 서브태스크의 인덱스입니다.
-
Visual Trace (시각적 궤적): 단순한 목표 지점이 아니라, 미래의 엔드 이펙터 이동 경로를 시퀀스 데이터로 예측합니다.
이 궤적 는 이미지 상에 선 형태로 렌더링되어 VLA의 공간적 어텐션(Spatial Attention)을 가이드합니다.
학습 및 추론 파이프라인
- 학습 단계:
- Manager 학습: 대규모 VLM(예: Qwen3-VL)을 기반으로, 현재 프레임에서 남은 서브태스크 텍스트와 2D 궤적을 예측하도록 파인튜닝합니다.
- Executor 학습: 기존 VLA 모델(예: )이 이미지 위에 렌더링된 Trace를 조건부 입력으로 받아 해당 경로를 추적하며 액션을 생성하도록 학습시킵니다.
- 추론 단계 (Closed-loop): 매 스텝 혹은 일정 주기마다 Manager가 "현재 상황에서 남은 최적의 경로"를 다시 계산(Receding Horizon)합니다. 만약 로봇이 물체를 놓치는 오류가 발생하면, 다음 스텝의 관찰값 에 실패 상태가 반영되므로 Manager는 자동으로 동일한 서브태스크를 다시 계획하거나 복구 경로를 생성합니다.

3. 실험 결과 (Experiments)
평가 환경 및 비교 대상
- 데이터셋: Bridge dataset(Open X-Embodiment) 기반의 실제 로봇 데이터와 LIBERO, VLABench 등 시뮬레이션 벤치마크를 사용했습니다.
- Baseline: , OpenVLA, GR00T 등 최신 단일 구조 VLA 모델들과 성능을 비교했습니다.
주요 성과 및 해석
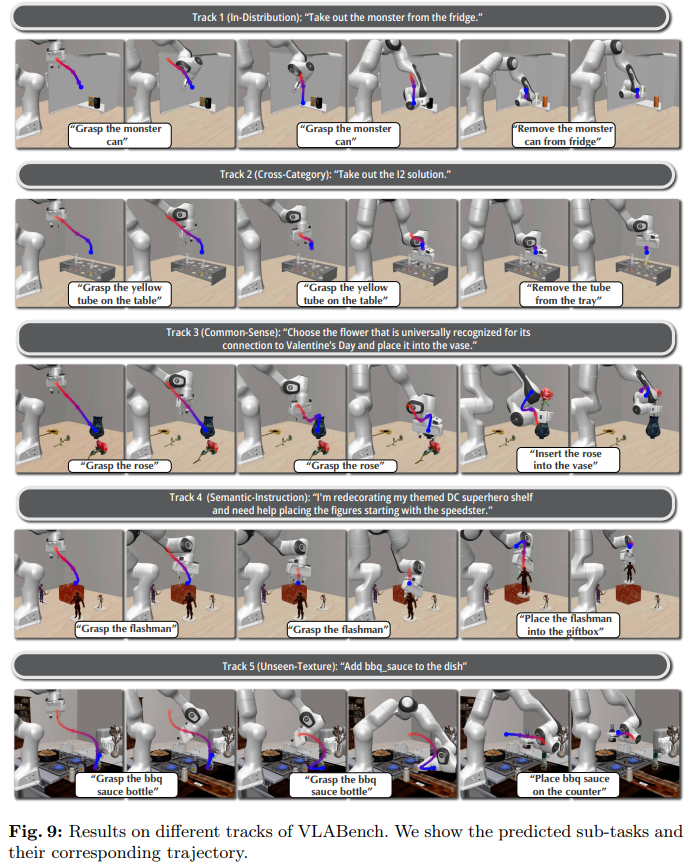
- 장기 작업 성공률: VLABench의 Semantic Instruction 트랙에서 기존 모델들이 17~20%의 성공률을 보인 반면, LoHo-Manip은 39%로 두 배 이상의 성능 향상을 기록했습니다.
- 오류 복구 능력: 로봇이 엉뚱한 물체를 집었을 때, "물체를 내려놓고 다시 목표 물체로 이동하라"는 복구 서브태스크와 궤적을 스스로 생성하는 능력이 확인되었습니다.
- 제로샷 일반화 (OOD): 학습 시 보지 못한 물체가 포함된 실제 로봇 환경에서도 Task Manager가 일반적인 VLM의 추론 능력을 발휘하여 정확한 2D 궤적을 생성함으로써, 실행기가 성공적으로 작업을 완수했습니다.



4. 한계점 및 시사점
기술적 한계 및 과제
- 2D 표현의 제약: 현재의 시각적 궤적은 2D 픽셀 좌표에 기반하고 있어, 3D 공간에서의 정밀한 깊이 제어나 복잡한 접촉이 필요한(Contact-rich) 동작에서는 정보 손실이 발생할 수 있습니다.
- Manager 의존성: 고수준 계획의 품질이 Task Manager인 VLM의 성능에 전적으로 의존하므로, 인지 모델의 환각(Hallucination) 현상이 발생할 경우 잘못된 가이드를 제공할 위험이 있습니다.
연구의 의의와 향후 방향
LoHo-Manip은 거대 언어 모델의 '추론 능력'을 로봇의 '동작 제어'에 직접적으로 연결하는 가장 효율적인 인터페이스로 'Visual Trace'를 제시했다는 점에서 큰 학술적 가치가 있습니다. 이는 향후 로봇 시스템이 독립적인 제어 모듈을 유지하면서도, 최신 VLM의 성능 향상을 즉각적으로 흡수할 수 있는 확장 가능한 아키텍처를 제시한 것으로 평가됩니다.
