1. LLM의 발전과 사전 학습의 힘
1) LLM의 스케일링
- 연산 능력의 증가: 1950년대부터 머신러닝 모델에 필요한 연산량은 기하급수적으로 증가해왔습니다. 현재 LLM은 FLOPS를 훌쩍 뛰어넘는 연산량을 요구합니다.
- 데이터의 확장: 모델이 커질수록 더 많은 데이터가 필요합니다. 2024년 라마 3 모델은 무려 15조 개의 토큰으로 학습되었는데, 이는 한 사람이 평생 들을 수 있는 양보다 훨씬 많은 데이터입니다.
2) 사전 학습(Pre-training)의 의미
- 핵심 목표: LLM의 사전 학습은 기본적으로 다음 토큰을 예측(Next Token Prediction)하는 아주 간단한 목표를 가지고 있습니다.
- 학습 내용:
- 지식(Knowledge): "스탠포드 대학은 캘리포니아에 있다"와 같은 세상의 지식을 학습합니다.
- 문법 및 의미(Syntax & Semantics): 문장의 구조와 의미를 자연스럽게 익힙니다.
- 다국어 능력(Multilingual Knowledge): 학습 데이터에 포함된 다양한 언어를 배웁니다.
- 지능의 발현(Emergence of Intelligence):
- 놀랍게도, 단순히 다음 단어를 예측하는 학습만으로도 모델은 인간의 신념이나 사고방식을 모델링하는 등 고차원적인 지능을 보여주기 시작합니다.
- 예시: "물리학자인 팻"과 "물리를 모르는 팻"이라는 조건에 따라 떨어지는 물체에 대한 예측이 달라지는 것을 이해하는 능력은, 모델이 단순한 텍스트 생성을 넘어 추론 능력을 갖추었음을 보여줍니다.
- 다양한 능력 습득:
- 사전 학습을 통해 LLM은 수학, 코딩(GitHub Copilot), 심지어 의학 진단까지 다양한 분야의 능력을 습득하며, 범용 다중 작업 조수(General Purpose Multitask Assistants)로 진화하고 있습니다.
2. 문맥 내 학습 (In-context Learning)

1) GPT 시리즈의 진화
- GPT-1 (2018): 4.6GB 데이터로 학습된 디코더 전용 모델로, 범용 작업에 사전 학습 기술이 효과적일 수 있다는 가능성을 처음으로 보여주었습니다.
- GPT-2 (2019): 모델과 데이터 크기를 10배 이상 키우면서 제로샷 학습(Zero-shot Learning) 능력이 처음으로 나타났습니다.
- 제로샷 학습: 모델에게 특정 작업에 대한 예시를 전혀 보여주지 않아도, 프롬프트를 통해 요약, 질의응답, 간단한 수학 문제 풀이 등을 수행하는 능력입니다.
- 작동 방식: "TLDR;" (Too Long; Didn't Read)을 붙이면 요약을 해주는 것처럼, 모델이 사전 학습 데이터에서 배운 패턴을 활용해 사용자의 의도를 파악하고 작업을 완료합니다.
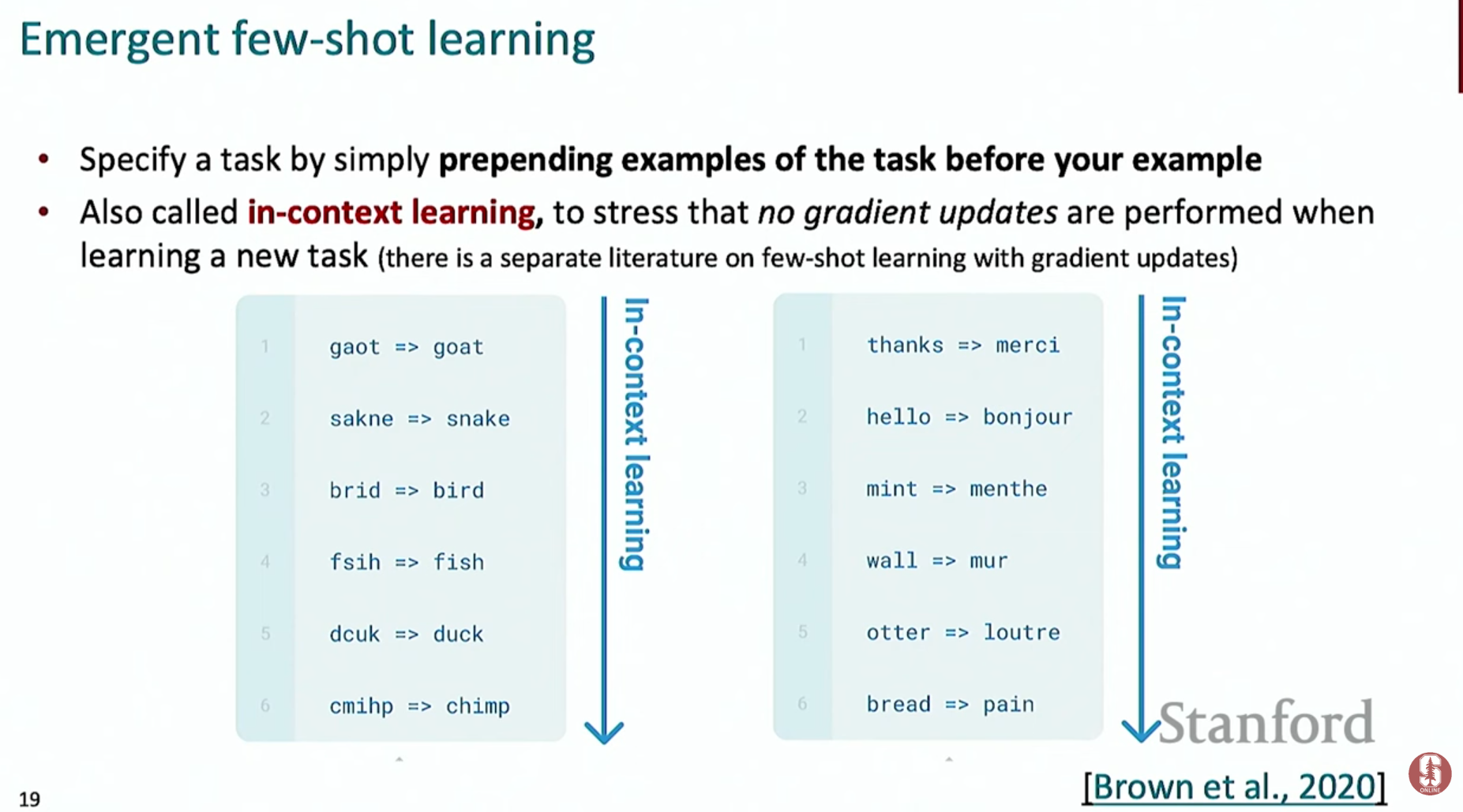
- GPT-3 (2020): 모델 크기를 1,750억 파라미터로 대폭 확장하며 퓨샷 학습(Few-shot Learning) 능력이 등장했습니다.
- 퓨샷 학습: 모델에게 몇 가지(few) 예시만 보여주면, 별도의 학습(그래디언트 업데이트) 없이도 번역과 같은 복잡한 작업을 수행하는 능력입니다.
- 규모의 효과 (Emergence Property): 모델의 크기가 커질수록 제로샷, 퓨샷 학습 능력이 비선형적으로 급격히 향상되는 현상이 관찰되었습니다.

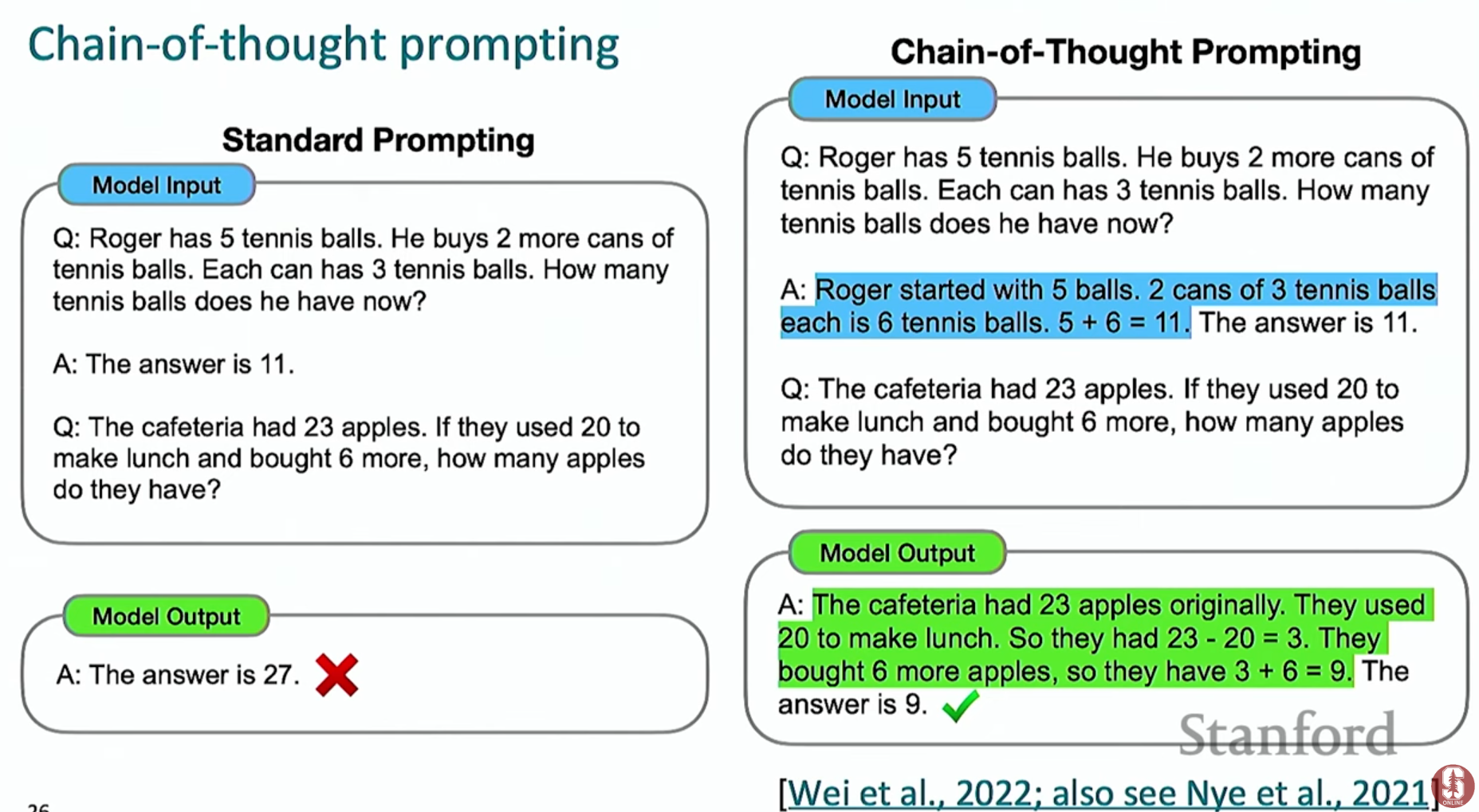
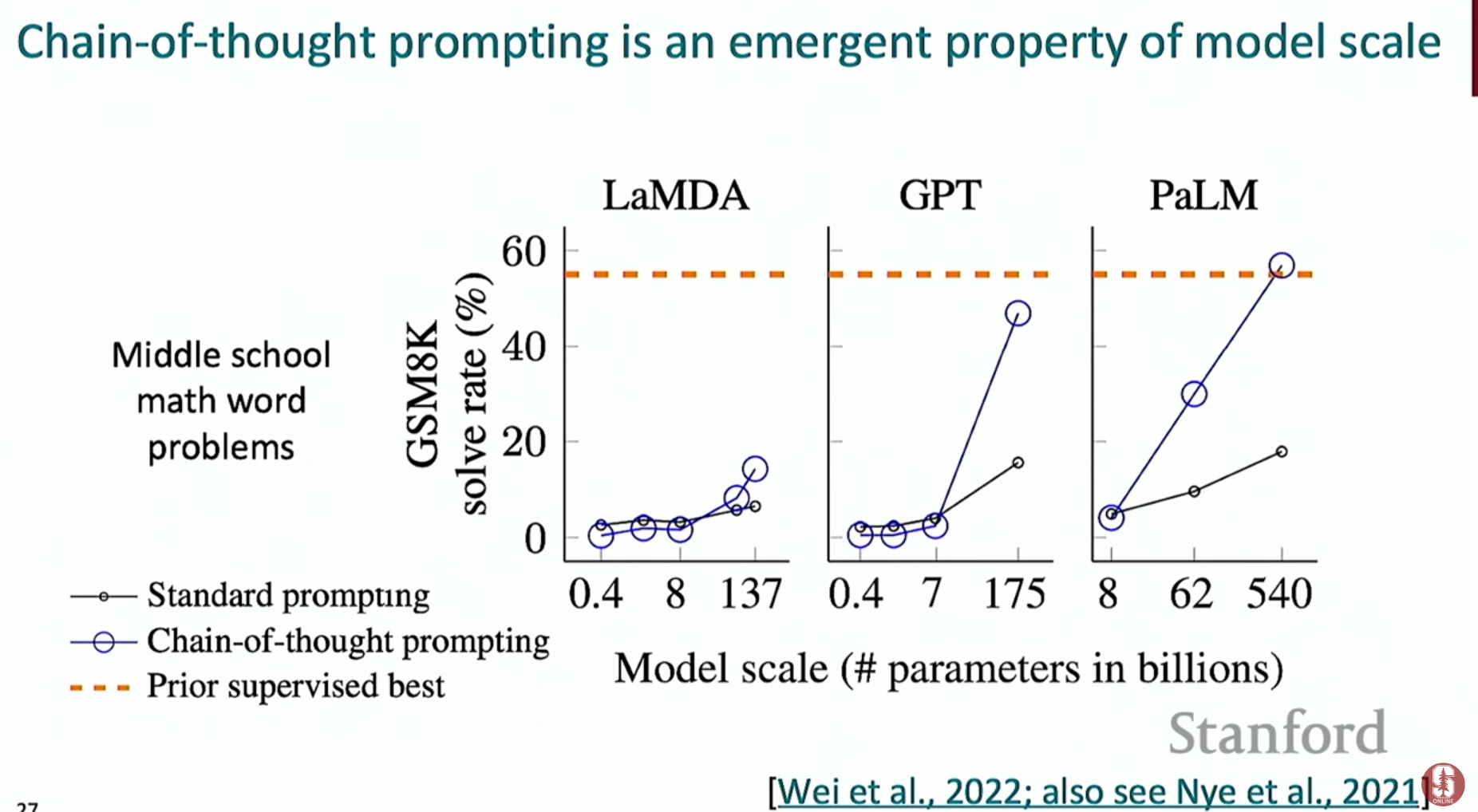
2) 사고의 연쇄 (Chain of Thought, CoT)
- 개념: 모델에게 단순히 '질문-정답' 쌍을 주는 것이 아니라, 정답에 도달하기까지의 단계별 추론 과정을 예시로 함께 보여주는 프롬프팅 기법입니다.
- 효과: 모델은 단순히 정답을 맞히는 것을 넘어 '어떻게' 문제를 푸는지 학습하게 되어, 복잡한 추론 문제에서 성능이 크게 향상됩니다.
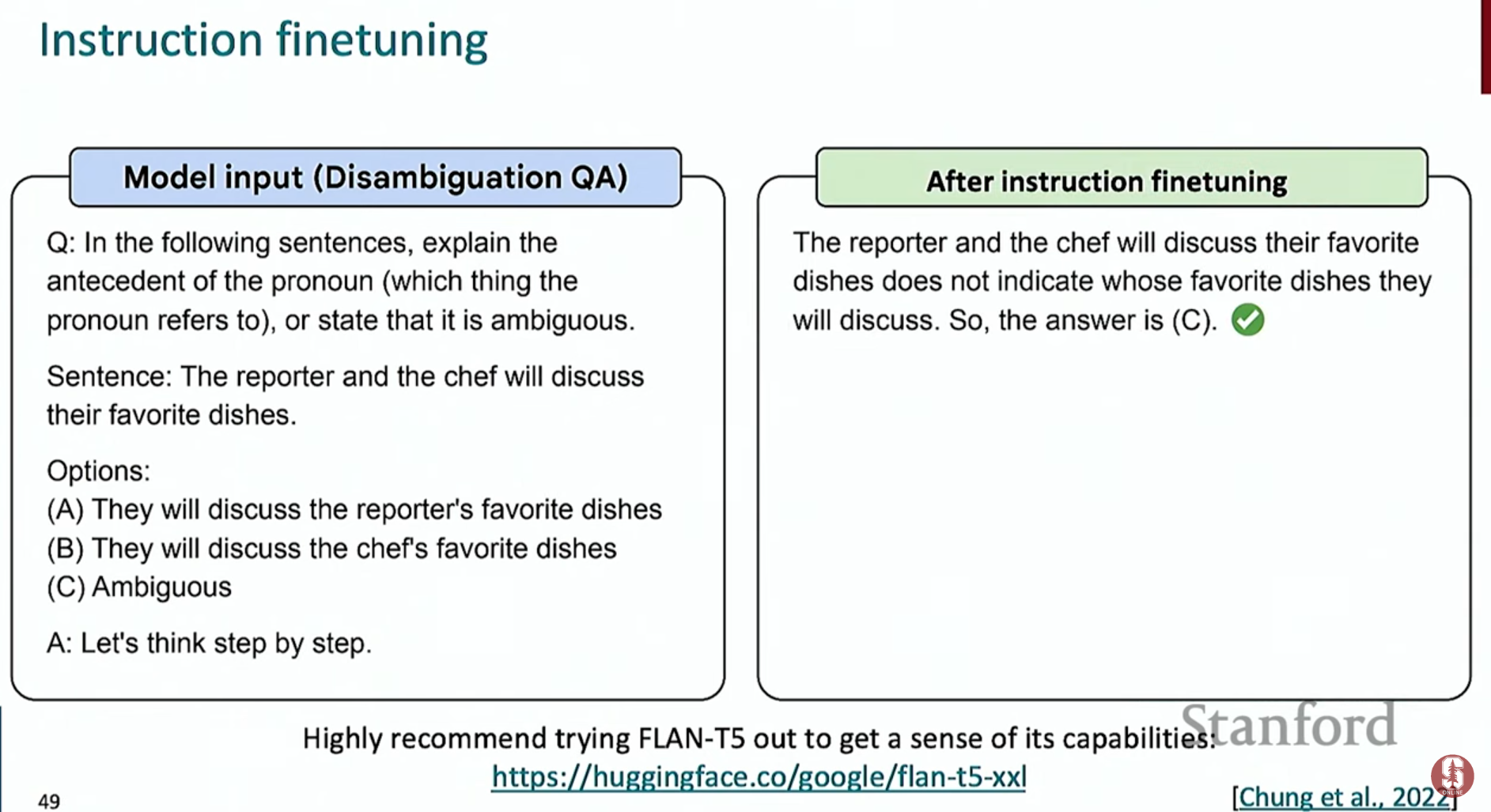
- 제로샷 CoT: 더 나아가, "Let's think step by step (단계별로 생각해보자)"와 같은 간단한 문장 하나를 프롬프트에 추가하는 것만으로도 모델이 스스로 추론 과정을 생성하며 정답률을 높일 수 있습니다.


3. 사용자 의도에 맞추기: 명령어 미세 조정 (Instruction Fine-tuning)

1) 필요성: 정렬(Alignment) 문제
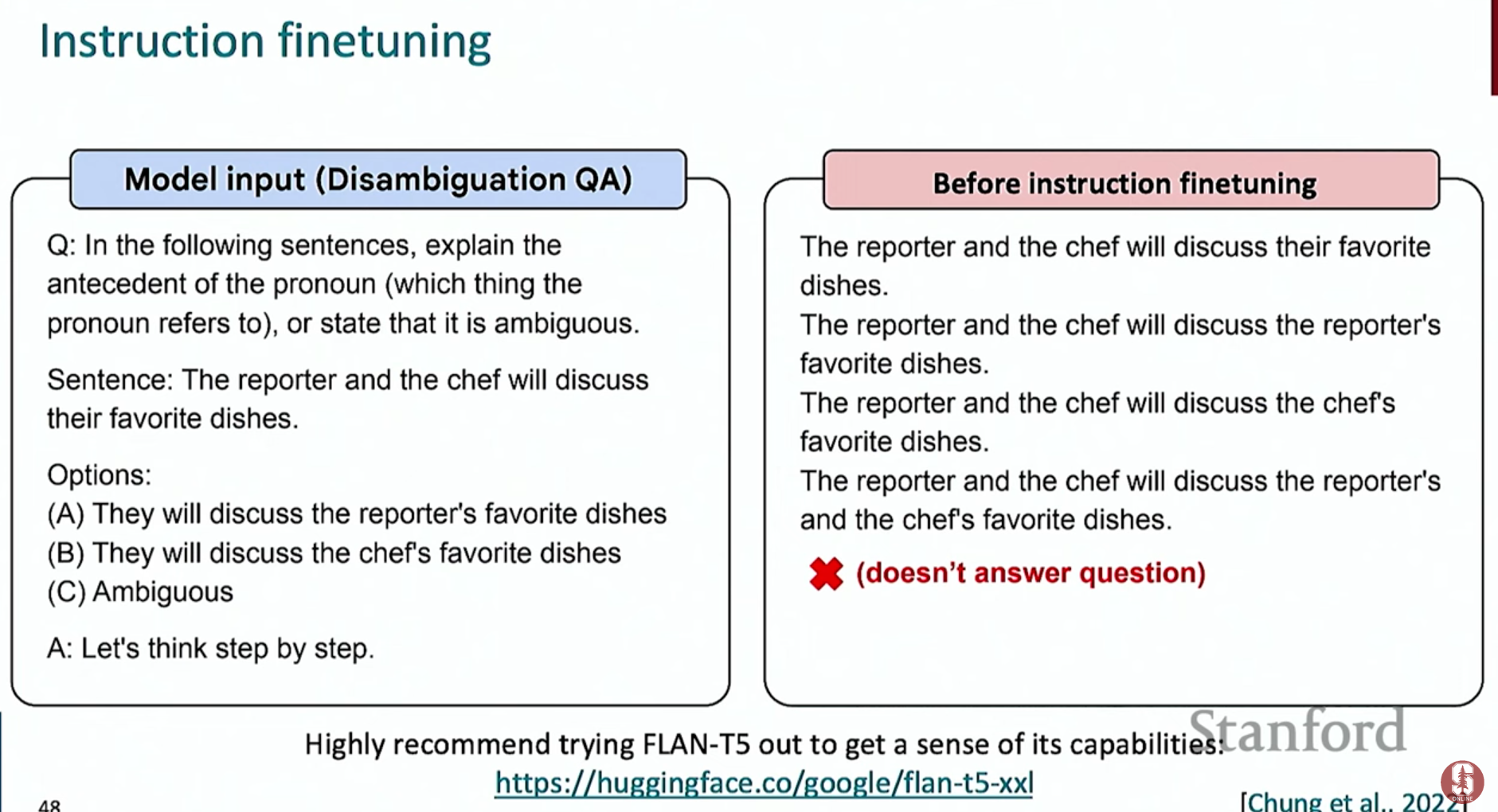
- 사전 학습된 모델은 '다음 단어'를 예측할 뿐, 사용자의 지시를 따르도록 학습되지는 않았습니다.
- 예시: GPT-3에게 "6살 아이에게 달 착륙을 설명해줘"라고 요청하면, 설명을 하는 대신 오히려 사용자에게 질문을 되묻는 등 의도와 다른 답변을 생성합니다. 이것이 바로 정렬되지 않은(unaligned) 상태입니다.


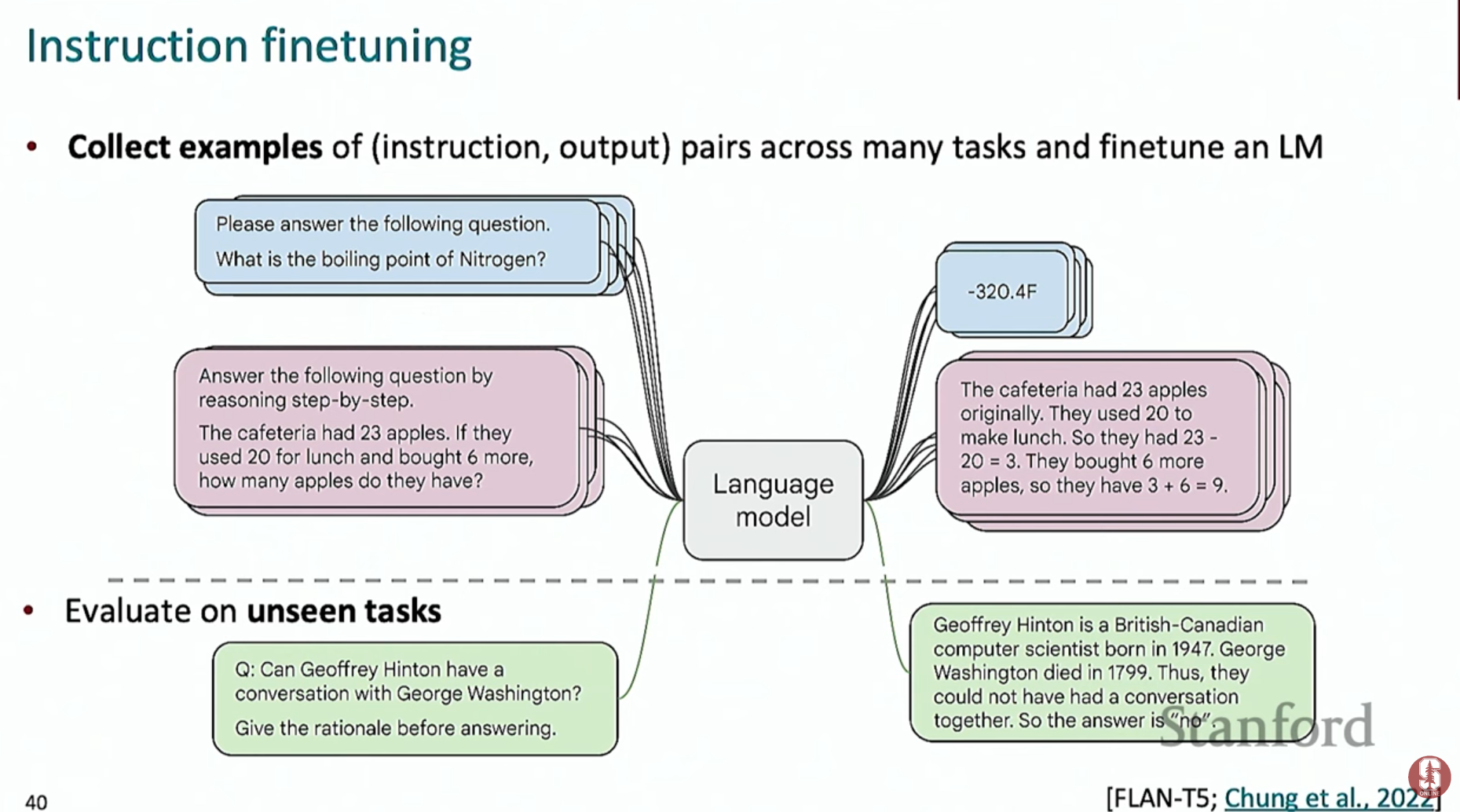
2) 명령어 미세 조정이란?
- 개념: 수많은 종류의 '명령어(Instruction) - 출력(Output)' 쌍 데이터셋을 이용해 모델을 추가로 학습시키는 과정입니다.
- 목표: 단일 모델이 질의응답, 요약, 번역, 코딩 등 다양한 작업을 수행하고, 처음 보는 지시에도 잘 따르도록 일반화 성능을 높이는 것입니다.
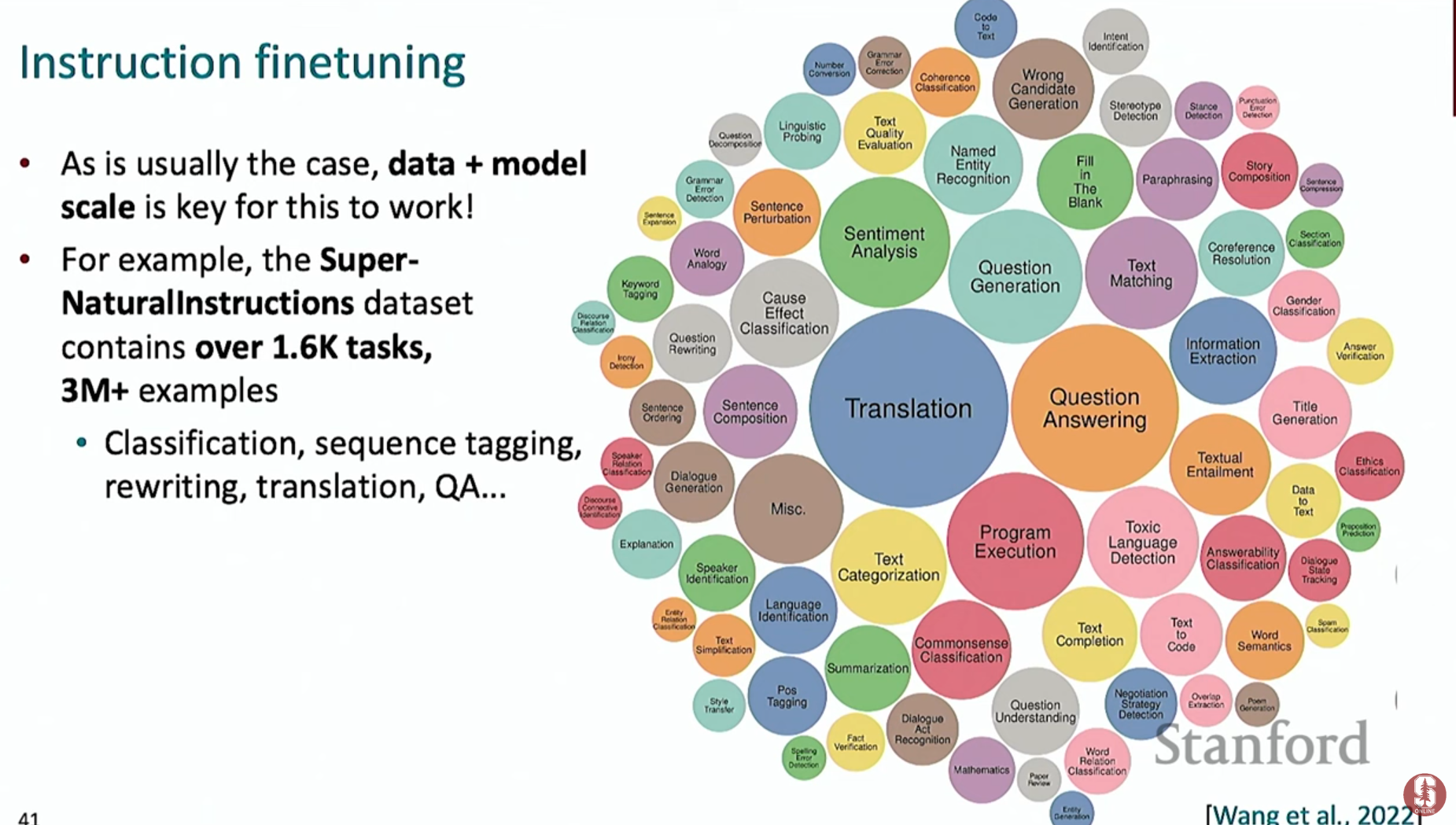
- 데이터와 규모의 중요성: 수천, 수만 가지의 다양한 작업과 수백만 개 이상의 데이터 예시를 통해 학습할수록 모델의 성능은 향상됩니다.
- 심화 내용: 명령어 데이터셋 구축 동향
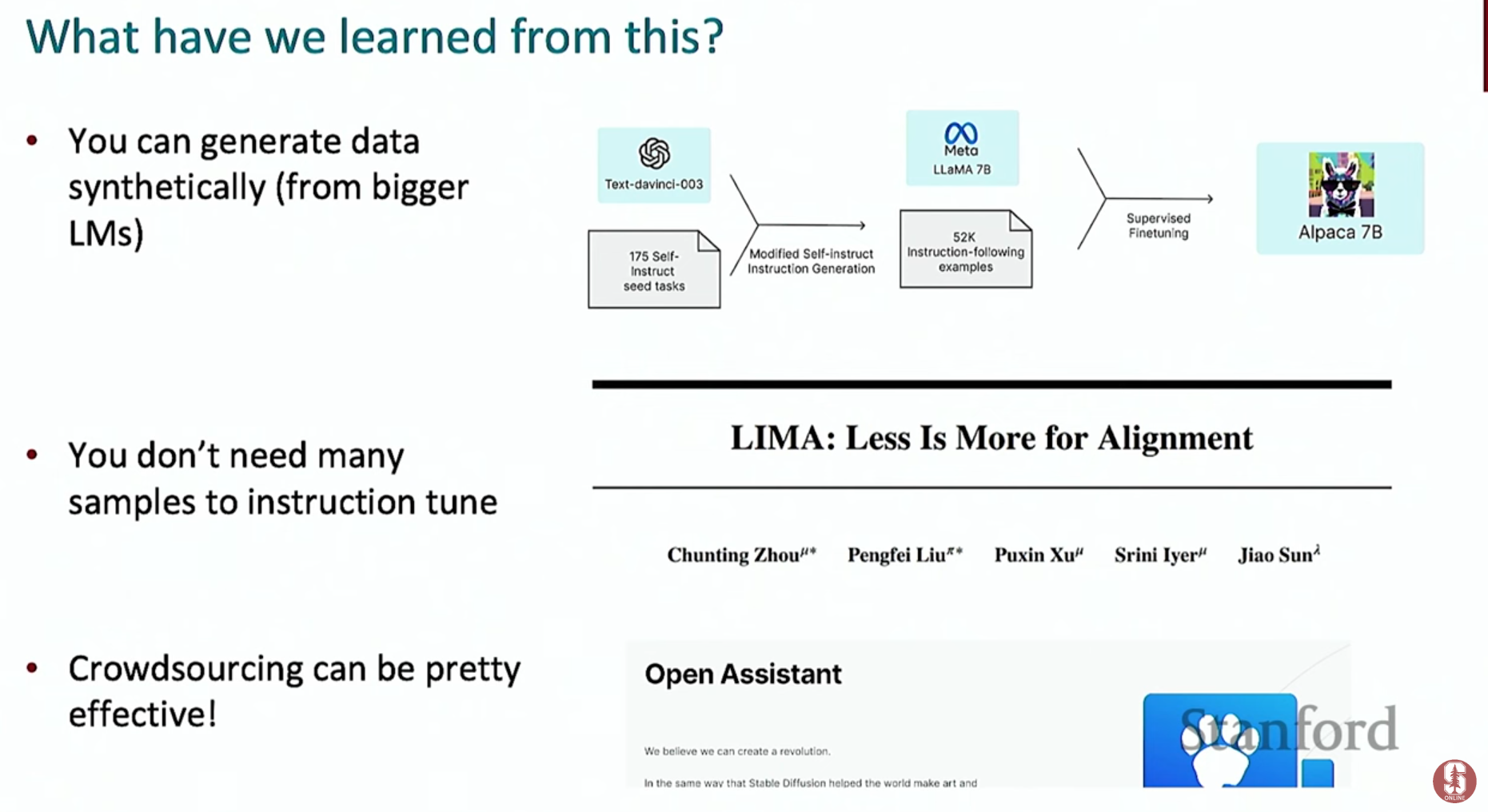
- 기술적 배경: 초기에는 사람이 직접 양질의 명령어-출력 쌍을 만들었지만, 비용과 시간의 한계가 명확했습니다.
- 최신 동향: 최근에는 GPT-4와 같은 고성능 모델을 사용하여 데이터를 자동으로 생성(Self-Instruct)하는 방식이 주를 이룹니다. 이를 통해 더 적은 비용으로 대규모의 고품질 데이터셋을 구축할 수 있게 되었습니다. Dolly, Alpaca와 같은 오픈소스 데이터셋이 대표적인 예시입니다.
- 명확한 한계점: 자동 생성된 데이터는 기존 모델의 편향을 그대로 학습하거나, 사실과 다른 내용을 생성할 수 있다는 한계가 있습니다. 따라서 데이터 정제 및 검수 과정이 여전히 매우 중요합니다.
4. 인간의 선호 학습하기: RLHF와 DPO

1) 명령어 미세 조정의 한계
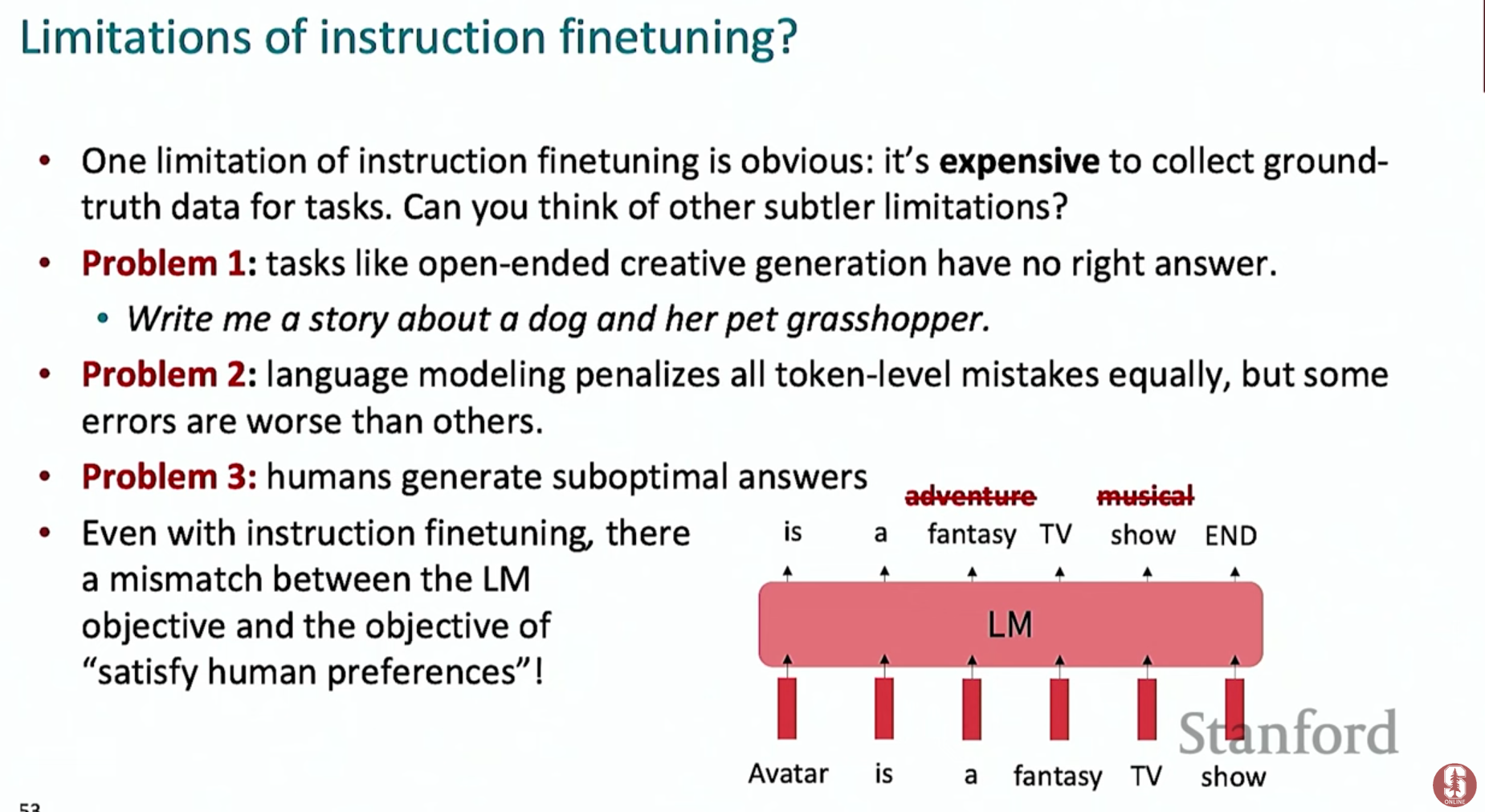
- 데이터 수집의 어려움: 창의적인 글쓰기처럼 정답이 없는 작업이나, 전문가 수준의 지식이 필요한 답변은 고품질 데이터를 만들기 어렵습니다.
- 잘못된 패널티: 모델은 모든 단어의 오류에 동일한 패널티를 부여하지만, 실제로는 문맥상 사소한 오류와 치명적인 오류의 중요도가 다릅니다.
- 인간의 선호도와 불일치: 최종 목표는 '그럴듯한 다음 단어'가 아니라 '인간이 유용하고 선호하는 답변'을 생성하는 것입니다.
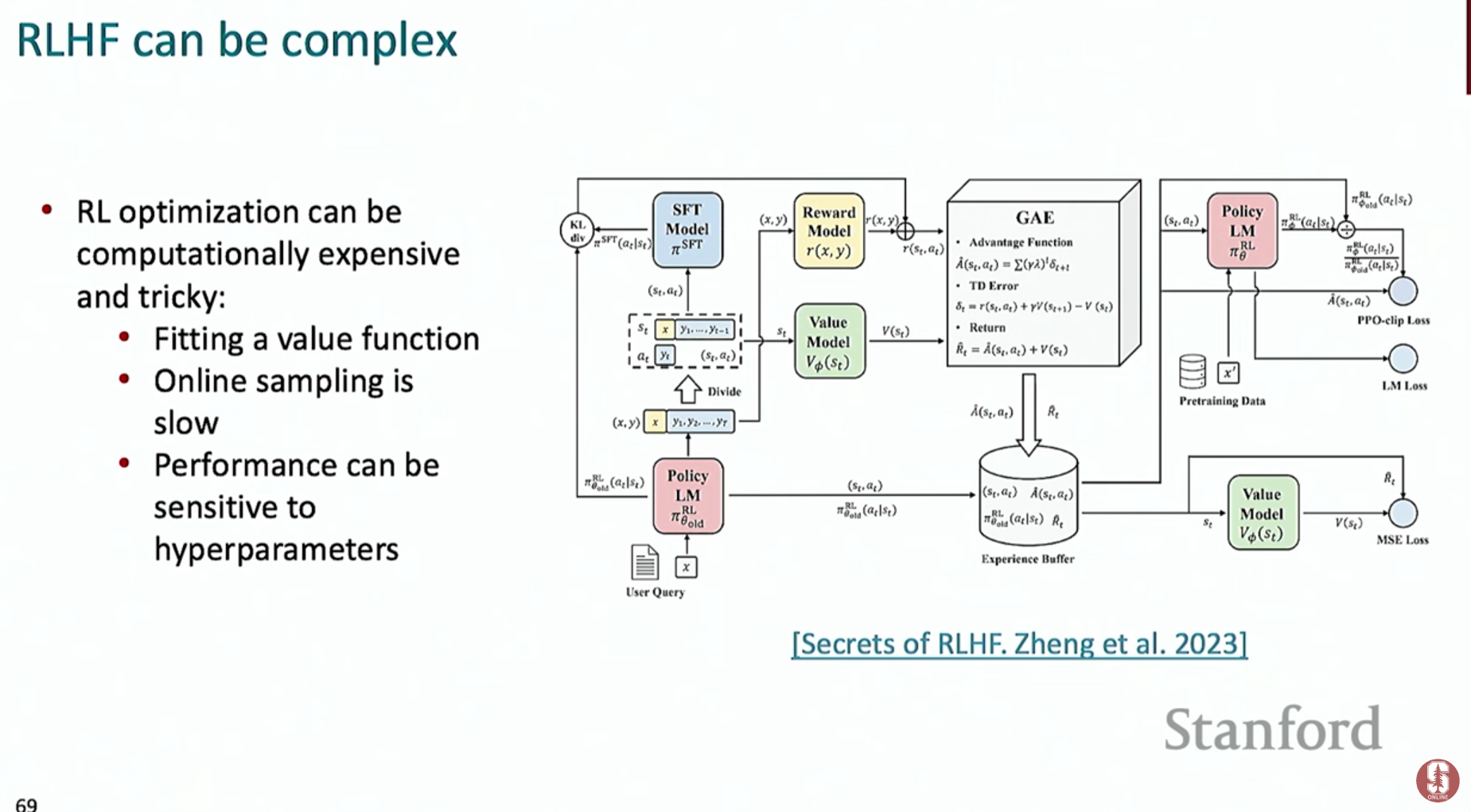
2) RLHF (인간 피드백 기반 강화 학습)
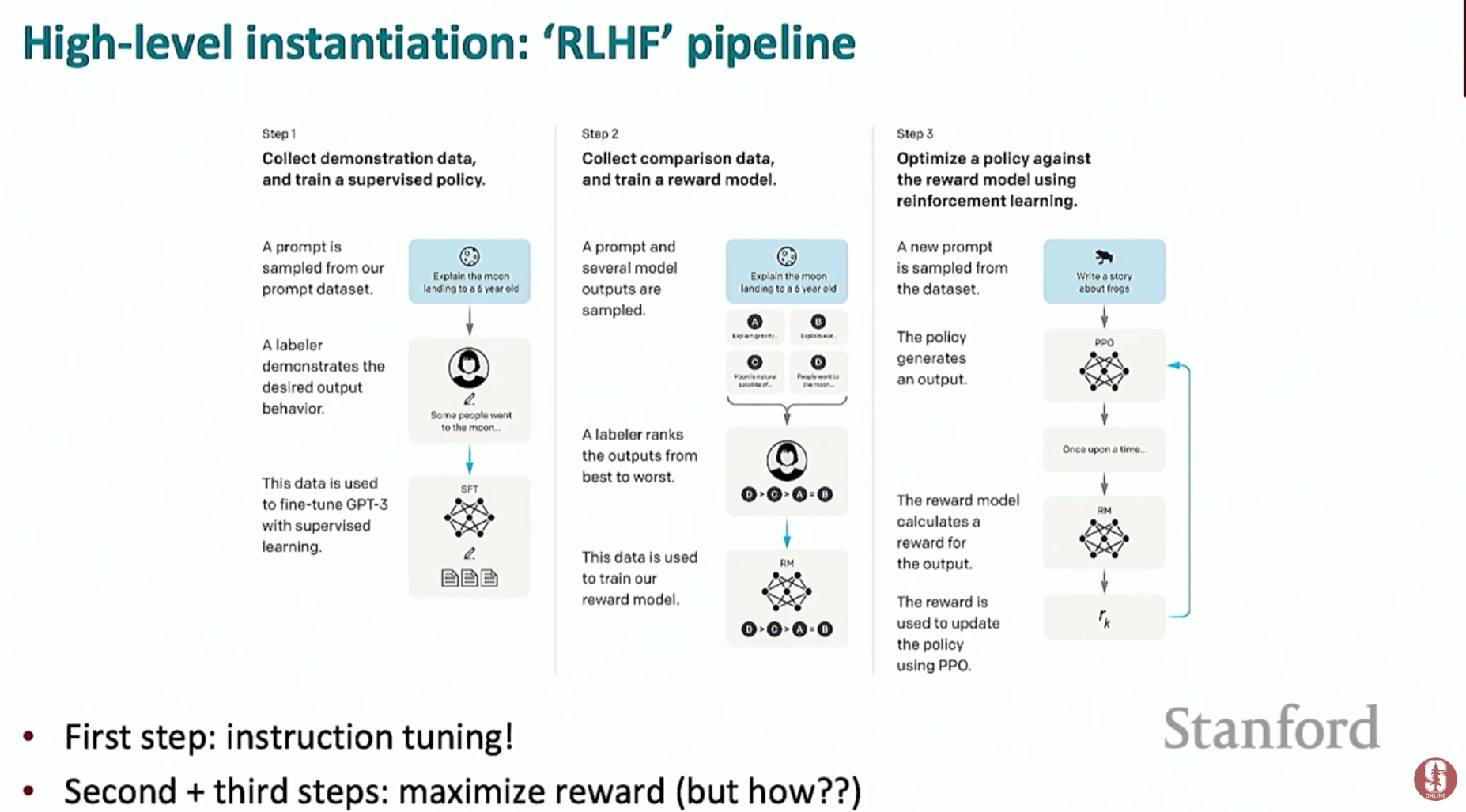
- 개념: 인간이 어떤 답변을 더 선호하는지에 대한 데이터를 직접 사용하여 모델을 최적화하는 3단계 파이프라인입니다. ChatGPT의 핵심 기술 중 하나입니다.
- RLHF 파이프라인:
1. 명령어 미세 조정 모델(SFT) 준비: 1단계로, 명령어 미세 조정을 마친 모델을 준비합니다.
2. 보상 모델(Reward Model) 학습:
- 사람이 직접 여러 개의 모델 답변을 보고 선호도 순위를 매깁니다. (A답변 > B답변)
- 이 순위 데이터를 이용해, 특정 답변이 얼마나 좋은지 점수를 예측하는 보상 모델을 학습시킵니다.
3. 강화 학습을 통한 LLM 최적화:
- SFT 모델이 새로운 답변을 생성하면, 보상 모델이 그 답변에 점수를 매깁니다.
- LLM은 이 보상 점수를 최대로 받는 방향으로 자신의 정책(답변 생성 방식)을 업데이트합니다.

3) RLHF의 수학적 원리
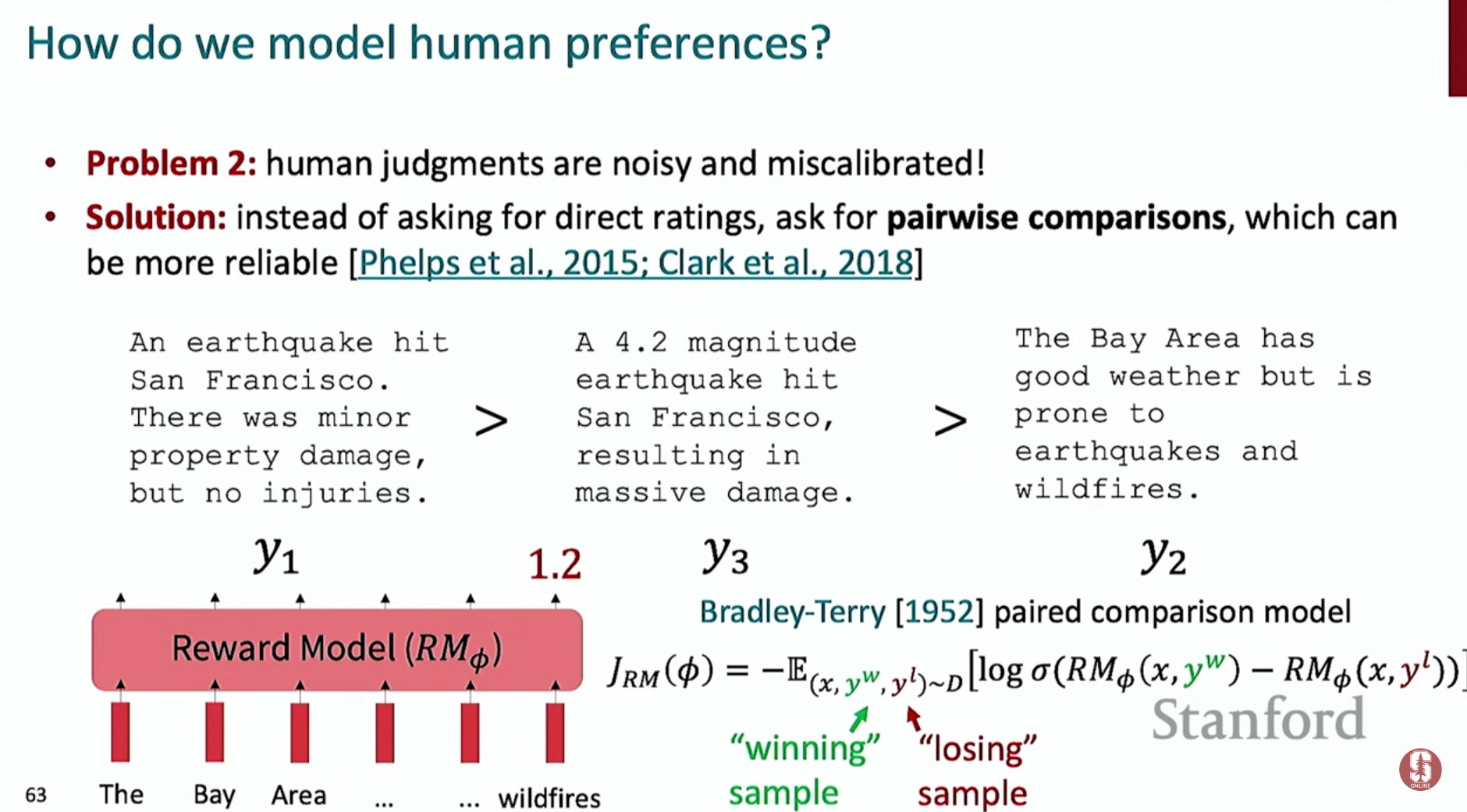
- 최적화 목표 함수: RLHF는 보상 모델()이 주는 보상의 기댓값을 최대화하는 동시에, 기존 언어 모델()에서 너무 멀리 벗어나지 않도록 KL 발산(KL-divergence) 페널티를 추가합니다.
- 수식:
- : 프롬프트 에 대한 응답 의 점수를 매기는 보상 모델입니다.
- : 페널티의 강도를 조절하는 가중치입니다.
- : 두 확률 분포의 차이를 측정하는 KL 발산으로, 모델이 비정상적인 텍스트를 생성하는 것(reward hacking)을 방지하는 역할을 합니다.


4) DPO (직접 선호도 최적화)
- 개념: RLHF의 복잡한 강화학습 과정을 없애고, 선호도 데이터를 이용해 직접 언어 모델을 최적화하는 더 간단하고 안정적인 방법입니다.
- 장점:
- 구현이 훨씬 간단하고 학습이 안정적입니다.
- RLHF와 동등하거나 더 나은 성능을 보입니다.
- 이 단순함 덕분에 Mistral, Llama 3 등 대부분의 최신 오픈소스 모델들이 DPO를 채택하고 있습니다.

5) DPO의 수학적 원리
-
핵심 아이디어: DPO는 RLHF의 최적화 목표를 수학적으로 변형하여, 보상 모델을 명시적으로 학습할 필요 없이 단순한 분류 손실(classification loss)만으로 동일한 목표를 달성할 수 있음을 보였습니다.
-
수학적 유도 과정:
- RLHF의 최적 해()는 보상 함수()와 기존 모델()을 사용해 특정 수식으로 표현됩니다.
- 이 수식을 보상 함수 에 대해 정리하면, 보상 함수가 두 언어 모델의 확률 비율로 표현될 수 있음을 알 수 있습니다.
- 문제는 이 식에 포함된 파티션 함수 항인데, 계산이 거의 불가능합니다.
- DPO는 인간의 선호도 데이터(선호하는 답변 , 비선호하는 답변 )의 보상 차이를 계산할 때, 이 항이 서로 상쇄되어 사라진다는 점을 이용합니다.
-
최종 손실 함수:
- 이 손실 함수는 강화학습 없이 **선호도 데이터를 이용해 직접 언어 모델을 최적화**하게 해주며, 이것이 DPO의 핵심입니다.

6) 심화 내용: RLHF vs DPO
- 기술적 배경: RLHF는 로봇 공학에서 아이디어를 얻어 언어 모델에 적용했지만, 4개의 모델을 동시에 학습시켜야 하는 등 구현이 매우 복잡하고 불안정했습니다.
- 최신 동향: DPO는 RLHF와 동일한 목표를 수학적으로 더 단순하게 풀어내면서 학습 안정성과 효율성을 크게 높였습니다. 이로 인해 최신 오픈소스 LLM 개발의 표준적인 방법론으로 빠르게 자리 잡고 있습니다.
- 명확한 한계점: 두 방법 모두 보상 해킹(Reward Hacking)의 위험이 있습니다. 즉, 모델이 보상 모델의 허점을 파고들어 점수만 높고 실제 품질은 낮은 답변을 생성할 수 있습니다.

5. 한계점 및 향후 전망
- 인간 선호도의 함정:
- 인간은 진실된 답변보다 자신감 있고 권위적으로 들리는 답변을 선호하는 경향이 있어, 모델이 환각(Hallucination)을 더 조장할 수 있습니다.
- 또한, 인간 레이블러들이 긴 답변을 더 선호하는 경향 때문에 초기 ChatGPT가 불필요하게 장황한 답변을 생성하는 과도한 장황함(Verbosity) 문제가 있었습니다.
- 남아있는 과제: 선호도 최적화 기법들은 모델을 더 유용하게 만들었지만, 환각(Hallucinations)이나 편향(Biases)과 같은 근본적인 문제를 해결하지는 못합니다.
결론적으로, LLM의 발전은 단순히 모델과 데이터를 키우는 것을 넘어, 문맥 내 학습, 명령어 미세 조정, 그리고 RLHF/DPO와 같은 후처리 기술을 통해 사용자의 의도와 가치에 더 잘 부합하는 방향으로 정교하게 '정렬'되어가는 과정이라고 할 수 있습니다.

AI 공부합니다