1. 모델 성능 평가의 필요성
1) 왜 모델 성능을 측정해야 할까요?
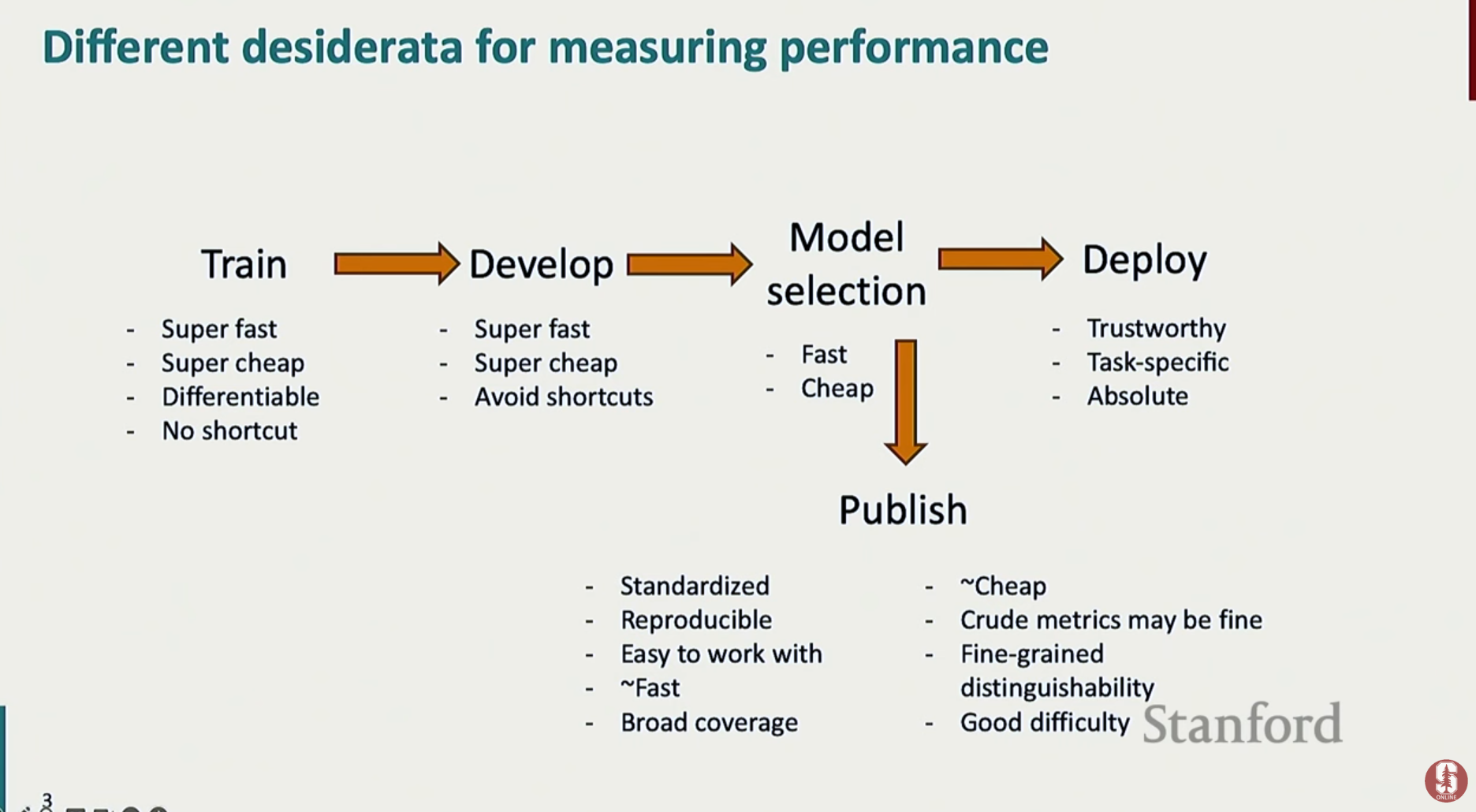
- 모델의 성능을 측정하는 것은 NLP 프로젝트의 성공을 위해 여러 단계에서 필수적인 과정입니다. 단순한 점수 확인을 넘어, 각 단계의 목표 달성을 위한 핵심적인 역할을 수행합니다.
- 모델 훈련 (Training): 훈련 과정에서 모델이 올바른 방향으로 학습되고 있는지 확인하고, 손실(loss)을 언제까지 최적화할지 결정하는 지표가 됩니다.
- 개발 (Development): 하이퍼파라미터 튜닝이나 조기 종료(early stopping)와 같은 의사결정을 내릴 때, 어떤 모델이 더 나은지 판단하는 기준을 제공합니다.
- 모델 선택 (Model Selection): 특정 과제(task)를 가장 잘 해결할 수 있는 모델이 무엇인지, 여러 후보 모델 중에서 객관적으로 비교하고 선택하기 위해 필요합니다.
- 배포 (Deployment): 개발된 모델이 실제 서비스 환경에 투입될 만큼 신뢰할 수 있고 안정적인 성능을 내는지 확인하는 최종 검증 단계입니다.
- 논문 출판 (Publishing): 연구의 독창성과 모델의 우수성을 학계에 증명하기 위해, 표준화된 벤치마크를 사용한 공신력 있는 평가 결과가 반드시 필요합니다.
2) 상황에 따라 달라지는 평가 방식
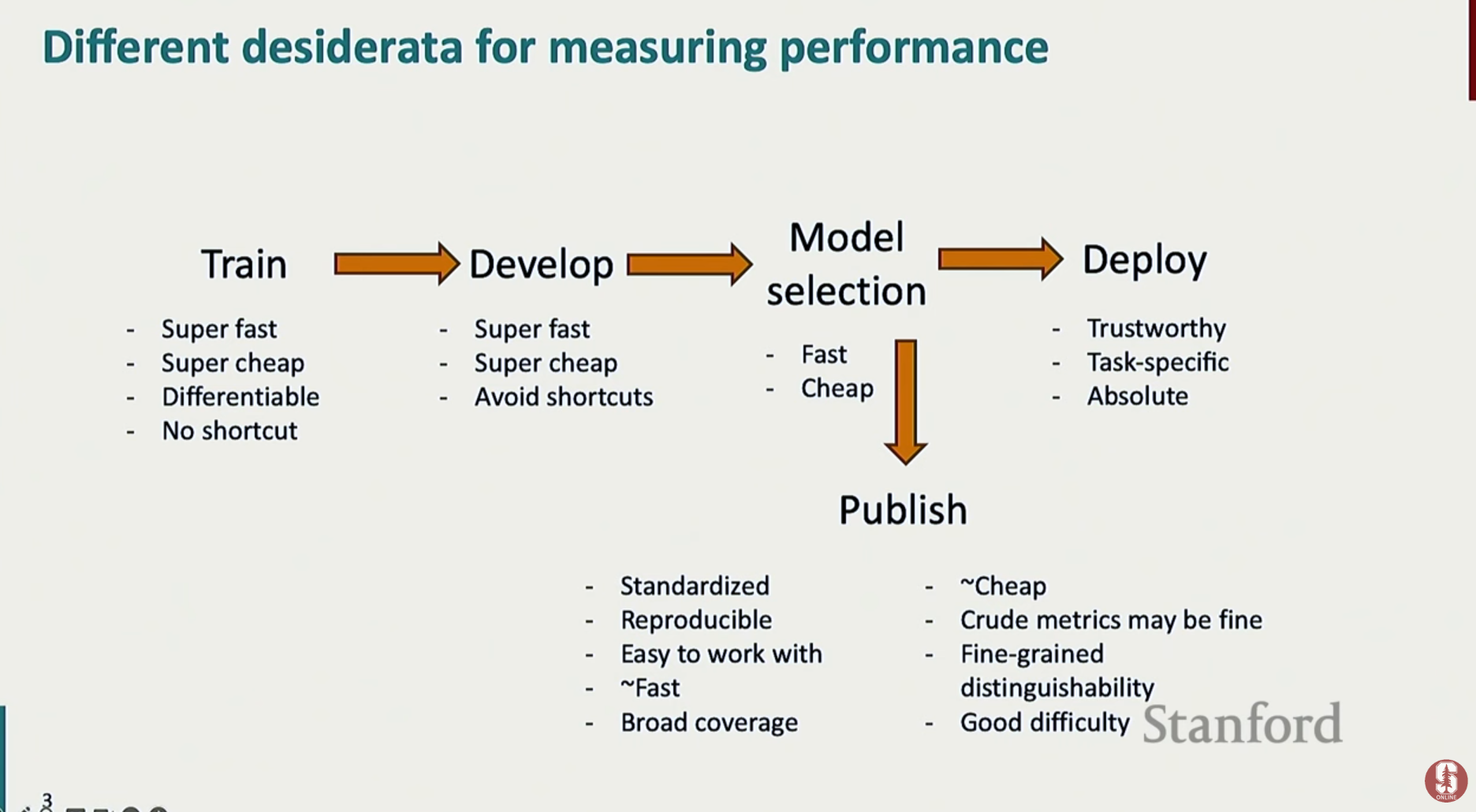
- 평가의 목적에 따라 중요하게 고려되는 요소들이 달라지며, 각기 다른 특성을 가진 평가지표가 요구됩니다.
- 훈련 중 평가:
- 훈련은 수없이 반복되므로 빠르고 저렴하게 계산할 수 있어야 합니다.
- 경사 하강법(gradient descent)을 사용하기 위해 평가 지표가 미분 가능해야 옵티마이저가 손실을 줄이는 방향으로 모델을 업데이트할 수 있습니다.
- 모델이 데이터의 특정 패턴에만 과적합되는 **지름길 최적화(shortcut optimization)**를 피하고, 일반적인 언어 능력을 학습하도록 유도해야 합니다.
- 배포 시 평가:
- 실제 서비스의 품질과 직결되므로 절대적으로 신뢰할 수 있어야 합니다.
- 서비스의 특성을 잘 반영하는 작업별(task-specific) 지표가 중요하며, 모델의 성능을 절대적인 기준으로 판단할 수 있어야 합니다.
- 학술 벤치마킹:
- 다른 연구자들도 동일한 조건에서 성능을 검증할 수 있도록 재현 가능하고 표준화되어야 합니다.
- 많은 연구자가 쉽게 사용할 수 있어야 하며, 벤치마크 자체가 너무 복잡하거나 단순하지 않고 적절한 난이도를 가져야 합니다.
2. NLP 과제의 종류와 평가 방법
1) 폐쇄형 과제 (Closed-ended Tasks)
- 정답의 가짓수가 정해져 있거나 제한적인 과제를 의미합니다. 예를 들어, 문장을 '긍정' 또는 '부정'으로 분류하는 경우가 대표적입니다.
- 대표적인 과제들:
- 감성 분석(Sentiment Analysis): 텍스트에 담긴 감정을 분류합니다.
- 자연어 추론(Entailment): 두 문장 간의 논리적 관계(함의, 모순, 중립)를 파악합니다.
- 품사 태깅(Part-of-speech Tagging): 문장 내 각 단어의 품사를 결정합니다.
- 개체명 인식(Named Entity Recognition): 인물, 장소, 기관 등 고유한 개체명을 식별합니다.
- 평가 지표:
- 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 점수와 같이 전통적인 머신러닝 분류 문제에서 널리 사용되는 표준 지표를 통해 명확하게 평가됩니다.
- 고려할 점:
- 표준 지표를 사용하더라도, 어떤 지표에 가중치를 둘지, 데이터의 레이블은 신뢰할 만한 출처에서 왔는지, 모델이 단순히 표면적인 단서에만 의존하는 **가짜 상관관계(spurious correlation)**를 학습한 것은 아닌지 등을 깊이 있게 분석해야 합니다.
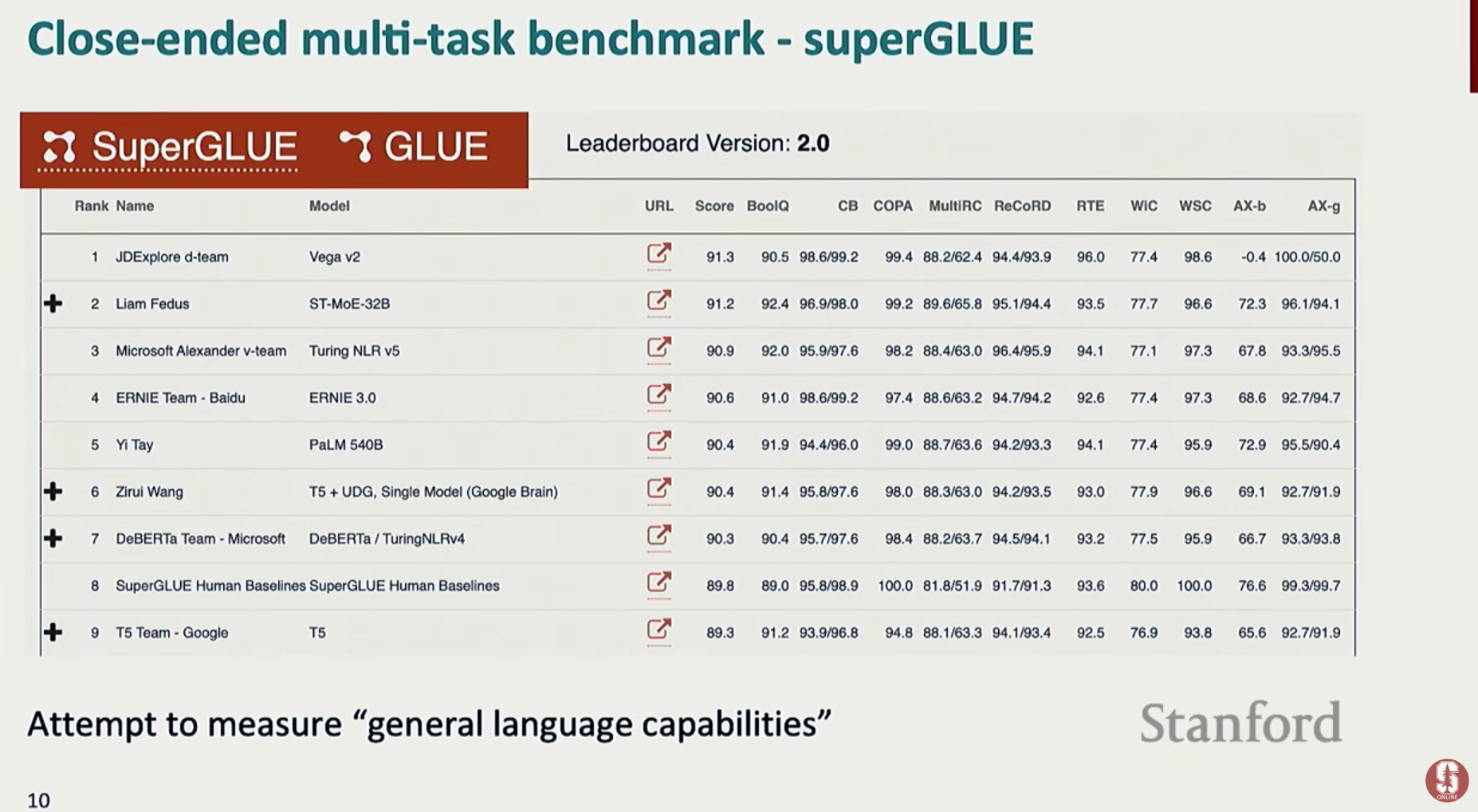
- 종합 벤치마크:
- SuperGLUE는 다양한 종류의 폐쇄형 과제를 모아놓은 벤치마크로, 모델의 전반적인 언어 이해 능력을 종합적으로 측정하는 데 사용됩니다.


2) 개방형 과제 (Open-ended Tasks)
- 정답이 하나로 정해져 있지 않고, 무수히 많은 정답이 가능한 과제를 의미합니다. 요약, 번역, 챗봇 대화와 같은 텍스트 생성 과제가 대표적입니다. 평가는 매우 도전적이며, 강의에서 가장 비중 있게 다루는 부분입니다.
평가 방법
- 콘텐츠 중복 기반 지표 (Content Overlap Metrics)
- 생성된 텍스트가 정답(참조) 텍스트와 얼마나 많은 단어 또는 구(phrase)를 공유하는지 측정하는 방식입니다.
- BLEU: 정밀도(Precision) 기반 지표로, 생성된 문장에 등장한 단어 n-gram이 정답 문장에도 등장하는지 확인합니다. 주로 기계 번역 평가에 사용됩니다.
- ROUGE: 재현율(Recall) 기반 지표로, 정답 문장의 단어 n-gram이 생성된 문장에 얼마나 포함되었는지 확인합니다. 주로 문서 요약 평가에 사용됩니다.
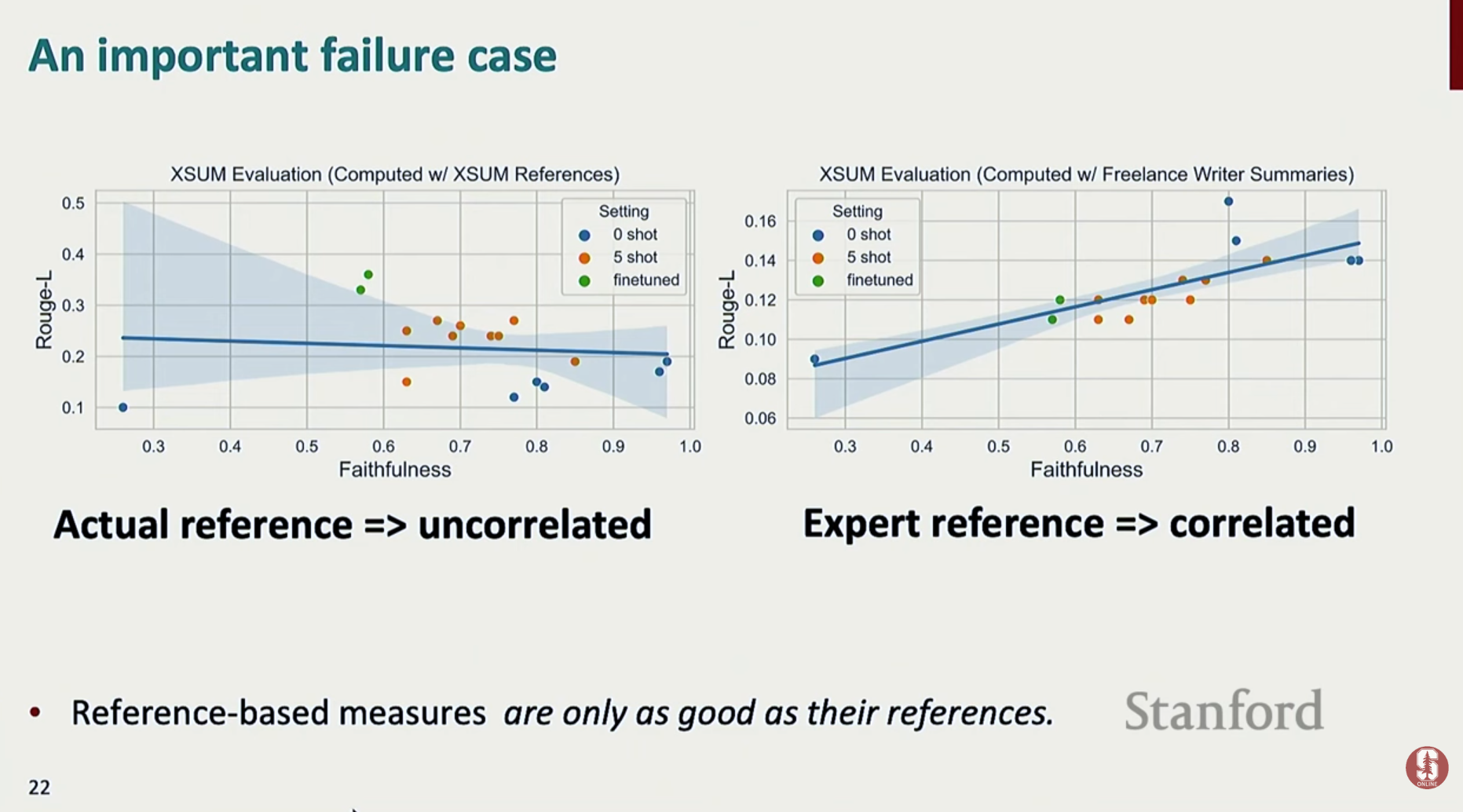
- 명확한 한계점: 이 방식들은 단어의 의미적 유사성을 전혀 고려하지 못합니다. 예를 들어 '좋다'와 '훌륭하다'를 완전히 다른 단어로 취급하여, 의미는 같지만 다른 단어를 사용한 좋은 품질의 생성을 제대로 평가하지 못하는 맹점이 있습니다.
- 해결책: 이러한 한계를 극복하기 위해 단어 임베딩의 유사도를 활용하는 BERTscore와 같은 지표가 등장했습니다. 이는 문맥을 고려하여 의미적 유사성을 측정함으로써 더 정교한 평가가 가능합니다.

- 모델 기반 평가 (Model-based Metrics)
- 평가 자체를 또 다른 머신러닝 문제로 정의하고, 인간의 평가를 예측하도록 훈련된 별도의 **'평가자 모델'**을 사용하는 방식입니다. BLURT가 대표적인 예입니다.

- 평가 자체를 또 다른 머신러닝 문제로 정의하고, 인간의 평가를 예측하도록 훈련된 별도의 **'평가자 모델'**을 사용하는 방식입니다. BLURT가 대표적인 예입니다.
- 인간 평가 (Human Evaluation)
- 사람이 직접 생성된 결과물을 읽고 품질을 평가하는 방식으로, 개방형 과제 평가에서 가장 신뢰할 수 있는 **'황금 표준(Gold Standard)'**으로 여겨집니다.
- 심각한 문제점: 하지만 느리고, 비용이 매우 비싸며, 평가자 개인의 주관에 따라 결과가 달라지는 등 일관성이 부족하고, 다른 연구자가 동일한 평가를 재현하기 어렵다는 치명적인 단점들을 가지고 있습니다.
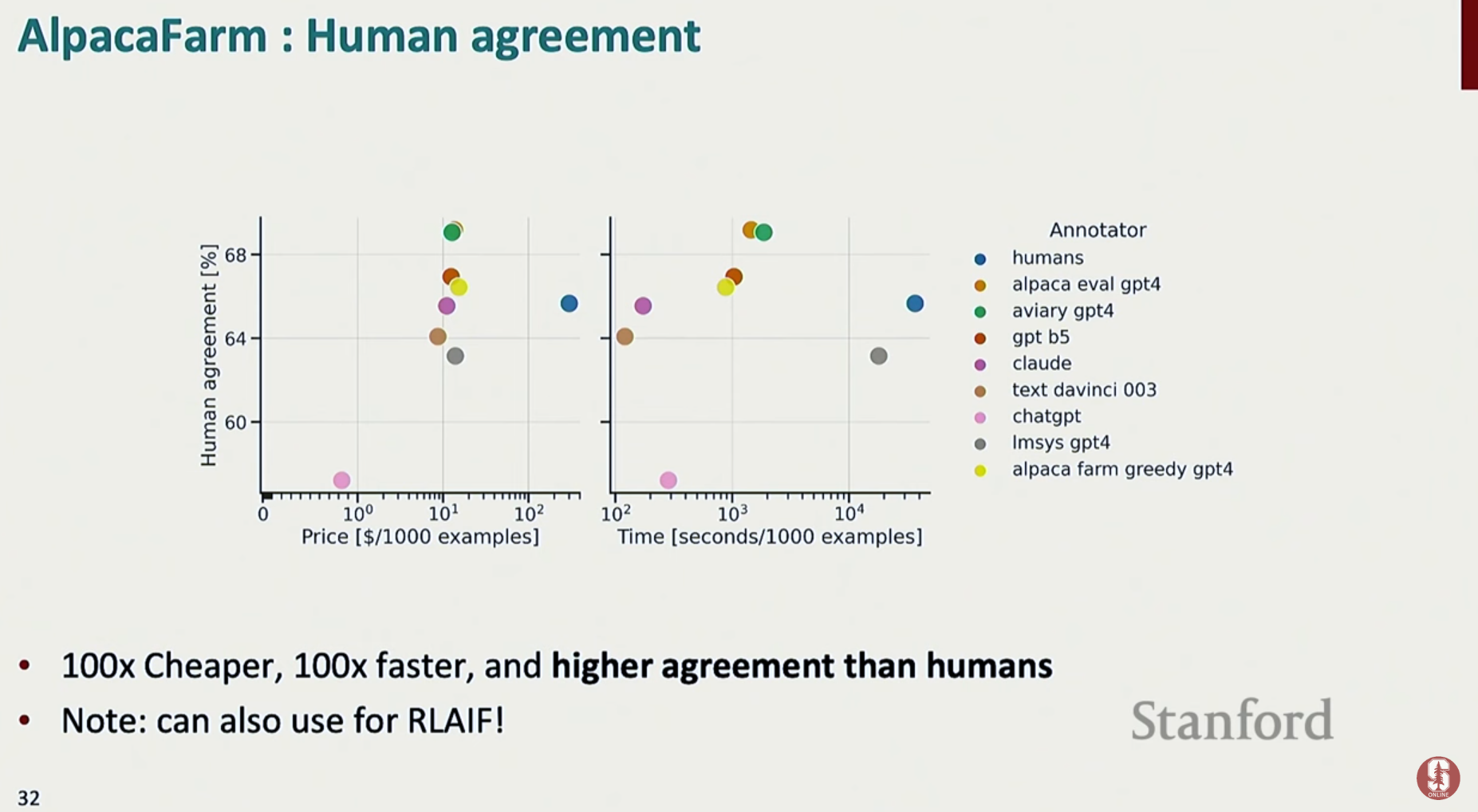
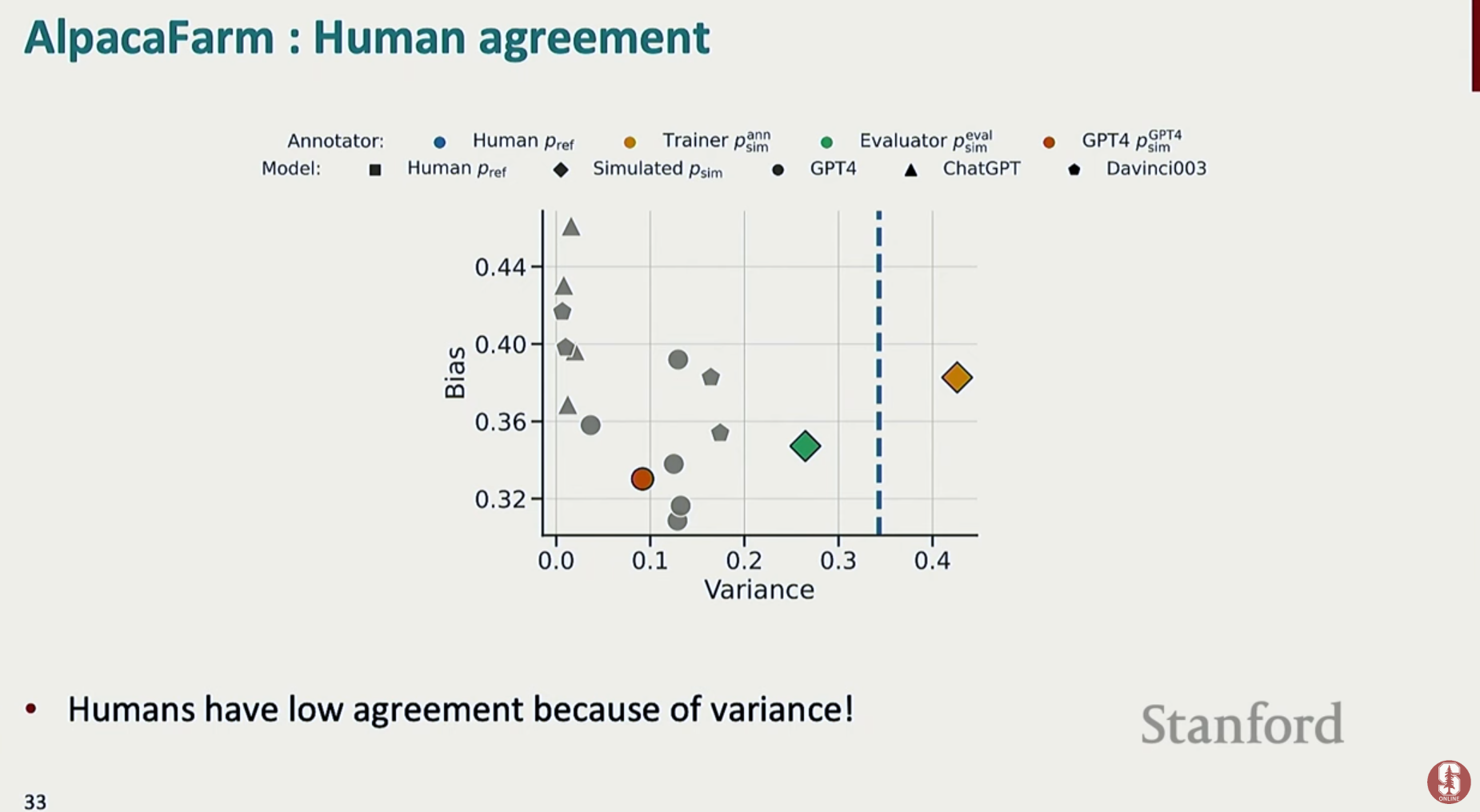

- LLM 기반 평가 및 아레나 방식
- 최근에는 GPT-4와 같은 초거대 언어 모델(LLM)을 평가자로 사용하여 생성물의 품질을 판단하는 방식이 새로운 대안으로 떠오르고 있습니다. 이는 참조 텍스트 없이도 평가가 가능하며, 인간 평가보다 훨씬 빠르고 저렴합니다.
- Chatbot Arena는 이러한 LLM 기반 평가를 대규모로 수행하는 대표적인 플랫폼입니다. 사용자들이 두 모델의 답변을 보고 더 선호하는 쪽을 선택하는 '블라인드 테스트'를 통해 데이터를 모으고, 이를 바탕으로 모델들의 ELO 등급을 매겨 순위를 정합니다.
- AlpacaEval과 MT-bench 역시 GPT-4를 평가자로 활용하는 대표적인 자동화 벤치마크입니다.

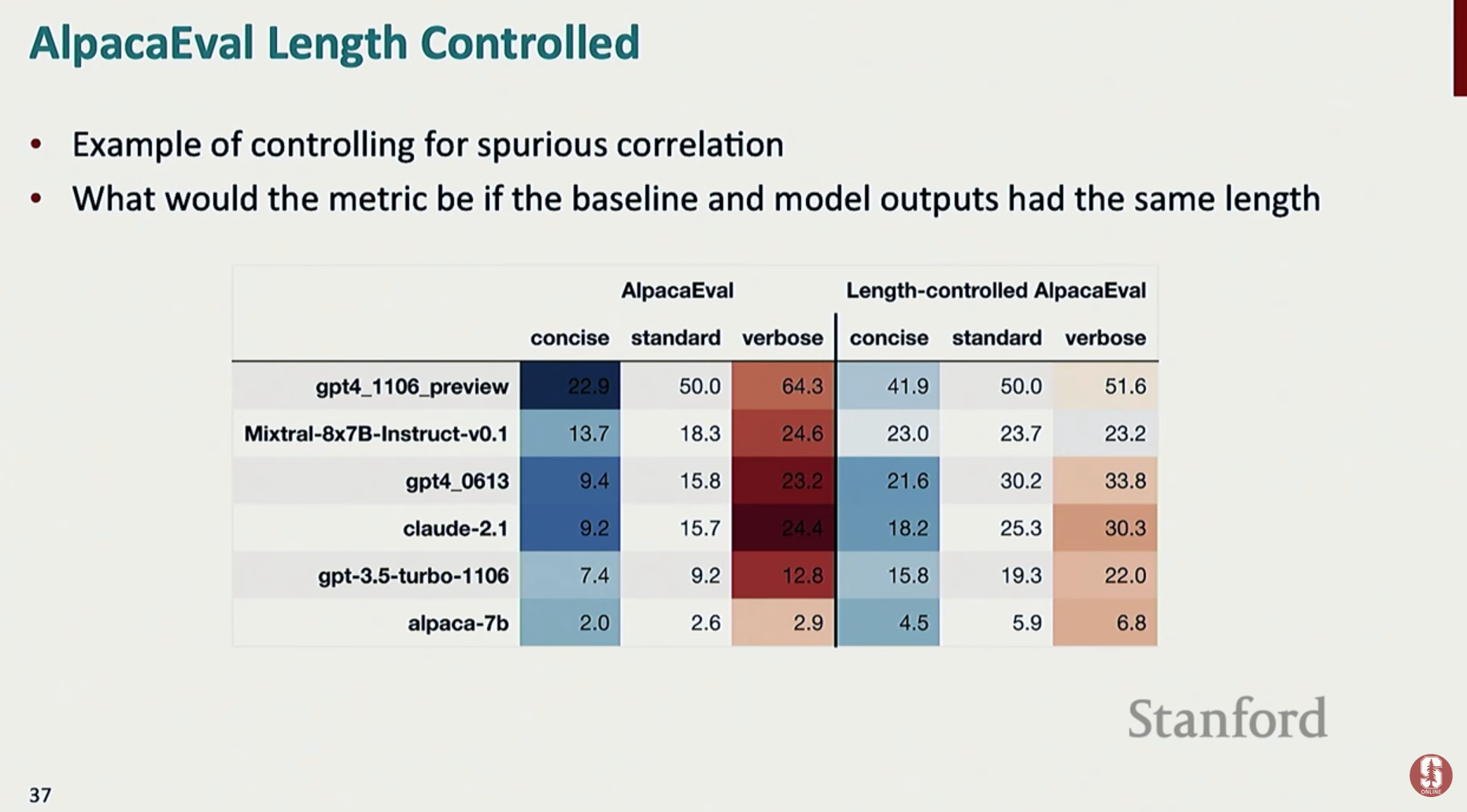
3. LLM 시대의 평가와 도전 과제
1) 현재 LLM은 어떻게 평가되고 있는가?
- LLM의 성능은 단일 지표가 아닌, 여러 방식을 종합하여 다각적으로 평가됩니다.
- Perplexity (혼잡도): 모델이 다음 단어를 얼마나 잘 예측하는지를 나타내는 지표로, 훈련 손실(training loss)과 직결됩니다. 이 지표는 모델의 기본적인 언어 모델링 성능을 보여주며, 실제 다운스트림 과제 성능과도 높은 상관관계를 보입니다.
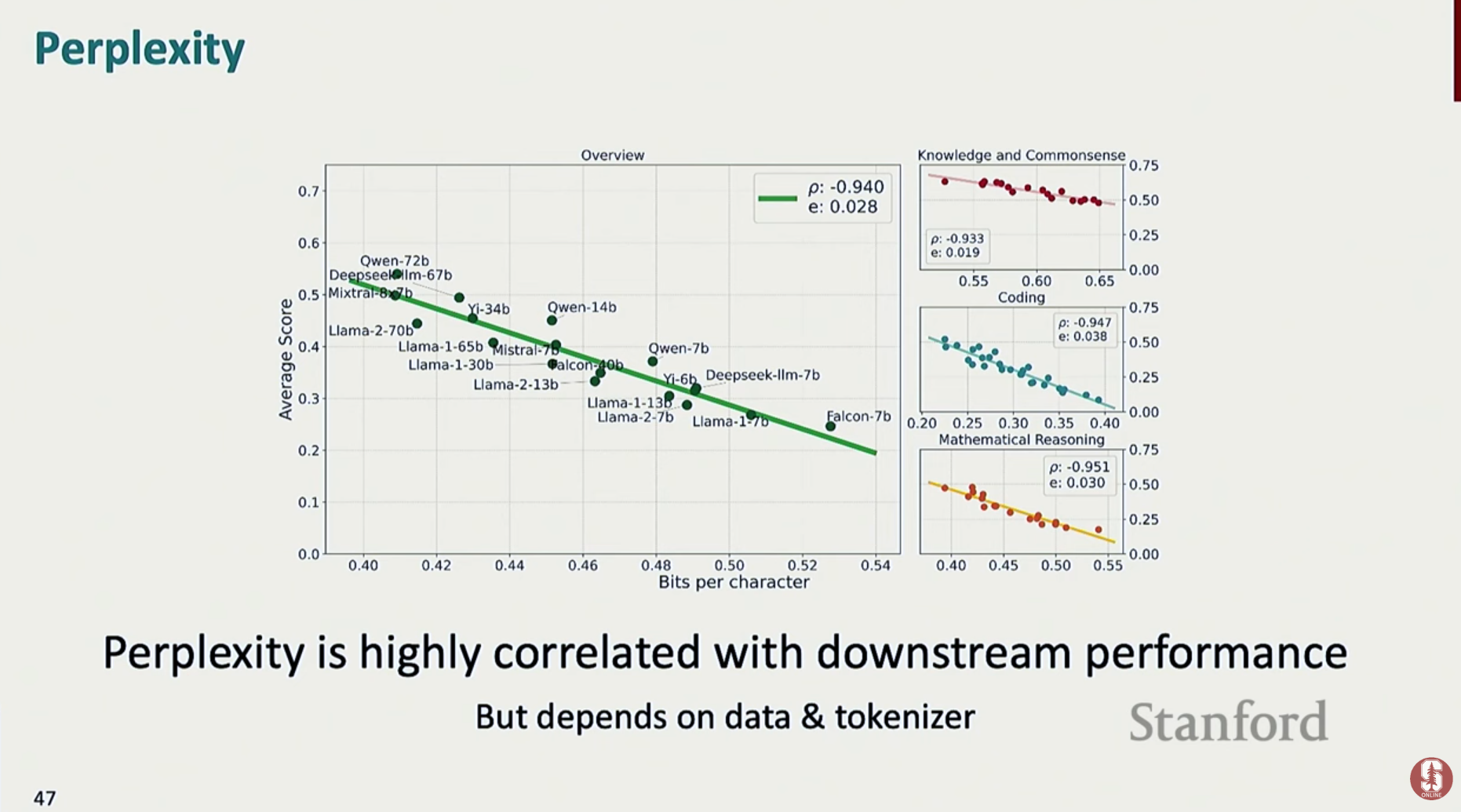
- 벤치마크 집계 (Benchmark Aggregation):
- Hugging Face Open LLM Leaderboard나 HELM과 같이, 다양한 분야의 자동 평가 벤치마크 점수를 평균 내어 종합 성능을 측정합니다.
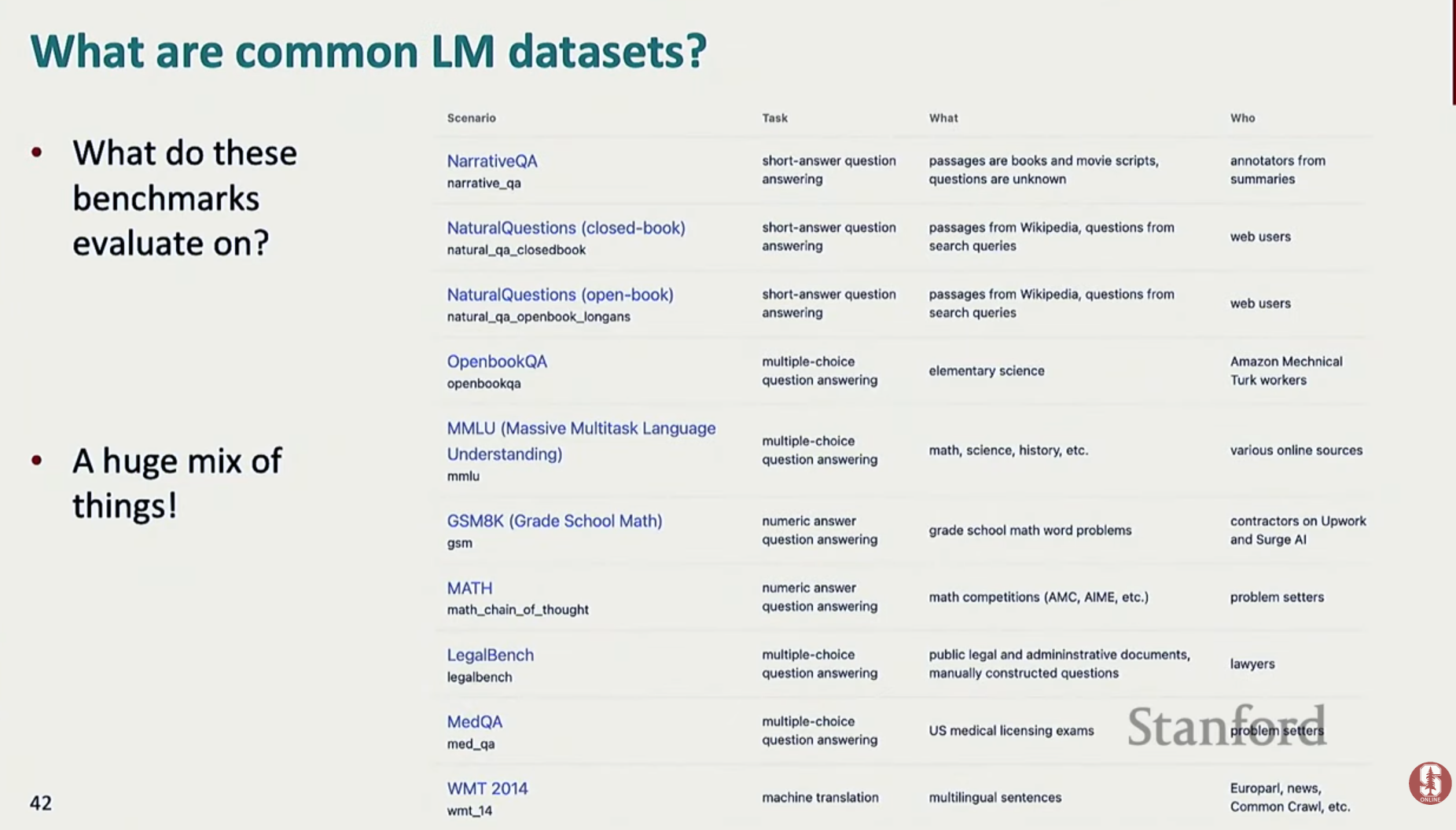
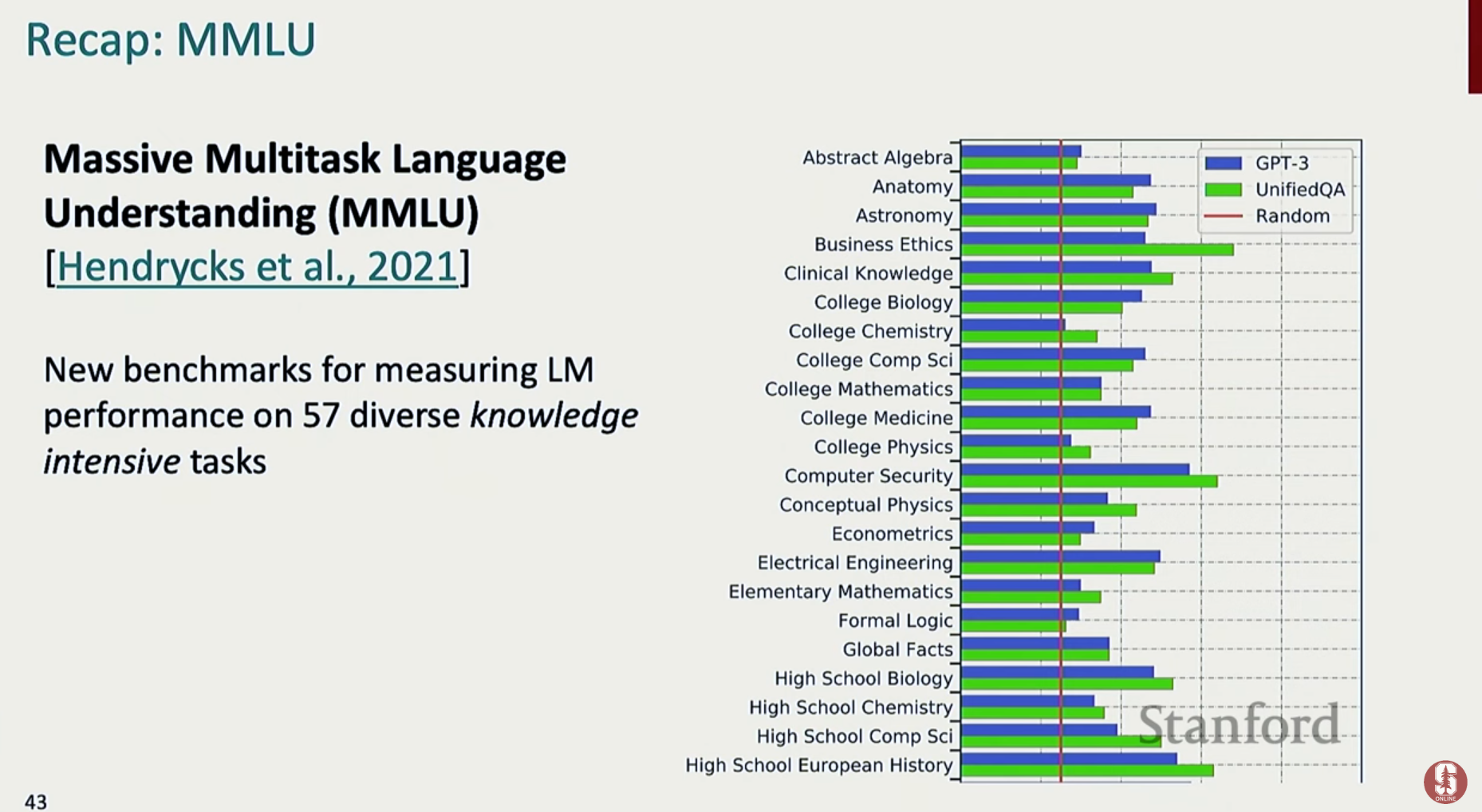
- MMLU: 57개의 다양한 학문 및 전문 분야에 대한 객관식 질문을 통해 모델의 다중 과제 언어 이해 능력과 전반적인 지식 수준을 평가하는 핵심 벤치마크입니다.
- 그 외에도 수학(GSM8K), 코딩, 법률(LegalBench), 의학(MedQA) 등 특정 영역의 문제 해결 능력을 평가하는 벤치마크들이 널리 사용됩니다.
2) 현재 평가 방식의 문제점
- 현재의 평가 방식들은 계속 발전하고 있지만, 여전히 해결해야 할 심각한 문제들을 안고 있습니다.
- 데이터 오염 (Data Contamination): 모델을 평가하기 위해 사용해야 할 테스트 데이터가 모델의 훈련 데이터에 이미 포함되어 있을 경우, 모델의 성능이 실제보다 훨씬 높게 측정되는 심각한 문제입니다. 이는 마치 시험 문제를 미리 보고 시험을 치르는 것과 같습니다.
- 해결책: 테스트 세트를 비공개로 유지하거나, 동적으로 새로운 문제를 생성하고, 훈련 데이터에 테스트 데이터가 얼마나 포함되었는지 추정하는 등의 방법으로 대응하고 있습니다.
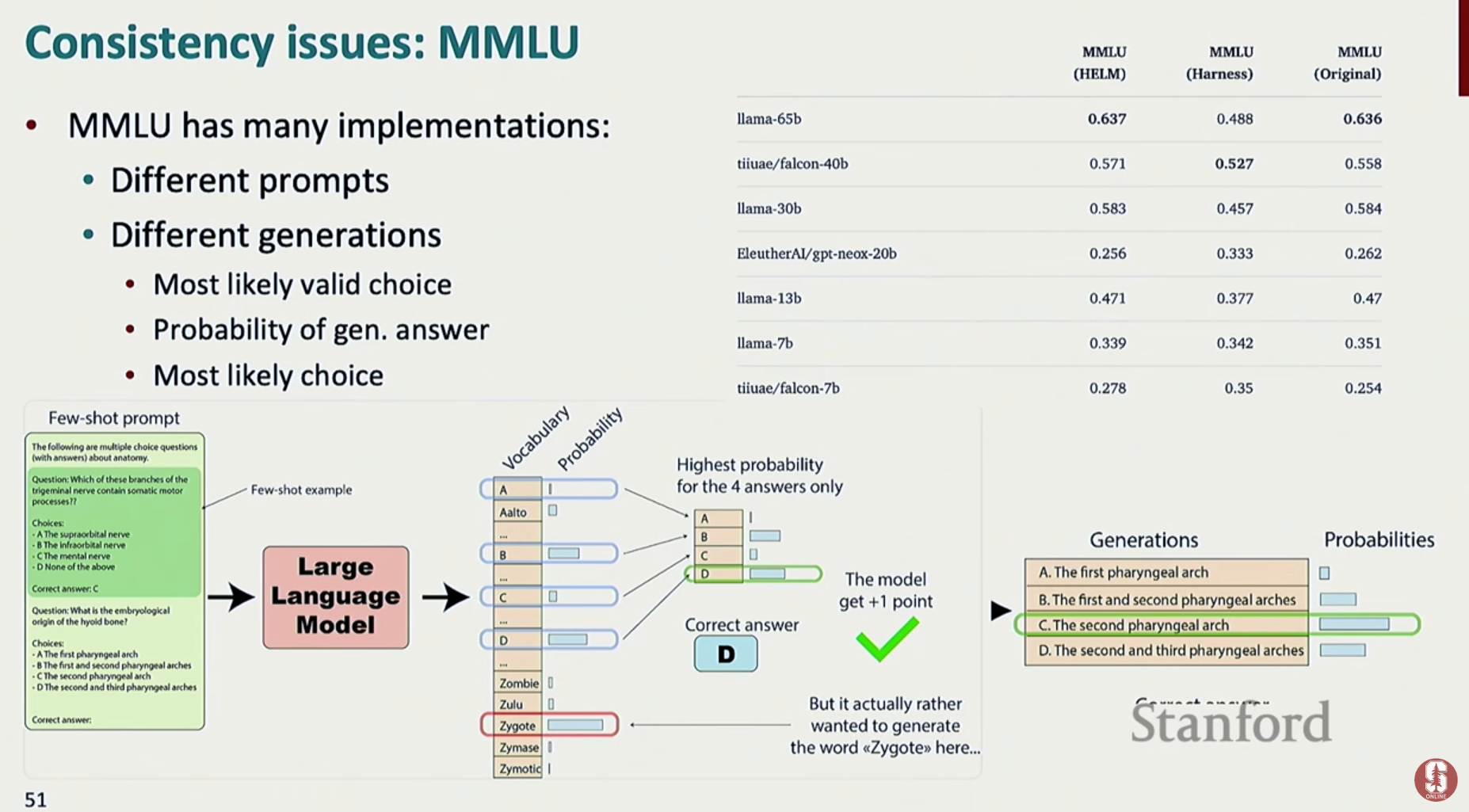
- 일관성 문제: 동일한 모델이라도 프롬프트의 미세한 차이나 샘플링 방식의 변화에 따라 결과가 크게 달라져 모델의 순위가 뒤바뀌는 등 평가의 안정성이 부족합니다.
- NLP 벤치마킹의 단일 문화: 대부분의 연구가 영어를 중심으로 이루어지며, 정확도와 같은 단일 지표에만 집중하는 경향이 있습니다. 이로 인해 다국어 환경에서의 성능이나 모델의 효율성, 편향성, 해석 가능성 등 중요한 다른 측면들을 놓치기 쉽습니다.
- LLM 평가자의 편향성: GPT-4와 같은 LLM을 평가자로 사용할 때, 평가자 모델 자체가 가진 편향(예: 더 긴 답변, 특정 스타일, 목록 형태 선호)이 평가 결과에 영향을 미쳐 공정성을 해칠 수 있습니다.

4. 결론 및 핵심 요약
- 1. 평가의 다양성: 모델 훈련, 배포, 연구 등 목적에 따라 각기 다른 평가 방식과 속성이 요구된다는 점을 반드시 이해해야 합니다.
- 2. 과제 유형별 접근: 폐쇄형 과제는 표준 머신러닝 지표로 비교적 명확하게 평가되지만, 개방형 과제는 콘텐츠 중복, LLM 기반, 인간 평가 등 복합적인 방법을 함께 고려해야 합니다.
- 3. 현재의 도전 과제: 데이터 오염, 일관성 부족, 편향성은 현재 LLM 평가 방식이 시급히 해결해야 할 주요 문제입니다.
- 4. 가장 중요한 원칙: 숫자로 표현된 점수에만 맹목적으로 의존해서는 안 됩니다. 항상 모델이 생성한 실제 결과물을 직접 눈으로 확인하고 질적으로 분석하는 것이 무엇보다 중요합니다.
심화 내용: LLM 기반 평가의 미래와 한계
- 기술적 배경 및 동향: 강의에서 강조된 것처럼, GPT-4와 같은 강력한 LLM의 등장은 평가의 패러다임을 바꾸고 있습니다. 인간의 판단을 모방하는 LLM 평가자는 정량화하기 어려웠던 '창의성', '논리성', '유용성' 등을 평가할 수 있는 가능성을 열었습니다. 최근 연구들은 여러 LLM 평가자의 결과를 종합하거나(앙상블), 평가자에게 명확한 기준(루브릭)을 제시하여 평가의 일관성과 신뢰도를 높이는 데 집중하고 있습니다. Chatbot Arena와 같은 플랫폼은 이러한 평가 방식을 대중화하며 커뮤니티 주도의 새로운 표준을 만들어가고 있습니다.
- 명확한 한계점: 그럼에도 불구하고 LLM 평가자는 완벽하지 않습니다. 강의에서 지적되었듯, 자기 편향(self-bias), 즉 자신이 생성했을 법한 스타일에 더 높은 점수를 주는 경향이 있습니다. 또한, 평가 모델이 모르는 최신 정보나 매우 전문적인 영역에 대한 평가는 부정확할 수 있습니다. 따라서 현재 LLM 기반 평가는 인간 평가를 완전히 대체하기보다는, 대규모 모델을 빠르고 저렴하게 비교하고 검증하기 위한 보조적인 도구로서 활용하는 것이 가장 합리적인 접근 방식입니다.

AI 공부합니다