1. 혼합 정밀도 훈련 (Mixed Precision Training)
- 모델 훈련 시 메모리 사용량을 줄이고 속도를 높이기 위해, 기존의 32비트 부동소수점(
fp32) 대신 16비트 부동소수점(fp16)을 함께 사용하는 기술입니다.
1) 부동소수점(Floating Point)과 그 한계
fp32 (단정밀도): 4바이트를 사용하며, 넓은 범위의 숫자를 높은 정밀도로 표현할 수 있어 안정적이지만 메모리 요구량이 큽니다.fp16 (반정밀도): 2바이트를 사용하여 메모리 사용량을 절반으로 줄일 수 있습니다. 하지만 표현할 수 있는 숫자의 범위와 정밀도가 낮다는 명확한 한계가 있습니다.
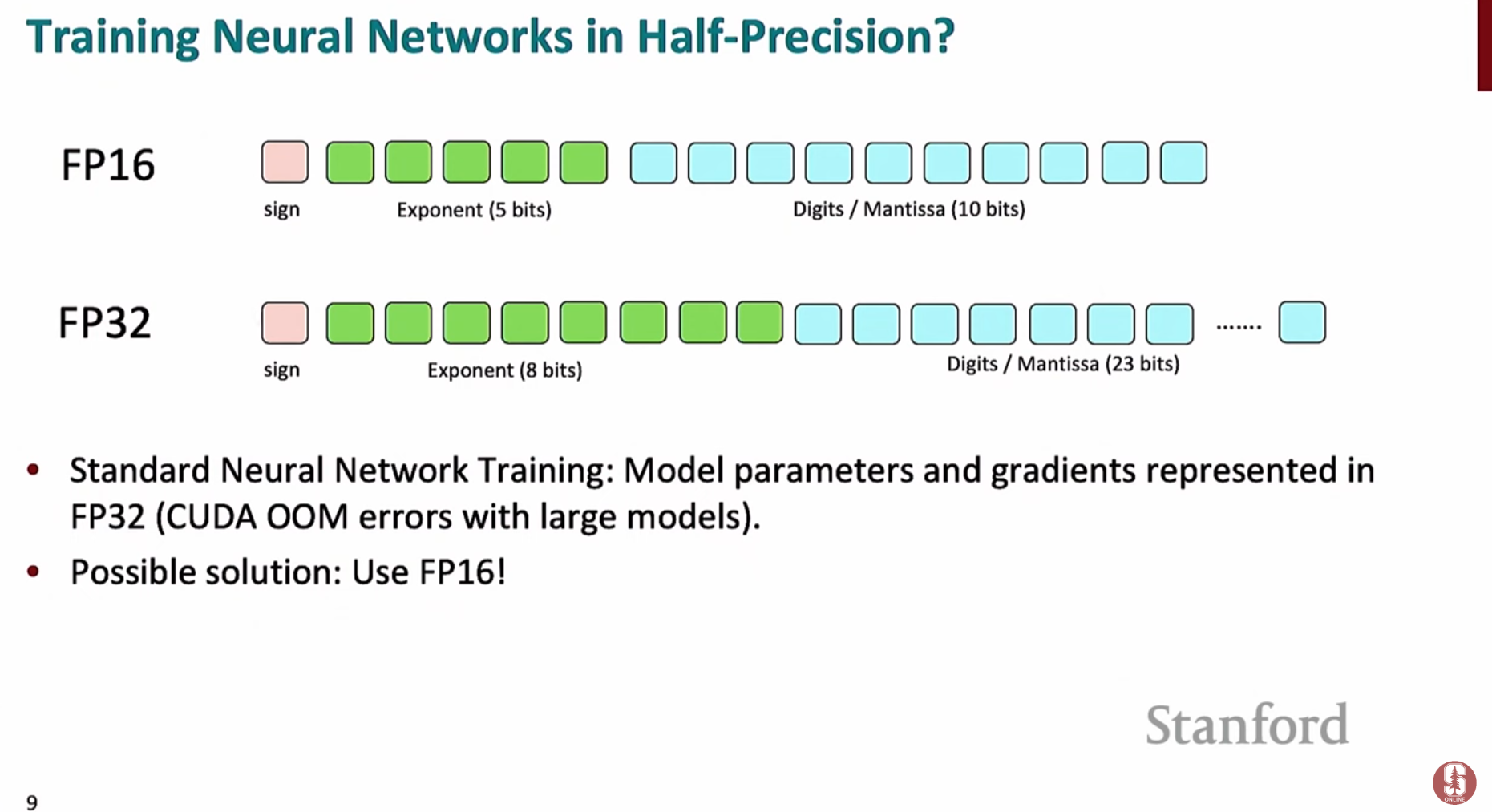

fp16의 문제점:- 언더플로우(Underflow): 너무 작은 값(예: 기울기)은 0으로 처리되어 모델이 학습되지 않는 문제가 발생할 수 있습니다.
- 오버플로우(Overflow): 표현 범위를 벗어나는 큰 값은 NaN(Not a Number)으로 처리되어 훈련이 불안정해집니다.
- 정밀도 손실: 반올림 오류로 인해 모델의 성능이 저하될 수 있습니다.
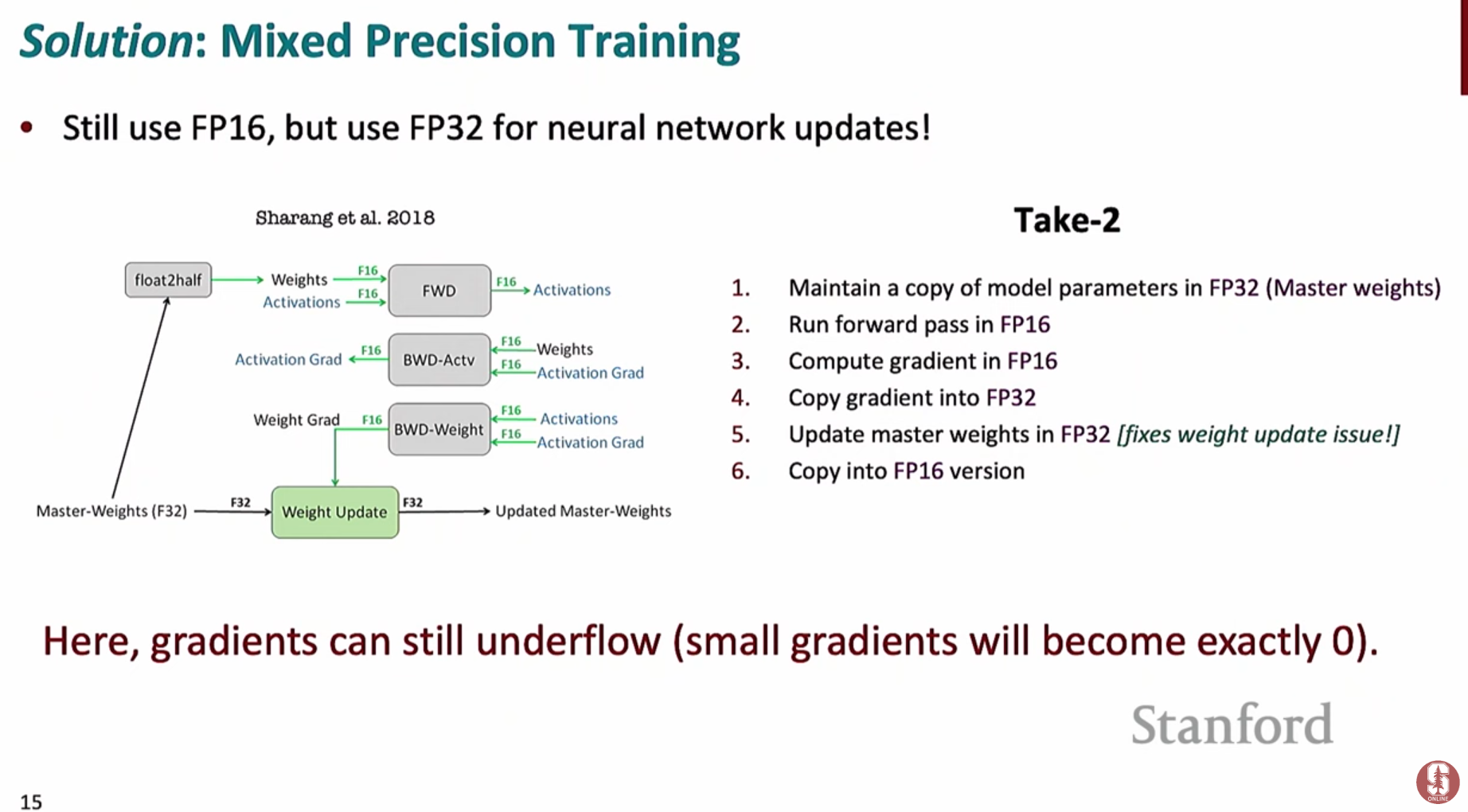
2) 문제 해결 방안: 기울기 스케일링 (Gradient Scaling)
fp16의 언더플로우 문제를 해결하기 위한 기법으로, 다음과 같은 단계로 진행됩니다.- 1단계:
fp32로 된 마스터 가중치(Master Weights)의 복사본을 유지합니다. - 2단계: 순전파(Forward Pass)와 역전파(Backward Pass)는
fp16으로 수행하여 속도와 메모리 이점을 얻습니다. - 3단계: 역전파 과정에서 계산된 손실(Loss)에 아주 큰 값(스케일링 팩터)을 곱해줍니다. 이 과정을 통해 기울기 값들이
fp16의 표현 범위를 벗어나 0이 되는 것을 방지합니다. - 4단계: 스케일링된 기울기를 다시
fp32로 변환한 후, 마스터 가중치를 업데이트하고 원래의 스케일링 팩터로 다시 나누어 줍니다.

- 1단계:
3) 더 나은 대안: BFloat16 (BF16)
- 구글 브레인에서 개발한
**BFloat16 (BF16)**은 기울기 스케일링의 복잡함을 해결해주는 데이터 형식입니다. fp32와 동일한 동적 범위(Dynamic Range)를 가지면서 정밀도만 낮춘 형태입니다.- 신경망 훈련에서는 높은 정밀도보다 넓은 표현 범위가 더 중요한 경우가 많기 때문에,
BF16은 언더플로우 문제 없이fp16의 장점을 누릴 수 있게 해줍니다. - 최신 Nvidia GPU(A100 등)에서 지원되며, 사용 가능하다면 복잡한 기울기 스케일링 없이 혼합 정밀도 훈련을 사용하는 것이 항상 권장됩니다.


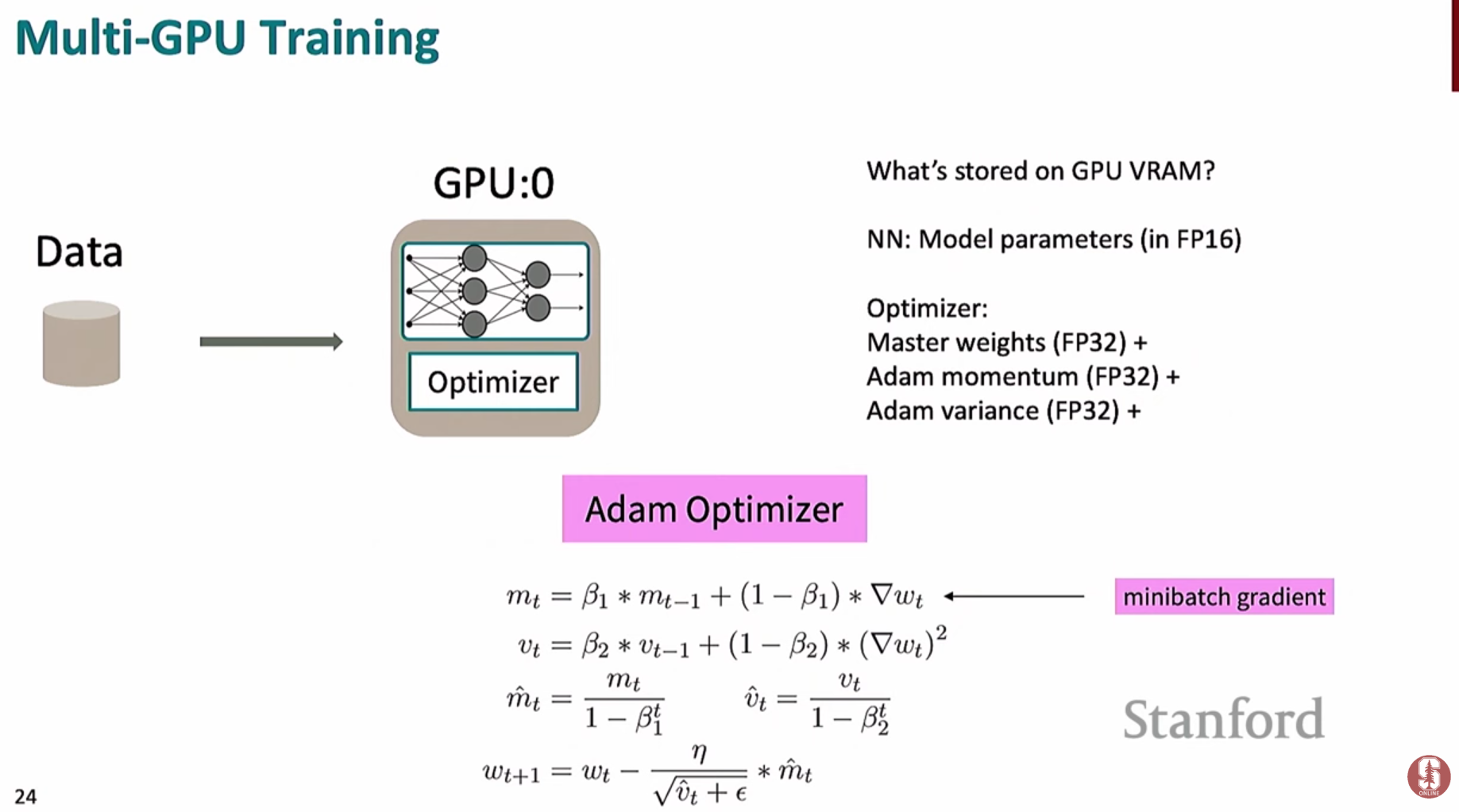
다중 GPU 훈련(Multi-GPU Training) 및 메모리 최적화
- 단일 GPU의 메모리 한계를 극복하고 훈련 속도를 높이기 위해 여러 개의 GPU를 동시에 사용하는 전략입니다.
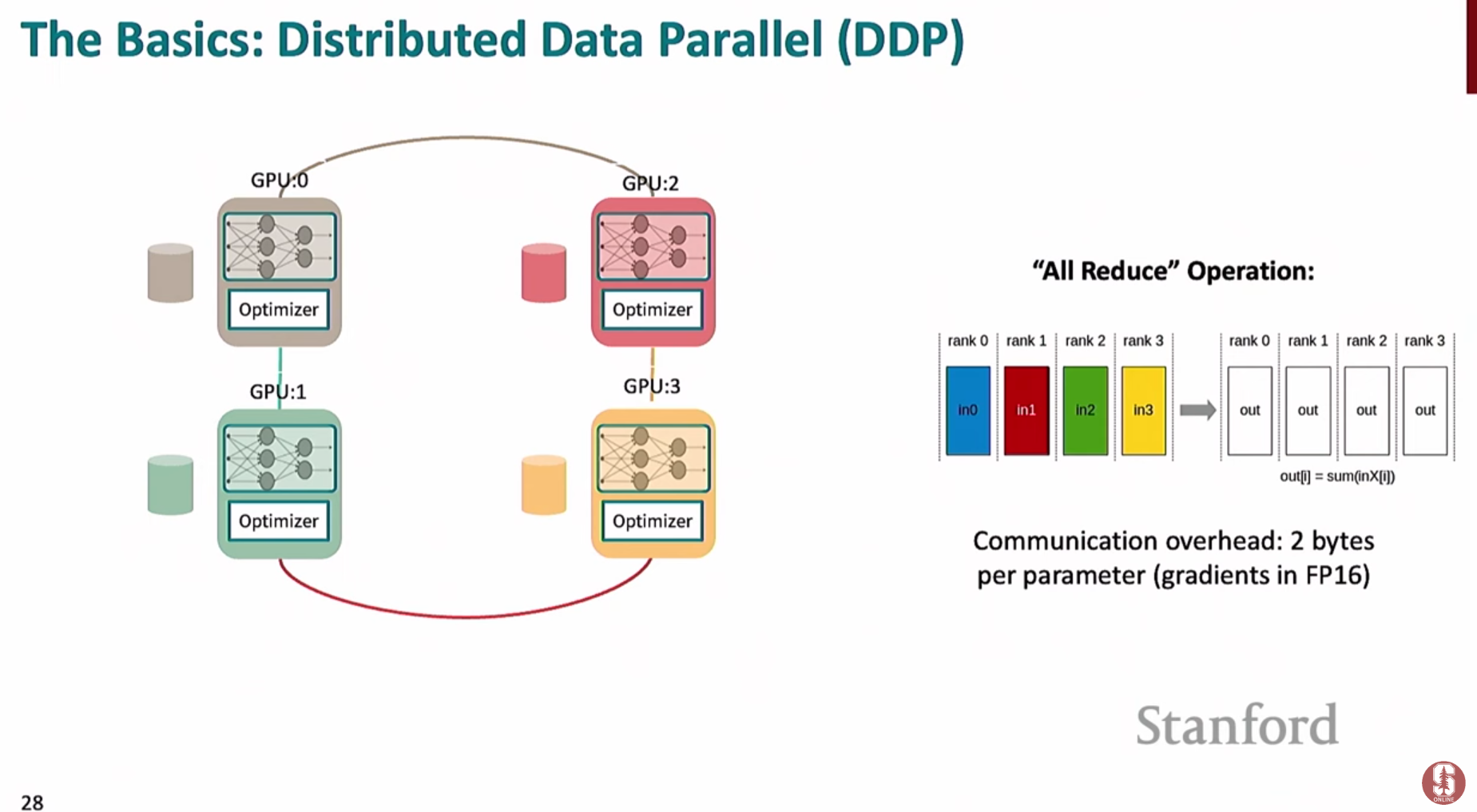
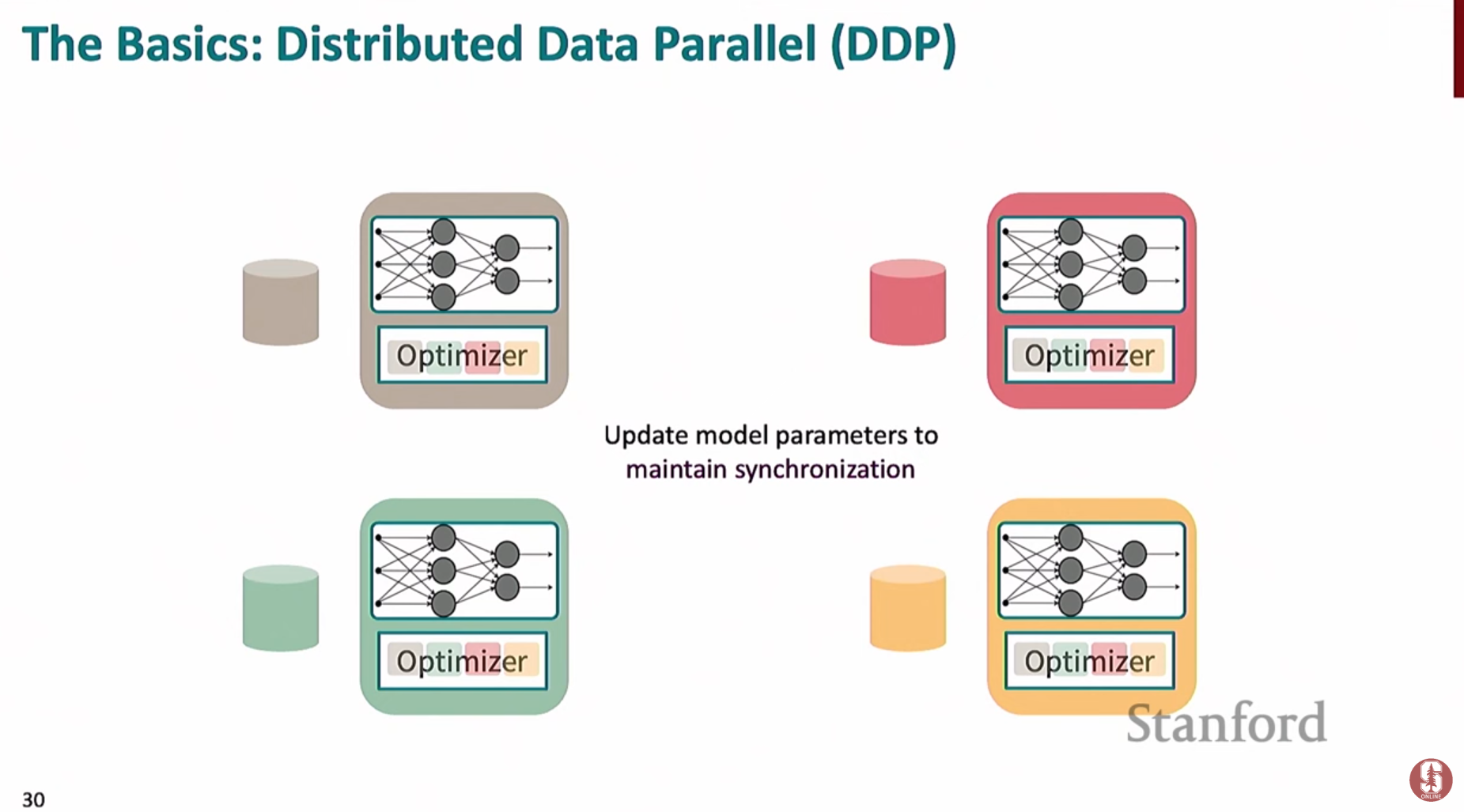
1) 분산 데이터 병렬화 (Distributed Data Parallel, DDP)
- 가장 기본적인 다중 GPU 훈련 방식으로, 전체 데이터셋을 여러 GPU에 나누어(분할) 훈련을 진행합니다.
- 각 GPU는 모델의 완전한 복사본을 가지고 있으며, 각자 맡은 데이터 조각으로 학습하여 기울기를 계산합니다.
**all-reduce**연산을 통해 모든 GPU의 기울기들을 평균 내어 동기화하고, 모든 모델이 동일한 가중치 업데이트를 수행하도록 보장합니다.- 문제점: 모델이 커질수록 각 GPU는 모델 파라미터, 기울기, 옵티마이저 상태를 모두 저장해야 하므로 메모리 효율이 떨어집니다. 예를 들어 Adam 옵티마이저는 파라미터 당 2개의 상태(모멘텀, 분산)를
fp32로 저장하므로 메모리 부담이 큽니다.
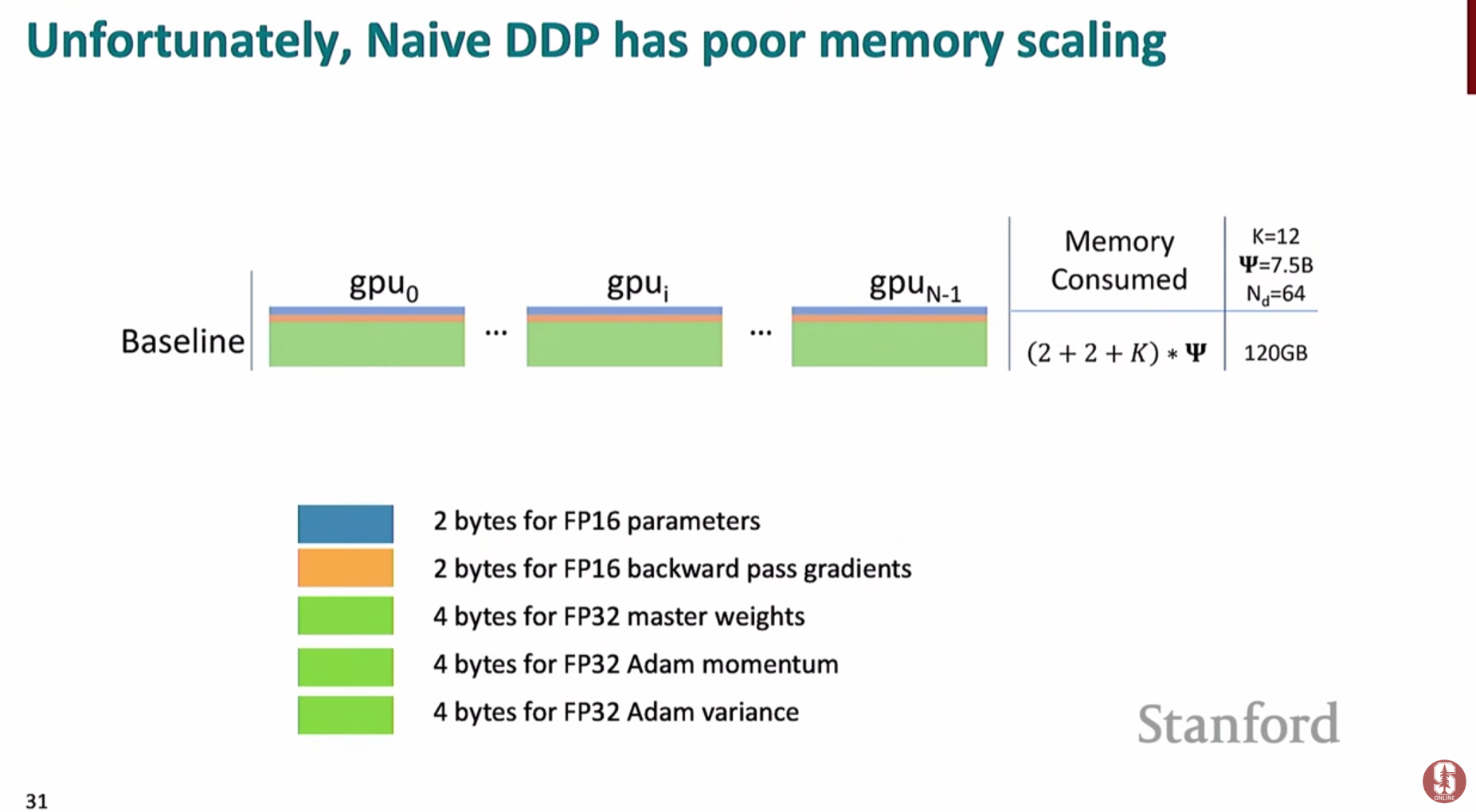
2) Zero Redundancy Optimizer (ZeRO)
-
DDP의 메모리 비효율 문제를 해결하기 위해 Microsoft에서 개발한 최적화 기법입니다. 중복을 제거하여 메모리를 절약하는 것이 핵심 아이디어입니다.
-
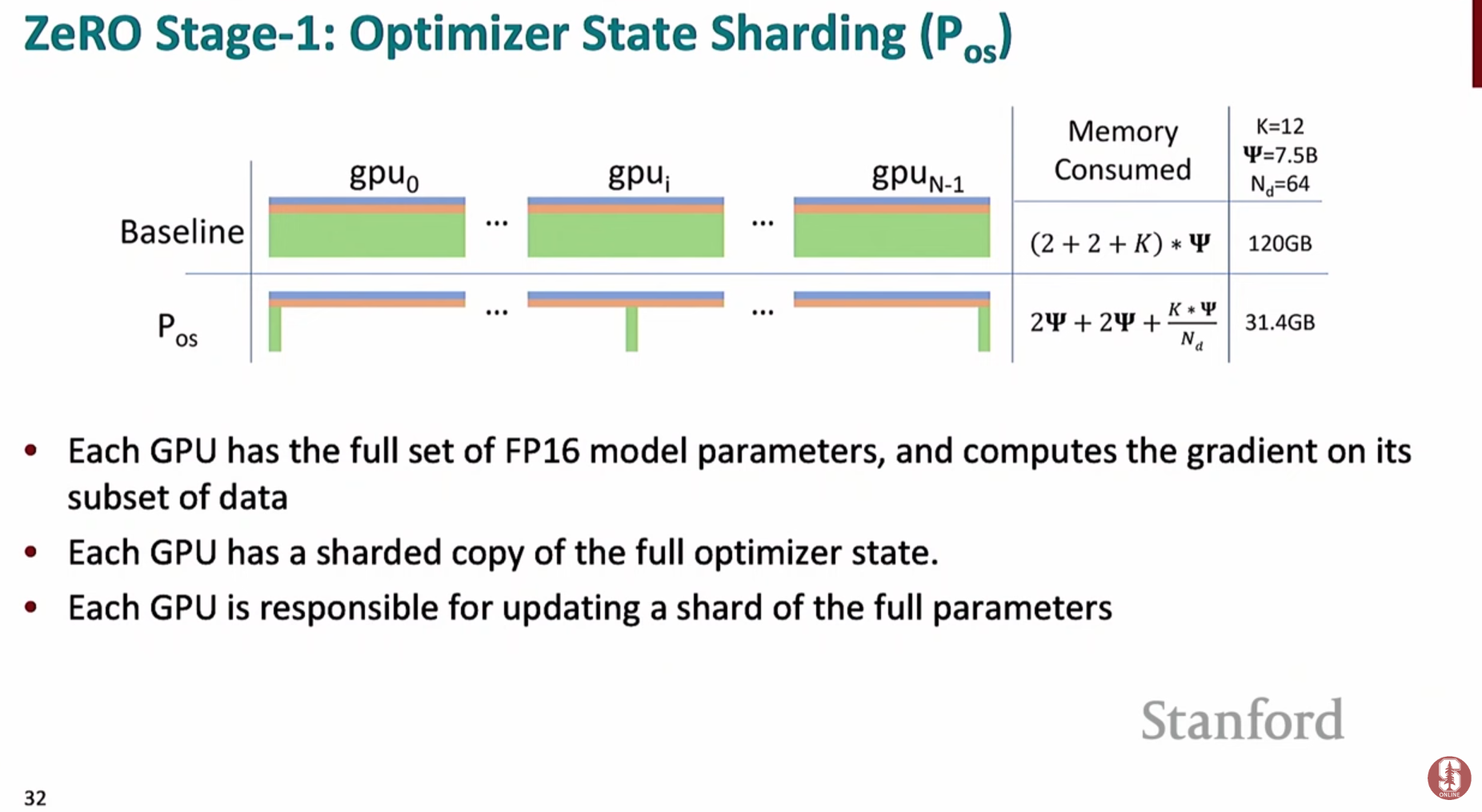
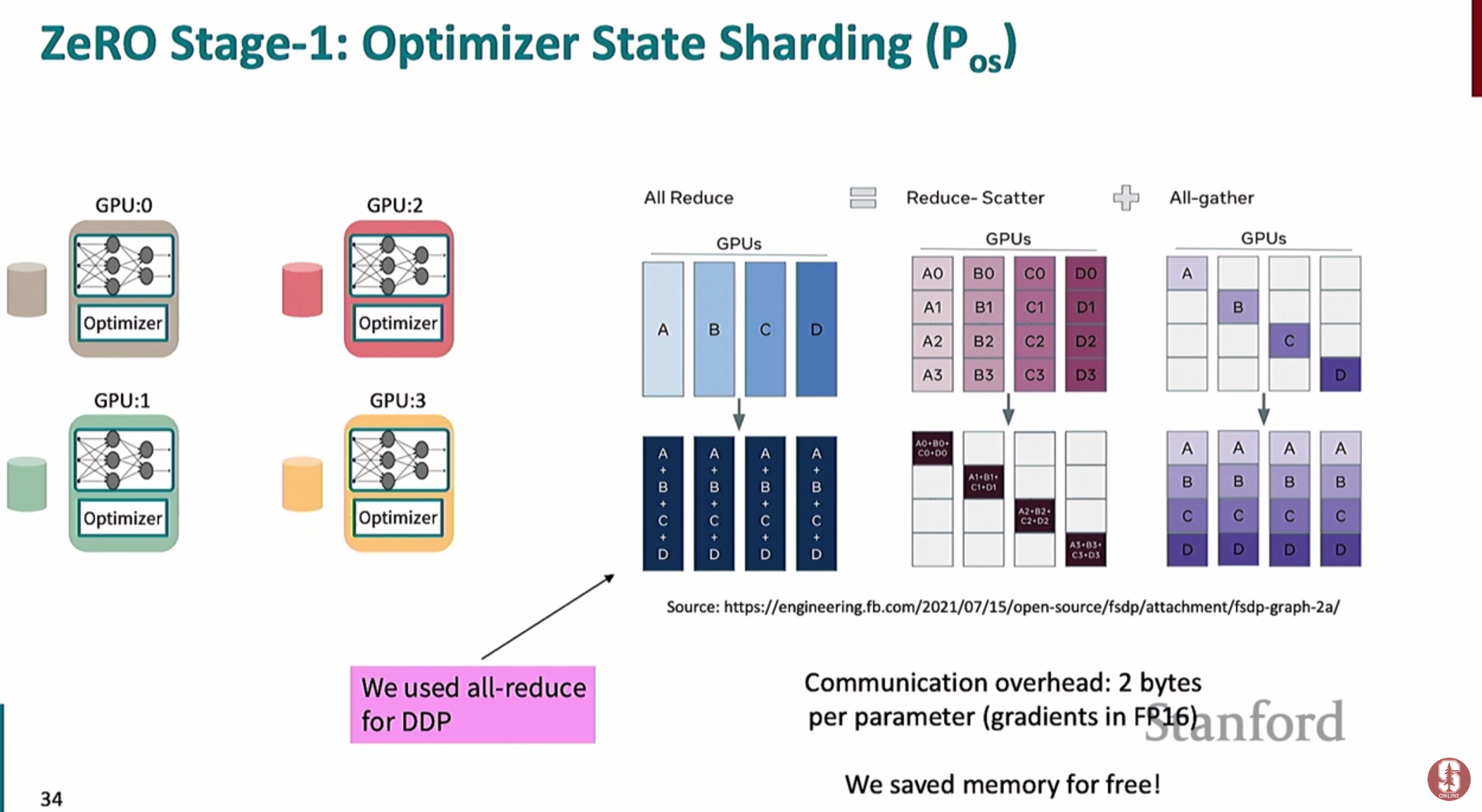
ZeRO 스테이지 1: 옵티마이저 상태(Optimizer States) 샤딩- 각 GPU가 전체 옵티마이저 상태를 복제하여 들고 있는 대신, 이를 여러 GPU에 걸쳐 분할(샤딩)하여 저장합니다.
- 기울기 계산 후
**reduce-scatter**연산을 통해 각 GPU는 자신이 담당하는 옵티마이저 상태에 해당하는 기울기만 받아서 가중치를 업데이트합니다. - 업데이트된 가중치는
**all-gather**연산을 통해 모든 GPU에 다시 동기화됩니다. - DDP와 통신량은 동일하면서도 옵티마이저 상태 저장에 필요한 메모리를 크게 절약할 수 있습니다.
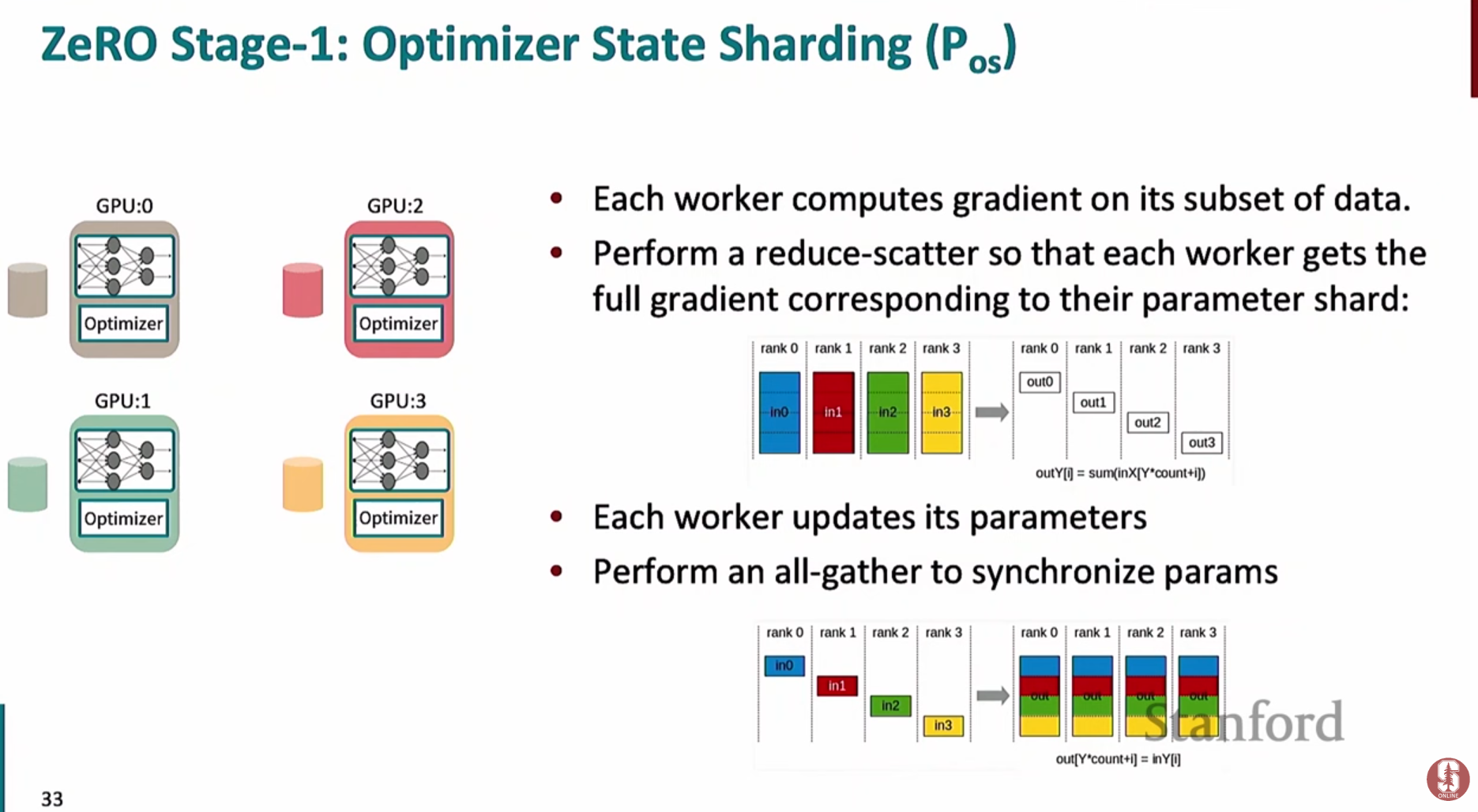
-
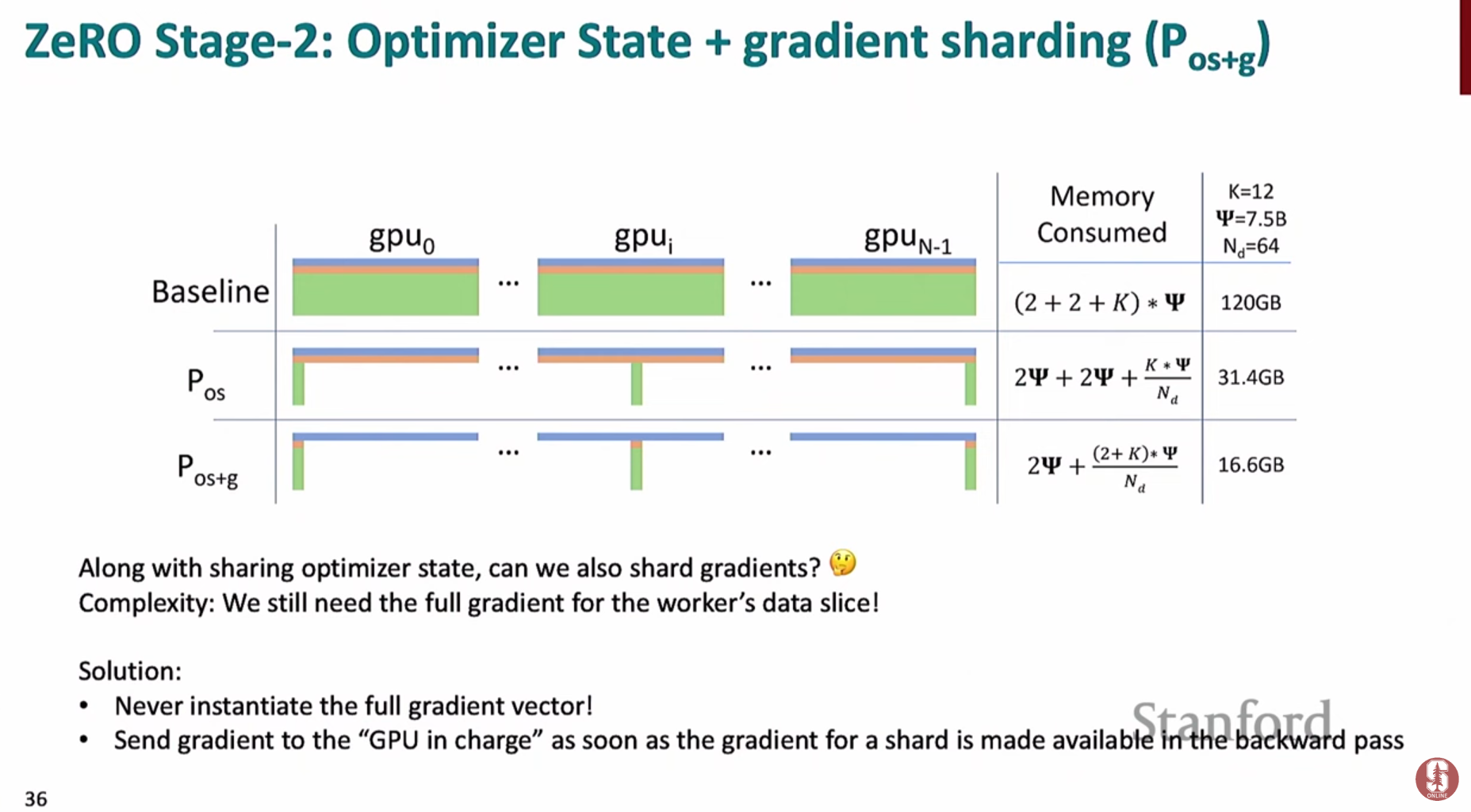
ZeRO 스테이지 2: 기울기(Gradients) 및 옵티마이저 상태 샤딩- 스테이지 1에서 더 나아가, 기울기 자체도 샤딩합니다.
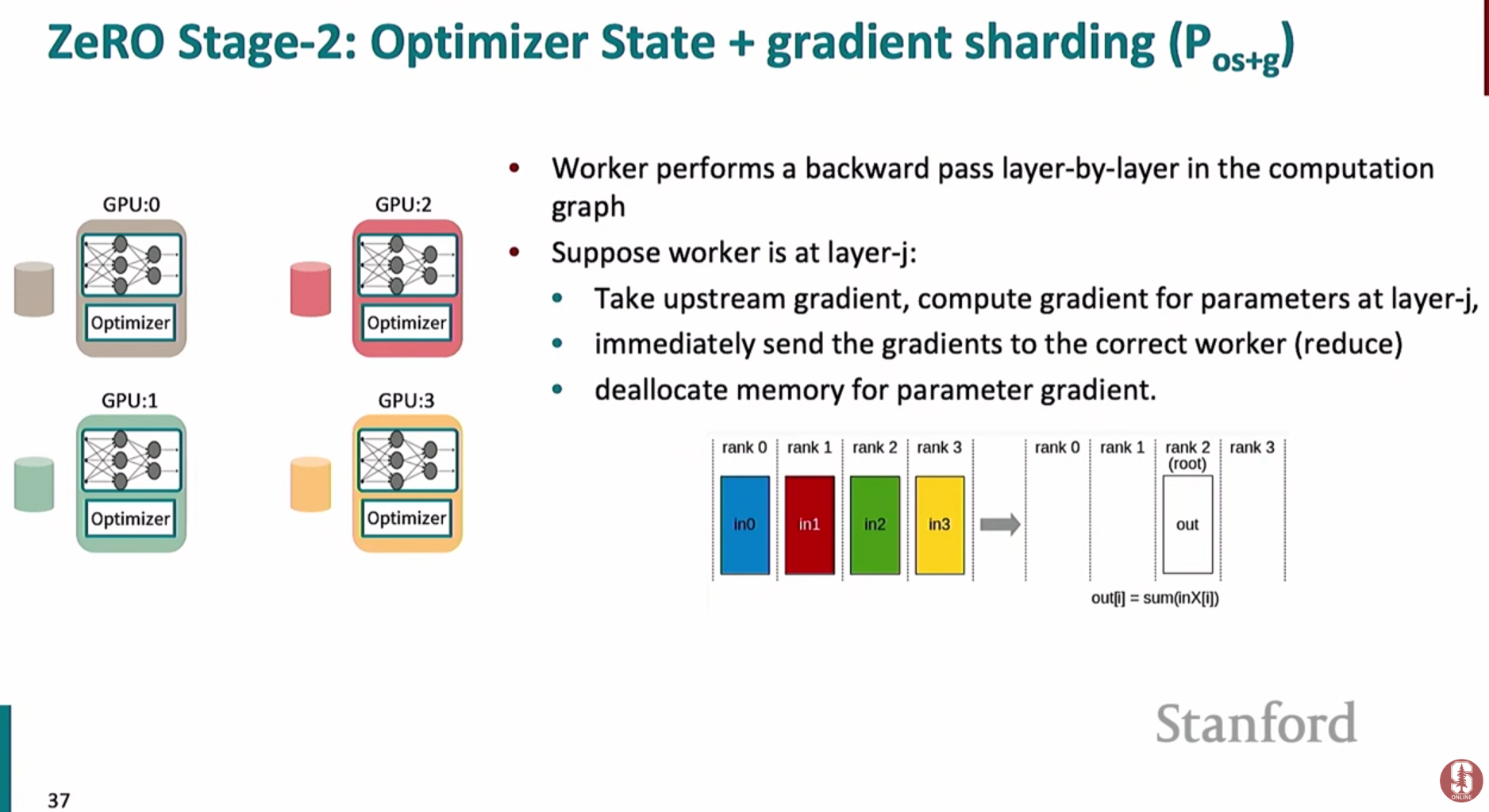
- 역전파 과정에서 기울기가 계산되는 즉시, 해당 파라미터를 책임지는 GPU에게
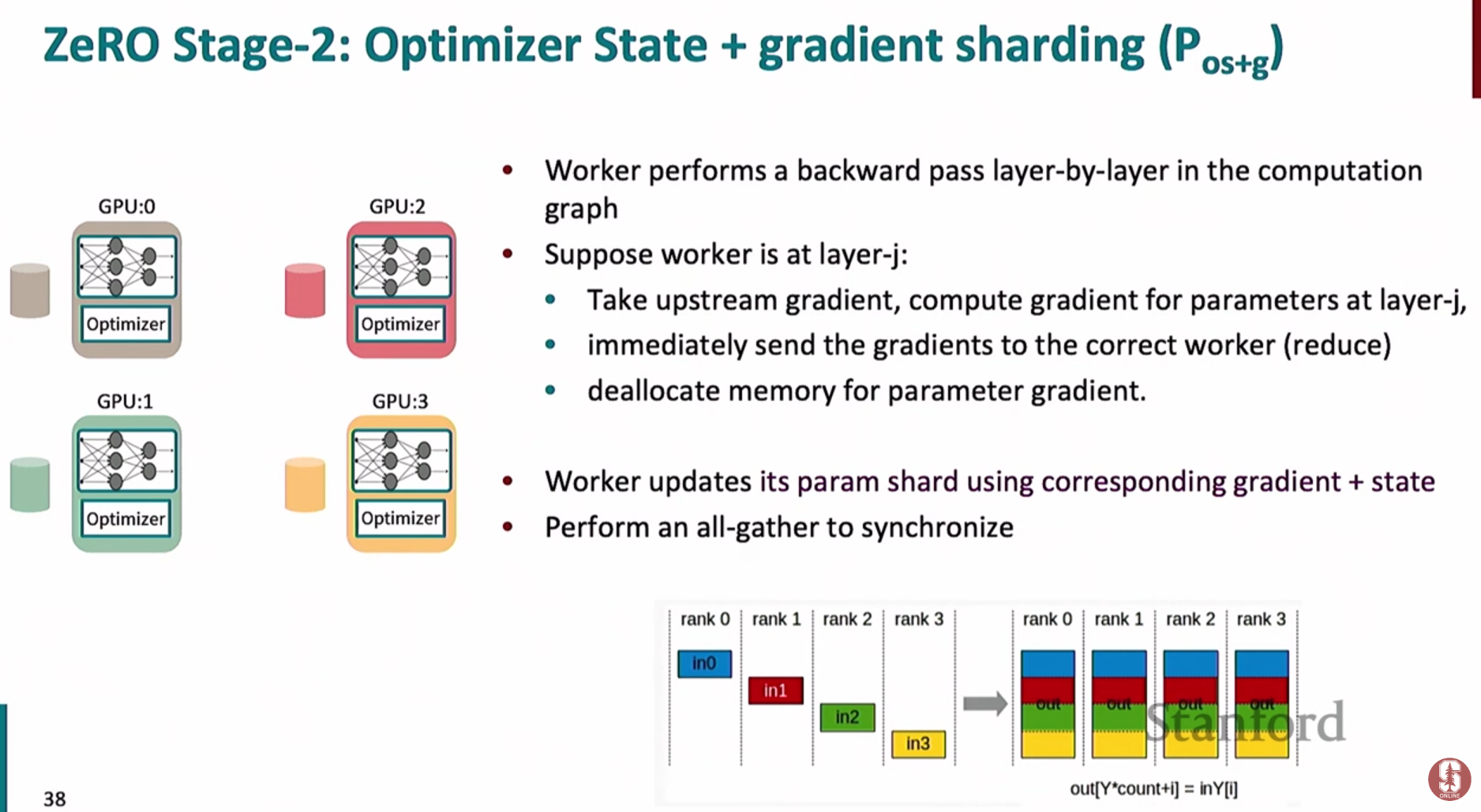
**reduce**연산으로 보내고 메모리에서 해제합니다. - 이를 통해 전체 기울기 벡터를 메모리에 올리지 않아도 되므로 메모리를 추가로 절약할 수 있습니다.
- DDP와 비교하여 추가적인 통신 오버헤드 없이 메모리 효율을 극대화할 수 있어 매우 효과적인 전략입니다.
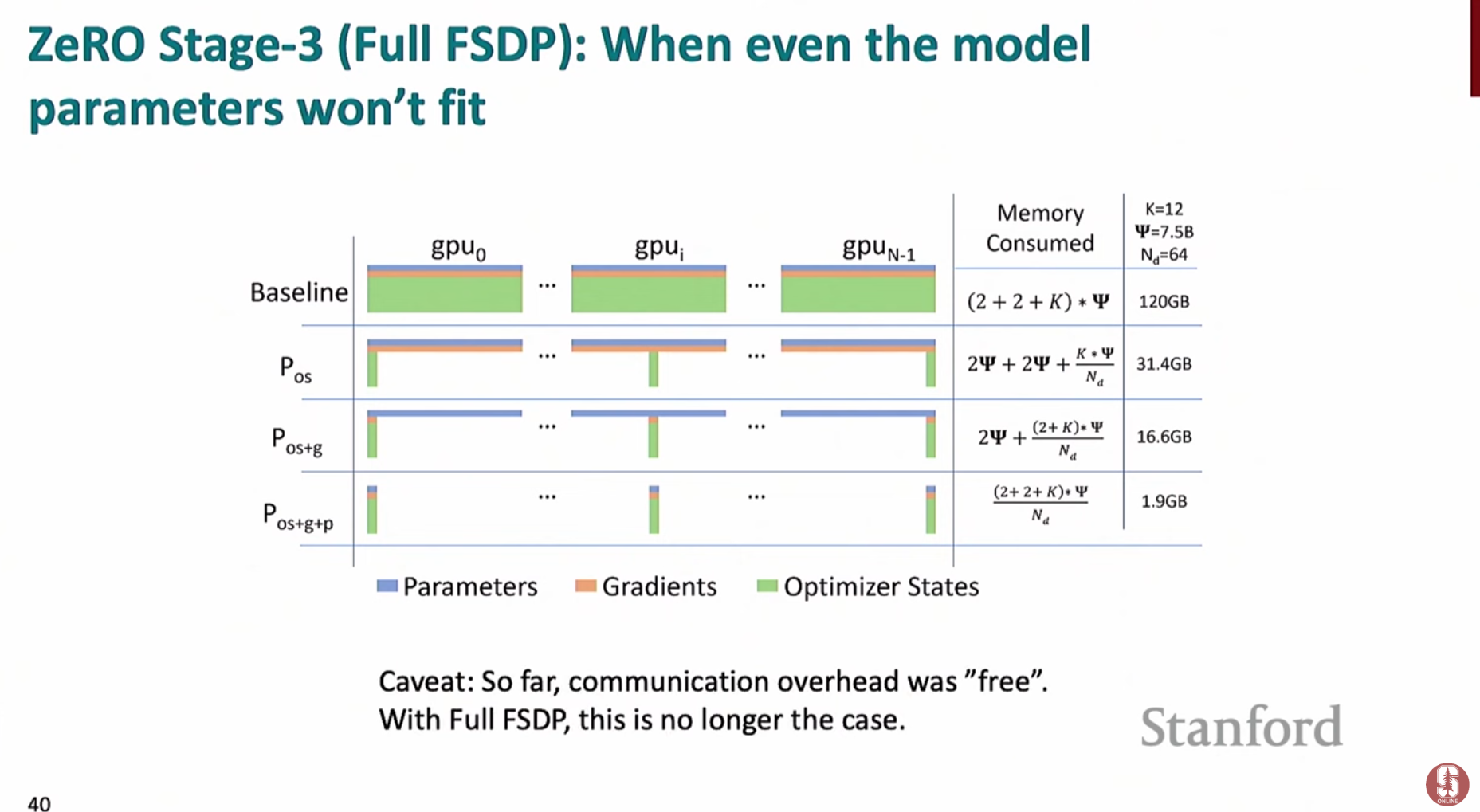
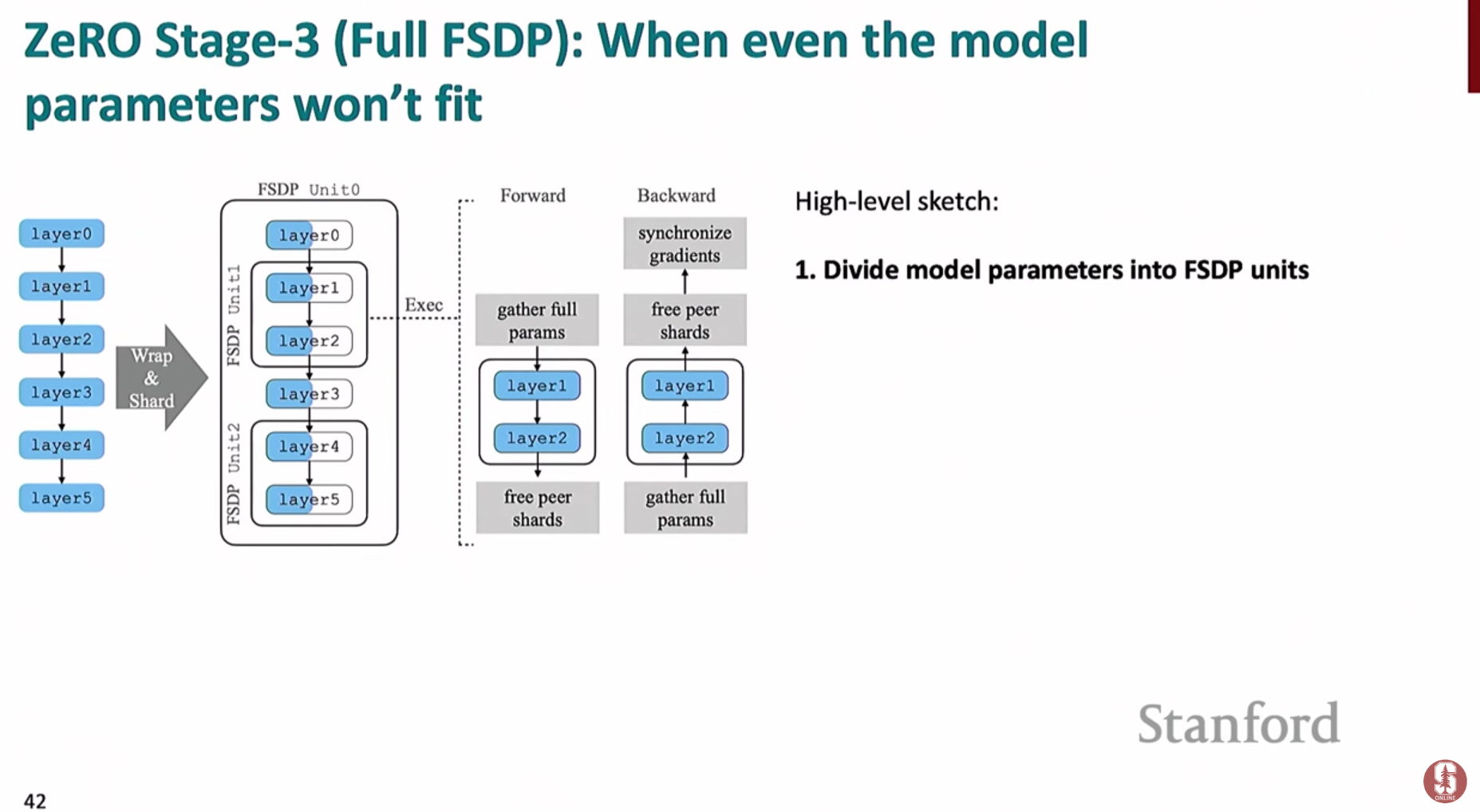
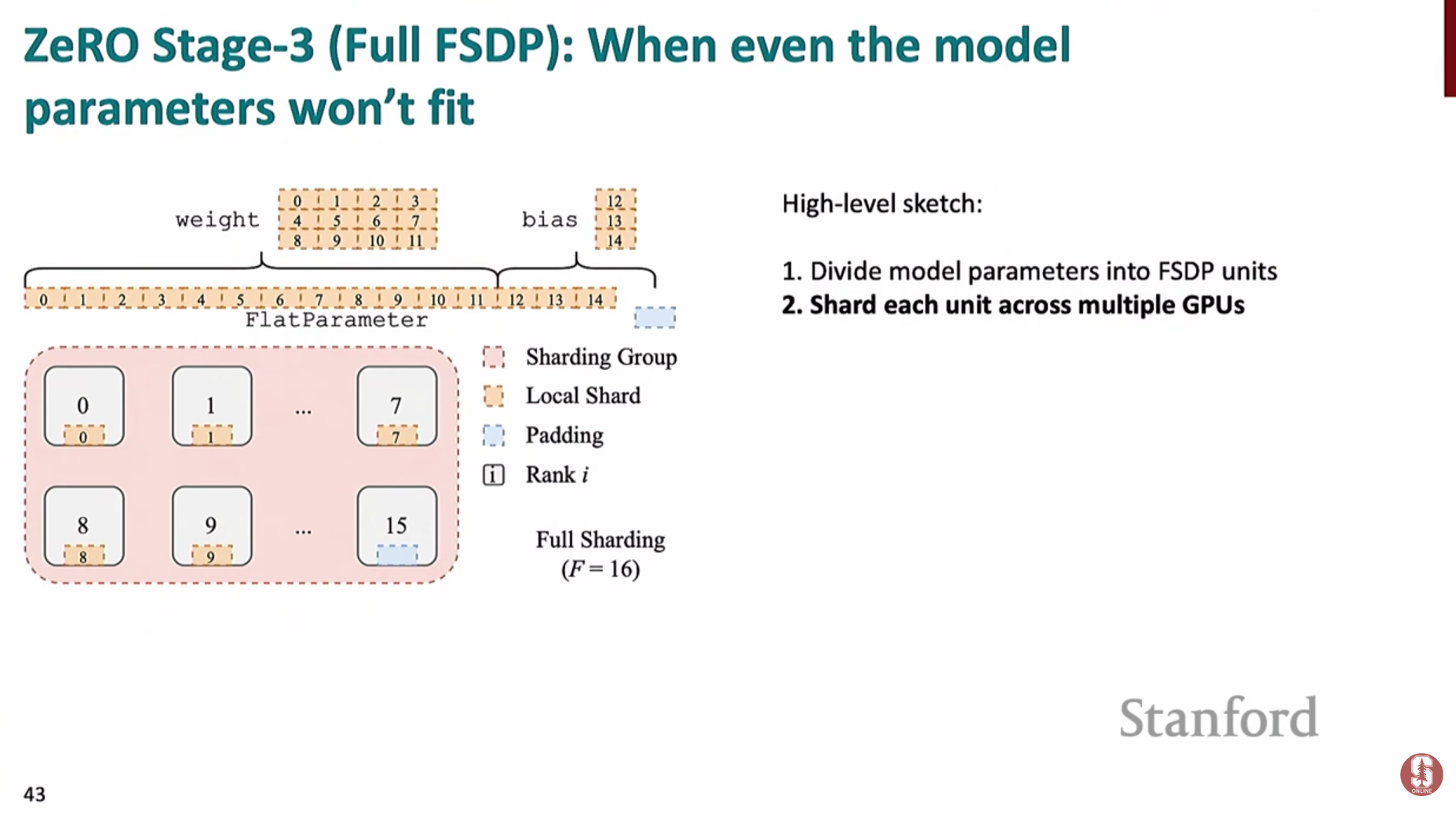
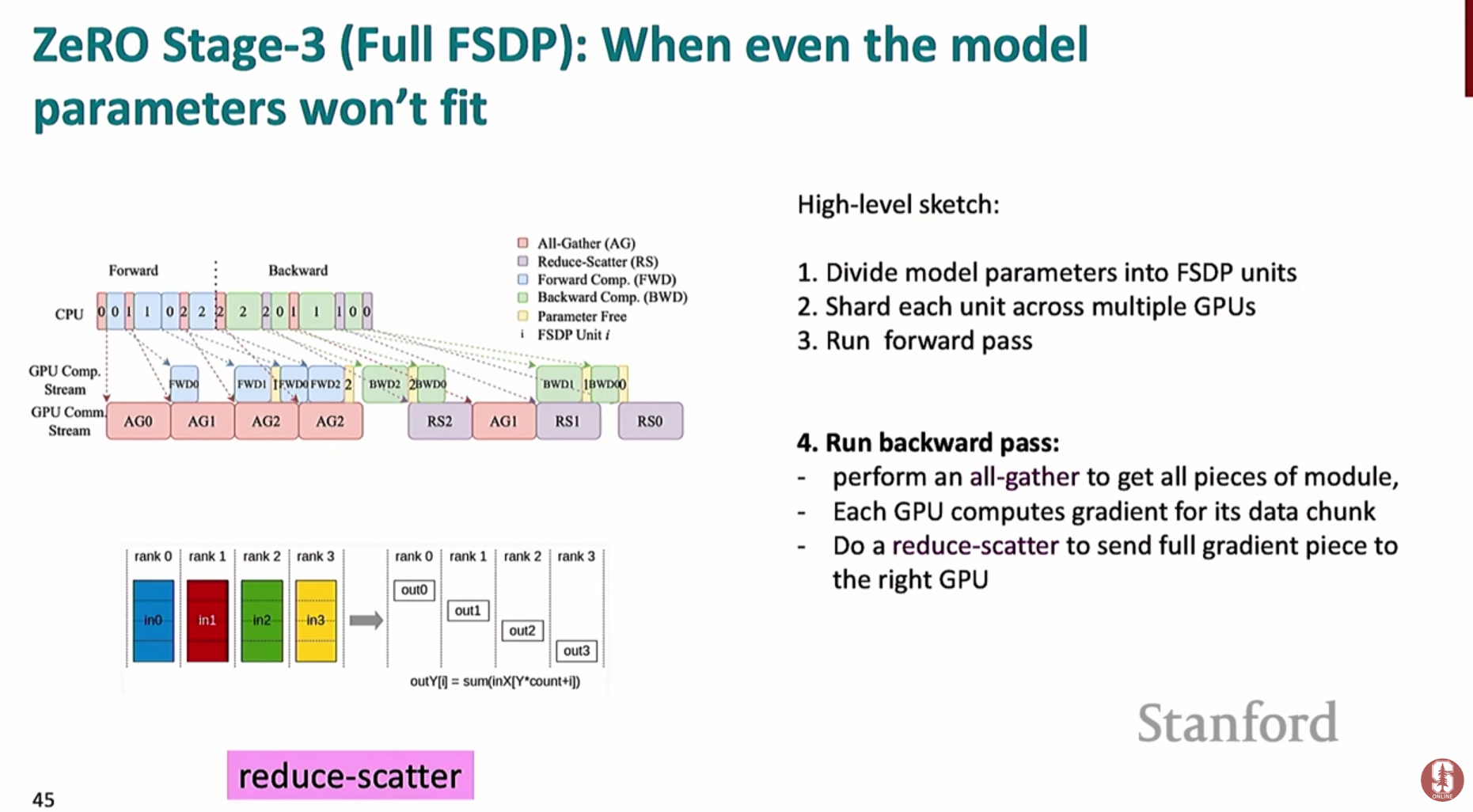
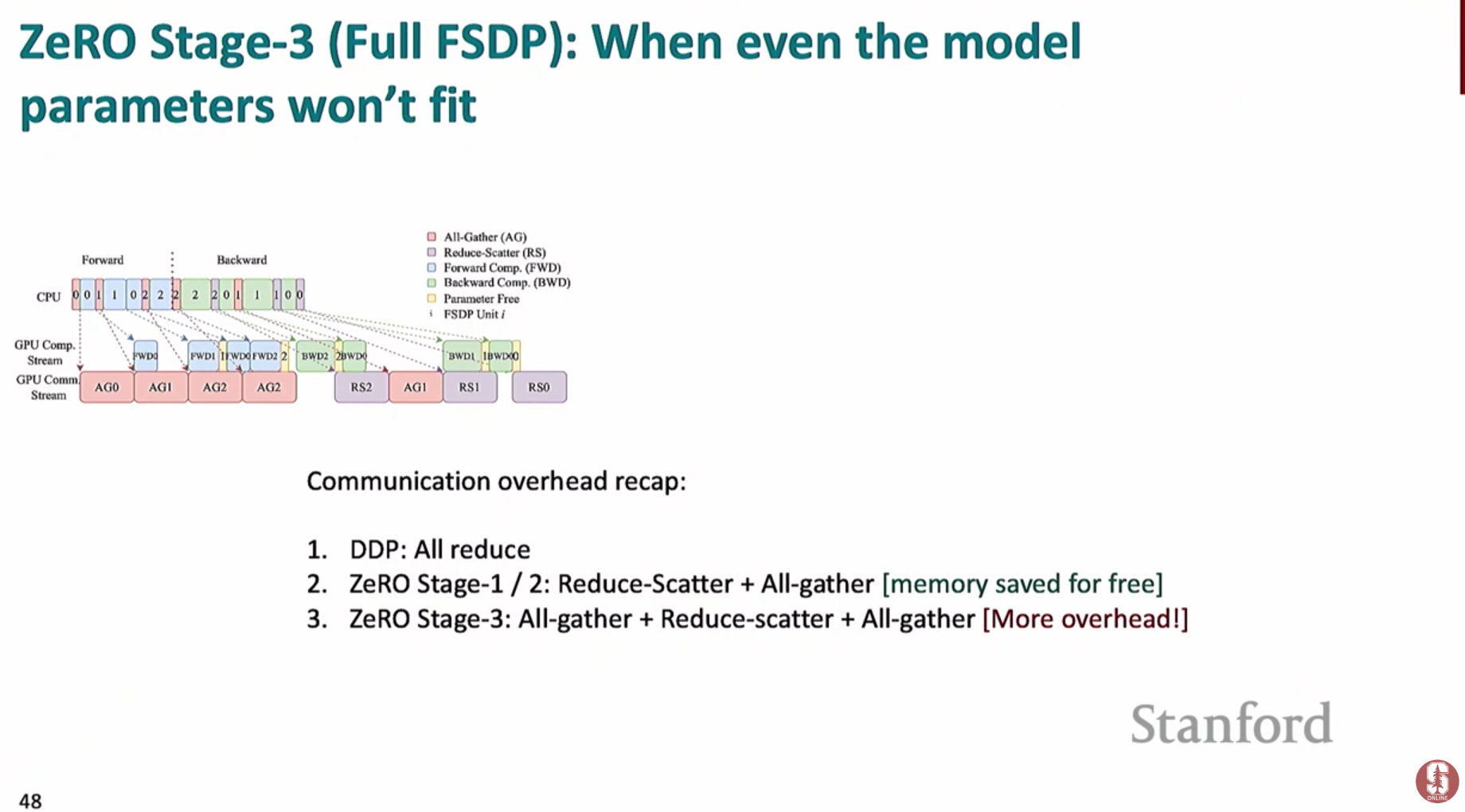
ZeRO 스테이지 3 (FSDP): 모델 파라미터(Model Parameters)까지 모두 샤딩- 모델의 파라미터 자체를 여러 GPU에 분할하여 저장합니다. (PyTorch에서는 FSDP라는 이름으로 구현됨)
- 순전파/역전파 시, 특정 레이어 계산이 필요할 때만
**all-gather**를 통해 해당 레이어의 전체 파라미터를 모든 GPU로 불러옵니다. - 계산이 끝나면 필요 없어진 파라미터는 즉시 메모리에서 해제하여 공간을 확보합니다.
- 통신 오버헤드는 더 크지만, 모델 자체가 단일 GPU 메모리에 올라가지 않을 정도로 거대할 때 유일한 해결책이 될 수 있습니다.


3) 활성화 메모리 (Activation Memory)
- 파라미터, 기울기, 옵티마이저 상태 외에도 활성화(Activations) 값들이 GPU 메모리를 차지합니다. 이는 역전파 시 기울기 계산에 필요하기 때문입니다.
- 활성화 메모리는 배치 크기에 비례하여 커지며, ZeRO 기술로 직접 해결되지 않는 영역입니다.
- 이를 해결하기 위해 기울기 체크포인팅(Gradient Checkpointing) 같은 기법을 사용하여, 활성화 값을 모두 저장하는 대신 필요할 때 재계산하는 방식으로 메모리를 절약할 수 있습니다.

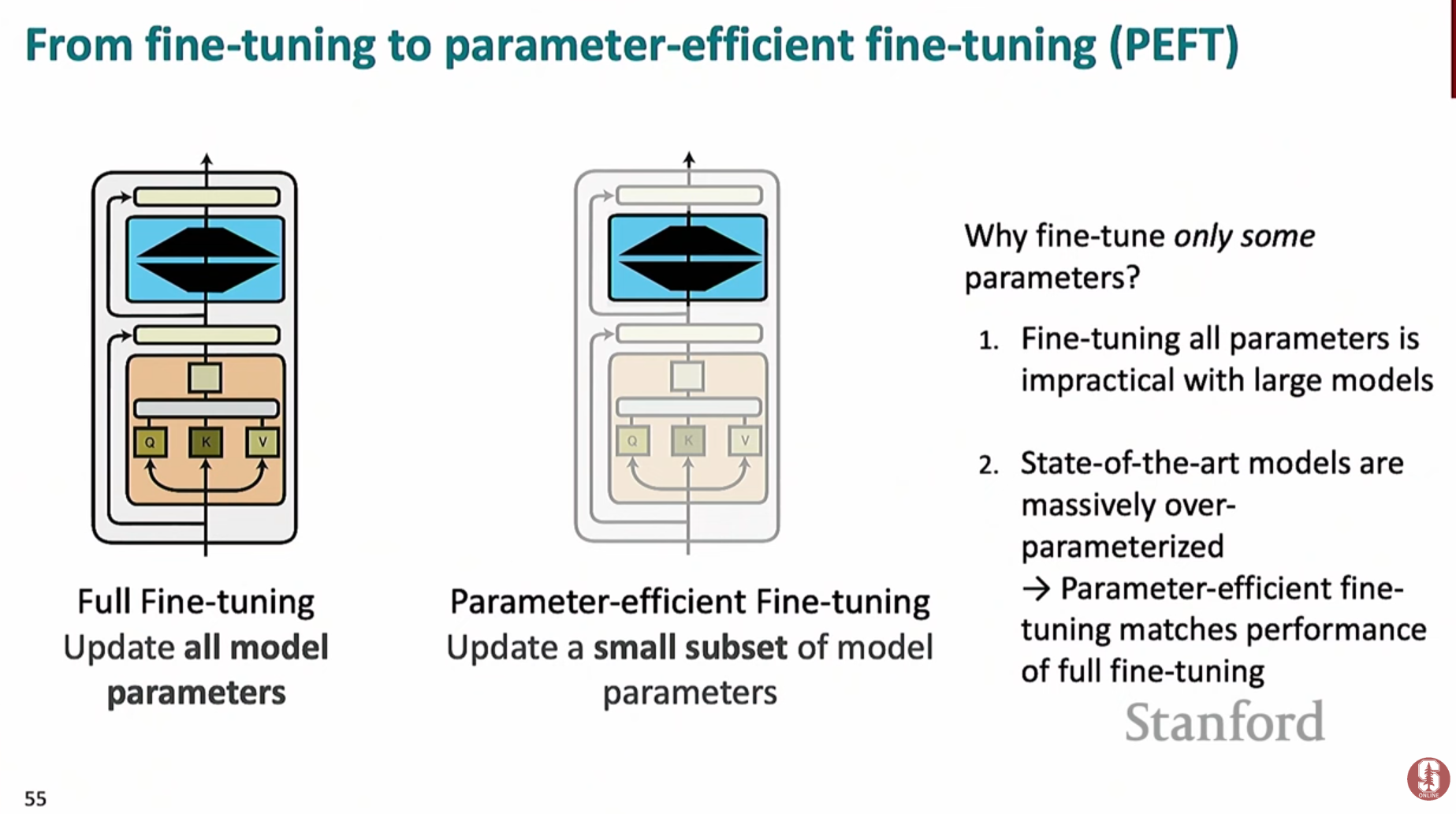
파라미터 효율적 미세조정 (Parameter-Efficient Fine-Tuning, PEFT)
- 수십, 수백억 개의 파라미터를 가진 거대 모델 전체를 미세조정(Fine-tuning)하는 것은 엄청난 계산 비용과 메모리를 요구합니다. PEFT는 이러한 부담을 줄이기 위해 등장했습니다.
1) PEFT의 필요성
- 계산 자원 한계: ZeRO와 같은 기술로도 감당하기 힘든 거대 모델의 등장.
- 저장 공간 문제: 태스크마다 전체 모델 가중치를 저장하는 것은 비효율적입니다.
- 과적합 방지: 적은 데이터로 거대 모델 전체를 학습시키면 과적합(Overfitting) 위험이 큽니다.
- 환경 및 비용 문제: AI 모델 훈련에 드는 막대한 에너지와 비용을 절감할 필요가 있습니다.


2) LoRA (Low-Rank Adaptation)
-
PEFT 기법 중 가장 널리 사용되고 효과적인 방법 중 하나입니다. "사전 훈련된 언어 모델의 가중치 업데이트는 낮은 내재적 차원(Low Intrinsic Rank)을 가진다"는 관찰에서 출발합니다.
-
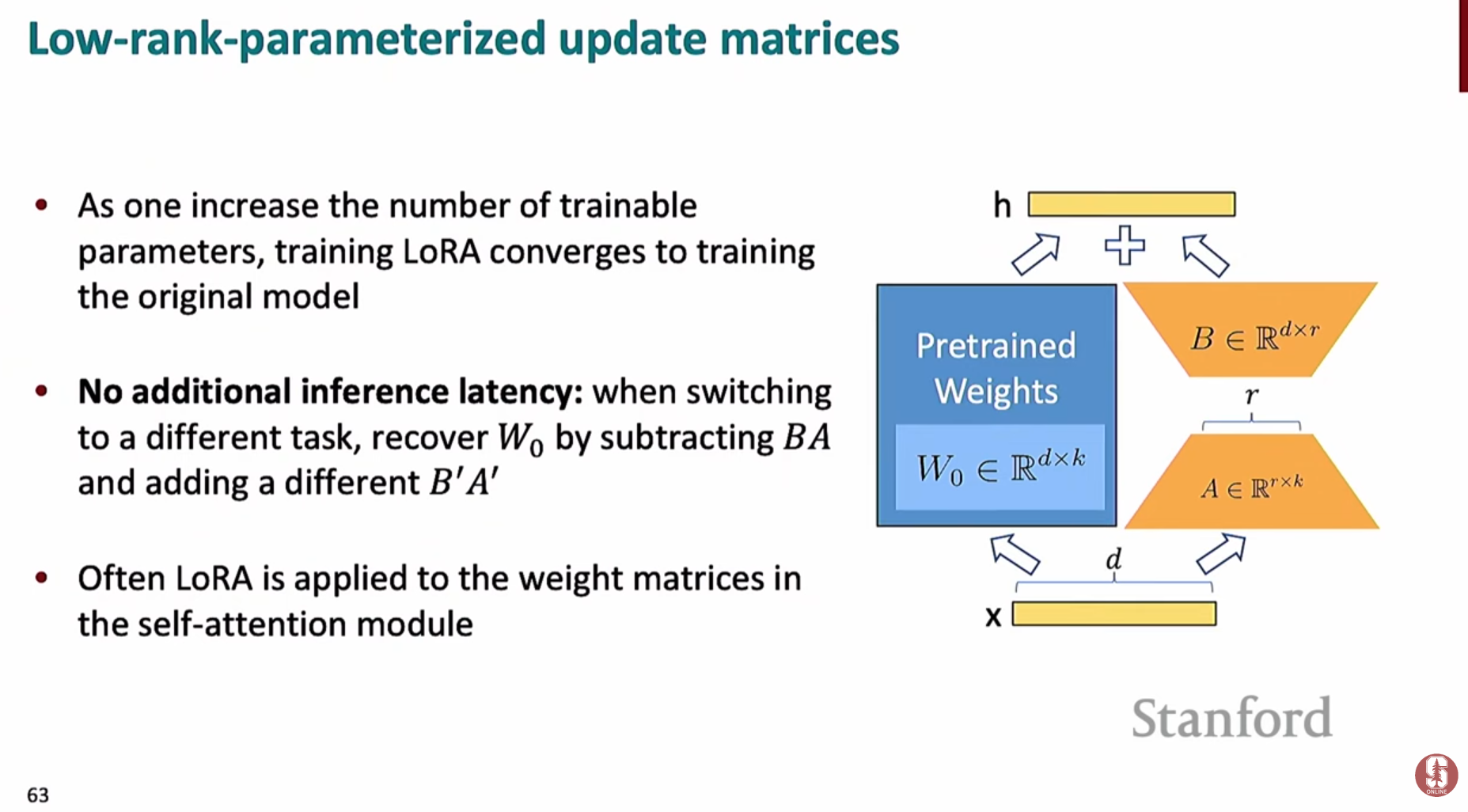
핵심 아이디어: 기존의 사전 훈련된 가중치()는 고정(freeze)시키고, 모델의 각 레이어에 아주 작은 크기의 새로운 학습 가능한 행렬(Adapter)을 추가하여 이 행렬들만 학습시킵니다.
-
수학적 원리:
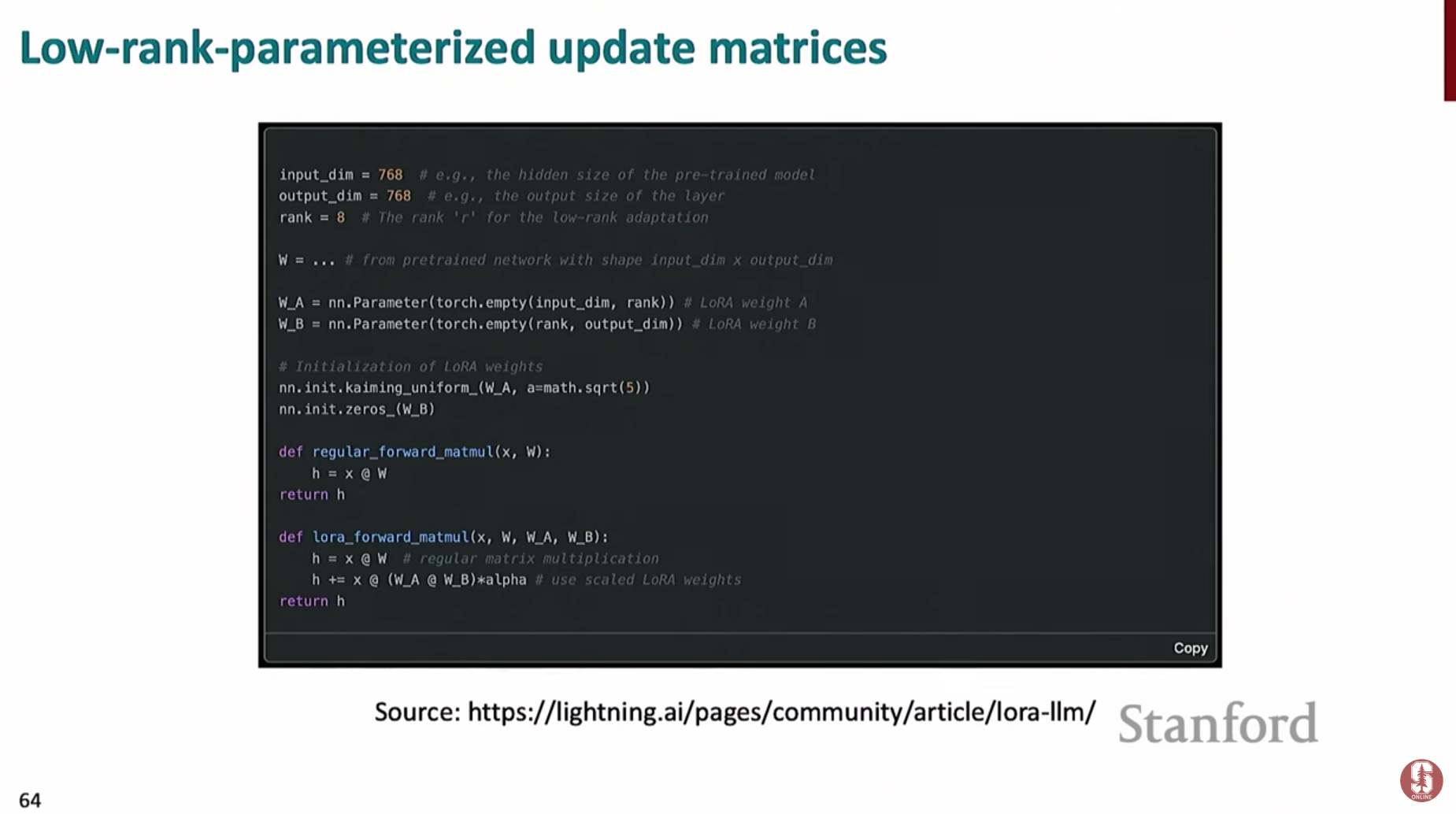
- 모델의 가중치 업데이트 행렬 를 두 개의 작은 행렬 와 의 곱으로 분해하여 근사합니다.
- 여기서 가 행렬일 때, 는 , 는 크기를 가집니다. 이때 이 바로 랭크(Rank)이며, 보통 8이나 16과 같은 아주 작은 값을 사용합니다.
- 따라서, 거대한 전체를 학습하는 대신, 훨씬 적은 파라미터를 가진 와 만 학습하면 되므로 메모리와 계산량이 획기적으로 줄어듭니다.
-
장점:
- 메모리 효율성: 수백억 파라미터 모델도 수십 MB의 어댑터 가중치만 추가로 저장하면 되므로 매우 효율적입니다.
- 추론 속도: 학습이 끝난 후, 학습된 를 기존 가중치 에 더하여 하나의 행렬로 만들 수 있습니다. 따라서 추론 시에는 어떠한 추가 계산이나 지연도 발생하지 않습니다.
- 빠른 전환: 여러 태스크에 대해 각각의 작은 LoRA 어댑터만 저장해두고 필요할 때마다 교체하며 사용할 수 있습니다.

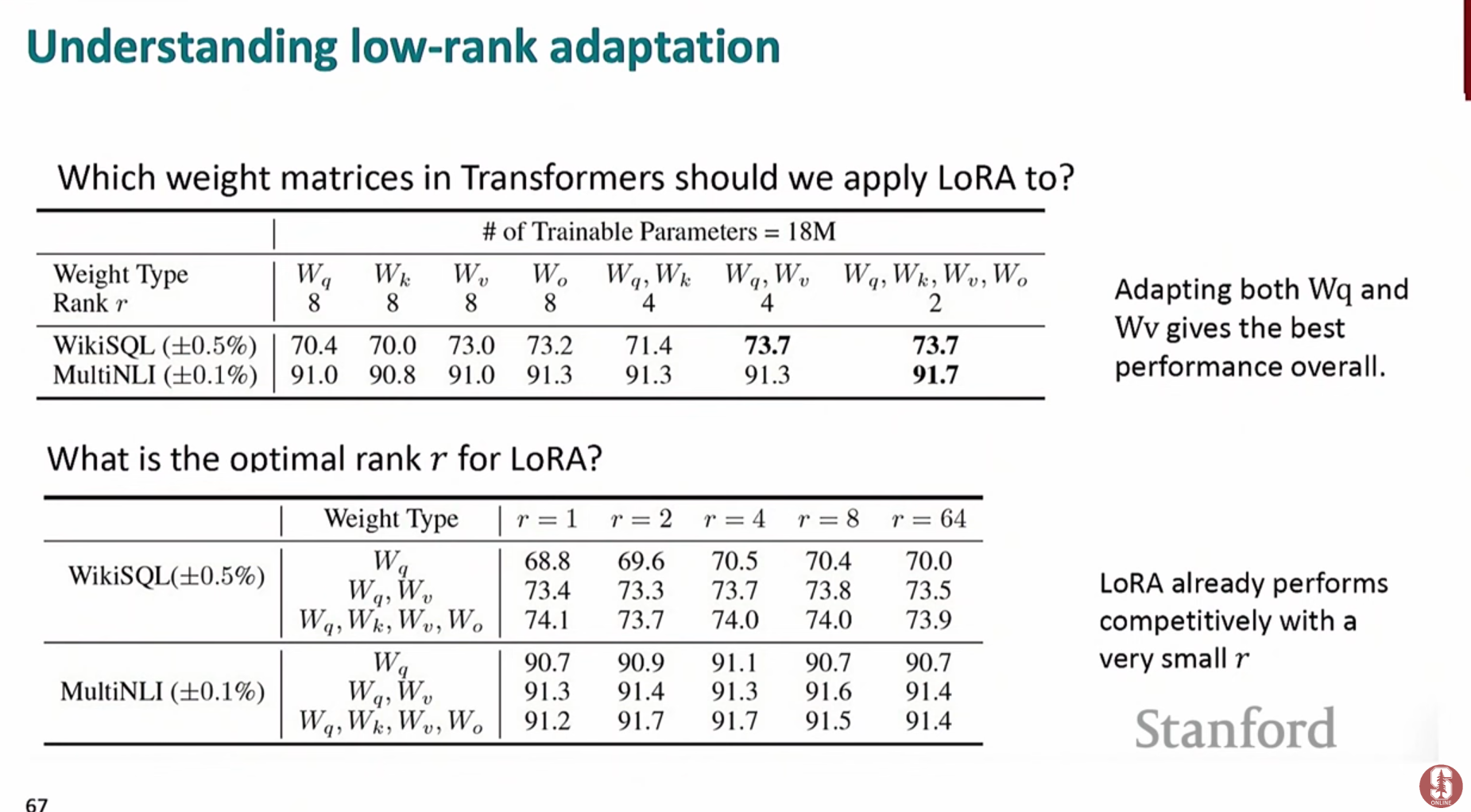
3) 심화 내용: LoRA의 기술적 배경, 최신 동향 및 한계점
- 기술적 배경: LoRA의 핵심은 대규모 모델을 미세조정할 때 필요한 정보의 대부분이 저차원 부분 공간에 집중되어 있다는 가설에 기반합니다. 모든 가중치를 수정하는 것은 중복된 정보를 학습하는 것과 같으므로, 저차원 행렬 분해를 통해 가장 핵심적인 변화만 효율적으로 학습하는 것입니다.
- 최신 동향:
- QLoRA: LoRA를 4비트 양자화(Quantization) 기술과 결합하여 메모리 사용량을 더욱 극한으로 줄인 기법입니다. 이를 통해 더 큰 모델을 더 적은 자원으로 미세조정할 수 있게 되었습니다.
- 다양한 변형: LoRA의 성능을 더욱 끌어올리기 위해 랭크를 동적으로 조절하거나(DyLoRA), 여러 LoRA 어댑터를 합치는(Merging) 등 다양한 연구가 활발히 진행되고 있습니다.
- 적용 분야 확장: 자연어 처리를 넘어 컴퓨터 비전, 음성 인식 등 다양한 분야의 거대 모델에 LoRA가 성공적으로 적용되고 있습니다.
- 명확한 한계점:
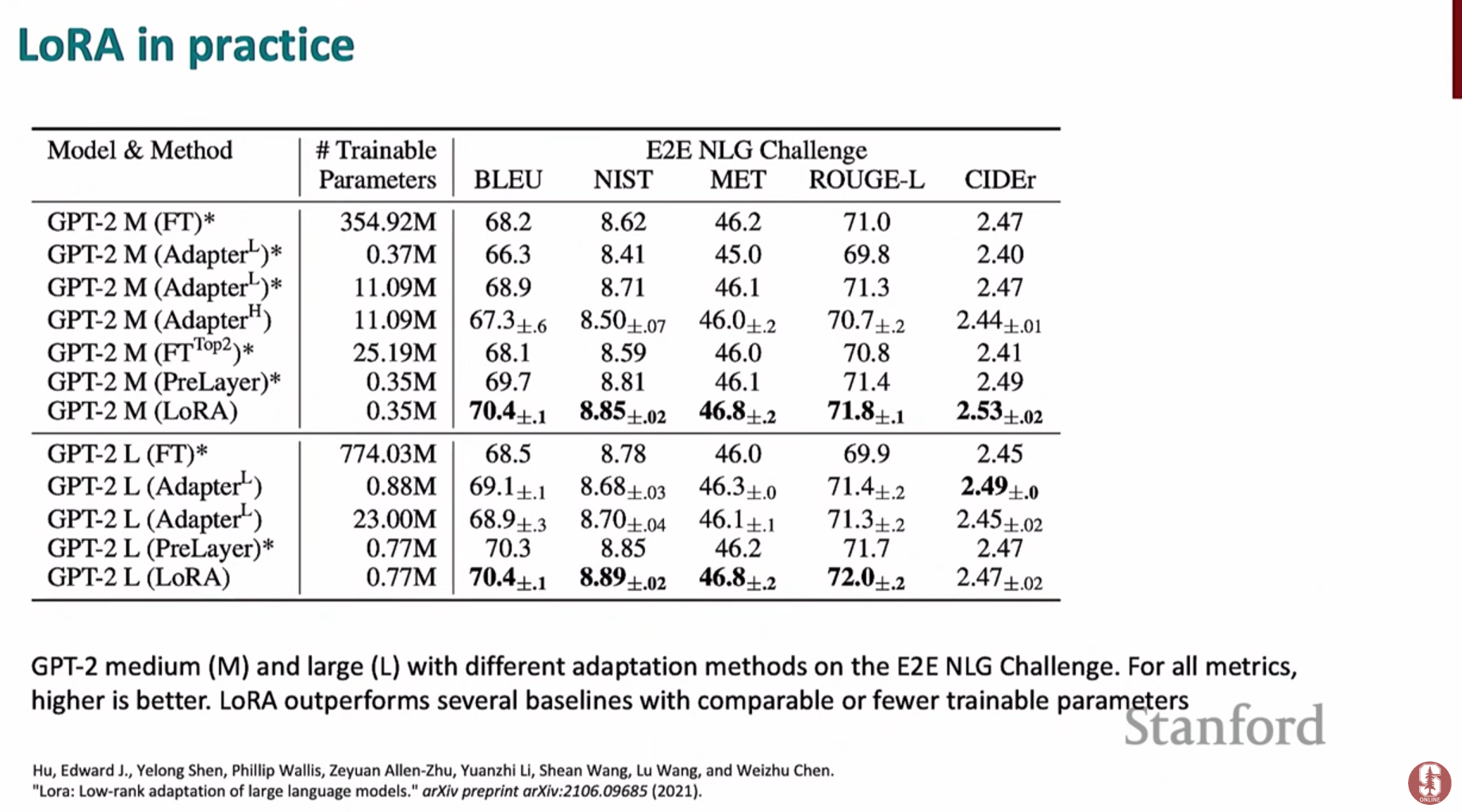
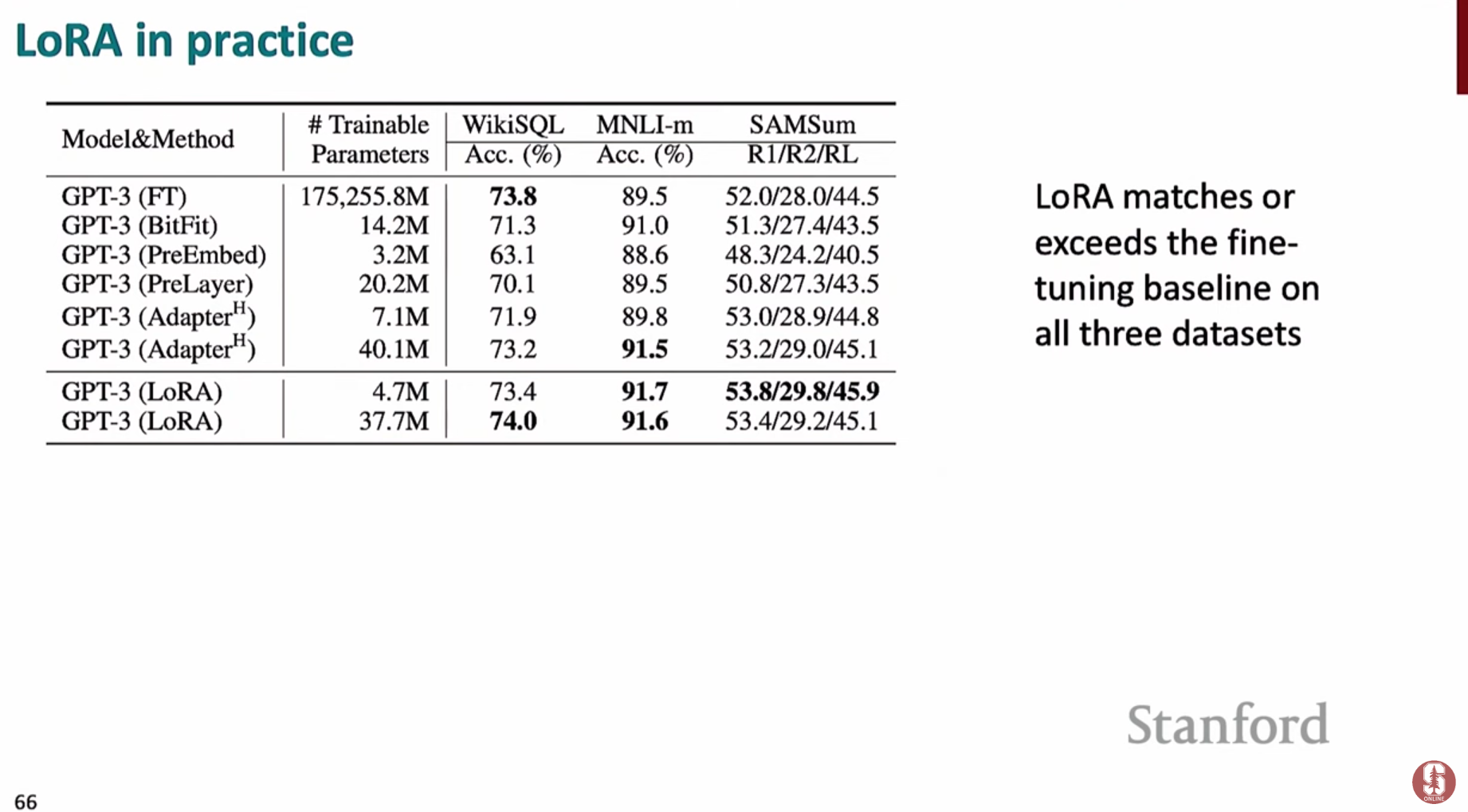
- 성능 저하 가능성: 대부분의 경우 전체 미세조정과 비슷한 성능을 내지만, 일부 복잡한 태스크에서는 성능이 약간 떨어질 수 있습니다. 이는 학습 가능한 파라미터 수를 제한하는 데서 오는 본질적인 트레이드오프입니다.
- 하이퍼파라미터 민감성: 랭크()나 스케일링 값()과 같은 하이퍼파라미터를 어떻게 설정하느냐에 따라 성능이 달라질 수 있어, 최적의 값을 찾는 조정 과정이 필요합니다.
- 적용 위치: 모델의 모든 레이어에 LoRA를 적용하는 것보다, 주로 어텐션 메커니즘의 쿼리(Query)와 값(Value) 가중치 행렬에 적용했을 때 가장 효율적이고 좋은 성능을 보이는 것으로 알려져 있습니다.
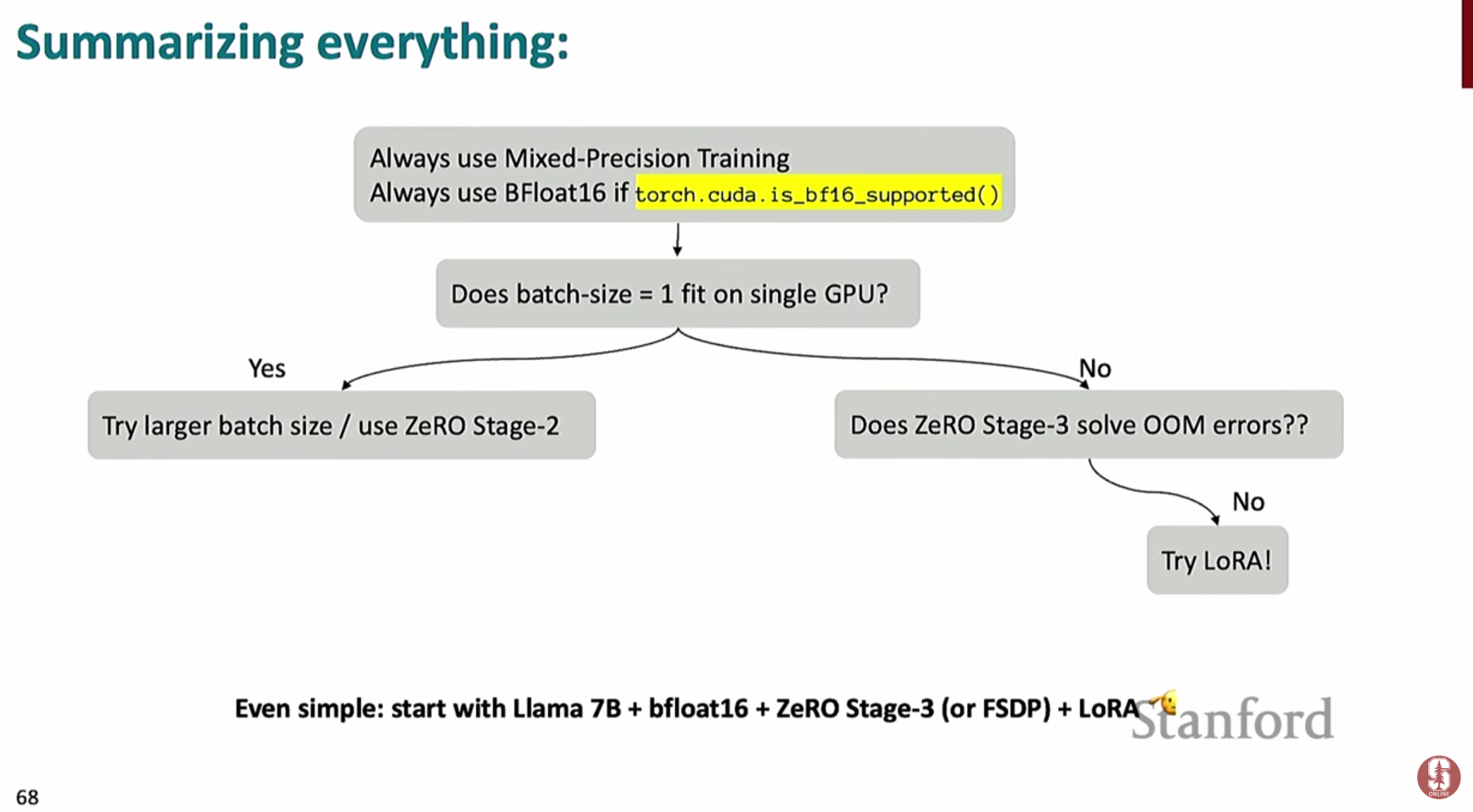
최종 훈련 전략 권장 흐름도
- 강의 내용을 바탕으로, 대규모 모델을 훈련할 때 시도해볼 수 있는 최적의 전략 흐름도입니다.
1) 1단계: 기본 설정
- 혼합 정밀도 훈련은 항상 사용합니다. 최신 GPU라면
BF16을, 아니라면fp16과 기울기 스케일링을 사용하세요.
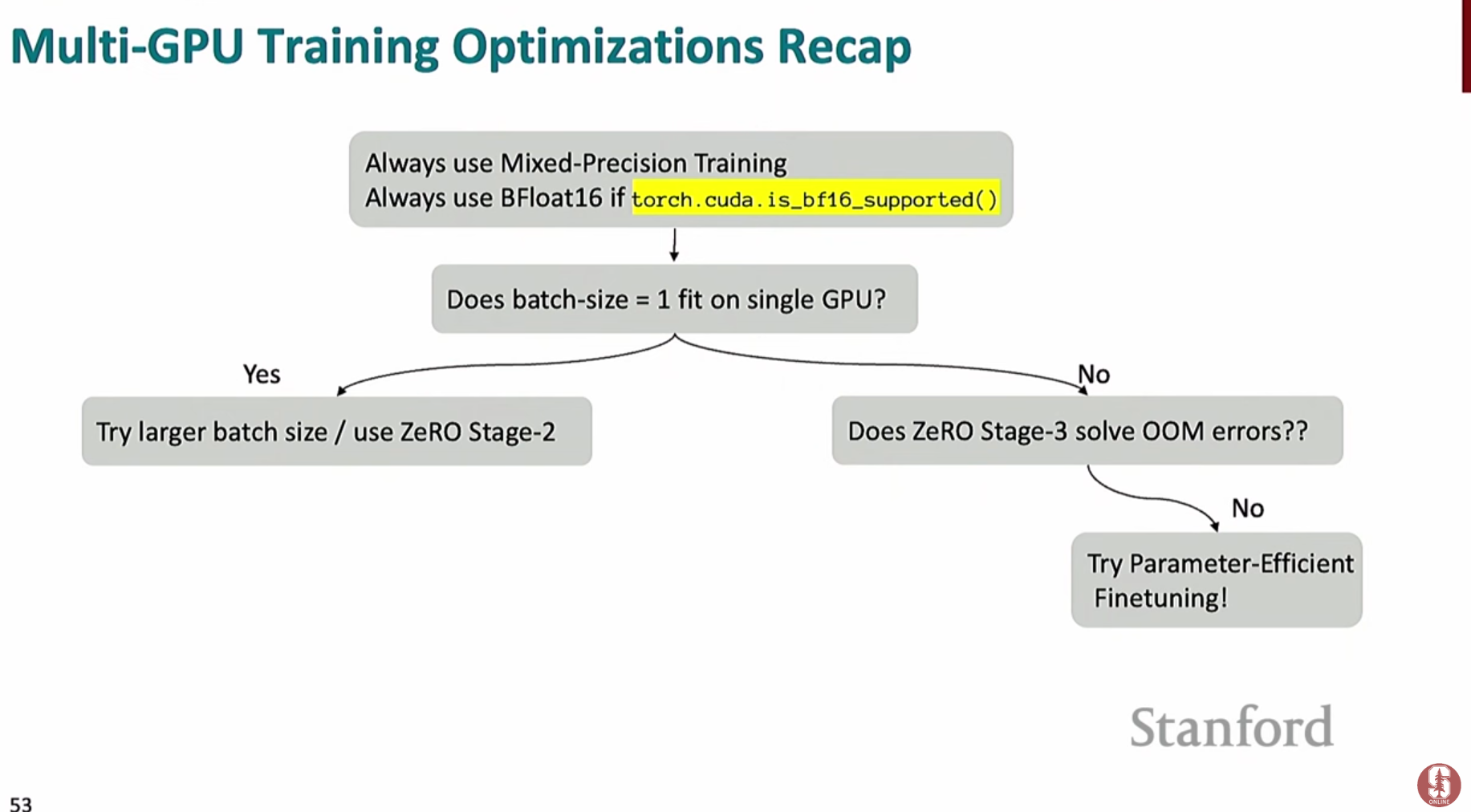
2) 2단계: 단일 GPU 메모리 확인
- 배치 크기를 1로 설정했을 때, 모델이 단일 GPU 메모리에 올라가는지 확인합니다.
- 메모리에 맞는 경우: 훈련 속도를 높이기 위해 배치 크기를 늘리고, 메모리 절약을 위해
ZeRO 스테이지 2를 적용하는 것이 가장 효율적입니다. - 메모리에 맞지 않는 경우: 모델이 너무 커서 단일 GPU에 적재되지 않는 상황입니다. 이 경우
ZeRO 스테이지 3 (FSDP)를 사용해야 합니다. 그래도 메모리가 부족하다면 기울기/활성화 체크포인팅을 추가로 적용합니다.
- 메모리에 맞는 경우: 훈련 속도를 높이기 위해 배치 크기를 늘리고, 메모리 절약을 위해
3) 3단계: 최후의 수단, LoRA
- 위의 모든 방법을 시도했음에도 메모리 부족 문제가 해결되지 않거나, 더 효율적인 미세조정을 원한다면 **
LoRA**를 적용합니다. LoRA를 시작할 때 추천하는 하이퍼파라미터 설정은 다음과 같습니다.- 적용 위치: 어텐션의 Query, Value 행렬
- 랭크 (R): 8
- 알파 (): 1

AI 공부합니다