1. BCI의 필요성: '갇힌 사람들'을 위한 희망
1) BCI 개발의 동기
- 하워드의 사례: 21세에 심각한 뇌졸중으로 인해 '갇힌 상태(locked-in state)'가 된 하워드는 움직이거나 말할 수 없게 되었어요. 뇌 기능은 정상이지만, 자신을 표현할 방법이 없는 것이죠. BCI는 이처럼 신체에 갇힌 사람들이 세상과 다시 소통할 수 있도록 돕기 위해 개발되기 시작했습니다.
2) 기존 보조 통신 장치의 한계
- 글자판 (Letter Board): 눈의 움직임으로 글자를 하나씩 선택하는 방식은 매우 느려서 한 문장을 만드는 데 몇 분씩 걸릴 수 있습니다.
- 시선 추적 장치 (Eye-Tracking Device): 가상 키보드를 계속 응시해야 해서 눈이 쉽게 피로해지고, 눈의 움직임조차 어려운 환자에게는 사용이 불가능합니다.
- 뉴럴링크 (Neuralink): 최근 주목받는 뉴럴링크는 뇌에 작은 장치를 이식하여 뇌 신호를 직접 해독하고, 이를 통해 컴퓨터나 로봇 팔 등을 제어하는 것을 목표로 합니다. 이는 기존 장치의 한계를 뛰어넘는 혁신적인 접근 방식입니다.
2. BCI의 역사: 뇌의 전기 신호를 발견하다
1) 뇌 활동과 전기 신호의 발견
- 19세기 리처드 케이턴 (Richard Caton): 동물의 뇌에서 전기 활동을 처음으로 측정했고, 동물의 행동에 따라 전기 신호가 변한다는 사실을 발견하여 BCI의 기초를 마련했습니다.
- 1924년 한스 베르거 (Hans Berger)와 EEG: 뇌전도(EEG)를 발명하여 두피에서 뇌파를 측정하는 데 성공했습니다. 그는 사람의 상태(안정, 인지 활동 등)에 따라 알파파, 베타파 등 뇌파의 주파수가 달라지는 것을 발견했죠. 흥미롭게도 텔레파시에 대한 개인적인 관심이 연구의 동기가 되었다고 합니다.
- EEG를 이용한 음악 연주: 1950년대에는 음악가들이 EEG 장치를 활용해 뇌파로 음악을 연주하는 실험을 진행하며, 뇌를 외부 장치에 직접 연결할 수 있다는 아이디어를 현실로 보여주었습니다.
3. BCI 기술의 발전: 뇌 속으로 더 가까이
1) EEG의 한계
- EEG는 두피 밖에서 수백만 개 뉴런의 평균적인 활동을 측정하기 때문에 신호가 약하고 해상도가 낮습니다. 이는 마치 방음이 안 되는 방에서 옆방의 대화를 어렴풋이 엿듣는 것과 같습니다. 더 정밀한 제어를 위해서는 뇌 안으로 직접 들어가 개별 뉴런의 활동을 측정해야 합니다.
2) 뉴런 활동 측정과 정보 해독
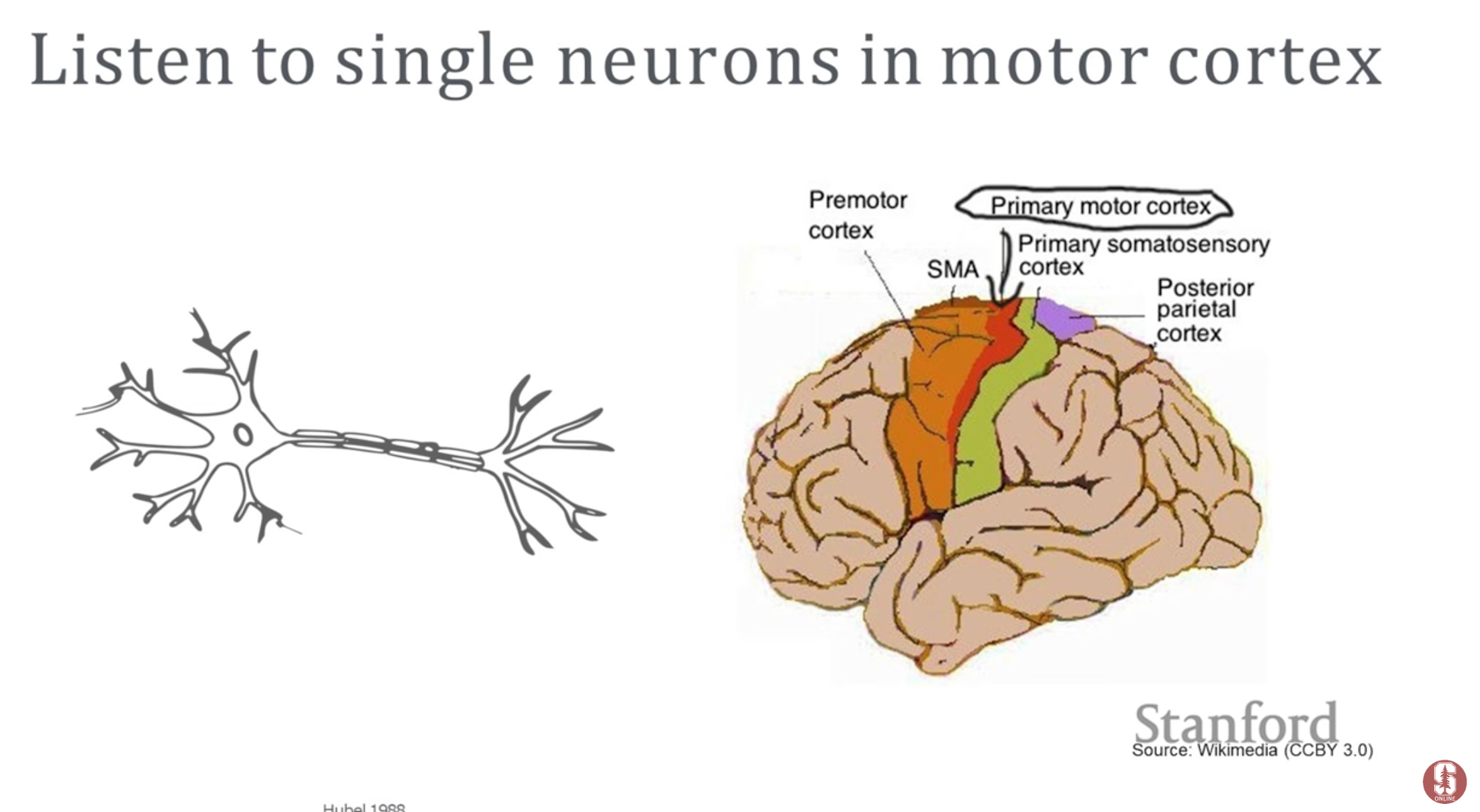
- 운동 피질 (Motor Cortex): 우리 몸의 모든 근육을 제어하는 운동 피질 영역의 뉴런 정보를 해독하면, 생각만으로 로봇 팔을 움직이거나 말을 할 수 있게 됩니다.
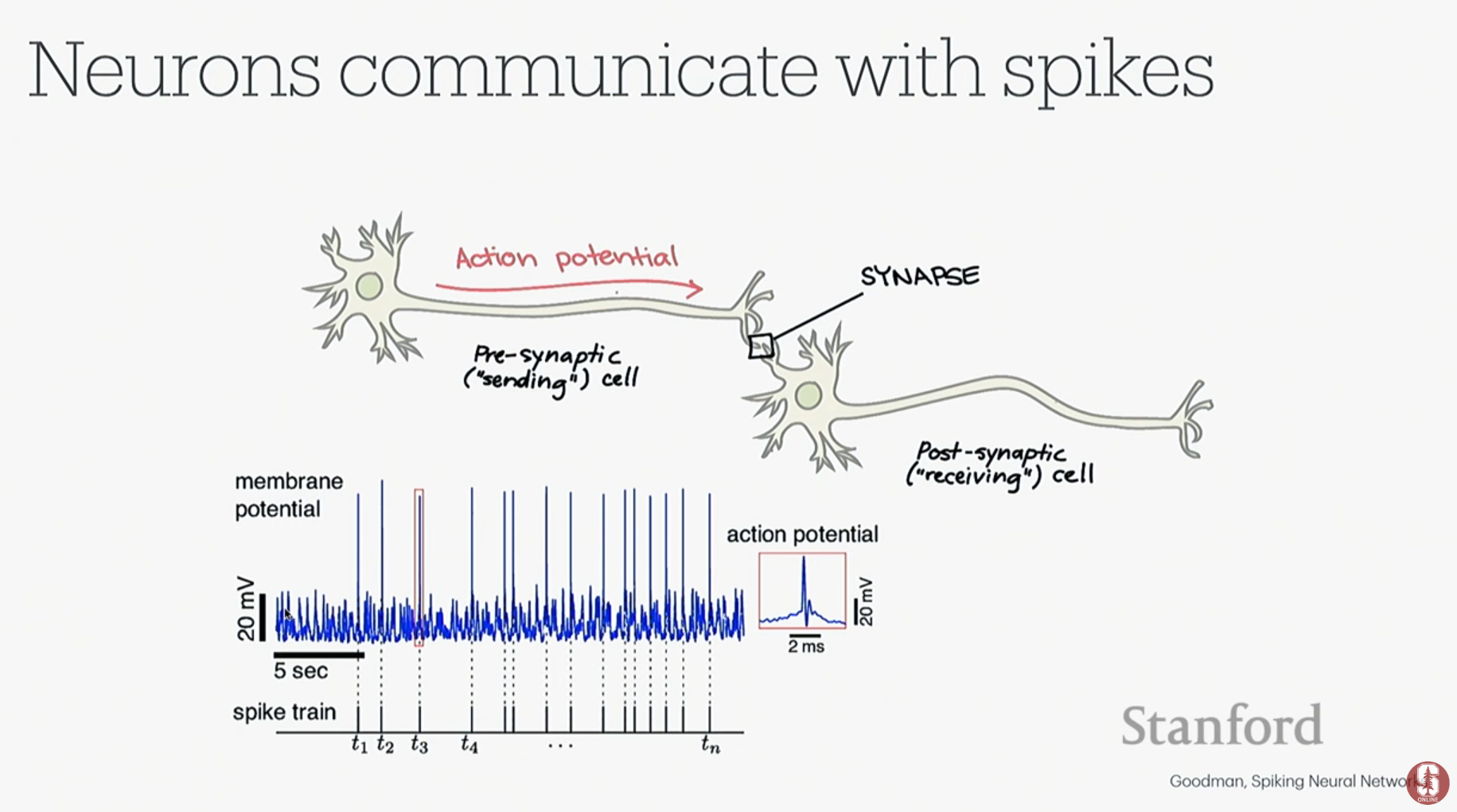
- 뉴런의 정보 전달 (스파이크): 뉴런은 활동 전위(Action Potential)라는 전기 신호, 즉 '스파이크'를 발생시켜 정보를 전달합니다. 전극을 뉴런 가까이에 배치하면 이 스파이크 신호를 측정할 수 있습니다.
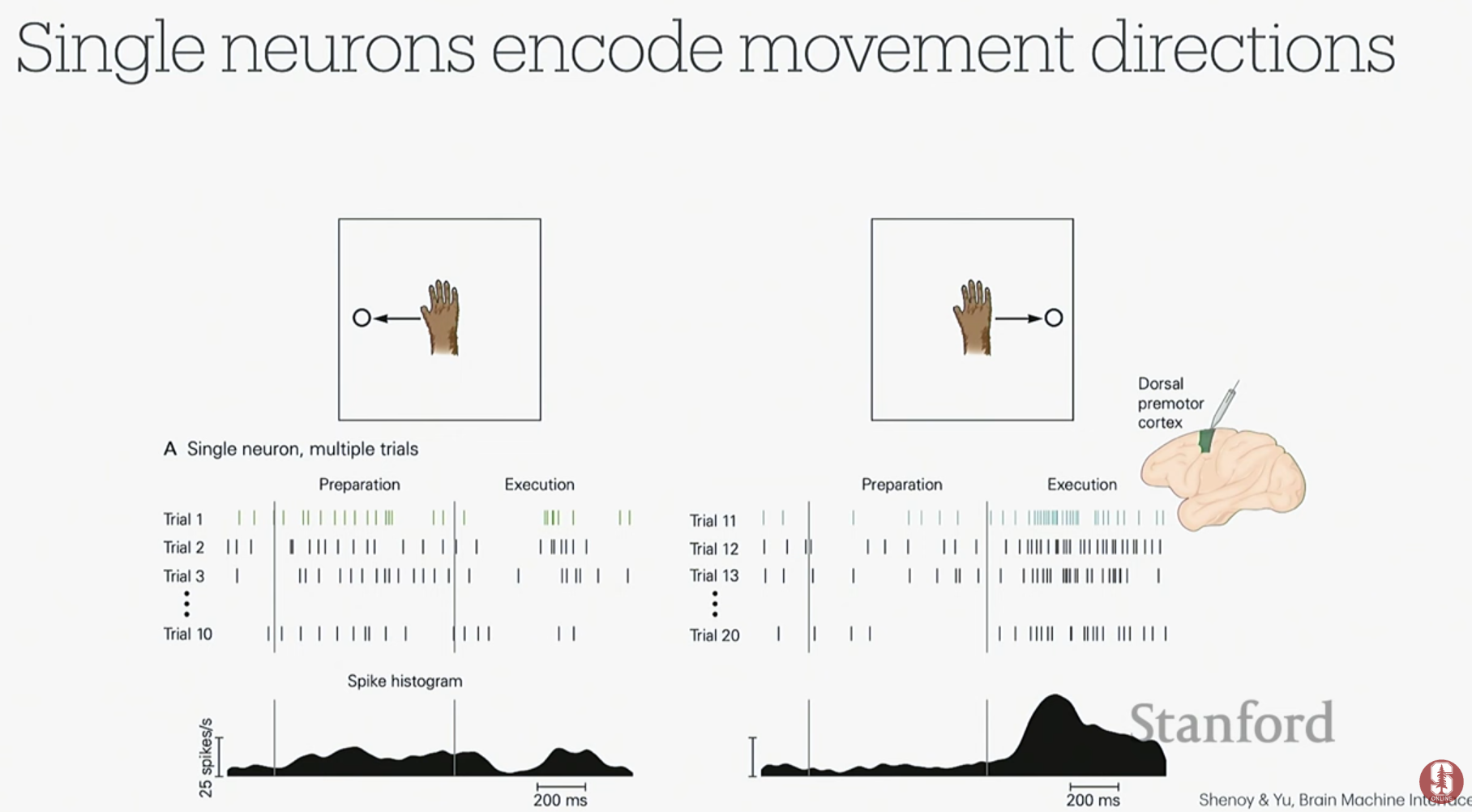
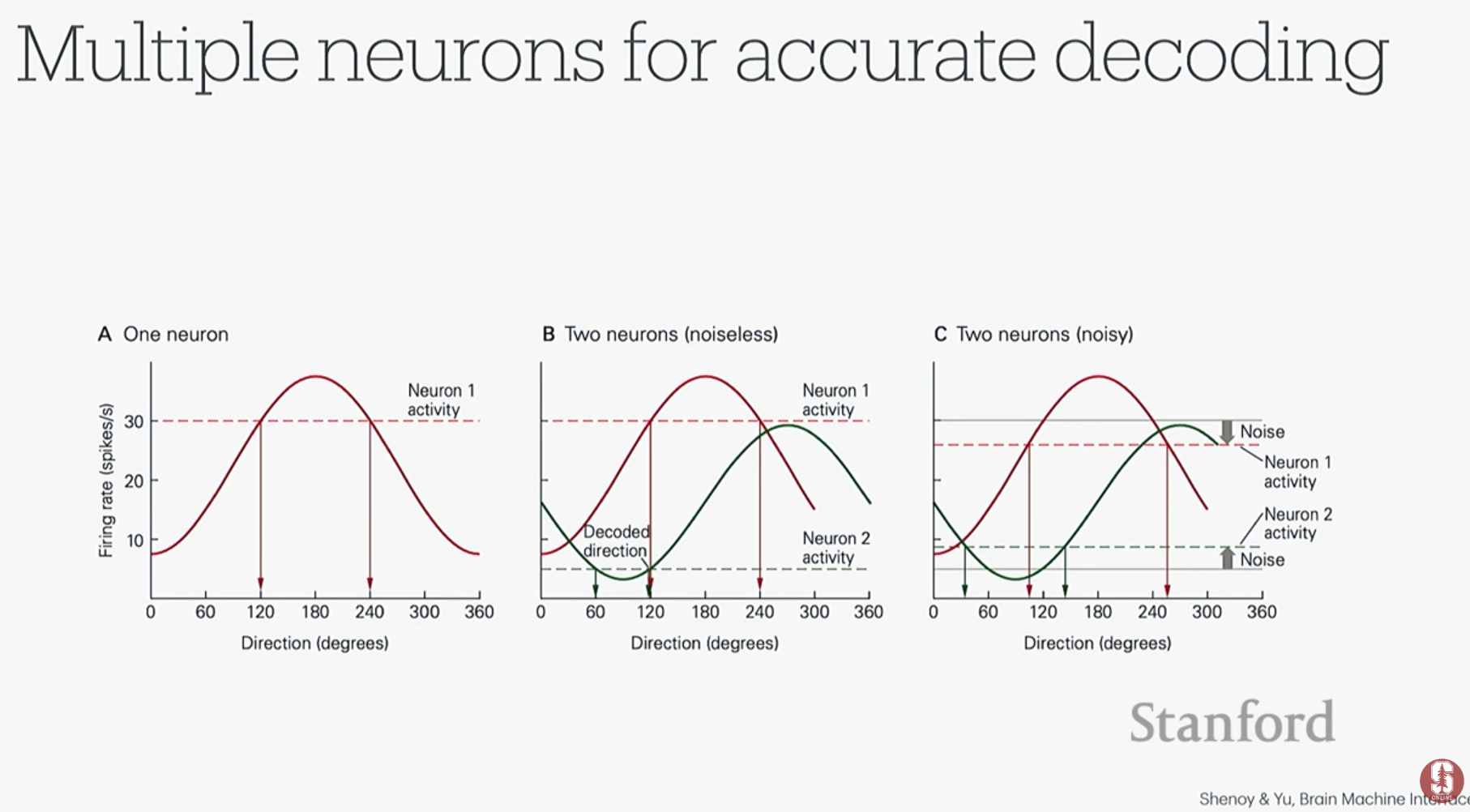
- 원숭이 실험과 튜닝 곡선: 원숭이가 손을 특정 방향으로 움직일 때, 특정 뉴런의 발화율(firing rate)이 가장 높아지는 현상을 발견했습니다. 이처럼 뉴런의 발화율이 움직임 방향에 따라 코사인 형태의 곡선을 그리는 것을 튜닝 곡선(Tuning Curve)이라고 하며, 이는 뉴런이 특정 정보를 인코딩하고 있음을 의미합니다.
3) 머신러닝의 활용
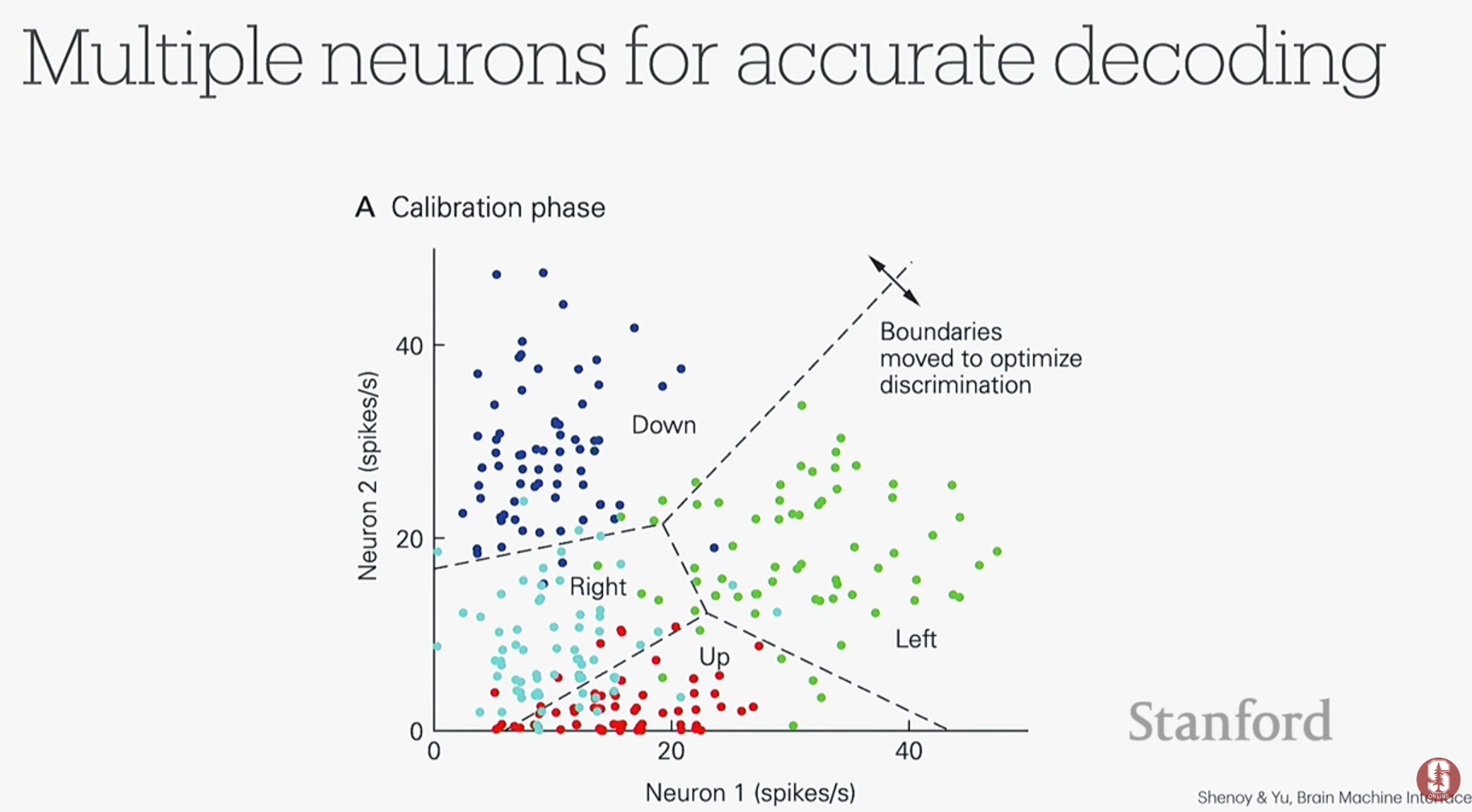
- 뉴런 신호에는 잡음(noise)이 많기 때문에, 여러 뉴런의 발화 조합 패턴을 학습하는 머신러닝 분류기를 사용하여 의도된 움직임을 더 정확하게 예측하고 분류할 수 있습니다.
4. 뇌 신호 기록 기술과 BCI의 실제 적용
1) 뇌 신호 기록 기술의 종류
- 뇌 신호 기록 기술은 공간 해상도(얼마나 미세한 영역을 측정하는지)와 시간 해상도(얼마나 빠르게 신호 변화를 측정하는지)에 따라 구분됩니다.
- fMRI: 혈류 변화를 측정하므로 시간 해상도가 낮아, 밀리초 단위로 빠르게 발생하는 뉴런의 발화 정보를 놓치기 쉽습니다.
- 다중 전극 어레이 (Multi-electrode Array): 현재 임상 시험에서 널리 사용되는 기술로, 미세한 바늘 형태의 전극을 뇌에 직접 삽입하여 수백 개 뉴런의 신호를 동시에 높은 시공간 해상도로 측정할 수 있습니다.
2) 운동 제어 BCI의 적용 사례
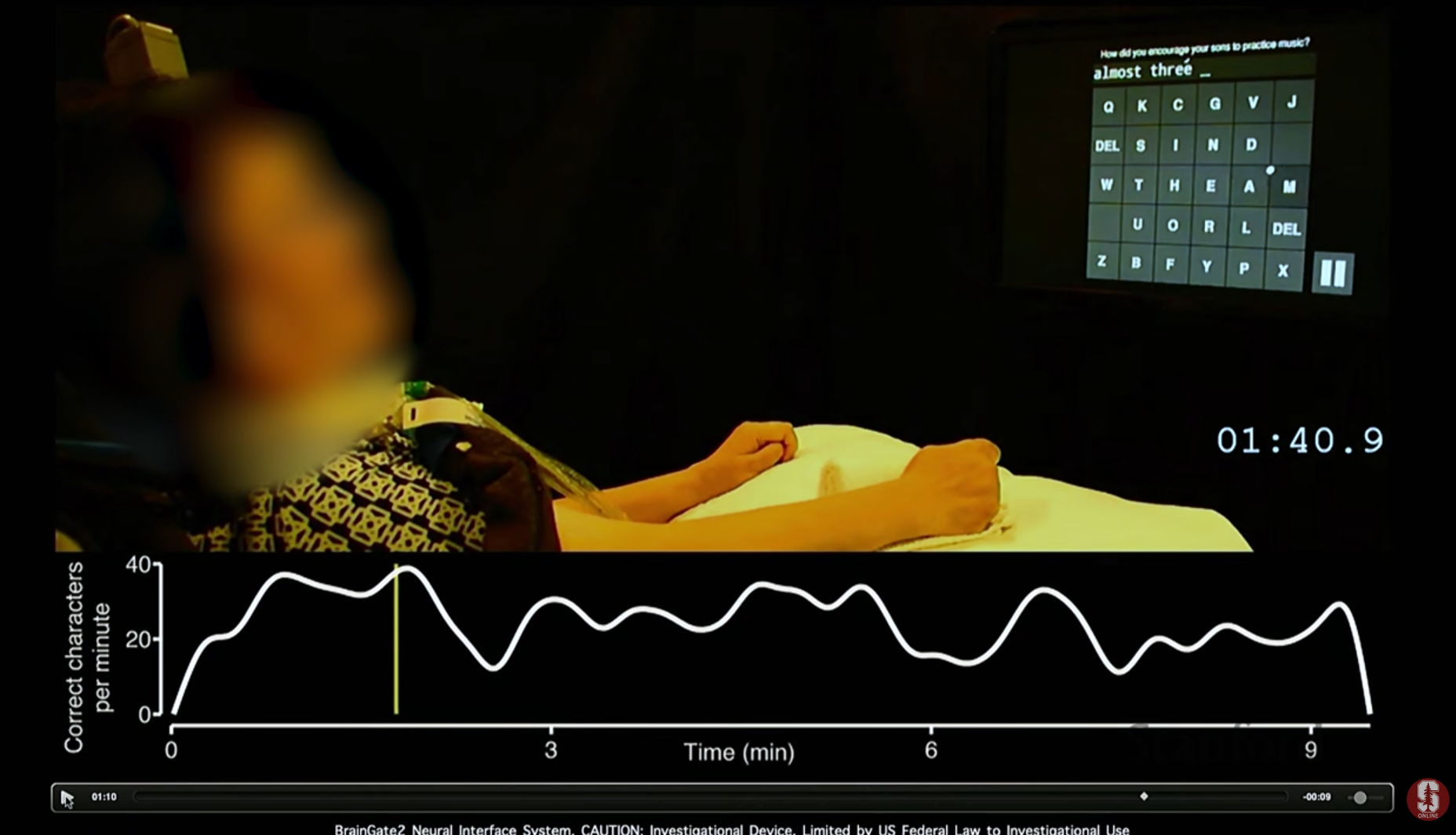
- 가상 키보드 타이핑: 척수 손상 환자가 운동 피질에 이식된 BCI를 통해 생각만으로 가상 키보드를 조작하여 분당 평균 20자, 최대 40자의 속도로 타이핑하는 데 성공했습니다. 이는 기존 보조 장치보다 훨씬 빠른 속도입니다.
- 로봇 팔 제어: 환자가 생각하는 대로 로봇 팔을 정교하게 제어하여 스스로 음료를 마시는 시연에 성공했습니다.
- 필기 능력 복원: 2021년 연구에서는 BCI를 통해 손으로 글씨를 쓰는 뇌 신호를 해독하여, 분당 18단어의 빠른 속도로 필기 능력을 복원하는 쾌거를 이루었습니다.
5. 음성 BCI: 말을 되찾아주는 기술
1) 언어 복원의 새로운 접근
- 자연스러운 대화 속도는 분당 150-160단어에 달하지만, 기존 커서 이동 방식의 BCI는 속도에 한계가 있었습니다.
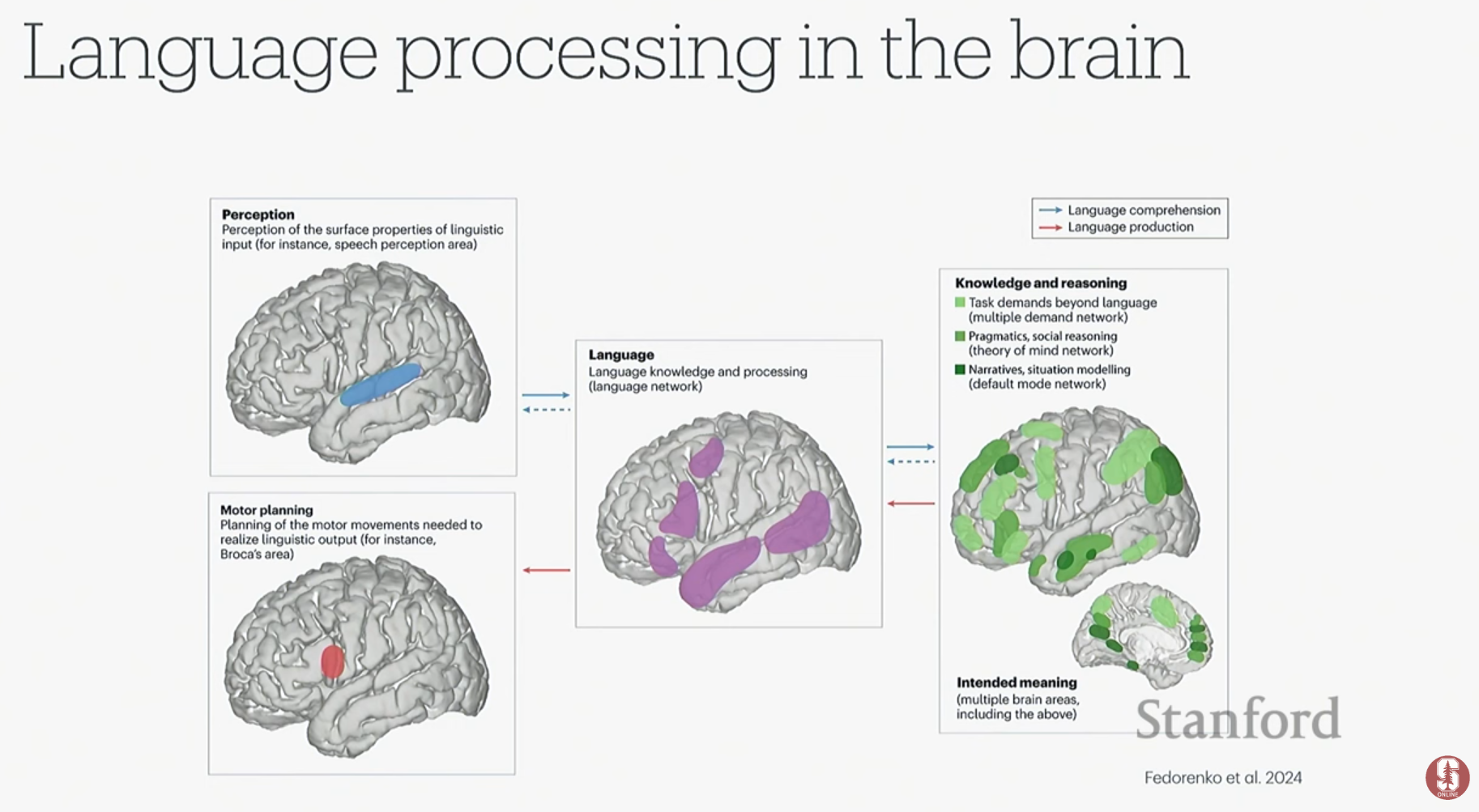
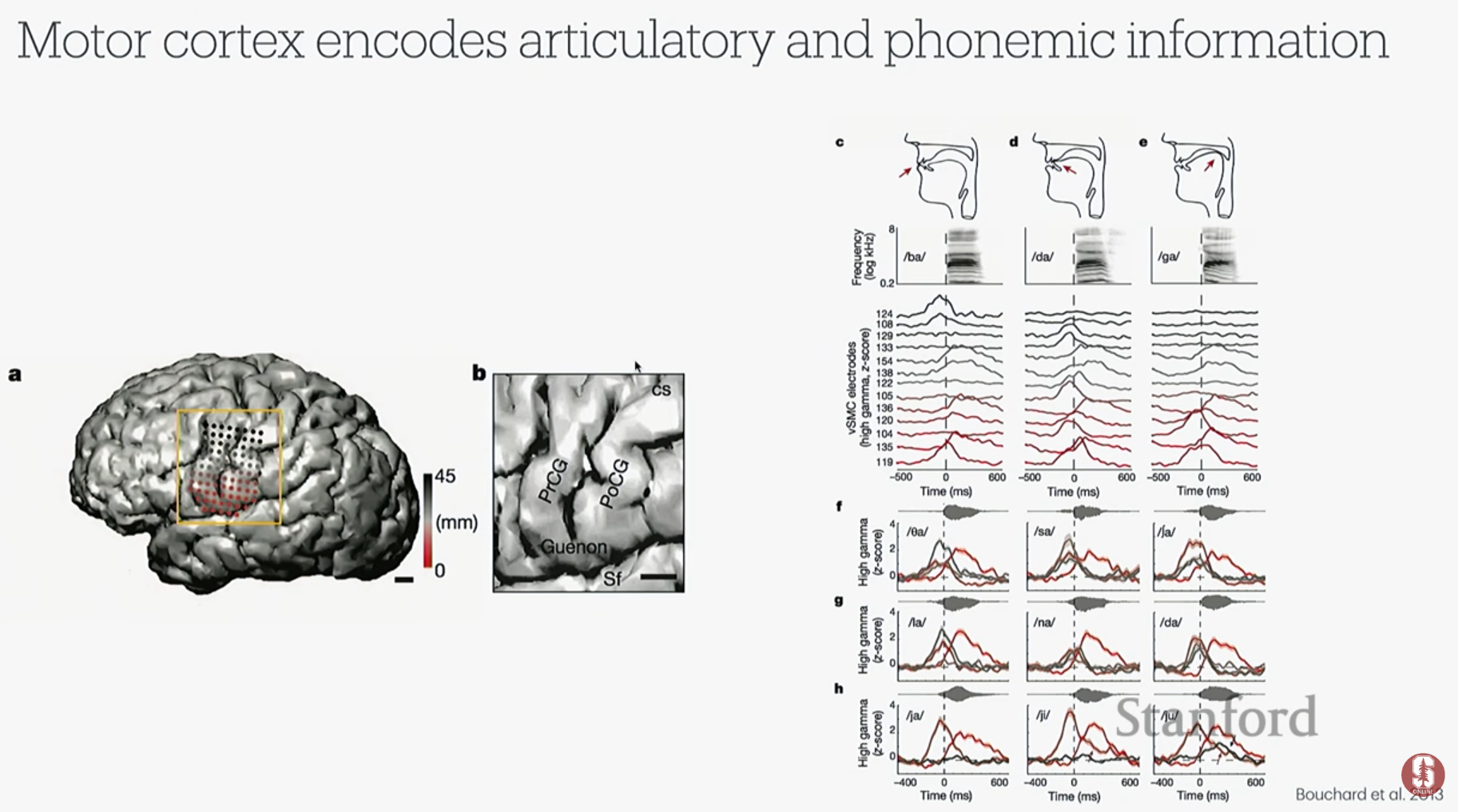
- 말을 할 때 입과 혀 등 조음 기관의 근육을 제어하는 운동 피질의 신호를 해독하면, 언어를 직접 복원할 수 있습니다.
- 연구팀은 복잡한 조음 움직임 대신, 언어의 기본 단위인 음소(Phonemes)를 해독하는 방식을 채택했습니다. 영어에는 약 40개의 음소가 있어, 수만 개의 단어를 직접 해독하는 것보다 훨씬 효율적입니다.
2) 스탠포드 연구실의 고성능 음성 BCI
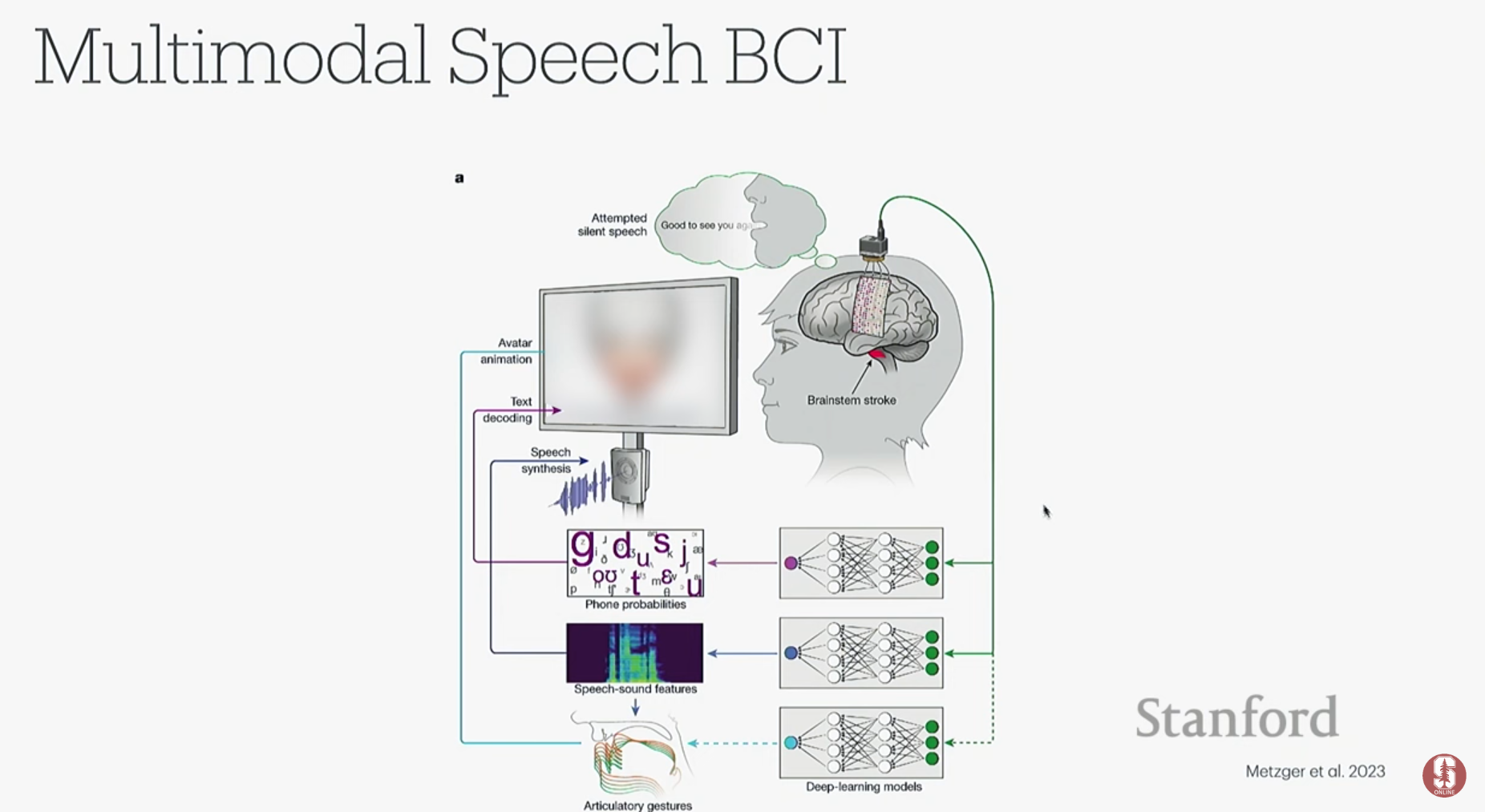
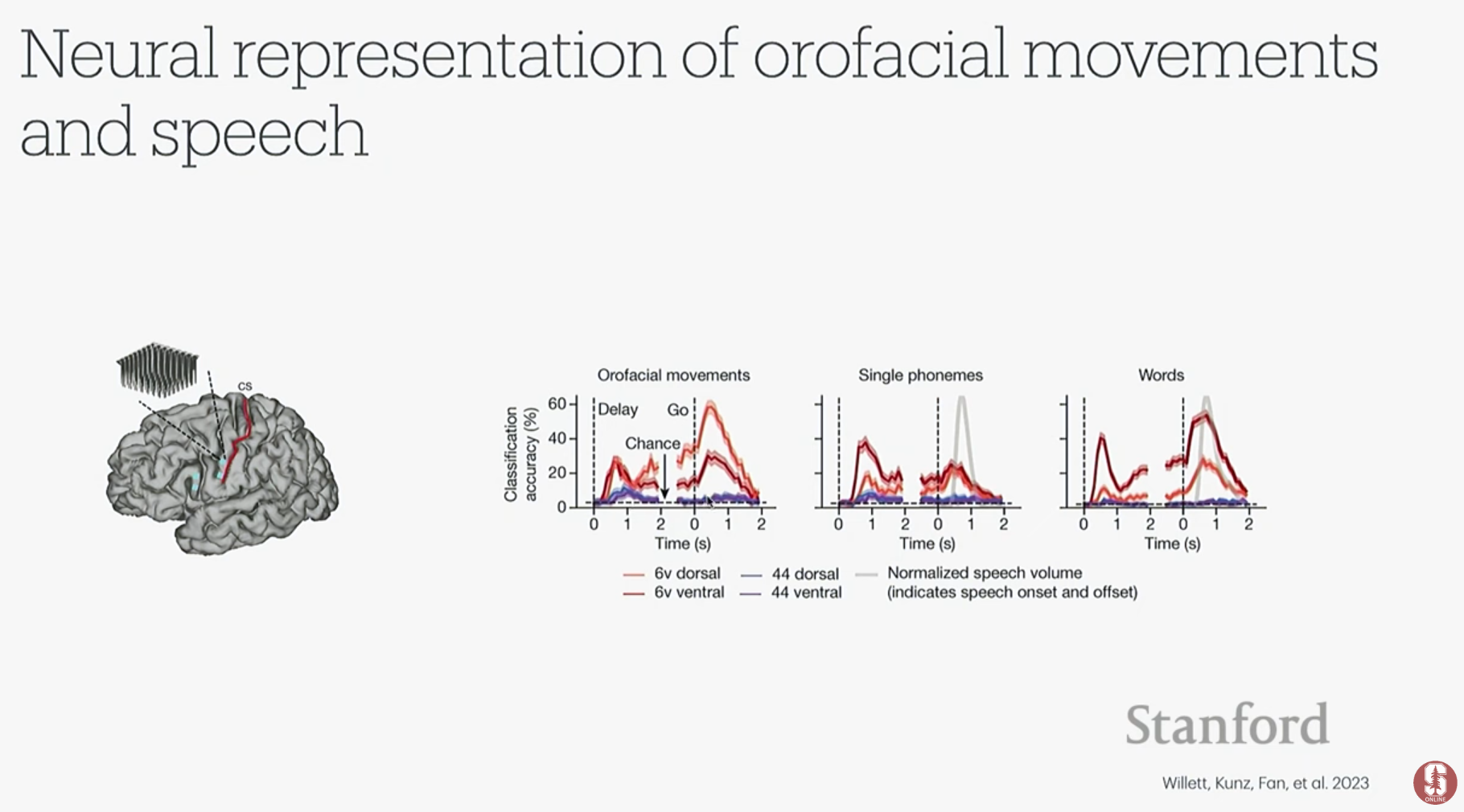
- 참가자 T12: 루게릭병(ALS)으로 언어 능력을 잃은 환자 T12의 운동 피질과 브로카 영역(언어 계획 담당)에 4개의 미세 전극 어레이를 이식했습니다.
- 연구 결과: 예상과 달리, 실제 발화 실행을 담당하는 운동 피질에서 언어 계획을 담당하는 브로카 영역보다 훨씬 더 풍부하고 정확한 음성 정보를 얻을 수 있었습니다.
- 실시간 뇌-텍스트 변환: T12가 문장을 말하려고 상상하자, BCI 시스템이 그녀의 뇌 신호를 실시간으로 해독하여 거의 완벽하게 텍스트로 변환해냈습니다. 소리를 내지 않고 입 모양만 따라 하거나 상상하는 것만으로도 높은 정확도를 보였습니다.
3) 음성 BCI의 기술적 원리: 딥러닝 디코더
-
데이터 수집: 약 3개월간 1만 개의 문장 데이터를 수집하여 뉴런 활동(입력)과 목표 문장(출력)의 쌍을 만들었습니다.
-
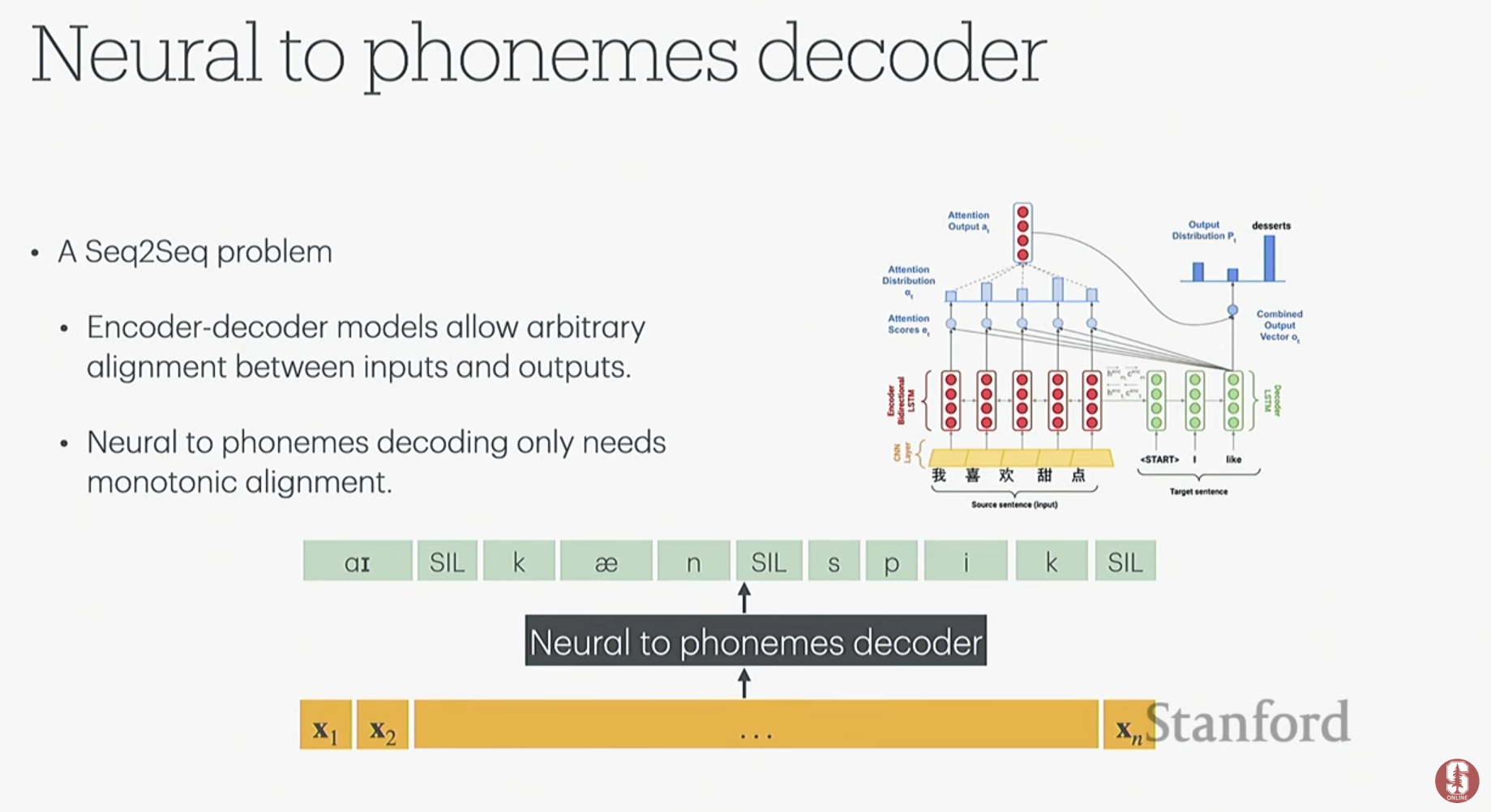
디코더 설계: 뉴런 신호 시퀀스(입력)를 단어 시퀀스(출력)로 변환하기 위해, 중간 단계로 음소(phoneme)를 예측하는 2단계 모델을 설계했습니다.
-
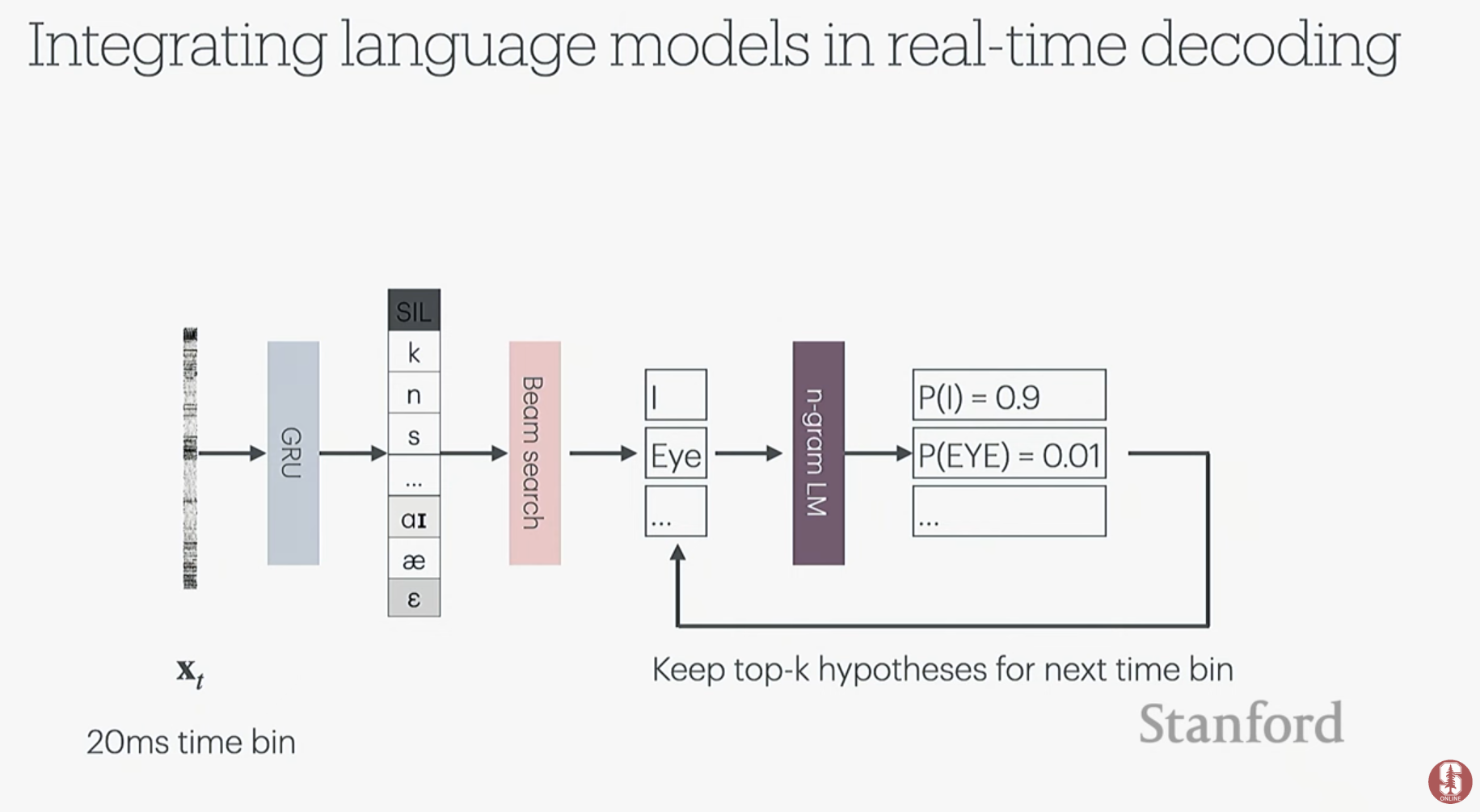
1단계 (뉴런 → 음소): 실시간 처리가 중요하기 때문에 거대한 Transformer 모델 대신 RNN 계열의 GRU(Gated Recurrent Unit) 모델을 사용했습니다. 여기서 입력과 출력의 길이가 다른 '정렬 문제'를 해결하기 위해 CTC(Connectionist Temporal Classification) 손실 함수가 핵심적인 역할을 합니다.
-
2단계 (음소 → 단어): 빔 탐색(Beam Search)과 실시간 처리에 용이한 N-gram 언어 모델을 사용하여 가장 가능성 있는 단어 시퀀스를 실시간으로 찾아냅니다. 문장 전체가 생성된 후에는 더 정교한 트랜스포머 언어 모델로 재평가하여 정확도를 높입니다.
심화 학습: CTC(Connectionist Temporal Classification)의 원리
- CTC는 입력 시퀀스(뇌 신호)와 출력 시퀀스(음소)의 길이가 다르고, 명확한 정렬 정보가 없을 때 사용되는 핵심 알고리즘입니다.
- 핵심 아이디어:
blank토큰- CTC는
blank토큰이라는 특별한 요소를 도입하여, 특정 시점에서 어떤 음소에도 해당하지 않는 부분을 처리하고, "HELLO"처럼 같은 글자가 반복되는 것을 구분합니다.
- CTC는
- 작동 방식 (3단계)
- 1. 프레임별 확률 출력: GRU 모델이 뇌 신호의 모든 시점마다 각 음소와
blank토큰에 대한 확률을 계산합니다. (예:H-H-[blank]-E-[blank]-L-L...) - 2. 반복 문자 통합: 연속되는 동일 문자를 하나로 합칩니다. 단,
blank가 사이에 있으면 합치지 않습니다. (예:L-[blank]-L은LL이 됨) - 3.
blank토큰 제거: 마지막으로 모든blank토큰을 제거하여 최종 음소 시퀀스를 얻습니다.
- 1. 프레임별 확률 출력: GRU 모델이 뇌 신호의 모든 시점마다 각 음소와
- 장점: 이 방식 덕분에 연구자들은 뇌 신호와 음소 데이터를 수동으로 정렬할 필요 없이, 모델이 스스로 정렬 방법을 학습하게 할 수 있습니다.


BCI의 미래와 윤리적 고찰
1) BCI의 미래 연구 방향
- 지속적인 성능 향상: 최근 연구에서는 BCI의 단어 오류율(Word Error Rate)이 0에 가까워지며, 일상적인 사용 가능성에 한 걸음 더 다가섰습니다.
- 내적 언어 (Inner Speech) 해독: 우리가 마음속으로 생각하는 '내적 언어'를 해독하는 연구가 진행 중입니다. 아직 초기 단계지만, 성공한다면 실제로 소리를 내려고 노력할 필요 없이 자연스러운 속도로 소통하는 길을 열어줄 것입니다.
2) 윤리적 문제
-
사생활 침해: 내적 언어 해독 기술이 발전하면 개인의 사적인 생각이나 기억까지 읽을 수 있게 될지 모른다는 윤리적 우려가 존재합니다.
-
인지 능력 향상 (Cognitive Enhancement): BCI가 질병 치료를 넘어 인간의 기억력이나 신체 능력을 강화하는 데 사용될 경우, 사회적 불평등을 야기할 수 있습니다.
-
사회적 논의의 필요성: BCI 기술이 인류에게 도움이 되는 방향으로 발전하기 위해서는 과학자, 엔지니어, 정책 입안자들이 함께 잠재적 위험을 인지하고 지속적으로 논의하는 것이 매우 중요합니다.
-
결론: BCI는 AI, 신경과학, 공학이 융합된 매우 흥미로운 분야입니다. 이 기술은 T12와 같은 사람들에게 다시 목소리를 찾아주는 희망이 될 뿐만 아니라, 뇌가 언어를 처리하는 방식에 대한 우리의 이해를 한 단계 끌어올릴 중요한 열쇠가 될 것입니다.