[논문 리뷰] AGATa: Attention-Guided Augmentation for Tabular Data in Contrastive Learning
논문 리뷰
1. 논문 정보
- 제목: AGATa: Attention-Guided Augmentation for Tabular Data in Contrastive Learning
- 저자: Moonjung Eo, Kyungeun Lee, Min-Kook Suh, Hye-Seung Cho, Ye Seul Sim, Woohyung Lim
- 소속: LG AI Research
- 발표: NeurIPS 2024 Workshop “Tabular Representation Learning (TRL)” Poster
- 주요 키워드: Tabular data, contrastive learning, data augmentation, attention guidance
2. 한 줄 요약
“AGATa는 Tabular 데이터에서 효과적인 contrastive learning을 위해,
모델 입력 단계에서 self-attention 기반으로 중요도가 낮은 feature를 선택하고,
CLS 토큰이 각 feature에 부여한 attention score를 기준으로
masking·shuffling·CutMix 등의 dynamic augmentation을 적용해
의미적으로 일관된 입력 변형을 생성하는 기법이다.”
3. 논문 배경 & 핵심 문제
Contrastive learning은 대표적인 Self-Supervised Learning(SSL) 방법으로서 서로 비슷하지만 변형된 두 view를 만들어 긍정 쌍(positive pair)을 형성하는 것이 핵심입니다.
이미지/텍스트처럼 명확한 구조가 없는 Tabular 데이터는 augmentation을 만드는 것이 까다롭고, 무작위로 입력을 변형하면 feature 간 상호작용이 왜곡될 위험이 큽니다.
이 논문은 Tabular 도메인에서의 contrastive learning 성능 개선을 위해 다음을 주장합니다:
“augmentation은 무작위가 아니라, 입력을 해석하는 모델의 관점(attention)을 기반으로 해야 한다.”
4. 전체 구조 및 아키텍처 요약
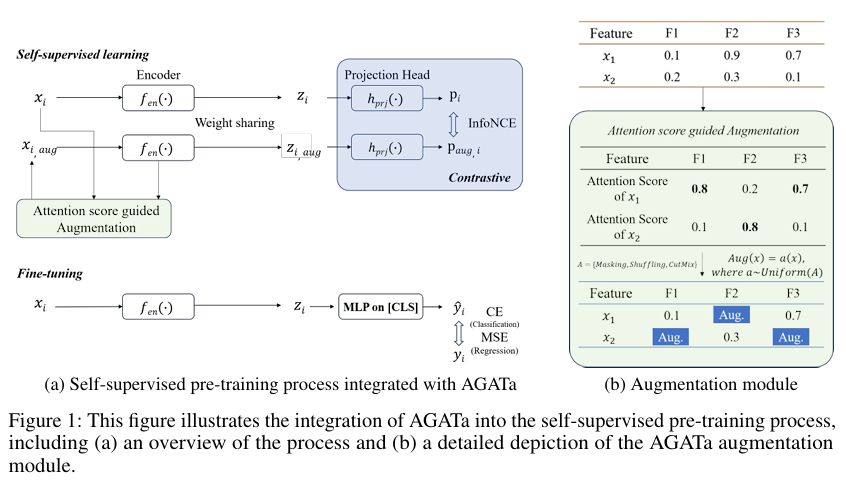
AGATa 프레임워크는 크게 다음 흐름으로 구성됩니다:
🔹 (1) Backbone
- Transformer 기반 모델을 Tabular 데이터에 적용
→ self-attention 모듈을 통해 feature 간 상호작용을 추정
🔹 (2) Attention-Guided Feature Selection
- Transformer의 최종 self-attention 스코어를 feature 중요도로 활용
→ attention score가 높은 feature는 중요한 정보로 간주
→ 스코어가 낮은 feature만 augmentation 후보로 선택

🔹 (3) Dynamic Augmentation Strategy
선택된 low-importance feature에 대해 무작위로 masking, shuffling, CutMix 중 하나를 적용:
- Masking: 해당 feature를 mask token으로 대체
- Shuffling: 같은 배치 내 다른 sample 값으로 섞기
- CutMix: 서로 다른 sample의 feature mix
이 변형은 같은 샘플로부터 생성된 augmented view를 원본과 긍정 쌍으로 만들어 contrastive 학습에 활용됩니다.
🔹 (4) Contrastive Training
- Augmented sample과 원본 sample을 positive pair로 삼고
- InfoNCE loss를 이용해 representation space에서 거리를 좁히고/멀게 학습시킴

5. 주요 구성 요소 상세 설명
🔹 ① Attention-Guided Feature Selection
Tabular 데이터는 피처 간 semantic 관계가 뚜렷하지 않기 때문에 어떤 feature를 변형해야 좋은 view가 되는지 모호합니다. 이를 해결하기 위해, AGATa는 Transformer self-attention score를 다음과 같이 활용합니다:
- Multi-head attention 결과를 평균하여 feature-level score 생성
- score가 낮은 feature들을 augmentation 대상으로 선택
즉, 중요 feature는 보존하고, 덜 중요한 feature만 변형함으로써 의미 있는 변형을 유도합니다.
🔹 ② Dynamic Augmentation Strategy
고정된 augmentation 방식을 쓰지 않고, epoch마다 무작위로 세 가지 방법을 섞어 사용함으로써 아래 효과를 의도합니다:
- 다양한 변형 패턴 생성
- Data distribution 내 장기적 다양성 확보
- 단일 augmentation의 한계 극복
🔹 ③ Contrastive Learning with InfoNCE
생성된 positive pair는 Transformer + projection head(MPL)를 통해 embedding space로 변환되며, InfoNCE loss로 학습됩니다.
이 과정은 representation이 유사한 입력을 가깝게, 다른 입력을 멀리 두도록 유도합니다.
6. 핵심 아이디어
AGATa의 본질은 다음 세 가지 관점을 동시에 만족시키는 설계입니다:
- Guided Augmentation: augmentation은 의미 없이 무작위가 아니라, transformer의 해석(attention)을 기반으로 한다.
- Selective Preservation: 중요한 feature는 그대로 둠으로써 의미 구조를 보존한다.
- Dynamic Diversity: 다양한 augmentation 방식을 섞어서 representation learning의 일반화 성능을 향상한다.
결과적으로, tabular 데이터의 구조적 한계를 보완한 contrastive view 생성 전략을 제시합니다.
7. 실험 결과 해석
AGATa는 아래와 같은 성능 개선을 보였습니다:
- 다양한 Tabular dataset(12개)에 대해 masking/shuffling/CutMix 대비 일관된 성능 향상
- DNN/Transformer 기반 방법들과 비교해도 경쟁력 있는 결과
- 특히 중요 feature를 보존하면서 변형하는 방식이 효과적임이 확인됨
또한 High-attention feature를 대상으로 augmentation을 할 경우(Reverse variant) 성능이 떨어지는 ablation study도 보고돼,
“중요 feature 보존”의 필요성을 실험적으로 뒷받침합니다.
8. 장점과 한계
장점
✅ Feature별 중요도 기반 augmentation
→ 의미 없는 noise를 줄이면서 contrastive view 생성
✅ 동적 augmentation strategy
→ 단일 augmentation보다 일반화 성능 향상
한계/아쉬운 점
❗ Transformer 기반 attention을 전제
→ 모델 구조 의존적임
❗ Augmentation 기법이 mask/shuffle/CutMix 범위로 제한됨
→ 더 advanced augmentation(learned)에 대한 비교 필요
❗ 실험 범위가 표준화된 대규모 benchmark까지는 아님
9. 개인적인 결론
AGATa는 Tabular contrastive learning에서 augmentation 설계의 근본 문제에 정면으로 접근한 흥미로운 연구입니다.
특히 “attention을 augmentation guide로 쓰는 것”은 매우 직관적이면서도 효과적인 전략이며, Tabular data 특유의 feature 편중 문제를 해결하는 하나의 답으로 보입니다.
이 접근은 향후 다른 Self-Supervised/Weakly Supervised framework에도 확장 가능하며, 기존 SSL에서 흔히 쓰는 무작위 입력 변형을 넘어선 방향성을 제시합니다.
10. 이어서 보면 좋은 키워드 / 논문
- Attention-based augmentation
- Transformer for tabular representation
- Contrastive learning view design
- Scalability of SSL for heterogeneous data
