1. 문제 정의 및 동기
자유 생성(Free-form Generation) 환경에서 LLM의 예측 불확실성(uncertainty) 을 정량화하는 문제를 다룬다.
QA와 같은 태스크에서는 단순 토큰 확률 기반 entropy가 의미적 중복 때문에 왜곡된다.
불확실성은 다음 두 항으로 분해된다:
- Aleatoric uncertainty: 의미적으로 여러 정답이 존재하는 구조적 불확실성
- Epistemic uncertainty: 모델의 지식 부족에서 오는 불확실성
기존 MC sampling은:
- 동일 의미의 응답을 반복 생성
- 의미 클러스터 추정 비효율
- 많은 샘플 필요
→ 의미 다양성을 직접 제어하는 sampling 전략 제안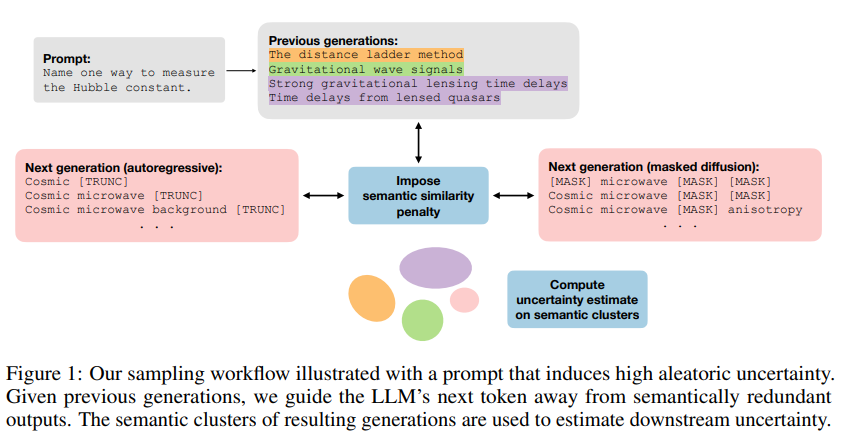
2. 의미 클러스터 기반 확률 정의
입력 , 모델 파라미터 .
모델의 생성 분포:
이를 의미 클러스터 단위로 집계:
실제 구현에서는 MC 샘플로 근사.
3. 전체 불확실성 분해
총 예측 불확실성:
- : 의미적 aleatoric entropy
- 두 번째 항 : epistemic uncertainty
핵심 목표는 의 정확한 추정.
4. Diversity-Steered Sampling (핵심 기법)
이미 생성된 답들과 의미적으로 유사한 후보의 확률을 감소시켜
의미 공간 탐색을 강제.
4.1 Autoregressive (ARM) 수정 확률
기존 토큰 확률:
수정된 제안 분포:
- : 이전 생성 문장 집합
- : NLI 기반 semantic similarity
- : 다양성 강도
의미적으로 기존 답과 가까울수록 확률 감소.
5. Forward 정보 흐름 (ARM)
- Prompt 입력
- 토큰 후보 확률 계산
- 각 후보에 대해:
- 기존 문장과 semantic score 계산
- 최대 similarity에 비례한 penalty 적용
- 수정된 softmax로 샘플링
- 완성 시 S에 추가
- 반복
→ 의미 공간에서 탐색 방향이 동적으로 조정됨.
6. Masked Diffusion Model (MDM) 확장
Diffusion step 에서:
기존:
수정:
- : partial sequence
Diffusion 구조에서도 semantic steering 적용.
7. Semantic Scorer (NLI 모듈)
구성:
- Pretrained NLI backbone
- 경량 fine-tuning
- 특수 토큰 처리:
[TRUNC],[MASK]
의미 유사도:
양방향 entailment 기반 similarity.
8. Importance Weighting (편향 보정)
제안 분포 에서 샘플링하므로 보정 필요.
가중치:
정규화:
9. Semantic Entropy 추정
클러스터 확률:
엔트로피:
Epistemic uncertainty는 mutual information 기반 계산.
10. 전체 알고리즘 (수식 기반 Pseudocode)


11. 실험 설정
- 다수 QA benchmark
- 비교:
- IID sampling
- Temperature sampling
- Diversity-steered
평가:
- estimator variance
- semantic cluster coverage
- sample efficiency
결과:
- 동일 정확도에서 샘플 수 감소
- 의미 클러스터 coverage 증가
- 분산 감소
12. Ablation
- Importance weighting 제거 → 편향 증가
- Lexical similarity 사용 → 성능 하락
- Adaptive λ → 고정 λ보다 안정적
- ARM/MDM 모두 개선 효과 확인
13. 한계
- NLI 모델 품질 의존
- 계산 비용 증가
- entailment 기반 의미 정의 한계
- 긴 prefix에서 semantic 평가 오차 가능
14. 핵심 기여 요약
- 의미 공간 기반 sampling 제어
- ARM/MDM 구조 일반화 가능
- Importance-weighted unbiased estimator
- 적은 샘플로 안정적 semantic uncertainty 추정
- Aleatoric/Epistemic 분해를 생성 구조에 직접 통합
15. 구성요소 점검
- Base LLM (ARM / MDM)
- Diversity steering module
- NLI semantic scorer
- Importance weighting
- Semantic clustering
- Entropy & MI estimator
- Adaptive λ
- 실험 및 ablation
모든 핵심 구성요소 포함 확인.

AI 공부합니다