논문링크 : Attention Is All You Need
1. 선택하게 된 이유
: GPT를 통해서 더 이상 공부하지 않을 수 없는 NLP에서 Transformer의 중요성을 알게 되어 한 번쯤 공부하고 싶었습니다. 그리고, SuperGlue 논문을 통해서 attention이 다양한 영역에도 사용될 수 있음을 깨달고 한번 제대로 공부해보고 싶은 마음이 들었습니다.
2. 서론
- Recurrent neural networks은 sequence modeling이랑 transduction(변환) 문제에서 유명한 방법이다.
- 하지만, 이 방법에는 sequential한 계산에서 memory constraints(제약)이 있다.
- Attention mechanisms는 sequence modeling과 transduction models와 같은 다양한 일에서 필수적인 부분이다.
- 왜냐하면, input과 output sequences에서 그들의 거리와 상관없이 dependencies(의존성) 모델링을 할 수 있게 하기 때문이다.
의존성 모델링은 데이터 내에서 서로 연결된 요소들 간의 관계나 의존성을 모델링하는 과정을 말한다.
- 이 논문에서는 Transformer라는 새로운 model architecture를 제시한다.
- 이 Transformer는 recurrence를 사용하지 않고, 대신에, 전적으로 attention mechanism에 의존한다.
3. 방법론(a) : Background
- CNN을 사용한 모든 모델들은 sequential computation(연산)을 줄이기 위한 노력을 하지만, 거리에 따라 연산이 늘어나는 문제가 있고, 이는 거리가 있는 positions들 사이에 dependecies를 학습하기 어렵게 한다.
- Transformer은 이러한 연산을 상수 수준으로 줄일 수 있다. (해상도가 감소하는 리스크가 존재하긴 하다.)
- Self-attention은 하나의 sequence에서 다른 위치들에 대해서 attention mechanism을 적용하는 방법이다.
- 이를 통해, sequence의 representation(특징과 패턴)을 계산할 수 있다.
- End-to-end memory networks는 sequence-aligned recurrence 대신에 recurrent attention mechanism을 기반으로 한다.
sequence-aligned recurrence는 주로 RNN과 함께 입력데이터 순서를 기준으로 순차적으로 처리하는 방법이다.
recurrent attention mechanism은 입력데이터의 특정부분에 집중하여 각 단계별 주목 요소 설정하여 선택적으로 집중이 가능한 방법이다.
- Transformer는 전적으로 self-attention에 의존하는 첫 transduction(변환) model이다.
여기서 transduction model은 입력 시퀀스를 기반으로 직접 출력을 생성하는 방식을 말한다. - 이 self-attention은 sequence-aligned인 RNN과 Convolution 없이 input과 output의 representation(특징과 패턴)을 계산한다.
4. 방법론(b) : Model Architecture
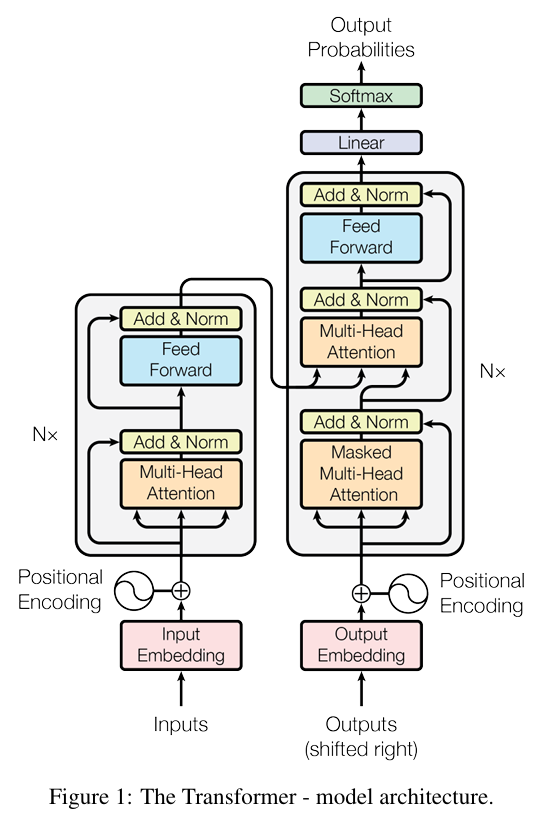
- encoder는 symbol representation 인 input sequence를 continuous representations 인 sequence로 맵핑한다.
- 가 주어지면, decoder는 symbols의 각 요소를 한번에 하나씩 output sequence 으로 생성한다.
- 이때, 각 step에서 model은 auto-regressive하다.
auto-regressive(자기회귀)는 이전의 생성된 symbols를 다음 생성과정의 추가적인 input으로 사용하는 것이다. - Transformer는 다음 2가지 층을 합쳐놓은 구조를 사용한다.
- self-attention
- point-wise, fully connected layers(뒤에서 소개될 Feed-Forward Network에서 사용되는 두가지 구조다.)
point-wise는 입력의 각 위치가 동일한 방식으로 연산되고 서로 영향을 주지 않는다는 의미이다.
fully connected layer는 모든 입력노드가 모든 출력 노드와 연결되어 입력 벡터의 차원을 변환하거나 비선형성을 추가하는 활성화함수를 적용하는 과정을 가진다.
4-1. Encoder and Decoder Stacks
(Figure 1)을 보면서 읽으면 이해가 잘 된다.
-
Encoder는 = 6인 동일한 layers의 stack으로 이루어져 있다.
-
각 layer는 2가지의 sub-layers로 구성된다.
- muti-head self-attention
- position-wise fully connected feed-forward netwrok
-
그리고, residual connection을 추가하고 layer normalization을 적용한다.
-
결국 하나의 sub-layer를 통과하면 다음과 같은 과정을 가지게 된다.
여기서 는 각 sub-layer에 맞는 함수다. -
그리고 residual connections을 적용하기 위해, 모든 sub-layers와 embedding layers는 = 512인 차원의 데이터를 outputs으로 만들어 낸다.
- Decoder도 마찬가지로, = 6인 동일한 layers로 이루어져 있다.
- Encoder와 달리, Decoder는 세 번째 sub-layer를 추가했다.
- 이 sub-layer는 encoder stack에서 나온 output에 multi-head attention을 적용한다.
- Decoder도 마찬가지로, 각 sub-layer에 residual connection을 더하고 layer normalization을 적용한다.
- 그리고, Decoder에서는 self-attention layer를 수정하여 특정 위치가 그 이후의 위치를 보지 못하게 막도록 masking작업을 더했다.
decoder는 아무래도 정답 시퀀스가 모두 들어가니까, 순차적으로 시퀀스를 처리하도록 하기 위함인 것 같다. 이를 통해, 예측의 일반화를 높일 수 있을 것 같다.
4-2. Attention
- Attention function은 query와 key-value 조합을 output에 매핑하는 것이라고 볼 수 있다.
- 이 output은 value의 weighted sum(가중 합)으로 볼 수 있다. (query와 key의 유사도로 각 value에 가중치를 곱하고 더하여 유사도 높은 특정 value들의 특징이 담기도록 한다의 의미다.)
4-2-a. Scaled Dot-Product Attention
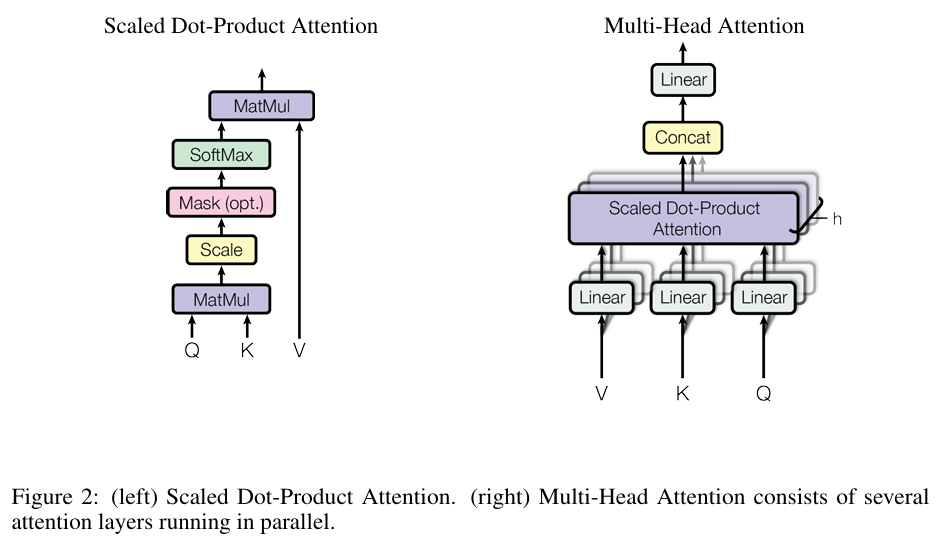
-
input에서 query와 key의 차원은 로 value의 차원은 로 나타낸다.
-
(Figure 2)에서의 'Scaled Dot-Product Attention'은 다음과 같은 식으로 나타낼 수 있다.
Equation 1
Q와 K를 내적하고 로 나눈 다음에 softmax 함수를 통해 가중치를 얻어내고 이를 V에 곱하는 방식이다. -
여기서 로 나눠서 스케일을 적용한 이유는 attention function으로 자주 사용되는 dot-product attention과 additive attention이 낮은 에서는 비슷하다가 가 커질수록 성능의 차이가 발생하여 스케일을 적용했다.
-
이렇게 까지 dot-product attention을 사용하는 이유는 학습 과정에서 더 빠르고 더 공간 효율적이기 때문이다.
4-2-b. Multi-Head Attention
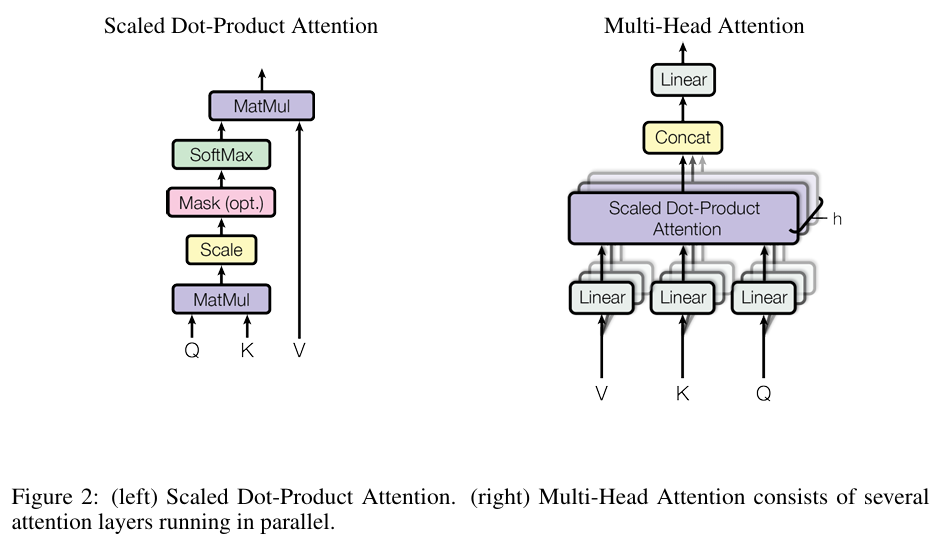
-
하나의 attention fuction으로 의 차원의 를 계산하는 대신에 에 linear project 적용하여 attention function을 병렬로 수행하여 의 차원의 output을 만들 수 있게 했다.
-
(Figure 2)의 'Multi-Head Attention'을 식으로 나타내면 다음과 같다.
where -
여기서 들은 모두 linear projection으로 위한 parameter matrices이다.
-
이 논문에서는 병렬 attention layers를 = 8로 설정하고, 각 층에서는 = = = 64로 사용했다.
-
각 head에서의 차원을 줄였기 때문에, 총 연산 비용은 전체 차원에 대한 single-head attention과 비슷하다.
노력해서 연산 비용을 맞출거면 왜 multi-head attention을 쓰는지 궁금해서 찾아본 결과 내 생각은 다음과 같다.
각 헤드가 conv 하나의 층과 같은 역할이라고 생각하면 쉽다.
각 헤드에서 W들이 projection해서 추출하는 특징이 헤드마다 다르기 때문에, 각 헤드 별로 다른 특징을 담을 수 있는 것이다. 이를 모두 반영이 되는 V를 얻기 때문에 더 이점이 있다고 볼 수 있다고 이해했다.
4-2-c. Applications of Attention in our Model
- 이러한 multi-head attention은 다음 3가지 상황에 쓰인다.
- encoder와 decoder가 만나는 층에서의 encoder-decoder 메커니즘
- encoder 내에서의 self-attention 메커니즘
- decoder 내에서의 self-attention 메커니즘
4-3. Position-wise Feed-Forward Networks
-
Fully connected feed-forward network에 대한 식은 다음과 같다.
Equation 2
-
모든 sub-layer에서의 FFN 식의 구조는 같지만, 사용하는 파라미터()는 layer마다 다르다.
-
이 FFN 구조는 두개의 kernel size 1인 두 개의 Convolutions으로 이루어 졌다고 볼 수도 있다.
-
input과 output의 차원()은 512이고, 그 사이의 은닉층()에서의 차원은 2048이다
4-4. Embeddings and Softmax
- 이 논문에서는 학습된 embeddings과 linear transformation을 사용한다.
- 여기서 embedding은 input과 output의 token들을 vector들로 변환하고, linear transformation은 decoder의 output을 다음 token에 대한 예측 확률로 바꾸는 역할을 한다.
- 이때, 두 기능이 사용하는 weight matrix는 같다.
왜냐하면, 모델의 파라미터 수를 줄이고 일관성을 위해서다. 쉽게 생각해서, 하나의 vocab(단어 사전)을 사용해서 일관성을 얻기 위함인 것 같다. - 그리고, embedding layer에서는 가중치에 를 곱한다.
정확히는 이해하지 못했지만, 이는 그냥 임베딩 벡터의 크기를 조정해서 임베딩의 내적이 너무 작아지지 않도록 하기 위함이라고 한다.
4-5. Positional Encoding
-
Transformer는 recurrence와 convolution이 없기 때문에, sequence의 순서를 이용하기 위해서 반드시 position 정보를 넣어줘야 한다.
-
Positional encoding 식은 다음과 같다.
는 position, 는 차원을 의미한다. -
즉, positional encoding의 각 차원은 sinusoid(정현파)를 이룬다.
-
위와 같은 식을 사용하면, 사인과 코사인 함수의 주기성으로 서로 다른 위치간 관계를 알 수 있고, 서로 다른 위치에 동일한 벡터를 가질 수 없도록 한다.
-
그리고, 파장은 부터 까지로 변화하고, 기하급수적으로 진행한다.(즉, 등비수열로 커진다.)
때문에 위와 같은 파장을 가지는 것 같다.
이 부분은 조금 더 이해가 필요할 것 같다.
4-6. Why Self-Attention

-
(Table 1)과 같이 다음 3가지 측면에서 장점을 가지기 때문에 self-attention을 선택했다.
- 각 layer에서의 총 연산 복잡도
- 최소한의 sequential operations의 수로 병렬화할 수 있는 계산의 양
- 네트워크에서 멀리 떨어진 요소들 간의 경로 길이
-
대부분의 경우에서 은 보다 작고, 심지어 Conv의 가장 성능이 좋은 case일 때도 self-attention과 비슷한 성능을 가지기 때문에 다른 방법보다 self-attention이 좋다.
5. 주요 결과
- adam optimizer를 사용했고, 다음과 같은 파라미터와 learning rate 식을 사용했다.
adam 파라미터는 로 설정했다.
- Residual Dropout은 를 사용했다.
- Label Smoothing은 를 사용했다.
Label Smoothing은 그 파라미터만큼 확률을 감소시켜서 나머지 확률에 분배하는 것이다. [0, 1, 0] -> [0.05, 0.9, 0.05]. 쉽게 말해서, hard한 방식을 soft한 방식으로 변경한다.
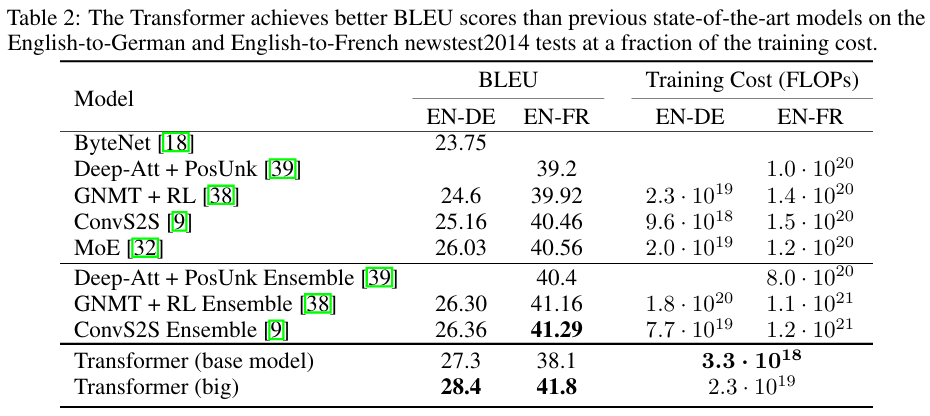
- EN-DE이 을 사용한 것과 달리, EN-FR은 0.1을 사용했다.
- 그리고, beam search는 beam size 4와 length penalty = 0.6으로 설정하여 사용했다.
beam search는 번역에 사용되는 탐색 알고리즘이다. 여러 후보를 정한 후, 그 후보들의 다음 단계 후보 중 가장 높은 후보 점수를 선택한다.
`추가적으로, beam size은 동시에 유지하는 후보 수를 나타내어, 값이 작을수록 좋은 후보를 놓칠 가능성이 있다.
length penalty는 작을 수록 짧은 문장도 어느정도 허용한다는 의미이고, 문장 길이 보정효과를 가진다. 보통 0.5~1.0의 값을 가진다. - 최대 output 길이는 'input length + 50'으로 설정했고 가능하면 빨리 끝낼 수 있게 했다.
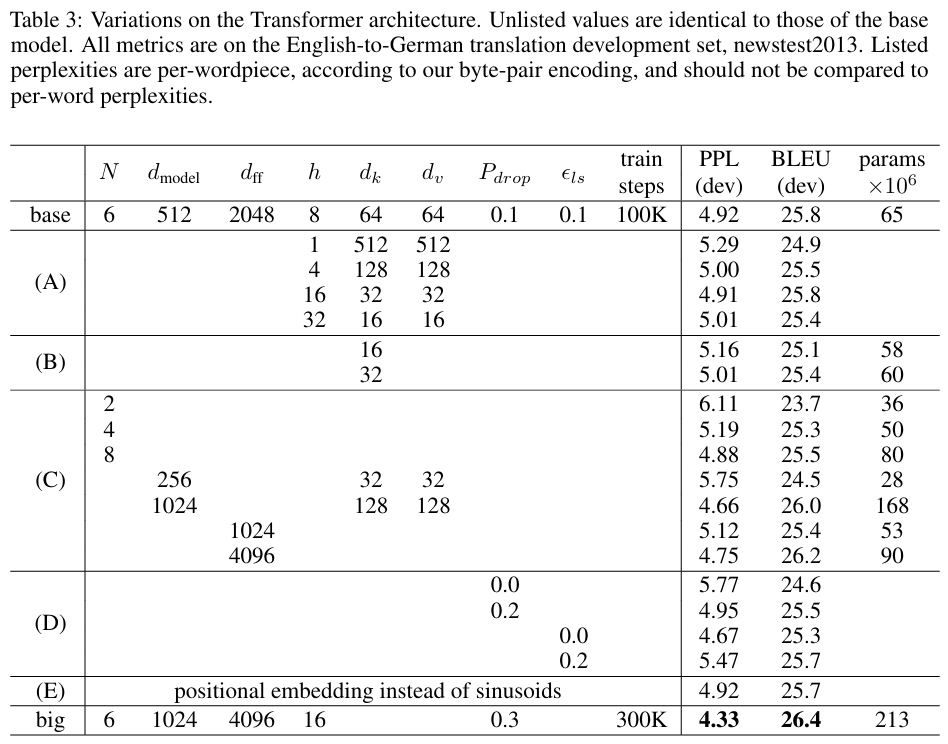
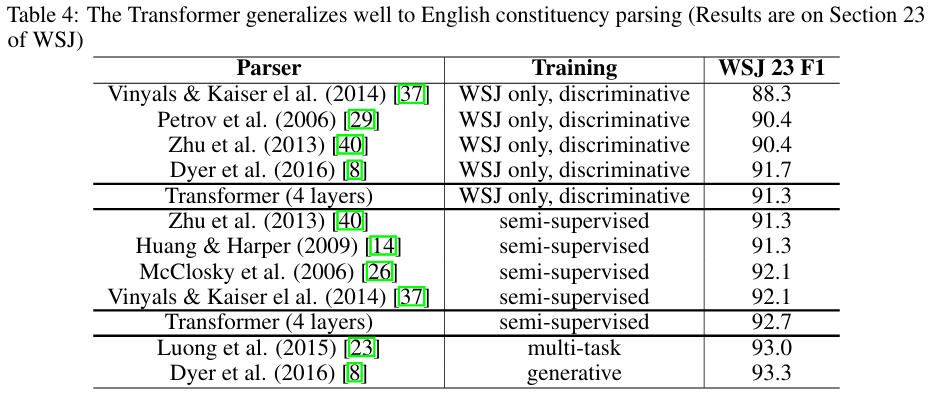
- Transformer가 다른 작업에 일반화될 수 있는지 평가하보려 했을 때, 가장 중요한 점은 output이 강한 구조적 제약(구조적으로 옳아야 하고)을 받고, input보다 훨씬 길어야 한다는 것이었다.
- 그래서 'input length + 300', 'beam size 21', ' = 0.3'으로 hyperparameter을 수정하고 WSJ 데이터로 F1score점수를 나타냈을 때, (Table 4)와 같은 결과를 얻을 수 있었다.
- 이러한 inference를 통해 다른 작업에 일반화될 수 있음을 확인했다.
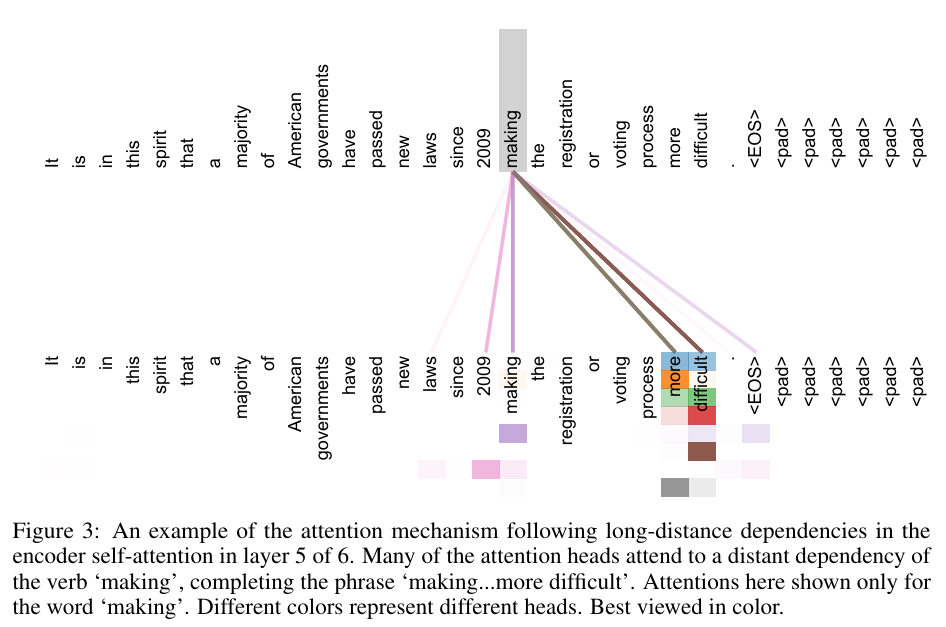
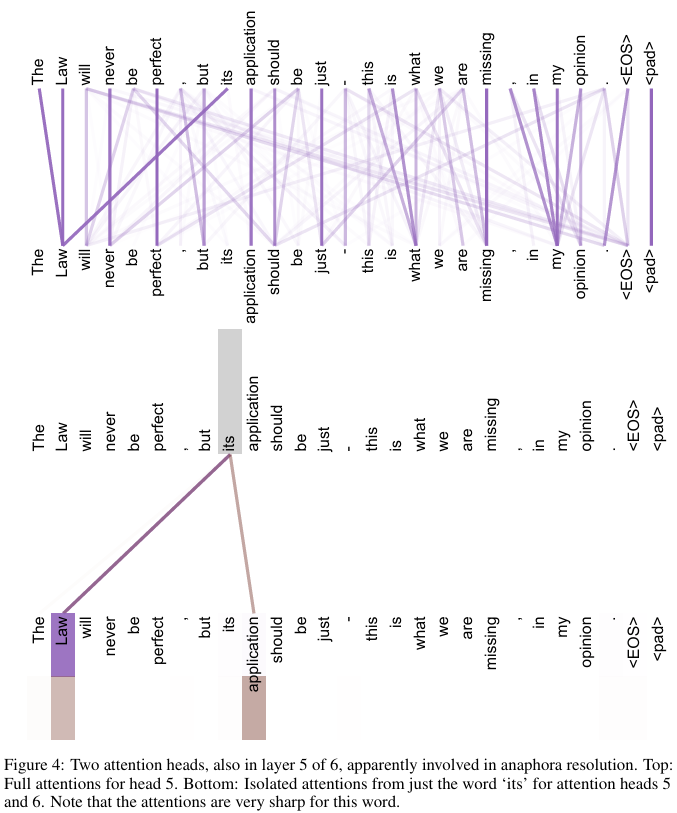
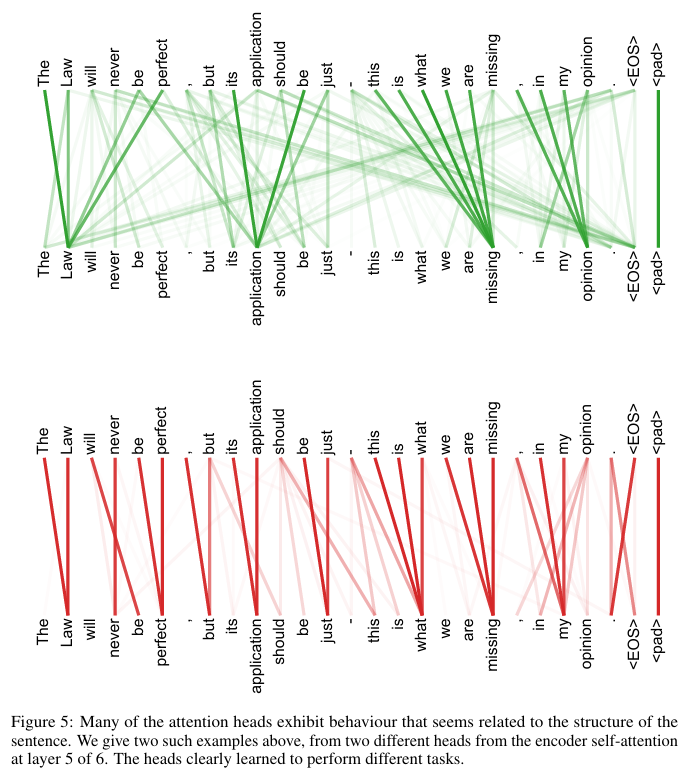
6. Comment
: 확실히 SuperGlue에서 한번 제대로 공부하고 가서 큰 틀의 논리는 이해하기 쉬웠습니다. 그리고, 이전 논문보다 확률적 수식 요소가 적다보니, 조금 편하게 읽을 수 있었습니다. 하지만, 아직 수식과 용어 대한 깊은 이해가 바로 와닿지 않고, 특히, FCN의 정확한 메커니즘과 의미를 잘 몰라서 공부해야겠다고 느꼈습니다. 정말 깔끔한 내용과 깔끔한 구조로 이렇게 중요한 구조를 만들어 냈다는 것이 정말 신기하고 대단하다고 느꼈습니다.
더 자세한 내용은 논문 원본을 참고하시기 바랍니다.
개인의 주관이 반영된 해석이라 논문의 의도와 다를 수 있습니다.
오류가 있다면 댓글로 알려주시면 감사하겠습니다!